遺傳演演算法解決函數優化問題
遺傳演演算法解決函數優化問題
- 作者: Cukor丘克
- 環境: MatlabR2020a + vscode
為什麼要學習遺傳演演算法
為什麼要學習遺傳演演算法,或者說遺傳演演算法有什麼厲害的地方。例如求解以下函數優化問題:
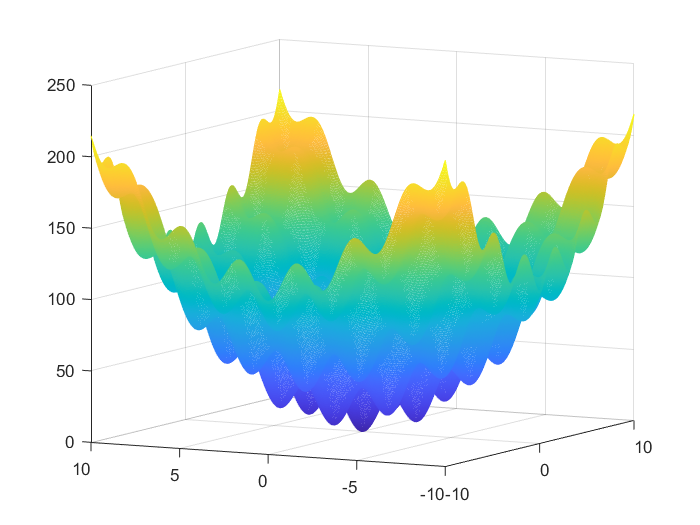
\(min f(x_1, x_2)=x^2_1+x^2_1+25*(sin^2x_1+sin^2x_2), -10 \le x_1 \le 10, -10 \le x_2 \le 10 .\)
方法一:
這個時候你可能想從設一個變數\(i\)從-10到10,一個變數\(j\)從-10到10,每個涉及到的點都遍歷,然後比較前後數值取最大的那個,當遍歷完成了就確定了最大值。
方法二:
對函數求導,然後令導為零,取最小值。
兩種方法在一般理論上都可行。但是有各自的缺點。
方法一的缺點:
每次都從頭開始遍歷,直到把所有的都遍歷完才能確定最值,太耗時間,而且大多數做的都是沒有意義的比較。而且計算機對浮點數的比較有精度的要求,有時候兩個數只差一點點,計算機就會將它們當作是相等的。
方法二的缺點:
不是所有函數的導函數都是容易求解的,而且當出現很多個峰值或谷值的時候也是比較麻煩,就展現不出求導的優勢了。
這個時候就需要像遺傳演演算法這樣的智慧優化演演算法來求解。
目標函數的影象
遺傳演演算法的基本認識
演化計算
生物進化是指一個種群經過漫長的時間所發生的累積變化,這些變化是由於生物體的基因變互斥或在繁殖期間以不同方式重組基因所產生的,而且這些變化可以被遺傳到生物體的後代。
生物的進化可以看成是一個優化過程,而優化的結果是產生能夠很好地適應環境的生物體。現在地球上的種類繁多‘結構複雜的生物都是通過漫長的由簡單到複雜、由低階到高階的進化過程而得到的優化結果。生物的進化過程也可以看成是在眾多可能性中搜尋「解」的一種方法。
演化演演算法
演化計算所涉及的演演算法稱為演化演演算法。所有的演化演演算法都有一個共同點:求解問題的過程也就是模擬大自然生物進化的過程。
演化演演算法模仿自然進化過程,在求解問題的過程中,保持一個個體的種群,每個個體表示問題的一個可能解。個體適應環境的程度用一個適應函數判斷,每個個體安裝適應函數來度量該個體作為問題解的好壞程度。
遺傳演演算法是應用最為廣泛的一種演化演演算法。遺傳演演算法是美國密歇根大學的J.H.Holland教授在研究自然界自適應現象的過程中提出來的。
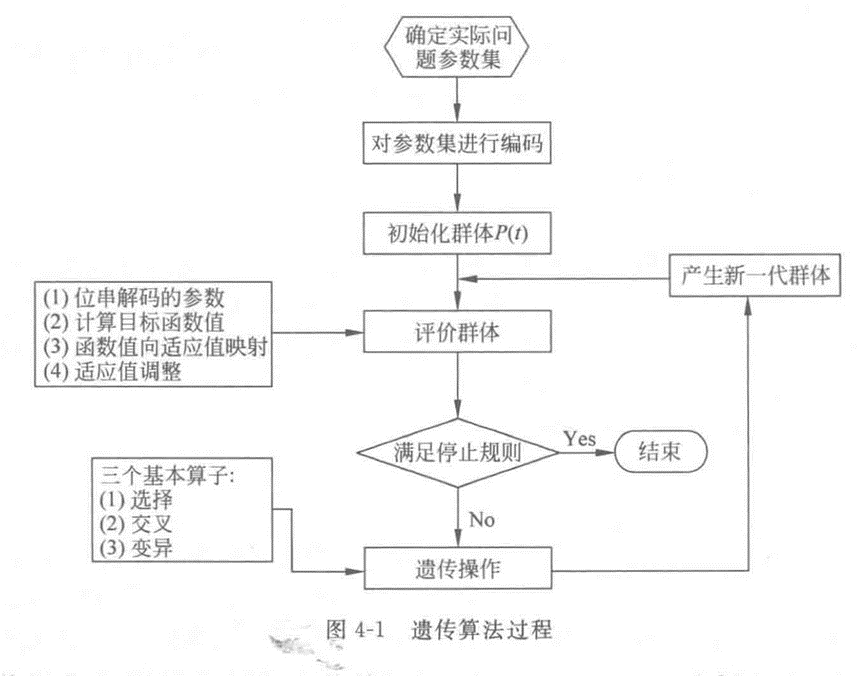
演演算法流程圖
引數初始化
主要影響遺傳演演算法的四個引數
- 種群大小(20~200)
- 交叉概率(0.7~0.9)
- 變異概率(0.02~0.2)
- 迭代次數(20~500)
次要的引數
- 下限
- 上限
- 保留小數點後t位
- 編碼長度陣列
- 個體編碼長度
個體編碼
設計演化演演算法的第一步是對問題的可能解進行編碼,其目的是為了能夠有效地執行遺傳操作。
演化演演算法不是直接作用在問題的解空間上的,而是交替地作用在編碼空間和解空間上。
編碼是一個從問題的解空間到編碼空間的對映。
編碼可以是二進位制編碼也可以是Gray碼編碼,一般就使用二進位制編碼。
一個編碼就對應著一個實數解,一個實數解對應一個編碼。這就需要編碼的長度一定要足夠大,這樣才能把所有的可能解都使用編碼表示 。
範例:
設\(a_j \le x_j \le b_j\)所要求的精度為小數點後t位,這要求將區間\([a_j, b_j]\)劃分為至少\((b_j-a_j)10^t\)份。假設表示變數\(x_j\)的位串長度用\(l_j\)表示,則\(l_j\)可取為滿足下列不等式的最小正整數\(m\):$$(b_j-a_j)10^t \le 2^m-1,$$
將\(x_j\)的二進位制表示轉換為十進位制表示可按下式計算:$$x_j=a_j+decimal(substring_j)*(b_j-a_j)/(2^k-1), k=l_j,$$
編碼
現有\(-3.0 \le x_1 \le 12.1\),精度為小數點後t位,\(t=4\),則帶入上述公式$$(12.1-(-3.0))*10^4=151000,$$
所以表示\(x_j\)的二進位制位串的長度為\(l_1=18,\)
同理\(4.1 \le x_2 \le 5.8\)可以使用\(l_2=15\)的二進位制位串來表示。
而一個個體是由\(x_1、x_2\)共同表示的,所以種群中的每個個體應該使用\(l_1+l_2=33\)的二進位制位串表示。
解碼
給定下列33位二進位制位串:$$011011100110001010110011011001101,$$
那麼表示前18位元所表示的變數\(x_1\)的值為$$x_1=-3.0+decimal(011011100110001010)*(12.1-(-3.0))/(2^k-1), k=18,$$
求得\(x_1=-3.0+113034*15.1/262143=3.5110\)
對\(x_2\)解碼同理。
計算個體的編碼長度的Matlab程式碼如下:
% 主函數中如下呼叫
L = getcodelen(a, b, t); % 編碼長度陣列
len = sum(L); % 編碼長度
% 返回的是一個編碼長度陣列,後續程式碼需要用到它,所以把它和個體的編碼長度分開
function L = getcodelen(a, b, t)
%getcodelen - 計算a到b的十進位制數的最大二進位制編碼長度
%
% Syntax: L = getcodelen(a, b, t)
%
% Long description
n = length(a);
L = zeros(n, 1);
for i = 1:n
while ((b(i) - a(i))*10.^t) > ((2^L(i)) - 1)
L(i) = L(i) + 1;
end
end
end
初始化種群
因為使用的是二進位制編碼,所以只需要確定種群的大小和編碼的長度即可初始化一個種群。然後不斷迭代產生最優的個體。
初始化種群的Matlab程式碼如下:
function pop = initpop(popsize, len)
pop = round(rand(popsize, len));
end
疑問環節:
問:因為種群是隨機生成的,有沒有一種可能,初始化的個體編碼不能和變數的定義域對應。
答:沒有這種可能。因為在設計編碼的時候就是按照定義域a到b的範圍設定的,所以不管怎麼隨機得到的二進位制位串,解碼之後都是在a到b的區間內。並且在解碼的公式中可以看出不會將二進位制位串解碼到a到b的區間之外。x=a+....就表示了最小值一定是a,如果\(decimal(substring)/(2^l-1)=1\),那麼整個式子就剩下\(x=a+b-a=b\),所以最大也就只能到b.
計算適應值
適應函數是區分種群個體好壞的唯一方式,是進行選擇的基礎。
在設計適應函數時,應遵守以下原則:
- 最優解與具有最大適應值的個體相對應
- 適應值能夠反映個體質量的差異
- 計算量應儘可能小
此外,有些選擇策略,如輪盤賭選擇,還要求適應值非負。
常見的適應函數
