【爬蟲+資料分析+資料視覺化】python資料分析全流程《2021胡潤百富榜》榜單資料!
一、爬蟲
1.1 爬取目標
本次爬取的目標是,2021年胡潤百富榜的榜單資料:胡潤百富 - 榜單
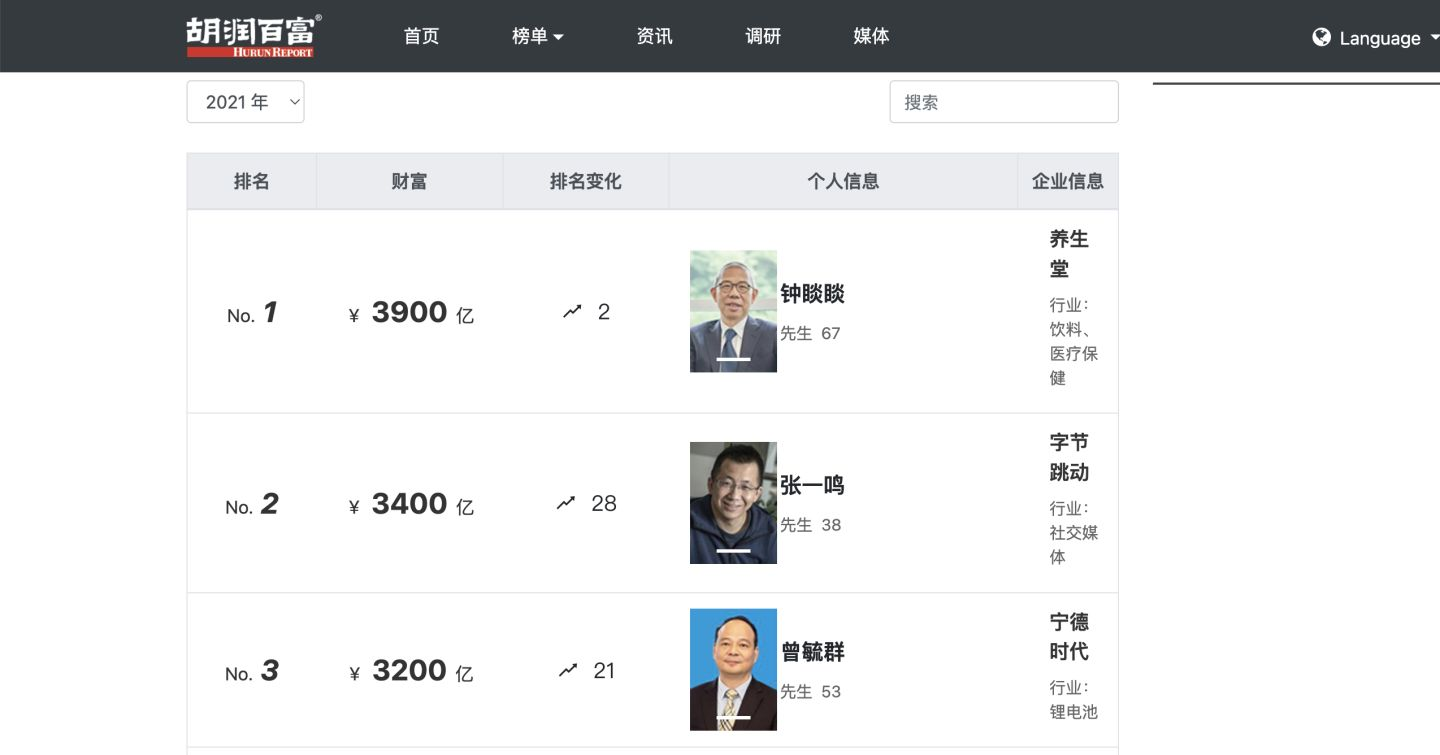
頁面上能看到的資訊有:
排名、財富值、排名變化、個人資訊(姓名、性別、年齡)、企業資訊(企業名稱、所屬行業)
頁面結構很整齊,資料也很完整,非常適合爬蟲和資料分析使用。
1.2 分析頁面
老規矩,開啟Chrome瀏覽器,按F12進入開發者模式,依次點選Network->Fetch/XHR,準備好捕獲ajax請求。
重新重新整理一下頁面,發現一條請求:

在預覽介面,看到一共20條(0~19)返回資料,正好對應頁面上的20個富豪資訊。
所以,後面編寫爬蟲程式碼,針對這個地址傳送請求就可以了。
另外,關於翻頁,我的個人習慣是,選擇每頁顯示最多的資料量,這樣能保證少翻頁幾次,少傳送幾次請求,防止被對端伺服器反爬。
所以,每頁選擇200條資料:
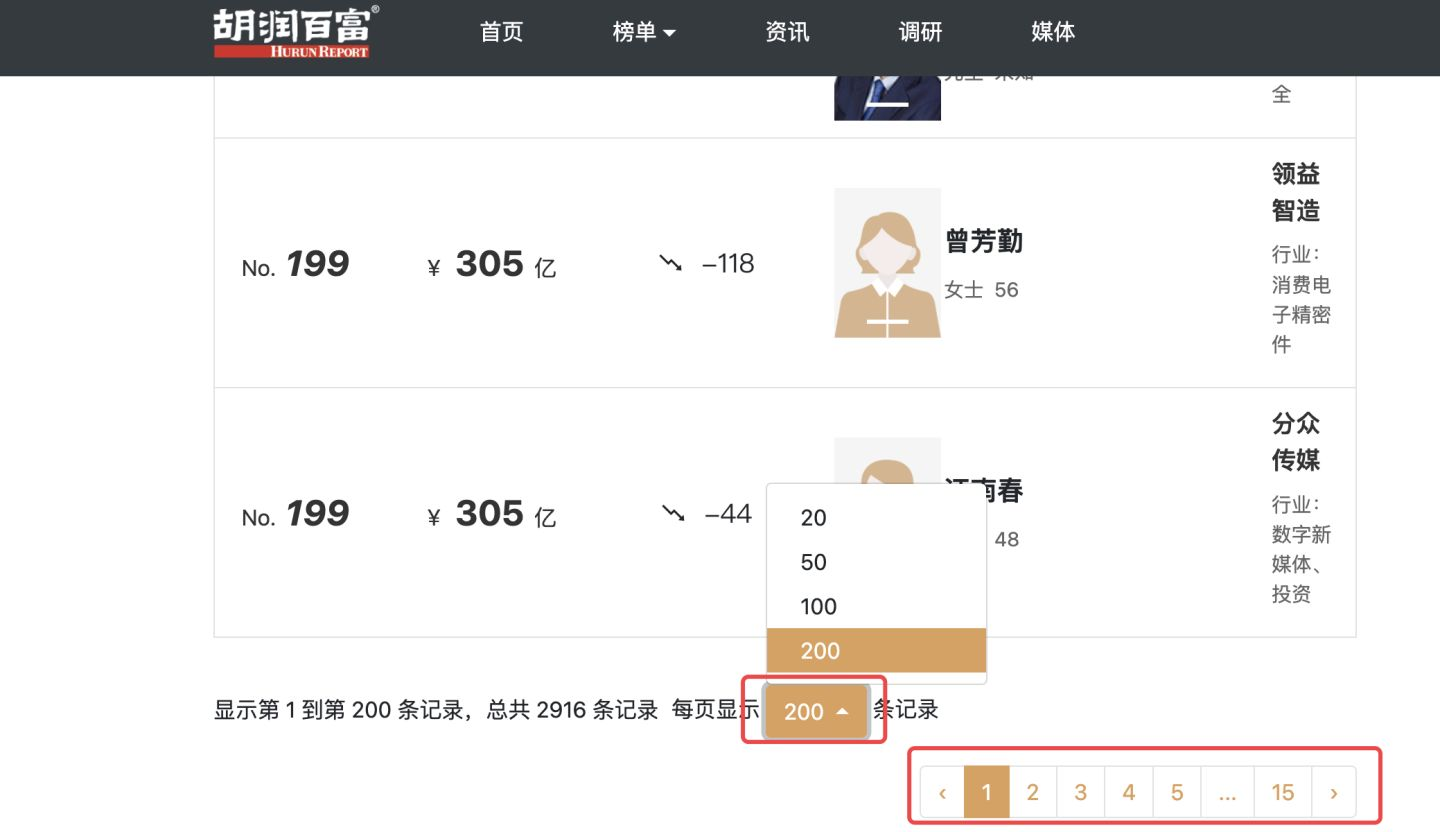
再重新整理一下頁面,進行幾次翻頁,觀察請求地址的變化規律:
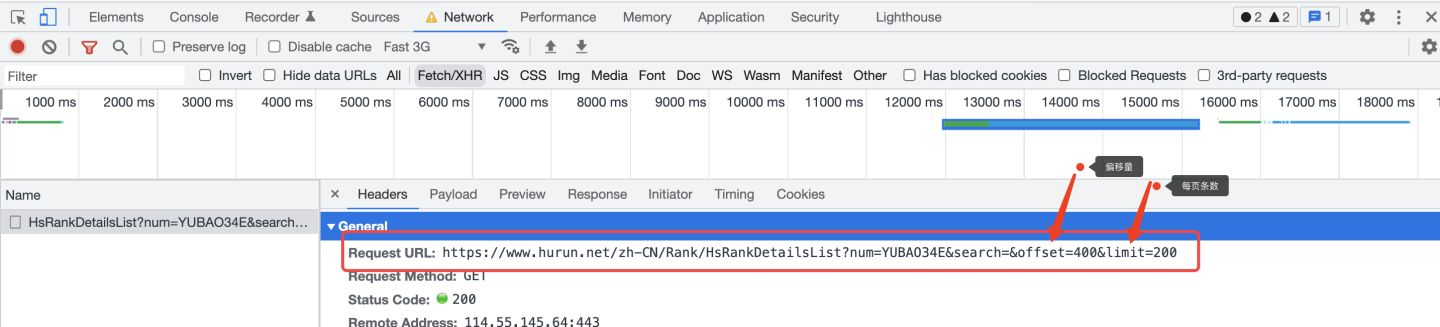
以翻到第3頁為例,url中的offset(偏移量)為400,limit(每頁的條數)為200,所以,可得出規律:
offset = (page - 1) * 200
limit = 200
下面開始編寫爬蟲程式碼。
1.3 爬蟲程式碼
首先,匯入需要用到的庫:
import requests # 傳送請求
import pandas as pd # 存入excel資料
from time import sleep # 等待間隔,防止反爬
