JAVA中使用最廣泛的本地快取?Ehcache的自信從何而來 —— 感受來自Ehcache的強大實力

大家好,又見面了。
本文是筆者作為掘金技術社群簽約作者的身份輸出的快取專欄系列內容,將會通過系列專題,講清楚快取的方方面面。如果感興趣,歡迎關注以獲取後續更新。
作為《深入理解快取原理與實戰設計》系列專欄,前面幾篇文章中我們詳細的介紹與探討了Guava Cache與Caffeine的實現、特性與使用方式。提到JAVA本地快取框架,還有一個同樣無法被忽視的強大存在 —— Ehcache!它最初是由Greg Luck於2003年開始開發,截止目前,Ehcache已經演進到了3.10.0版本,各方面的能力已經構建的非常完善。Ehcache官網上也毫不謙虛的描述自己是「Java's most widely-used cache」,即JAVA中使用最廣泛的快取,足見Ehcache的強大與自信。

此外,Ehcache還是被Hibernate選中並預設整合的快取框架,它究竟有什麼魅力可以讓著名的Hibernate對其青眼有加?它與Caffeine又有啥區別呢?我們實際的業務專案裡又該如何取捨呢?帶著這些疑問,接下來就來認識下Ehcache,一睹Ehcache那些閃閃發光的優秀特性吧!

Ehcache的閃光特性
支援多級快取
之前文章中我們介紹過的Guava Cache或者是Caffeine,都是純記憶體快取,使用上會受到記憶體大小的制約,而Ehcache則打破了這一約束。Ehcache2.x時代就已經支援了基於記憶體和磁碟的二級快取能力,而演進到Ehcache3.x版本時進一步擴充套件了此部分能力,增加了對於堆外快取的支援。此外,結合Ehcache原生支援的叢集能力,又可以打破單機的限制,完全解決容量這一制約因素。
綜合而言,Ehcache支援的快取形式就有了如下四種:
- 堆內快取(heap)
所謂的堆內(heap)快取,就是我們常規意義上說的記憶體快取,嚴格意義上來說,是指被JVM託管佔用的部分記憶體。記憶體快取最大的優勢就是具有超快的讀寫速度,但是不足點就在於容量有限、且無法持久化。
在建立快取的時候可以指定使用堆內快取,也可以一併指定堆內快取允許的最大位元組數。
// 指定使用堆內快取,並限制最大容量為100M
ResourcePoolsBuilder.newResourcePoolsBuilder().heap(100, MemoryUnit.MB);
除了按照總位元組大小限制,還可以按照記錄數進行約束:
// 指定使用堆內快取,並限制最大容量為100個Entity記錄
ResourcePoolsBuilder.newResourcePoolsBuilder().heap(100, EntryUnit.ENTRIES);
- 堆外快取(off-heap)
堆外(off-heap)快取,同樣是儲存在記憶體中。其實就是在記憶體中開闢一塊區域,將其當做磁碟進行使用。由於記憶體的讀寫速度特別快,所以將資料儲存在這個區域,讀寫上可以獲得比本地磁碟讀取更優的表現。這裡的「堆外」,主要是相對與JVM的堆記憶體而言的,因為這個區域不在JVM的堆記憶體中,所以叫堆外快取。這塊的關係如下圖示意:

看到這裡,不知道大家是否有這麼個疑問:既然都是記憶體中儲存,那為何多此一舉非要將其劃分為堆外快取呢?直接將這部分的空間類駕到堆內快取上,不是一樣的效果嗎?
我們知道JVM會基於GC機制自動的對記憶體中不再使用的物件進行垃圾回收,而GC的時候對系統效能的影響是非常大的。堆內快取的資料越多,GC的壓力就會越大,對系統效能的影響也會越明顯。所以為了降低大量快取物件的GC回收動作的影響,便出現了off-heap處理方式。在JVM堆外的記憶體中開闢一塊空間,可以像使用本地磁碟一樣去使用這塊記憶體區域,這樣就既享受了記憶體的高速讀寫能力,又避免頻繁GC帶來的煩惱。
可以在建立快取的時候,通過offheap方法來指定使用堆外快取並設定堆外快取的容量大小,這樣當heap快取容量滿之後,其餘的資料便會儲存到堆外快取中。
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(100, MemoryUnit.KB) // 堆內快取100K
.offheap(10, MemoryUnit.MB); // 堆外快取10M
堆外快取的時候,offheap的大小設定需要注意兩個原則:
- offheap需要大於heap的容量大小(前提是heap大小設定的是位元組數而非Entity數)
- offheap大小必須1M以上。
如果設定的時候不滿足上述條件,會報錯:
Caused by: java.lang.IllegalArgumentException: The value of maxBytesLocalOffHeap is less than the minimum allowed value of 1M. Reconfigure maxBytesLocalOffHeap in ehcache.xml or programmatically.
