終於弄明白了 RocketMQ 的儲存模型
RocketMQ 優異的效能表現,必然繞不開其優秀的儲存模型 。
這篇文章,筆者按照自己的理解 , 嘗試分析 RocketMQ 的儲存模型,希望對大家有所啟發。
1 整體概覽
首先溫習下 RocketMQ 架構。
整體架構中包含四種角色 :
-
Producer :訊息釋出的角色,Producer 通過 MQ 的負載均衡模組選擇相應的 Broker 叢集佇列進行訊息投遞,投遞的過程支援快速失敗並且低延遲。
-
Consumer :訊息消費的角色,支援以 push 推,pull 拉兩種模式對訊息進行消費。
-
NameServer :名字服務是一個非常簡單的 Topic 路由註冊中心,其角色類似 Dubbo 中的 zookeeper ,支援 Broker 的動態註冊與發現。
-
BrokerServer :Broker 主要負責訊息的儲存、投遞和查詢以及服務高可用保證 。
本文的重點在於分析 BrokerServer 的訊息儲存模型。我們先進入 broker 的檔案儲存目錄 。

訊息儲存和下面三個檔案關係非常緊密:
-
資料檔案 commitlog
訊息主體以及後設資料的儲存主體 ;
-
消費檔案 consumequeue
訊息消費佇列,引入的目的主要是提高訊息消費的效能 ;
-
索引檔案 index
索引檔案,提供了一種可以通過 key 或時間區間來查詢訊息。
RocketMQ 採用的是混合型的儲存結構,Broker 單個範例下所有的佇列共用一個資料檔案(commitlog)來儲存。
生產者傳送訊息至 Broker 端,然後 Broker 端使用同步或者非同步的方式對訊息刷盤持久化,儲存至 commitlog 檔案中。只要訊息被刷盤持久化至磁碟檔案 commitlog 中,那麼生產者傳送的訊息就不會丟失。
