如何設定 SLO
前言
無論是對外提供 IaaS PaaS SaaS 的雲公司,還是提供資訊科技服務的乙方公司,亦或是金融 製造等各行各業的資料中心、運維部門,我們的一個非常重要的合同承諾或考核評估指標就是:SLA(即:Service-Level Agreement 服務等級協定)。
而真正落地實現 SLA 的精確測量,最廣為人知的就是 Google 的 SRE 理論。
Google SRE SLO & SLA
在 Google,會明確區分 SLO 和服務等級協定 (SLA)。SLA 通常涉及向服務使用者承諾,即服務可用性 SLO 應在特定時間段內達到特定級別。如果不這樣做,就會導致某種懲罰。這可能是客戶為該期間支付的服務訂閱費的部分退款,或者免費新增的額外訂閱時間。SLO 不達標會傷害到服務團隊,因此他們將努力留在 SLO 內。如果您要向客戶收取費用,則可能需要 SLA。
SLA 中的可用性 SLO 通常比內部可用性 SLO 更寬鬆。這可以用可用性數位表示:例如,一個月內可用性 SLO 為 99.9%,內部可用性 SLO 為 99.95%。或者,SLA 可能僅指定構成內部 SLO 的指標的子集。
如果 SLA 中的 SLO 與內部 SLO 不同(幾乎總是如此),則監控必須顯式測量 SLO 達標情況。您希望能夠檢視系統在 SLA 日程期間的可用性,並快速檢視它是否似乎有脫離 SLO 的危險。
您還需要對合規性進行精確測量,通常來自 Metrics、Tracing、Logging 分析。由於我們對付費客戶有一組額外的義務(如 SLA 中所述),因此我們需要將從他們那裡收到的查詢與其他查詢分開進行度量。這是建立 SLA 的另一個好處 — 這是確定流量優先順序的明確方法。
定義 SLA 的可用性 SLO 時,請注意將哪些查詢視為合法查詢。例如,如果客戶因為釋出了其移動使用者端的錯誤版本而超出配額,則可以考慮從 SLA 中排除所有"超出配額"的響應程式碼。
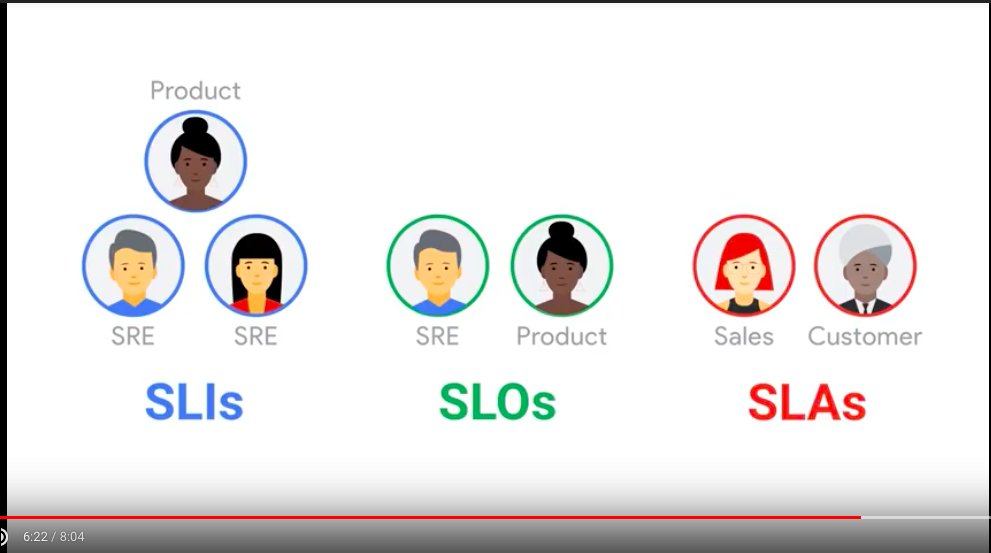
SLI
SLI 是經過仔細定義的測量指標,它根據不同系統特點確定要測量什麼。
常見的 SLI 有:
- 效能
- 響應時間 (latency)
- 吞吐量 (throughput)
- 請求量 (qps)
- 實效性 (freshness)
- 可用性
- 執行時間 (uptime)
- 故障時間/頻率
- 可靠性
- 質量
- 準確性 (accuracy)
- 正確性 (correctness)
- 完整性 (completeness)
- 覆蓋率 (coverage)
- 相關性 (relevance)
- 內部指標
- 佇列長度 (queue length)
- 記憶體佔用 (RAM usage)
- 因素人
- 響應時間 (time to response)
- 修復時間 (time to fix)
- 修復率 (fraction fixed)
SLO
SLO(服務等級目標)指定了服務所提供功能的一種期望狀態,服務提供者用它來指定系統的預期狀態。SLO 裡不會提到,如果目標達不到會怎麼樣。
SLO 是用 SLI 來描述的,一般描述為:
比如以下SLO:
- 每分鐘平均 qps > 100 k/s
- 99% 存取延遲 < 500ms
- 99% 每分鐘頻寬 > 200MB/s
設定 SLO 時的目標依賴於系統的不同狀態(conditions),根據不同狀態設定不同的SLO:
總 SLO = service1.SLO1 weight1 + service2.SLO2 weight2 + …
為什麼要有 SLO,設定 SLO 的好處是什麼呢?
