萬字長文詳解 YOLOv1-v5 系列模型
一,YOLOv1
YOLOv1 出自 2016 CVPR 論文 You Only Look Once:Unified, Real-Time Object Detection.
YOLO 系列演演算法的核心思想是將輸入的影象經過 backbone 提取特徵後,將得到特徵圖劃分為 S x S 的網格,物體的中心落在哪一個網格內,這個網格就負責預測該物體的置信度、類別以及座標位置。
Abstract
作者提出了一種新的目標檢測方法 YOLO,之前的目標檢測工作都是重新利用分類器來執行檢測。作者的神經網路模型是端到端的檢測,一次執行即可同時得到所有目標的邊界框和類別概率。
YOLO 架構的速度是非常快的,base 版本實時影格率為 45 幀,smaller 版本能達到每秒 155 幀,效能由於 DPM 和 R-CNN 等檢測方法。
1. Introduction
之前的目標檢測器是重用分類器來執行檢測,為了檢測目標,這些系統在影象上不斷遍歷一個框,並利用分類器去判斷這個框是不是目標。像可變形部件模型(DPM)使用互動視窗方法,其分類器在整個影象的均勻間隔的位置上執行。
作者將目標檢測看作是單一的迴歸問題,直接從影象畫素得到邊界框座標和類別概率。
YOLO 檢測系統如圖 1 所示。單個檢測折積網路可以同時預測多個目標的邊界框和類別概率。YOLO 和傳統的目標檢測方法相比有諸多優點。

首先,YOLO 速度非常快,我們將檢測視為迴歸問題,所以檢測流程也簡單。其次,YOLO 在進行預測時,會對影象進行全面地推理。第三,YOLO 模型具有泛化能力,其比 DPM 和R-CNN 更好。最後,雖然 YOLO 模型在精度上依然落後於最先進(state-of-the-art)的檢測系統,但是其速度更快。
2. Unified Detectron
YOLO 系統將輸入影象劃分成 \(S\times S\) 的網格(grid),然後讓每個gird 負責檢測那些中心點落在 grid 內的目標。
檢測任務:每個網路都會預測 \(B\) 個邊界框及邊界框的置信度分數,所謂置信度分數其實包含兩個方面:一個是邊界框含有目標的可能性,二是邊界框的準確度。前者記為 \(Pr(Object)\),當邊界框包含目標時,\(Pr(Object)\) 值為 1,否則為 0;後者記為 \(IOU_{pred}^{truth}\),即預測框與真實框的 IOU。因此形式上,我們將置信度定義為 \(Pr(Object)*IOU_{pred}^{truth}\)。如果 grid 不存在目標,則置信度分數置為 0,否則,置信度分數等於預測框和真實框之間的交集(IoU)。
每個邊界框(bounding box)包含 5 個預測變數:\(x\),\(y\),\(w\),\(h\) 和 confidence。\((x,y)\) 座標不是邊界框中心的實際座標,而是相對於網格單元左上角座標的偏移(需要看程式碼才能懂,論文只描述了出「相對」的概念)。而邊界框的寬度和高度是相對於整個圖片的寬與高的比例,因此理論上以上 4 預測量都應該在 \([0,1]\) 範圍之內。最後,置信度預測表示預測框與實際邊界框之間的 IOU。
值得注意的是,中心座標的預測值 \((x,y)\) 是相對於每個單元格左上角座標點的偏移值,偏移量 = 目標位置 - grid的位置。

分類任務:每個網格單元(grid)還會預測 \(C\) 個類別的概率 \(Pr(Class_i)|Object)\)。grid 包含目標時才會預測 \(Pr\),且只預測一組類別概率,而不管邊界框 \(B\) 的數量是多少。
在推理時,我們乘以條件概率和單個 box 的置信度。
它為我們提供了每個框特定類別的置信度分數。這些分數編碼了該類出現在框中的概率以及預測框擬合目標的程度。
在 Pscal VOC 資料集上評測 YOLO 模型時,我們設定 \(S=7\), \(B=2\)(即每個 grid 會生成 2 個邊界框)。Pscal VOC 資料集有 20 個類別,所以 \(C=20\)。所以,模型最後預測的張量維度是 \(7 \times 7\times (20+5*2) = 1470\)。
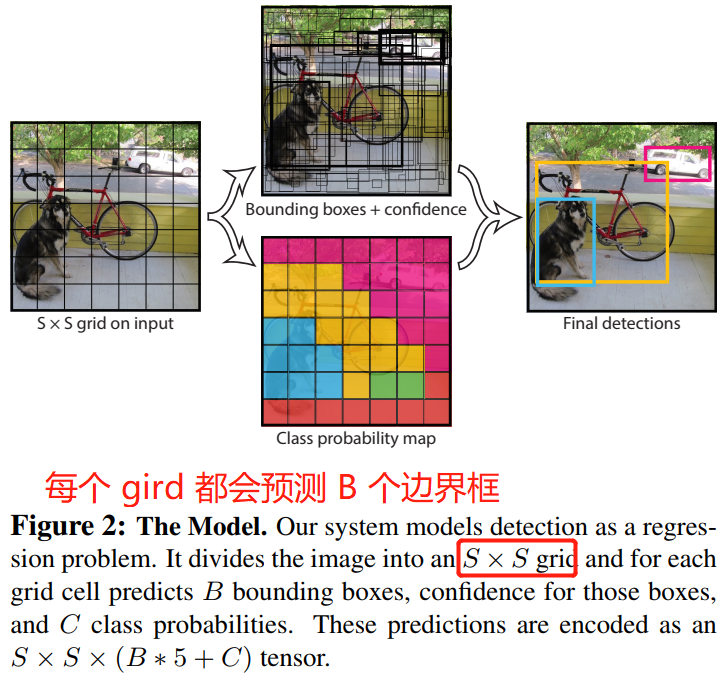
總結:YOLO 系統將檢測建模為迴歸問題。它將影象分成 \(S \times S\) 的 gird,每個 grid 都會預測 \(B\) 個邊界框,同時也包含 \(C\) 個類別的概率,這些預測對應的就是 \(S \times S \times (C + 5*B)\)。
這裡其實就是在描述 YOLOv1 檢測頭如何設計:迴歸網路的設計 + 訓練集標籤如何構建(即 yoloDataset 類的構建),下面給出一份針對 voc 資料集編碼為 yolo 模型的輸入標籤資料的函數,讀懂了這個程式碼,就能理解前面部分的描述。
程式碼來源這裡。
def encoder(self, boxes, labels):
'''
boxes (tensor) [[x1,y1,x2,y2],[]] 目標的邊界框座標資訊
labels (tensor) [...] 目標的類別資訊
return 7x7x30
'''
grid_num = 7 # 論文中設為7
target = torch.zeros((grid_num, grid_num, 30)) # 和模型輸出張量維尺寸一樣都是 14*14*30
cell_size = 1./grid_num # 之前已經把目標框的座標進行了歸一化(這裡與原論文有區別),故這裡用1.作為除數
# 計算目標框中心點座標和寬高
wh = boxes[:, 2:]-boxes[:, :2]
cxcy = (boxes[:, 2:]+boxes[:, :2])/2
# 1,遍歷各個目標框;
for i in range(cxcy.size()[0]): # 對應於資料集中的每個框 這裡cxcy.size()[0] == num_samples
# 2,計算第 i 個目標中心點落在哪個 `grid` 上,`target` 相應位置的兩個框的置信度值設為 `1`,同時對應類別值也置為 `1`;
cxcy_sample = cxcy[i]
ij = (cxcy_sample/cell_size).ceil()-1 # ij 是一個list, 表示目標中心點cxcy在歸一化後的圖片中所處的x y 方向的第幾個網格
# [0,1,2,3,4,5,6,7,8,9, 10-19] 對應索引
# [x,y,w,h,c,x,y,w,h,c, 20 個類別的 one-hot編碼] 與原論文輸出張量維度各個索引對應目標有所區別
target[int(ij[1]), int(ij[0]), 4] = 1 # 第一個框的置信度
target[int(ij[1]), int(ij[0]), 9] = 1 # 第二個框的置信度
target[int(ij[1]), int(ij[0]), int(labels[i])+9] = 1 # 第 int(labels[i])+9 個類別為 1
# 3,計算目標中心所在 `grid`(網格)的左上角相對座標:`ij*cell_size`,然後目標中心座標相對於子網格左上角的偏移比例 `delta_xy`;
xy = ij*cell_size
delta_xy = (cxcy_sample -xy)/cell_size
# 4,最後將 `target` 對應網格位置的 (x, y, w, h) 分別賦相應 `wh`、`delta_xy` 值。
target[int(ij[1]), int(ij[0]), 2:4] = wh[i] # 範圍為(0,1)
target[int(ij[1]), int(ij[0]), :2] = delta_xy
target[int(ij[1]), int(ij[0]), 7:9] = wh[i]
target[int(ij[1]), int(ij[0]), 5:7] = delta_xy
return target
程式碼分析,一張圖片對應的標籤張量 target 的維度是 \(7 \times 7 \times 30\)。然後分別對各個目標框的 boxes: \((x1,y1,x2,y2)\) 和 labels:(0,0,...,1,0)(one-hot 編碼的目標類別資訊)進行處理,符合檢測系統要求的輸入形式。演演算法步驟如下:
- 計算目標框中心點座標和寬高,並遍歷各個目標框;
- 計算目標中心點落在哪個
grid上,target相應位置的兩個框的置信度值設為1,同時對應類別值也置為1; - 計算目標中心所在
grid(網格)的左上角相對座標:ij*cell_size,然後目標中心座標相對於子網格左上角的偏移比例delta_xy; - 最後將
target對應網格位置的 \((x, y, w, h)\) 分別賦相應wh、delta_xy值。
2.1. Network Design
YOLO 模型使用折積神經網路來實現,折積層負責從影象中提取特徵,全連線層預測輸出類別概率和座標。
YOLO 的網路架構受 GooLeNet 影象分類模型的啟發。網路有 24 個折積層,最後面是 2 個全連線層。整個網路的折積只有 \(1 \times 1\) 和 \(3 \times 3\) 折積層,其中 \(1 \times 1\) 折積負責降維 ,而不是 GoogLeNet 的 Inception 模組。

圖3:網路架構。作者在 ImageNet 分類任務上以一半的解析度(輸入影象大小 \(224\times 224\))訓練折積層,但預測時解析度加倍。
Fast YOLO 版本使用了更少的折積,其他所有訓練引數及測試引數都和 base YOLO 版本是一樣的。
網路的最終輸出是 \(7\times 7\times 30\) 的張量。這個張量所代表的具體含義如下圖所示。對於每一個單元格,前 20 個元素是類別概率值,然後 2 個元素是邊界框置信度,兩者相乘可以得到類別置信度,最後 8 個元素是邊界框的 \((x,y,w,h)\) 。之所以把置信度 \(c\) 和 \((x,y,w,h)\) 都分開排列,而不是按照\((x,y,w,h,c)\) 這樣排列,存粹是為了後續計算時方便。

劃分 \(7 \times 7\) 網格,共
98個邊界框,2個框對應一個類別,所以YOLOv1只能在一個網格中檢測出一個目標、單張圖片最多預測49個目標。
2.2 Training
模型訓練最重要的無非就是超引數的調整和損失函數的設計。
因為 YOLO 演演算法將檢測問題看作是迴歸問題,所以自然地採用了比較容易優化的均方誤差作為損失函數,但是面臨定位誤差和分類誤差權重一樣的問題;同時,在每張影象中,許多網格單元並不包含物件,即負樣本(不包含物體的網格)遠多於正樣本(包含物體的網格),這通常會壓倒了正樣本的梯度,導致訓練早期模型發散。
為了改善這點,引入了兩個引數:\(\lambda_{coord}=5\) 和 \(\lambda_{noobj} =0.5\)。對於邊界框座標預測損失(定位誤差),採用較大的權重 \(\lambda_{coord} =5\),然後區分不包含目標的邊界框和含有目標的邊界框,前者採用較小權重 \(\lambda_{noobj} =0.5\)。其他權重則均設為 0。
對於大小不同的邊界框,因為較小邊界框的座標誤差比較大邊界框要更敏感,所以為了部分解決這個問題,將網路的邊界框的寬高預測改為對其平方根的預測,即預測值變為 \((x, y, \sqrt w, \sqrt h)\)。
YOLOv1 每個網格單元預測多個邊界框。在訓練時,每個目標我們只需要一個邊界框預測器來負責。我們指定一個預測器「負責」根據哪個預測與真實值之間具有當前最高的 IOU 來預測目標。這導致邊界框預測器之間的專業化。每個預測器可以更好地預測特定大小,方向角,或目標的類別,從而改善整體召回率。
YOLO由於每個網格僅能預測2個邊界框且僅可以包含一個類別,因此是對於一個單元格存在多個目標的問題,YOLO只能選擇一個來預測。這使得它在預測臨近物體的數量上存在不足,如鋼筋、人臉和鳥群檢測等。
最終網路總的損失函數計算公式如下:
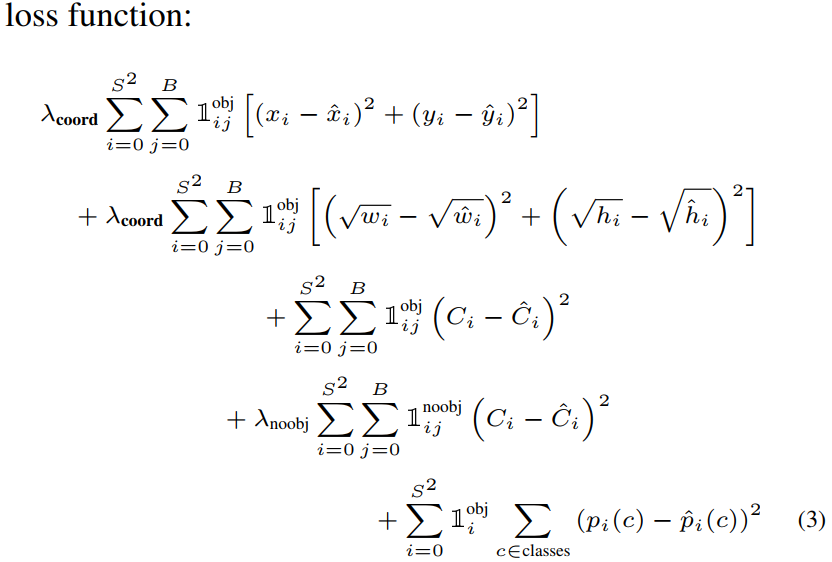
\(I_{ij}^{obj}\) 指的是第 \(i\) 個單元格存在目標,且該單元格中的第 \(j\) 個邊界框負責預測該目標。 \(I_{i}^{obj}\) 指的是第 \(i\) 個單元格存在目標。
- 前 2 行計算前景的
geo_loss(定位loss)。 - 第 3 行計算前景的
confidence_loss(包含目標的邊界框的置信度誤差項)。 - 第 4 行計算背景的
confidence_loss。 - 第 5 行計算分類損失
class_loss。
值得注意的是,對於不存在對應目標的邊界框,其誤差項就是隻有置信度,座標項誤差是沒法計算的。而只有當一個單元格內確實存在目標時,才計算分類誤差項,否則該項也是無法計算的。
2.4. Inferences
同樣採用了 NMS 演演算法來抑制多重檢測,對應的模型推理結果解碼程式碼如下,這裡要和前面的 encoder 函數結合起來看。
# 對於網路輸出預測 改為再圖片上畫出框及score
def decoder(pred):
"""
pred (tensor) torch.Size([1, 7, 7, 30])
return (tensor) box[[x1,y1,x2,y2]] label[...]