import random # 隨機等待
根據1.2章節分析得出的結論,編寫邏輯程式碼,向頁面傳送請求:
# 迴圈請求1-15頁
for page in range(1, 16):
# 胡潤百富榜地址
sleep_seconds = random.uniform(1, 2)
print('開始等待{}秒'.format(sleep_seconds))
sleep(sleep_seconds)
print('開始爬取第{}頁'.format(page))
offset = (page - 1) * 200
url = 'https://www.hurun.net/zh-CN/Rank/HsRankDetailsList?num=YUBAO34E&search=&offset={}&limit=200'.format(offset)
# 構造請求頭
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'accept-encoding': 'gzip, deflate, br',
'content-type': 'application/json',
'referer': 'https://www.hurun.net/zh-CN/Rank/HsRankDetails?pagetype=rich'
}
# 傳送請求
r = requests.get(url, headers=headers)
用json格式解析返回的請求資料:(一行程式碼即可完成接收)
json_data = r.json()
由於解析的欄位較多,這裡不再贅述詳細過程,欄位資訊包含:
Fullname_Cn_list = [] # 全名_中文
Fullname_En_list = [] # 全名_英文
Age_list = [] # 年齡
BirthPlace_Cn_list = [] # 出生地_中文
BirthPlace_En_list = [] # 出生地_英文
Gender_list = [] # 性別
Photo_list = [] # 照片
ComName_Cn_list = [] # 公司名稱_中文
ComName_En_list = [] # 公司名稱_英文
ComHeadquarters_Cn_list = [] # 公司總部地_中文
ComHeadquarters_En_list = [] # 公司總部地_英文
Industry_Cn_list = [] # 所在行業_中文
Industry_En_list = [] # 所在行業_英文
Ranking_list = [] # 排名
Ranking_Change_list = [] # 排名變化
Relations_list = [] # 組織結構
Wealth_list = [] # 財富值_人民幣_億
Wealth_Change_list = [] # 財富值變化
Wealth_USD_list = [] # 財富值_美元
Year_list = [] # 年份
最後,依然採用我最習慣的儲存資料的方法,先拼裝DataFrame資料:
df = pd.DataFrame( # 拼裝爬取到的資料為DataFrame
{
'排名': Ranking_list,
'排名變化': Ranking_Change_list,
'全名_中文': Fullname_Cn_list,
'全名_英文': Fullname_En_list,
'年齡': Age_list,
'出生地_中文': BirthPlace_Cn_list,
