資料探勘原理與應用期末考試複習
1 緒論
資料探勘定義
資料探勘是從大量的、不完全的、有噪聲的、模糊的、隨機的資料中提取隱含在其中的、人們事先不知道的、但又是潛在有用的資訊和知識的過程。
資料探勘是從資料中提取資訊和知識的過程。

*資料規範和離散化分別解決資料中的哪些問題,分別有哪些方法?
-
資料規範化解決不同量綱下資料的統一問題,將資料放縮至一個合適的區間,避免資料對量綱選擇的依賴性;
-
主要方法有:最大最小規範化法、z-score規範化法、小數定標
-
資料離散化解決資料探勘演演算法的對離散資料的需求問題
-
主要方法有:等寬法、等頻法、聚類法
4 樸素貝葉斯分類
分類概念
找出描述和區分資料類或概念集的模型,以便能夠使用該模型預測類標號未知的物件的類標號
分類一般過程


最大分類錯誤數


*資訊增益演演算法的基本原理是什麼?
基本原理來源於數學中的熵,提出資訊熵,熵越高表示資料越混亂,熵越低表示資料越純。
因此提出資訊增益的概念,資訊增益越大表示劃分的分類越純,因此根據資訊增益從大到小的排列順序列為決策樹中從上到下的各節點
資料是連續的怎麼辦
二元劃分-離散化
等寬法、收入變成三個離散狀態
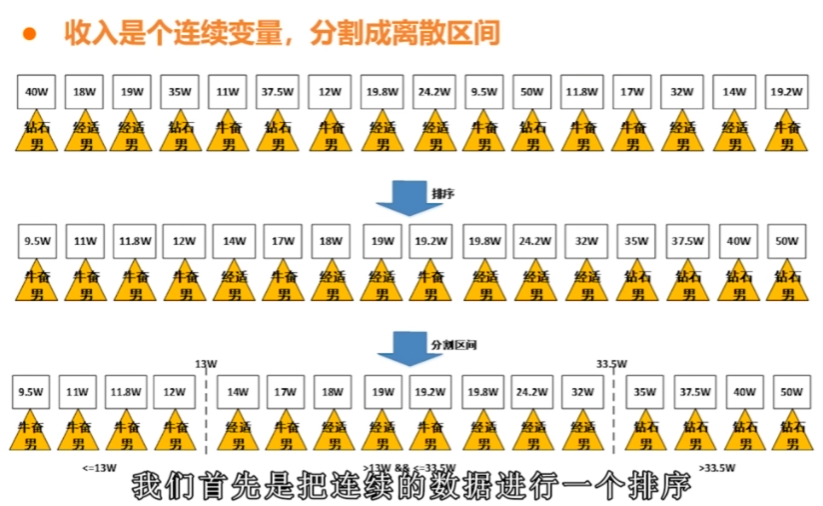
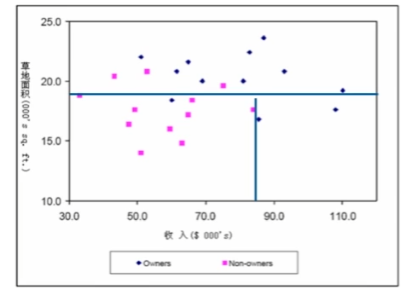
二元劃分-分割區間