"""
grid_num = 7
boxes = []
cls_indexs = []
probs = []
cell_size = 1./grid_num
pred = pred.data # torch.Size([1, 14, 14, 30])
pred = pred.squeeze(0) # torch.Size([14, 14, 30])
# 0 1 2 3 4 5 6 7 8 9
# [中心座標,長寬,置信度,中心座標,長寬,置信度, 20個類別] x 7x7
contain1 = pred[:, :, 4].unsqueeze(2) # torch.Size([14, 14, 1])
contain2 = pred[:, :, 9].unsqueeze(2) # torch.Size([14, 14, 1])
contain = torch.cat((contain1, contain2), 2) # torch.Size([14, 14, 2])
mask1 = contain > 0.1 # 大於閾值, torch.Size([14, 14, 2]) content: tensor([False, False])
mask2 = (contain == contain.max()) # we always select the best contain_prob what ever it>0.9
mask = (mask1+mask2).gt(0)
# min_score,min_index = torch.min(contain, 2) # 每個 cell 只選最大概率的那個預測框
for i in range(grid_num):
for j in range(grid_num):
for b in range(2):
# index = min_index[i,j]
# mask[i,j,index] = 0
if mask[i, j, b] == 1:
box = pred[i, j, b*5:b*5+4]
contain_prob = torch.FloatTensor([pred[i, j, b*5+4]])
xy = torch.FloatTensor([j, i])*cell_size # cell左上角 up left of cell
box[:2] = box[:2]*cell_size + xy # return cxcy relative to image
box_xy = torch.FloatTensor(box.size()) # 轉換成xy形式 convert[cx,cy,w,h] to [x1,y1,x2,y2]
box_xy[:2] = box[:2] - 0.5*box[2:]
box_xy[2:] = box[:2] + 0.5*box[2:]
max_prob, cls_index = torch.max(pred[i, j, 10:], 0)
if float((contain_prob*max_prob)[0]) > 0.1:
boxes.append(box_xy.view(1, 4))
cls_indexs.append(cls_index.item())
probs.append(contain_prob*max_prob)
if len(boxes) == 0:
boxes = torch.zeros((1, 4))
probs = torch.zeros(1)
cls_indexs = torch.zeros(1)
else:
boxes = torch.cat(boxes, 0) # (n,4)
# print(type(probs))
# print(len(probs))
# print(probs)
probs = torch.cat(probs, 0) # (n,)
# print(probs)
# print(type(cls_indexs))
# print(len(cls_indexs))
# print(cls_indexs)
cls_indexs = torch.IntTensor(cls_indexs) # (n,)
# 去除冗餘的候選框,得到最佳檢測框(bbox)
keep = nms(boxes, probs)
# print("keep:", keep)
a = boxes[keep]
b = cls_indexs[keep]
c = probs[keep]
return a, b, c
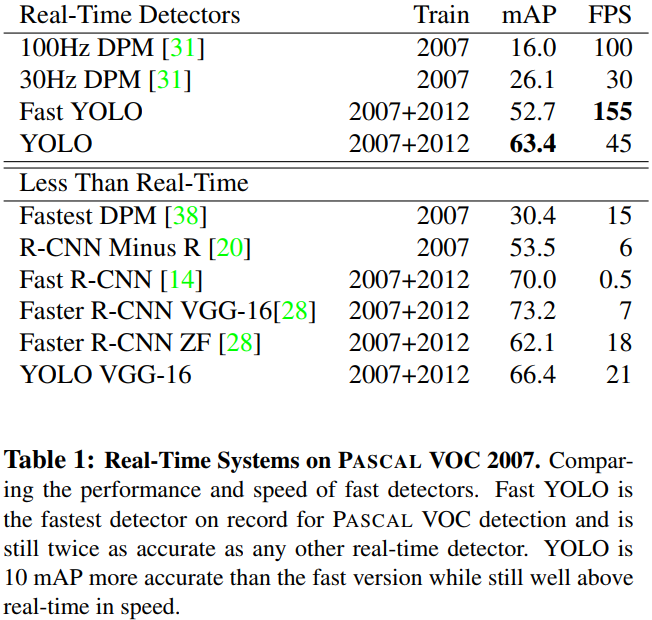
4.1 Comparison to Other Real-Time Systems
基於 GPU Titan X 硬體環境下,與他檢測演演算法的效能比較如下。
5,程式碼實現思考
一些思考:快速的閱讀了網上的一些 YOLOv1 程式碼實現,發現整個 YOLOv1 檢測系統的程式碼可以分為以下幾個部分:
- 模型結構定義:特徵提器模組 + 檢測頭模組(兩個全連線層)。
- 資料預處理,最難寫的程式碼,需要對原有的
VOC資料做預處理,編碼成YOLOv1要求的格式輸入,訓練集的label的shape為(bach_size, 7, 7, 30)。 - 模型訓練,主要由損失函數的構建組成,損失函數包括
5個部分。 - 模型預測,主要在於模型輸出的解析,即解碼成可方便顯示的形式。
二,YOLOv2
YOLO9000是CVPR2017的最佳論文提名,但是這篇論文其實提出了YOLOv2和YOLO9000兩個模型,二者略有不同。前者主要是YOLO的升級版,後者的主要檢測網路也是YOLOv2,同時對資料集做了融合,使得模型可以檢測9000多類物體。
摘要
YOLOv2 其實就是 YOLO9000,作者在 YOLOv1 基礎上改進的一種新的 state-of-the-art 目標檢測模型,它能檢測多達 9000 個目標!利用了多尺度(multi-scale)訓練方法,YOLOv2 可以在不同尺寸的圖片上執行,並取得速度和精度的平衡。
在速度達到在 40 FPS 同時,YOLOv2 獲得 78.6 mAP 的精度,效能優於backbone 為 ResNet 的 Faster RCNN 和 SSD 等當前最優(state-of-the-art) 模型。最後作者提出一種聯合訓練目標檢測和分類的方法,基於這種方法,YOLO9000 能實時檢測多達 9000 種目標。
YOLOv1 雖然速度很快,但是還有很多缺點:
- 雖然每個
grid預測兩個框,但是隻能對應一個目標,對於同一個grid有著兩個目標的情況下,YOLOv1是檢測不全的,且模型最多檢測 \(7 \times 7 = 49\) 個目標,即表現為模型查全率低。 - 預測框不夠準確,之前回歸 \((x,y,w,h)\) 的方法不夠精確,即表現為模型精確率低。
- 迴歸引數網路使用全連線層引數量太大,即模型檢測頭還不夠塊。
YOLOv2 的改進
1,中心座標位置預測的改進
YOLOv1 模型預測的邊界框中心座標 \((x,y)\) 是基於 grid 的偏移,這裡 grid 的位置是固定劃分出來的,偏移量 = 目標位置 - grid 的位置。
邊界框的編碼過程:YOLOv2 參考了兩階段網路的 anchor boxes 來預測邊界框相對先驗框的偏移,同時沿用 YOLOv1 的方法預測邊界框中心點相對於 grid 左上角位置的相對偏移值。\((x,y,w,h)\) 的偏移值和實際座標值的關係如下圖所示。
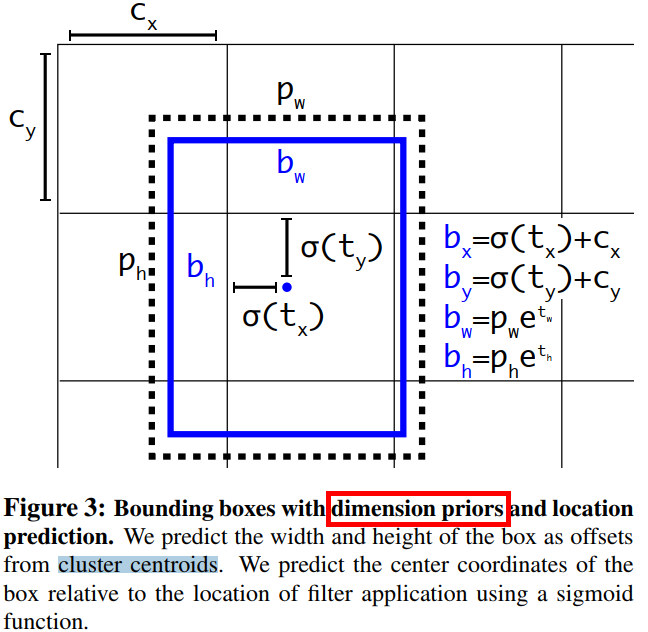
各個字母的含義如下:
- \(b_x,b_y,b_w,b_h\) :模型預測結果轉化為
box中心座標和寬高後的值 - \(t_x,t_y,t_w,t_h\) :模型要預測的偏移量。
- \(c_x,c_y\) :
grid的左上角座標,如上圖所示。 - \(p_w,p_h\) :
anchor的寬和高,這裡的anchor是人為定好的一個框,寬和高是固定的。
通過以上定義我們從直接預測位置改為預測一個偏移量,即基於 anchor 框的寬高和 grid 的先驗位置的偏移量,位置上使用 grid,寬高上使用 anchor 框,得到最終目標的位置,這種方法叫作 location prediction。
預測偏移不直接預測位置,是因為作者發現直接預測位置會導致神經網路在一開始訓練時不穩定,使用偏移量會使得訓練過程更加穩定,效能指標提升了
5%左右。
在資料集的預處理過程中,關鍵的邊界框編碼函數如下(程式碼來自 github,這個版本更清晰易懂):
def encode(self, boxes, labels, input_size):
'''Encode target bounding boxes and class labels into YOLOv2 format.
Args:
boxes: (tensor) bounding boxes of (xmin,ymin,xmax,ymax) in range [0,1], sized [#obj, 4].
labels: (tensor) object class labels, sized [#obj,].
input_size: (int) model input size.
Returns:
loc_targets: (tensor) encoded bounding boxes, sized [5,4,fmsize,fmsize].
cls_targets: (tensor) encoded class labels, sized [5,20,fmsize,fmsize].
box_targets: (tensor) truth boxes, sized [#obj,4].
'''
num_boxes = len(boxes)
# input_size -> fmsize
# 320->10, 352->11, 384->12, 416->13, ..., 608->19
fmsize = (input_size - 320) / 32 + 10
grid_size = input_size / fmsize
boxes *= input_size # scale [0,1] -> [0,input_size]
bx = (boxes[:,0] + boxes[:,2]) * 0.5 / grid_size # in [0,fmsize]
by = (boxes[:,1] + boxes[:,3]) * 0.5 / grid_size # in [0,fmsize]
bw = (boxes[:,2] - boxes[:,0]) / grid_size # in [0,fmsize]
bh = (boxes[:,3] - boxes[:,1]) / grid_size # in [0,fmsize]
tx = bx - bx.floor()
ty = by - by.floor()
xy = meshgrid(fmsize, swap_dims=True) + 0.5 # grid center, [fmsize*fmsize,2]
wh = torch.Tensor(self.anchors) # [5,2]
xy = xy.view(fmsize,fmsize,1,2).expand(fmsize,fmsize,5,2)
wh = wh.view(1,1,5,2).expand(fmsize,fmsize,5,2)
anchor_boxes = torch.cat([xy-wh/2, xy+wh/2], 3) # [fmsize,fmsize,5,4]
ious = box_iou(anchor_boxes.view(-1,4), boxes/grid_size) # [fmsize*fmsize*5,N]
ious = ious.view(fmsize,fmsize,5,num_boxes) # [fmsize,fmsize,5,N]
loc_targets = torch.zeros(5,4,fmsize,fmsize) # 5boxes * 4coords
cls_targets = torch.zeros(5,20,fmsize,fmsize)
for i in range(num_boxes):
cx = int(bx[i])
cy = int(by[i])
_, max_idx = ious[cy,cx,:,i].max(0)
j = max_idx[0]
cls_targets[j,labels[i],cy,cx] = 1
tw = bw[i] / self.anchors[j][0]
th = bh[i] / self.anchors[j][1]
loc_targets[j,:,cy,cx] = torch.Tensor([tx[i], ty[i], tw, th])
return loc_targets, cls_targets, boxes/grid_size
邊界框的解碼過程:雖然模型預測的是邊界框的偏移量 \((t_x,t_y,t_w,t_h)\),但是可通過以下公式計算出邊界框的實際位置。
其中,\((c_x, c_y)\) 為 grid 的左上角座標,因為 \(\sigma\) 表示的是 sigmoid 函數,所以邊界框的中心座標會被約束在 grid 內部,防止偏移過多。\(p_w\)、\(p_h\) 是先驗框(anchors)的寬度與高度,其值相對於特徵圖大小 \(W\times H\) = \(13\times 13\) 而言的,因為劃分為 \(13 \times 13\) 個 grid,所以最後輸出的特徵圖中每個 grid 的長和寬均是 1。知道了特徵圖的大小,就可以將邊界框相對於整個特徵圖的位置和大小計算出來(均取值 \({0,1}\))。
在模型推理的時候,將以上 4 個值分別乘以圖片的寬度和長度(畫素點值)就可以得到邊界框的實際中心座標和大小。
在模型推理過程中,模型輸出張量的解析,即邊界框的解碼函數如下:
def decode(self, outputs, input_size):
'''Transform predicted loc/conf back to real bbox locations and class labels.
Args:
outputs: (tensor) model outputs, sized [1,125,13,13].
input_size: (int) model input size.
Returns:
boxes: (tensor) bbox locations, sized [#obj, 4].
labels: (tensor) class labels, sized [#obj,1].
'''
fmsize = outputs.size(2)
outputs = outputs.view(5,25,13,13)
loc_xy = outputs[:,:2,:,:] # [5,2,13,13]
grid_xy = meshgrid(fmsize, swap_dims=True).view(fmsize,fmsize,2).permute(2,0,1) # [2,13,13]
box_xy = loc_xy.sigmoid() + grid_xy.expand_as(loc_xy) # [5,2,13,13]
loc_wh = outputs[:,2:4,:,:] # [5,2,13,13]
anchor_wh = torch.Tensor(self.anchors).view(5,2,1,1).expand_as(loc_wh) # [5,2,13,13]
box_wh = anchor_wh * loc_wh.exp() # [5,2,13,13]
boxes = torch.cat([box_xy-box_wh/2, box_xy+box_wh/2], 1) # [5,4,13,13]
boxes = boxes.permute(0,2,3,1).contiguous().view(-1,4) # [845,4]
iou_preds = outputs[:,4,:,:].sigmoid() # [5,13,13]
cls_preds = outputs[:,5:,:,:] # [5,20,13,13]
cls_preds = cls_preds.permute(0,2,3,1).contiguous().view(-1,20)
cls_preds = softmax(cls_preds) # [5*13*13,20]
score = cls_preds * iou_preds.view(-1).unsqueeze(1).expand_as(cls_preds) # [5*13*13,20]
score = score.max(1)[0].view(-1) # [5*13*13,]
print(iou_preds.max())
print(cls_preds.max())
print(score.max())
ids = (score>0.5).nonzero().squeeze()
keep = box_nms(boxes[ids], score[ids]) # NMS 演演算法去除重複框
return boxes[ids][keep] / fmsize
2,1 個 gird 只能對應一個目標的改進
或者說很多目標預測不到,查全率低的改進
YOLOv2 首先把 \(7 \times 7\) 個區域改為 \(13 \times 13\) 個 grid(區域),每個區域有 5 個anchor,且每個 anchor 對應著 1 個類別,那麼,輸出的尺寸就應該為:[N,13,13,125]
\(125 = 5 \times (5 + 20)\)

值得注意的是之前 YOLOv1 的每個 grid 只能預測一個目標的分類概率值,兩個 boxes 共用這個置信度概率。現在 YOLOv2 使用了 anchor 先驗框後,每個 grid 的每個 anchor 都單獨預測一個目標的分類概率值。
之所以每個 grid 取 5 個 anchor,是因為作者對 VOC/COCO 資料集進行 K-means 聚類實驗,發現當 k=5 時,模型 recall vs. complexity 取得了較好的平衡。當然,\(k\) 越好,mAP 肯定越高,但是為了平衡模型複雜度,作者選擇了 5 個聚類簇,即劃分成 5 類先驗框。設定先驗框的主要目的是為了使得預測框與 ground truth 的 IOU 更好,所以聚類分析時選用 box 與聚類中心 box 之間的 IOU 值作為距離指標:
與
Faster RCNN手動設定anchor的大小和寬高比不同,YOLOv2 的 anchor 是從資料集中統計得到的。
3,backbone 的改進
作者提出了一個全新的 backbone 網路:Darknet-19,它是基於前人經典工作和該領域常識的基礎上進行設計的。Darknet-19 網路和 VGG 網路類似,主要使用 \(3 \times 3\) 折積,並且每個 \(2 \times 2\) pooling 操作之後將特徵圖通道數加倍。借鑑 NIN 網路的工作,作者使用 global average pooling 進行預測,並在 \(3 \times 3\) 折積之間使用 \(1 \times 1\) 折積來降低特徵圖通道數從而降低模型計算量和引數量。Darknet-19 網路的每個折積層後面都是用了 BN 層來加快模型收斂,防止模型過擬合。
Darknet-19 網路總共有 19 個折積層(convolution)、5 最大池化層(maxpooling)。Darknet-19 以 5.58 T的計算量在 ImageNet 資料集上取得了 72.9% 的 top-1 精度和 91.2% 的 top-5 精度。Darket19 網路參數列如下圖所示。
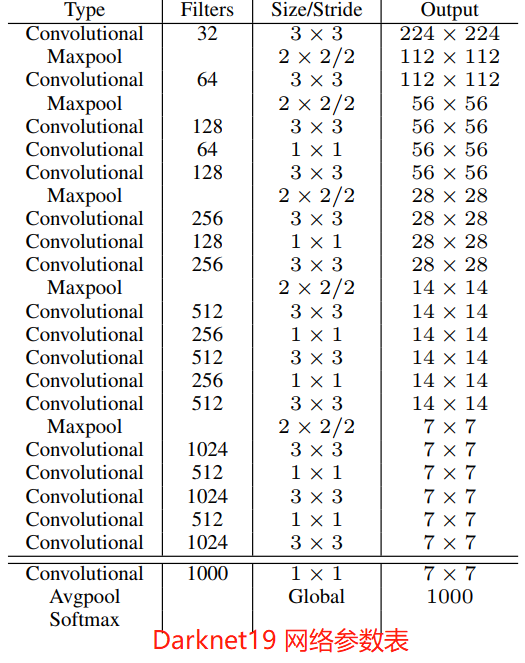
檢測訓練。在 Darknet19 網路基礎上進行修改後用於目標檢測。首先,移除網路的最後一個折積層,然後新增濾波器個數為 1024 的 \(3 \times 3\) 折積層,最後新增一個 \(1 \times 1\) 折積層,其濾波器個數為模型檢測需要輸出的變數個數。對於 VOC 資料集,每個 grid 預測 5 個邊界框,每個邊界框有 5 個座標(\(t_x, t_y, t_w, t_h \ 和\ t_o\))和 20 個類別,所以共有 125 個濾波器。我們還新增了從最後的 3×3×512 層到倒數第二層折積層的直通層,以便模型可以使用細粒度特徵。
Yolov2 整個模型結構程式碼如下:
程式碼來源 這裡。
'''Darknet in PyTorch.'''
