Google分散式檔案系統GFS論文學習
GFS作為最著名的分散式檔案系統,首先具備了大規模、可延伸、適配大檔案、自動運維等高階特性。雖然是比較早期的分散式檔案系統,但是它裡面的設計思想還是值得現代分散式系統設計參考的,並且還有很多後期著名的分散式檔案系統就是根據 GFS 來的。
一、設計預期
在論文前面,列舉了設計預期,也就是 GFS 是一個怎麼樣的分散式檔案檔案系統:
- 失效是一種常態,因為叢集系統由許多廉價的普通元件組成,元件失效是一種常態。系統必須持續監控自身的狀態,它必須將組 件失效作為一種常態,能夠迅速地偵測、冗餘並恢復失效的元件。
- 系統儲存的是大檔案,而不是小檔案物件儲存,這個非常重要。系統儲存一定數量的大檔案。我們預期會有幾百萬檔案,檔案的大小通常在100MB或者以上。數個 GB大小的檔案也是普遍存在,並且要能夠被有效的管理。系統也必須支援小檔案,但是不需要針對 小檔案做專門的優化。
- 系統支援兩種主要的讀取方式:大規模的流式讀取和小規模的隨機讀取。大規模的流式讀取 通常一次讀取數百KB的資料,更常見的是一次讀取1MB甚至更多的資料。來自同一個客戶機的連續 操作通常是讀取同一個檔案中連續的一個區域。小規模的隨機讀取通常是在檔案某個隨機的位置讀取 幾個KB資料。
- 系統支援高效能的寫功能:追加寫(append)和覆蓋改寫(oever-write)。
- 系統必須高效的、行為定義明確的(alex注:well-defined)實現多使用者端並行追加資料到同一個檔案裡的語意,意思是讀取的資料必須符合一致性原則。
- 高效能的穩定網路頻寬遠比低延遲重要。
GFS中提供檔案系統的介面有如下:
- 建立(Create)
- 刪除(Delete)
- 開啟(Open)
- 關閉(Close)
- 讀取(Read)
- 寫入(Write)
- 生成快照(Snapshot)
- 修改(Update)
- 追加(Append)
二、整體架構
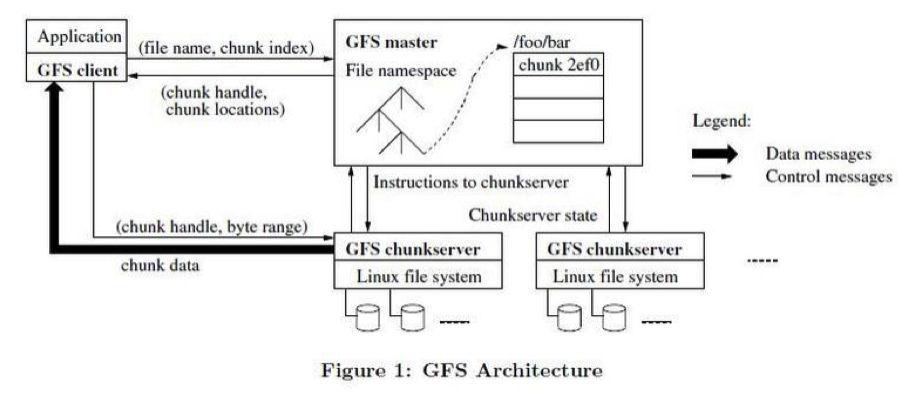
GFS中有三種節點:GFS client,GFS master,GFS chunkserver
- GFS client:維持專用介面,與應用互動。
GFS使用者端程式碼以庫的形式被連結到客戶程式裡。使用者端程式碼實現了GFS檔案系統的API介面函數、應用程 序與Master節點和Chunk伺服器通訊、以及對資料進行讀寫操作。使用者端和Master節點的通訊只獲取後設資料,所有的資料操作都是由使用者端直接和Chunk伺服器進行互動的。
- GFS master:維持後設資料,統一管理 chunk 位置和租約。