Broker 端的後臺服務執行緒會不停地分發請求並非同步構建 consumequeue(消費檔案)和 indexFile(索引檔案)。
2 資料檔案
RocketMQ 的訊息資料都會寫入到資料檔案中, 我們稱之為 commitlog 。
所有的訊息都會順序寫入資料檔案,當檔案寫滿了,會寫入下一個檔案。

如上圖所示,單個檔案大小預設 1G , 檔名長度為 20 位,左邊補零,剩餘為起始偏移量,比如 00000000000000000000 代表了第一個檔案,起始偏移量為 0 ,檔案大小為1 G = 1073741824。
當第一個檔案寫滿了,第二個檔案為 00000000001073741824,起始偏移量為 1073741824,以此類推。
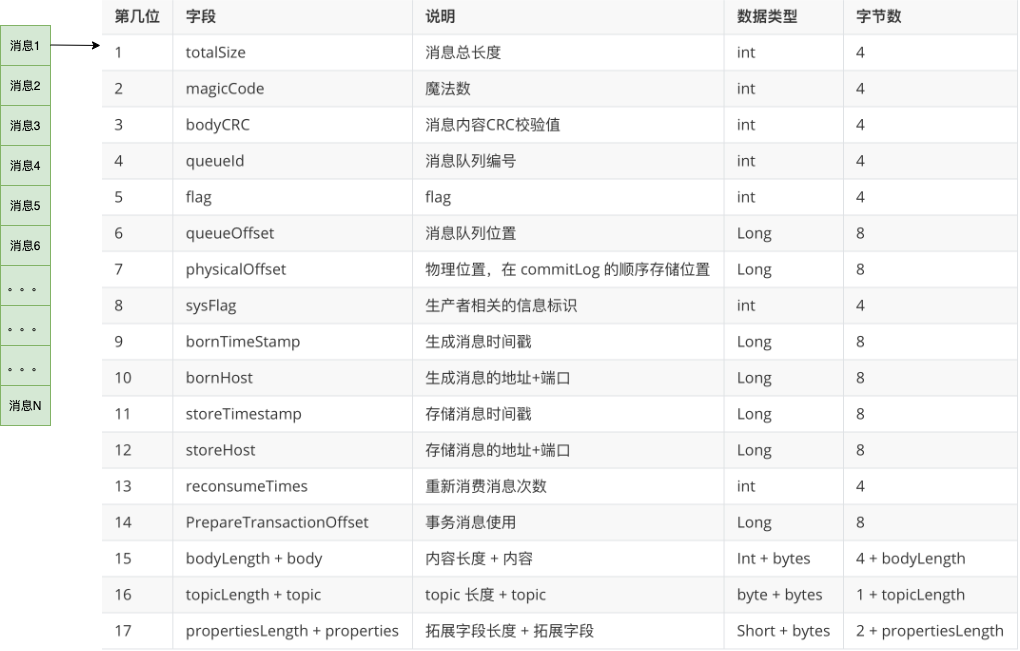
從上圖中,我們可以看到訊息是一條一條寫入到檔案,每條訊息的格式是固定的。
這樣設計有三點優勢:
-
順序寫
磁碟的存取速度相對記憶體來講並不快,一次磁碟 IO 的耗時主要取決於:尋道時間和碟片旋轉時間,提高磁碟 IO 效能最有效的方法就是:減少隨機 IO,增加順序 IO 。
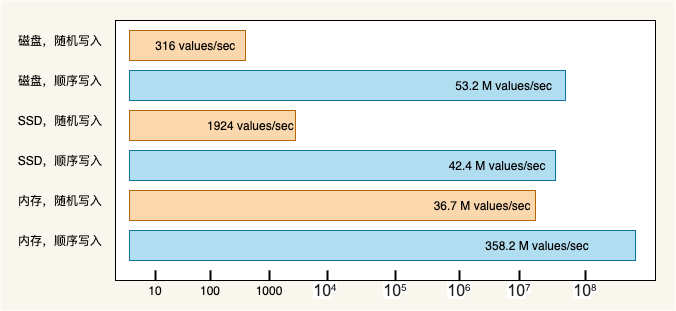
《 The Pathologies of Big Data 》這篇文章指出:記憶體隨機讀寫的速度遠遠低於磁碟順序讀寫的速度。磁碟順序寫入速度可以達到幾百兆/s,而隨機寫入速度只有幾百 KB /s,相差上千倍。
-
快速定位
因為訊息是一條一條寫入到 commitlog 檔案 ,寫入完成後,我們可以得到這條訊息的物理偏移量。
每條訊息的物理偏移量是唯一的, commitlog 檔名是遞增的,可以根據訊息的物理偏移量通過二分查詢,定位訊息位於那個檔案中,並獲取到訊息實體資料。
-
通過訊息 offsetMsgId 查詢訊息資料