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as F
from torch.autograd import Variable
class Darknet(nn.Module):
# (64,1) means conv kernel size is 1, by default is 3.
cfg1 = [32, 'M', 64, 'M', 128, (64,1), 128, 'M', 256, (128,1), 256, 'M', 512, (256,1), 512, (256,1), 512] # conv1 - conv13
cfg2 = ['M', 1024, (512,1), 1024, (512,1), 1024] # conv14 - conv18
def __init__(self):
super(Darknet, self).__init__()
self.layer1 = self._make_layers(self.cfg1, in_planes=3)
self.layer2 = self._make_layers(self.cfg2, in_planes=512)
#### Add new layers
self.conv19 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=1)
self.bn19 = nn.BatchNorm2d(1024)
self.conv20 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=1)
self.bn20 = nn.BatchNorm2d(1024)
# Currently I removed the passthrough layer for simplicity
self.conv21 = nn.Conv2d(1024, 1024, kernel_size=3, stride=1, padding=1)
self.bn21 = nn.BatchNorm2d(1024)
# Outputs: 5boxes * (4coordinates + 1confidence + 20classes)
self.conv22 = nn.Conv2d(1024, 5*(5+20), kernel_size=1, stride=1, padding=0)
def _make_layers(self, cfg, in_planes):
layers = []
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
out_planes = x[0] if isinstance(x, tuple) else x
ksize = x[1] if isinstance(x, tuple) else 3
layers += [nn.Conv2d(in_planes, out_planes, kernel_size=ksize, padding=(ksize-1)//2),
nn.BatchNorm2d(out_planes),
nn.LeakyReLU(0.1, True)]
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = F.leaky_relu(self.bn19(self.conv19(out)), 0.1)
out = F.leaky_relu(self.bn20(self.conv20(out)), 0.1)
out = F.leaky_relu(self.bn21(self.conv21(out)), 0.1)
out = self.conv22(out)
return out
def test():
net = Darknet()
y = net(Variable(torch.randn(1,3,416,416)))
print(y.size()) # 模型最後輸出張量大小 [1,125,13,13]
if __name__ == "__main__":
test()
4,多尺度訓練
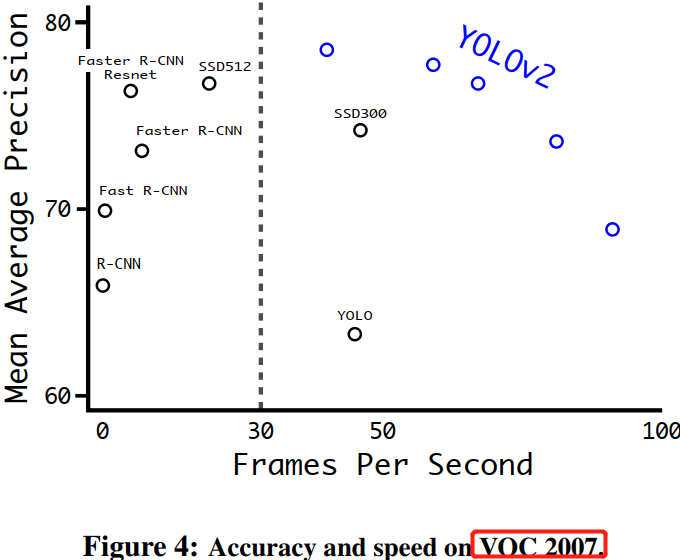
YOLOv1 輸入影象解析度為 \(448 \times 448\),因為使用了 anchor boxes,所以 YOLOv2 將輸入解析度改為 \(416 \times 416\)。又因為 YOLOv2 模型中只有折積層和池化層,所以YOLOv2的輸入可以不限於 \(416 \times 416\) 大小的圖片。為了增強模型的魯棒性,YOLOv2 採用了多尺度輸入訓練策略,具體來說就是在訓練過程中每間隔一定的 iterations 之後改變模型的輸入圖片大小。由於 YOLOv2 的下取樣總步長為 32,所以輸入圖片大小選擇一系列為 32 倍數的值: \(\lbrace 320, 352,...,608 \rbrace\) ,因此輸入圖片解析度最小為 \(320\times 320\),此時對應的特徵圖大小為 \(10\times 10\)(不是奇數),而輸入圖片最大為 \(608\times 608\) ,對應的特徵圖大小為 \(19\times 19\) 。在訓練過程,每隔 10 個 iterations 隨機選擇一種輸入圖片大小,然後需要修最後的檢測頭以適應維度變化後,就可以重新訓練。
採用 Multi-Scale Training 策略,YOLOv2 可以適應不同輸入大小的圖片,並且預測出很好的結果。在測試時,YOLOv2 可以採用不同大小的圖片作為輸入,在 VOC 2007 資料集上的測試結果如下圖所示。
損失函數
YOLOv2 的損失函數的計算公式歸納如下
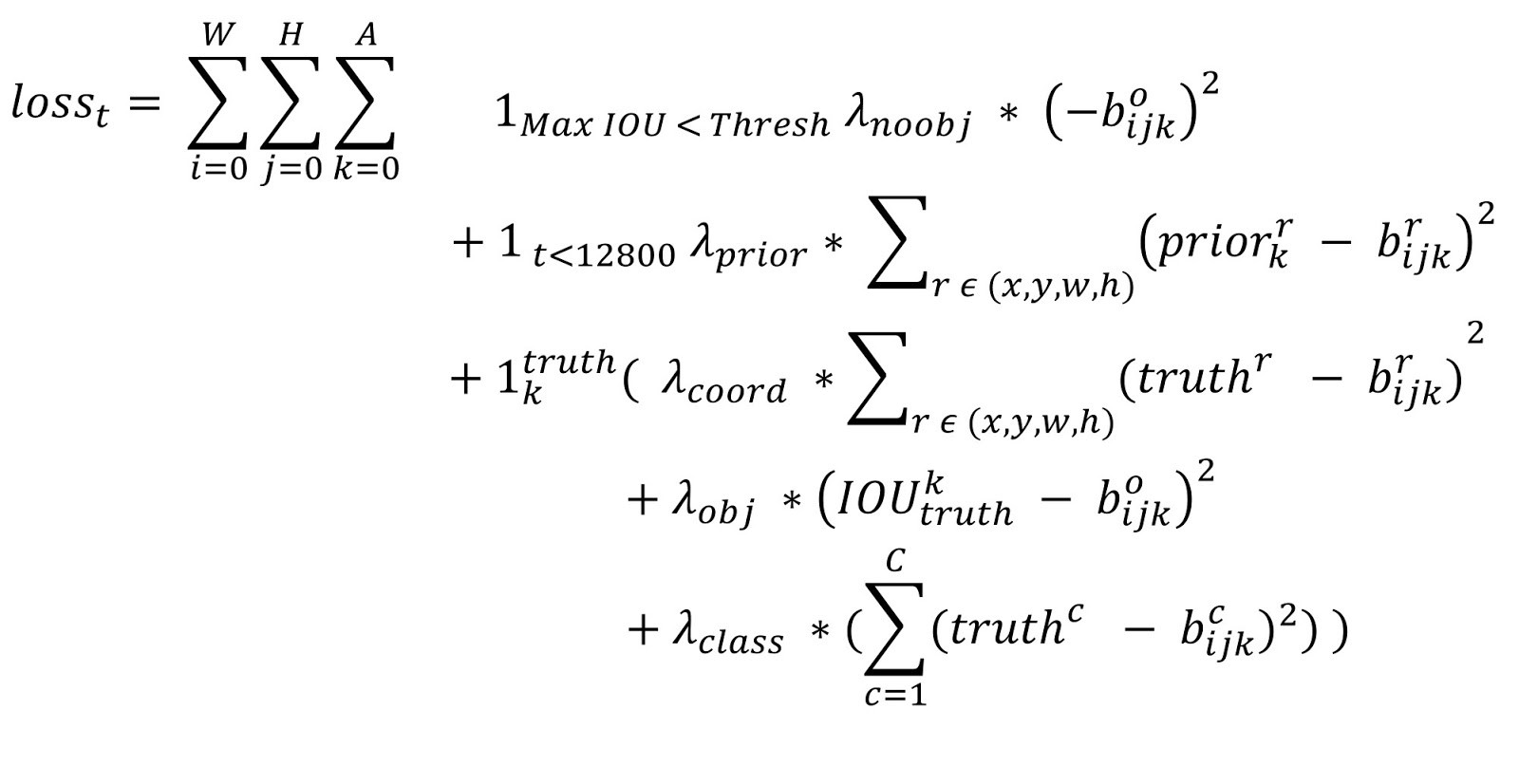
第 2,3 行:\(t\) 是迭代次數,即前 12800 步我們計算這個損失,後面不計算了。即前 12800 步我們會優化預測的 \((x,y,w,h)\) 與 anchor 的 \((x,y,w,h)\) 的距離 + 預測的 \((x,y,w,h)\) 與 GT 的 \((x,y,w,h)\) 的距離,12800 步之後就只優化預測的 \((x,y,w,h)\)與 GT 的 \((x,y,w,h)\) 的距離,原因是這時的預測結果已經較為準確了,anchor已經滿足檢測系統的需要,而在一開始預測不準的時候,用上 anchor 可以加速訓練。
YOLOv2 的損失函數實現程式碼如下,損失函數計算過程中的模型預測結果的解碼函數和前面的解碼函數略有不同,其包含關鍵部分目標 bbox 的解析。
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from utils import box_iou, meshgrid
class YOLOLoss(nn.Module):
def __init__(self):
super(YOLOLoss, self).__init__()
def decode_loc(self, loc_preds):
'''Recover predicted locations back to box coordinates.
Args:
loc_preds: (tensor) predicted locations, sized [N,5,4,fmsize,fmsize].
Returns:
box_preds: (tensor) recovered boxes, sized [N,5,4,fmsize,fmsize].
'''
anchors = [(1.3221,1.73145),(3.19275,4.00944),(5.05587,8.09892),(9.47112,4.84053),(11.2364,10.0071)]
N, _, _, fmsize, _ = loc_preds.size()
loc_xy = loc_preds[:,:,:2,:,:] # [N,5,2,13,13]
grid_xy = meshgrid(fmsize, swap_dims=True).view(fmsize,fmsize,2).permute(2,0,1) # [2,13,13]
grid_xy = Variable(grid_xy.cuda())
box_xy = loc_xy.sigmoid() + grid_xy.expand_as(loc_xy) # [N,5,2,13,13]
loc_wh = loc_preds[:,:,2:4,:,:] # [N,5,2,13,13]
anchor_wh = torch.Tensor(anchors).view(1,5,2,1,1).expand_as(loc_wh) # [N,5,2,13,13]
anchor_wh = Variable(anchor_wh.cuda())
box_wh = anchor_wh * loc_wh.exp() # [N,5,2,13,13]
box_preds = torch.cat([box_xy-box_wh/2, box_xy+box_wh/2], 2) # [N,5,4,13,13]
return box_preds
def forward(self, preds, loc_targets, cls_targets, box_targets):
'''
Args:
preds: (tensor) model outputs, sized [batch_size,150,fmsize,fmsize].
loc_targets: (tensor) loc targets, sized [batch_size,5,4,fmsize,fmsize].
cls_targets: (tensor) conf targets, sized [batch_size,5,20,fmsize,fmsize].
box_targets: (list) box targets, each sized [#obj,4].
Returns:
(tensor) loss = SmoothL1Loss(loc) + SmoothL1Loss(iou) + SmoothL1Loss(cls)
'''
batch_size, _, fmsize, _ = preds.size()
preds = preds.view(batch_size, 5, 4+1+20, fmsize, fmsize)
### loc_loss
xy = preds[:,:,:2,:,:].sigmoid() # x->sigmoid(x), y->sigmoid(y)
wh = preds[:,:,2:4,:,:].exp()
loc_preds = torch.cat([xy,wh], 2) # [N,5,4,13,13]
pos = cls_targets.max(2)[0].squeeze() > 0 # [N,5,13,13]
num_pos = pos.data.long().sum()
mask = pos.unsqueeze(2).expand_as(loc_preds) # [N,5,13,13] -> [N,5,1,13,13] -> [N,5,4,13,13]
loc_loss = F.smooth_l1_loss(loc_preds[mask], loc_targets[mask], size_average=False)
### iou_loss
iou_preds = preds[:,:,4,:,:].sigmoid() # [N,5,13,13]
iou_targets = Variable(torch.zeros(iou_preds.size()).cuda()) # [N,5,13,13]
box_preds = self.decode_loc(preds[:,:,:4,:,:]) # [N,5,4,13,13]
box_preds = box_preds.permute(0,1,3,4,2).contiguous().view(batch_size,-1,4) # [N,5*13*13,4]
for i in range(batch_size):
box_pred = box_preds[i] # [5*13*13,4]
box_target = box_targets[i] # [#obj, 4]
iou_target = box_iou(box_pred, box_target) # [5*13*13, #obj]
iou_targets[i] = iou_target.max(1)[0].view(5,fmsize,fmsize) # [5,13,13]
mask = Variable(torch.ones(iou_preds.size()).cuda()) * 0.1 # [N,5,13,13]
mask[pos] = 1
iou_loss = F.smooth_l1_loss(iou_preds*mask, iou_targets*mask, size_average=False)
### cls_loss
cls_preds = preds[:,:,5:,:,:] # [N,5,20,13,13]
cls_preds = cls_preds.permute(0,1,3,4,2).contiguous().view(-1,20) # [N,5,20,13,13] -> [N,5,13,13,20] -> [N*5*13*13,20]
cls_preds = F.softmax(cls_preds) # [N*5*13*13,20]
cls_preds = cls_preds.view(batch_size,5,fmsize,fmsize,20).permute(0,1,4,2,3) # [N*5*13*13,20] -> [N,5,20,13,13]
pos = cls_targets > 0
cls_loss = F.smooth_l1_loss(cls_preds[pos], cls_targets[pos], size_average=False)
print('%f %f %f' % (loc_loss.data[0]/num_pos, iou_loss.data[0]/num_pos, cls_loss.data[0]/num_pos), end=' ')
return (loc_loss + iou_loss + cls_loss) / num_pos
YOLOv2 在 VOC2007 資料集上和其他 state-of-the-art 模型的測試結果的比較如下曲線所示。
三,YOLOv3
YOLOv3的論文寫得不是很好,需要完全看懂,還是要看程式碼,C/C++基礎不好的建議看Pytorch版本的復現。下文是我對原論文的精簡翻譯和一些難點的個人理解,以及一些關鍵程式碼解析。
摘要
我們對 YOLO 再次進行了更新,包括一些小的設計和更好的網路結構。在輸入影象解析度為 \(320 \times 320\) 上執行 YOLOv3 模型,時間是 22 ms 的同時獲得了 28.2 的 mAP,精度和 SSD 類似,但是速度更快。和其他閾值相比,YOLOv3 尤其在 0.5 IOU(也就是 \(AP_{50}\))這個指標上表現非常良好。在 Titan X 環境下,YOLOv3 的檢測精度為 57.9 AP50,耗時 51 ms;而 RetinaNet 的精度只有 57.5 AP50,但卻需要 198 ms,相當於 YOLOv3的 3.8 倍。
一般可以認為檢測模型 = 特徵提取器 + 檢測頭。
1,介紹
這篇論文其實也是一個技術報告,首先我會告訴你們 YOLOv3 的更新(改進)情況,然後介紹一些我們失敗的嘗試,最後是這次更新方法意義的總結。
2,改進
YOLOv3 大部分有意的改進點都來源於前人的工作,當然我們也訓練了一個比其他人更好的分類器網路。
2.1,邊界框預測
這部分內容和
YOLOv2幾乎一致,但是內容更細緻,且閾值的取值有些不一樣。
和 YOLOv2 一樣,我們依然使用維度聚類的方法來挑選 anchor boxes 作為邊界框預測的先驗框。每個邊界框都會預測 \(4\) 個偏移座標 \((t_x,t_y,t_w,t_h)\)。假設 \((c_x, c_y)\) 為 grid 的左上角座標,\(p_w\)、\(p_h\) 是先驗框(anchors)的寬度與高度,那麼網路預測值和邊界框真實位置的關係如下所示:
假設某一層的
feature map的大小為 \(13 \times 13\), 那麼grid cell就有 \(13 \times 13\) 個,則第 \(n\) 行第 \(n\) 列的grid cell的座標 \((x_x, c_y)\) 就是 \((n-1,n)\)。
\(b_x,b_y,b_w,b_h\) 是邊界框的實際中心座標和寬高值。在訓練過程中,我們使用平方誤差損失函數。利用上面的公式,可以輕鬆推出這樣的結論:如果預測座標的真實值(ground truth)是 \(\hat{t}_{\ast}\),那麼梯度就是真實值減去預測值 \(\hat{t}_{\ast} - t_{\ast }\)。
梯度變成 \(\hat{t}_{\ast} - t_{\ast }\) 有什麼好處呢?
