GitHub車牌檢測識別專案調研
- 一,EasyOCR
- 二,HyperLPR
- 三,simple-car-plate-recognition-2
- 四,車牌檢測-License-Plate-Detector
- 五,MMOCR
- 六,推薦 YOLOv5-LPRNet-Licence-Recognition
一,EasyOCR
1.1,倉庫介紹
EasyOCR 是一個用於從影象中提取文字的 python 庫, 它是一種通用的 OCR,既可以讀取自然場景文字,也可以讀取檔案中的密集文字。目前支援 80 多種語言和所有流行的書寫指令碼,包括:拉丁文、中文、阿拉伯文、梵文、西里爾文等。
EasyOCR 倉庫 截止到 2022-11-8日,star 數為 16.2k,其檔案目錄和作者給出的一些範例效果如下。
├── custom_model.md
├── Dockerfile
├── easyocr
├── easyocr.egg-info
├── examples
├── LICENSE
├── MANIFEST.in
├── README.md
├── releasenotes.md
├── requirements.txt
├── scripts
├── setup.cfg
├── setup.py
├── trainer
└── unit_test

1.2,使用記錄
1,安裝較為麻煩
在自行安裝了 cuda 庫和 pytorch 的基礎上,可通過 pip install easyocr 命令安裝 easyocr 庫,但是注意解除安裝掉之前安裝的 opencv-python 庫(如果有)。
2,程式碼自動下載模型速度很慢
下載的倉庫裡面預設是不提供任何模型的,因此第一次執行快速推理指令碼會自動下載對應的 ocr 模型,但是!如果網路不穩定,其下載速度非常慢,試了 n 次,基本不可能下載成功。
所以一般必須通過 Model hub 頁面藉助瀏覽器手動點選下載對應中英文 ocr 識別模型,然後手動把模型檔案移動到 ~/.EasyOCR/model 資料夾下。
EasyOCR 倉庫主要是通過 download_and_unzip 介面下載對應模型檔案的,其也是通過呼叫 urllib 模組提供的 urlretrieve() 函數來實現檔案的下載,其定義如下:
def download_and_unzip(url, filename, model_storage_directory, verbose=True):
zip_path = os.path.join(model_storage_directory, 'temp.zip')
reporthook = printProgressBar(prefix='Progress:', suffix='Complete', length=50) if verbose else None
# url 下載連結,zip_path 檔案儲存的本地路徑, reporthook 利用這個回撥函數來顯示當前的下載進度
urlretrieve(url, zip_path, reporthook=reporthook)
with ZipFile(zip_path, 'r') as zipObj:
zipObj.extract(filename, model_storage_directory) # 解壓到指定目錄
os.remove(zip_path) # 移除下載的壓縮包檔案
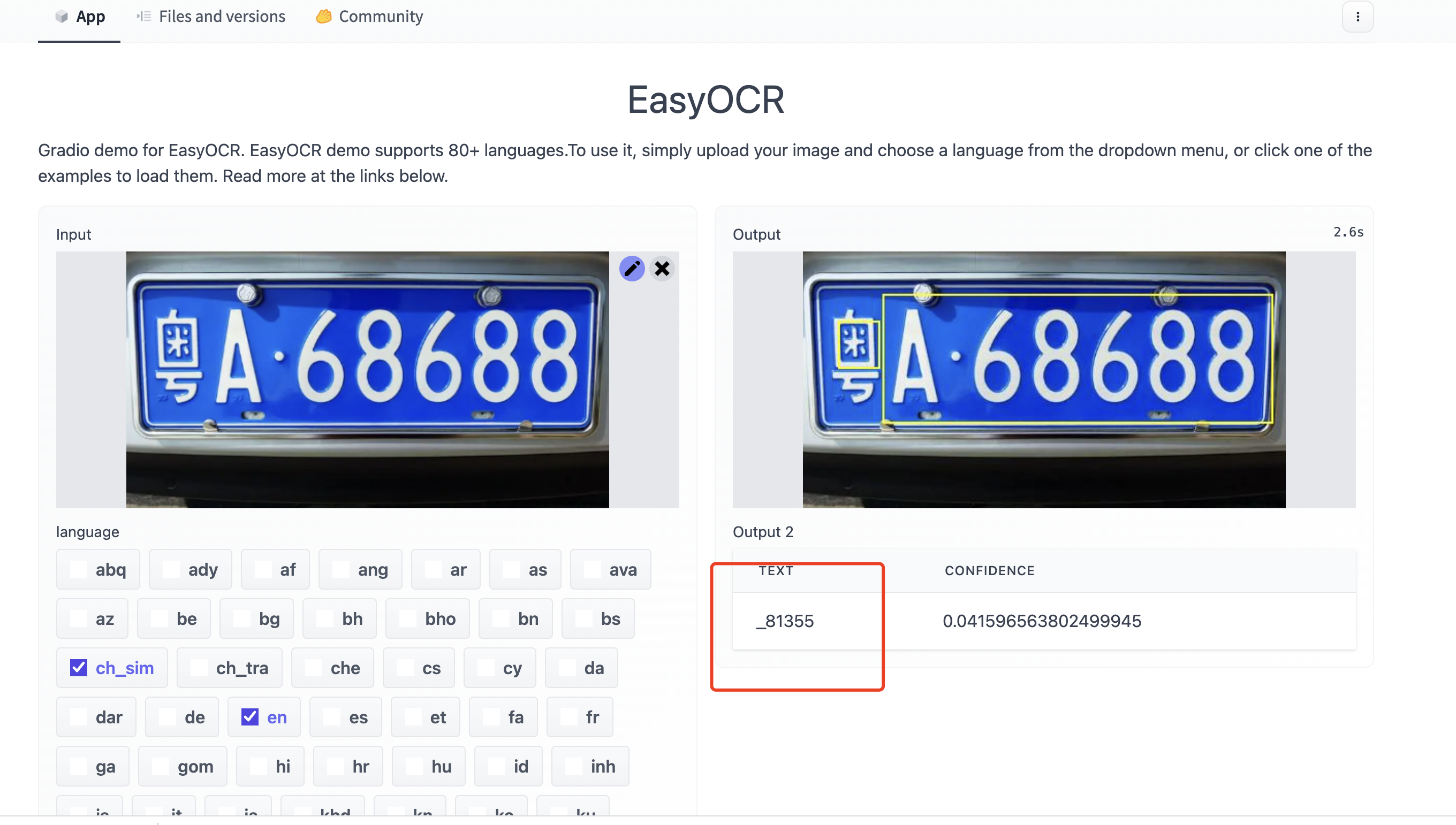
3,車牌場景識別準確率非常低
經過我的大量測試,其在中國車牌場景下識別率幾乎為 0,我猜測是因為作者提供的訓練模型所用的訓練資料沒有車牌場景的,而 ocr 效果又非常依賴場景資料,所以導致汽車車牌識別率幾乎為 0 ,具體實踐效果如下。
二,HyperLPR
2.1,HyperLPR 概述
HyperLPR 框架是 github 作者 szad670401 開源的基於深度學習高效能中文車牌識別框架,支援多平臺,提供了 Window、Linux、Android、IOS、ROS 平臺的支援。 Python 依賴於 Keras (>2.0.0) 和 Theano(>0.9) or Tensorflow(>1.1.x) 機器學習庫。專案的 C++ 實現和 Python 實現無任何關聯,均為單獨實現。
作者提供的測試用例效果如下:

2.3,使用記錄
倉庫 README 檔案描述說 HyperLPR 框架對 python 包支援一鍵安裝: pip install hyperlpr 。但是經過我實際測試發現,pip install hyperlpr 命令只能成功安裝 hyperlpr 庫.