Cart演演算法
基於Gini指數
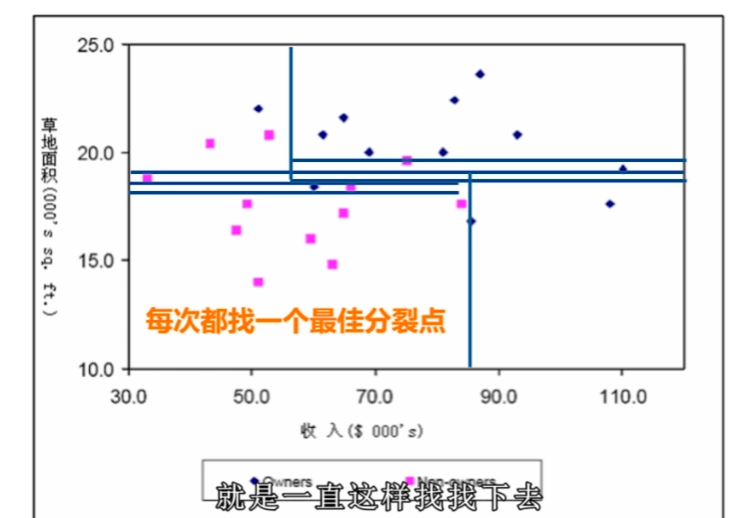
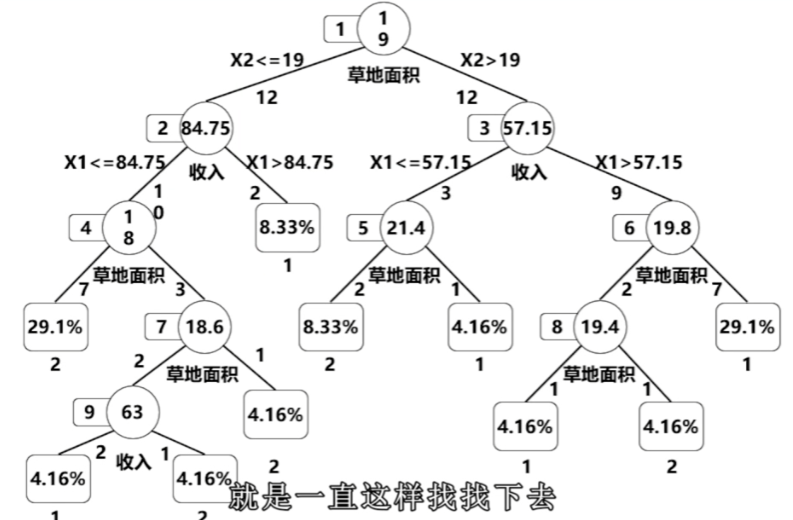
複雜決策樹帶來過擬合問題
過擬合,訓練集太少,模型太複雜。
欠擬合,訓練集太多,模型太簡單。
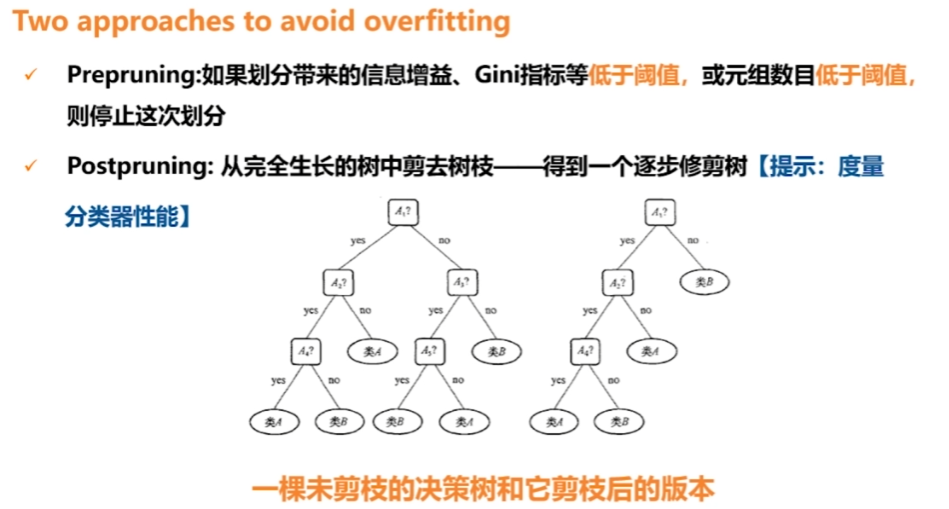
- 對決策樹進行剪枝
- 事前剪枝,構造過程中資訊增益越來越小,設定閾值,小到一定程度不再劃分
- 事後剪枝,構造完成後用新測試集對每個分支錯誤率進行計算,把錯誤率高的去掉
決策樹特點

缺點
1、子樹可能在決策樹中重複多次,容易發生過擬合(隨機森林可以很大程度上減少過擬合);
2、容易忽略資料集中屬性的相互關聯,特徵關聯較強時表現不好
6 K-均值聚類
聚類概念