注意,計算損失的時候,模型預測輸出的 \(t_x,t_y\) 外面要套一個 sigmoid 函數 ,否則座標就不是 \((0,1)\) 範圍內的,一旦套了 sigmoid,就只能用 BCE 損失函數去反向傳播,這樣第一步算出來的才是 \(t_x-\hat{t}_x\);\((t_w,t_h)\) 的預測沒有使用 sigmoid 函數,所以損失使用 \(MSE\)。
\(\hat{t}_x\) 是預測座標偏移的真實值(
ground truth)。
YOLOv3 使用邏輯迴歸來預測每個邊界框的 objectness score(置信度分數)。如果當前先驗框和 ground truth 的 IOU 超過了前面的先驗框,那麼它的分數就是 1。和 Faster RCNN 論文一樣,如果先驗框和 ground truth 的 IOU不是最好的,那麼即使它超過了閾值,我們還是會忽略掉這個 box,正負樣本判斷的閾值取 0.5。YOLOv3 檢測系統只為每個 ground truth 物件分配一個邊界框。如果先驗框(bonding box prior,其實就是聚類得到的 anchors)未分配給 ground truth 物件,則不會造成位置和分類預測損失,只有置信度損失(only objectness)。
將 coco 資料集的標籤編碼成 \((t_x,t_y,t_w,t_h)\) 形式的程式碼如下:
def get_target(self, target, anchors, in_w, in_h, ignore_threshold):
"""
Maybe have problem.
target: original coco dataset label.
in_w, in_h: feature map size.
"""
bs = target.size(0)
mask = torch.zeros(bs, self.num_anchors, in_h, in_w, requires_grad=False)
noobj_mask = torch.ones(bs, self.num_anchors, in_h, in_w, requires_grad=False)
tx = torch.zeros(bs, self.num_anchors, in_h, in_w, requires_grad=False)
ty = torch.zeros(bs, self.num_anchors, in_h, in_w, requires_grad=False)
tw = torch.zeros(bs, self.num_anchors, in_h, in_w, requires_grad=False)
th = torch.zeros(bs, self.num_anchors, in_h, in_w, requires_grad=False)
tconf = torch.zeros(bs, self.num_anchors, in_h, in_w, requires_grad=False)
tcls = torch.zeros(bs, self.num_anchors, in_h, in_w, self.num_classes, requires_grad=False)
for b in range(bs):
for t in range(target.shape[1]):
if target[b, t].sum() == 0:
continue
# Convert to position relative to box
gx = target[b, t, 1] * in_w
gy = target[b, t, 2] * in_h
gw = target[b, t, 3] * in_w
gh = target[b, t, 4] * in_h
# Get grid box indices
gi = int(gx)
gj = int(gy)
# Get shape of gt box
gt_box = torch.FloatTensor(np.array([0, 0, gw, gh])).unsqueeze(0)
# Get shape of anchor box
anchor_shapes = torch.FloatTensor(np.concatenate((np.zeros((self.num_anchors, 2)),
np.array(anchors)), 1))
# Calculate iou between gt and anchor shapes
anch_ious = bbox_iou(gt_box, anchor_shapes)
# Where the overlap is larger than threshold set mask to zero (ignore)
noobj_mask[b, anch_ious > ignore_threshold, gj, gi] = 0
# Find the best matching anchor box
best_n = np.argmax(anch_ious)
# Masks
mask[b, best_n, gj, gi] = 1
# Coordinates
tx[b, best_n, gj, gi] = gx - gi
ty[b, best_n, gj, gi] = gy - gj
# Width and height
tw[b, best_n, gj, gi] = math.log(gw/anchors[best_n][0] + 1e-16)
th[b, best_n, gj, gi] = math.log(gh/anchors[best_n][1] + 1e-16)
# object
tconf[b, best_n, gj, gi] = 1
# One-hot encoding of label
tcls[b, best_n, gj, gi, int(target[b, t, 0])] = 1
return mask, noobj_mask, tx, ty, tw, th, tconf, tcls
另一個複習版本關於資料集標籤的處理程式碼如下:
def build_targets(p, targets, model):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = 3, targets.shape[0] # number of anchors, targets #TODO
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
# Make a tensor that iterates 0-2 for 3 anchors and repeat that as many times as we have target boxes
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt)
# Copy target boxes anchor size times and append an anchor index to each copy the anchor index is also expressed by the new first dimension
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2)
for i, yolo_layer in enumerate(model.yolo_layers):
# Scale anchors by the yolo grid cell size so that an anchor with the size of the cell would result in 1
anchors = yolo_layer.anchors / yolo_layer.stride
# Add the number of yolo cells in this layer the gain tensor
# The gain tensor matches the collums of our targets (img id, class, x, y, w, h, anchor id)
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Scale targets by the number of yolo layer cells, they are now in the yolo cell coordinate system
t = targets * gain
# Check if we have targets
if nt:
# Calculate ration between anchor and target box for both width and height
r = t[:, :, 4:6] / anchors[:, None]
# Select the ratios that have the highest divergence in any axis and check if the ratio is less than 4
j = torch.max(r, 1. / r).max(2)[0] < 4 # compare #TODO
# Only use targets that have the correct ratios for their anchors
# That means we only keep ones that have a matching anchor and we loose the anchor dimension
# The anchor id is still saved in the 7th value of each target
t = t[j]
else:
t = targets[0]
# Extract image id in batch and class id
b, c = t[:, :2].long().T
# We isolate the target cell associations.
# x, y, w, h are allready in the cell coordinate system meaning an x = 1.2 would be 1.2 times cellwidth
gxy = t[:, 2:4]
gwh = t[:, 4:6] # grid wh
# Cast to int to get an cell index e.g. 1.2 gets associated to cell 1
gij = gxy.long()
# Isolate x and y index dimensions
gi, gj = gij.T # grid xy indices
# Convert anchor indexes to int
a = t[:, 6].long()
# Add target tensors for this yolo layer to the output lists
# Add to index list and limit index range to prevent out of bounds
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1)))
# Add to target box list and convert box coordinates from global grid coordinates to local offsets in the grid cell
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
# Add correct anchor for each target to the list
anch.append(anchors[a])
# Add class for each target to the list
tcls.append(c)
return tcls, tbox, indices, anch
關於更多模型推理部分程式碼的復現和理解,可閱讀這個 github專案程式碼。
2.2,分類預測
每個框使用多標籤分類來預測邊界框可能包含的類。我們不使用 softmax 啟用函數,因為我們發現它對模型的效能影響不好。相反,我們只是使用獨立的邏輯分類器。在訓練過程中,我們使用二元交叉熵損失來進行類別預測。
在這個資料集 Open Images Dataset 中有著大量的重疊標籤。如果使用 softmax ,意味著強加了一個假設,即每個框只包含一個類別,但通常情況並非如此。多標籤方法能更好地模擬資料。
2.3,跨尺度預測
YOLOv3 可以預測 3 種不同尺度(scale)的框。
總的來說是,引入了類似 FPN 的多尺度特徵圖融合,從而加強小目標檢測。與原始的 FPN 不同,YOLOv3 的 Neck 網路只輸出 3 個分支,分別對應 3 種尺度,高層網路輸出的特徵圖經過上取樣後和低層網路輸出的特徵圖融合是使用 concat 方式拼接,而不是使用 element-wise add 的方法。
首先檢測系統利用和特徵金字塔網路[8](FPN 網路)類似的概念,來提取不同尺度的特徵。我們在基礎的特徵提取器基礎上新增了一些折積層。這些折積層的最後會預測一個 3 維張量,其是用來編碼邊界框,框中目標和分類預測。在 COCO 資料集的實驗中,我們每個輸出尺度都預測 3 個 boxes,所以模型最後輸出的張量大小是 \(N \times N \times [3*(4+1+80)]\),其中包含 4 個邊界框offset、1 個 objectness 預測(前景背景預測)以及 80 種分類預測。
objectness預測其實就是前景背景預測,有些類似YOLOv2的置信度c的概念。
然後我們將前面兩層輸出的特徵圖上取樣 2 倍,並和淺層中的特徵圖,用 concatenation 方式把高低兩種解析度的特徵圖連線到一起,這樣做能使我們同時獲得上取樣特徵的有意義的語意資訊和來自早期特徵的細粒度資訊。之後,再新增幾個折積層來處理這個融合後的特徵,並輸出大小是原來高層特徵圖兩倍的張量。
按照這種設計方式,來預測最後一個尺度的 boxes。可以知道,對第三種尺度的預測也會從所有先前的計算中(多尺度特徵融合的計算中)獲益,同時能從低層的網路中獲得細粒度( finegrained )的特徵。
顯而易見,低層網路輸出的特徵圖語意資訊比較少,但是目標位置準確;高層網路輸出的特徵圖語意資訊比較豐富,但是目標位置比較粗略。
依然使用 k-means 聚類來確定我們的先驗邊界框(box priors,即選擇的 anchors),但是選擇了 9 個聚類(clusters)和 3 種尺度(scales,大、中、小三種 anchor 尺度),然後在整個尺度上均勻分割聚類。在COCO 資料集上,9 個聚類是:(10×13);(16×30);(33×23);(30×61);(62×45);(59×119);(116×90);(156×198);(373×326)。
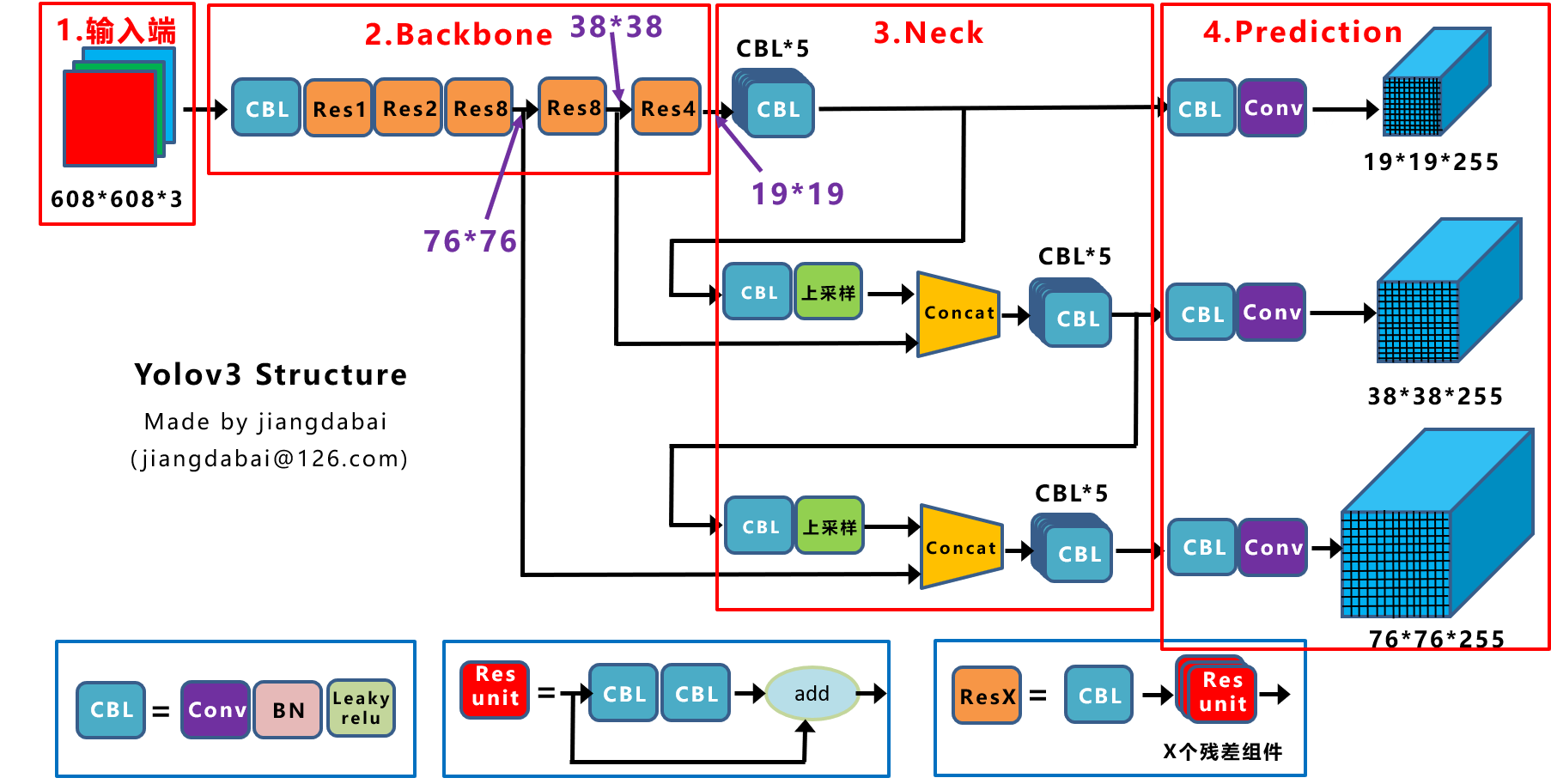
從上面的描述可知,YOLOv3 的檢測頭變成了 3 個分支,對於輸入影象 shape 為 (3, 416, 416)的 YOLOv3 來說,Head 各分支的輸出張量的尺寸如下:
- [13, 13, 3*(4+1+80)]
- [26, 2, 3*(4+1+80)]
- [52, 52, 3*(4+1+80)]
3 個分支分別對應 32 倍、16 倍、8倍下取樣,也就是分別預測大、中、小目標。32 倍下取樣的特徵圖的每個點感受野更大,所以用來預測大目標。
每個 sacle 分支的每個 grid 都會預測 3 個框,每個框預測 5 元組+ 80 個 one-hot vector類別,所以一共 size 是:3*(4+1+80)。
根據前面的內容,可以知道,YOLOv3 總共預測 \((13 \times 13 + 26 \times 26 + 52 \times 52) \times 3 = 10467(YOLOv3) \gg 845 = 13 \times 13 \times 5(YOLOv2)\) 個邊界框。
2.4,新的特徵提取網路
我們使用一個新的網路來執行特徵提取。它是 Darknet-19和新型殘差網路方法的融合,由連續的 \(3\times 3\) 和 \(1\times 1\) 折積層組合而成,並新增了一些 shortcut connection,整體體量更大。因為一共有 $53 = (1+2+8+8+4)\times 2+4+2+1 $ 個折積層,所以我們稱為 Darknet-53。
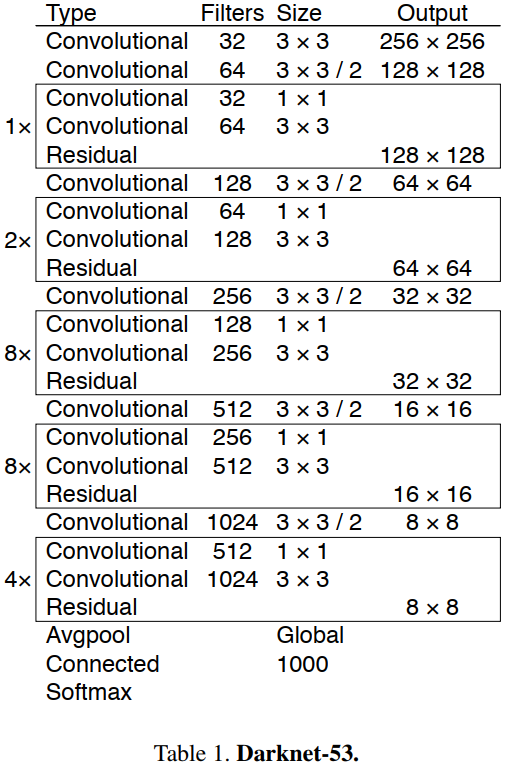
總的來說,DarkNet-53 不僅使用了全折積網路,將 YOLOv2 中降取樣作用 pooling 層都換成了 convolution(3x3,stride=2) 層;而且引入了殘差(residual)結構,不再使用類似 VGG 那樣的直連型網路結構,因此可以訓練更深的網路,即折積層數達到了 53 層。(更深的網路,特徵提取效果會更好)
Darknet53 網路的 Pytorch 程式碼如下所示。
程式碼來源這裡。
import torch
import torch.nn as nn
import math
from collections import OrderedDict
__all__ = ['darknet21', 'darknet53']
class BasicBlock(nn.Module):
"""basic residual block for Darknet53,折積層分別是 1x1 和 3x3
"""
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1,
stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):s
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
self.inplanes = 32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
self.layer1 = self._make_layer([32, 64], layers[0])
self.layer2 = self._make_layer([64, 128], layers[1])
self.layer3 = self._make_layer([128, 256], layers[2])
self.layer4 = self._make_layer([256, 512], layers[3])
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, planes, blocks):
layers = []
# 每個階段的開始都要先 downsample,然後才是 basic residual block for Darknet53
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3,
stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# blocks
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5
def darknet21(pretrained, **kwargs):
"""Constructs a darknet-21 model.