Master節點管理所有的檔案系統後設資料(後設資料包括檔名,檔案對映對應的chunk,chunkid對應的chunkserver)。這些後設資料包括名稱空間、存取控制資訊、檔案和Chunk的對映 資訊、以及當前Chunk的位置資訊。Master節點還管理著系統範圍內的活動,比如,Chunk租用管理、孤兒Chunk(alex注:orphaned chunks)的回 收、以及Chunk在Chunk伺服器之間的遷移。Master節點使用心跳資訊週期地和每個Chunk伺服器通 訊,傳送指令到各個Chunk伺服器並接收Chunk伺服器的狀態資訊。
- GFS chunkserver:儲存資料。
在Chunk建立的時候,Master伺服器會給每個Chunk分 配一個不變的、全球唯一的64位元的Chunk標識。Chunk伺服器把Chunk以linux檔案的形式儲存在本地硬碟上,並且根據指定的Chunk標識和位元組範圍來讀寫塊資料。出於可靠性的考慮,每個塊都會複製到多個 塊伺服器上。預設情況下,我們使用3個儲存複製節點,不過使用者可以為不同的檔案名稱空間設定不同的複製級別。
三、儲存設計
因為GFS設計預期是儲存大檔案,有可能是幾PB的巨大檔案,並且大小不均。所以GFS沒有選擇直接以檔案為單位進行儲存,而是吧檔案分為一個個chunk來儲存。GFS 把每個 chunk 設定為64MB。
選擇較大的chunksize的原因在論文中也做了詳細的說明:
- 首先,它減少了使用者端和Master節點通訊的需求,因為只需要 一次和Mater節點的通訊就可以獲取Chunk的位置資訊,之後就可以對同一個Chunk進行多次的讀寫操作。這種方式對降低 GFS 的工作負載來說效果顯著,因為應用程式通常是連續讀寫大檔案。即使是小規模的隨機讀取,採用較大的Chunk尺寸也帶來明顯的好處,使用者端可以輕鬆的快取一個數TB的工作資料集所有的Chunk位置資訊。
- 其次,採用較大的Chunk尺寸,使用者端能夠對一個塊進行多次操作,這樣就 可以通過與Chunk伺服器保持較長時間的TCP連線來減少網路負載。
- 第三,選用較大的Chunk尺寸減少了 Master節點需要儲存的後設資料的數量。這就允許 client 把後設資料全部放在記憶體中。比如64mb的chunk後設資料只需要小於64byte的大小即可儲存,幾G的記憶體就可以快取幾個PB的資料後設資料。
當然更大的chunk意味著多個執行緒同時操作一個chunk的可能性增加,容易產生熱點問題,對於這個問題 GFS 在一致性設計上做出了對效能的妥協。