劃分方法



K均值演演算法適用性
球狀的簇。

K均值演演算法

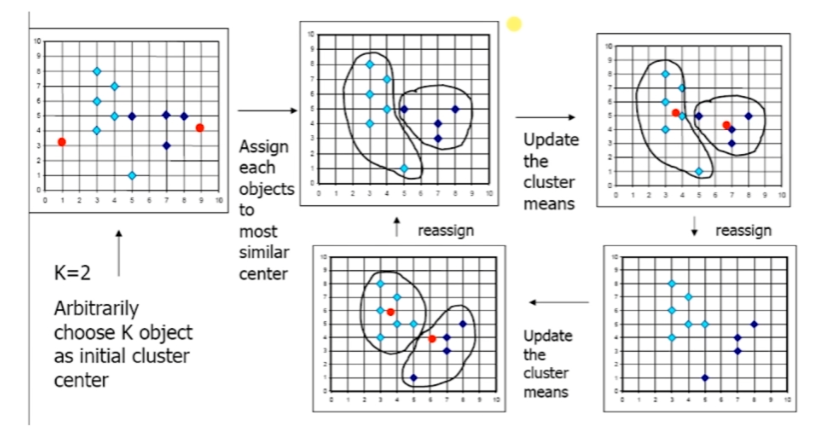
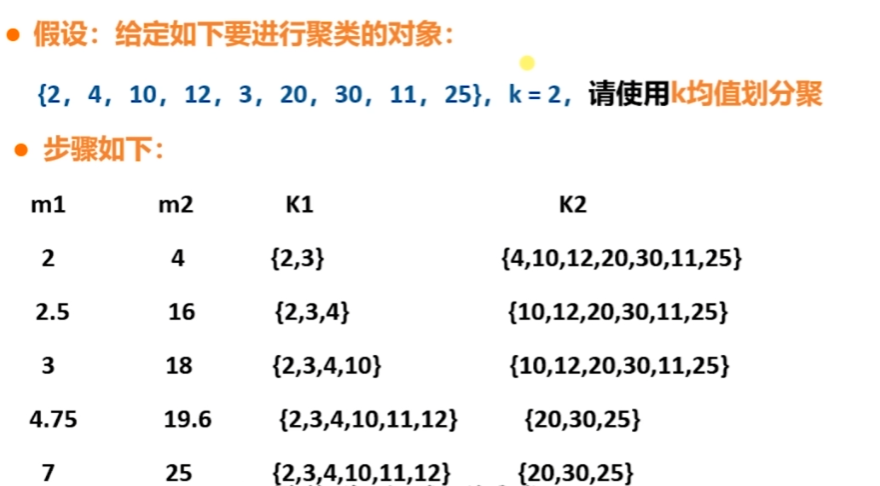
K均值演演算法特點

*k-均值演演算法的基本原理是什麼?
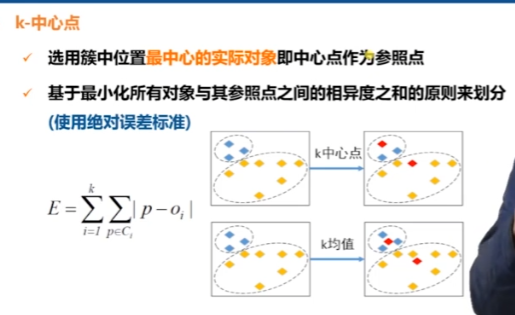
基本原理; 在給定子集個數的條件下,將資料按照距離分佈在隨機點周圍,並不斷調整,保證簇中的資料距離中心最優
K-means演演算法是一種典型的基於劃分的聚類演演算法,該演演算法具有運算速度快,執行過程簡單的優點,在很多巨量資料處理領域得到了廣泛的應用。K-means演演算法的思想利用相似性度量方法來衡量資料集中所有資料之間的關係,將關係比較密切的資料劃分到一個集合中。
(1) K-means演演算法首先需要選擇K個初始化聚類中心
(2) 計算每個資料物件到K個初始化聚類中心的距離,將資料物件分到距離聚類中心最近的那個資料集中,當所有資料物件都劃分以後,就形成了K個資料集(即K個簇)
(3)接下來重新計算每個簇的資料物件的均值,將均值作為新的聚類中心
(4)最後計算每個資料物件到新的K個初始化聚類中心的距離,重新劃分
(5)每次劃分以後,都需要重新計算初始化聚類中心,一直重複這個過程,直到所有的資料物件無法更新到其他的資料集中。
K均值的問題
- K估計比較重要, 散點圖人工觀察簇的個數、根據經驗使用總資料集個數的開根號作為k的個數
- 資料分佈形狀對分簇結果影響
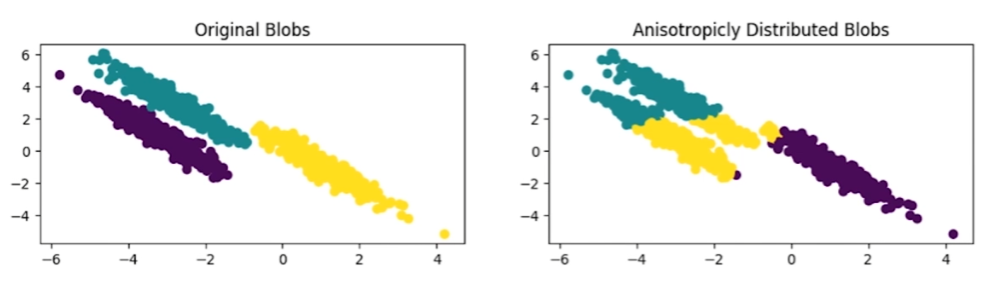
- 資料分散程度對分簇結果影響
- 隨機初始種子對分簇結果影響
標稱型別資料怎麼辦
K modes眾數演演算法。找均值點,出現次數最多的數作為離散資料的均值點。
K均值++演演算法解決初始點選擇問題