'出生地_英文': BirthPlace_En_list,
'性別': Gender_list,
'照片': Photo_list,
'公司名稱_中文': ComName_Cn_list,
'公司名稱_英文': ComName_En_list,
'公司總部地_中文': ComHeadquarters_Cn_list,
'公司總部地_英文': ComHeadquarters_En_list,
'所在行業_中文': Industry_Cn_list,
'所在行業_英文': Industry_En_list,
'組織結構': Relations_list,
'財富值_人民幣_億': Wealth_list,
'財富值變化': Wealth_Change_list,
'財富值_美元': Wealth_USD_list,
'年份': Year_list
}
)
再用pandas的to_csv方法儲存:
# 儲存結果資料
df.to_csv('2021胡潤百富榜.csv', mode='a+', index=False, header=header, encoding='utf_8_sig')
注意,加上這個編碼格式選項(utf_8_sig),否則產生亂碼哦。
爬蟲開發完成,下面展示結果資料。
1.4 結果資料
看一下榜單上TOP20的資料吧:
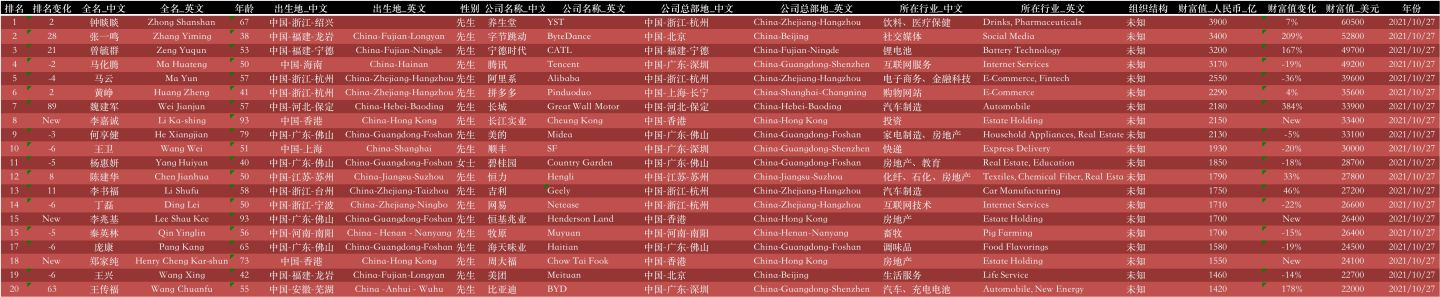
資料一共2916條,19個欄位資訊,含:
排名、排名變化、全名_中文、全名_英文、年齡、出生地_中文、出生地_英文、性別、公司名稱_中文、公司名稱_英文、公司總部地_中文、公司總部地_英文、所在行業_中文、所在行業_英文、組織結構、財富值_人民幣_億、財富值變化、 財富值_美元、年份。
資料資訊還是很豐富的,希望能夠挖掘出一些有價值的結論!