"""
model = DarkNet([1, 1, 2, 2, 1])
if pretrained:
if isinstance(pretrained, str):
model.load_state_dict(torch.load(pretrained))
else:
raise Exception("darknet request a pretrained path. got [{}]".format(pretrained))
return model
def darknet53(pretrained, **kwargs):
"""Constructs a darknet-53 model.
"""
model = DarkNet([1, 2, 8, 8, 4])
if pretrained:
if isinstance(pretrained, str):
model.load_state_dict(torch.load(pretrained))
else:
raise Exception("darknet request a pretrained path. got [{}]".format(pretrained))
return model
3 個預測分支,對應預測 3 種尺度(大、種、小),也都採用了全折積的結構。
YOLOv3 的 backbone 選擇 Darknet-53後,其檢測效能遠超 Darknet-19,同時效率上也優於 ResNet-101 和 ResNet-152,對比實驗結果如下:
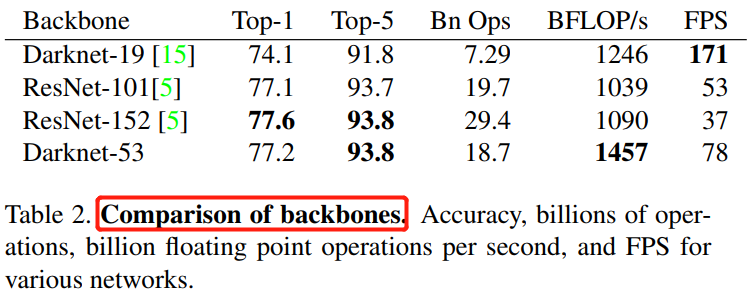
在對比實驗中,每個網路都使用相同的設定進行訓練和測試。執行速度 FPS 是在 Titan X 硬體上,輸入影象大小為 \(256 \times 256\) 上測試得到的。從上表可以看出,Darknet-53 和 state-of-the-art 分類器相比,有著更少的 FLOPs 和更快的速度。和 ResNet-101 相比,精度更高並且速度是前者的 1.5 倍;和 ResNet-152 相比,精度相似,但速度是它的 2 倍以上。
Darknet-53 也可以實現每秒最高的測量浮點運算。這意味著其網路結構可以更好地利用 GPU,從而使其評估效率更高,速度更快。這主要是因為 ResNets 的層數太多,效率不高。
2.5,訓練
和 YOLOv2 一樣,我們依然訓練所有圖片,沒有 hard negative mining or any of that stuff。我們依然使用多尺度訓練,大量的資料增強操作和 BN 層以及其他標準操作。我們使用之前的 Darknet 神經網路框架進行訓練和測試[12]。
損失函數的計算公式如下。

YOLO v3 使用多標籤分類,用多個獨立的 logistic 分類器代替 softmax 函數,以計算輸入屬於特定標籤的可能性。在計算分類損失進行訓練時,YOLOv3 對每個標籤使用二元交叉熵損失。
正負樣本的確定:
- 正樣本:與
GT的IOU最大的框。 - 負樣本:與
GT的IOU<0.5的框。 - 忽略的樣本:與
GT的IOU>0.5但不是最大的框。 - 使用 \(t_x\) 和 \(t_y\) (而不是 \(b_x\) 和 \(b_y\) )來計算損失。
注意:每個 GT 目標僅與一個先驗邊界框相關聯。如果沒有分配先驗邊界框,則不會導致分類和定位損失,只會有目標的置信度損失。
YOLOv3 網路結構圖如下所示(這裡輸入影象大小為 608*608,來源 這裡 )。
2.5,推理
總的來說還是將輸出的特偵圖劃分成 S*S(這裡的S和特徵圖大小一樣) 的網格,通過設定置信度閾值對網格進行篩選,只有大於指定閾值的網格才認為存在目標,即該網格會輸出目標的置信度、bbox 座標和類別資訊,並通過 NMS 操作篩選掉重複的框。
值得注意的是,模型推理的 bbox 的 \(xywh\) 值是對應 feature map 尺度的,所以後面還需要將 xywh 的值 * 特徵圖的下取樣倍數。
# 將 bbox 預測值, box 置信度, box 分類結果的矩陣拼接成一個新的矩陣
# * _scale 是為了將預測的 box 對應到原圖尺寸, _scale 是特徵圖下取樣倍數。
# 對於大目標檢測分支 pred_boxes.view(bs, -1, 4) 後的 shape 為 [1, 507, 4], output 的 shape 為 [1, 507, 85]
# bs 是 batch_size,即一次推理多少張圖片。
output = torch.cat((pred_boxes.view(bs, -1, 4) * _scale,
conf.view(bs, -1, 1), pred_cls.view(bs, -1, self.num_classes)), -1)
3,實驗結果
YOLOv3 實驗結果非常好!詳情見表3。
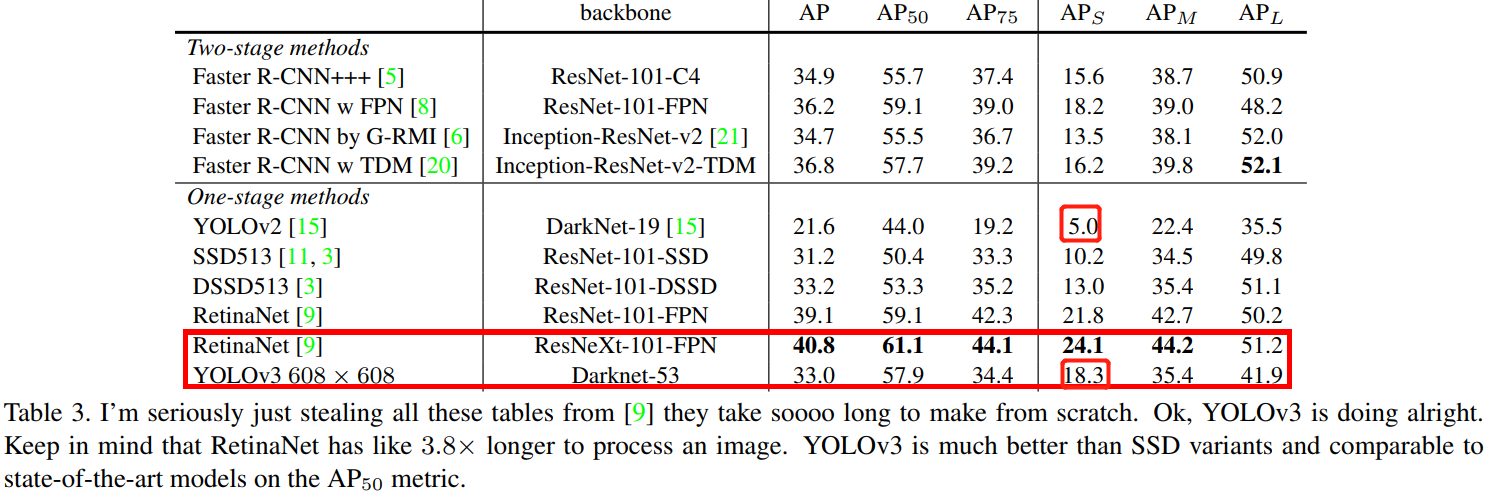
就 COCO 的 mAP 指標而言,YOLOv3 和 SSD 變體相近,但是速度卻比後者快了 3 倍。儘管如此,YOLOv3 還是比 Retinanet 這樣的模型在精度上要差一些。
但是當我們以 IOU = 0.5 這樣的舊指標對比,YOLOv3 表現更好,幾乎和 Retinanet 相近,遠超 SSD 變體。這表面它其實是一款非常靈活的檢測器,擅長為檢測物件生成合適的邊界框。然而,隨著IOU閾值增加,YOLOv3 的效能開始同步下降,這時它預測的邊界框就不能做到完美對齊了。
在過去的 YOLOv1/v2 上,YOLO 一直在小目標檢測領域表現不好,現在 YOLOv3 基本解決了這個問題,有著更好的 \(AP_S\) 效能。但是它目前在中等尺寸或大尺寸物體上的表現還相對較差,仍需進一步的完善。
當我們基於 \(AP_{50}\) 指標繪製精度和速度曲線(Figure 3)時,我們發現YOLOv3與其他檢測系統相比具有顯著優勢,換句話說,它更快更好。
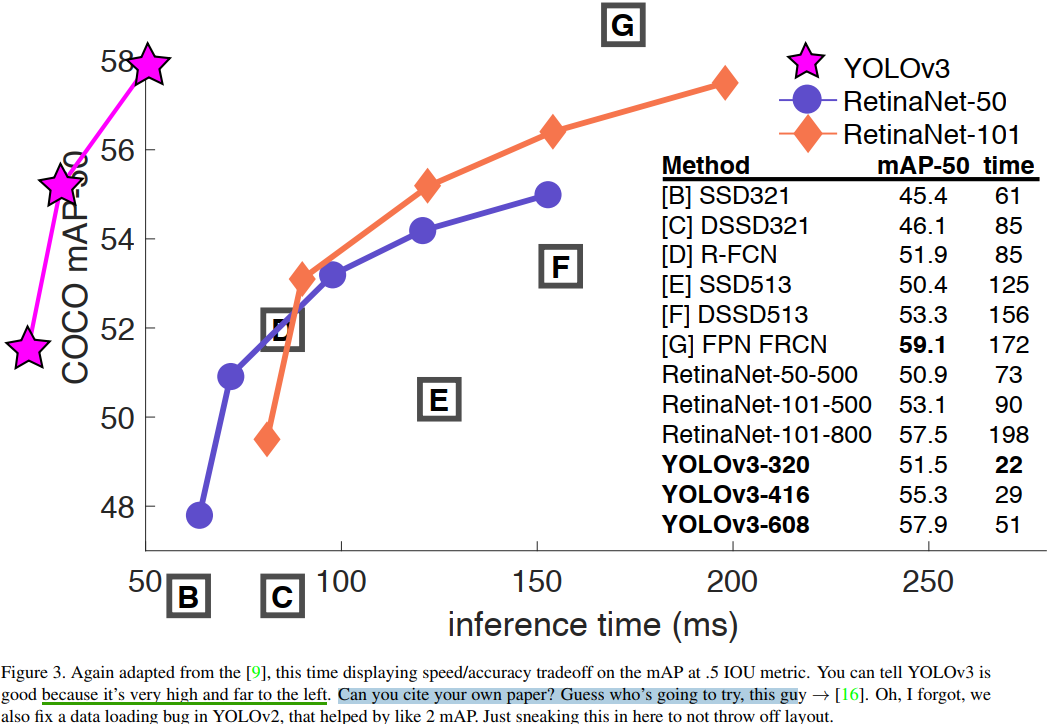
從
Figure 3可以看出,YOLOv3的曲線非常靠近曲線座標的同時又非常高,這意味著YOLOv3有著良好速度的同時又有很好的精度,無愧當前最強目標檢測模型。
4,失敗的嘗試
一些沒有作用的嘗試工作如下。
Anchor box x,y 偏移預測。我們嘗試了常規的 Anchor box 預測方法,比如利用線性啟用將座標 \(x、y\) 的偏移程度,預測為邊界框寬度或高度的倍數。但我們發現這種做法降低了模型的穩定性,且效果不佳。
用線性方法預測 x,y,而不是使用 logistic。我們嘗試使用線性啟用函數來直接預測 \(x,y\) 的偏移,而不是 ligistic 啟用函數,但這降低了 mAP。
focal loss。我們嘗試使用focal loss,但它使我們的 mAP降低了 2 點。 對於 focal loss 函數試圖解決的問題,YOLOv3 已經具有魯棒性,因為它具有單獨的物件性預測(objectness predictions)和條件類別預測。因此,對於大多數範例來說,類別預測沒有損失?或者其他的東西?我們並不完全確定。
雙 IOU 閾值和真值分配。在訓練過程中,Faster RCNN 用了兩個IOU 閾值,如果預測的邊框與的 ground truth 的 IOU 是 0.7,那它是正樣本 ;如果 IOU 在 [0.3—0.7]之間,則忽略這個 box;如果小於 0.3,那它是個負樣本。我們嘗試了類似的策略,但效果並不好。
5,改進的意義
YOLOv3 是一個很好的檢測器,速度很快,很準確。雖然它在 COCO 資料集上的 mAP 指標,即 \(AP_{50}\) 到 \(AP_{90}\) 之間的平均值上表現不好,但是在舊指標 \(AP_{50}\) 上,它表現非常好。
總結 YOLOv3 的改進點如下:
- 使用金字塔網路來實現多尺度預測,從而解決小目標檢測的問題。
- 借鑑殘差網路來實現更深的
Darknet-53,從而提升模型檢測準確率。 - 使用