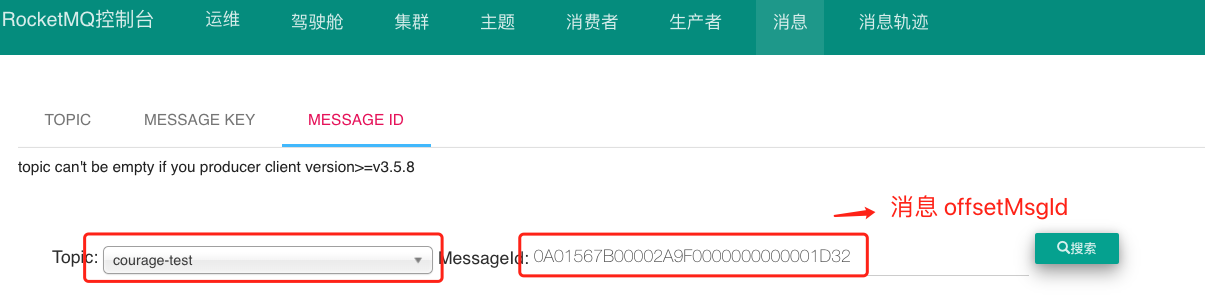
訊息 offsetMsgId 是由 Broker 伺服器端在寫入訊息時生成的 ,該訊息包含兩個部分:
-
Broker 伺服器端 ip + port 8個位元組;
-
commitlog 物理偏移量 8個位元組 。
我們可以通過訊息 offsetMsgId ,定位到 Broker 的 ip 地址 + 埠 ,傳遞物理偏移量引數 ,即可定位該訊息實體資料。
-
3 消費檔案
在介紹 consumequeue 檔案之前, 我們先溫習下訊息佇列的傳輸模型-釋出訂閱模型 , 這也是 RocketMQ 當前的傳輸模型。
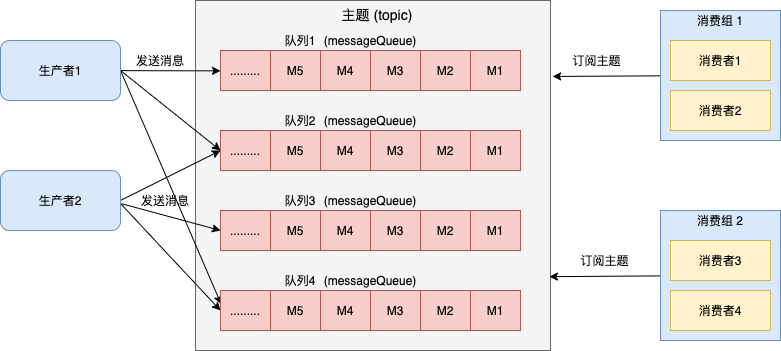
釋出訂閱模型具有如下特點:
- 消費獨立:相比佇列模型的匿名消費方式,釋出訂閱模型中消費方都會具備的身份,一般叫做訂閱組(訂閱關係),不同訂閱組之間相互獨立不會相互影響。
- 一對多通訊:基於獨立身份的設計,同一個主題內的訊息可以被多個訂閱組處理,每個訂閱組都可以拿到全量訊息。因此釋出訂閱模型可以實現一對多通訊。
因此,rocketmq 的檔案設計必須滿足釋出訂閱模型的需求。
那麼僅僅 commitlog 檔案是否可以滿足需求嗎 ?
假如有一個 consumerGroup 消費者,訂閱主題 my-mac-topic ,因為 commitlog 包含所有的訊息資料,查詢該主題下的訊息資料,需要遍歷資料檔案 commitlog , 這樣的效率是極其低下的。
進入 rocketmq 儲存目錄,顯示見下圖:
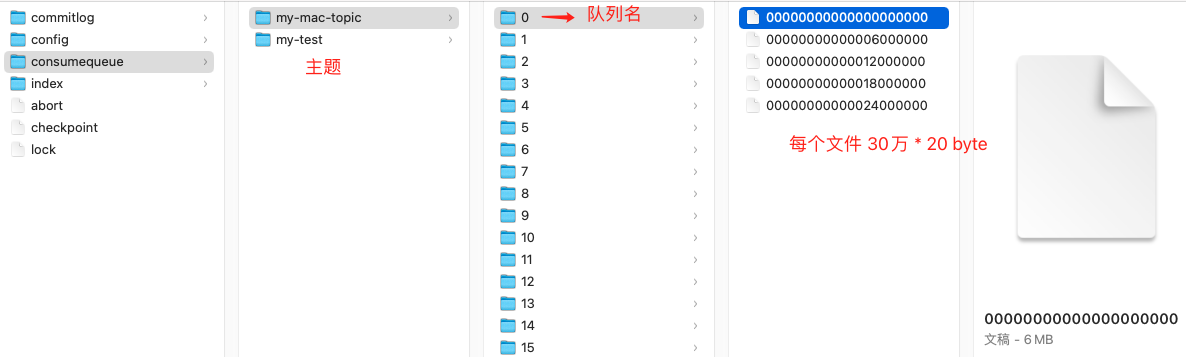
- 消費檔案按照主題儲存,每個主題下有不同的佇列,圖中 my-mac-topic 有 16 個佇列 ;
