.NET效能優化-使用RecyclableMemoryStream替代MemoryStream
提到MemoryStream大家可能都不陌生,在編寫程式碼中或多或少有使用過;比如Json序列化反序列化、匯出PDF/Excel/Word、進行圖片或者文書處理等場景。但是如果使用它高頻、巨量資料量處理這些資料,就存在一些效能陷阱。
今天給大家帶來的這個優化技巧其實就是池化MemoryStream的版本RecyclableMemoryStream,它通過池化MemoryStream底層buffer來降低記憶體佔用率、GC暫停時間和GC次數達到提升效能目的。
它的開源庫地址如下連結:
https://github.com/microsoft/Microsoft.IO.RecyclableMemoryStream
使用它也非常簡單,直接安裝對應的Nuget包即可,目前最新版本是2.2.1版本。
// 命令列安裝
dotnet add package Microsoft.IO.RecyclableMemoryStream --version 2.2.1
// csproj 安裝
<PackageReference Include="Microsoft.IO.RecyclableMemoryStream" Version="2.2.1" />
然後建立一個RecyclableMemoryStreamManager物件,即可使用它的GetStream方法來獲取一個池化的流,當然使用完這個流以後需要呼叫Dispose方法將其歸還到池中,也可以使用using模式來釋放。
class Program
{
private static readonly RecyclableMemoryStreamManager manager = new RecyclableMemoryStreamManager();
static void Main(string[] args)
{
var sourceBuffer = new byte[] { 0, 1, 2, 3, 4, 5, 6, 7 };
using (var stream = manager.GetStream())
{
stream.Write(sourceBuffer, 0, sourceBuffer.Length);
}
}
}
在建立RecyclableMemoryStreamManager和GetStream時有很多選項,可以設定底層buffer的大小、為流進行命名隔離等精細化的選項,這些大家可以看官方檔案瞭解,本文不再贅述。
效能比較
為了直觀的比較效能,我構建了一個Benchmark,這個基準測試分別使用MemoryStream和RecyclableMemoryStream實現資料緩衝的功能,下面是測試程式碼:
public class BenchmarkRecyclableMemoryStream
{
// 生成亂數
private static readonly Random Random = new(1024);
// 填充的資料
private static readonly byte[] Data = Enumerable.Range(0, 81920).Select(d => (byte) d).ToArray();
// 每次隨機填充
private static readonly int[] DataLength = Enumerable.Range(0, 1000).Select(d => Random.Next(10240, 81920)).ToArray();
// RecyclableManager
private static readonly RecyclableMemoryStreamManager Manager = new();
[Benchmark(Baseline = true)]
public long UseMemoryStream()
{
var sum = 0L;
for (int i = 0; i < DataLength.Length; i++)
{
using var stream = new MemoryStream();
stream.Write(Data, 0, DataLength[i]);
sum += stream.Length;
}
return sum;
}
[Benchmark]
public long UseRecyclableMemoryStream()
{
var sum = 0L;
for (int i = 0; i < DataLength.Length; i++)
{
using var stream = Manager.GetStream();
stream.Write(Data, 0, DataLength[i]);
sum += stream.Length;
}
return sum;
}
}
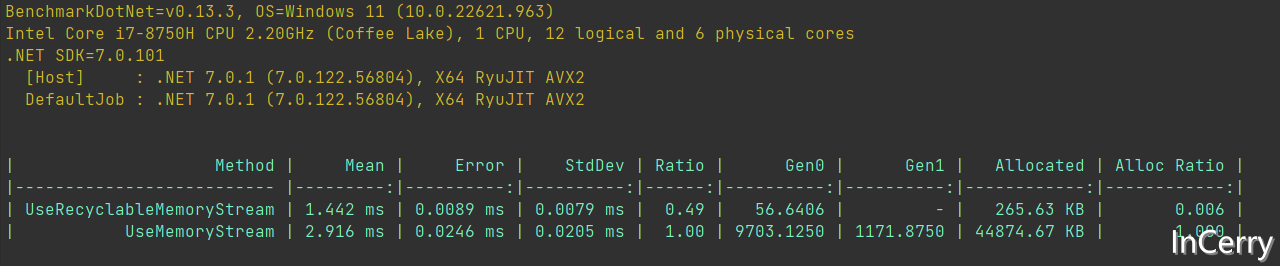
下方是測試的結果,可以看到使用RecyclableMemoryStream比直接使用MemoryStream在記憶體和速度上有很大的優勢。
- 執行效率快51%
- 記憶體分配要低99.4%
工作原理
RecyclableMemoryStream提升GC效能的方式是通過將緩衝區分配和保持在第二代堆,這能減少FullGC的頻率,另外如果您設定的緩衝區大小超過85,000位元組,那麼緩衝區將分配在LOH上,GC不會經常掃描這些物件堆。