- 原始適應函數。原始適應函數是直接由目標函數變化而來。當優化問題為\(max f(x)\)時,適應函數為\(f(x)\),當優化問題為\(min f(x)\)時,適應函數為\(-f(x)\).
- 簡單適應函數。為了防止適應值為負的情形,常常需要對目標函數作簡單變換。對於優化問題\(max f(x)\),適應函數可以定義為$$1/(cmax-f(x)),$$
其中,\(cmax>f(x)\).對應優化問題\(min f(x)\),適應函數可以定義為$$1/(f(x)-cmin),$$
其中,\(f(x)>cmin\).
function fitvalue = fitness(pop, f, a, b, L, cmin)
%fitness - 計算適應值
%
% Syntax: fitvalue = fitness(pop, f, a, b, L, cmin)
%
% Long description
[px, ~] = size(pop);
fitvalue = zeros(px, 1);
x = zeros(px, length(L));
for i = 1:px
x(i, :) = decode(pop(i, :), a, b, L);
fitvalue(i) = 1./(f(x(i, 1), x(i, 2)) - cmin);
end
end
父體選擇
選擇或複製操作是決定哪些個體可以進入下一代。選擇哪些適應值比較高的個體。我們採用選擇策略是輪盤賭選擇,因為這個方法比較簡單,也比較直觀。
輪盤的設計
- 累加適應值,得到一個常數F
- 每個適應值除以F,得到了每個個體的適應值所佔整體的份數\(p_i\)
- 累加每個\(p_i\),實現擺盤操作
轉動輪盤
隨機地產生一些亂數,相當於轉動了輪盤。可以使用rand函數來實現。
function newpop = parent_select(pop, fitvalue)
%parent_select - 父體選擇
%
% Syntax: newpop = parent_select(pop, fitvalue)
%
% Long description
[px, py] = size(pop);
newpop = zeros(px, py);
%% 輪盤的設計
p = cumsum(fitvalue./sum(fitvalue));
%% 轉動輪盤
r = sort(rand(px, 1)); % 排序是為了減少頻繁變動輪盤的指標
j = 1;
for i = 1:px
while r(i) > p(j)
j = j + 1;
end
% r(i) <= p(j)
newpop(i, :) = pop(j, :);
end
end
交叉
遺傳運算元的設計是與編碼密切相關的。因為之前採用的編碼是二進位制編碼,所以後面提到的遺傳運算元的交叉、變異都是基於二進位制位串的。
- 點式雜交。
- 單點雜交
- 多點雜交
本次案例採用的雜交方式是單點雜交。
單點雜交演演算法過程:
設二進位制位串的長度是\(L\),首先隨機地產生一個整數\(pos\)作為雜交點的位置,\(1 \le pos \le L\),然後將兩個父體在該雜交點右邊的子串進行交換,產生兩個後代個體。
例如:給定兩個父體如下:
$v_1=(100111000101\ |\ 01011001110), $
$v_2=(100010111100\ |\ 11001100101). $
假設雜交點的位置是13,也就是上面畫 |之後的二進位制位串進行交叉。結果如下:
$v' _1 =(100111000101\ |\ 11001100101), $
