Redis網路模型究竟有多強
如果面試官問我:Redis為什麼這麼快?
我肯定會說:因為Redis是記憶體資料庫!如果不是直接把資料放在記憶體裡,甭管怎麼優化資料結構、設計怎樣的網路I/O模型,都不可能達到如今這般的執行效率。
但是這麼回答多半會讓我直接回去等通知了。。。因為面試官想聽到的就是資料結構和網路模型方面的回答,雖然這兩者只是在記憶體基礎上的錦上添花。
說這些並非為了強調網路模型並不重要,恰恰相反,它是Redis實現高吞吐量的重要底層支撐,是「高效能」的重要原因,卻不是「快」的直接理由。
本文將從BIO開始介紹,經過NIO、多路複用,最終說回Redis的Reactor模型,力求詳盡。本文與其他文章的不同點主要在於:
1、不會介紹同步阻塞I/O、同步非阻塞I/O、非同步阻塞I/O、非同步非阻塞I/O等概念,這些術語只是對底層原理的一些概念總結而已,我覺得沒有用。底層原理搞懂了,這些概念根本不重要,我希望讀完本文之後,各位能夠不再糾結這些概念。
2、不會只拿生活中例子來說明問題。之前看過特別多的文章,這些文章舉的「燒水」、「取快遞」的例子真的是深入淺出,但是看懂這些例子會讓我們有一種我們真的懂了的錯覺。尤其對於網路I/O模型而言,很難找到生活中非常貼切的例子,這種例子不過是已經懂了的人高屋建瓴,對外輸出的一種形式,但是對於一知半解的讀者而言卻猶如鈍刀殺人。
牛皮已經吹出去了,正文開始。
1. 一次I/O到底經歷了什麼
我們都知道,網路I/O是通過Socket實現的,在說明網路I/O之前,我們先來回顧(瞭解)一下本地I/O的流程。
舉一個非常簡單的例子,下面的程式碼實現了檔案的拷貝,將file1.txt的資料拷貝到file2.txt中:
public static void main(String[] args) throws Exception {
FileInputStream in = new FileInputStream("/tmp/file1.txt");