K中心點方法解決對離群點敏感問題

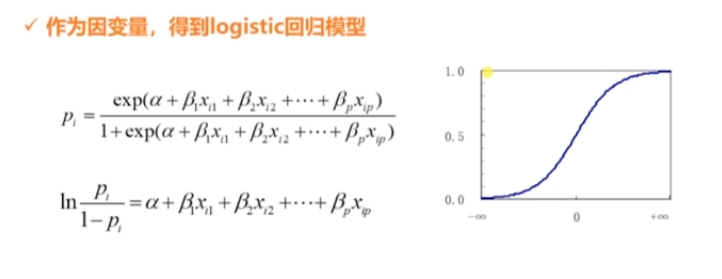
7 邏輯迴歸(X)
概念


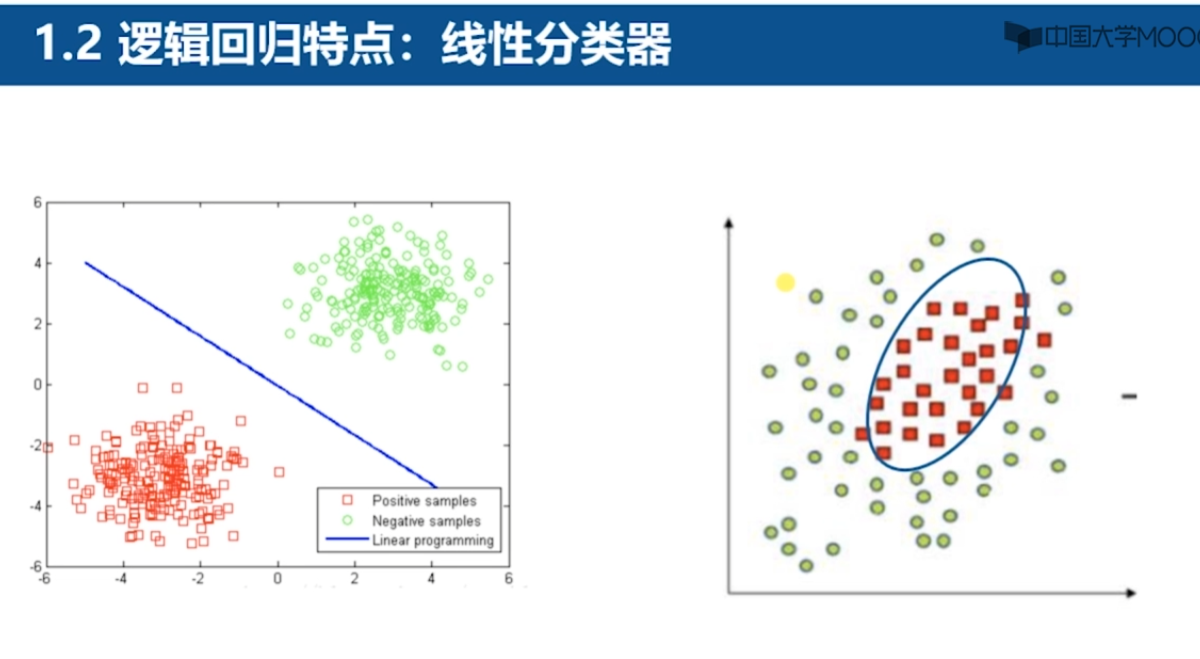
線性分類器

8 關聯規則挖掘
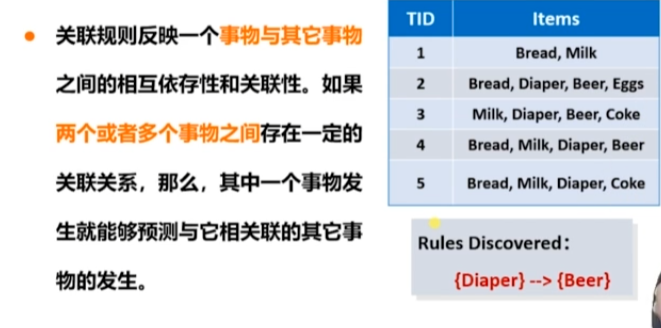
項集概念
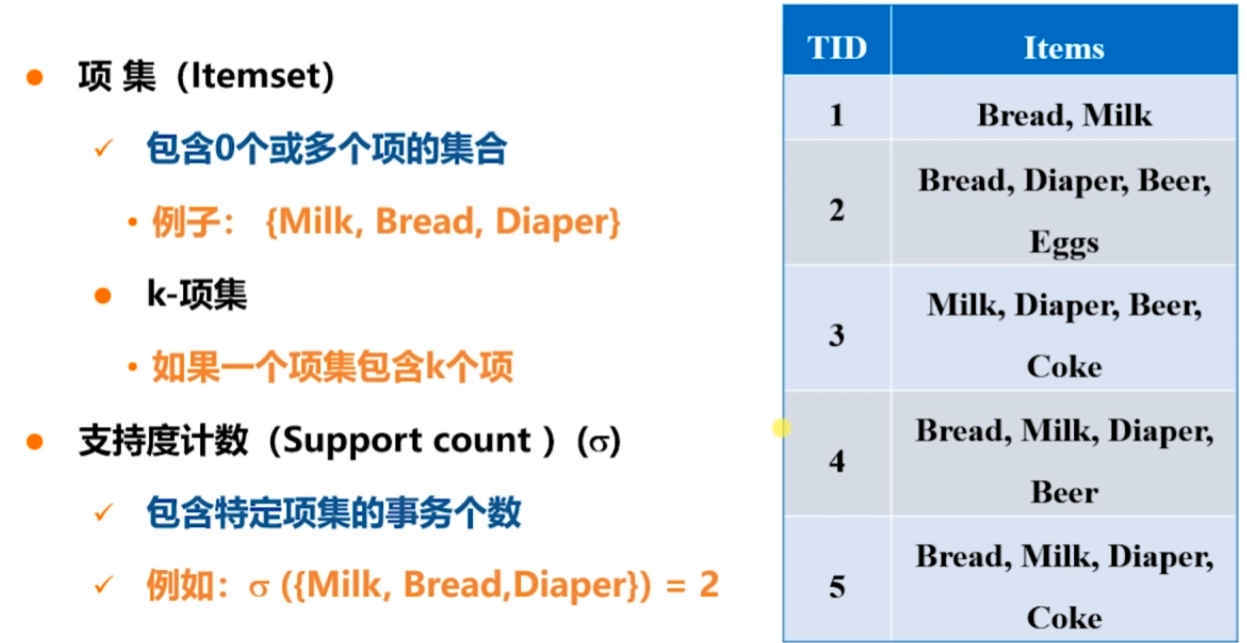