- 對於客戶而言,是可預期的服務質量,可以簡化使用者端的系統設計
- 對於服務提供者而言
- 可預期的服務質量
- 更好的取捨成本/收益
- 更好的風險控制(當資源受限的時候)
- 故障時更快的反應,採取正確措施
SLA
SLA = SLO + 後果
小結
- SLI:服務等級指標,經過仔細定義的測量指標
- SLO:服務等級目標,
總 SLO = service1.SLO1 weight1 + service2.SLO2 weight2 + … - SLA: 服務等級協定,
SLA = SLO + 後果
如何設定 SLO
公有云常見 SLO
常見於通過 處理請求的服務或 API 提供的服務(如:物件儲存 或 API 閘道器)
- 錯誤率 (error rate) 計算的是服務返回給使用者的 error 總數
- 如果錯誤率大於X%(如 0.5%),就算是服務 down了,開始計算 downtime
- 如果錯誤率持續超過 Y (如 5)分鐘,這個downtime就會被計算在內
- 間斷性的小於 Y 分鐘的downtime是不被計算在內的。
前端 Web 或 APP
前端使用者體驗 Apdex 目標
如果有前端 js 探針監控,或撥測監控,那麼可以用前端使用者體驗 Apdex 作為 SLO。
Apdex 定義了一個效能標準,將應用程式使用者分為三個組:
- 滿意、
- 可容忍(一般)
- 沮喪(不滿意)。
例如,作為前端應用程式的 SLO,您可以指定希望 90% 的使用者 Apdex 都是 滿意 。
如,My WebApp Apdex 公式如下:
100% * (apps.web.actionCount.category:filter(eq(Apdex category,SATISFIED)):splitBy("My WebApp")) / (apps.web.actionCount.category:splitBy("My WebApp"))
前端 APP 無崩潰(Crash)使用者率目標
衡量手機 App (iOS 和 Android) 的可用性和可靠性的最重要指標之一是 無崩潰使用者率。指的是沒有崩潰的情況下開啟並使用移動 APP 的使用者百分比。
因此,公式範例如下:
apps.other.crashFreeUsersRate.os:splitBy("My mobile app")
撥測可用性目標
撥測可用性 SLO 表示撥測處於可用狀態下的時間百分比,或者,成功撥測佔執行的總測試數的百分比。
因此,公式範例為:
(synthetic.browser.availability.location.total:splitBy("My WebApp"))
後端應用 或 Service
基本的 SLO - 呼叫成功率目標
成功率 = 成功的請求呼叫次數 / 總的請求呼叫次數
如:My service 的 成功率:
100% * (service.requestCount.successCount:splitBy("My service"))/(service.requestCount.totalCount:splitBy("My service"))
那麼,如果 My service 的關鍵 API 或請求需要計量,就可能是下面的公式:
(100%)*(service.keyRequest.successCount:splitBy(type("SERVICE_API") AND entityId("POST /login")))/(service.keyRequest.totalCount:splitBy(type("SERVICE_API") AND entityId("POST /login")))
ℹ️ 提示:
成功的請求最簡單的一種方式是:http 狀態碼為 2xx 或 3xx 的請求即視為成功。
還有一種,請求執行過程中沒有丟擲錯誤(紀錄檔或異常)的請求視為成功。
服務效能目標
重點在於效能。
服務效能 SLO 表示 「fast」 服務呼叫佔服務呼叫總數的百分比,其中 「fast」使用自定義條件定義。例如:
- fast:0 - 3s 內完成服務呼叫()