1,快速上手的 py 程式碼執行會出錯:

2,我把 demo 程式碼移動到 hyperlpr_py3 目錄下執行,不再報上圖的錯誤,但是又報了 opencv 函數版本的問題。
hyperlpr) root@crowd-max:/framework/HyperLPR/hyperlpr_py3# python test.py
(1, 3, 150, 400)
40 22 335 123
Traceback (most recent call last):
File "test.py", line 7, in <module>
print(HyperLPR_plate_recognition(image))
File "/opt/miniconda3/envs/hyperlpr/lib/python3.8/site-packages/hyperlpr/__init__.py", line 8, in HyperLPR_plate_recognition
return PR.plate_recognition(Input_BGR,minSize,charSelectionDeskew)
File "/opt/miniconda3/envs/hyperlpr/lib/python3.8/site-packages/hyperlpr/hyperlpr.py", line 311, in plate_recognition
cropped_finetuned = self.finetune(cropped)
File "/opt/miniconda3/envs/hyperlpr/lib/python3.8/site-packages/hyperlpr/hyperlpr.py", line 263, in finetune
g = self.to_refine(image_, pts)
File "/opt/miniconda3/envs/hyperlpr/lib/python3.8/site-packages/hyperlpr/hyperlpr.py", line 231, in to_refine
mat_ = cv2.estimateRigidTransform(org_pts, target_pts, True)