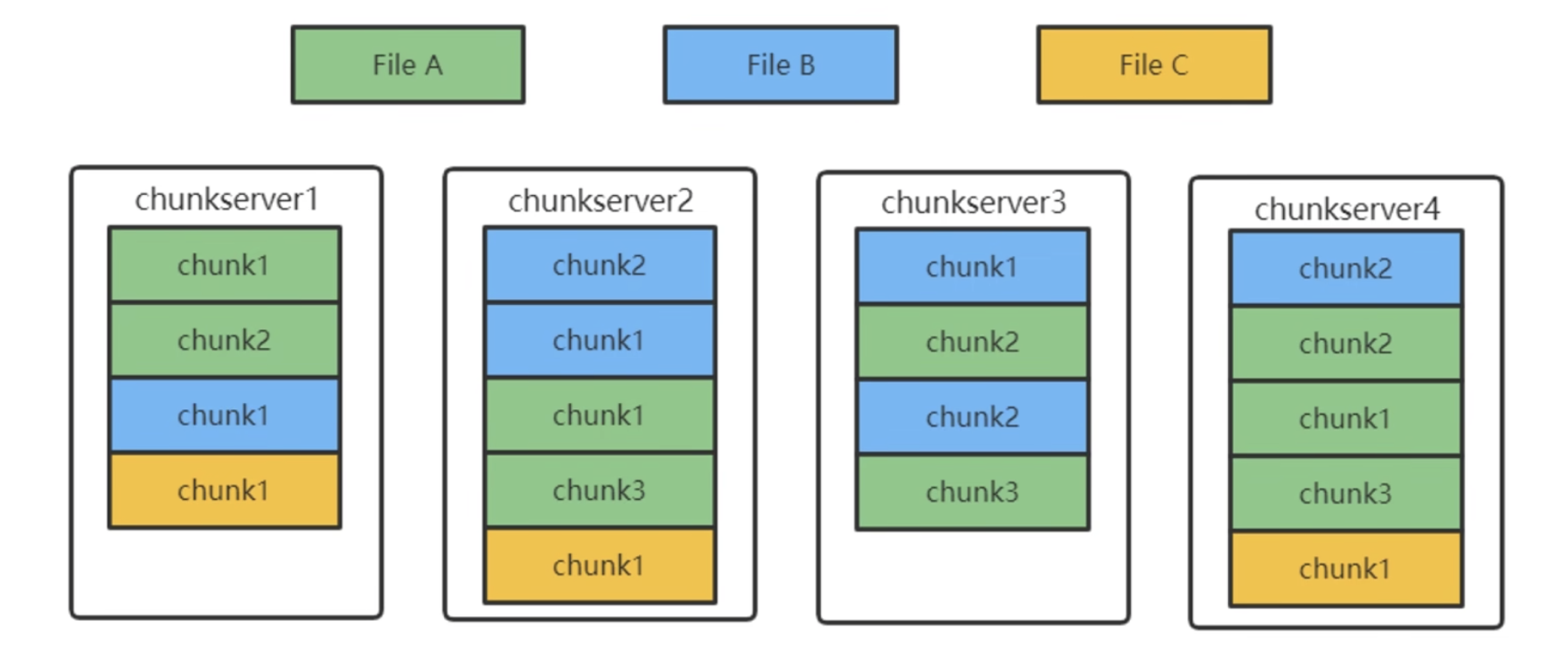
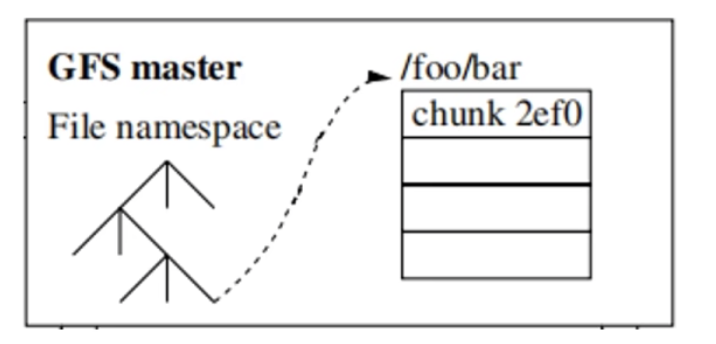
比如檔案 FileA 中一共有三個 chunk,master節點只記錄儲存了檔案名稱空間對應的chunk對映關係,然後在 chunk 具體需要怎麼儲存完全是依靠chunkserver原生的物理儲存的。比如其中 chunk1 是儲存在 chunkserver1,2,4 中,其中兩個是副本。
三、master節點設計
master節點並沒有使用非中心共識演演算法來保證資料的可靠性,相反使用了單中心節點的設計,並且論文裡對比了這兩者優劣:
GFS設計了單個 master 節點,用來儲存整個檔案系統的三類後設資料:
- 所有檔案和chunk的名稱空間namespace(持久化)
- 檔案到chunk的對映(持久化)
- 每個chunk的位置(非持久化)通過master和chunkserver互動,由chunkserver告知master
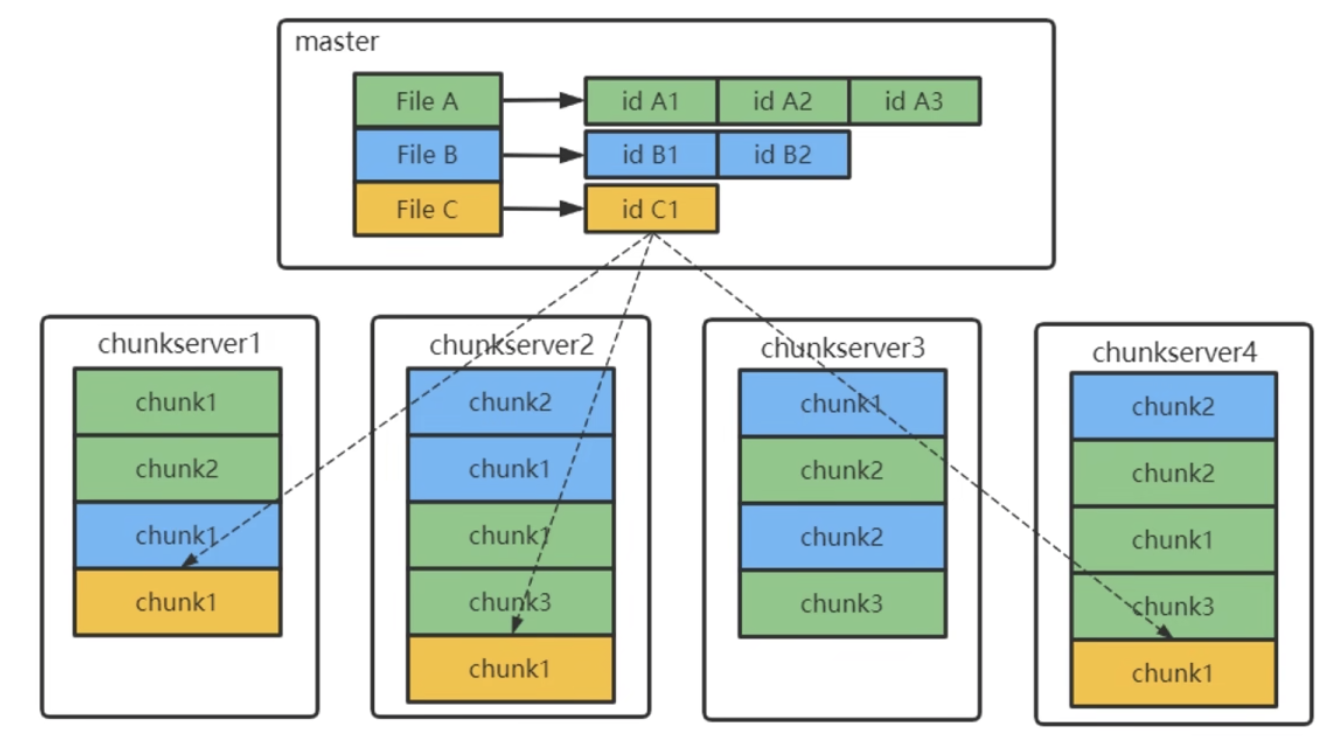
不進行chunk位置的持久化資料的原因是,每個chunkserver才是真正儲存chunk的地方,就算 master 進行資料持久化,最後還是需要去詢問每個 chunkserver ,此chunk是否存在,所以與其做無用功,乾脆就不持久化儲存了。
在 master 中讀取一個檔案的過程是:
檔名 -> 獲取檔名對應的所有chunk名 -> 獲取所有chunk的位置 -> 依次到對應的chunkserver中讀取chunk
所以 master 只需要保證後設資料高可用性,就不必擔心整個分散式檔案系統的讀寫會收到影響。而後設資料在 master 中其實也不是單份儲存的,利用 checkpoint 和操作紀錄檔的方式,可以隨時在備份節點上恢復後設資料,拉起備份節點。有點類似 mysql 資料庫的 redolog 和 binlog 的作用,checkpoint 是對定時進行資料的快照備份,操作紀錄檔來補全剩餘的操作動作。
三、高可用設計
GFS誕生的時候共識演演算法並不像現在這成熟,所以GFS借鑑了主備的思想,為系統的後設資料和檔案資料都單獨設計了高可用方案。因為 google 的檔案量很大,所以 chunkserver 可能會非常非常多,所以發生宕機的機率可能會非常大,頻繁宕機節點的問題GFS可以自動解決,即自動切換主備。而關於高可用的設計,主要是GFS的後設資料和檔案資料的高可用。
1. master的高可用設計:
- master的三類後設資料中,namespace和檔案與chunk的對應關係,因為只有在 master 中存在,所以必須要持久化,也自然是要保證其高可用的
- GFS除了正在使用的 master 節點(primary master)外,還維持了 shadow master 作為備份
- master 在正常執行時,對後設資料做的所有修改操作,都要先記錄紀錄檔 write ahead log(WAL),再真正去修改記憶體中的資料
- primary master會實時向 shadow master 同步 WAL。只有 shadow master 同步紀錄檔完成,後設資料修改操作才算完完成
如果 master 宕機,GFS會使用 Chubby(本質上是共識演演算法)來識別並切換到 shadow master,這個切換是秒級的。master 的高可用機制就和 mysql 的主備機制非常相像。
2. chunk的高可用設計
- 檔案是被拆為一個個chunk來進行儲存,每個chunk都有三個副本。所以檔案資料的高可用是以chunk為維度來保持的。
- 注意,chunk並不是依賴傳統的主備關係,利用主chunk來進行資料的備份,GFS利用 master 來維持 chunk 的副本資訊,也就是 master 來控制哪個 chunk 是主,並且在寫過程中控制備份資料的落盤,具體可以看後面的讀寫過程在實現中,GFS對於一個 chunk 的寫入,必須確保在三個副本中的寫入都完成,才視為寫入完成。並且一個 chunk 的所有副本都會有完整的資料,如果一個chunkserver宕機了,它上面的所有chunk都有另外兩個副本依舊可以儲存這個chunk資料。如果在這個宕機的副本在一段時間之後都沒有回覆,那麼master就可以在另外一個chunkserver上重建一個副本,從而始終把chunk的副本數目維持在3個
- 每個 chunk 都會維持一個校驗和,獨缺的時候通過校驗和檢驗,如果不匹配,chunksever會反饋給master,master會選擇其他副本進行讀取,並重建此 chunk 副本
- 為了減少對於master的壓力,GFS採用一種租約的機制(Lease),把檔案的讀寫許可權下放給某個chunk副本,這樣就不用頻繁互動向 master 獲取 chunkserver 中的 primary chunk
- 租約的主備只決定控制流走向,不影響資料流
chunk的副本放置也需要考慮,GFS 找那個有三種情況需要 master 發起建立 chunk 副本,分別是:建立新chunk、chunk副本複製、負載均衡