$v' _2 =(100010111100\ |\ 01011001110), $
多點雜交演演算法過程:
設二進位制位串的長度是\(L\),多點雜交在$1~ ~\ ~L-1 $之間隨機地選擇多個雜交點,然後再保持第一個雜交點左邊的對應字串不交換的情形下,間隔地交換兩個父體在雜交點之間的對應字串,生成兩個後代 。
例如,給定兩個父體如下:
\(f_1=(1000111110~|~10101110101~|~001001),\)
\(f_2=(1011011101~|~00100110100~|~110101).\)
假設所選擇的兩個雜交點分別為11和22,那麼經兩點雜交後,所得到的兩個後代個體如下:
\(s_1=(1000111110~|~00100110100~|~001001),\)
\(s_2=(1011011101~|~10101110101~|~110101).\)
在多點雜交中,有三段雜交的也是類似的操作。
- 均勻雜交。
均勻雜交是依概率交換兩個父體位串的每一位,其過程如下:
先隨機地產生一個與父體等長的二進位制位串,其中,0表示不交換,1表示交換,這個二進位制位串稱為雜交模板,然後根據所產生的雜交模板對兩個父體進行雜交。
例如,給定兩個父體如下:
\(f_1=(01001),\)
\(f_2=(10101).\)
假設所產生的雜交模板為:
\((00101)\)
所得到的兩個後代如下:
\(s_1=(01101),\)
\(s_2=(10001).\)
下面給出單點雜交的Matlab程式碼,其他的兩種雜交演演算法由你自己實現,也很好實現的。
function newpop = crossover(pop, L, pc)
%crossover - 交叉
%
% Syntax: newpop = crossover(pop, L, pc)
%
% Long description
[px, ~] = size(pop);
newpop = pop;
start = 3; % 奇數的情況,從第3個個體開始
if mod(px, 2) == 0
start = 2;
end
n = length(L);
for i = start:2:px
if rand <= pc
rear = 0;
for j = 1:n
front = rear + 1;
rear = front + L(j) - 1;
[newpop(i, front:rear), newpop(i-1, front:rear)] ...
= sub_crossover(pop(i, front:rear), pop(i-1, front:rear));
end
end
end
end
function [newcode1, newcode2] = sub_crossover(code1, code2)
%sub_crossover - 子交叉函數
%
% Syntax: [newcode1, newcode2] = sub_crossover(code1, code2)
%
% Long description
n = length(code1);
pos = -1; % 交叉點
while pos < 1
pos = ceil(rand * n);
end
newcode1 = code1;
newcode2 = code2;
newcode1(pos:n) = code2(pos:n);
newcode2(pos:n) = code1(pos:n);
end
變異
二進位制編碼時的變異運算元非常簡單,只是依一定概率\(p_m\)(變異概率)將所選個體的位串取反,即若是1則取0;若是0,則取1.
