Apache Kafka 移除 ZK Proposals
Zookeeper 和 KRaft
這裡有一篇 Kafka 功能改進的 proposal 原文。要了解移除 ZK 的原因,可以仔細看看該文章。以下是對該文章的翻譯。
動機
目前,Kafka 使用 Zookeeper 儲存與分割區(patitions)、brokers 相關的後設資料,以及選舉 Kafka 控制器(某個 broker)。我們將移除對 Zookeeper 的依賴。如此一來,Kafka 在管理後設資料方面,將獲得更好的可延伸性和魯棒性,同時支援更多的分割區。在部署、設定 Kafka 方面,也將得到極大的簡化。
將後設資料視為 Event Log
我們常說將狀態做為事件流管理的好處。一個在流中描述消費者位置的數位:offset。消費者通過回放 offset 之後的事件,就能獲取最新狀態。紀錄檔建立一套清晰、有序的事件機制,並確保每個消費者能獲取到自己的時間線。
雖然我們的使用者享受這些便利,但是忽略了 Kafka 本身。我們將作用到後設資料的變更看作彼此孤立,互不相干。當控制器將狀態變更通知到叢集中的其他 broker 時,其他 broker 可能會收到一些變更,但不是全部變更。雖然控制器會重試幾次,但最終會停止重試。這將導致 broker 之間處於不同步的狀態。
更糟糕的是,雖然 Zookeeper 儲存 record,但是 Zookeeper 中儲存的狀態經常與控制器儲存在記憶體中的狀態無法匹配。例如,當分割區 leader 在 Zookeeper 中變更其 ISR(in-sync Replica)時,通常情況下,控制器會延誤幾秒鐘才能獲知其變更。對於控制器來說,沒有通用的方法追蹤 Zookeeper 的 event log。雖然控制器可以設定一次性守衛,但是守衛的數量由於效能問題會受到限制。當觸發守衛時,守衛不負責通知控制器當前狀態,僅僅是通知控制器狀態發生了變更。同時,控制器重讀 znode,然後設定一個新的守衛,但是,從最初守衛發出通知,到控制器完成重讀,重新設定守衛期間,狀態可能已經產生了新的變更。如果不設定守衛,控制器將永遠無法得知變更。某些情況下,重啟控制器是解決狀態不一致的唯一手段。
後設資料與其儲存在獨立的系統中,不如儲存在 Kafka 中。這種情況下,控制器狀態與 Zookeeper 狀態之間和差異相關的問題將不復存在。與其挨個通知 broker,不如讓 broker 們從 event log 中消費後設資料事件。這樣就確保了後設資料變更能夠按相同的順序同步到 broker 中。broker 將後設資料儲存在本地檔案中。當這些 broker 啟動時,它們只需要從控制器中(某個 broker)中讀取變更,而無需全量讀取狀態。在這種情況下,我們消耗更少的 CPU 資源就能獲得更多分割區。
簡化部署與設定
Zookeeper 是一套獨立的系統,有其組態檔語法,管理工具以及部署模式。這意味著系統管理員為了部署 Kafka,需要學習如何管理和部署兩套獨立的分散式系統。這對系統管理員來說,是非常艱鉅的任務,尤其是在他們不熟悉部署 Java 服務的情況下。統一系統將極大地改善執行 Kafka 的初次體驗,並有助於拓寬其應用範圍。