二、資料分析
2.1 匯入庫
首先,匯入用於資料分析的庫:
import pandas as pd # 讀取csv檔案
import matplotlib.pyplot as plt # 畫圖
from wordcloud import WordCloud # 詞雲圖
增加一個設定項,用於解決matplotlib中文亂碼的問題:
# 解決中文顯示問題
plt.rcParams['font.sans-serif'] = ['SimHei'] # 顯示中文標籤 # 指定預設字型
plt.rcParams['axes.unicode_minus'] = False # 解決儲存影象是負號'-'顯示為方塊的問題
讀取csv資料:
# 讀取csv資料
df = pd.read_csv('2021胡潤百富榜.csv')
2.2 資料概況
檢視資料形狀:

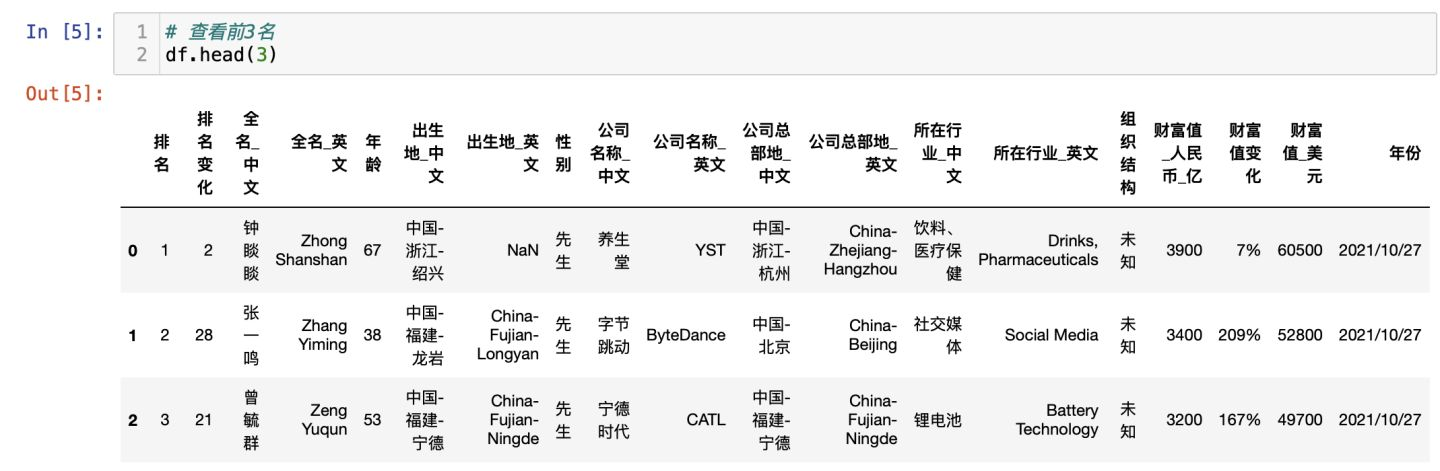