FileOutputStream out = new FileOutputStream("/tmp/file2.txt");
byte[] buf = new byte[in.available()];
in.read(buf);
out.write(buf);
}
這個I/O操作在底層到底經歷了什麼呢?下圖給出了說明:
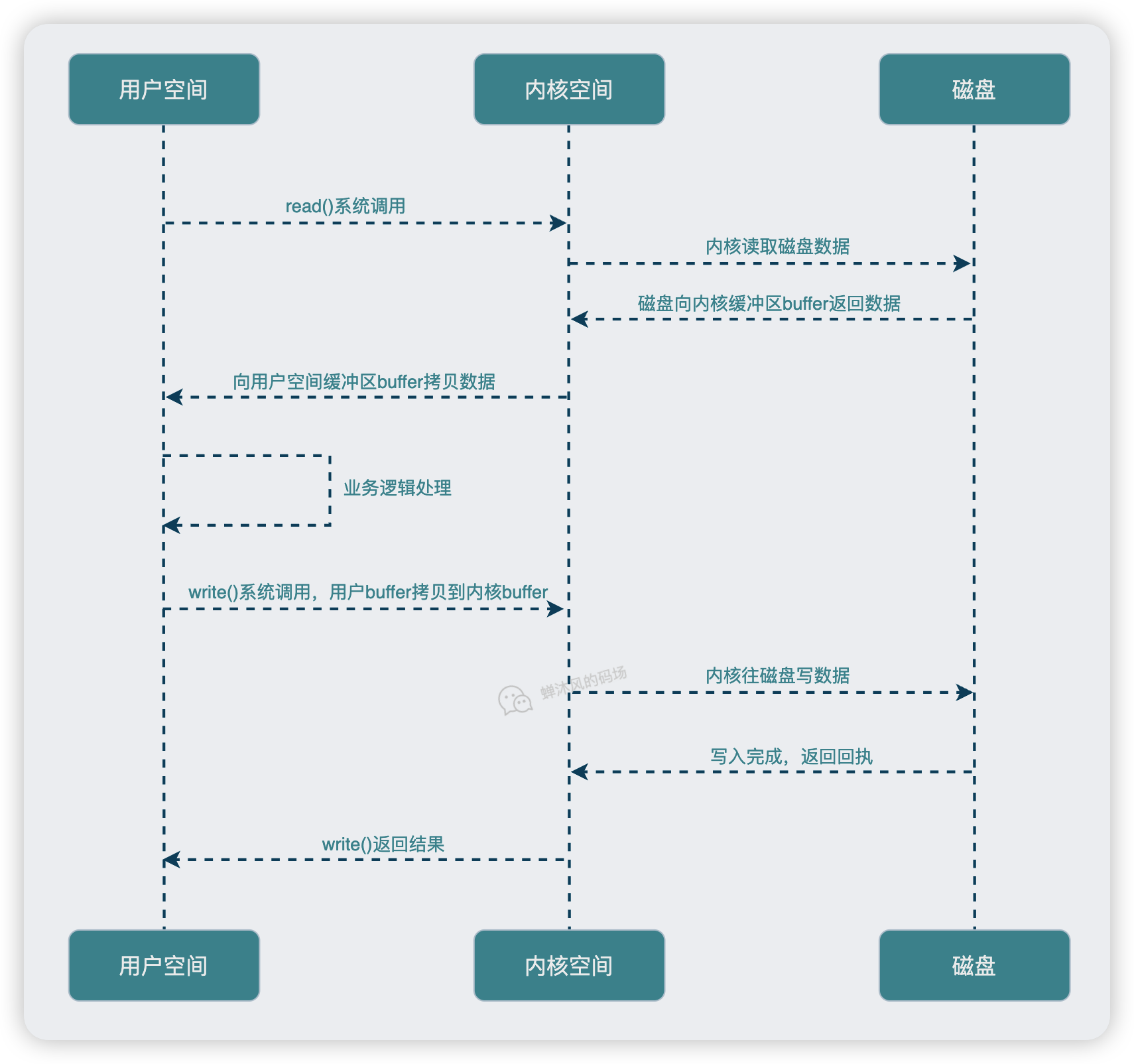
大致可以概括為如下幾個過程:
in.read(buf)執行時,程式向核心發起read()系統呼叫;- 作業系統發生上下文切換,由使用者態(User mode)切換到核心態(Kernel mode),把資料讀取到核心緩衝區 (buffer)中;
- 核心把資料從核心空間拷貝到使用者空間,同時由核心態轉為使用者態;
- 繼續執行
out.write(buf); - 再次發生上下文切換,將資料從使用者空間buffer拷貝到核心空間buffer中,由核心把資料寫入檔案。
之所以先拿本地I/O舉個例子,是因為我想說明I/O模型並非僅僅針對網路IO(雖然網路I/O最常被我們拿來舉例),本地I/O同樣受到I/O模型的約束。比如在這個例子中,本地I/O用的就是典型的BIO,至於什麼是BIO,稍安勿躁,接著往下看。
除此之外,通過本地I/O,我還想向各位說明下面幾件事情:
- 我們編寫的程式本身並不能對檔案進行讀寫操作,這個步驟必須依賴於作業系統,換個詞兒就是「核心」;
- 一個看似簡單的I/O操作卻在底層引發了多次的使用者空間和核心空間的切換,並且資料在核心空間和使用者空間之間拷貝來拷貝去。
不同於本地I/O是從原生的檔案中讀取資料,網路I/O是通過網路卡讀取網路中的資料,網路I/O需要藉助Socket來完成,所以接下來我們重新認識一下Socket。
2. 什麼是Socket