sigmoid函數替代softmax啟用來實現多標籤分類器。 - 位置預測修改,一個
gird預測3個box。
四,YOLOv4
因為
YOLOv1-v3的作者不再更新YOLO框架,所以Alexey Bochkovskiy接起了傳承YOLO的重任。相比於它的前代,YOLOv4不再是原創性且讓人眼前一亮的研究,但是卻整合了目標檢測領域的各種實用tricks和隨插即用模組 ,稱得上是基於YOLOv3框架的各種目標檢測tricks的集大成者。
本文章不會對原論文進行一一翻譯,但是做了系統性的總結和關鍵部分的翻譯。
1,摘要及介紹
我們總共使用了:WRC、CSP、CmBN、SAT、Mish 啟用和 Mosaic 資料增強、CIoU 損失方法,並組合其中的一部分,使得最終的檢測模型在 MS COCO 資料集、Tesla V100 顯示卡上達到了 43.5% AP 精度 和 65 FPS 速度。
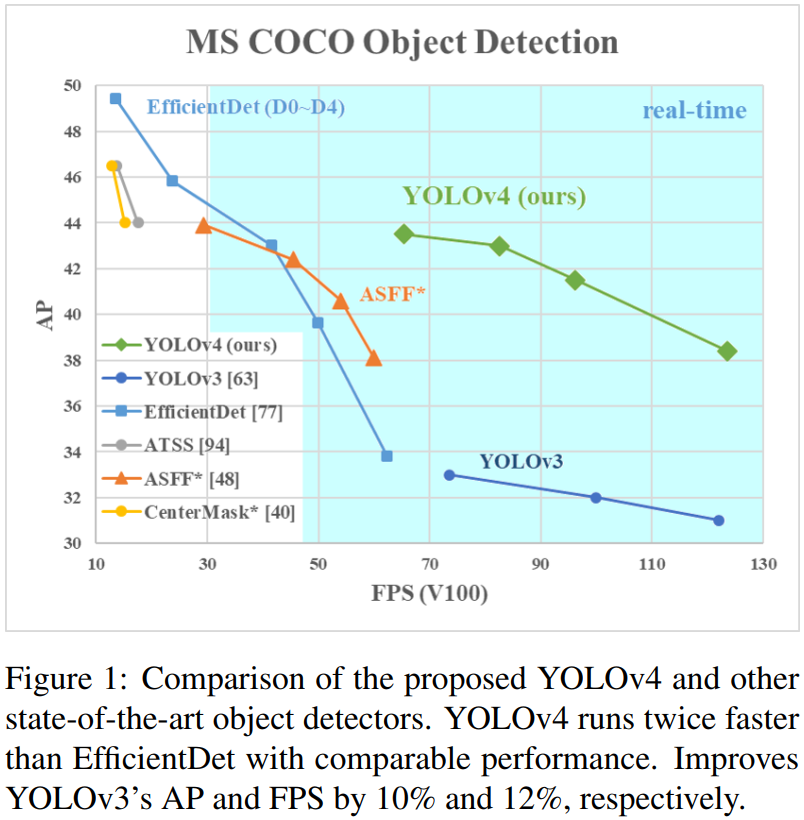
我們的主要貢獻在於:
- 構建了簡單高效的
YOLOv4檢測器,修改了CBN、PAN、SAM方法使得YOLOv4能夠在一塊1080Ti上就能訓練。 - 驗證了當前最先進的
Bag-of-Freebies和Bag-of-Specials方法在訓練期間的影響。
目前的目標檢測網路分為兩種:一階段和兩階段。檢測演演算法的組成:Object detector = backbone + neck + head,具體結構如下圖所示。
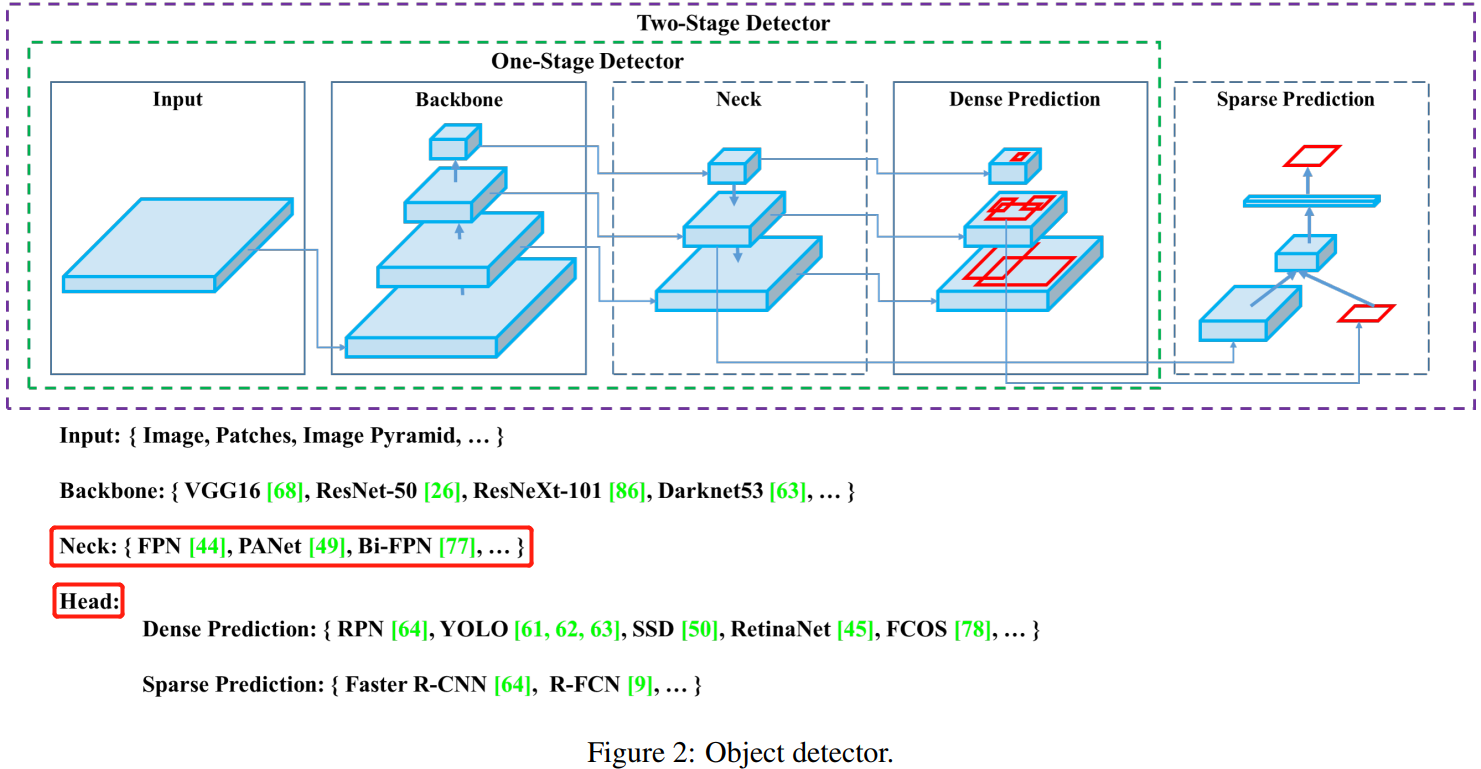
2,相關工作
2.1,目標檢測方法
按照檢測頭的不同(head)將目標檢測模型分為:兩階段檢測和一階段檢測模型,各自代表是 Faster RCNN 和 YOLO 等,最近也出了一些無 anchor 的目標檢測器,如 CenterNet 等。近幾年來的檢測器會在Backbone網路(backbone)和頭部網路(head)之間插入一些網路層,主要作用是收集不同階段的特徵。,稱其為檢測器的頸部(neck)。 neck 通常由幾個自下而上(bottom-up)的路徑和幾個自上而下(top-down)的路徑組成。 配備此機制的網路包括特徵金字塔網路(FPN)[44],路徑聚合網路(PAN)[49],BiFPN [77]和NAS-FPN [17]。
一般,目標檢測器由以下幾部分組成:

2.2,Bag of freebies(免費技巧)
不會改變模型大小,主要是針對輸入和
loss等做的優化工作,一切都是為了讓模型訓練得更好。
最常用的方式是資料增強(data augmentation),目標是為了提升輸入影象的可變性(variability),這樣模型在不同環境中會有更高的魯棒性。常用的方法分為兩類:光度失真和幾何失真(photometric distortions and geometric distortions)。在處理光度失真時,我們調整了影象的亮度、對比度、色調、飽和度和噪聲;對於幾何失真,我們新增隨機縮放,裁剪,翻轉和旋轉。
上述資料增強方法都是逐畫素調整的,並且保留了調整區域中的所有原始畫素資訊。此外,也有些研究者將重點放在模擬物件遮擋的問題上,並取得了一些成果。例如隨機擦除(random-erase)[100] 和 CutOut [11] 方法會隨機選擇影象中的矩形區域,並填充零的隨機或互補值。而捉迷藏(hide-and-seek)[69] 和網格遮罩(grid-mask)[6] 方法則隨機或均勻地選擇影象中的多個矩形區域,並將它們替換為所有的 zeros。這個概念有些類似於 Dropout、DropConnect 和 DropBlock 這些在 feature 層面操作的方法,如 。此外,一些研究人員提出了使用多個影象一起執行資料增強的方法。 例如,MixUp 方法使用兩個影象以不同的係數比值相乘後疊加,然後使用這些疊加的比值來調整標籤。 對於 CutMix,它是將裁切後的影象覆蓋到其他影象的矩形區域,並根據混合區域的大小調整標籤。 除了以上方法之外,還有 style transfer GAN 方法用於資料擴充、減少 CNN 所學習的紋理偏差。
MIX-UP:Mix-up在分類任務中,將兩個影象按照不同的比例相加,例如 \(A\ast 0.1 + B\ast 0.9=C\),那麼 \(C\)的label就是 \([0.1A, 0.9A]\)。在目標檢測中的做法就是將一些框相加,這些label中就多了一些不同置信度的框。
上面的方法是針對資料增強目標,第二類方法是針對解決資料集中語意分佈可能存在偏差的問題( semantic distribution in the dataset may have bias)。在處理語意分佈偏差問題時,類別不平衡(imbalance between different classes)問題是其中的一個關鍵,在兩階段物件檢測器中通常通過困難負樣本挖掘(hard negative example mining)或線上困難樣本挖掘(online hard example mining,簡稱 OHEM)來解決。但樣本挖掘方法並不能很好的應用於一階段檢測器,因為它們都是密集檢測架構(dense prediction architecture)。因此,何凱明等作者提出了 Focal Loss 用來解決類別不平衡問題。 另外一個關鍵問題是,很難用 one-hot hard representation 來表達不同類別之間的關聯度的關係,但執行標記時又通常使用這種表示方案。 因此在(Rethinking the inception architecture for computer vision)論文中提出標籤平滑(label smoothing)的概念,將硬標籤轉換為軟標籤進行訓練,使模型更健壯。為了獲得更好的軟標籤,論文(Label refinement network for coarse-to-fine semantic segmentation)介紹了知識蒸餾的概念來設計標籤細化網路。
最後一類方法是針對邊界框(BBox)迴歸的目標函數。傳統的目標檢測器通常使用均方誤差(\(MSE\))對BBox 的中心點座標以及高度和寬度直接執行迴歸,即 \(\lbrace x_{center}, y_{center}, w, h \rbrace\) 或者 \(\lbrace x_{top-left}, y_{top-left}, x_{bottom-right}, y_{bottom-right} \rbrace\) 座標。如果基於錨的方法,則估計相應的偏移量,例如 \(\lbrace x_{cener-offset}, y_{cener-offset}, w, h \rbrace\) 或者 \(\lbrace x_{top-left-offset}, y_{top-left-offset}, x_{bottom-right-offset}, y_{bottom-right-offset} \rbrace\)。這些直接估計 BBox 的各個點的座標值的方法,是將這些點視為獨立的變數,但是實際上這沒有考慮物件本身的完整性。為了更好的迴歸 BBox,一些研究者提出了 IOU 損失[90]。顧名思義,IoU 損失既是使用 Ground Truth 和預測 bounding box(BBox)的交併比作為損失函數。因為 IoU 是尺度不變的表示,所以可以解決傳統方法計算 \(\lbrace x,y,w,h \rbrace\) 的 \(L1\) 或 \(L2\) 損失時,損失會隨著尺度增加的問題。 最近,一些研究人員繼續改善 IoU 損失。 例如,GIoU 損失除了覆蓋區域外還包括物件的形狀和方向,GIoU 損失的分母為同時包含了預測框和真實框的最小框的面積。DIoU 損失還考慮了物件中心的距離,而CIoU 損失同時考慮了重疊區域,中心點之間的距離和縱橫比。 CIoU 損失在 BBox 迴歸問題上可以實現更好的收斂速度和準確性。
[90] 論文: An advanced object detection network.
2.3,Bag of specials(隨插即用模組+後處理方法)
對於那些僅增加少量推理成本但可以顯著提高目標檢測器準確性的外掛模組或後處理方法,我們將其稱為 「Bag of specials」。一般而言,這些外掛模組用於增強模型中的某些屬性,例如擴大感受野,引入注意力機制或增強特徵整合能力等,而後處理是用於篩選模型預測結果的方法。
增大感受野模組。用來增強感受野的常用模組有 SPP、ASPP 和 RFB。SPP 起源於空間金字塔匹配(SPM),SPM 的原始方法是將特徵圖分割為幾個 \(d\times d\) 個相等的塊,其中 \(d\) 可以為 \(\lbrace 1,2,3,.. \rbrace\),從而形成空間金字塔。SPP 將 SPM 整合到 CNN 中,並使用最大池化操作(max pooling)替代 bag-of-word operation。原始的 SPP 模組是輸出一維特徵向量,這在 FCN 網路中不可行。
引入注意力機制。在目標檢測中經常使用的注意力模組,通常分為 channel-wise 注意力和 point-wise 注意力。代表模型是 SE 和 SAM(Spatial Attention Module )。雖然 SE 模組可以提高 ReSNet50 在 ImageNet 影象分類任務 1% 的 top-1 準確率而計算量只增加 2%,但是在 GPU 上,通常情況下,它會將增加推理時間的 10% 左右,所以更適合用於行動端。但對於 SAM,它只需要增加 0.1% 的額外的推理時間,就可以在 ImageNet 影象分類任務上將 ResNet50-SE 的top-1 準確性提高 0.5%。 最好的是,它根本不影響 GPU 上的推理速度。
特徵融合或特徵整合。早期的實踐是使用 skip connection 或 hyper-column 將低層物理特徵整合到高層語意特徵。 由於諸如 FPN 的多尺度預測方法已變得流行,因此提出了許多整合了不同特徵金字塔的輕量級模組。 這種模組包括 SFAM,ASFF和 BiFPN。 SFAM 的主要思想是使用 SE 模組在多尺度級聯特徵圖上執行通道級級別的加權。 對於 ASFF,它使用softmax 作為逐點級別權重,然後新增不同比例的特徵圖。在BiFPN 中,提出了多輸入加權殘差連線以執行按比例的級別重新加權,然後新增不同比例的特徵圖。
啟用函數。良好的啟用函數可以使梯度在反向傳播演演算法中得以更有效的傳播,同時不會引入過多的額外計算成本。2010 年 Nair 和 Hinton 提出的 ReLU 啟用函數,實質上解決了傳統的tanh 和 sigmoid 啟用函數中經常遇到的梯度消失問題。隨後,隨後,LReLU,PReLU,ReLU6,比例指數線性單位(SELU),Swish,hard-Swish 和 Mish等啟用函數也被提出來,用於解決梯度消失問題。LReLU 和 PReLU 的主要目的是解決當輸出小於零時 ReLU 的梯度為零的問題。而 ReLU6 和 Hard-Swish 是專門為量化網路設計的。同時,提出了 SELU 啟用函數來對神經網路進行自歸一化。 最後,要注意 Swish 和 Mish 都是連續可區分的啟用函數。
後處理。最開始常用 NMS 來剔除重複檢測的 BBox,但是 NMS 會不考慮上下文資訊(可能會把一些相鄰檢測框框給過濾掉),因此 Girshick 提出了 Soft NMS,為相鄰檢測框設定一個衰減函數而非徹底將其分數置為零。而 DIoU NMS 則是在 soft NMS 的基礎上將中心距離的資訊新增到 BBox 篩選過程中。值得一提的是,因為上述後處理方法都沒有直接涉及捕獲的影象特徵,因此在後續的 anchor-free 方法中不再需要 NMS 後處理。
3,方法
我們的基本目標是在生產系統中快速對神經網路進行操作和平行計算優化,而不是使用低計算量理論指示器(BFLOP)。 我們提供了兩種實時神經網路:
- 對於
GPU,我們在折積層中使用少量分組(1-8):如CSPResNeXt50 / CSPDarknet53 - 對於
VPU,我們使用分組折積,但是我們避免使用SE-特別是以下模型:EfficientNet-lite / MixNet [76] / GhostNet [21] / MobiNetNetV3
3.1,架構選擇
我們的目標是在輸入影象解析度、折積層數量、引數量、層輸出(濾波器)數量之間找到最優平衡。我們大量的研究表面,在 ILSVRC2012(ImageNet) 分類資料集上,CSPResNext50 網路優於 CSPDarknet,但是在 MS COCO 目標檢測資料集上,卻相反。
這是為什麼呢,兩種網路,一個分類資料集表現更好,一個檢測資料集表現更好。

在分類問題上表現最優的參考模型並不一定總是在檢測問題上也表現最優。與分類器相比,檢測器需要滿足以下條件:
- 更高的輸入網路尺寸(解析度),用於檢測多個小型物體。
- 更多的網路層,用以得到更高的感受野以覆蓋更大的輸入網路尺寸。
- 更多引數,用以得到更大的模型容量,從而可以在單個影象中檢測到多個不同大小的物件。
表1 顯示了 CSPResNeXt50,CSPDarknet53 和EfficientNet B3 網路的資訊。CSPResNext50 僅包含16 個 \(3\times 3\) 折積層,最大感受野為 \(425\times 425\)和網路引數量為 20.6 M,而 CSPDarknet53 包含 29 個 \(3\times 3\) 折積層,最大感受野為 \(725\times 725\) 感受野和引數量為 27.6 M。理論上的論證再結合作者的大量實驗結果,表面 CSPDarknet53 更適合作為目標檢測器的 backbone。
不同大小的感受野的影響總結如下:
- 達到物件大小 - 允許檢視整個物件
- 達到網路大小 - 允許檢視物件周圍的上下文環境
- 超過網路規模 - 增加影象點和最終啟用之間的連線
我們在 CSPDarknet53 上新增了 SPP 模組,因為它顯著增加了感受野,分離出最重要的上下文特徵,並且幾乎沒有降低網路執行速度。 我們使用 PANet 作為針對不同檢測器級別的來自不同backbone 級別的引數聚合方法,而不是 YOLOv3中使用的FPN。
最後,我們的 YOLOv4 架構體系如下:
backbone:CSPDarknet53+SPPneck:PANethead:YOLOv3的head
3.2,Selection of BoF and BoS
為了更好的訓練目標檢測模型,CNN 通常使用如下方法:
- 啟用函數:
ReLU,leaky-ReLU,parameter-ReLU,ReLU6,SELU,Swish或Mish; - 邊界框迴歸損失:
MSE,IoU,GIoU,CIoU,DIoU損失; - 資料擴充:
CutOut,MixUp,CutMix - 正則化方法:
DropOut,DropPath,空間DropOut或DropBlock - 通過均值和方差對網路啟用進行歸一化:批歸一化(BN),交叉-GPU 批次處理規範化(
CGBN或SyncBN),過濾器響應規範化(FRN)或交叉迭代批次處理規範化(CBN); - 跳躍連線:殘差連線,加殘差連線,多輸入加權殘差連線或跨階段區域性連線(
CSP)
以上方法中,我們首先提出了難以訓練的 PRELU 和 SELU,以及專為量化網路設計的 ReLU6 啟用。因為 DropBlock 作者證明了其方法的有效性,所以正則化方法中我們使用 DropBlock。
3.3,額外的改進
這些方法是作者對現有方法做的一些改進。
為了讓 YOLOv4 能更好的在單個 GPU 上訓練,我們做了以下額外改進:
- 引入了新的資料增強方法:
Mosaic和自我對抗訓練self-adversarial training(SAT)。 - 通過遺傳演演算法選擇最優超引數。
- 修改了
SAM、PAN和CmBN。
Mosaic 是一種新的資料增強方法,不像 cutmix 僅混合了兩張圖片,它混合了 \(4\) 張訓練影象,從而可以檢測到超出其正常上下文的物件。 此外,BN 在每層上計算的啟用統計都是來自 4 張不同影象,這大大減少了對大 batch size 的需求。

CmBN 僅收集單個批次中的 mini-batch 之間的統計資訊。
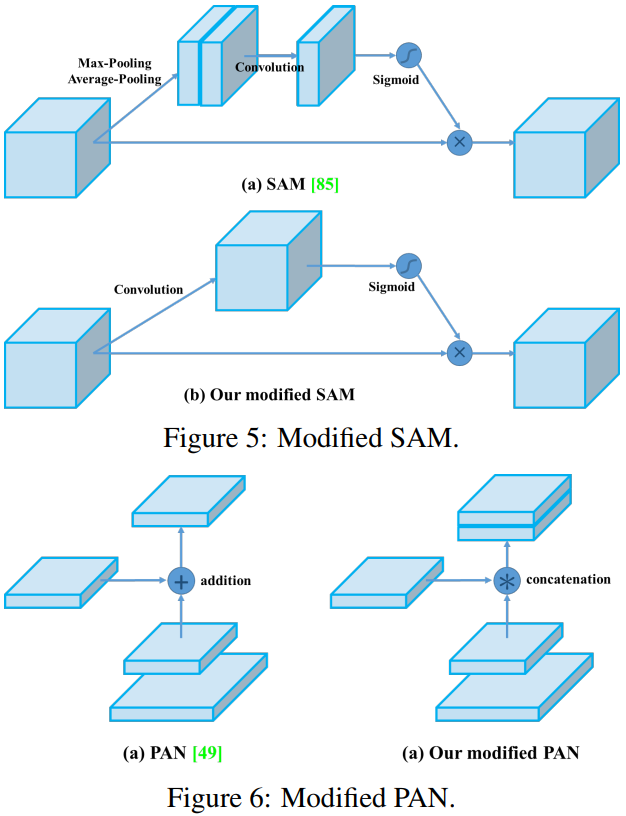
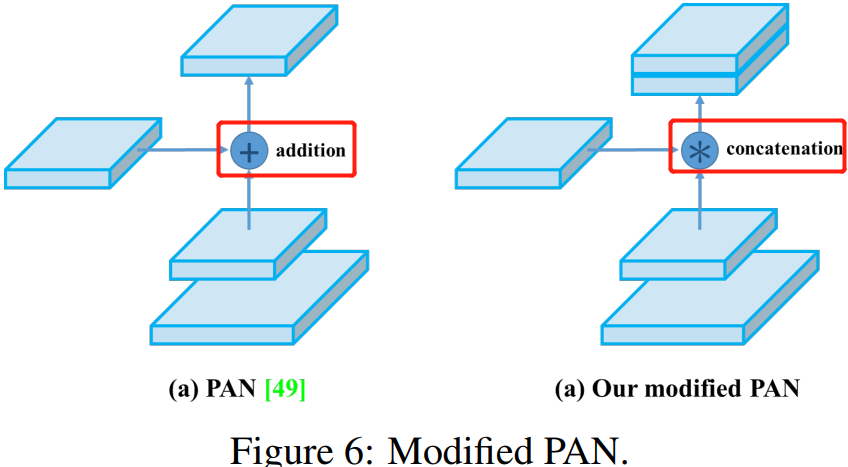
我們將 SAM 從 spatial-wise attentation 改為 point-wise attention,並將 PAN 的 shortcut 連線改為 concatenation(拼接),分別如圖 5 和圖 6 所示。
3.4 YOLOv4
YOLOv4 網路由以下部分組成:
Backbone:CSPDarknet53Neck:SPP,PANHead:YOLOv3
同時,YOLO v4 使用了:
- 用於
backbone的BoF:CutMix和Mosaic資料增強,DropBlock正則化,類標籤平滑。 - 用於
backbone的BoS:Mish啟用,跨階段部分連線(CSP),多輸入加權殘餘連線(MiWRC)。 - 用於檢測器的
BoF:CIoU損失,CmBN,DropBlock正則化,mosaic資料增強,自我對抗訓練,消除網格敏感性,在單個ground-truth上使用多個anchor,餘弦退火排程器,最佳超引數,隨機訓練形狀。 - 用於檢測器
BoS:Mish啟用,SPP模組,SAM模組,PAN路徑聚集塊,DIoU-NMS。
4,實驗
4.1,實驗設定
略
4.2,對於分類器訓練過程中不同特性的影響
圖 7 視覺化了不同資料增強方法的效果。

表 2 的實驗結果告訴我們,CutMix 和 Mosaic 資料增強,類別標籤平滑及 Mish 啟用可以提高分類器的精度,尤其是 Mish 啟用提升效果很明顯。

4.3,對於檢測器訓練過程中不同特性的影響
- \(S\):
Eliminate grid sensitivit。原來的 \(b_x = \sigma(t_x) + c_x\),因為sigmoid函數值域範圍是 \((0,1)\) 而不是 \([0,1]\),所以 \(b_x\) 不能取到grid的邊界位置。為了解決這個問題,作者提出將 \(\sigma(t_x)\) 乘以一個超過 \(1\) 的係數,如 \(b_x = 1.1\sigma(t_x) + c_x\),\(b_y\) 的公式類似。 - \(IT\):之前的
YOLOv3是 \(1\) 個anchor負責一個GT,現在YOLOv4改用多個anchor負責一個GT。對於GT來說,只要 \(IoU(anchor_i, GT_j) > IoU -threshold\) ,就讓 \(anchor_i\) 去負責 \(GT_j\)。 - \(CIoU\):使用了
GIoU,CIoU,DIoU,MSE這些誤差演演算法來實現邊框迴歸,驗證出CIoU損失效果最好。 - 略
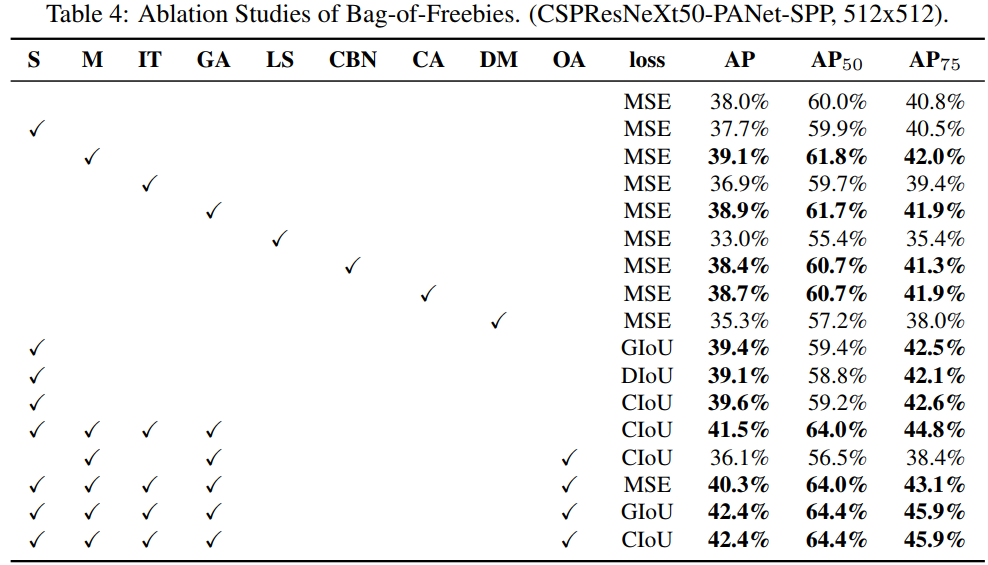
同時實驗證明,當使用 SPP,PAN 和 SAM 時,檢測器將獲得最佳效能。
4.4,不同骨幹和預訓練權重對檢測器訓練的影響
綜合各種改進後的骨幹網路對比實驗,發現 CSPDarknet53 比 CSPResNext 模型顯示出提高檢測器精度的更大能力。
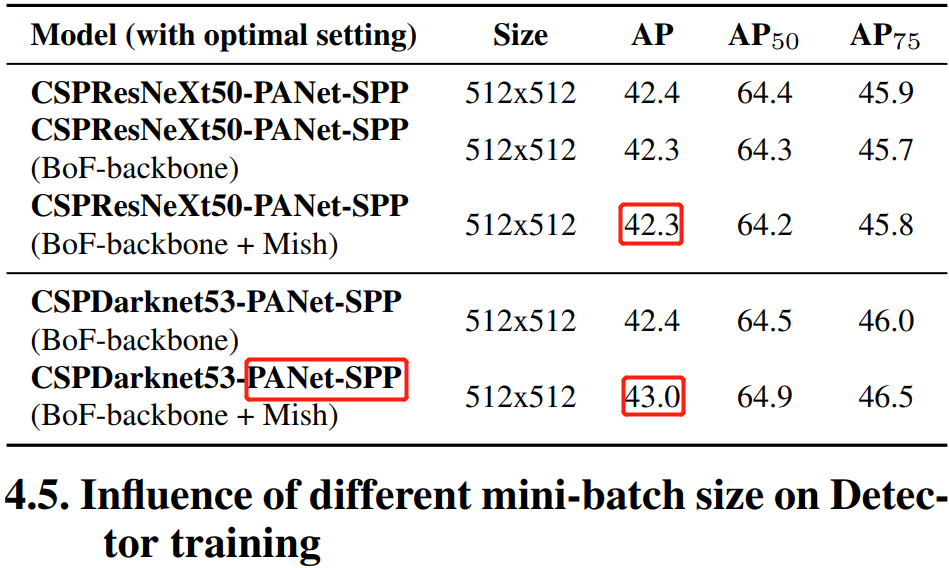
4.5,不同小批次的大小對檢測器訓練的影響
實驗證明,在使用了 BoF 和 BoS 訓練策略後,小批次大小(mini-batch sizes)對檢測器的效能幾乎沒有影響。實驗結果對比表格就不放了,可以看原論文。
5,結果
與其他 state-of-the-art 目標檢測演演算法相比,YOLOv4 在速度和準確性上都表現出了最優。詳細的比較實驗結果參考論文的圖 8、表 8和表 9。
6,YOLOv4 主要改進點
例舉出一些我認為比較關鍵且值得重點學習的改進點。
6.1,Backbone 改進
後續所有網路的結構圖來都源於江大白公眾號,之後不再一一註明結構圖來源。
Yolov4 的整體結構可以拆分成四大板塊,結構圖如下圖所示。
.png)
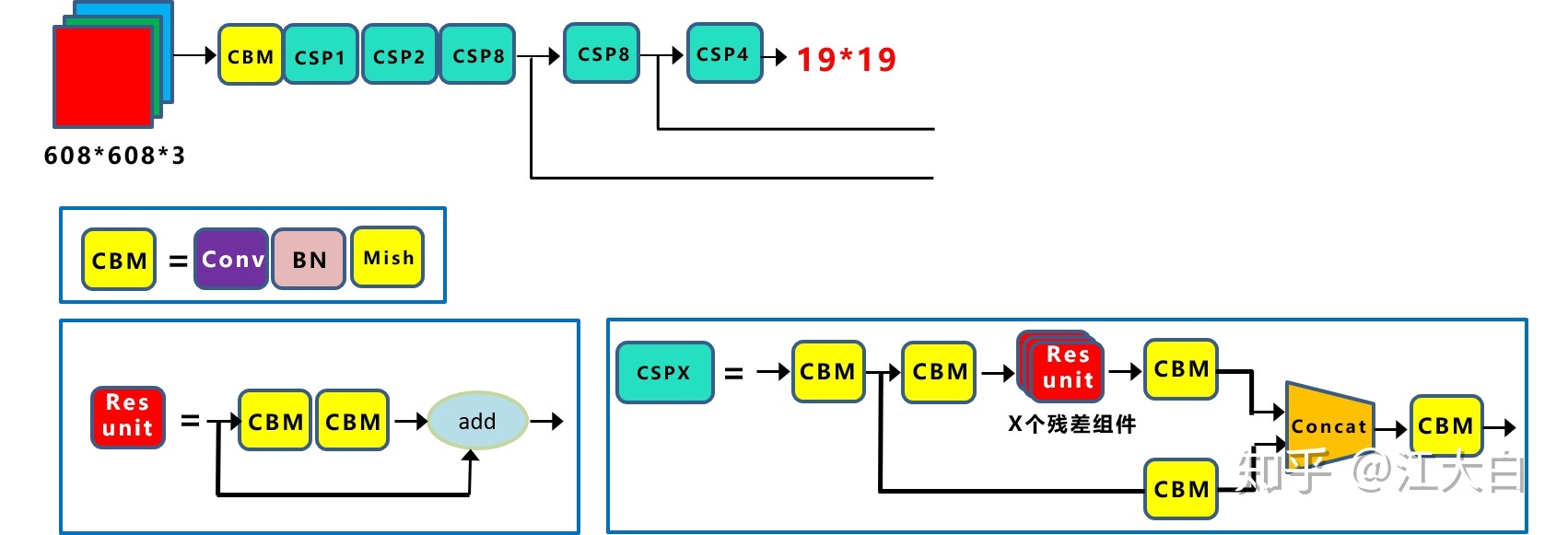