閾值根據經驗事先指定。

關聯規則
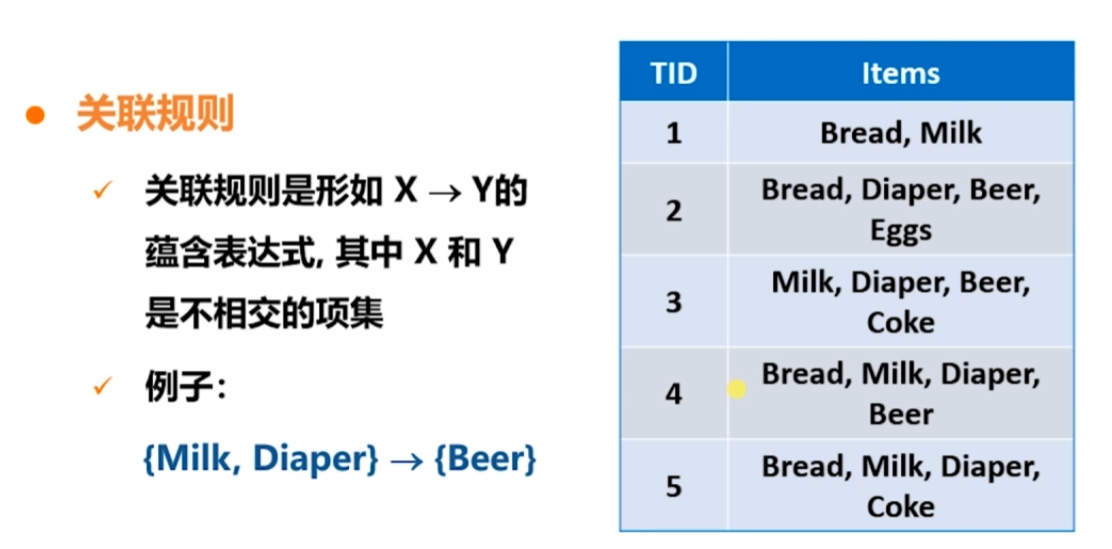

關聯規則發現

置信度一般要考慮頻繁二項集及以上。
關聯規則任務的過程

蠻力法
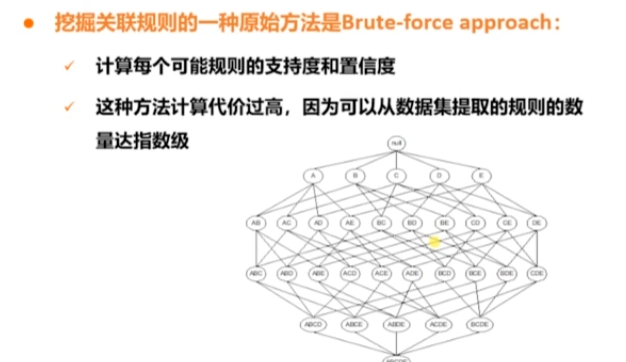
Apriori演演算法


基於先驗原理進行提前剪枝
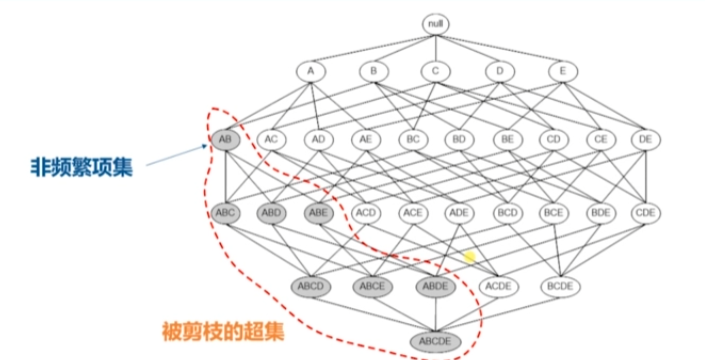
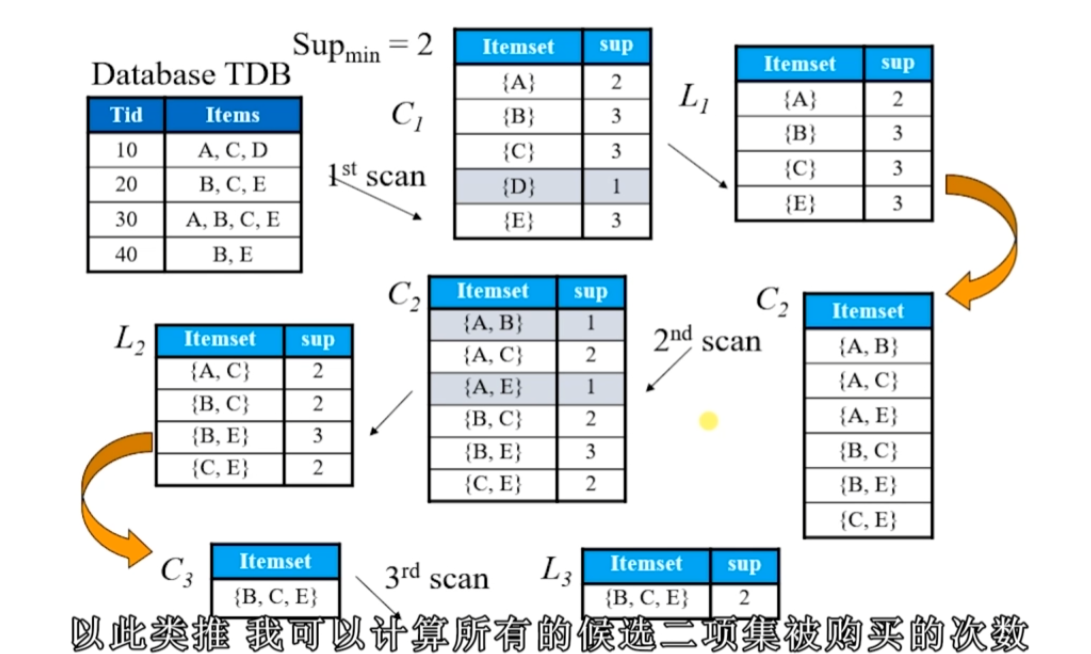
*關聯規則的基礎演演算法是如何工作的?
①尋找頻繁項集:找出支援度大於等於閾值的項集
