巨量資料
| 統計主題 | 需求指標【ADS】 | 輸出方式 | 計算來源 | 來源層級 |
|---|---|---|---|---|
| 訪客【DWS】 | pv | 視覺化大屏 | page_log 直接可求 | dwd |
| UV(DAU) | 視覺化大屏 | 需要用 page_log 過濾去重 | dwm | |
| UJ 跳出率 | 視覺化大屏 | 需要通過 page_log 行為判斷 | dwm | |
| 進入頁面數 | 視覺化大屏 | 需要識別開始存取標識 | dwd | |
| 連續存取時長 | 視覺化大屏 | page_log 直接可求 | dwd | |
| 商品 | 點選 | 多維分析 | page_log 直接可求 | dwd |
| 收藏 | 多維分析 | 收藏表 | dwd | |
| 加入購物車 | 多維分析 | 購物車表 | dwd | |
| 下單 | 視覺化大屏 | 訂單寬表 | dwm | |
| 支付 | 多維分析 | 支付寬表 | dwm | |
| 退款 | 多維分析 | 退款表 | dwd | |
| 評論 | 多維分析 | 評論表 | dwd | |
| 地區 | PV | 多維分析 | page_log 直接可求 | dwd |
| UV | 多維分析 | 需要用 page_log 過濾去重 | dwm | |
| 下單 | 視覺化大屏 | 訂單寬表 | dwm | |
| 關鍵詞 | 搜尋關鍵詞 | 視覺化大屏 | 頁面存取紀錄檔 直接可求 | dwd |
| 點選商品關鍵詞 | 視覺化大屏 | 商品主題下單再次聚合 | dws | |
| 下單商品關鍵詞 | 視覺化大屏 | 商品主題下單再次聚合 | dws |
DWS 層的定位是什麼
- 輕度聚合,因為 DWS 層要應對很多實時查詢,如果是完全的明細那麼查詢的壓力是非常大的。
- 將更多的實時資料以主題的方式組合起來便於管理,同時也能減少維度查詢的次數。
DWS 層-訪客主題寬表的計算
| 統計主題 | 需求指標【ADS】 | 輸出方式 | 計算來源 | 來源層級 |
|---|---|---|---|---|
| 訪客【DWS】 | PV | 視覺化大屏 | page_log 直接可求 | dwd |
| UV(DAU) | 視覺化大屏 | 需要用 page_log 過濾去重 | dwm | |
| 跳出率 | 視覺化大屏 | 需要通過 page_log 行為判斷 | dwm | |
| 進入頁面數 | 視覺化大屏 | 需要識別開始存取標識 | dwd | |
| 連續存取時長 | 視覺化大屏 | page_log 直接可求 | dwd |
設計一張 DWS 層的表其實就兩件事:維度和度量(事實資料)
- 度量包括 PV、UV、跳出次數、進入頁面數(session_count)、連續存取時長
- 維度包括在分析中比較重要的幾個欄位:渠道、地區、版本、新老使用者進行聚合
需求分析與思路
- 接收各個明細資料,變為資料流
- 把資料流合併在一起,成為一個相同格式物件的資料流
- 對合並的流進行聚合,聚合的時間視窗決定了資料的時效性
- 把聚合結果寫在資料庫中
功能實現
封裝 VisitorStatsApp,讀取 Kafka 各個流資料
訪客主題寬表計算
- 要不要把多個明細的同樣的維度統計在一起?