這部分在一定程度上是我的強迫症作祟,我關於文章對知識點講解的完備性上對自己近乎苛刻。我覺得把Socket講明白對接下來的講解是一件很重要的事情,看過我之前的文章的讀者或許能意識到,我儘量避免把前置知識直接以連結的形式展示出來,我認為會割裂整篇文章的閱讀體驗。
不割裂的結果就是文章可能顯得很囉嗦,好像一件事情非得從盤古開天闢地開始講起。因此,如果各位覺得對這個知識點有足夠的把握,就直接略過好了~
我們所做的任何需要和遠端裝置進行互動的操作,並非是操作軟體本身進行的資料通訊。舉個例子就是我們用瀏覽器刷B站視訊的時候,並非是瀏覽器自身向B站請求視訊資料的,而是必須委託作業系統核心中的協定棧。
協定棧就是下邊這些書的程式碼實現,裡邊包含了TCP/IP及其他各種網路實現細節,這樣解釋應該好理解吧。

而Socket庫就是作業系統提供給我們的,用於呼叫協定棧網路功能的一堆程式元件的集合,也就是我們平時聽過的作業系統庫函數,Socket庫和協定棧的關係如下圖所示。
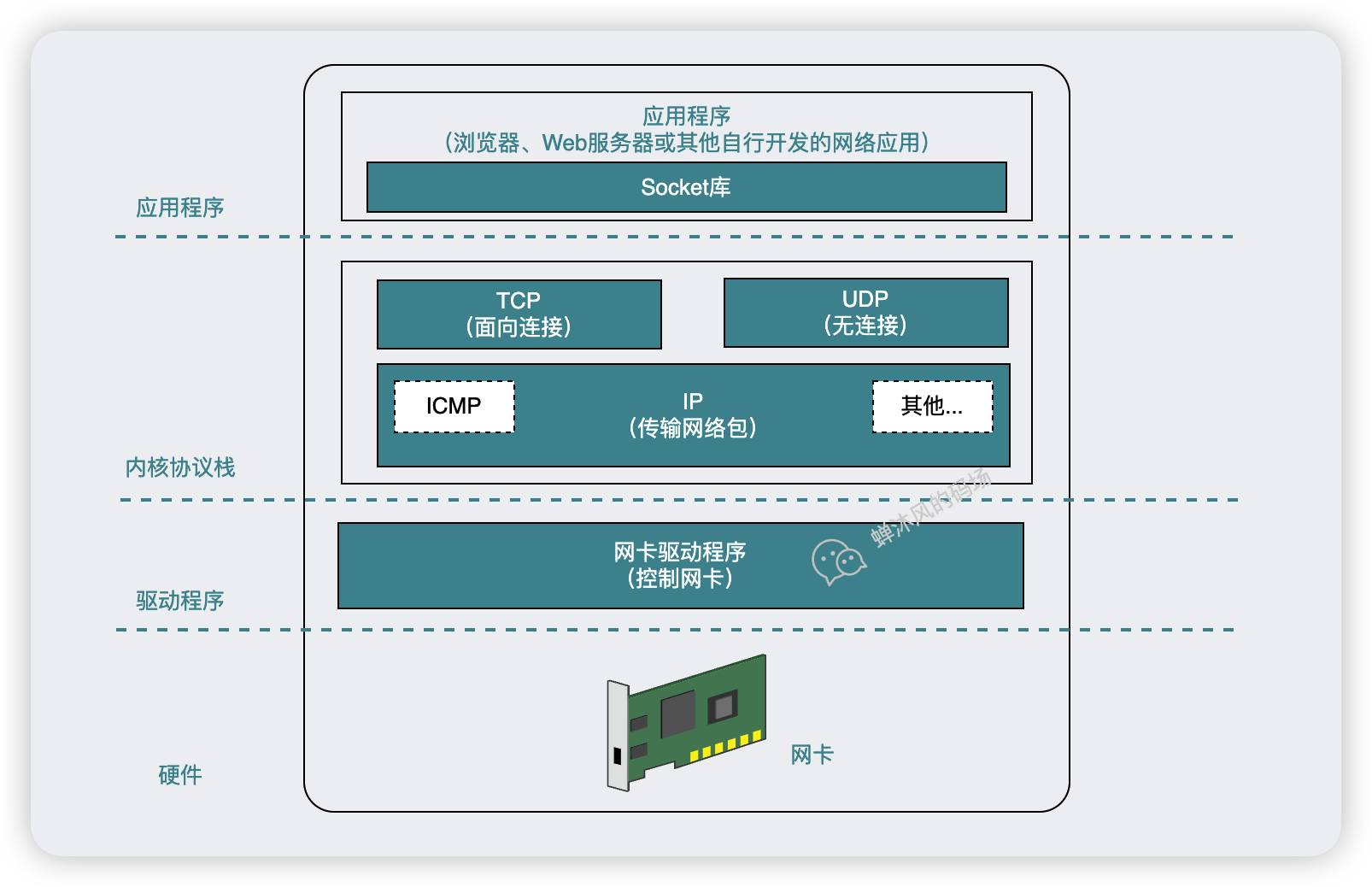
使用者程序向作業系統核心的協定棧發出委託時,需要按照指定的順序來呼叫 Socket 庫中的程式元件。
本文的所有案例都以TCP協定為例進行講解。
大家可以把資料收發想象成在兩臺計算機之間建立了一條資料通道,計算機通過這條通道進行資料收發的雙向操作,當然,這條通道是邏輯上的,並非實際存在。
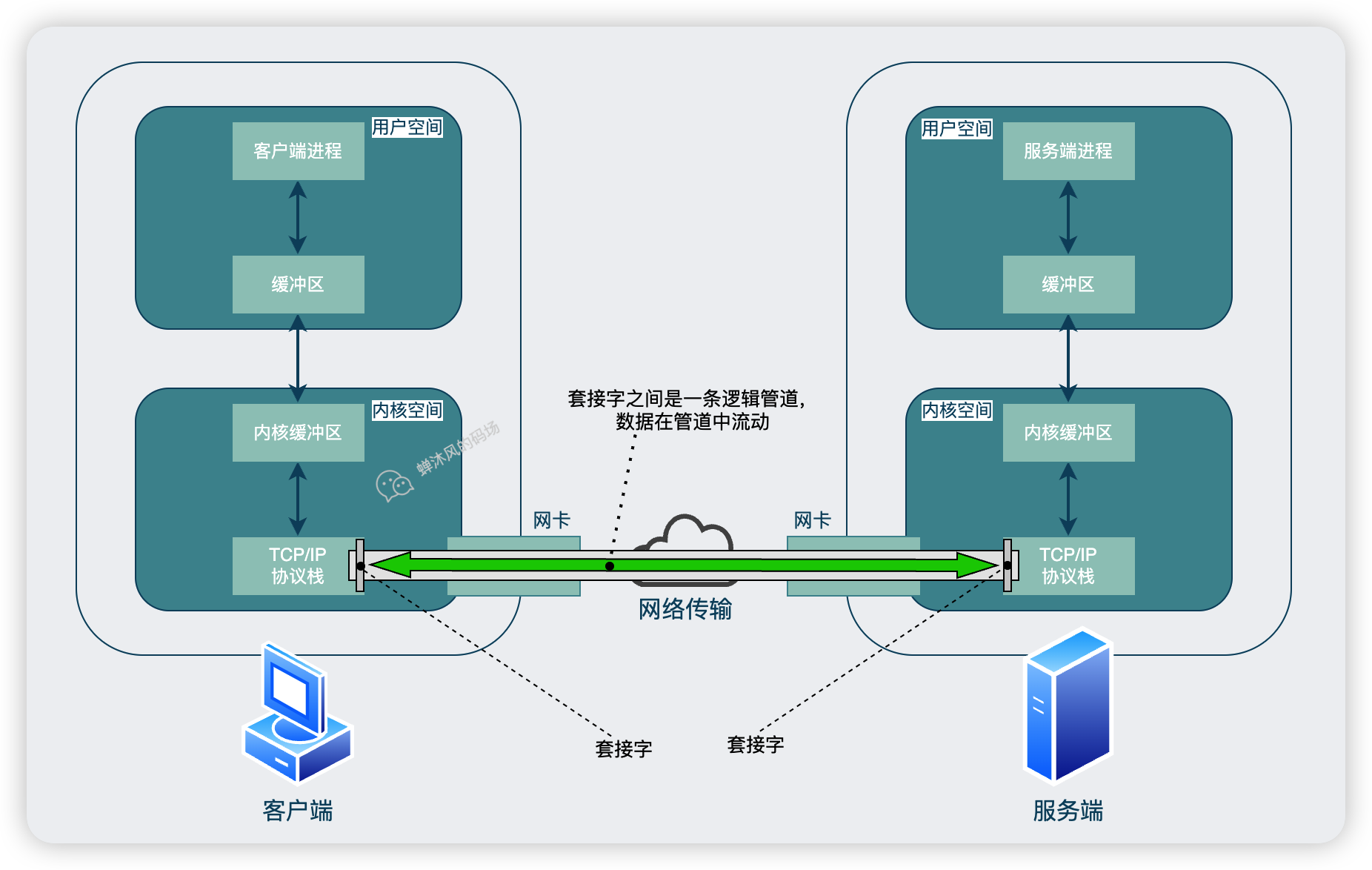
資料通過管道流動這個比較好理解,但是問題在於這條管道雖然只是邏輯上存在,但是這個「邏輯」也不是光用腦袋想想就會出現的。就好比我們手機打電話,你總得先把號碼撥出去呀。
對應到網路I/O中,就意味著雙方必須建立各自的資料出入口,然後將兩個資料出入口像連線水管一樣接通,這個資料出入口就是上圖中的通訊端,就是大名鼎鼎的socket。
使用者端和伺服器端之間的通訊可以被概括為如下4個步驟:
- 伺服器端建立socket,等待使用者端連線(建立socket階段);
- 使用者端建立socket,連線到伺服器端(連線階段);