②生成關聯規則:找出置信度大於等於閾值的關聯規則
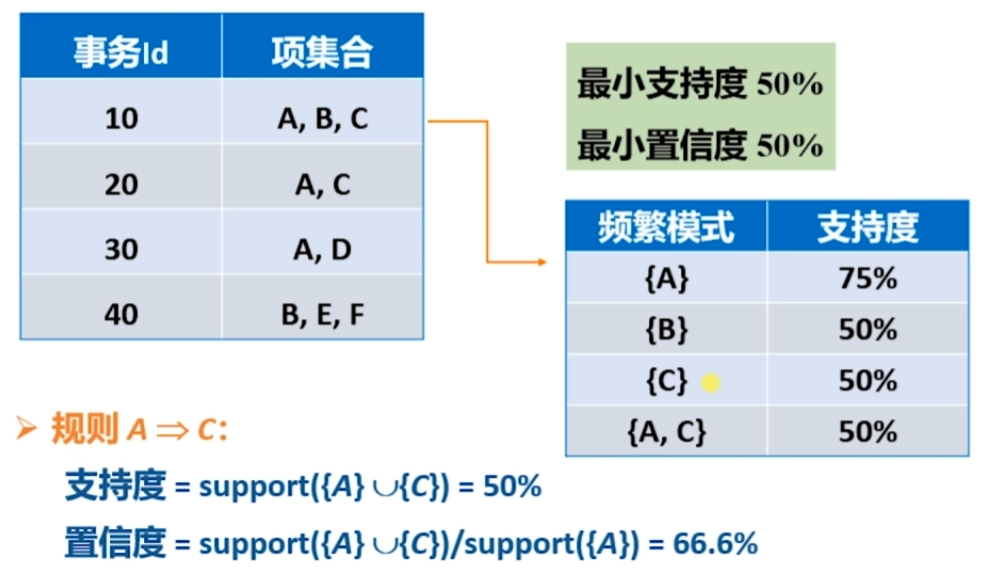
*什麼叫做支援度和置信度?
支援度:包含特定項集的事務的個數與總事務個數之比
置信度:確定Y在包含X的事務中出現的頻繁程度。理解為一種條件概率,在X->Y的蘊含規則下,選擇包含X的項集中,Y出現的概率
*Apriori演演算法的先驗原理是什麼?
如果一個項集是頻繁的,則他的所有子集也是頻繁的;
如果一個項集是非頻繁的,則他的超集也是非頻繁的。
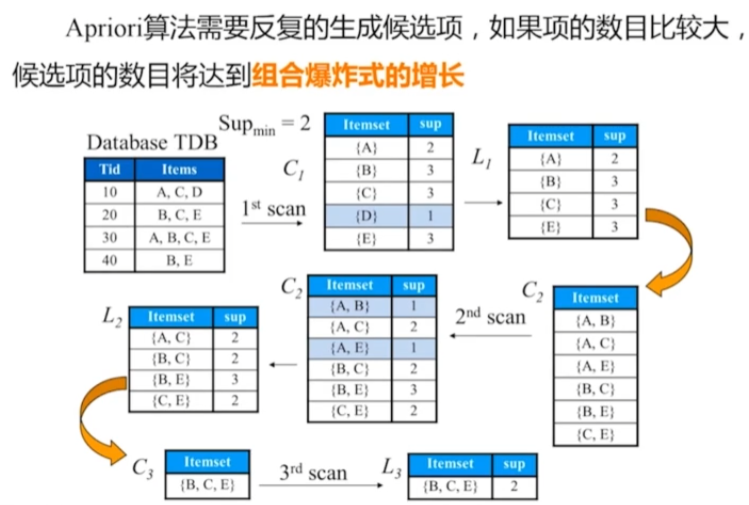
*Apriori計算題