變異的Matlab程式碼
function newpop = mutation(pop, pm)
%mutation - 變異
%
% Syntax: newpop = mutation(pop, pm)
%
% Long description
[px, py] = size(pop);
newpop = pop;
cnt = ceil(rand*py/2); % 確定變異點的個數
pos = mod(ceil(rand(px,cnt) * py), py) + 1; % 變異點的位置
for i = 1:px
if rand <= pm
for j = 1:cnt
newpop(i, pos(i, j)) = ~newpop(i, pos(i, j));
end
end
end
end
到此為止,已經將遺傳演演算法的主體部分介紹完畢,接下來就是回到實際問題中,使用遺傳演演算法解決它,即繪圖分析、結果分析之類的。
回到問題
原問題是求解以下函數優化問題:
\(min f(x_1, x_2)=x^2_1+x^2_1+25*(sin^2x_1+sin^2x_2), -10 \le x_1 \le 10, -10 \le x_2 \le 10 .\)
那就把圖畫出來,用遺傳演演算法把每一代的最優個體所對應影象上的點繪製出來,最後在歷代最優個體中選出適應值最高的個體,這個個體(可能解)就當作是函數\(f(x_1,x_2)\)的全域性最優解。
下面給出本次案例的主函數的matlab程式碼。所涉及到的其他呼叫子函數已經在上面實現,在自己編寫的時候記得自己另建立一個對應的*.m檔案。
%% 遺傳演演算法解決優化問題
%% 清屏
clear; clc;
%% 目標函數
f = @(x1, x2)(x1.^2 + x2.^2 + 25*(sin(x1).^2 + sin(x2).^2));
%% 引數初始化
% 主要影響遺傳演演算法的四個引數
popsize = 100; % 種群大小
pc = 0.8; % 交叉概率
pm = 0.05; % 變異概率
gen = 200; % 迭代次數
% 次要的引數
a = [-10.0 -10.0]; % 下限
b = [10.0 10.0]; % 上限
t = 4; % 保留小數點後t位
L = getcodelen(a, b, t); % 編碼長度陣列
len = sum(L); % 個體編碼長度
cmin = -100;
% 與畫圖有關的變數
x = zeros(gen, length(L)); % 每一代的最優解的x分量
z = zeros(gen, 1); % 每一代的最優解的適應值
%% 初始化種群
pop = initpop(popsize, len);
%% 開始迭代
for it = 1:gen
fitvalue = fitness(pop, f, a, b, L, cmin); % 計算適應值