- 每個佇列目錄下 ,儲存 consumequeue 檔案,每個 consumequeue 檔案也是順序寫入,資料格式見下圖。
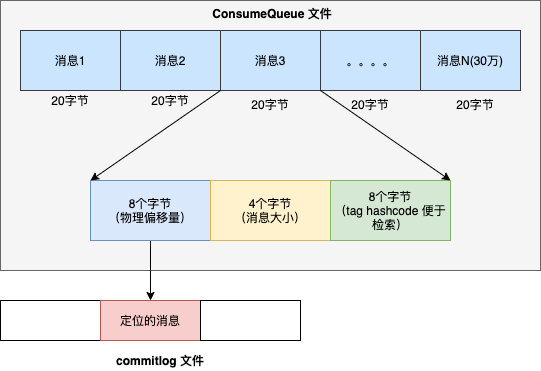
每個 consumequeue 包含 30 萬個條目,每個條目大小是 20 個位元組,每個檔案的大小是 30 萬 * 20 = 60萬位元組,每個檔案大小約5.72M 。和 commitlog 檔案類似,consumequeue 檔案的名稱也是以偏移量來命名的,可以通過訊息的邏輯偏移量定位訊息位於哪一個檔案裡。
消費檔案按照主題-佇列來儲存 ,這種方式特別適配釋出訂閱模型。
消費者從 broker 獲取訂閱訊息資料時,不用遍歷整個 commitlog 檔案,只需要根據邏輯偏移量從 consumequeue 檔案查詢訊息偏移量 , 最後通過定位到 commitlog 檔案, 獲取真正的訊息資料。
這樣就可以簡化消費查詢邏輯,同時因為同一主題下,消費者可以訂閱不同的佇列或者 tag ,同時提高了系統的可延伸性。
4 索引檔案
每個訊息在業務層面的唯一標識碼要設定到 keys 欄位,方便將來定位訊息丟失問題。伺服器會為每個訊息建立索引(雜湊索引),應用可以通過 topic、key 來查詢這條訊息內容,以及訊息被誰消費。
由於是雜湊索引,請務必保證key儘可能唯一,這樣可以避免潛在的雜湊衝突。
//訂單Id
String orderId = "1234567890";
message.setKeys(orderId);
從開源的控制檯中根據主題和 key 查詢訊息列表:
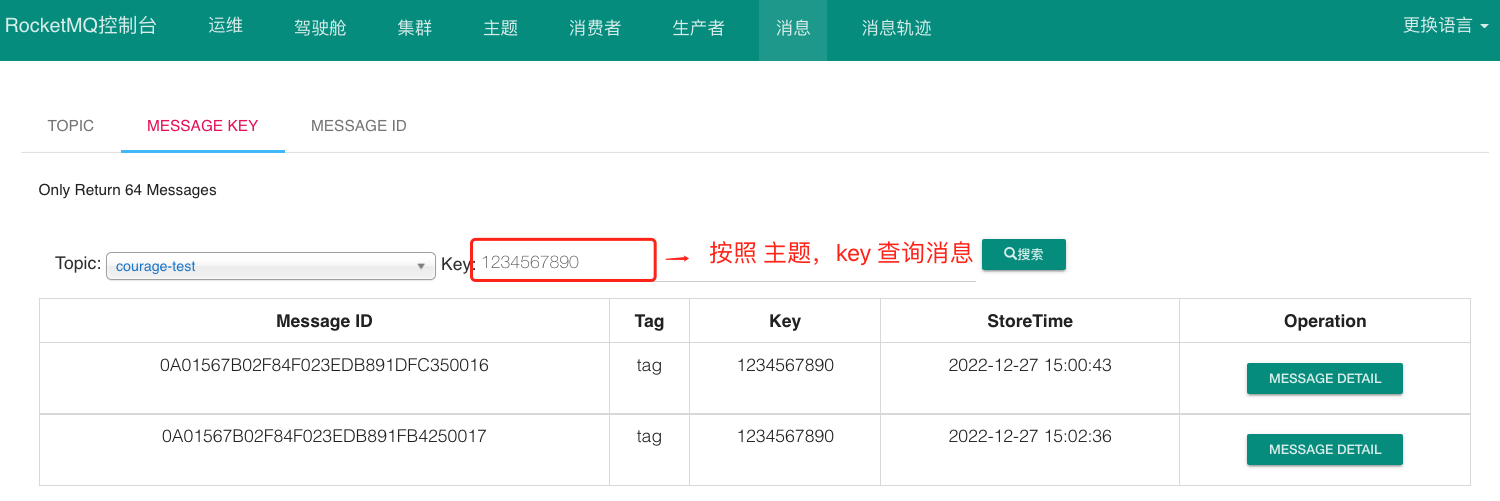
進入索引檔案目錄 ,如下圖所以:
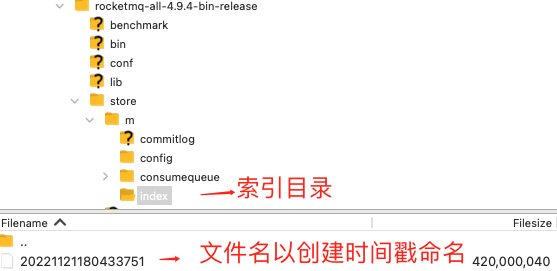