檢視前3名富豪:
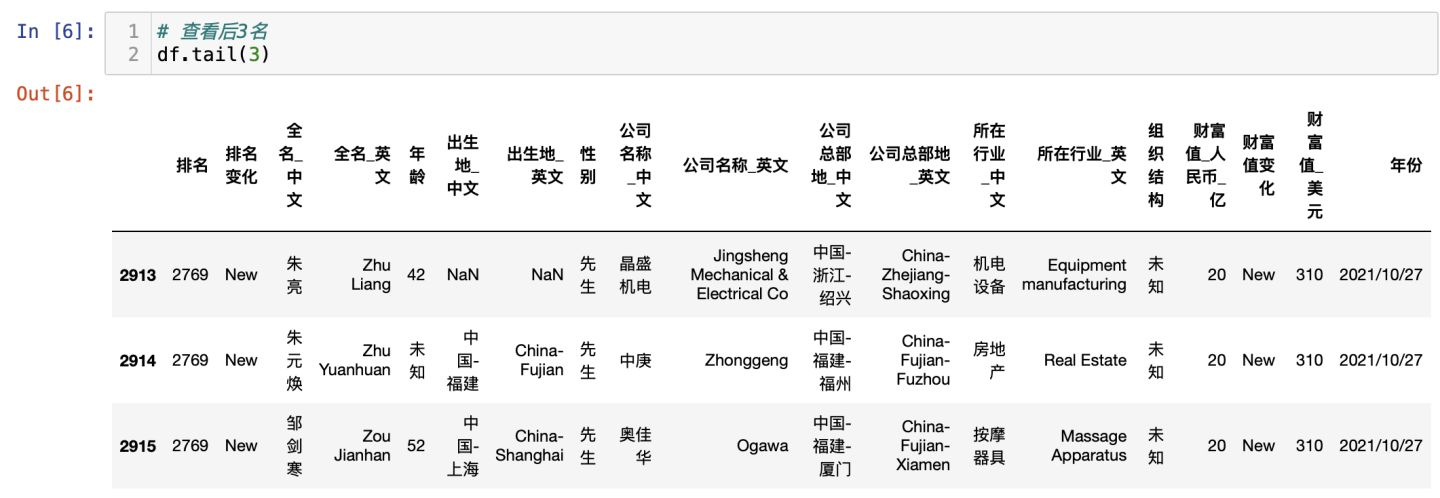
檢視最後3名富豪:
描述性統計:
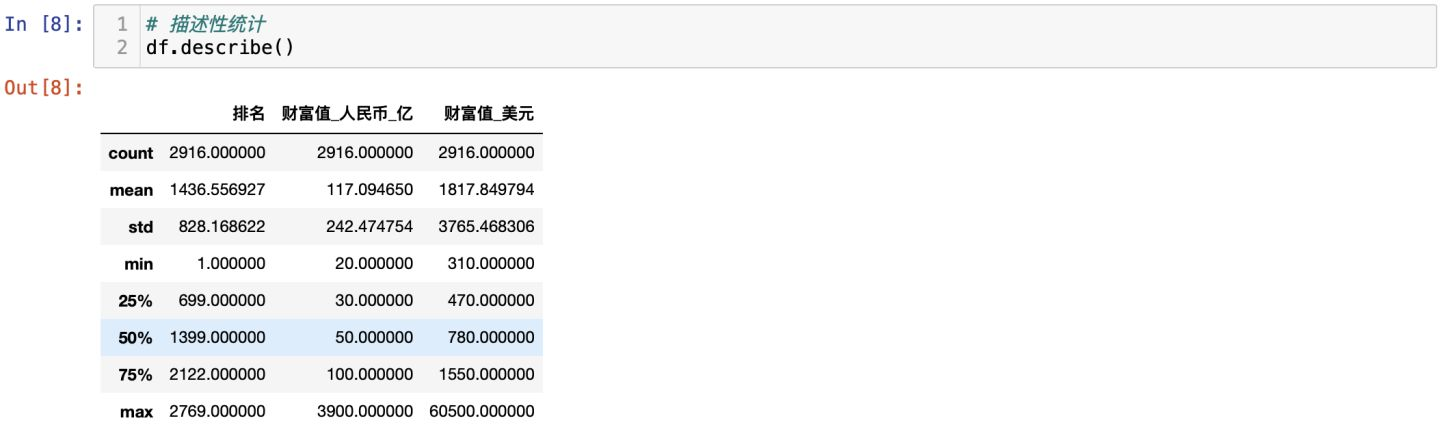
從描述性統計,可以得出結論:
從最大值3900億、最小值20億、方差242來看,分佈很零散,各位富豪掌握的財富差距很大,馬太效應明顯。
2.3 視覺化分析
2.3.1 財富分佈
程式碼:
df_Wealth = df['財富值_人民幣_億']
# 繪圖
df_Wealth.plot.hist(figsize=(18, 6), grid=True, title='財富分佈-直方圖')
# 儲存圖片
plt.savefig('財富分佈-直方圖.png')
視覺化圖:
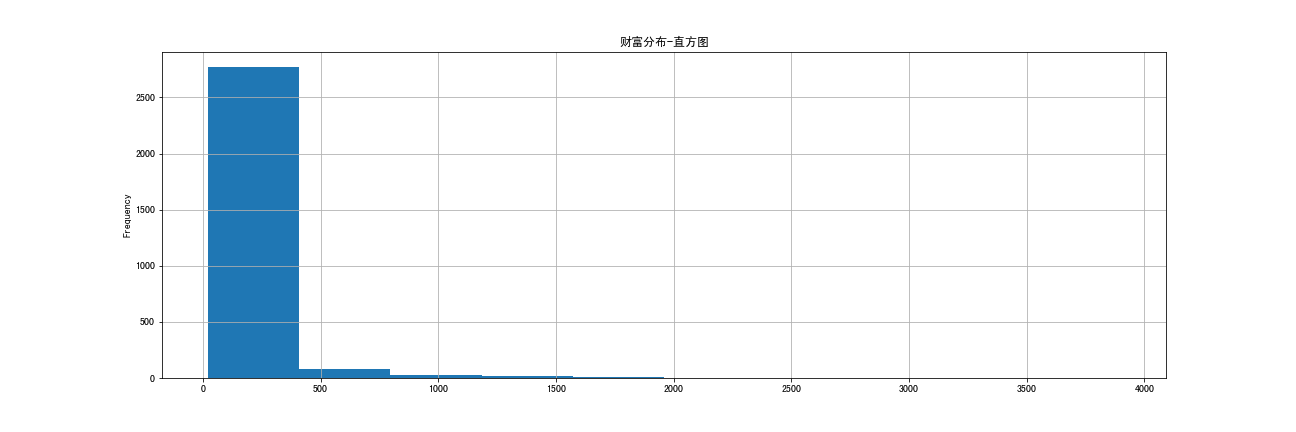
