3D視覺演演算法初學概述
3D 視覺演演算法包括很多內容,此文僅當作入門瞭解些概念和知識概括。
背景知識
3D影象描述有多種方法,常見的如下:
- 點雲
- 網格(meshes)
- 基於檢視的描述
- 深度影象(depth images)
RGB-D相機
一般普通的相機拍出來的影象,其每個畫素座標(x, y)可以獲得三種顏色屬性(R, G, B)。但在 RGB-D 影象中,每個(x, y)座標將對應於四個屬性(深度 D,R,G,B)。
一,基於3DMM的三維人臉重建技術概述
1.1,3D 人臉重建概述
3D 人臉重建定義:從一張或多張2D影象中重建出人臉的3D模型。數學表示式:
\(M = (S,T)\)
其中 S 表示人臉 3D 座標形狀向量(shape-vector),T 表示對應點的紋理資訊向量(texture-vector)。
3D 人臉重建演演算法分類:
1.2,初版 3DMM
1999 年論文 《A Morphable Model For The Synthesis Of 3D Faces》提出三維形變模型(3DMM),三維形變模型建立在三維人臉資料庫的基礎上,以人臉形狀和人臉紋理統計為約束,同時考慮到了人臉的姿態和光照因素的影響,因而生成的三維人臉模型精度高。每一個人臉模型都由相應的形狀向量 \(S_i\) 和 \(T_i\)組成,其定義如下:
\(S_{newModel} = \bar{S} + \sum_{i=1}^{m-1} \alpha_{i} s_{i}\)
\(T_{newModel} = \bar{T} + \sum_{i=1}^{m-1} bata_{i} t_{i}\)
其中 \(\bar{S}\) 表示平均臉部形狀模型,\(s_i\)表示 shape 的 PCA 部分(按照特徵值降序排列的協方差陣的特徵向量),\(\alpha_i\)表示對應形狀係數;紋理模型符號定義類似。通過調整形狀、紋理係數係數可生成不同的人臉 3D 模型。
二,視覺SLAM演演算法基礎概述
SLAM問題的本質:對運動主體自身和周圍環境空間不確定性的估計。為了解決SLAM問題,我們需要狀 態估計理論,把定位和建圖的不確定性表達出來,然後採用濾波器或非線性優化,估計狀態的均值和不確定性(方差)。
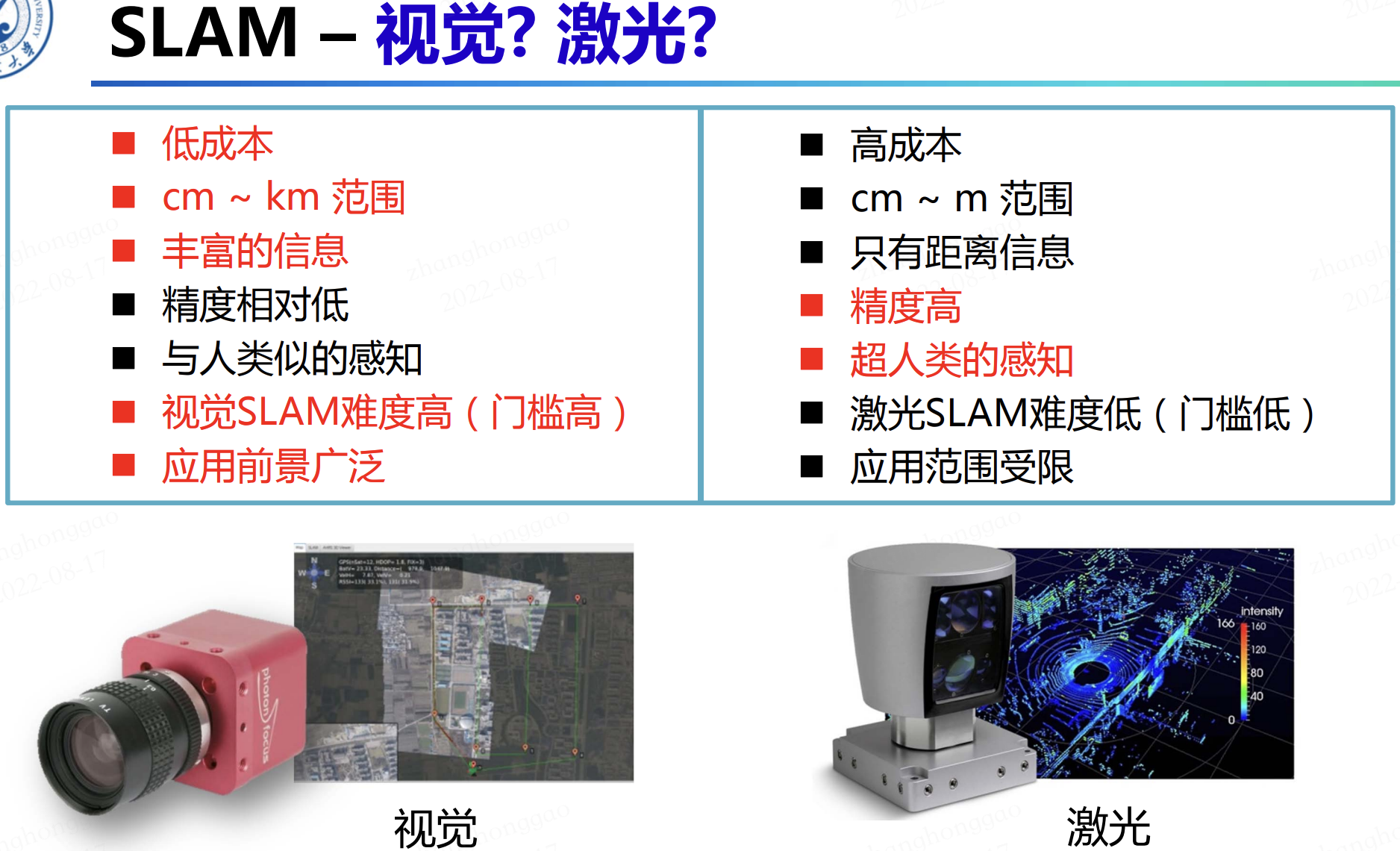
SLAM 是Simultaneous Localization and Mapping的縮寫,中文譯作「同時定位與地圖構建」。它是指搭載特定感測器(單目、雙目、RGB-D相機、Lidar)的主體,在沒有環境先驗資訊的情況下,在運動過程中建立環境的模型,同時估計自己的運動。如果這裡的感測器主要為相機,那就稱為「視覺SLAM」;如果感測器位鐳射,則為鐳射 SLAM,兩者對比如下:
SLAM 主要解決定位和地圖構建兩個問題。視覺 SLAM 流程圖如下:
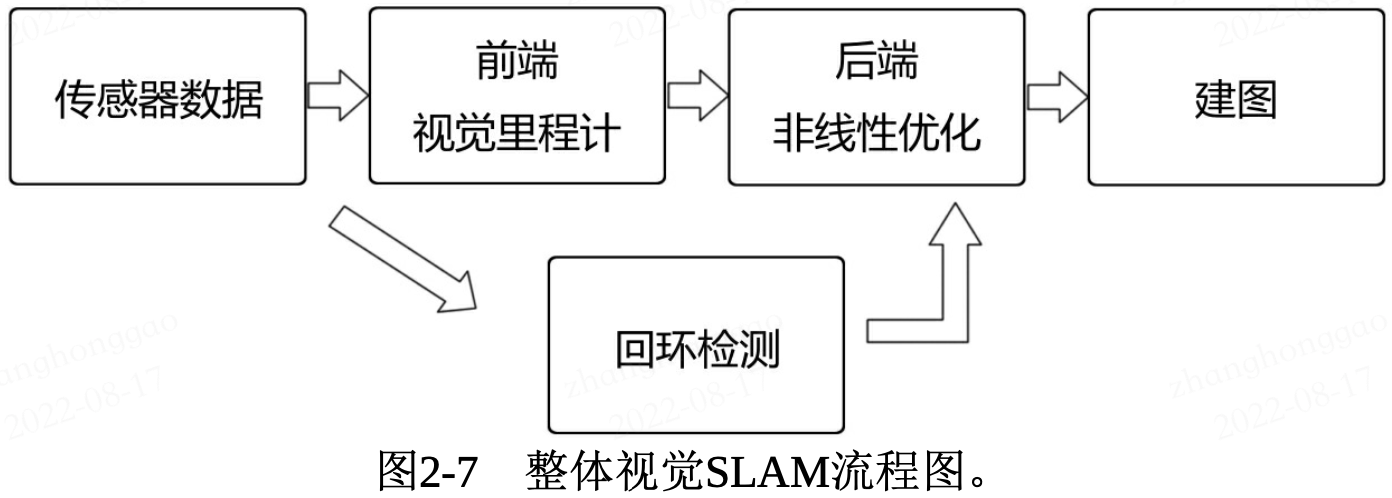
整個視覺 SLAM 流程包括以下幾個步驟:
- 感測器資訊讀取。視覺 SLAM 中主要指攝像頭影象資料讀取與預處理。
- 視覺里程計(
Visual Odometry,VO)。視覺里程計的任務是估算相鄰影象間相機的運動,以及區域性地圖的樣子。VO又稱為前端 (Front End)。 - 後端優化(
Optimization)。後端接受不同時刻視覺里程計測量的相機位姿,以及迴環檢測的資訊,對它們進行優化,得到全域性一致的軌跡和地圖。由於接在VO之後,又稱為後端(Back End)。 - **迴環檢測 **(
Loop Closing)。迴環檢測判斷機器人是否到達過先前的位置。如果檢測到迴環,它會把資訊提供給後端進行處理。 - 建圖(
Mapping)。它根據估計的軌跡,建立與任務要求對應的地圖。
2.1,視覺里程計
視覺里程計 VO 目的是通過相鄰幀間的影象估計相機運動,並恢復場景的空間結構。其中為了定量地估計相機運動,必須先了解相機與空間點的幾何關係。同時,僅通過視覺里程計來估計軌跡,將不可避免地出現累積漂移 (Accumulating Drift),即每次估計都有誤差的情況下,先前時刻的誤差將會傳遞到下一個時刻,導致經過一段時間累積之後,估計的軌跡將不再準確,如下圖所示。
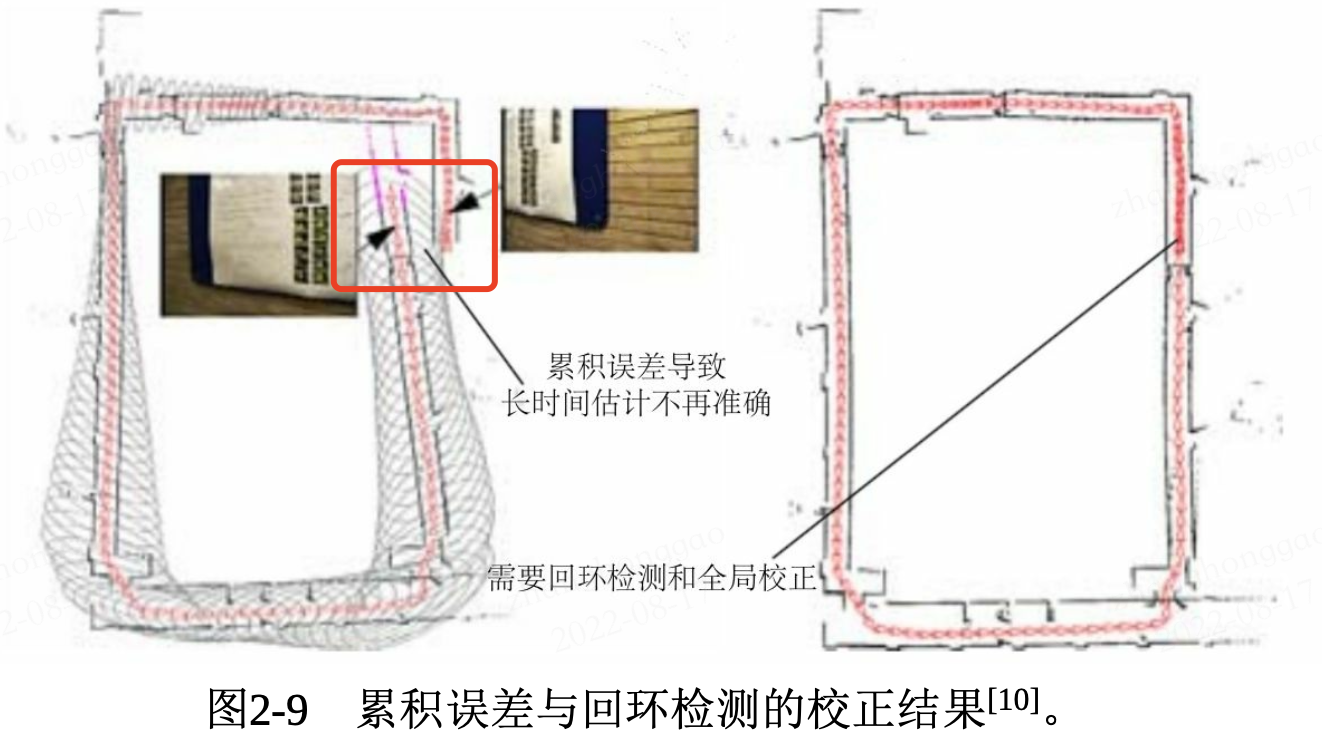
2.2,後端優化
概述性的說,後端優化主要目是為了處理 SLAM 過程中噪聲的問題。後端優化要考慮的問題,就是如何從這些帶有噪聲的資料中估計整 個系統的狀態,以及這個狀態估計的不確定性有多大—這稱為最大後 驗概率估計(Maximum-a-Posteriori,MAP)。這裡的狀態既包括機器 人自身的軌跡,也包含地圖。
前端與後端的關係:前端給後端提供待優化的資料,以及這些資料的初始值。後端只關心資料的優化過程,不關係這些資料來源於什麼感測器。因此在視覺 SLAM 中,前端和計算機視覺研究領域更為相關,比如影象的特徵提取與匹配等,後端則主要是濾波與非線性優化演演算法。
2.3,迴環檢測
迴環檢測(又稱閉環檢測 Loop Closure Detection),主要目的是為了解決位置估計隨時間漂移的問題。
可以通過影象相似性來完成迴環檢測。在檢測到迴環之後,我們會把「A與B是同一個點」這樣的資訊告訴 後端優化演演算法。然後,後端根據這些新的資訊,把軌跡和地圖調整到符合迴環檢測結果的樣子。這樣,如果我們有充分而且正確的迴環檢測, 就可以消除累積誤差,得到全域性一致的軌跡和地圖。
2.4,建圖
建圖(Mapping)是指構建地圖的過程。這裡的地圖是對環境的描述,但這個描述並不是固定的,需要視SLAM 的應用而定。
建圖技術,根據用途的不同,可以分為稀疏重建和稠密重建,稀疏重建通常是重建一些影象特徵點的三維座標,稀疏重建主要用於定位。稠密建圖又稱三維重建,是對整個影象或影象中絕大部分畫素進行重建,在導航、避障等方面起著舉足輕重的作用。
三,三維點雲語意分割和範例分割綜述
3.1,三維資料的表示方法
三維影象 = 普通的 RGB 三通道彩色影象 + Depth Map。
三維資料有四種表示方法,分別是 point cloud(點雲),Mesh(網格),Voxel(體素)以及 Multi-View(多角度圖片)。由此也衍生出了對應的三維資料語意和範例分割的演演算法,但主要是針對 point cloud 的演演算法越來越多。三維資料集有 ShapeNet、S3DIS、ModelNet40 等。
3.1.1,點雲定義
點雲簡單來說就是一堆三維點的集合,必須包括各個點的三維座標資訊,其他資訊比如各個點的法向量、顏色、分類值、強度值、時間等均是可選。
點雲在組成特點上分為兩種,一種是有序點雲,一種是無序點雲。
- 有序點雲:一般由深度圖還原的點雲,有序點雲按照圖方陣一行一行的,從左上角到右下角排列,當然其中有一些無效點因為。有序點雲按順序排列,可以很容易的找到它的相鄰點資訊。有序點雲在某些處理的時候還是很便利的,但是很多情況下是無法獲取有序點雲的。
- 無序點雲:無序點雲就是其中的點的集合,點排列之間沒有任何順序,點的順序交換後沒有任何影響。是比較普遍的點雲形式,有序點雲也可看做無序點雲來處理。
3.1.2,點雲的屬性:
- 空間解析度、點位精度、表面法向量等。
- 點雲可以表達物體的空間輪廓和具體位置,我們能看到街道、房屋的形狀,物體距離攝像機的距離也是可知的;其次,點雲本身和視角無關,可以任意旋轉,從不同角度和方向觀察一個點雲,而且不同的點雲只要在同一個座標系下就可以直接融合。
3.1.3,點雲獲取
點雲一般需要通過三維成像感測器獲得,比如雙目相機、RGB-D相機和 LiDAR鐳射感測器。
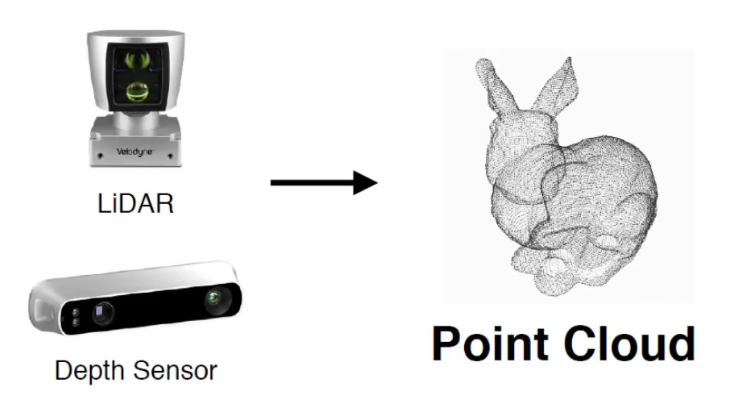
根據鐳射測量原理得到的點雲,包括三維座標(XYZ)和鐳射反射強度(Intensity),強度資訊與目標的表面材質、粗糙度、入射角方向以及儀器的發射能量、鐳射波長有關。根據攝影測量原理得到的點雲,包括三維座標(XYZ)和顏色資訊(RGB)。結合鐳射測量和攝影測量原理得到點雲,包括三維座標(XYZ)、鐳射反射強度(Intensity)和顏色資訊(RGB)。
3.1.4,點雲端儲存格式
點雲的檔案格式可以有很多種,包括 .xyz,npy,ply,obj,off 等(mesh 可以通過泊松取樣等方式轉化成點雲)。對於單個點雲,如果你使用np.loadtxt得到的實際上就是一個維度為 的張量,num_channels一般為 3,表示點雲的三維座標。
- pts 點雲檔案格式是最簡便的點雲格式,直接按
XYZ順序儲存點雲資料, 可以是整型或者浮點型。

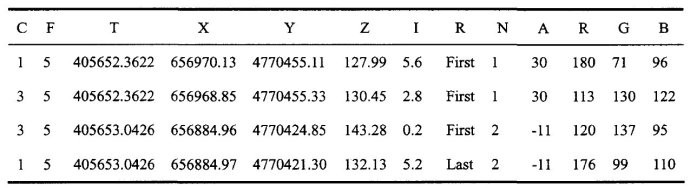
- LAS 是鐳射雷達資料(LiDAR),儲存格式比 pts 複雜,旨在提供一種開放的格式標準,允許不同的硬體和軟體提供商輸出可互操作的統一格式。LAS 格式點雲截圖,其中 C:class(所屬類),F:flight(航線號),T:time(GPS 時間),I:intensity(回波強度),R:return(第幾次回波),N:number of return(回波次數),A:scan angle(掃描角),RGB:red green blue(RGB 顏色值)。
- .xyz 一種文字格式,前面 3 個數位表示點座標,後面 3 個數位是點的法向量,數位間以空格分隔。

- .pcap 是一種通用的資料流格式,現在流行的 Velodyne 公司出品的鐳射雷達預設採集資料檔案格式。它是一種二進位制檔案

3.1.5,三維點雲的多種表示方法
三維點雲除了原始點雲表示還要網格 (Mesh) 表示和體素表示,如下圖所示:

3.2,基於點雲的分類和檢測
背景:相比於影象資料,點雲不直接包含空間結構,因此點雲的深度模型必須解決三個主要問題:
- 如何從稀疏的點雲找到高資訊密度的表示。
- 如何構建一個網路滿足必要的限制如 size-variance 和 permutation-invariance。
- 如何以較低的時間和計算資源消耗處理大量資料。
對點雲的分類通常稱為三維形狀分類。與影象分類模型相似,三維形狀分類模型通常是先通過聚合編碼器生成全域性嵌入,然後將嵌入通過幾個完全連通的層來獲得最終結果。基於點雲聚合方法,分類模型大致可分為兩類: 基於投影的方法和基於點的方法。
3.3,基於點雲的語意分割
基於點雲的語意分割方法大致可分為基於投影的方法和基於點的方法。
3.3.1,PointNet 網路
PointNet 是第一個可以直接處理原始三維點雲的深度神經網路,簡單來說 PointNet 所作的事情就是對點雲做特徵學習,並將學習到的特徵去做不同的應用:分類(shape-wise feature)、分割(point-wise feature)等。
無論是分類還是分割,本質上都還是分類任務,只是粒度不同罷了。因此損失函數 loss 一定有有監督分類任務中常用的交叉熵 loss,另外 loss 還有之前 alignment network(用於實現網路對於仿射變換、剛體變換等變換的無關性)的約束 loss,也就是上面的 mat_diff_loss 。
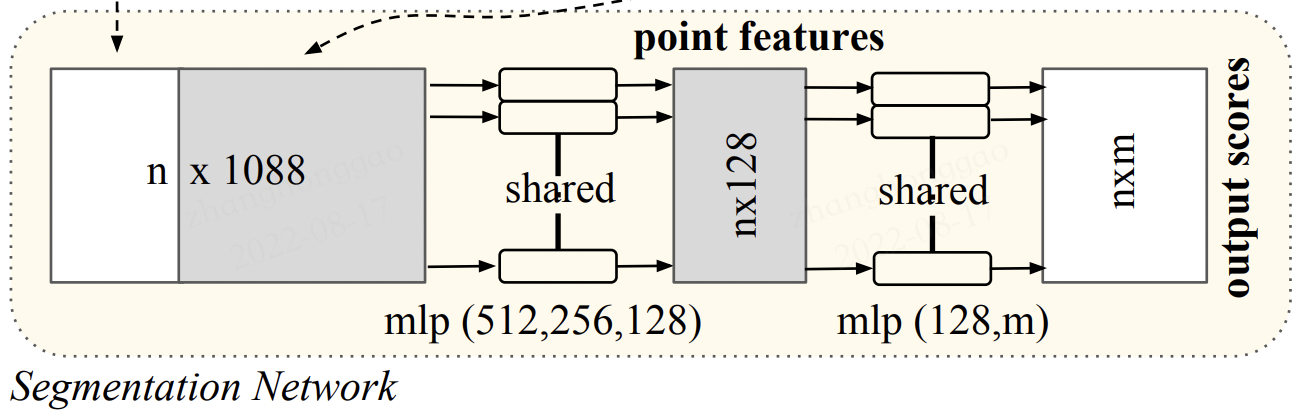
PointNet 網路結構如下所示:
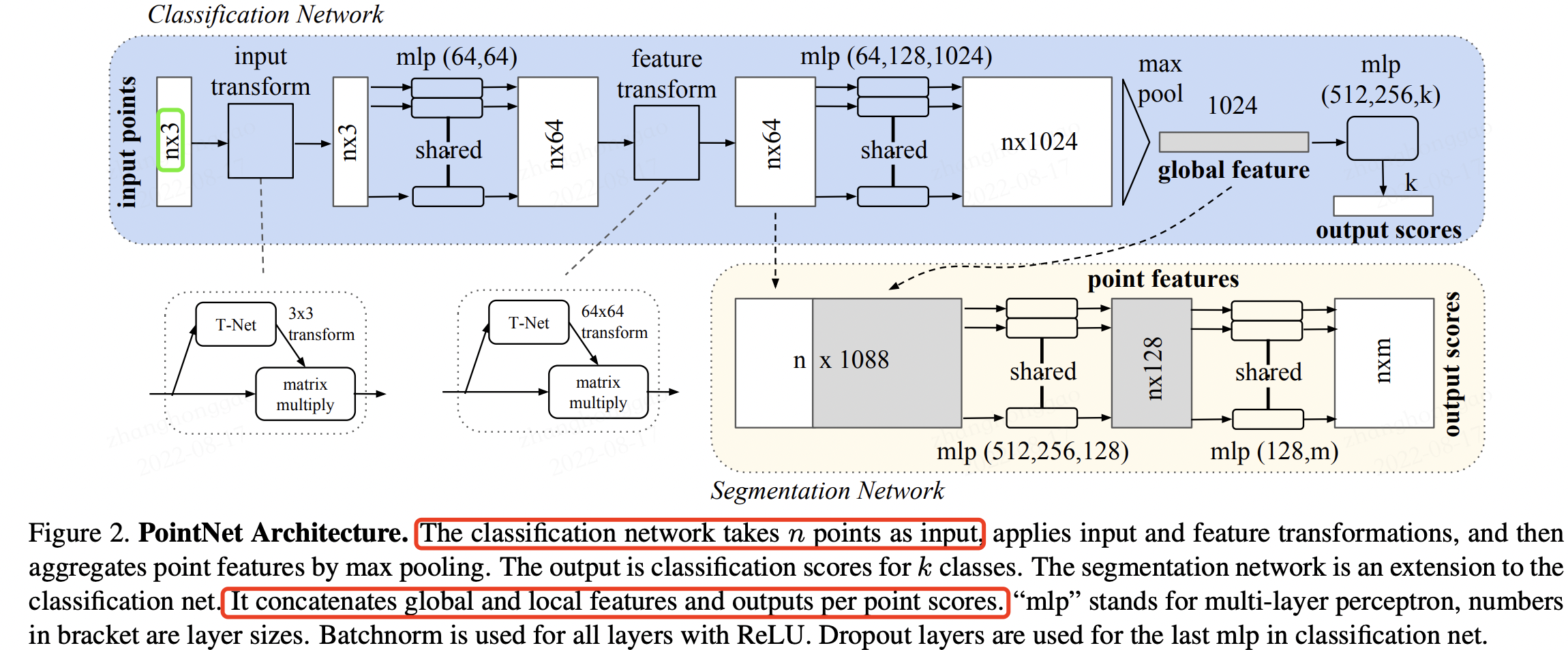
其大致的運算流程如下(來自【3D視覺】PointNet和PointNet++):
- 輸入為一幀的全部點雲資料的集合,表示為一個 nx3 的 2d tensor,其中 n 代表點雲數量,3 對應 xyz 座標。
- 輸入資料先通過和一個
T-Net學習到的轉換矩陣相乘來對齊,保證了模型的對特定空間轉換的不變性。 - 通過多次 mlp 對各點雲資料進行特徵提取後,再用一個 T-Net 對特徵進行對齊。
- 在特徵的各個維度上執行 maxpooling 操作來得到最終的全域性特徵。
- 對分類任務,將全域性特徵通過 mlp 來預測最後的分類分數。
- 對分割任務,將全域性特徵和之前學習到的各點雲的區域性特徵進行串聯,再通過 mlp 得到每個資料點的分類結果。
分割任務針對於每一個點做分類,在下面的圖中,把全域性的特徵複製成 n 份然後與之前的 64 維特徵進行拼接,然後接著做一個 mlp,最後的輸出 nxm 就是每一個點的分類結果。