- 收發資料(通訊階段);
- 斷開管道並刪除socket(斷開連線)。
每一步都是通過特定語言的API呼叫Socket庫,Socket庫委託協定棧進行操作的。socket就是呼叫Socket庫中程式元件之後的產成品,比如Java中的ServerSocket,本質上還是呼叫作業系統的Socket庫,因此下文的程式碼範例雖然採用Java語言,但是希望各位讀者注意:只有語法上抽象與具體的區別,socket的操作邏輯是完全一致的。
但是,我還是得花點口舌囉嗦一下這幾個步驟的一些細節,為了不至於太枯燥,接下來將這4個步驟和BIO一起講解。
3. 阻塞I/O(Blocking I/O,BIO)
我們先從比較簡單的使用者端開始談起。
3.1. 使用者端的socket流程
public class BlockingClient {
public static void main(String[] args) {
try {
// 建立通訊端 & 建立連線
Socket socket = new Socket("localhost", 8099);
// 向伺服器端寫資料
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("我是使用者端,收到請回答!!\n");
bufferedWriter.flush();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String line = bufferedReader.readLine();
System.out.println("收到伺服器端返回的資料:" + line);
} catch (IOException e) {
// 錯誤處理
}
}
}
上面展示了一段非常簡單的Java BIO的使用者端程式碼,相信你們一定不會感到陌生,接下來我們一點點分析使用者端的socket操作究竟做了什麼。