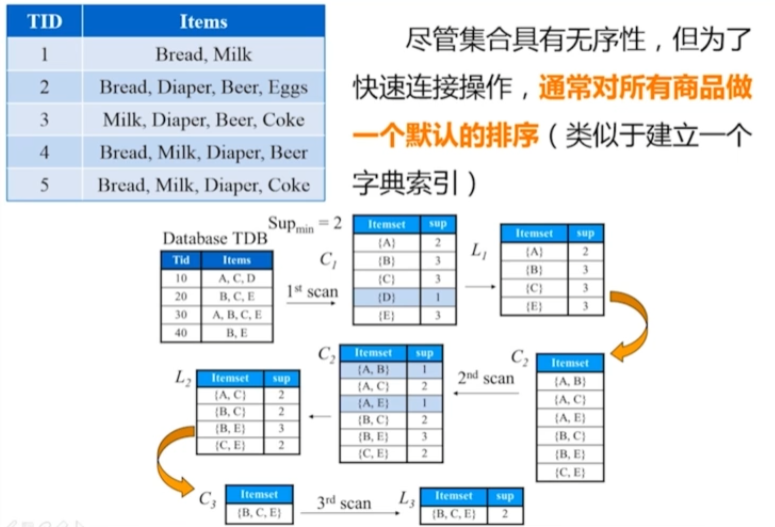
Apriori-項的字典序
Apriori-項的連線
降低候選項的生成。
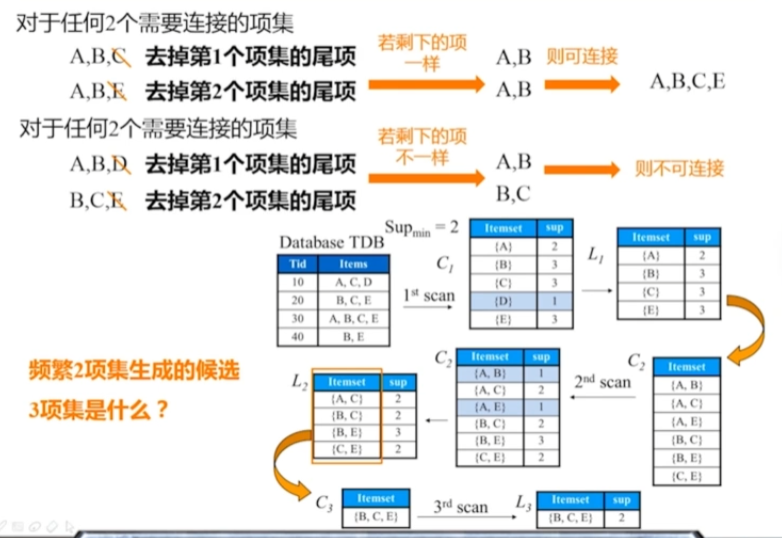
Apriori特點
- 多次掃描資料庫
- 候選項規模龐大
- 計算支援度開銷大
FPGrowth 模式增長樹

