遺傳演演算法解決旅行商問題(TSP)
遺傳演演算法解決旅行商問題
- 作者:Cukor丘克
- 環境:MatlabR2020a + vscode
問題描述
旅行商問題(TSP). 一個商人慾從自己所在的城市出發,到若干個城市推銷商品,然後回到其所在的城市。如何選擇一條周遊路線,使得商人經過每個城市一次且僅一次後回到起點,並使他所走過的路徑最短?
TSP 即Travelling Salesman Problem. 中文翻譯過來就是旅行商問題。
旅行商問題是一個典型的NP難問題。NP指的是Non-deterministic Polynomial,即多項式複雜程度的非確定性問題。由於該問題的組合特性,旅行商問題已成為測試新演演算法的標準問題,如模擬退火、神經網路和演化演演算法等都用旅行商問題作為測試用例。旅行商問題的一個範例可由一個距離矩陣所給定。
用遺傳演演算法求解旅行商問題時,適應函數可以取為目標函數或目標函數的一個簡單變換,選擇策略可以是輪盤賭選擇,所以演演算法設計的重點主要集中在以下三個方面:
- 採用適當的方法對周遊路線編碼
- 設計專門的遺傳運算元,以避免不可行性
- 防止過早收斂
下面討論周遊路線常用的幾種表示及其相應的遺傳運算元。
周遊路線編碼
主要有3種編碼表示
- 近鄰表示
- 次序表示
- 路徑表示
近鄰表示
近鄰表示將一條周遊路線表示成\(n\)個城市 的一個排列\(Π=(Π_1,Π_2,...,Π_n)\),\(Π_i=j\)當且僅當周遊路線中從城市\(i\)到達的下一個城市為\(j\).
例如,排列
\((2~4~8~3~9~7~1~5~6 )\)
表示周遊路線為\(1-2-4-3-8-5-9-6-7-1.\)
顯然,每一條周遊路線都對應一個近鄰表示,但任一近鄰排列卻不一定對應於一條周遊路線。
例如,排列
\((2~4~8~1~9~3~5~7~6)\)
導致了不完全迴路\(1-2-4-1\),因而無法對應一條周遊路線。所以周遊路線的近鄰表示就沒有必要再往下介紹。
次序表示
次序表示將一條周遊路線表示為\(n\)個城市的有序表,其中,表中的第\(i\)個元素在\(1\)到\(n-i+1\)取值。該表的一個優點是每一個次序表示都對應於一條合法的周遊路線。
次序表示的基本思想是:取\(n\)個城市的某個排列\((Π_1,Π_2,...,Π_n)\)作為參照排列,通常取\((1,2,...,n)\)作為參照排列,然後將周遊路線中的城市按照其在參照排列中的次序記錄下來,形成一個具有\(n\)個元素的有序表.具體做法如下:
對給定的一條路徑\(Π_1-Π_2-...-Π_n\),首先記錄城市\(Π_1\)在參照排列\((p_1,p_2,...,p_n)\)中的次序\(i_1\),將\(Π_1\)從\((p_1,p_2,...,p_n)\)中刪除得\(n-1\)個城市的參照排列\((q_1,q_2,...,q_k),k=n-1\),再記錄城市\(Π_2\)在參照排列\((q_1,q_2,...,q_k),k=n-1\)中的次序\(i_2\),然後將城市\(Π_2\)從\((q_1,q_2,...,q_k),k=n-1\)中刪除得\(n-2\)個城市的參照排列\((r_1,r_2,...,r_k), k=n-2\),以此類推,直到城市\(Π_n\)的次序\(i_n\)記錄下來為止。有序表\((i_1,i_2,...,i_n)\)稱為路徑\(Π_1-Π_2-...-Π_n\)的次序表示。注意\(i_j\)的取值範圍為\(1 \le i_j \le n-j+1\).
例如,若取\((1,2,...,9)\)作為參照排列,那麼路徑
\(1-2-4-3-8-5-9-6-7\)
的次序表示為
\((1~1~2~1~4~1~3~1~1)\).