由於 Kafka 和 Zookeeper 的組態檔是分離的,因此極易產生錯誤。例如,管理員在 Kafka 中設定了 SASL(Simple Authentication Security Layer,簡單認證安全層),並且錯誤的認為對所有在網路中傳輸的資料都做了加密。事實上,還需要在外部系統 Zookeeper 中設定加密。統一兩個系統將獲得完整的加密設定模型。
最後,未來我們可能需要支援單節點 Kafka 模型。對於那些要測試 Kafka 功能的人來說,無需啟動守護行程,將提供極大的便利性。移除 Zookeeper 依賴,將使其成為可能。
架構
介紹
本 KIP(Kafka Improvement Proposal,Kafka 改進 Proposal) 展現的是一個可延伸的後 Zookeeper 時代的 Kafka 系統的總體願景。為了突出重要部分,我忽略了大多數細節,比如 RPC 格式、磁碟格式等等。在後續 KIP 中,我們將逐步深入描述細節。與 KIP-4 類似,提出總體願景,後續的 KIP 中逐步擴充。
總覽
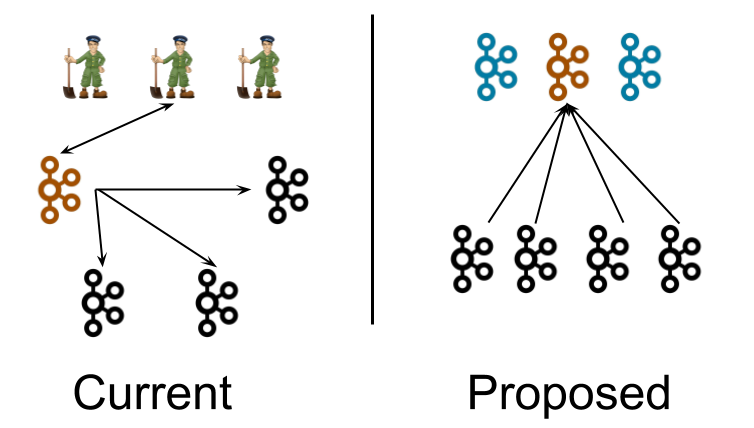
目前,一套 Kafka 叢集包括幾個 broker 節點,Zookeeper 節點做為一套外部 quorum (投票機制,少數服從多數)。我們畫了 4 個 broker 節點和 3 個 Zookeeper 節點。這是小叢集所需的正常設定。控制器(用橙色標識)在被選舉後,從 Zoopeeper 的 quorum 中載入其狀態。從控制器連線其他節點的線,在 broker 中代表更新控制器推播的訊息,比如 LeaderAndIsr、UpdateMetadata 訊息。
注意,這張圖有誤導的地方。除控制器以外,其他 broker 也可以與 Zookeeper 通訊。因此,每個 broker 都應該畫一條連線 ZK 的線。無論如何,畫太多線將導致該圖難以閱讀。該圖還忽略了,在不需要控制器介入的情況下,能夠修改 Zookeeper 中的狀態的外部命令列工具和工具包。正如上面討論的那樣,這些問題導致了控制器記憶體中狀態無法真正的反映 Zookeeper 中的持久化狀態。
在 Proposed 架構中,三個控制器節點取代了 Zookeeper 的 3 個節點。控制器節點和 broker 節點在不同的 JVM 中執行。控制器節點為後設資料分割區選舉一個 leader 節點,用橙色標識。相較於控制器向各個 broker 推播後設資料更新,在 Proposed 中,各個 broker 從 leader 中拉取後設資料更新。這就是箭頭指向控制器的原因。
注意,控制器程序與 broker 程序是邏輯隔離的,它們不必做物理隔離。在某些情況下,將部分或者全部控制器程序與 broker 程序部署在一個節點上,有其存在的意義。這和 Zookeeper 程序和 Kafka broker 部署在同一個節點上(目前小型叢集的部署方式)類似。通常,各種各樣的部署方式都可能出現,包括在同一個 JVM 中執行。
控制器 Quorum