[z(it), best_index] = max(fitvalue); % 記錄每一代的最優個體(最高適應值、下標)
x(it, :) = decode(pop(best_index, :), a, b, L);
newpop = parent_select(pop, fitvalue); % 父體選擇
newpop = crossover(newpop, L, pc); % 交叉
newpop = mutation(newpop, pm); % 變異
pop = newpop;
end
%% 列印最優解
[best_fitvalue, best_index] = max(z);
best_solution = x(best_index, :);
best_value = f(best_solution(1), best_solution(2));
disp(['最優解為: ' num2str(best_solution)]);
disp(['最優適應值為:' num2str(best_fitvalue)]);
disp(['最小值為:' num2str(best_value)]);
%% 畫圖
figure(1)
[X, Y] = meshgrid(a(1):0.05:b(1), a(2):0.05:b(2));
Z = f(X, Y);
mesh(X, Y, Z);
text(x(:, 1), x(:, 2),f(x(:,1), x(:, 2)), 'o', 'Color','blue', 'Fontsize', 8);
text(best_solution(1), best_solution(2), best_value, 'O', 'Color', 'red', 'FontSize', 15)
hold on;
best = z;
for i = 2:gen
best(i) = max(best(i), best(i-1));
end
figure(2)
plot(z);
figure(3);
plot(best);
結果圖
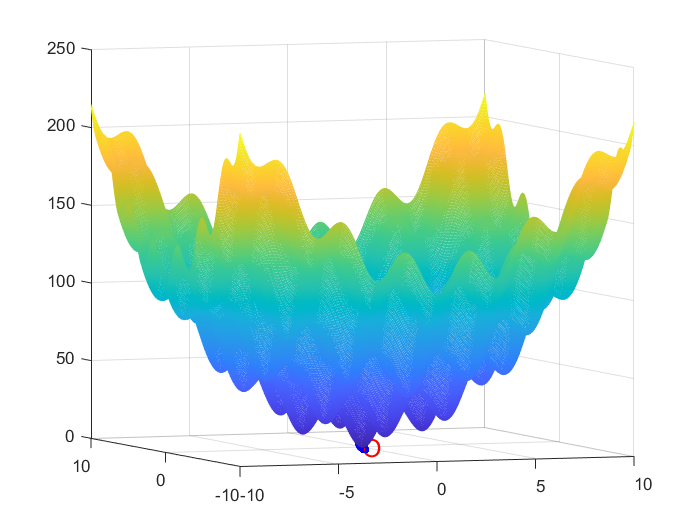
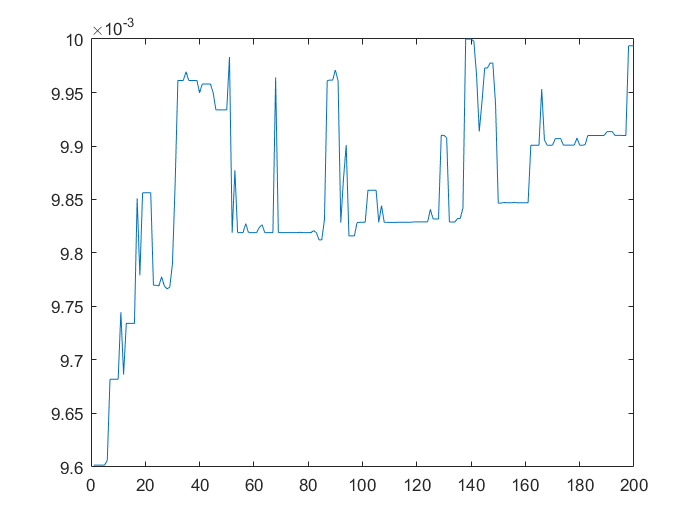
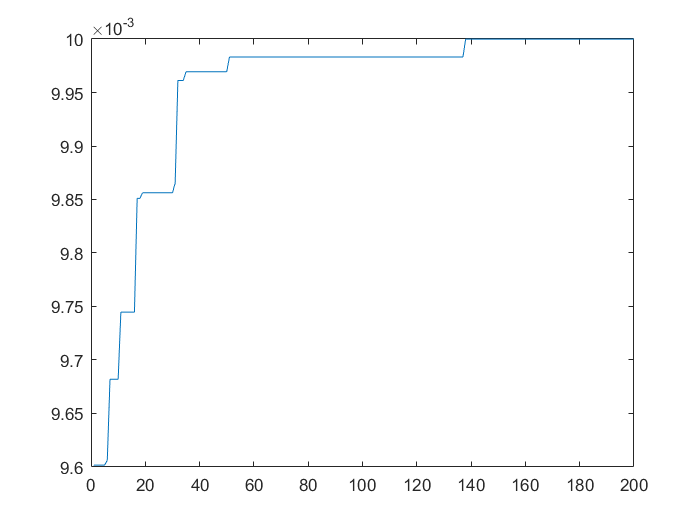
從圖1可以看出,通過遺傳演演算法計算出的最優解基本貼近原函數的的最小值的位置,說明這個最優解可行。從圖2和圖3可以看到遺傳演演算法是可以收斂到最優解的。本次執行程式大概在第145代左右確定全域性最優解,雖然不是標準最優解\((0,0)\),但是這個最優解已經貼近標準最優解了。
同時本文章也有配套的視訊講解,下面是筆者在bilibli釋出的遺傳演演算法的講解視訊連結:
Cukor丘克-《通過例子學習遺傳演演算法(遺傳演演算法解決函數優化問題)》
參考文獻
[1] 黃競偉, 朱福喜, 康立山. 《計算智慧》. 科學出版社,2010.6.
[2] 溫正. 《智慧優化演演算法》.