雖然次序表示具有可以使用傳統雜交運算元的優點,但實驗表明在次序表示與傳統的雜交運算元相結合所得到的結果並不理想。
路徑表示
路徑表示也許是周遊路徑最自然的一種表示。例如,一條周遊路線
\(5-1-7-8-9-4-6-2-3-5\)
可表示為排列\((5~1~7~8~9~4~6~2~3)\),這裡將排列看成一個首尾相接的圓形排列。
本次案例對周遊路線的編碼採用路徑表示的方案。
雜交
路徑表示的雜交運算元主要有以下幾個:
- 部分對映雜交
- 次序雜交
- 迴圈雜交
- 基於位置雜交
部分對映雜交
部分對映雜交運算元通過從一個父體中選擇一個子序列,並儘可能多地保持另一個父體中城市的次序和位置的方式產生 後代。具體過程如下:
對給定的兩個父體\(p_1,p_2\),部分對映雜交首先隨機地在父體上選擇兩個雜交點,然後交換父體\(p_1,p_2\)在這兩點之間的中間段得到兩個後代\(o_1,o_2\),這一交換同時定義了一個部分對映。這時,\(o_1,o_2\)上除了這兩點之間的城市外,其他的城市尚未確定。對\(o_1,o_2\)中尚未確定的城市,分別保留各自父體 中與中間段無衝突的城市,對與中間段有衝突的城市,則執行部分對映,直到與中間段無衝突為止,再將該城市填入相應的位置即可。
例如,給定下列兩個父體,隨機地選擇兩個雜交點 (以"|"標記),
\(p_1=(2~6~4~|~7~3~5~8~|~9~1),\)
\(p_2=(4~5~2~|~1~8~7~6~|~9~3),\)
將\(p_1,p_2\)在這兩點之間 的中間段交換得
\(o_1=(\#~\#~\#~|~1~8~7~6~|~\#~\#),\)
\(o_2=(\#~\#~\#~|~7~3~5~8~|~\#~\#),\)
其中,\(\#\)表示待定城市。這一交換所確定的部分對映為
\(1<->7,\)
\(8<->3,\)
\(7<->5,\)
\(6<->8.\)
然後,再從各自父體中填入與中間段無衝突的城市得
\(o_1=(2~\#~4~|~1~8~7~6~|~9~\#),\)
\(o_2=(4~\#~2~|~7~3~5~8~|~9~\#),\)
對\(o_1,o_2\)中與中間段有衝突的\(\#\)部分,執行部分對映,直到無衝突為止。例如,\(o_1\)中的第一個\(\#\)初始為6,但6與中間段中的城市衝突,部分對映將6對映到8,但8仍與中間段衝突,部分對映到3,3與中間段不衝突,這時第一個\(\#\)填入3.類似地可以確定其他的\(\#\)部分,最後所得到的\(o_1,o_2\)如下:
\(o_1=(2~3~4~|~1~8~7~6~|~9~5),\)
\(o_2=(4~1~2~|~7~3~5~8~|~9~6),\)
部分對映雜交實現起來比較麻煩,跳來跳去的,所以本次案例不適用部分對映雜交。
次序雜交
次序雜交運算元通過從一個父體中選擇一個子序列,並保持另一個父體中城市的相對次序的方式產生後代。具體操作如下:
對給定的兩個父體\(p_1,p_2\),次序雜交首先隨機地再父體上選擇兩個雜交點,分別保留父體\(p_1,p_2\)在這兩個雜交點之間的中間段得到兩個後代\(o_1,o_2\).這時\(o_1,o_2\)上除了這兩個中間段中的城市外,其他的城市尚未確定。對\(o_1\)中尚未確定的城市,首先將\(p_2\)中的城市從第二個雜交點開始按其相對次序列出,然後將該序列中在\(o_1\)中間段中出現的城市刪除,再將剩餘子序列從第二個雜交點填入\(o_1\)的相應位置即可。同樣的方式可得\(o_2\).