- 因為單位時間內 mid 的運算元據非常有限不能明顯的壓縮資料量(如果是資料量夠大,或者單位時間夠長可以)
- 所以用常用統計的四個維度進行聚合 渠道、新老使用者、app 版本、省市區域
- 度量值包括 啟動、日活(當日首次啟動)、存取頁面數、新增使用者數、跳出數、平均頁面停留時長、總存取時長
- 聚合視窗: 10 秒
- 各個資料在維度聚合前不具備關聯性,所以先進行維度聚合
- 進行關聯 這是一個 fulljoin
- 可以考慮使用 FlinkSQL 完成
合併資料流
把資料流合併在一起,成為一個相同格式物件的資料流
合併資料流的核心運算元是 union。但是 union 運算元,要求所有的資料流結構必須一致。所以 union 前要調整資料結構。
根據維度進行聚合
- 設定時間標記及水位線,因為涉及開窗聚合,所以要設定事件時間及水位線
- 分組 分組選取四個維度作為 key , 使用 Tuple4 組合
- 開窗
- 視窗內聚合及補充時間欄位
- 寫入 OLAP 資料庫
為何要寫入 ClickHouse 資料庫,ClickHouse 資料庫作為專門解決大量資料統計分析的資料庫,在保證了海量資料儲存的能力,同時又兼顧了響應速度。而且還支援標準 SQL,即靈活又易上手。
flink-connector-jdbc 是官方通用的 jdbcSink 包。只要引入對應的 jdbc 驅動,flink 可以用它應對各種支援 jdbc 的資料庫,比如 phoenix 也可以用它。但是這個 jdbc-sink 只支援資料流對應一張資料表。如果是一流對多表,就必須通過自定義的方式實現了,比如之前的維度資料。
雖然這種 jdbc-sink 只能一流對一表,但是由於內部使用了預編譯器,所以可以實現批次提交以優化寫入速度。
DWS 層-商品主題寬表的計算
| 商品 | 點選 | 多維分析 | page_log 直接可求 | dwd |
| 收藏 | 多維分析 | 收藏表 | dwd | |
| 加入購物車 | 多維分析 | 購物車表 | dwd | |
| 下單 | 視覺化大屏 | 訂單寬表 | dwm | |
| 支付 | 多維分析 | 支付寬表 | dwm | |
| 退款 | 多維分析 | 退款表 | dwd | |
| 評論 | 多維分析 | 評論表 | dwd |
需求分析與思路
- 從 Kafka 主題中獲得資料流
- 把 Json 字串資料流轉換為統一資料物件的資料流
- 把統一的資料結構流合併為一個流
- 設定事件時間與水位線
- 分組、開窗、聚合
- 關聯維度補充資料
- 寫入 ClickHouse
功能實現
- 封裝商品統計實體類 ProductStats
- 建立 ProductStatsApp,從 Kafka 主題中獲得資料流
- 把 JSON 字串資料流轉換為統一資料物件的資料流
- 建立電商業務常數類 GmallConstant