at org.ehcache.impl.internal.store.offheap.HeuristicConfiguration.<init>(HeuristicConfiguration.java:55)
at org.ehcache.impl.internal.store.offheap.OffHeapStore.createBackingMap(OffHeapStore.java:102)
at org.ehcache.impl.internal.store.offheap.OffHeapStore.access$500(OffHeapStore.java:69)
總結下堆內快取與堆外快取的區別與各自優缺點:
堆內快取是由JVM管理的,在JVM中可以直接去以參照的形式去讀取,所以讀寫的速度會特別高。而且JVM會負責其內容的回收與清理,使用起來比較「省心」。堆外快取是在記憶體中劃定了一塊獨立的儲存區域,然後可以將這部分記憶體當做「磁碟」進行使用。需要使用方自行維護資料的清理,讀寫前需要序列化與反序列化操作,但可以省去GC的影響。
- 磁碟快取(disk)
當我們需要快取的資料量特別大、記憶體容量無法滿足需求的時候,可以使用disk磁碟儲存來作為補充。相比於記憶體,磁碟的讀寫速度顯然要慢一些、但是勝在其價格便宜,容量可以足夠大。
我們可以在快取建立的時候,指定使用磁碟快取,作為堆內快取或者堆外快取的補充。
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, MemoryUnit.MB)
.offheap(1, MemoryUnit.MB)
.disk(10, MemoryUnit.GB); // 指定使用10G磁碟快取空間
需要注意這裡磁碟的容量設定一定要大於前面的heap以及offHeap的大小,否則會報錯:
Exception in thread "main" java.lang.IllegalArgumentException: Tiering Inversion: 'Pool {100 MB offheap}' is not smaller than 'Pool {20 MB disk}'
at org.ehcache.impl.config.ResourcePoolsImpl.validateResourcePools(ResourcePoolsImpl.java:137)
at org.ehcache.config.builders.ResourcePoolsBuilder.<init>(ResourcePoolsBuilder.java:53)
- 叢集快取(Cluster)
作為單機快取,資料都是存在各個程序內的,在分散式組網系統中,如果快取資料發生變更,就會出現各個程序節點中快取資料不一致的問題。為了解決這一問題,Ehcache支援通過叢集的方式,將多個分散式節點組網成一個整體,保證相互節點之間的資料同步。
需要注意的是,除了堆內快取屬於JVM堆內部,可以直接通過參照的方式進行存取,其餘幾種型別都屬於JVM外部的資料互動,所以對這部分資料的讀寫時,需要先進行序列化與反序列化,因此要求快取的資料物件一定要支援序列化與反序列化。
不同的快取型別具有不同的運算處理速度,堆內快取的速度最快,堆外快取次之,叢集快取的速度最慢。為了兼具處理效能與快取容量,可以採用多種快取形式組合使用的方式,構建多級快取來實現。組合上述幾種不同快取型別然後構建多級快取的時候,也需要遵循幾個約束:
- 多級快取中必須有堆內快取,必須按照
堆內快取 < 堆外快取 < 磁碟快取 < 叢集快取的順序進行組合; - 多級快取中的容量設定必須遵循
堆內快取 < 堆外快取 < 磁碟快取 < 叢集快取的原則; - 多級快取中不允許磁碟快取與叢集快取同時出現;

按照上述原則,可以組合出所有合法的多級快取型別:
堆內快取 + 堆外快取