RecyclableMemoryStreamManager類維護了兩個獨立的物件池:
- 小型池:儲存小型緩衝區(可設定大小),預設情況下用於所有正常的讀、寫操作,多個小的緩衝區能連結在一起,形成單獨的
Stream。 - 大型池:儲存大型緩衝區,只有在必須需要單個且連續緩衝區才使用,比如呼叫
GetBuffer方法,它可以建立比單個緩衝區大的多的Stream,最大不超過.NET對陣列型別的限制。
RecyclableMemoryStream首先會使用一個小的緩衝區,隨著寫入資料的增多,會將其它緩衝區連結起來組合使用。如果您呼叫了GetBuffer方法,並且已有的資料大於單個小緩衝區的容量,那麼就會被轉換為大緩衝區。
另外您還可以為Stream設定初始容量,如果容量大於單個緩衝區大小,會在一開始就連結好多個塊,當然也可以直接分配大型緩衝區,只需將asContiguousBuffer設定為true。
大型池有兩個版本:
- 線性(預設):指定一個倍數和最大的大小,然後建立一個緩衝區陣列,從(1x倍數)、(2x倍數)一直到最大值。
- 指數:緩衝區不是線性增長而是指數增長,每個槽大小將增加一倍。
如下圖所示:

那麼您應該用哪一個?這取決於您的業務場景。如果您的緩衝區大小不可預測,那麼線性緩衝區可能更合適。如果您知道不可能分配較長的流長度,但是可能有很多較小尺寸的流,那麼選擇指數版本可能會導致較少的總體記憶體使用。
緩衝區是在第一次被請求時按需建立的。使用完Stream後,這些緩衝區將通過RecyclableMemoryStream的Dispose方法返回到池中。當這種返回發生時,RecyclableMemoryStreamManager將使用屬性MaximumFreeSmallPoolBytes和MaximumFreeLargePoolBytes來決定是否將這些緩衝區放回池中,或者讓它們離開(從而被垃圾收集)。正是通過這些屬性,你決定了你的池子可以增長到多大。如果你把這些屬性設定為0,你就會有無限制的池增長,這與記憶體漏失基本上沒有區別。對於每一個應用程式,你必須通過分析和實驗來確定記憶體池大小和垃圾收集之間的適當平衡。
如果忘記呼叫流的 Dispose 方法,可能會導致記憶體漏失。為了幫助您避免這種情況,每個流都有一個終端子,一旦沒有更多對流的參照,CLR 將呼叫該終端子。此終端子將引發有關洩漏流的事件或記錄有關洩漏流的訊息。
請注意,由於效能原因,緩衝區從來沒有預先初始化或歸零。您有責任確保它們的內容是有效和安全的,可以使用緩衝區回收。
使用指南
雖然這個庫力求非常通用化,並且不會對如何使用它施加太多限制,但是它的目的是減少由於頻繁的大量分配而產生的垃圾收集的成本。因此,以下是一些對你有用的通用使用指南:
- 將
blockSize、largeBufferMultiple、maxBufferSize、MaximumFreeLargePoolBytes和MaximumFreeSmallPoolBytes屬性設定為符合你的應用和資源要求的合理值。如果你不設定MaximumFreeLargePoolBytes和MaximumFreeSmallPoolBytes,就有可能出現無限制的記憶體增長! - 每個流總是被精確地
Dispose一次。 - 大多數應用程式不應該呼叫
ToArray,如果可能,應該避免呼叫GetBuffer。相反,使用GetReadOnlySequence來讀取,使用IBufferWriter方法GetSpan、GetMemory和Advance來寫入。還有一些雜七雜八的CopyTo和WriteTo方法,可能很方便。重點是要儘可能避免產生不必要的GC壓力。 - 通過實驗找到適合你情況的設定。
在你嘗試用這個庫來優化你的方案之前,對垃圾收集器有一定的瞭解是一個非常好的主意。像垃圾收集這樣的文章,或者像《編寫高效能的.NET程式碼》這樣的書,將幫助你理解這個庫的設計原則。
在設定選項時,要考慮這樣的問題。
- 我期望的流的長度分佈是怎樣的?
- 有多少個流會在同一時間被使用?
GetBuffer是否經常被呼叫?我需要多大程度的使用大型池緩衝區?- 我需要對活動高峰有多大的彈性? 即我應該保留多少空閒位元組以備不時之需?
- 我在要使用的機器上有哪些實體記憶體限制?
總結
本文中介紹了一個通用的MemoryStream池化庫,使用它能顯著的提升你係統的效能,你幾乎可以在任何場景使用RecyclableMemoryStream替代MemoryStream。要知道在我們效能評測中,RecyclableMemoryStream比MemoryStream快51%,而且它能節省99.4%的記憶體分配。
.NET效能優化交流群
相信大家在開發中經常會遇到一些效能問題,苦於沒有有效的工具去發現效能瓶頸,或者是發現瓶頸以後不知道該如何優化。之前一直有讀者朋友詢問有沒有技術交流群,但是由於各種原因一直都沒建立,現在很高興的在這裡宣佈,我建立了一個專門交流.NET效能優化經驗的群組,主題包括但不限於:
- 如何找到.NET效能瓶頸,如使用APM、dotnet tools等工具
- .NET框架底層原理的實現,如垃圾回收器、JIT等等
- 如何編寫高效能的.NET程式碼,哪些地方存在效能陷阱
希望能有更多志同道合朋友加入,分享一些工作中遇到的.NET效能問題和寶貴的效能分析優化經驗。由於已經達到200人,可以加我微信,我拉你進群: ls1075