AttributeError: module 'cv2' has no attribute 'estimateRigidTransform'
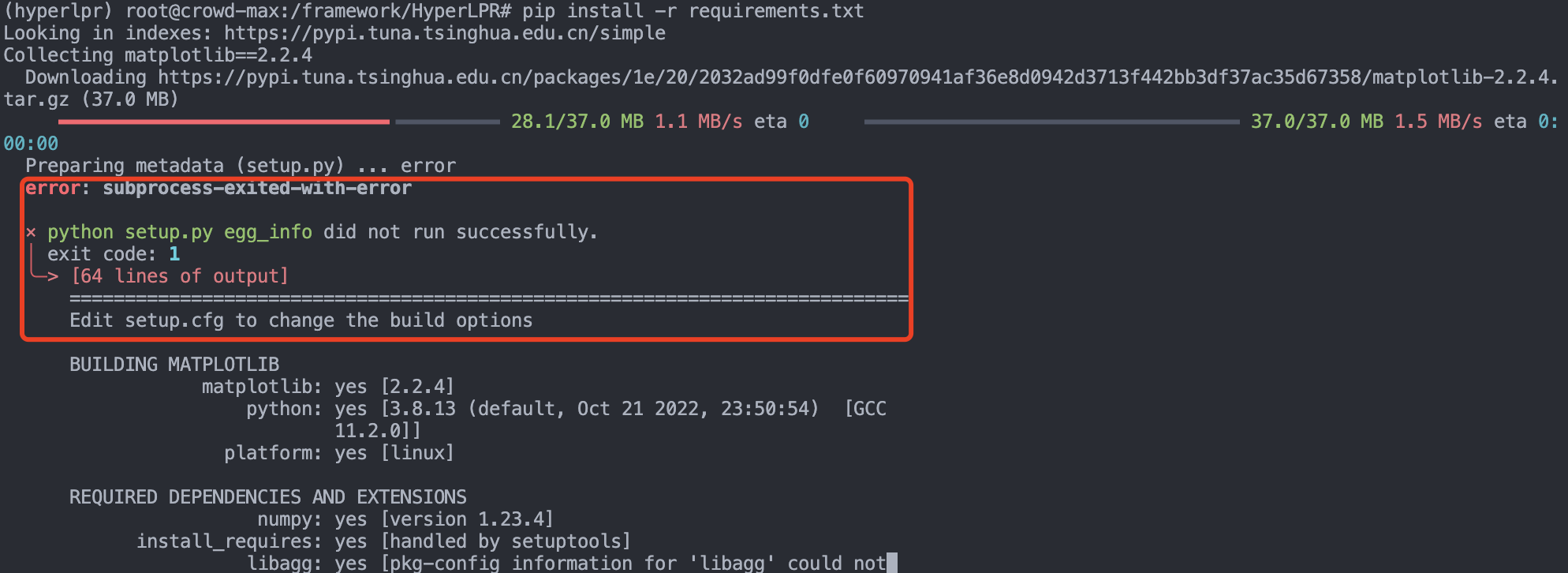
3,ubuntu16.04+python3.8+cuda11.0 環境下,pip install -r requirements.txt 命令安裝依賴包依然會出錯。
2.3,使用建議
個人建議直接使用 C++ 版本,截止到 2022-11-8 日為止,純 Python 版本還是有各種問題。
三,simple-car-plate-recognition-2
3.1,倉庫介紹
simple-car-plate-recognition-2倉庫 簡稱:簡易車牌字元識別 2-Inception/CTC 。
作者使用的字元識別模型是參考 HyperLPR 裡面的一個叫 SegmenationFree-Inception 的模型結構,並改用 pytorch 框架實現,然後訓練模型,最後測試用整張車牌圖片進行字元識別。
作者所用的車牌訓練集,是利用 generateCarPlate 這個車牌生成工具生成的。
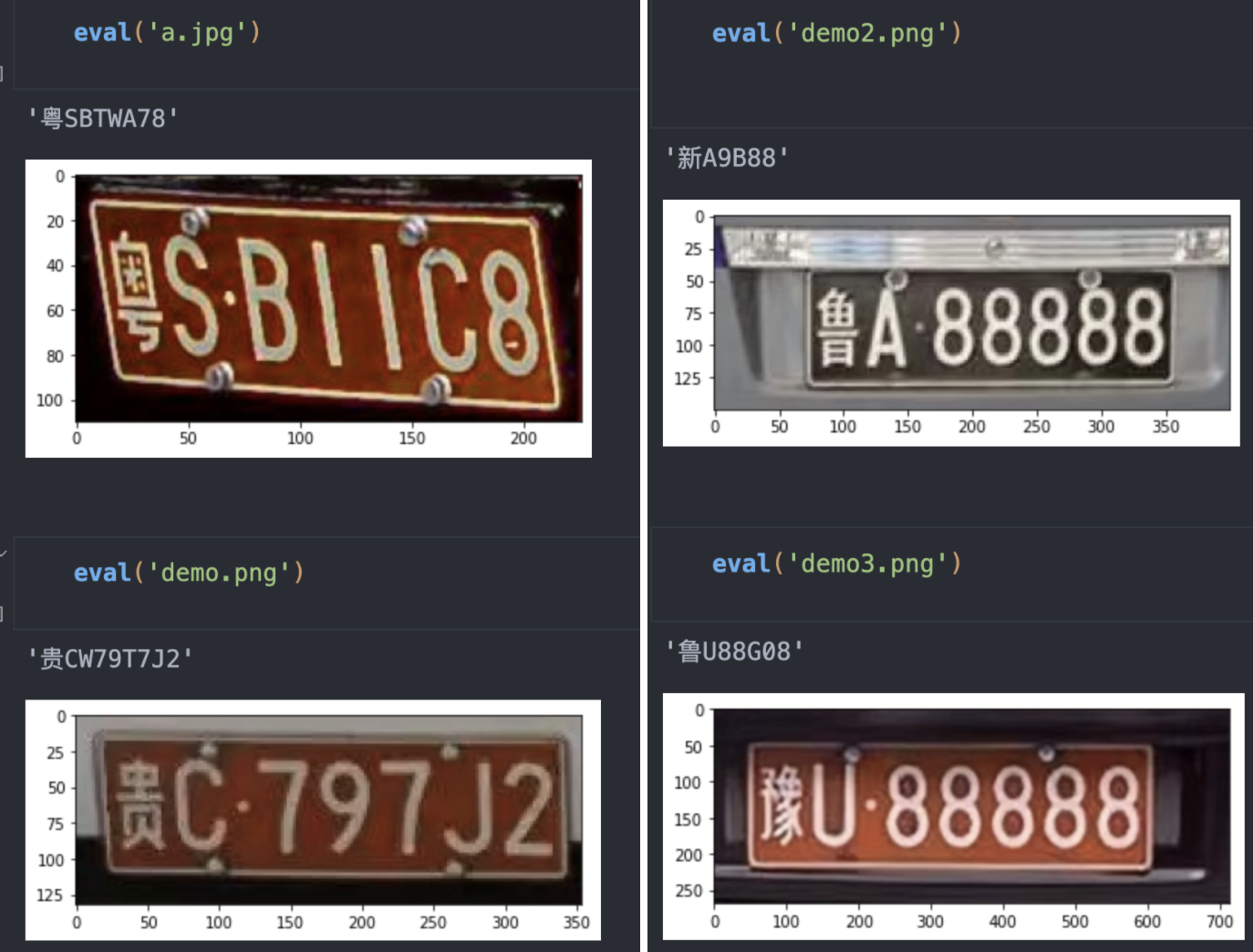
3.2,使用記錄
直接用車牌做識別,實際測試下來,不管用作者給的模型,還是自己訓練的模型,效果都很差。
3.3,使用建議
雖然程式碼簡單,模型結構容易看懂,但是不建議使用,效果不穩定和太差。
四,車牌檢測-License-Plate-Detector
4.1,倉庫介紹
License-Plate-Detector 倉庫 作者利用 Yolov5 模型進行了車牌檢測,訓練集使用 CCPD 資料集,測試效果如下:

4.2,建議
不建議使用,程式碼寫的不夠整潔,使用不夠方便,使用 yolov5** 用作車牌檢測的模型**的方法還是可以參考下。
五,MMOCR
5.1,倉庫介紹
mmocr 是商湯 + openmmlab 實驗室開發的 OCR 框架。MMOCR 是基於 PyTorch 和 mmdetection 的開源工具箱,專注於文字檢測,文字識別以及相應的下游任務,如關鍵資訊提取。 它是 OpenMMLab 專案的一部分。