堆內快取 + 堆外快取 + 磁碟快取
堆內快取 + 堆外快取 + 叢集快取
堆內快取 + 磁碟快取
堆內快取 + 叢集快取
支援快取持久化
常規的基於記憶體的快取都有一個通病就是無法持久化,每次重新啟動的時候,快取資料都會丟失,需要重新去構建。而Ehcache則支援使用磁碟來對快取內容進行持久化儲存。
如果需要開啟持久化儲存能力,我們首先需要在建立快取的時候先指定下持久化結果儲存的磁碟根目錄,然後需要指定組合使用磁碟儲存的容量,並選擇開啟持久化資料的能力。
public static void main(String[] args) {
CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.withCache("myCache", CacheConfigurationBuilder.newCacheConfigurationBuilder(Integer.class,
String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(1, MemoryUnit.MB)
.disk(10, MemoryUnit.GB, true)) // 指定需要持久化到磁碟
.build())
.with(CacheManagerBuilder.persistence("d:\\myCache\\")) // 指定持久化磁碟路徑
.build(true);
Cache<Integer, String> myCache = cacheManager.getCache("myCache", Integer.class, String.class);
myCache.put(1, "value1");
myCache.put(2, "value2");
System.out.println(myCache.get(2));
cacheManager.close();
}
執行之後,指定的目錄裡面會留有對應的持久化檔案記錄:
這樣在程序重新啟動的時候,會自動從持久化檔案中讀取內容並載入到快取中,可以直接使用。比如我們將程式碼修改下,快取建立完成後不執行put操作,而是直接去讀取資料。比如還是上面的這段程式碼,將put操作註釋掉,重新啟動執行,依舊可以獲取到快取值。
支援變身分散式快取
在本專欄開立後的第一篇文章《聊一聊作為高並行系統基石之一的快取,會用很簡單,用好才是技術活》中,我們介紹了下在叢集多節點場景下本地快取經常會出現的一個快取漂移問題。比如一個互動論壇系統裡面,其中一個節點處理了修改請求並同步更新了自己的本地快取,但是其餘節點沒有感知到這個變更操作,導致相互之間記憶體資料不一致,這個時候查詢請求就會出現一會正常一會異常的情況。
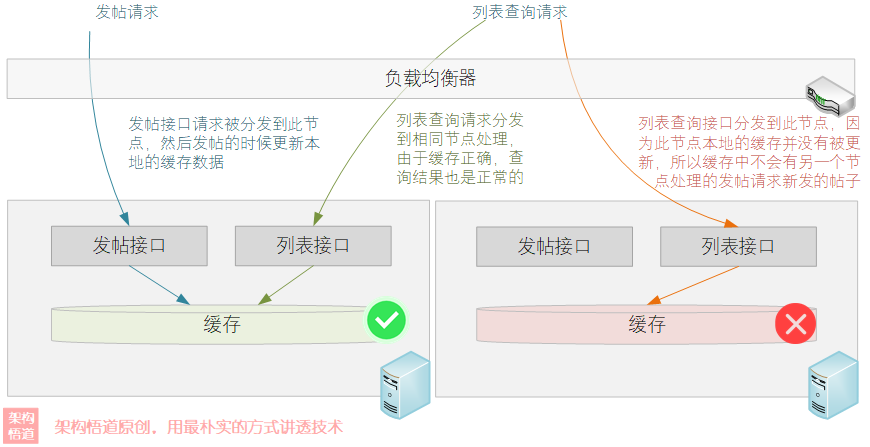
對於分散式系統,或者是叢集場景下,並非是本地快取的主戰場。為了保證叢集內資料的一致性,很多場景往往就直接選擇Redis等集中式快取。但是集中式快取也弊端,比如有些資料並不怎麼更新、但是每個節點對其依賴度卻非常高,如果頻繁地去Redis請求互動,又會導致大量的效能損耗在網路IO互動處理上。
針對這種情況,Ehcache給出了一個相對完美的答案:本地 + 叢集化策略。即在本地快取的基礎上,將叢集內各本地節點組成一個相互連線的網,然後基於某種機制,將一個節點上發生的變更同步給其餘節點進行同步更新自身快取資料,這樣就可以實現各個節點的快取資料一致。
Ehcache提供了多種不同的解決方案,可以將其由本地快取變身為「分散式快取」:
-
RMI組播方式 -
JMS訊息方式 -
Cache Server模式 -
JGroup方式 -
Terracotta方式
在下一篇文章中,將專門針對上面的幾種方式進行展開介紹。
更靈活和細粒度的過期時間設定