控制器節點由管理後設資料紀錄檔的 Raft quorum(Raft 選舉機制)組成。該紀錄檔包括每次變更叢集的後設資料相關資訊。目前,一切資訊都儲存在 Zookeeper 中,比如 topic、partition、ISR、設定等,在新的架構中,這些資訊都將存在紀錄檔中。
通過 Raft 演演算法,控制器節點將在它們之間選舉 leader,不需要依賴任何外部系統。後設資料紀錄檔的 leader 被稱作活動的(active)控制器。活動控制器處理所有來自 broker 的 RPC 呼叫。follower 控制器(相對 leader 控制來說)從活動控制器中複製所有寫入的資料,並且當活動控制器故障時,做為熱備(hot standbys)。由於控制器全量追蹤最新狀態,控制器故障切換將不再需要花很多時間轉移最新狀態到新的控制器上。
和 Zookeeper 一樣,Raft 需要大多數節點能正常執行,才能正常工作。因此,3 個節點控制器叢集允許一個節點失效。5 個節點的控制器叢集允許兩個節點失效,以此類推。
控制器將按週期將後設資料快照寫入磁碟。雖然在概念上和壓縮相似,但是程式碼路徑有些許不同,原因是我們從記憶體中讀取狀態,而不是從磁碟中重讀紀錄檔。
管理 broker 後設資料
不同於控制器將更新推播至各個 broker,這些 broker 將通過新的 MetadataFetch API 從活動控制器拉取更新。
MetadataFetch 與拉取請求類似。就和拉取請求一樣,broker 將記錄最近一次拉取的更新的 offset,並且只從活動控制器請求新的更新。
broker 將拉取到的後設資料持久化至磁碟。這將使得 broker 啟動的非常快,即使有成百上千分割區,甚至上百萬個分割區。(注意,這種持久化是一種優化,如果忽略這種優化可以提高開發效率,那麼我們可以在第一個版本中忽略它)
大多數時候,broker 只需要拉取增量狀態(deltas),而不是全量狀態。無論如何,如果 broker 的狀態與活動控制器的狀態差距過大,或者 broker 完全沒有快取後設資料,控制器將返回全量後設資料映象,而不是返回一些列的增量資料。
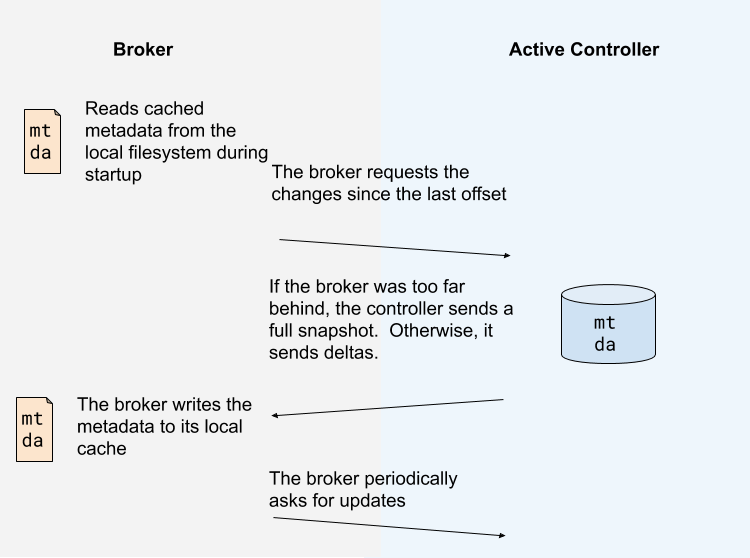
broker 按週期從活動控制器中請求後設資料更新。該請求同時做為心跳傳送,控制器以此得知該 broker 是存活狀態。
注意,雖然本節只討論管理 broker 的後設資料,但是管理使用者端的後設資料對於可伸縮性也很重要。一旦傳送增量後設資料更新的基礎設施搭建好後,這些基礎設施將用於使用者端和 broker。畢竟,一般情形下,使用者端的數量會大於 broker 的數量。隨著分割區數量的增長,使用者端感興趣的分割區也會越多,所以,以增量的方式將後設資料更新交付給使用者端將變得越來越重要。我們將在接下來的幾個小節中討論這個問題。
broker 狀態機
目前,broker 在啟動以後,馬上在 Zookeeper 中註冊自己。註冊的過程完成兩件事:告訴 broker 它是否被選舉為控制器,讓其他節點知道如何和它聯絡。
在後 Zookeeper 時代的世界裡,broker 通過控制器 quorum 註冊自己,而不是 Zookeeper。
當前,一個能夠聯絡 Zookeeper ,但由控制器分割區的 broker,能繼續為使用者的請求提供服務,但不會接收任何後設資料更新。這將導致一些令人困惑、難以應對的情況。例如,一個 producer 通過 acks=1 繼續傳送資料給 leader,但實際上該 leader 已經不再是真正的 leader,但是這個失效的 leader 無法接收控制器的 LeaderAndIsrRequest,從而移除 leader 地位。
在後 ZK 時代的世界裡,叢集的成員關係整合在後設資料更新中。如果 broker 無法接收後設資料更新,將從叢集的成員中移除。雖然該 broker 仍然可能被某個特殊的使用者端分割區,但如果該 broker 是由控制器分割區的,仍將從叢集中移除。
broker 狀態
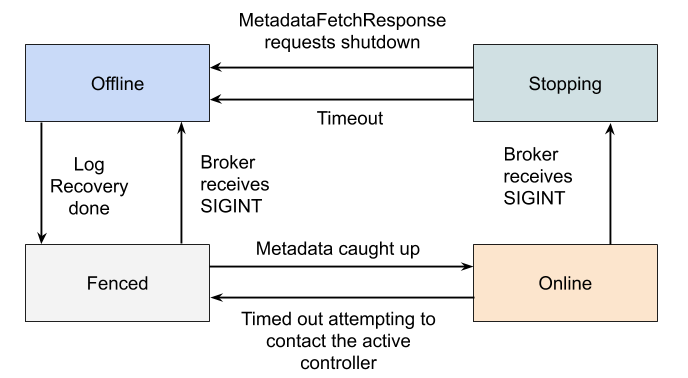
Offline
當 broker 程序為 Offline 狀態,它要麼沒有啟動,要麼在執行啟動所需的單節點任務,比如,初始化 JVM 或者執行恢復紀錄檔。
Fenced
當 broker 處於 Fenced 狀態,它將不再響應來自使用者端的 RPC 請求。broker 在啟動後,嘗試拉取最新的後設資料時,將處於 fenced 狀態。如果無法聯絡活動控制器,broker 將重新進入 fenced 狀態。發給使用者端的後設資料應該忽略狀態為 fenced 的 broker。
Online
當 broker 狀態為 online 時,表示該 broker 準備好響應使用者端的請求了。
Stopping
broker 進入 stoppoing 狀態表示它們收到 SIGINT 訊號。該訊號表明系統管理員要關閉 broker。
broker 在 stopping 狀態時,仍在執行,但是我們嘗試將分割區 leader 從 broker 中移除。
最後,活動控制器在 MetadataFetchResponse 中新增一串特殊的程式碼,要求 broker 進入 offline 狀態。或者,如果 leader 在預先定義的時間內沒有動作,broker 將關閉。
將已有的 API 遷移到控制器中
之前的很多直接寫入 Zookeeper 的操作將變為寫入控制器。例如,變更設定、修改儲存預設授權的 ACLs,等等。
新版本的使用者端應該將這些操作直接發給活動控制器。這是一個向後相容的變更:在新舊叢集中都能正常工作。為了相容老使用者端,這些操作將隨機傳送給 broker,broker 將這些請求轉發給活動控制器。
新的控制器 API
在某些情況下,我們需要建立一個新的 API 替換之前通過 Zookeeper 完成的操作。例如,當分割區 leader 要修改 in-sync replica 集合時,在後 ZK 時代的世界裡,它直接修改 Zookeeper,現在,leader 發起一個 RPC 請求到活動控制器。
從工具包中移除直接存取 Zookeeper
目前,一些工具和指令碼直接聯絡 Zookeeper。在後 Zookeeper 時代的世界裡,這些工具將被 Kafka API 取代。幸運的是,「KIP-4:命令列和中心化管理操作」,在幾年前開始移除直接存取 Zookeeper,並且快完成了。