遷移學習(DANN)《Domain-Adversarial Training of Neural Networks》
論文資訊
論文標題:Domain-Adversarial Training of Neural Networks
論文作者:Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle....
論文來源: JMLR 2016
論文地址:download
論文程式碼:download
參照次數:5292
1 Domain Adaptation
We consider classification tasks where $X$ is the input space and $Y=\{0,1, \ldots, L-1\}$ is the set of $L$ possible labels. Moreover, we have two different distributions over $X \times Y$ , called the source domain $\mathcal{D}_{\mathrm{S}}$ and the target domain $\mathcal{D}_{\mathrm{T}}$ . An unsupervised domain adaptation learning algorithm is then provided with a labeled source sample $S$ drawn i.i.d. from $\mathcal{D}_{\mathrm{S}}$ , and an unlabeled target sample $T$ drawn i.i.d. from $\mathcal{D}_{\mathrm{T}}^{X}$ , where $\mathcal{D}_{\mathrm{T}}^{X}$ is the marginal distribution of $\mathcal{D}_{\mathrm{T}}$ over $X$ .
$S=\left\{\left(\mathbf{x}_{i}, y_{i}\right)\right\}_{i=1}^{n} \sim\left(\mathcal{D}_{\mathrm{S}}\right)^{n}$
$T=\left\{\mathbf{x}_{i}\right\}_{i=n+1}^{N} \sim\left(\mathcal{D}_{\mathrm{T}}^{X}\right)^{n^{\prime}}$
with $N=n+n^{\prime}$ being the total number of samples. The goal of the learning algorithm is to build a classifier $\eta: X \rightarrow Y$ with a low target risk
$R_{\mathcal{D}_{\mathrm{T}}}(\eta)=\operatorname{Pr}_{(\mathbf{x}, y) \sim \mathcal{D}_{\mathrm{T}}}(\eta(\mathbf{x}) \neq y),$
while having no information about the labels of $\mathcal{D}_{\mathrm{T}}$ .
2 Domain Divergence
$d_{\mathcal{H}}\left(\mathcal{D}_{\mathrm{S}}^{X}, \mathcal{D}_{\mathrm{T}}^{X}\right)= 2 \text{sup}_{\eta \in \mathcal{H}}\left|\operatorname{Pr}_{\mathbf{x} \sim \mathcal{D}_{\mathrm{S}}^{X}}\; \;\; [\eta(\mathbf{x})=1]-\operatorname{Pr}_{\mathbf{x} \sim \mathcal{D}_{\mathrm{T}}^{X}} \; [\eta(\mathbf{x})=1]\right|$
該散度的意思是,在一個假設空間 $\mathcal{H}$ 中,找到一個函數 $\mathrm{h}$,使得 $\operatorname{Pr}_{x \sim \mathcal{D}}[h(x)=1]$ 的概率儘可能大,而 $\operatorname{Pr}_{x \sim \mathcal{D}^{\prime}}[h(x)=1]$ 的概率儘可能小。【如果資料來自源域,域標籤為 $1$,如果資料來自目標域,域標籤為 $0$】也就是說,用最大距離來衡量 $\mathcal{D}, \mathcal{D}^{\prime}$ 之間的距離。同時這個 $h$ 也可以理解為是用來儘可能區分 $\mathcal{D}$,$\mathcal{D}^{\prime}$ 這兩個分佈的函數。