主分支目前支援 PyTorch 1.6 以上的版本。mmocr 庫的安裝,可參考我之前的文章-ubuntu16.04安裝mmdetection庫。
5.2,使用記錄
1,官方提供中文字元識別模型只有一個,其使用步驟如下:
- 建立
mmocr/data/chineseocr/labels目錄; - 為了模型推理成功,下載中文字典,並放置到
labels目錄;
wget -c https://download.openmmlab.com/mmocr/textrecog/sar/dict_printed_chinese_english_digits.txt
mv dict_printed_chinese_english_digits.txt mmocr/data/chineseocr/labels
- 執行推理指令碼。
python mmocr/utils/ocr.py --det DB_r18 --recog SAR_CN demo/car1.jpeg --output='./'
車牌識別效果不好,測試結果如下:



2,官方提供的測試用例的推理效果如下:

5.3,使用建議
官方提供的不管是中文還是英文文字識別模型,在車牌場景下識別效果都不好,不推薦在車牌識別場景下使用,更適合通用場景。
六,推薦 YOLOv5-LPRNet-Licence-Recognition
6.1,倉庫介紹
YOLOv5-LPRNet-Licence-Recognition 專案是使用 YOLOv5s 和 LPRNet 對中國車牌進行檢測和識別,車牌資料集是使用 CCPD。
車牌字元識別的準確率如下:
model |
資料集 | epochs |
acc |
size |
|---|---|---|---|---|
| LPRNet | val | 100 | 94.33% | 1.7M |
| LPRNet | test | 100 | 94.30% | 1.7M |
總體模型速度:(YOLOv5 + LPRNet)速度:47.6 FPS(970 GPU)。
6.2,使用記錄
作者提供的模型實際測試下來效果還不錯,部分範例如下:


