有向圖的拓撲排序——DFS
在有向圖的拓撲排序——BFS這篇文章中,介紹了有向圖的拓撲排序的定義以及使用廣度優先搜尋(BFS)對有向圖進行拓撲排序的方法,這裡再介紹另一種方法:深度優先搜尋(DFS)。
演演算法
考慮下面這張圖:
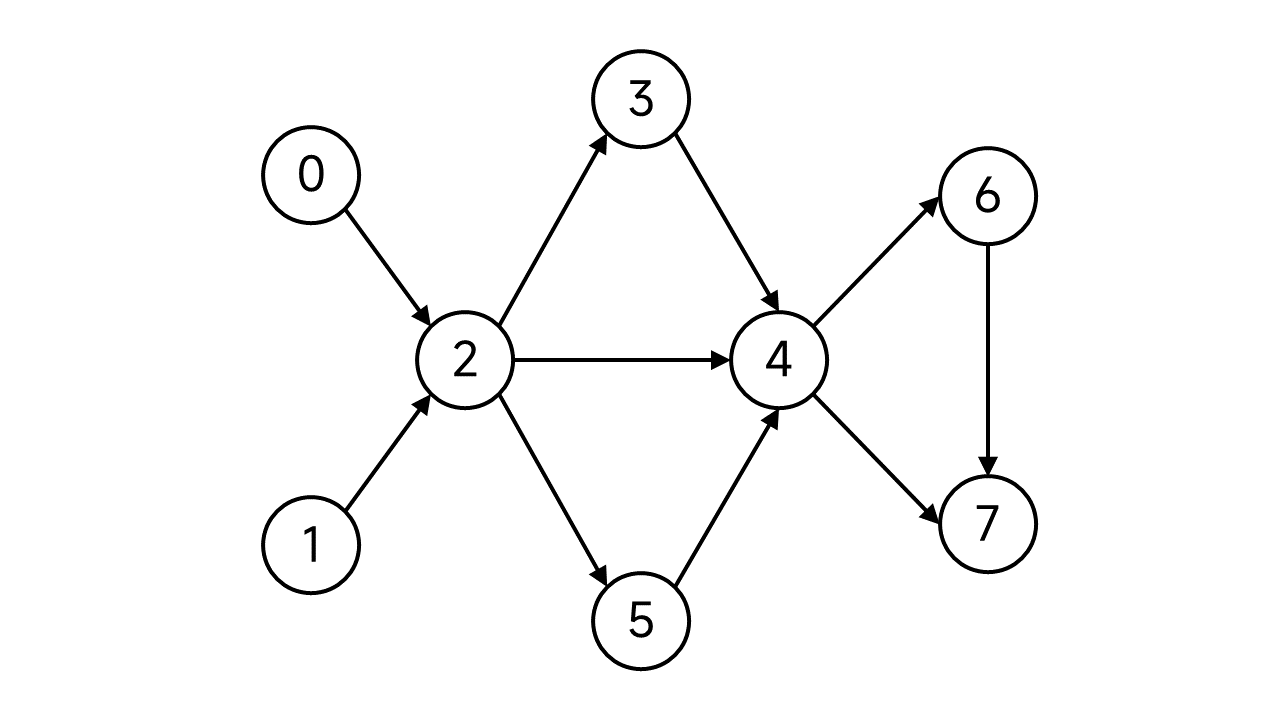
首先,我們需要維護一個棧,用來存放DFS到的節點。另外規定每個節點有兩個狀態:未存取(這裡用藍綠色表示)、已存取(這裡用黑色表示)。
任選一個節點開始DFS,比如這裡就從0開始吧。
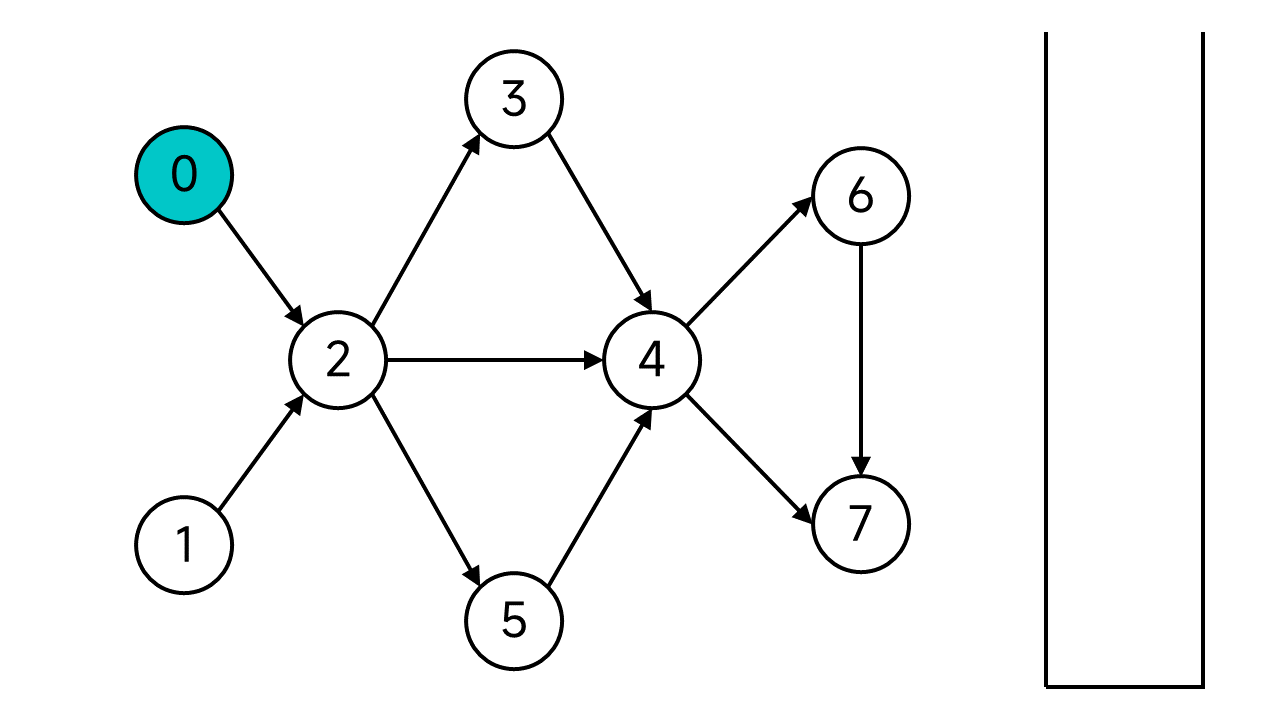
首先將節點0的狀態設為已存取,然後節點0的鄰居(節點0的出邊指向的節點)共有1個:節點2,它是未存取狀態,於是順下去存取節點2。
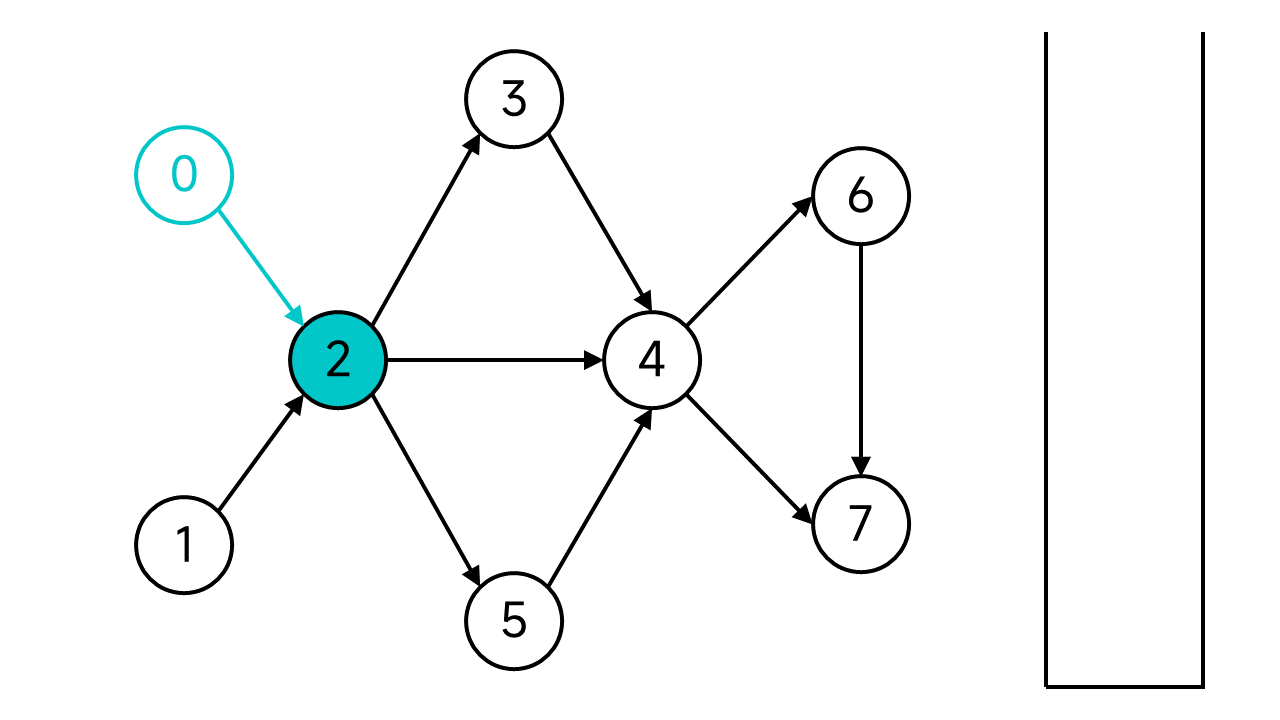
節點2的狀態也設為已存取。節點2有3個鄰居:3、4、5,都是未存取狀態,不妨從3開始。一直這樣存取下去,直到存取到沒有出邊的節點7。
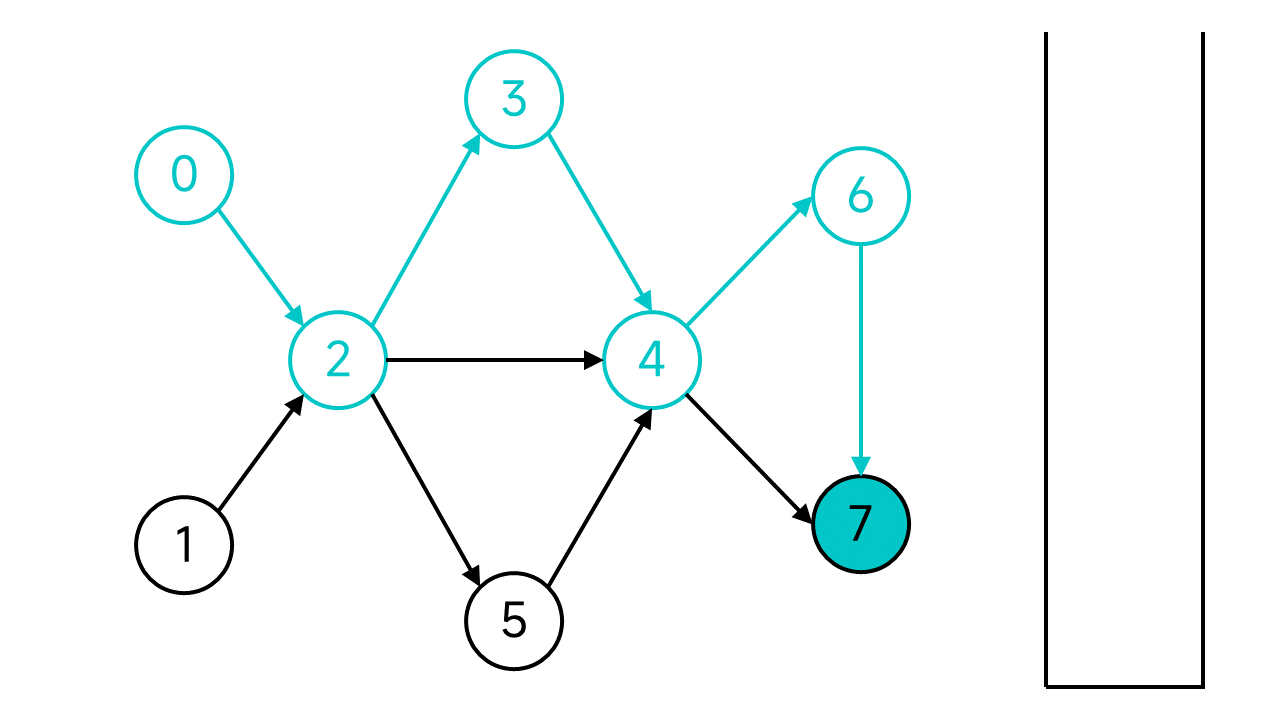
節點7沒有出邊了,這時候就將節點7入棧。
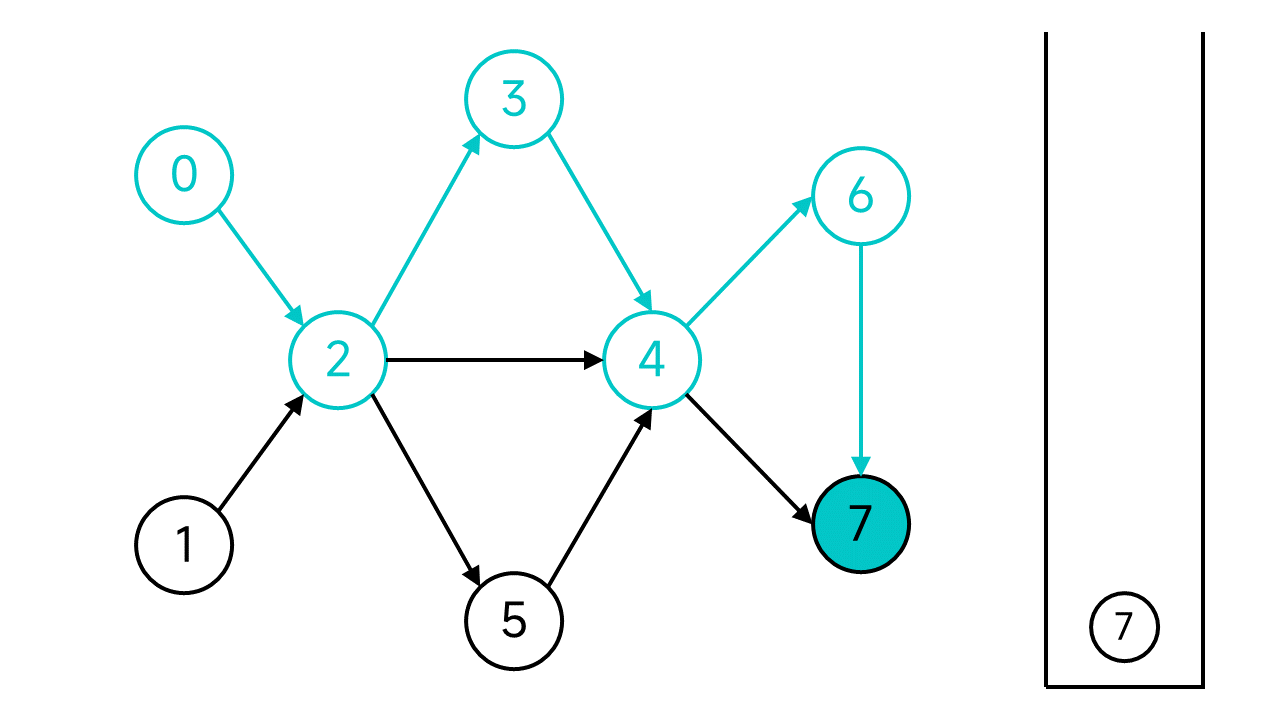
退回到節點6,雖然6還有鄰居,但是唯一的鄰居節點7是已存取狀態,也入棧。再次退回,節點4的兩個鄰居也都已存取,依舊入棧並後退。以此類推,退回到節點2。
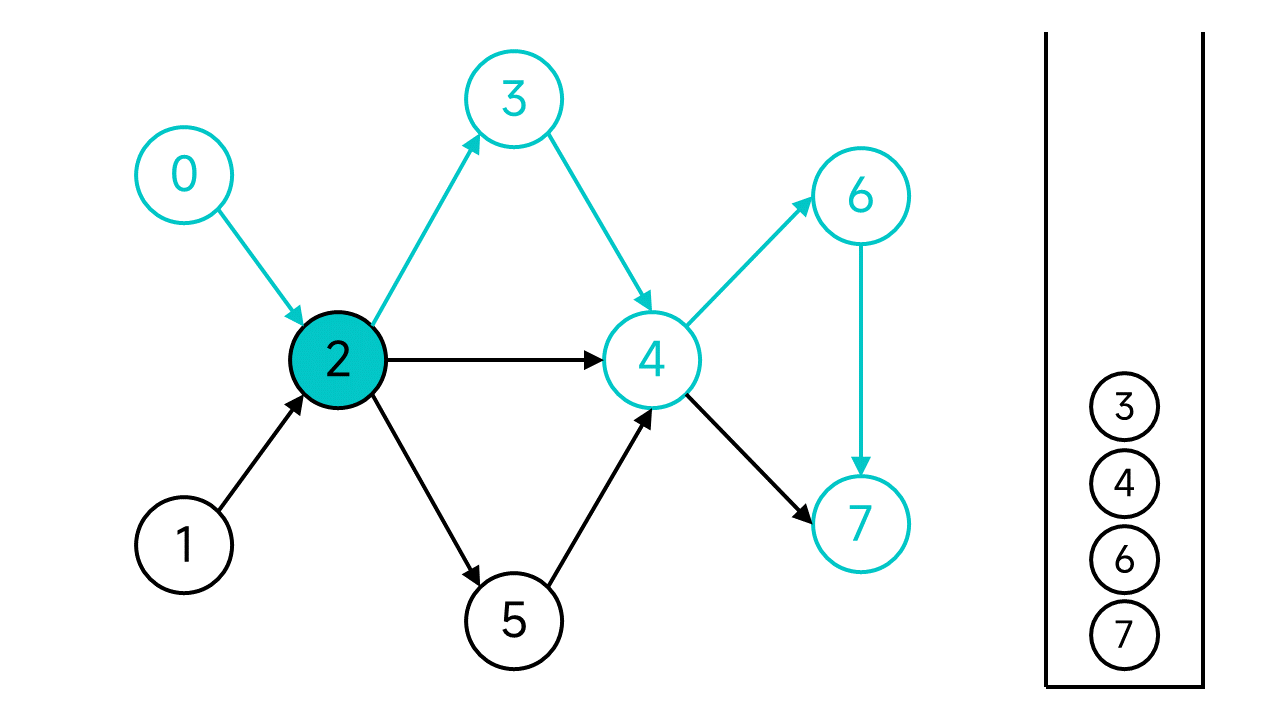
節點2有3個鄰居,其中節點3和4已存取,但是節點5還未存取,存取節點5。
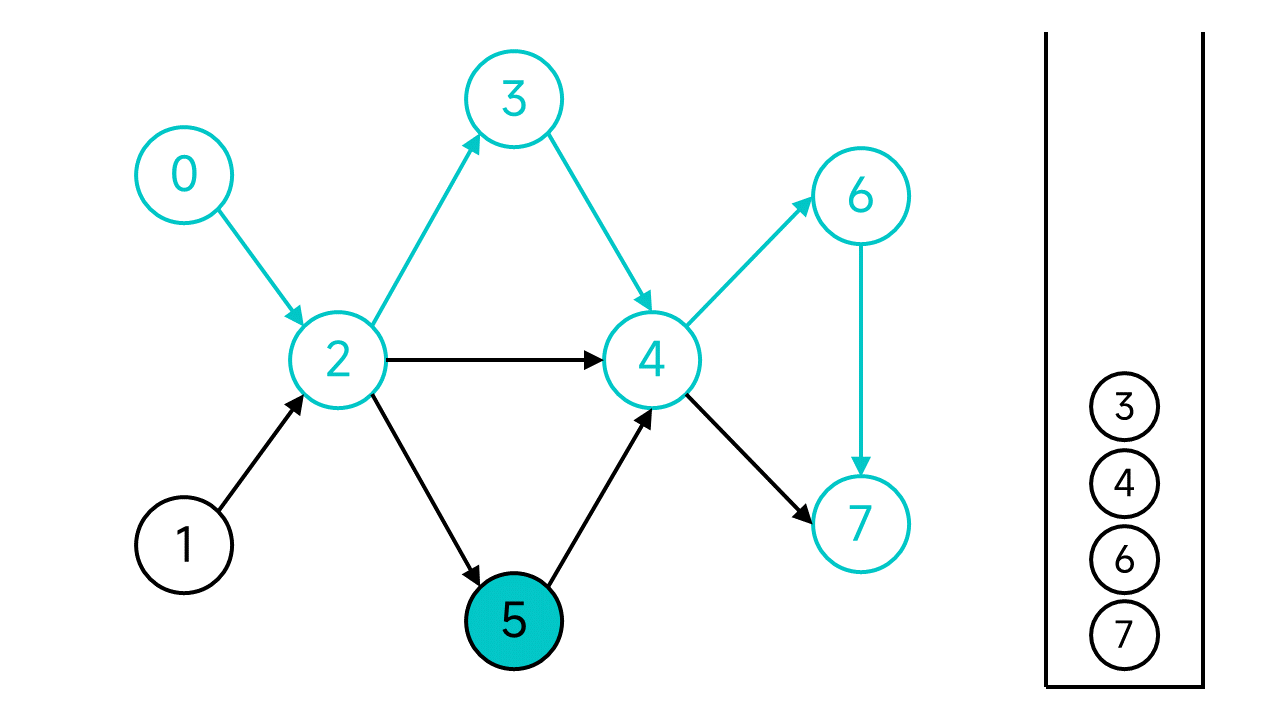
接下來的步驟是一樣的,不再贅述了,直接退回到節點0並將0入棧。
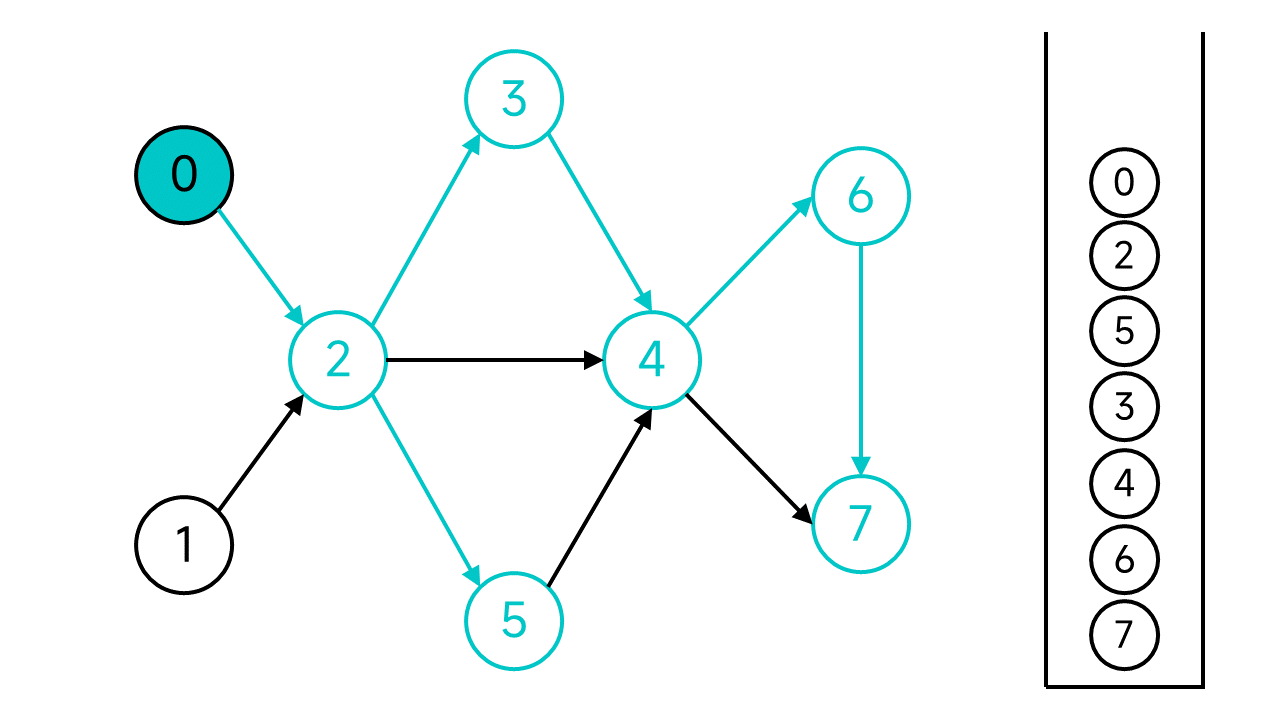
現在,從節點0開始的DFS宣告結束,但是圖中還有未存取的節點:節點1,從節點1繼續開始DFS。
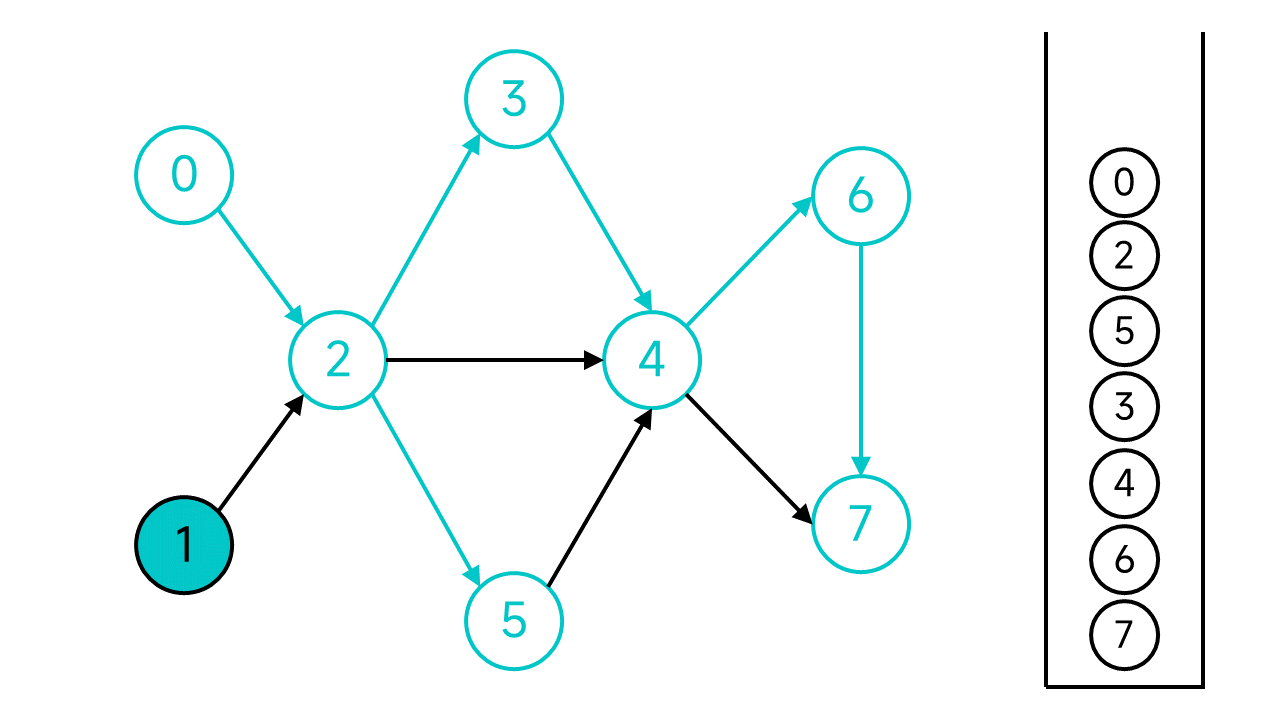
節點1的鄰居節點2已經存取過了,直接將節點1入棧。
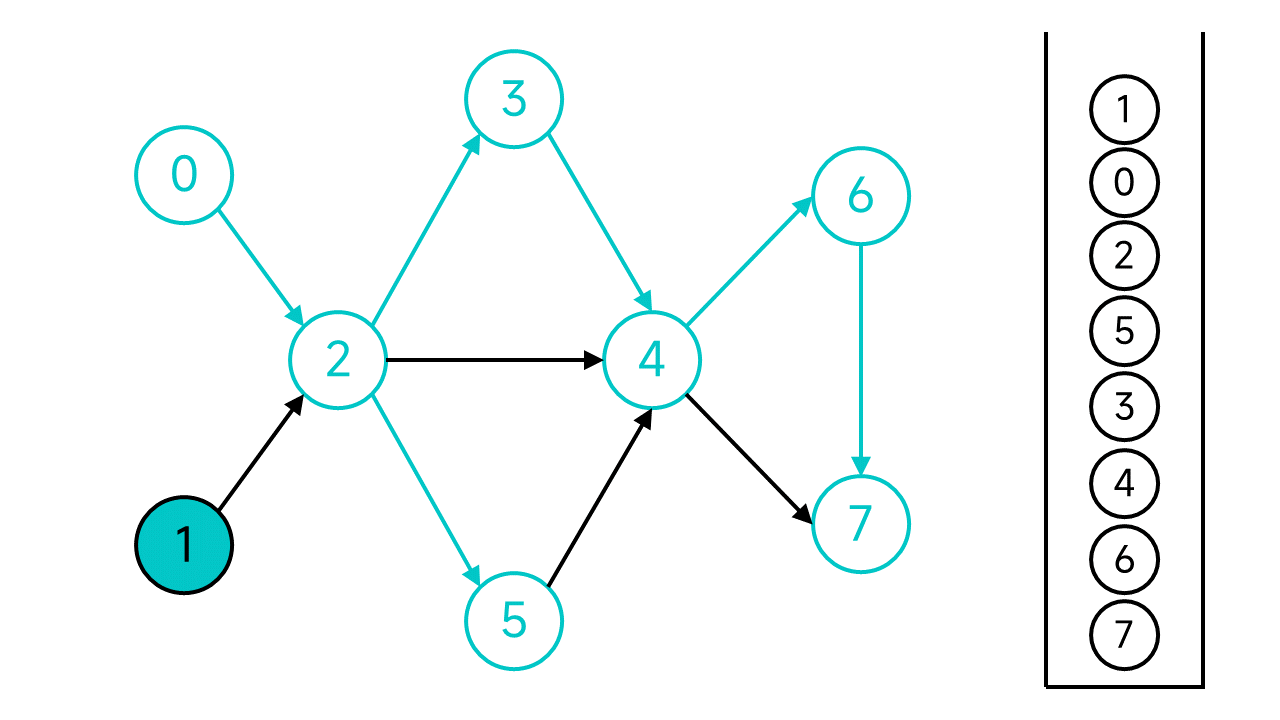
至此,整個DFS過程宣告結束。從棧頂到棧底的節點序列1 0 2 5 3 4 6 7就是整個圖的一個拓撲排序序列。
實現
這裡同樣使用型別別名node_t代表節點序號unsigned long long:
using node_t = unsigned long long;
同樣使用鄰接表來儲存圖結構,整個圖的定義如下:
class Graph {
unsigned long long n;
vector<vector<node_t>> adj;
protected:
void dfs(node_t cur, vector<bool> &visited, stack<node_t> &nodeStack);
public:
Graph(initializer_list<initializer_list<node_t>> list) : n(list.size()), adj({}) {
for (auto &l : list) {
adj.emplace_back(l);
}
}
vector<node_t> toposortDfs();
};
DFS
函數dfs的引數及說明如下:
cur:當前存取的節點。visited:存放各個節點狀態的陣列,false表示未存取,true表示已存取。初始化為全為false。nodeStack:存放節點的棧。
整個過程如下:
- 首先,我們需要將當前節點的狀態設為已存取:
visited[cur] = true;
- 依次檢查當前節點的所有鄰居的狀態:
for (node_t neighbor: adj[cur]) {
// ...
}
- 如果某個節點已存取,則跳過。
if (visited[neighbor]) continue;
- 否則,遞迴的對該節點進行DFS:
dfs(neighbor, visited, nodeStack);
- 所有鄰居檢查完後,就將該節點入棧:
nodeStack.push(cur);
整個dfs函數的程式碼如下:
void Graph::dfs(node_t cur, vector<bool> &visited, stack<node_t> &nodeStack) {
visited[cur] = true;
for (node_t neighbor: adj[cur]) {
if (visited[neighbor]) continue;
dfs(neighbor, visited, nodeStack);
}
nodeStack.push(cur);
}
拓撲排序
我們需要初始化3個資料結構:
sort:存放拓撲排序序列的陣列。visited:見上文。nodeStack:見上文。
vector<node_t> sort;
vector<bool> visited(n, false);
stack<node_t> nodeStack;
整個過程如下:
- 依次檢查每個節點的狀態,如果未存取,則從該節點開始進行DFS:
for (node_t node = 0; node < n; ++node) {
if (visited[node]) continue;
dfs(node, visited, nodeStack);
}
- 此時
nodeStack已經儲存了整個拓撲排序序列,我們只需要轉移到sort陣列並返回即可:
while (!nodeStack.empty()) {
sort.push_back(nodeStack.top());
nodeStack.pop();
}
return sort;
整個程式碼如下:
vector<node_t> Graph::toposortDfs() {
vector<node_t> sort;
vector<bool> visited(n, false);
stack<node_t> nodeStack;
for (node_t node = 0; node < n; ++node) {
if (visited[node]) continue;
dfs(node, visited, nodeStack);
}
while (!nodeStack.empty()) {
sort.push_back(nodeStack.top());
nodeStack.pop();
}
return sort;
}
測試
程式碼:
int main() {
Graph graph{{2},
{2},
{3, 4, 5},
{4},
{6, 7},
{4},
{7},
{}};
auto sort = graph.toposortDfs();
cout << "The topology sort sequence is:\n";
for (const auto &node: sort) {
cout << node << ' ';
}
return 0;
}
輸出:
The topology sort sequence is:
1 0 2 5 3 4 6 7
複雜度分析
- 時間複雜度:\(O(n+e)\),\(n\)為節點總數,\(e\)為邊的總數。其中DFS的時間複雜度為\(O(n+e)\)。
- 空間複雜度:\(O(n)\)(鄰接表的空間複雜度為\(O(n+e)\),不計入在內),其中維護
visited陣列和nodeStack棧分別需要\(O(n)\)的額外空間。
本文來自部落格園,作者:YVVT_Real,轉載請註明原文連結:https://www.cnblogs.com/YWT-Real/p/17015184.html