例如,給定下列兩個父體,隨機地選擇兩個雜交點,
\(p_1=(2~6~4~|~7~3~5~8|~9~1),\)
\(p_2=(4~5~2~|~1~8~7~6~|~9~3),\)
保留\(p_1,p_2\)上兩個雜交點之間的中間段得
\(o_1=(\#~\#~\#~|~7~3~5~8~|~\#~\#),\)
\(o_2=(\#~\#~\#~|~1~8~7~6~|~\#~\#),\)
其中,\(\#\)表示待定城市。然後從第二個雜交點 開始,將\(p_2\)中的城市按原次序列出得
\(9-3-4-5-2-1-8-7-6,\)
從中刪除\(o_1\)中間段中的城市得
\(9-4-2-1-6.\)
將該子序列從第二個雜交點開始依次填入到\(o_1\)中得
\(o_1=(2~1~6~|~7~3~5~8~|~9~4),\)
類似可得
\(o_2=(4~3~5~|~1~8~7~6~|~9~2).\)
本次案例使用的雜交運算元就是次序雜交。
迴圈雜交
迴圈雜交運算元如下產生後代:後代中的每個城市是某個父體相應位置的城市。具體過程如下:
對給定的兩個父體\(p_1=(u_1,u_2,...,u_n)\),\(p_2=(v_1,v_2,...,v_n)\),先確定後代\(o_1\)中來自於父體\(p_1\)中的城市。假定\(p_1\)中的第一個城市\(u_1\)在\(o_1\)中,即將\(o_1\)中的第一個位置填入\(u_1\),那麼\(o_1\)中的城市\(v_1\)不可能來自\(p_2\),必來自於\(p_1\).假設\(v1=u_1\),若\(u_i\)還沒填入\(o_1\)中,則在\(o_1\)的第\(i\)個位置上填入\(u_i\).同樣,\(o_1\)中的城市\(v_i\)不可能來自\(p_2\),必來自於\(p_1\).假設\(v_i=u_i\),若\(u_j\)還沒有填入\(o_1\)中,則在\(o_1\)的第\(j\)個位置上填入\(u_j\).這樣繼續下去直到將某個\(u_k\)填入到\(o_1\)後,\(p_2\)中與其相應的城市\(v_k\)也已經填入到\(o_1\)為止,這就構成一個迴圈。再將\(p_2\)中尚未在\(o_1\)中出現的城市直接填入到\(o_1\)中相應的位置即可。類似可得後代\(o_2\).
例如,給定下列兩個父體:
\(p_1=(2~6~4~7~3~5~8~9~1),\)
\(p_2=(4~5~2~1~8~7~6~9~3),\)
先從\(p_1\)中取第一個城市2作為\(o_1\)的第一個城市得
\(o_1=(2~\#~\#~\#~\#~\#~\#~\#~\#).\)
\(p_1\)中城市2對應\(p_2\)中的城市4,而4還沒有填入到\(o_1\)中,將4填入到\(o_1\)中得
\(o_1=(2~\#~4~\#~\#~\#~\#~\#~\#).\)
\(p_1\)中城市4對應\(p_2\)中的城市2,但2已經填入\(o_1\)中了,這完成了一個迴圈。將\(p_2\)中尚未在\(o_1\)中出現的城市直接填入到\(o_1\)中相應的位置後得
\(o_1=(2~5~4~1~8~7~6~9~3).\)
類似可得
\(o_2=(4~6~2~7~3~5~8~9~1).\)
基於位置雜交
基於位置雜交類似於次序雜交,唯一的區別在於:在基於位置雜交中,不是選取父體的一個連續的子序列,而是隨機地選取一些位置,再按次序雜交的方式產生後代。
例如,給定下列兩個父體:
\(p_1=(2~6~4~7~3~5~8~9~1),\)
\(p_2=(4~5~2~1~8~7~6~9~3),\)
假定隨機地選取的位置為2,3,6,8.保留\(p_1,p_2\)上這些位置的城市得
\(o_1=(\#~6~4~\#~\#~5~\#~9~\#),\)
\(o_2=(\#~5~2~\#~\#~7~\#~9~\#),\)
然後從最後一個選取位置的後面開始,將\(p_2\)中的城市按原次序列出得
\(3-4-5-2-1-8-7-6-9,\)
從中刪除\(o_1\)中已經選取的城市得
\(3-2-1-8-7.\)
將該子序列從最後一個選取位置的後面開始依次填入\(o_1\)中得
\(o_1=(2~6~4~1~8~5~7~9~3),\)
\(o_2=(6~5~2~4~3~7~8~9~1).\)
變異
路徑表示的變異運算元有下面幾個:
- 倒位變異
- 插入變異
- 移位變異
- 互換變異
倒位變異
倒位變異的過程如下:
首先在父體上隨機地選擇兩個城市,然後將這兩個城市之間的子序列反轉。
例如,設有父體
\((1~2~3~4~5~6~7~8~9).\)
假定隨機地選擇的兩個城市為3, 7,則對該個體進行倒位變異後得
\((1~2~7~6~5~4~3~8~9).\)
插入變異
插入變異的過程如下:
首先在父體中隨機地選擇一個城市,然後在該城市插入到某個隨機的位置上。
例如,設有父體
\((1~2~3~4~5~6~7~8~9).\)
假定隨機地選擇的城市為2,隨機地選擇位置為6,那麼將城市2插入到第6個位置上得
\((1~3~4~5~6~2~7~8~9).\)
要注意的是,當將所選擇的城市插入到所選擇的位置上時,有兩種城市移動方式。若所選擇的城市在要插入的位置的左邊,則所選擇城市到插入位置之間的城市(包括插入位置上的城市)向左移動一個位置,否則向右移動一個位置。
移位變異
移位變異的過程如下:
首先在父體中隨機地選擇一個連續子序列,然後將該子序列插入到某個隨機的位置上。
例如,設有父體
\((1~2~3~4~5~6~7~8~9).\)
假定隨機地選擇的子序列為4 5 6,隨機地選擇的位置是8,那麼經移位變異後得
\((1~2~3~7~8~4~5~6~9).\)
互換變異
互換變異隨機地選擇兩個城市,並將這兩個城市互換。
例如,設有父體
\((1~2~3~4~5~6~7~8~9).\)
隨機地選擇的兩個城市為3,7,那麼經互換變異後得
\((1~2~7~4~5~6~3~8~9).\)
本次案例採用的變異運算元是互換變異。
演演算法實現
本次使用Matlab來實現遺傳演演算法解決旅行商問題。其中,所涉及到的各子函數放到附錄中。
程式目錄結構如下:
主函數
- main.m
%% 遺傳演演算法解決旅行商問題
%% 清屏
clear; close; clc;
%% 載入資料
city = xlsread('./resources/city.xlsx'); % 載入Excel表格資料
%% 引數初始化
% 主要的引數
popsize = 200; % 種群大小
pc = 0.9; % 交叉概率
pm = 0.05; % 變異概率
gen = 1000; % 迭代次數
% 次要的引數
D = Distance(city); % 城市距離矩陣
[citycount, ~] = size(city); % 記錄城市個數
best_fitvalue = zeros(gen, 1); % 記錄每一代最優的適應值
minlen = zeros(gen, 1); % 記錄每一代路徑最小值
%% 初始化種群
pop = initpop(popsize, citycount);
%% 開始迭代
for it = 1:gen
fitvalue = fitness(pop, D); % 計算適應值
[best_fitvalue(it), best_index] = max(fitvalue); % 記錄適應值最高的值與下標
best_solution = pop(best_index, :); % 記錄當前代的最優個體
minlen(it) = decode(best_solution, D, citycount); % 記錄每一代的最短路徑
newpop = parent_selection(pop, fitvalue); % 父體選擇
newpop = crossover(newpop, pc); % 交叉
newpop = mutation(newpop, pm); % 變異
pop = newpop; % 更新種群
pop(mod(ceil(rand * citycount), citycount)+1, :) = best_solution; % 保留最優個體
end
%% 畫圖
figure(1)
for i = 2:citycount
plot([city(best_solution(i-1), 1), city(best_solution(i), 1)], ...
[city(best_solution(i-1), 2), city(best_solution(i), 2)], 'bo-');
hold on;
end
plot([city(best_solution(citycount), 1), city(best_solution(1), 1)], ...
[city(best_solution(citycount), 2), city(best_solution(1), 2)], 'ro-');
title(['優化最短距離:', num2str(min(minlen))]);
figure(2)
plot(best_fitvalue);
xlabel('迭代次數')
ylabel('目標函數值')
title('適應值變化曲線')
figure(3)
plot(minlen);
xlabel('迭代次數')
ylabel('目標函數值')
title('最短路徑變化曲線')
%% 列印周遊路線
disp('周遊路線:')
words = num2str(best_solution(1));
for i = 2:citycount
words = append(words, '->', num2str(best_solution(i)));
end
words = append(words, '->', num2str(best_solution(1)));
disp(words);
效果圖:
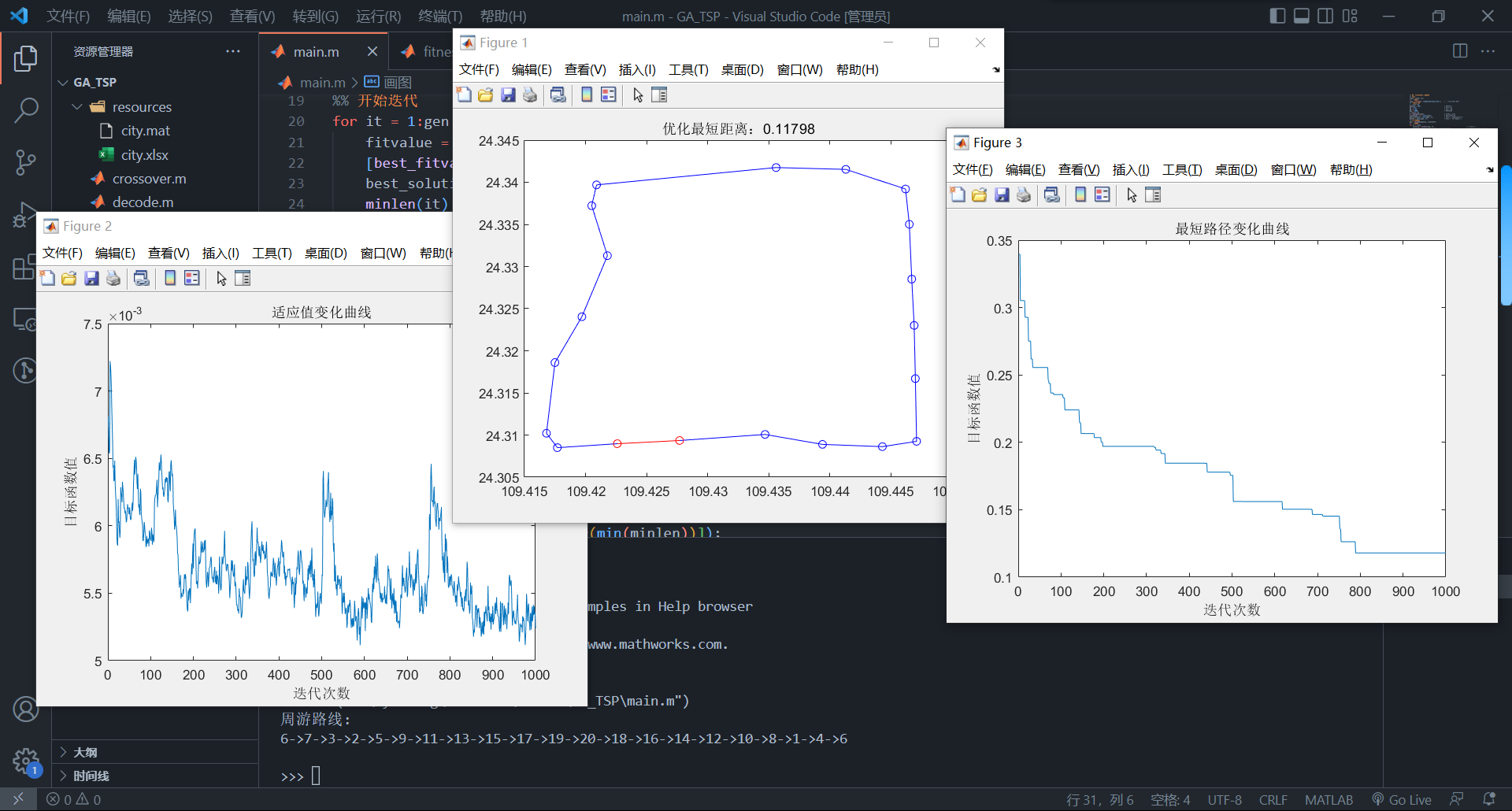
從圖1中可以看到優化最短路徑為0.11798(單位自己換算,一開始用的點是經緯度表示的)周遊路線已繪出,沒有交叉的小圈,基本上是最優解了;圖2是適應值變化曲線,這個是記錄每一代的最優個體的適應值,一直在波動,很符合遺傳演演算法的隨機性;圖3記錄的是每一代的最短路徑,基本在第800代左右收斂到最優解;命令視窗也將周遊路線列印出來,得本次執行的最短路線為
6->7->3->2->5->9->11->13->15->17->19->20->18->16->14->12->10->8->1->4->6。
附錄
各個子函數的Matlab程式碼實現。
- Distance.m
function D = Distance(city)
%Distance - 計算兩個城市之間的距離
%
% Syntax: D = Distance(city)
%
% Long 返回的是一個距離矩陣,記錄每兩個城市之間的距離
[n, ~] = size(city);
D = ones(n, n);
for i = 1:n
for j = i:n
D(i, j) = sqrt((city(i, 1) - city(j, 1)).^2 + (city(i, 2) - city(j, 2)).^2);
D(j, i) = D(i, j);
end
end
end
- decode.m
function path_len = decode(code, D, n)
%decode - 對種群個體解碼
%
% Syntax: path_len = decode(code, D, n)
%
% Long 返回的是路徑長度,一個1*1的矩陣(變數)
path_len = 0;
for j = 2:n
path_len = path_len + D(code(j-1), code(j));
end
path_len = path_len + D(code(n), code(1));
end
- initpop.m
function pop = initpop(popsize, citycount)
%initpop - 初始化種群
%
% Syntax: pop = initpop(popsize, citycount)
%
% Long 返回一個popsize*citycount的矩陣
pop = ones(popsize, citycount);
for i = 1:popsize
pop(i, :) = randperm(citycount);
end
end
- fitness.m
function fitvalue = fitness(pop, D)
%fitness - 計算適應值
%
% Syntax: fitvalue = fitness(pop, D)
%
% Long 返回的是px行1列的矩陣,記錄的是當前種群pop的每一個個體的適應值
[px, py] = size(pop);
fitvalue = zeros(px, 1);
for i = 1:px
fitvalue(i) = decode(pop(i, :), D, py);
end
fitvalue = 1./fitvalue;
fitvalue = fitvalue./sum(fitvalue); % 適應值歸一化
end
- parent_selection.m
function newpop = parent_selection(pop, fitvalue)