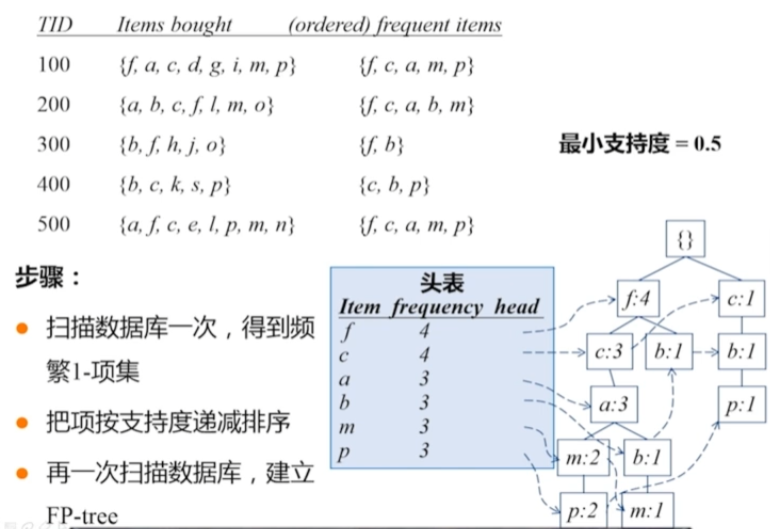
生成條件模式

特點

產生關聯規則


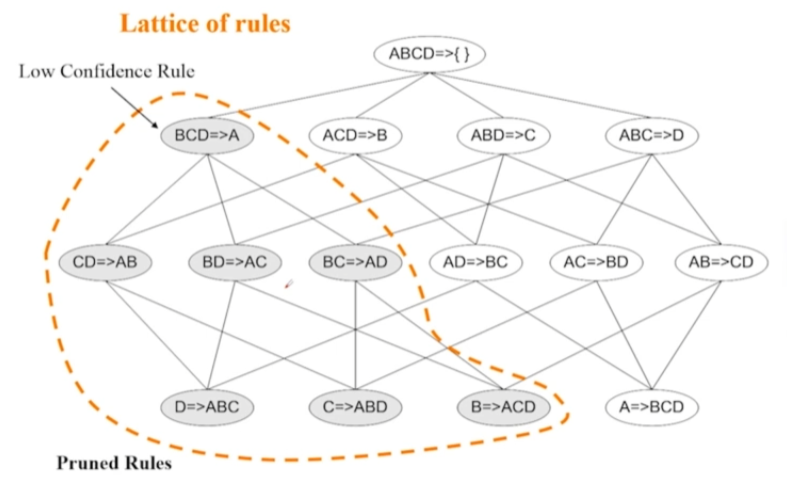
評價關聯規則