負載均衡是指因為某些chunkserver負載過高,比如chunk資料過於熱點,那麼就會觸發把 chunk 副本搬到另外的 chunkserver 上,當然這裡的搬遷操作,就是新建 chunk 和刪除原來 chunk。
副本複製則是因為一個副本所在的 chunkserver 宕機,導致 chunk 副本數小於預期值,然後新增一個 chunk 副本。
在副本位置選擇策略中,master節點遵循以下幾點:
- 新副本所在的 chunkserver 負載資源利用率較低
- 新副本的 chunkserver 最近新建的 chunk 副本不多。這裡是為了防止某個 chunkserver 新增大量的副本,成為熱點
- chunk 的其他副本不能再同一個機架上,這個是為了保證機架或者機房級別的高可用
四、GFS 的讀寫流程
寫操作
GFS 的寫入需要三個副本都完成寫入後才會返回寫入結果。我覺得寫入的流程至少現在看來,依然很驚豔。
- 流水線技術
- 資料流和控制流分離技術
在看論文的時候總是有這樣的疑問,為什麼 client 會先把相關變更的資料先傳送到離當前最近的 chunkserver 備份資料上,然後再由 primary chunk 來控制寫入的資料。
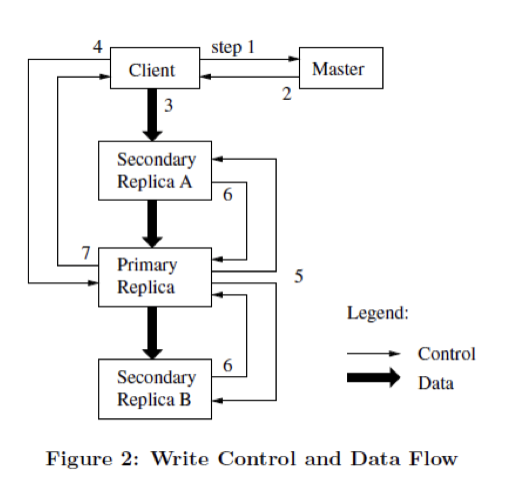
寫入流程
- 第1和2步驟,client 向 master 詢問要寫入的 chunk 租約在哪個 chunkserver 上(primary replica),以及所有的副本(secondary replica)的位置,如果 client 上有快取的話則直接快取獲取
- 第3步驟,client把資料都推播到離此最近的副本上,這一步會用到流水線技術,也就是寫入過程中唯一的資料流操作,最近的副本會把資料擴散到其他的 replica,利用全雙工網路傳輸,可以一邊接收資料,一邊傳送給其他副本,最大化利用網路資源
- 第4步驟中。確認所有的副本上收到資料後,client 會傳送正式寫入的請求到 primary replica。primary replica 接收到這個請求後,會對這個chunk上所有的操作進行排序,然後按照順序執行寫入,這裡比較關鍵的是,primary 唯一確定寫入順序,保證副本的一致性
- primary replica 把 chunk 的寫入順序同步給所有的 second replica
如果一部分的備份寫入失敗,那麼就將從第三步重新寫入。並且如果一個寫入操作設計到多個chunk,client會把他們分成多個寫入來執行。
以一個例子來說明,s1、s2、s3三個 chunkserver,client 在北京,s1 是主,在上海。s2、s3是備,在北京。