%parent_selection - 父體選擇
%
% Syntax: newpop = parent_selection(pop, fitvalue)
%
% Long 返回和pop一樣大小的矩陣,新種群,採用輪盤賭選擇策略
[px, py] = size(pop);
newpop = zeros(px, py);
%% 設計輪盤
p = cumsum(fitvalue); % 在計算適應值函數中已經做好歸一化
%% 轉動輪盤
r = sort(rand(px, 1));
j = 1;
for i = 1:px
while r(i) > p(j)
j = j + 1;
end
% r(i) <= p(j)
newpop(i, :) = pop(j, :);
end
end
- crossover.m
function newpop = crossover(pop, pc)
%crossover - 交叉
%
% Syntax: newpop = crossover(pop, pc)
%
% Long description
[px, ~] = size(pop);
newpop = pop;
for i = 2:2:px
if rand <= pc
[newpop(i, :), newpop(i-1, :)] = sub_crossover(pop(i, :), pop(i-1, :));
end
end
end
function [newcode1, newcode2] = sub_crossover(code1, code2)
%sub_crossover - 子交叉函數
%
% Syntax: [newcode1, newcode2] = sub_crossover(code1, code2)
%
% Long 採用次序雜交的方式進行雜交
newcode1 = code1;
newcode2 = code2;
n = length(code1);
front = -1;
rear = -1;
while front < 1 || rear <= front || rear >= n
front = ceil(rand * n);
rear = ceil(rand * n);
end
p2 = code2;
p1 = code1;
for i = front:rear
p2(p2 == code1(i)) = [];
p1(p1 == code2(i)) = [];
end
j = 1;
for i = 1:n
if i < front || i > rear
newcode1(i) = p2(j);
newcode2(i) = p1(j);
j = j + 1;
end
end
end
- mutation.m
function newpop = mutation(pop, pm)
%mutation - 變異
%
% Syntax: newpop = mutation(pop, pm)
%
% Long 採用互換變異運算元
[px, py] = size(pop);
newpop = pop;
cnt = ceil(rand*py/2); % 確定變異點的個數
pos = mod(ceil(rand(px, cnt) * py), py) + 1; % 變異點的位置
for i = 1:px
if rand <= pm
for j = 2:2:cnt
temp = newpop(i, pos(i, j));
newpop(i, pos(i, j)) = newpop(i, pos(i, j-1));
newpop(i, pos(i, j-1)) = temp;
end
end
end
end
城市資料
>>> city
city =
109.4177 24.3085
109.4443 24.3086
109.4394 24.3089
109.4226 24.3090
109.4471 24.3092
109.4277 24.3093
109.4347 24.3101
109.4168 24.3102
109.4470 24.3167
109.4175 24.3186
109.4469 24.3230
109.4197 24.3240
109.4467 24.3285
109.4218 24.3313
109.4465 24.3350
109.4205 24.3372
109.4462 24.3392
109.4209 24.3397
109.4413 24.3415
109.4356 24.3418
下面是我在bilibli釋出的視訊講解連結:
Cukor丘克-遺傳演演算法解決旅行商問題