結論:大部分的富豪的財富集中在20億~400億之間,個別頂級富豪的財富在3000億以上。
2.3.2 年齡分佈
程式碼:
# 剔除未知
df_Age = df[df.年齡 != '未知']
# 資料切割,8個分段
df_Age_cut = pd.cut(df_Age.年齡.astype(float), bins=[20, 30, 40, 50, 60, 70, 80, 90, 100])
# 畫柱形圖
df_Age_cut.value_counts().plot.bar(figsize=(16, 6), title='年齡分佈-柱形圖')
# 儲存圖片
plt.savefig('年齡分佈-柱形圖.png')
視覺化圖:
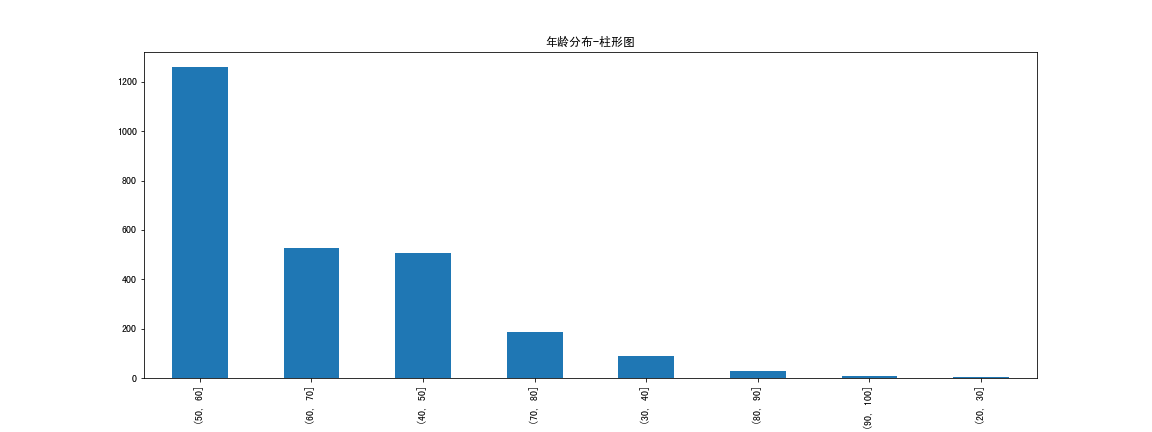
結論:大部分富豪的年齡在50-60歲,其次是60-70和40-50歲。極少數富豪在20-30歲(年輕有為