可以通過計算來計算兩個樣本 $S \sim\left(\mathcal{D}_{\mathrm{S}}^{X}\right)^{n}$ 和 $T \sim\left(\mathcal{D}_{\mathrm{T}}^{X}\right)^{n^{\prime}}$ 之間的經驗 $\text { H-divergence }$:
$\hat{d}_{\mathcal{H}}(S, T)=2\left(1- \underset{\eta \in \mathcal{H}}{\text{min}} \left[\frac{1}{n} \sum\limits_{i=1}^{n} I\left[\eta\left(\mathbf{x}_{i}\right)=0\right]+\frac{1}{n^{\prime}} \sum\limits _{i=n+1}^{N} I\left[\eta\left(\mathbf{x}_{i}\right)=1\right]\right]\right) \quad\quad(1)$
其中,$I[a]$ 是指示函數,當 $a$ 為真時,$I[a] = 1$,否則 $I[a] = 0$。
3 Proxy Distance
由於經驗 $\mathcal{H}$-divergence 難以精確計算,可以使用判別源樣本與目標樣本的學習演演算法完成近似。
構造新的資料集 $U$ :
$U=\left\{\left(\mathbf{x}_{i}, 0\right)\right\}_{i=1}^{n} \cup\left\{\left(\mathbf{x}_{i}, 1\right)\right\}_{i=n+1}^{N}\quad\quad(2)$
使用 $\mathcal{H}$-divergence 的近似表示 Proxy A-distance(PAD),其中 $\epsilon$ 為 源域和目標域樣本的分類泛化誤差:
$\hat{d}_{\mathcal{A}}=2(1-2 \epsilon)\quad\quad(3)$
4 Method
為學習一個可以很好地從一個域推廣到另一個域的模型,本文確保神經網路的內部表示不包含關於輸入源(源或目標域)來源的區別資訊,同時在源(標記)樣本上保持低風險。
首先考慮一個標準的神經網路(NN)結構與一個單一的隱藏層。為簡單起見,假設輸入空間由 $m$ 維向量 $X=\mathbb{R}^{m}$ 構成。隱層 $G_{f}$ 學習一個函數 $G_{f}: X \rightarrow \mathbb{R}^{D}$ ,該函數將一個範例對映為一個 $\mathrm{d}$ 維表示,並由矩陣-向量對 $ (\mathbf{W}, \mathbf{b}) \in \mathbb{R}^{D \times m} \times \mathbb{R}^{D} $ 引數化:
$\begin{array}{l}G_{f}(\mathbf{x} ; \mathbf{W}, \mathbf{b})=\operatorname{sigm}(\mathbf{W} \mathbf{x}+\mathbf{b}) \\\text { with } \operatorname{sigm}(\mathbf{a})=\left[\frac{1}{1+\exp \left(-a_{i}\right)}\right]_{i=1}^{|\mathbf{a}|}\end{array}$
類似地,預測層 $G_{y}$ 學習一個函數 $G_{y}: \mathbb{R}^{D} \rightarrow[0,1]^{L}$,該函數由一對 $(\mathbf{V}, \mathbf{c}) \in \mathbb{R}^{L \times D} \times \mathbb{R}^{L}$:
$\begin{array}{l}G_{y}\left(G_{f}(\mathbf{x}) ; \mathbf{V}, \mathbf{c}\right)=\operatorname{softmax}\left(\mathbf{V} G_{f}(\mathbf{x})+\mathbf{c}\right)\\\text { with }\quad \operatorname{softmax}(\mathbf{a})=\left[\frac{\exp \left(a_{i}\right)}{\sum_{j=1}^{|a|} \exp \left(a_{j}\right)}\right]_{i=1}^{|\mathbf{a}|}\end{array}$
其中 $L=|Y|$。通過使用 softmax 函數,向量 $G_{y}\left(G_{f}(\mathbf{x})\right)$ 的每個分量表示神經網路將 $\mathbf{x}$ 分配給該分量在 $Y$ 中表示的類的條件概率。給定一個源樣本 $\left(\mathbf{x}_{i}, y_{i}\right)$,使用正確標籤的負對數概率:
$\mathcal{L}_{y}\left(G_{y}\left(G_{f}\left(\mathbf{x}_{i}\right)\right), y_{i}\right)=\log \frac{1}{G_{y}\left(G_{f}(\mathbf{x})\right)_{y_{i}}}$
對神經網路的訓練會導致源域上的以下優化問題:
$\underset{\mathbf{W}, \mathbf{b}, \mathbf{V}, \mathbf{c}}{\text{min}} \left[\frac{1}{n} \sum_{i=1}^{n} \mathcal{L}_{y}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{V}, \mathbf{c})+\lambda \cdot R(\mathbf{W}, \mathbf{b})\right]$
其中,$\mathcal{L}_{y}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{V}, \mathbf{c})=\mathcal{L}_{y}\left(G_{y}\left(G_{f}\left(\mathbf{x}_{i} ; \mathbf{W}, \mathbf{b}\right) ; \mathbf{V}, \mathbf{c}\right), y_{i}\right)$,$R(\mathbf{W}, \mathbf{b})$ 是一個正則化項。
我們的方法的核心是設計一個直接從 Definition 1 的 $\mathcal{H}$-divergence 推匯出的域正則化器。為此,我們將隱層 $G_{f}(\cdot)$($\text{Eq.4}$)的輸出視為神經網路的內部表示。因此,我們將源樣本表示法表示為
$S\left(G_{f}\right)=\left\{G_{f}(\mathbf{x}) \mid \mathbf{x} \in S\right\}$
類似地,給定一個來自目標域的未標記樣本,我們表示相應的表示形式
$T\left(G_{f}\right)=\left\{G_{f}(\mathbf{x}) \mid \mathbf{x} \in T\right\}$
在 $\text{Eq.1}$ 的基礎上,給出了樣本 $S\left(G_{f}\right)$ 和 $T\left(G_{f}\right)$ 之間的經驗 $\mathcal{H}\text{-divergence}$:
$\hat{d}_{\mathcal{H}}\left(S\left(G_{f}\right), T\left(G_{f}\right)\right)=2\left(1-\min _{\eta \in \mathcal{H}}\left[\frac{1}{n} \sum\limits_{i=1}^{n} I\left[\eta\left(G_{f}\left(\mathbf{x}_{i}\right)\right)=0\right]+\frac{1}{n^{\prime}} \sum\limits_{i=n+1}^{N} I\left[\eta\left(G_{f}\left(\mathbf{x}_{i}\right)\right)=1\right]\right]\right) \quad\quad(6)$
域分類層 $G_{d}$ 學習了一個邏輯迴歸變數 $G_{d}: \mathbb{R}^{D} \rightarrow[0,1]$ ,其引數為 向量-常數對 $(\mathbf{u}, z) \in \mathbb{R}^{D} \times \mathbb{R}$,它模擬了給定輸入來自源域 $\mathcal{D}_{\mathrm{S}}^{X}$ 或目標域 $\mathcal{D}_{\mathrm{T}}^{X}$ 的概率:
$G_{d}\left(G_{f}(\mathbf{x}) ; \mathbf{u}, z\right)=\operatorname{sigm}\left(\mathbf{u}^{\top} G_{f}(\mathbf{x})+z\right)\quad\quad(7)$
因此,函數 $G_{d}(\cdot)$ 是一個域迴歸器。我們定義它的損失是:
$\mathcal{L}_{d}\left(G_{d}\left(G_{f}\left(\mathbf{x}_{i}\right)\right), d_{i}\right)=d_{i} \log \frac{1}{G_{d}\left(G_{f}\left(\mathbf{x}_{i}\right)\right)}+\left(1-d_{i}\right) \log \frac{1}{1-G_{d}\left(G_{f}\left(\mathbf{x}_{i}\right)\right)}$
其中,$d_{i}$ 表示第 $i$ 個樣本的二進位制域標籤,如果 $d_{i}=0$ 表示樣本 $\mathbf{x}_{i}$ 是來自源分佈 $\mathbf{x}_{i} \sim \mathcal{D}_{\mathrm{S}}^{X}$),如果 $d_{i}=1$ 表示樣本來自目標分佈 $\mathbf{x}_{i} \sim \mathcal{D}_{\mathrm{T}}^{X} $。
回想一下,對於來自源分佈($d_{i}=0$)的例子,相應的標籤 $y_{i} \in Y$ 在訓練時是已知的。對於來自目標域的例子,我們不知道在訓練時的標籤,而我們想在測試時預測這些標籤。這使得我們能夠在 $\text{Eq.5}$ 的目標中新增一個域自適應項,並給出以下正則化器:
$R(\mathbf{W}, \mathbf{b})=\underset{\mathbf{u}, z}{\text{max}} {}\left[-\frac{1}{n} \sum\limits _{i=1}^{n} \mathcal{L}_{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)-\frac{1}{n^{\prime}} \sum\limits_{i=n+1}^{N} \mathcal{L}_{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)\right]\quad\quad(8)$
其中,$\mathcal{L}_{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)=\mathcal{L}_{d}\left(G_{d}\left(G_{f}\left(\mathbf{x}_{i} ; \mathbf{W}, \mathbf{b}\right) ; \mathbf{u}, z\right), d_{i}\right)$ 。這個正則化器試圖近似 $\text{Eq.6}$ 的 $\mathcal{H}\text{-divergence}$,因為 $2(1-R(\mathbf{W}, \mathbf{b}))$ 是 $\hat{d}_{\mathcal{H}}\left(S\left(G_{f}\right), T\left(G_{f}\right)\right)$ 的一個替代品。
為了學習,可以將 $\text{Eq.5}$ 的完整優化目標重寫如下:
$\begin{array}{l}E(\mathbf{W}, \mathbf{V}, \mathbf{b}, \mathbf{c}, \mathbf{u}, z) \\\quad=\frac{1}{n} \sum\limits _{i=1}^{n} \mathcal{L}_{y}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{V}, \mathbf{c})-\lambda\left(\frac{1}{n} \sum\limits_{i=1}^{n} \mathcal{L}_{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)+\frac{1}{n^{\prime}} \sum_{i=n+1}^{N} \mathcal{L}_{d}^{i}(\mathbf{W}, \mathbf{b}, \mathbf{u}, z)\right)\end{array}\quad\quad(9)$
對應的引數優化 $\hat{\mathbf{W}}$, $\hat{\mathbf{V}}$, $\hat{\mathbf{b}}$, $\hat{\mathbf{c}}$, $\hat{\mathbf{u}}$, $\hat{z}$:
$\begin{array}{l}(\hat{\mathbf{W}}, \hat{\mathbf{V}}, \hat{\mathbf{b}}, \hat{\mathbf{c}}) & =& \underset{\mathbf{W}, \mathbf{V}, \mathbf{b}, \mathbf{c}}{\operatorname{arg min}} E(\mathbf{W}, \mathbf{V}, \mathbf{b}, \mathbf{c}, \hat{\mathbf{u}}, \hat{z}) \\(\hat{\mathbf{u}}, \hat{z}) & =&\underset{\mathbf{u}, z}{\operatorname{arg max}} E(\hat{\mathbf{W}}, \hat{\mathbf{V}}, \hat{\mathbf{b}}, \hat{\mathbf{c}}, \mathbf{u}, z)\end{array}$
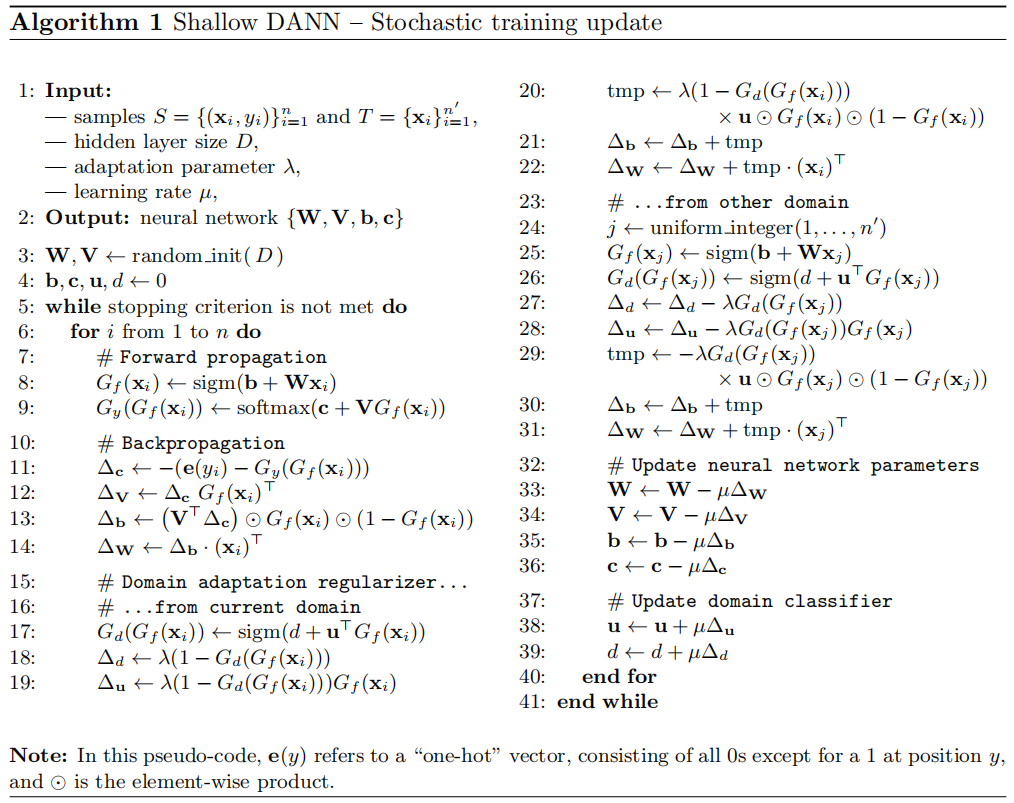
Generalization to Arbitrary Architectures
分類損失和域分類損失:
$\begin{aligned}\mathcal{L}_{y}^{i}\left(\theta_{f}, \theta_{y}\right) & =\mathcal{L}_{y}\left(G_{y}\left(G_{f}\left(\mathbf{x}_{i} ; \theta_{f}\right) ; \theta_{y}\right), y_{i}\right) \\\mathcal{L}_{d}^{i}\left(\theta_{f}, \theta_{d}\right) & =\mathcal{L}_{d}\left(G_{d}\left(G_{f}\left(\mathbf{x}_{i} ; \theta_{f}\right) ; \theta_{d}\right), d_{i}\right)\end{aligned}$
優化目標:
$E\left(\theta_{f}, \theta_{y}, \theta_{d}\right)=\frac{1}{n} \sum\limits_{i=1}^{n} \mathcal{L}_{y}^{i}\left(\theta_{f}, \theta_{y}\right)-\lambda\left(\frac{1}{n} \sum\limits_{i=1}^{n} \mathcal{L}_{d}^{i}\left(\theta_{f}, \theta_{d}\right)+\frac{1}{n^{\prime}} \sum\limits_{i=n+1}^{N} \mathcal{L}_{d}^{i}\left(\theta_{f}, \theta_{d}\right)\right) \quad\quad(10)$
對應的引數優化 $\hat{\theta}_{f}$, $\hat{\theta}_{y}$, $\hat{\theta}_{d}$:
$\begin{array}{l}\left(\hat{\theta}_{f}, \hat{\theta}_{y}\right) & =&\underset{\theta_{f}, \theta_{y}}{\operatorname{argmin}} E\left(\theta_{f}, \theta_{y}, \hat{\theta}_{d}\right) \quad\quad(11) \\\hat{\theta}_{d} & =&\underset{\theta_{d}}{\operatorname{argmax}} E\left(\hat{\theta}_{f}, \hat{\theta}_{y}, \theta_{d}\right)\quad\quad(12)\end{array}$
如前所述,由 $\text{Eq.11-Eq.12}$ 定義的鞍點可以作為以下梯度更新的平穩點找到:
$\begin{array}{l}\theta_{f} \longleftarrow \theta_{f}-\mu\left(\frac{\partial \mathcal{L}_{y}^{i}}{\partial \theta_{f}}-\lambda \frac{\partial \mathcal{L}_{d}^{i}}{\partial \theta_{f}}\right)\quad\quad(13) \\\theta_{y} \longleftarrow \quad \theta_{y}-\mu \frac{\partial \mathcal{L}_{y}^{i}}{\partial \theta_{y}}\quad\quad\quad\quad \quad\quad(14) \\\theta_{d} \quad \longleftarrow \quad \theta_{d}-\mu \lambda \frac{\partial \mathcal{L}_{d}^{i}}{\partial \theta_{d}}\quad\quad\quad\quad(15) \\\end{array}$
整體框架:

元件:
-
- 特徵提取器(feature extractor)$G_{f}\left(\cdot ; \theta_{f}\right)$ :將源域樣本和目標域樣本進行對映和混合,使域判別器無法區分資料來自哪個域;提取後續網路完成任務所需要的特徵,使標籤預測器能夠分辨出來自源域資料的類別;
- 標籤預測器(label predictor)$G_{y}\left(\cdot ; \theta_{y}\right)$:對 Source Domain 進行訓練,實現資料的分類任務,本文就是讓 Source Domain 的圖片分類越正確越好;
- 域分類器(domain classifier)$G_{d}\left(\cdot ; \theta_{d}\right)$:二分類器,要讓 Domain 的分類越正確越好,分類出是 Source 還是 Target ;
為什麼要加梯度反轉層:GRL?
域分類器和特徵提取器中間有一個梯度反轉層(Gradient reversal layer)。梯度反轉層顧名思義將梯度乘一個負數,然後進行反向傳播。加入GRL的目的是為了讓域判別器和特徵提取器之間形成一種對抗。
最大化 loss $L_{d}$ ,這樣就可以儘可能的讓兩個 domain 分不開, feature 自己就漸漸趨於域自適應了。這是使用 GRL 來實現的,loss $L_{d}$ 在 domain classifier 中是很小的,但通過 GRL 後,就實現在 feature extractor 中不能正確的判斷出資訊來自哪一個域。
因上求緣,果上努力~~~~ 作者:加微信X466550探討,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/17020391.html