流水線同步寫入的順序是:Client -> s2/s3 -> s1,只有一次跨地域傳輸。如果是常規的主備的話,一定會先落入s1主,然後再同步到備用,那麼在這個例子就會出現兩次跨地域傳輸。
注意這裡的第4步驟,和第3步驟的區別:
- 第3步驟:客戶機把資料推播到所有的副本上。注意是變更的資料儲存在這裡,比如資料的變更:set v1 1、set v1 2、set v1 3,這三個操作如果不同的順序執行會產生不同的結果,順序只有 primary chunk 來決定的
- 第4步驟:確定控制流,也就是順序執行的資料。當所有的副本都確認接收到了資料,客戶機傳送寫請求到主Chunk伺服器。這個請求標識了早前推 送到所有副本的資料。主Chunk為接收到的所有操作分配連續的序列號,這些操作可能來自不同的 客戶機,序列號保證了操作順序執行。它以序列號的順序把操作應用到它自己的本地狀態中。
這就是所謂的資料流和控制流的分離,保證GFS對一致性的保證可以不受資料同步的干擾。
寫操作包括追加和改寫,GFS 一般建議的是 append 追加的寫入操作,因為如果改寫的話,可能會涉及多個 chunk,而如果部分 chunk 成功,部分 chunk 失敗,我們讀到的檔案就是不正確的。所以改寫如果想要保持一致性,必須使用一個分散式鎖的操作,這樣會增加效能的開銷,所以 GFS 建議追加的寫入模式。
讀取流程

- client 收到讀取一個檔案的請求後,首先會檢視自身的快取中有沒有此檔案的後設資料資訊,如果沒有則請求 master 節點獲取後設資料並快取
- client計算檔案偏移量對應的 chunk
- 然後 client 向離自己最近的 chunkserver 傳送讀請求,如果讀取失敗則再向請求master後設資料
- 讀取會進行 chunk 校驗和的確認,如果不通過,則讀取其他的副本
五、GFS 的一致性模型
在使用中,因為有多個 client ,那麼寫入往往是並行的,所以會導致副本不一致的風險
並行改寫:對於單個改寫操作而言,成功就意味著副本間是一致的,但是並行操作可能會設計多個 chunk,不同 chunk 對改寫的執行順序不一定相同,而這有可能造成應用讀取不到預期的結果。如下
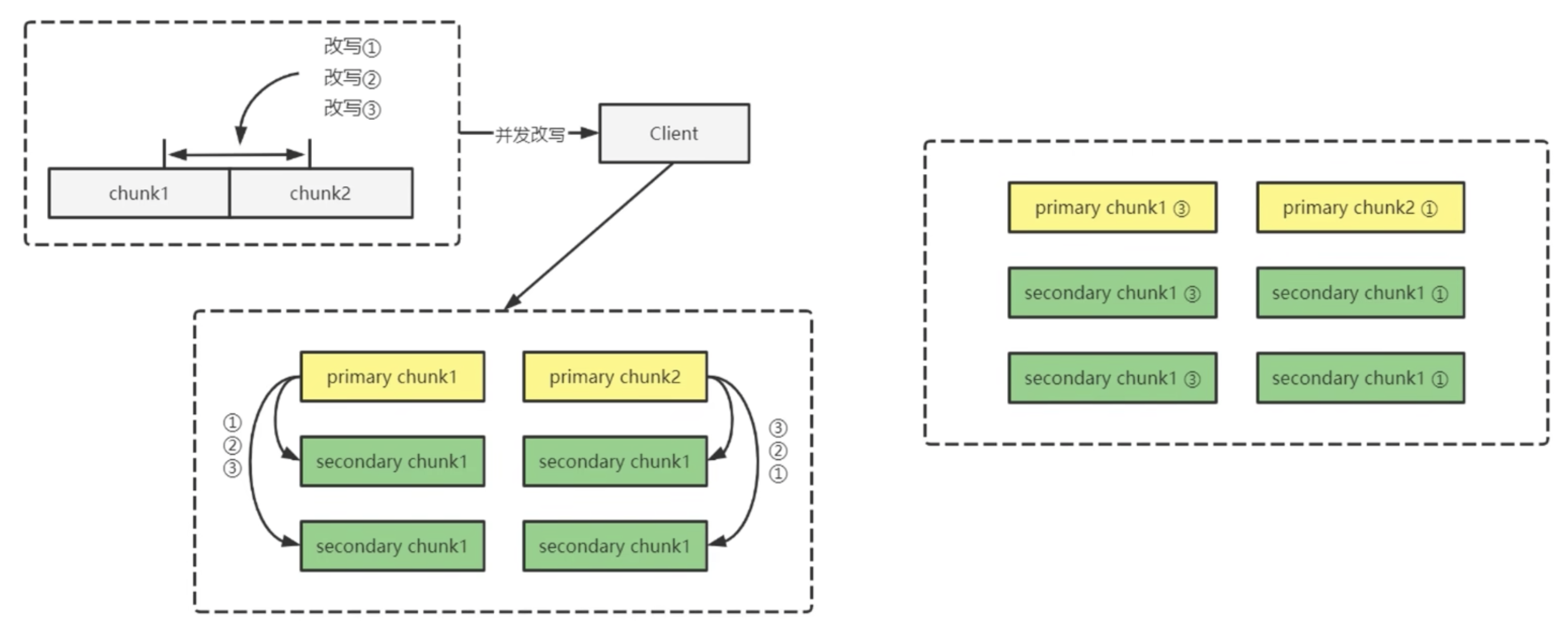
如果在 client 角度,改寫1-3是按順序來執行的,但是對於跨 chunk 來說,primary chunk會根據 client 到達的時間來獲取序列,那麼有可能在 primary chunk2 中獲取的順序是改寫3-1,那麼會導致結果不一致。