前面我們介紹過的本地快取框架Caffeine與Guava Cache,它們支援設定過期時間,但是僅允許為設定快取容器級別統一的過期時間,容器內的所有元素都遵循同一個過期時間。
Ehcache不僅支援快取容器物件級別統一的過期時間設定,還會支援為容器中每一條快取記錄設定獨立過期時間,允許不同記錄有不同的過期時間。這在某些場景下還是非常友好的,可以指定部分熱點資料一個相對較長的過期時間,避免熱點資料因為過期導致的快取擊穿。
同時支援JCache與SpringCache規範
Ehcache作為一個標準化構建的通用快取框架,同時支援了JAVA目前業界最為主流的兩大快取標準,即官方的JSR107標準以及使用非常廣泛的Spring Cache標準,這樣使得業務中可以基於標準化的快取介面去呼叫,避免了Ehcache深度耦合到業務邏輯中去。
作為當前絕對主流的Spring框架,Ehcache可以做到無縫整合,便於專案中使用。在下面的章節中會專門介紹如何與Spring進行整合,此處先不贅述。
Hibernate的預設快取策略
Hibernate是一個著名的開源ORM框架實現,提供了對JDBC的輕量級封裝實現,可以在程式碼中以物件導向的方式去運算元據庫資料,此前著名的SSH框架中的H,指的便是Hibernate框架。Hibernate支援一二級快取,其中一級快取是session級別的快取,預設開啟。而Hibernate的二級快取,預設使用的便是Ehcache來實現的。能夠被大名鼎鼎的Hibernate選中作為預設的快取實現,也可以證明Ehcache不俗的實力。
Ehcache、Caffeine、Redis如何選擇
之前的文章中介紹過Caffeine的相關特性與用法,兩者雖然同屬JVM級別的本地快取框架,但是兩者在目標細分領域,還是各有側重的。而作為具備分散式能力的本地快取,Ehcache與天生的分散式集中式快取之間似乎也存在一些功能上的重合度,那麼Ehcache、Caffeine、Redis三者之間應該如何選擇呢?先看下三者的定位:
- Caffeine
- 更加輕量級,使用更加簡單,可以理解為一個增強版的HashMap;
- 足夠純粹,適用於僅需要本地快取資料的常規場景,可以獲取到絕佳的命中率與並行存取效能。
- Redis
- 純粹的集中快取,為叢集化、分散式多節點場景而生,可以保證快取的一致性;
- 業務需要通過網路進行互動,相比與本地快取而言效能上會有損耗。
- Ehcache
- 支援多級快取擴充套件能力。通過
記憶體+磁碟等多種儲存機制,解決快取容量問題,適合本地快取中對容量有特別要求的場景; - 支援快取資料
持久化操作。允許將記憶體中的快取資料持久化到磁碟上,程序啟動的時候從磁碟載入到記憶體中; - 支援多節點
叢集化組網。可以將分散式場景下的各個節點組成叢集,實現快取資料一致,解決快取漂移問題。
相比而言,Caffeine專注於提供純粹且簡單的本地基礎快取能力、Redis則聚焦統一快取的資料一致性方面,而Ehcache的功能則是更為的中庸,介於兩者之間,既具有本地快取無可比擬的效能優勢,又兼具分散式快取的多節點資料一致性與容量擴充套件能力。專案裡面進行選型的時候,可以結合上面的差異點,評估下自己的實際訴求,決定如何選擇。
簡單來說,把握如下原則即可:
-
如果只是本地簡單、少量快取資料使用的,選擇
Caffeine; -
如果本地快取資料量較大、記憶體不足需要使用磁碟快取的,選擇
EhCache; -
如果是大型分散式多節點系統,業務對快取使用較為重度,且各個節點需要依賴並頻繁操作同一個快取,選擇
Redis。
小結回顧
好啦,關於Ehcache的一些問題關鍵特性,就介紹到這裡了。不知道小夥伴們是否開始對Ehcache更加的感興趣了呢?後面我們將一起來具體看下如何在專案中進行整合與使用Ehcache,充分去發掘與體驗其強大之處。而關於Ehcache你是否有自己的一些想法與見解呢?歡迎評論區一起交流下,期待和各位小夥伴們一起切磋、共同成長。