索引檔名 fileName 是以建立時的時間戳命名的,固定的單個 IndexFile 檔案大小約為 400 M 。
IndexFile 的檔案邏輯結構類似於 JDK 的 HashMap 的陣列加連結串列結構。
索引檔案主要由 Header、Slot Table (預設 500 萬個條目)、Index Linked List(預設最多包含 2000萬個條目)三部分組成 。
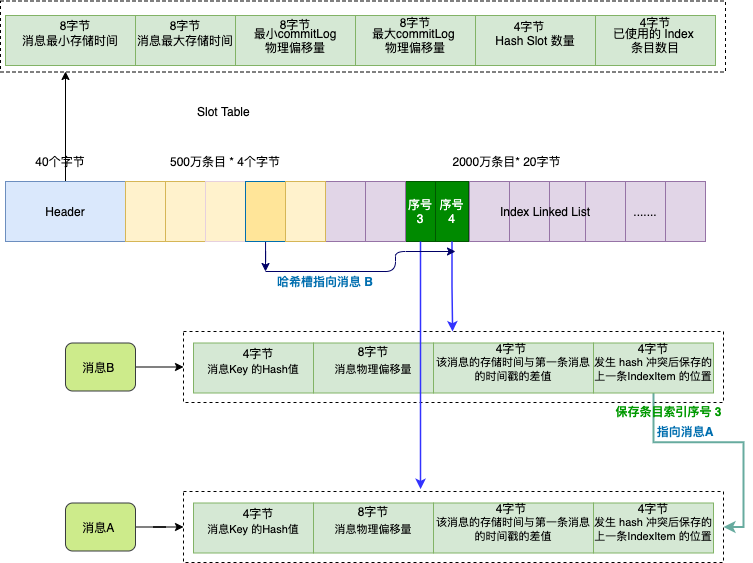
假如訂單系統傳送兩條訊息 A 和 B , 他們的 key 都是 "1234567890" ,我們依次儲存訊息 A , 訊息 B 。
因為這兩個訊息的 key 的 hash 值相同,它們對應的雜湊槽(深黃色)也會相同,雜湊槽會儲存的最新的訊息 B 的索引條目序號 , 序號值是 4 ,也就是第二個深綠色條目。
而訊息 B 的索引條目資訊的最後 4 個位元組會儲存上一條訊息對應的索引條目序號,索引序號值是 3 , 也就是訊息 A 。
5 寫到最後
Databases are specializing – the 「one size fits all」 approach no longer applies ------ MongoDB設計哲學
RocketMQ 儲存模型設計得非常精巧,筆者覺得每種設計都有其底層思考,這裡總結了三點 :
- 完美適配訊息佇列釋出訂閱模型 ;
- 資料檔案,消費檔案,索引檔案各司其職 ,同時以資料檔案為核心,非同步構建消費檔案 + 索引檔案這種模式非常容易擴充套件到主從複製的架構;
- 充分考慮業務的查詢場景,支援訊息 key ,訊息 offsetMsgId 查詢訊息資料。也支援消費者通過 tag 來訂閱主題下的不同訊息,提升了消費者的靈活性。
如果我的文章對你有所幫助,還請幫忙點贊、在看、轉發一下,你的支援會激勵我輸出更高質量的文章,非常感謝!