追加寫:追加寫並不會如同改寫一樣順序執行不同導致結果不一致。但是有可能重複執行會導致副本間的不一致。為了實現一致性,GFS 對追加寫操作做了一些限制。
- 單次 append 大小不超過 64MB
- 如果檔案最後一個 chunk 的大小不足以提供此次追加所需的空間,則把此空間用 padding 填滿,然後新增 chunk 進行 append
這樣可以保證每次 append 都限制在一個 chunk 上,從而保證追加操作的原子性,並且在論文中說明,追加操作中因為失敗重試的機制會導致一個副本中會有重複執行追加的資料,比如檔案原油的值為「ABC」,追加「DEF」。有的副本第一次失敗再重複執行就是「ABCDEF」,而兩次都正確執行的副本則為「ABCDEFEDF」。利用記錄檔案長度,和各個副本的定期校驗來消除這個重複。
保證強一致性:
- 對於一個chunk所有副本寫入順序都是一致的,這是由控制流和資料流分離技術實現的,控制流都是由 primary 發出的,而副本的寫入順序也是由 primay 到 secodary
- 使用 chunk 版本號來檢測 chunk 副本是否出現過宕機。失效的副本不會再寫入操作,master 不會再記錄這個副本的資訊,gc 程式會自動回收這些副本
- master 會定期檢查 chunk 副本的 checksum 來確認其是否正確
- GFS 推薦應用更多的使用追加來達到一致性
GFS的快照機制:
- 快照的機制是根據 Copy on write 寫時複製來實現的,當需要生成快照時,master 會回收對應的 chunk 的租約,停止對應 chunk 的所有寫入
- 拷貝一份檔案的後設資料並命名為快照檔案,快照檔案的後設資料仍指向原檔案的 chunk。例如,拷貝檔案fileA的後設資料,生成檔案 fileA_backup 後設資料,依然指向原 chunk
- 增加檔案所有chunk的參照計數,例如本來 fileA 的所有 chunk 參照計數都是1,只有 fileA 參照,但是現在變成2,fileA 和 fileA_backup 都參照
- master 正常授權租約,允許對chunk寫入,開始準備下次 fileA 的寫入
- 當下次寫入操作到來時,發現 chunk 的參照次數大於1,修改時會先拷貝一個新 chunk,再在新 chunk 上寫入。例如 fileA 的三個 chunk ABC,chunk C 有寫入,那麼寫入時拷貝 chunk C 為 C’,並寫入 C‘。然後此時的 fileA 指向為 chunk ABC’,fileA_backup指向的是 chunk ABC。這時候才發生真正的快照