YOLOv4 的五個基本元件如下:
- CBM:
Yolov4網路結構中的最小元件,由Conv+Bn+Mish啟用函數三者組成。 - CBL:由
Conv+Bn+Leaky_relu啟用函數三者組成。 - Res unit:借鑑
Resnet網路中的殘差結構思想,讓網路可以構建的更深,和ResNet的basic block由兩個CBL(ReLU)組成不同,這裡的Resunit由2個CBM組成。 - CSPX:借鑑
CSPNet網路結構,由三個折積層和X個Res unint模組Concate組成。 - SPP:採用
1×1,5×5,9×9,13×13的最大池化的方式,進行多尺度融合。
其他基礎操作:
- Concat:張量拼接,會擴充維度。
- add:逐元素相加操作,不改變維度(
element-wise add)。
因為每個 CSPX 模組有 \(5+2\ast X\) 個折積層,因此整個 backbone 中共有 \(1 + (5+2\times 1) + (5+2\times 2) + (5+2\times 8) + (5+2\times 8) + (5+2\times 4) = 72\) 個折積層
這裡折積層的數目
72雖然不等同於YOLOv3中53,但是backbone依然是由 [1、2、8、8、4] 個折積模組組成的,只是這裡的YOLOv4中的折積模組替換為了CSPX折積模組,猜想是這個原因所以YOLOv4的作者這裡依然用來Darknet53命名字尾。
6.1.1,CSPDarknet53
YOLOv4 使用 CSPDarknet53 作為 backbone,它是在 YOLOv3 的骨幹網路 Darknet53 基礎上,同時借鑑 2019 年的 CSPNet 網路,所產生的新 backbone。
CSPDarknet53 包含 5 個 CSP 模組,CSP 中殘差單元的數量依次是 \([1, 2,8,8,4]\),這點和 Darknet53 類似。每個 CSP 模組最前面的折積核的大小都是 \(3\times 3\),stride=2,因此可以起到下取樣的作用(特徵圖大小縮小一倍)。因為 backbone 總共有 5 個 CSP模組,而輸入影象是 \(608\times 608\),所以特徵圖大小變化是:608->304->152->76->38->19,即經過 bckbone 網路後得到 \(19\times 19\) 大小的特徵圖。CSPDarknet53 網路結構圖如下圖所示。
CSPNet作者認為,MobiletNet、ShuffleNet系列模型是專門為行動端(CPU)平臺上設計的,它們所採用的深度可分離折積技術(DW+PW Convolution)並不相容用於邊緣計算的ASIC晶片。
CSP 結構是一種思想,它和ResNet、DenseNet 類似,可以看作是 DenseNet 的升級版,它將 feature map 拆成兩個部分,一部分進行折積操作,另一部分和上一部分折積操作的結果進行concate。
CSP 結構主要解決了四個問題:
- 增強 CNN 的學習能力,能夠在輕量化的同時保持著準確性;
- 降低計算成本;
- 降低記憶體開銷。CSPNet 改進了密集塊和過渡層的資訊流,優化了梯度反向傳播的路徑,提升了網路的學習能力,同時在處理速度和記憶體方面提升了不少。
- 能很好的和
ResNet、DarkNet等網路嵌入在一起,增加精度的同時減少計算量和降低記憶體成本。
6.1.2,Mish 啟用
在 YOLOv4 中使用 Mish 函數的原因是它的低成本和它的平滑、非單調、無上界、有下界等特點,在表 2 的對比實驗結果中,和其他常用啟用函數如 ReLU、Swish 相比,分類器的精度更好。
Mish 啟用函數是光滑的非單調啟用函數,定義如下:
Mish 函數曲線圖和 Swish 類似,如下圖所示。
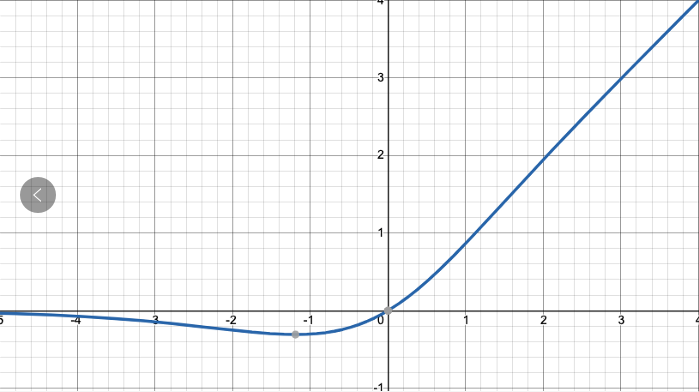
值得注意的是 Yolov4 的 Backbone 中的啟用函數都使用了Mish 啟用,但後面的 neck + head 網路則還是使用leaky_relu 函數。
6.1.3,Dropblock
Yolov4 中使用的 Dropblock ,其實和常見網路中的 Dropout 功能類似,也是緩解過擬合的一種正則化方式。
傳統
dropout功能是隨機刪除減少神經元的數量,使網路變得更簡單(緩解過擬合)。
6.2,Neck 網路改進
在目標檢測領域中,為了更好的融合 low-level 和 high-level 特徵,通常會在 backbone 和 head 網路之間插入一些網路層,這個中間部分稱為 neck 網路,典型的有 FPN 結構。
YOLOv4 的 neck 結構採用了 SPP 模組 和 FPN+PAN 結構。
先看看 YOLOv3 的 neck 網路的立體圖是什麼樣的,如下圖所示。

FPN 是自頂向下的,將高層的特徵資訊經過上取樣後和低層的特徵資訊進行傳遞融合,從而得到進行預測的特徵圖 ①②③。
再看下圖 YOLOv4 的 Neck 網路的立體影象,可以更清楚的理解 neck 是如何通過 FPN+PAN 結構進行融合的。

FPN 層自頂向下傳達強語意特徵,而特徵金字塔則自底向上傳達強定位特徵,兩兩聯手,從不同的主幹層對不同的檢測層進行引數聚合,這種正向反向同時結合的操作確實 6 啊。
值得注意的是,Yolov3 的 FPN 層輸出的三個大小不一的特徵圖①②③直接進行預測。但Yolov4 輸出特徵圖的預測是使用 FPN 層從最後的一個 76*76 特徵圖 ① 和而經過兩次PAN 結構的特徵圖 ② 和 ③ 。
另外一點是,原本的 PANet 網路的 PAN 結構中,兩個特徵圖結合是採用 shortcut + element-wise 操作,而 Yolov4 中則採用 concat(route)操作,特徵圖融合後的尺寸會變化。原本 PAN 和修改後的 PAN 結構對比圖如下圖所示。
6.3,預測的改進
6.3.1,使用CIoU Loss
Bounding Box Regeression 的 Loss 近些年的發展過程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
6.3.2,使用DIoU_NMS
6.4,輸入端改進
6.4.1,Mosaic 資料增強
YOLOv4 原創的 Mosaic 資料增強方法是基於 2019 年提出的 CutMix 資料增強方法做的優化。CutMix 只對兩張圖片進行拼接,而 Mosaic 更激進,採用 4 張圖片,在各自隨機縮放、裁剪和排布後進行拼接。

在目標檢測器訓練過程中,小目標的 AP 一般比中目標和大目標低很多。而 COCO 資料集中也包含大量的小目標,但比較麻煩的是小目標的分佈並不均勻。在整體的資料集中,它們的佔比並不平衡。
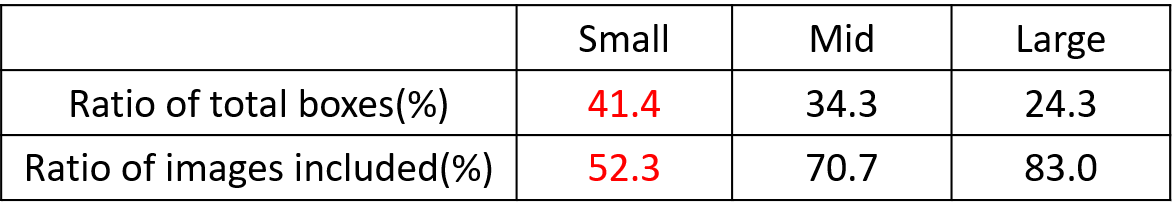
如上表所示,在 COCO 資料集中,小目標占比達到 41.4%,數量比中目標和大目標要大得多,但是在所有的訓練集圖片中,只有 52.3% 的圖片有小目標,即小物體數量很多、但分佈非常不均勻,而中目標和大目標的分佈相對來說更加均勻一些。
少部分圖片卻包含了大量的小目標。
針對這種狀況,Yolov4 的作者採用了 Mosaic 資料增強的方式。器主要有幾個優點:
- 豐富資料集:隨機使用
4張圖片,隨機縮放,再隨機分佈進行拼接,大大豐富了檢測資料集,特別是隨機縮放增加了很多小目標,讓網路的魯棒性更好。 - 減少訓練所需
GPU數量:Mosaic增強訓練時,可以直接計算4張圖片的資料,使得Mini-batch大小並不需要很大,一個GPU就可以訓練出較好的模型。
五,YOLOv5
YOLOv5 僅在 YOLOv4 發表一個月之後就公佈了,這導致很多人對 YOLOv5 的命名有所質疑,因為相比於它的前代 YOLOv4,它在理論上並沒有明顯的差異,雖然整合了最近的很多新的創新,但是這些整合點又和 YOLOv4 類似。我個人覺得之所以出現這種命名衝突應該是釋出的時候出現了 「撞車」,畢竟 YOLOv4 珠玉在前(早一個月),YOLOv5 也只能命名為 5 了。但是,我依然認為 YOLOv5 和 YOLOv4 是不同的,至少在工程上是不同的,它的程式碼是用 Python(Pytorch) 寫的,與 YOLOv4 的 C程式碼 (基於 darknet 框架)有所不同,所以程式碼更簡單、易懂,也更容易傳播。
另外,值得一提的是,YOLOv4 中提出的關鍵的 Mosaic 資料增強方法,作者之一就是 YOLOv5 的作者 Glenn Jocher。同時,YOLOv5 沒有發表任何論文,只是在 github 上開源了程式碼。
5.1,網路架構
通過解析程式碼倉庫中的 .yaml 檔案中的結構程式碼,YOLOv5 模型可以概括為以下幾個部分:
Backbone:Focus structure,CSP networkNeck:SPP block,PANetHead:YOLOv3 head using GIoU-loss
5.2,創新點
5.2.1,自適應anchor
在訓練模型時,YOLOv5 會自己學習資料集中的最佳 anchor boxes,而不再需要先離線執行 K-means 演演算法聚類得到 k 個 anchor box 並修改 head 網路引數。總的來說,YOLOv5 流程簡單且自動化了。
5.2.2, 自適應圖片縮放
在常用的目標檢測演演算法中,不同的圖片長寬都不相同,因此常用的方式是將原始圖片統一縮放到一個標準尺寸,再送入檢測網路中。
5.2.3,Focus結構
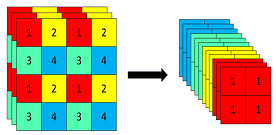
Focus 結構可以簡單理解為將 \(W\times H\) 大小的輸入圖片 4 個畫素分別取 1 個(類似於鄰近下取樣)形成新的圖片,這樣 1 個通道的輸入圖片會被劃分成 4 個通道,每個通道對應的 WH 尺寸大小都為原來的 1/2,並將這些通道組合在一起。這樣就實現了畫素資訊不丟失的情況下,提高通道數(通道數對計算量影響更小),減少輸入影象尺寸,從而大大減少模型計算量。
以 Yolov5s 的結構為例,原始 640x640x3 的影象輸入 Focus 結構,採用切片操作,先變成 320×320×12 的特徵圖,再經過一次 32 個折積核的折積操作,最終變成 320×320×32 的特徵圖。
5.3,四種網路結構
YOLOv5 通過在網路結構問價 yaml 中設定不同的 depth_multiple 和 width_multiple 引數,來建立大小不同的四種 YOLOv5 模型:Yolv5s、Yolv5m、Yolv5l、Yolv5x。
5.4,實驗結果
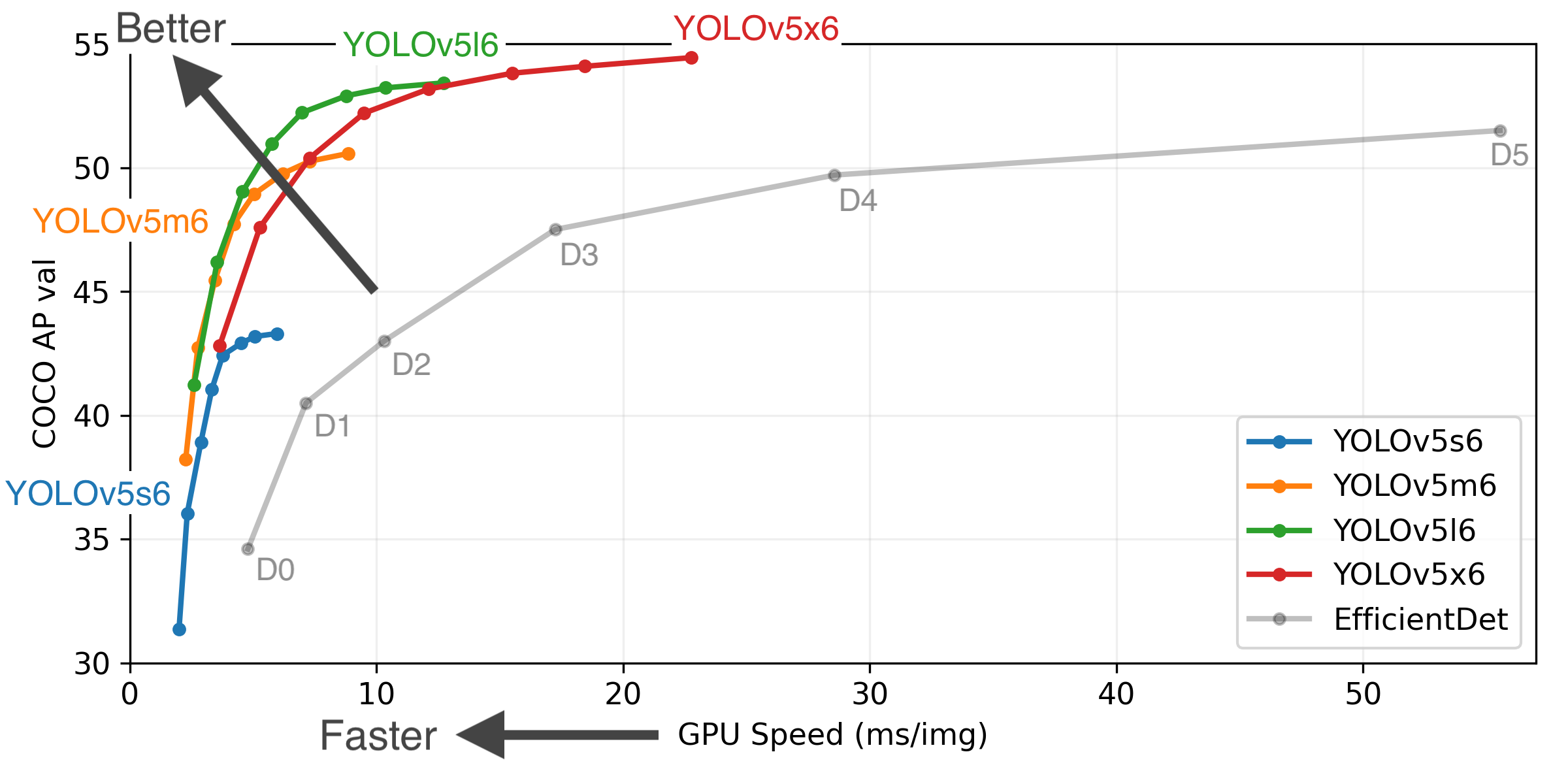
各個版本的 YOLOv5 在 COCO 資料集上和 V100 GPU 平臺上的模型精度和速度實驗結果曲線如下所示。
參考資料
- 你一定從未看過如此通俗易懂的YOLO系列(從v1到v5)模型解讀 (上)
- 你一定從未看過如此通俗易懂的YOLO系列(從v1到v5)模型解讀 (中)
- 目標檢測|YOLO原理與實現
- YOLO論文翻譯——中英文對照
- Training Object Detection (YOLOv2) from scratch using Cyclic Learning Rates
- 目標檢測|YOLOv2原理與實現(附YOLOv3)
- YOLO v1/v2/v3 論文
- https://github.com/BobLiu20/YOLOv3_PyTorch/blob/master/nets/yolo_loss.py
- https://github.com/Peterisfar/YOLOV3/blob/03a834f88d57f6cf4c5016a1365d631e8bbbacea/utils/datasets.py
- 深入淺出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基礎知識完整講解
EVOLUTION OF YOLO ALGORITHM AND YOLOV5: THE STATE-OF-THE-ART OBJECT DETECTION ALGORITHM