- 把統一的資料結構流合併為一個流
- 設定事件時間與水位線
- 分組、開窗、聚合
- 補充商品維度資訊
因為除了下單操作之外,其它操作,只獲取到了商品的 id,其它維度資訊是沒有的 - 寫入 ClickHouse product_stats
DWS 層-地區主題表(FlinkSQL)
| 地區 | PV | 多維分析 | page_log 直接可求 | dwd |
| UV | 多維分析 | 需要用 page_log 過濾去重 | dwm | |
| 下單 | 視覺化大屏 | 訂單寬表 | dwm |
需求分析與思路
- 定義 Table 流環境
- 把資料來源定義為動態表
- 通過 SQL 查詢出結果表
- 把結果錶轉換為資料流
- 把資料流寫入目標資料庫
如果是 Flink 官方支援的資料庫,也可以直接把目標資料表定義為動態表,用 insert into 寫入。由於ClickHouse目前官方沒有支援的jdbc聯結器(目前支援Mysql、PostgreSQL、Derby)。也可以製作自定義 sink,實現官方不支援的聯結器。但是比較繁瑣。
功能實現
DWS 層-關鍵詞主題寬表的計算
| 關鍵詞 | 搜尋關鍵詞 | 視覺化大屏 | 頁面存取紀錄檔 直接可求 | dwd |
| 點選商品關鍵詞 | 視覺化大屏 | 商品主題下單再次聚合 | dws | |
| 下單商品關鍵詞 | 視覺化大屏 | 商品主題下單再次聚合 | dws |
需求分析與思路
關鍵詞主題這個主要是為了大屏展示中的字元雲的展示效果,用於感性的讓大屏觀看者感知目前的使用者都更關心的那些商品和關鍵詞。
關鍵詞的展示也是一種維度聚合的結果,根據聚合的大小來決定關鍵詞的大小。
關鍵詞的第一重要來源的就是使用者在搜尋欄的搜尋,另外就是從以商品為主題的統計中獲取關鍵詞。
功能實現
關於分詞
以我們需要根據把長文字分割成一個一個的詞,這種分詞技術,在搜尋引擎中可能會用到。對於中文分詞,現在的搜尋引擎基本上都是使用的第三方分詞器,咱們在計算資料中也可以,使用和搜尋引擎中一致的分詞器,IK。
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
有了分詞器,那麼另外一個要考慮的問題就是如何把分詞器的使用揉進 FlinkSQL 中。
因為 SQL 的語法和相關的函數都是 Flink 內定的,想要使用外部工具,就必須結合自定義函數。
https://www.bilibili.com/video/BV1Ju411o7f8/?p=115
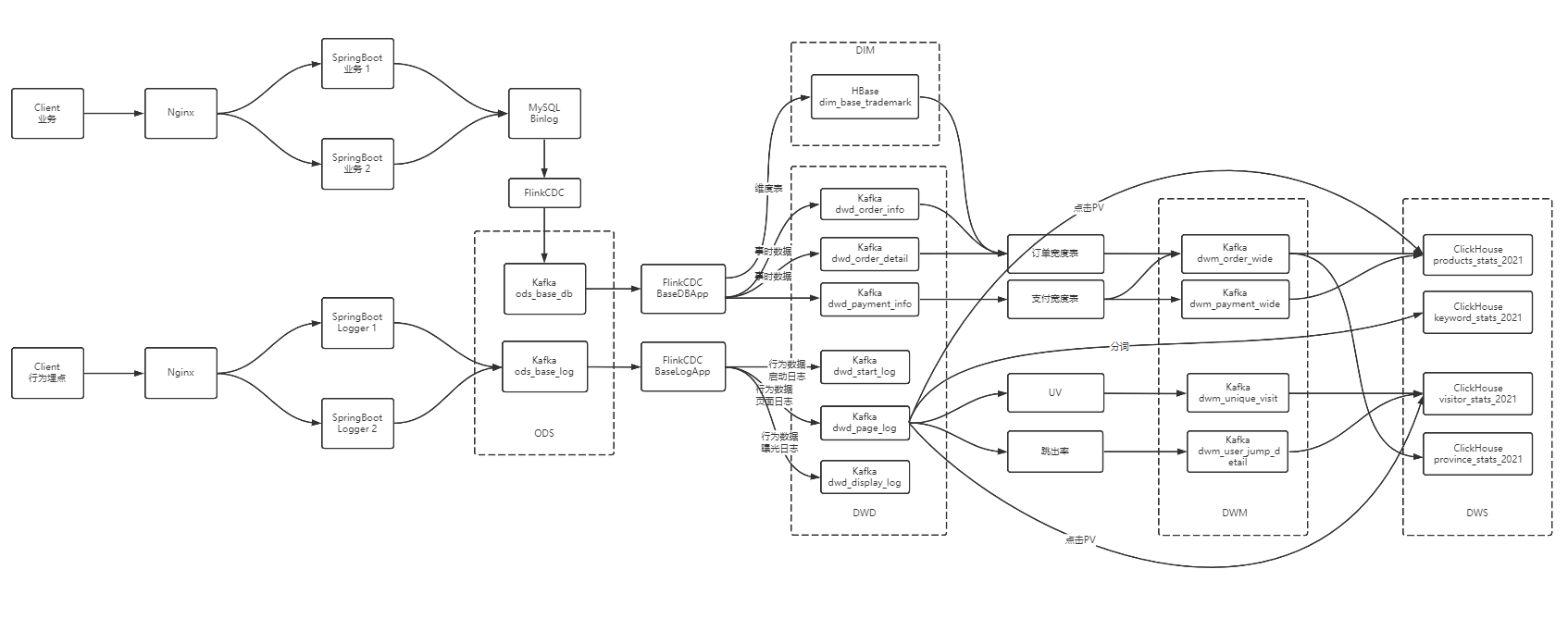
巨量資料-資料倉儲-實時數倉架構分析
巨量資料-業務資料採集-FlinkCDC
巨量資料 - DWD&DIM 行為資料
巨量資料 - DWD&DIM 業務資料
巨量資料 DWM層 業務實現