- normal:3 - 5s 內完成服務呼叫
- slow:5s 以上完成服務呼叫或超時
ℹ️ 提示:
當然,上邊的 3s 也不應該是拍腦袋想的,而應該是例如基於過去一個月系統正常執行時 99% 百分位數的響應時間。
公式範例為:
(service:fastRequests:splitBy("My WebApp")) / (service:totalRequests:splitBy("My WebApp"))
後端資料庫
資料庫可用性或讀可用性目標
錯誤率:是在給定的一小時間隔內,DB 的失敗 SQL 執行次數除以總 SQL 執行次數。
讀錯誤率:是在給定的一小時間隔內,DB 的失敗查詢 SQL 執行次數除以總 SQL 執行次數。
公式範例為:
可用性 % = 100% - Average DB Error Rate
或:
讀可用性 % = 100% - Average DB Read Error Rate
吞吐量目標
-
吞吐量失敗的請求:是指請求尚未超過給定 DB 吞吐量,卻被 DB 吞吐量限制,導致錯誤碼
-
吞吐量錯誤率:是在給定的一小時間隔內,給定 DB 的吞吐量失敗請求總數除以總請求數。
那麼,公式範例為:
吞吐量目標% = 100% -平均吞吐量錯誤率
一致性目標
SLI 為:
一致性違規率:是指在給定的 DB 中,在給定的一小時間隔內,對所選的一致性級別(按總請求數劃分)執行一致性保證時無法傳送的成功請求。
延遲目標
- P99 延遲:計算出的一段時間內的測試 SQL (如
select 1 from dual) 執行時間的 99% 百分位響應時間。 - 延遲時間和:是指在應用程式提交的 SQL 成功請求導致 P99 延遲大於或等於 10ms 的一個小時間隔的總數。
那麼,範例公式為:
延遲目標% = 100% - 總的延遲時間和的次數 / (DB 總使用時間/1H)
如:過去 1 個月,總的延遲時間和的次數為 50 次,分母為:30 * 24 / 1 = 720
那麼:延遲目標% = 100% - 50 / 720 ≈ 93%
MQ 類
訊息成功率目標
就是成功的訊息除以 MQ 接收的總訊息。
公式範例為:
(100)*((mq.rabbitmq.queue.requests.successful:splitBy("payment"))/mq.rabbitmq.queue.requests.incoming:splitBy("payment")))
Host 類
UPTIME 目標
例如,每小時正常執行時間百分比 = 100% - 單個 Host 範例處於不可用狀態的總時間(沒有超過多長時間才算不可用一說)百分比
不可用的定義可以是:
- 該 Host 範例沒有網路連線
- 該 Host 範例 無法執行讀寫 IO,且 IO 在佇列中掛起。即 IO hang。
K8S 類
K8S 類是一類綜合系統,需要考慮如下目標
- API Server 成功率目標
- 計算目標
- 儲存目標
- 網路目標
- …
儲存類
可用性(Availability)目標
大致也是類似上邊的可用性目標。
資料永續性(Durability)目標
這個通常非常高,比如:99.999999999%
可以簡單粗暴認為:只要有資料丟失的情況,就是沒達到目標。
典型案例就是騰訊的那次。
網路類
可用性目標
以 NAT 閘道器為例:
單範例服務不可用分鐘數: 當某一分鐘內,NAT 閘道器範例出方向所有封包都被 NAT 閘道器丟棄時,則視為該分鐘內該 NAT 閘道器範例服務不可用。在一個服務週期內 NAT 閘道器範例不可用分鐘數之和即服務不可用分鐘數。
總結
可以根據不同的層次、元件設定不同的 SLO。
SLO 的監測是需要監控工具的支援。
常用的 SLO 包括:
- 可用性(Availability)目標
- 成功率(Success Rate)目標
- 延遲 (Latency) 目標
- 執行時間 (Uptime) 目標
- 資料永續性(Durability)目標
EOF
三人行, 必有我師; 知識共用, 天下為公. 本文由東風微鳴技術部落格 EWhisper.cn 編寫.