Socket socket = new Socket("localhost", 8099);
雖然只是簡單的一行語句,但是其中包含了兩個步驟,分別是建立通訊端、建立連線,等價於下面兩行虛擬碼:
<描述符> = socket(<使用IPv4>, <使用TCP>, ...);
connect(<描述符>, <伺服器IP地址和埠號>, ...);
注意:
文中會出現多個關於*ocket的術語,比如Socket庫,就是作業系統提供的庫函數;socket元件就是Socket庫中和socket相關的程式的統稱;socket()函數以及socket(或稱:通訊端)就是接下來要講的內容,我會盡量在描述過程中不產生混淆,大家注意根據上下文進行辨析。
3.1.1. 何為socket?
上文已經說了,邏輯管道存在的前提是需要各自先建立socket(就好比你打電話之前得先有手機),然後將兩個socket進行關聯。使用者端建立socket非常簡單,只需要呼叫Socket庫中的socket元件的socket()函數就可以了。
<描述符> = socket(<使用IPv4>, <使用TCP>, ...);
使用者端程式碼呼叫socket()函數向協定棧申請建立socket,協定棧會根據你的引數來決定socket是IPv4還是IPv6,是TCP還是UDP。除此之外呢?
基本的髒活累活都是協定棧完成的,協定棧想傳遞訊息總得知道目的IP和埠吧,要是你用的是TCP協定,你甚至還得記錄每個包的傳送時間以及每個包是否收到回覆,否則TCP的超時重傳就不會正常工作。。。等等。。。
因此,協定棧會申請一塊記憶體空間,在其中存放諸如此類的各種控制資訊,協定棧就是根據這些控制資訊來工作的,這些控制資訊我們就可以理解為是socket的實體。怎麼樣,是不是之前感覺虛無縹緲的socket突然鮮活了起來?
我們看一個更鮮活的例子,我在本級上執行netstat -anop命令,得到的每一行資訊我們就可以理解為是一個socket,我們重點看一下下圖中標註的兩條。
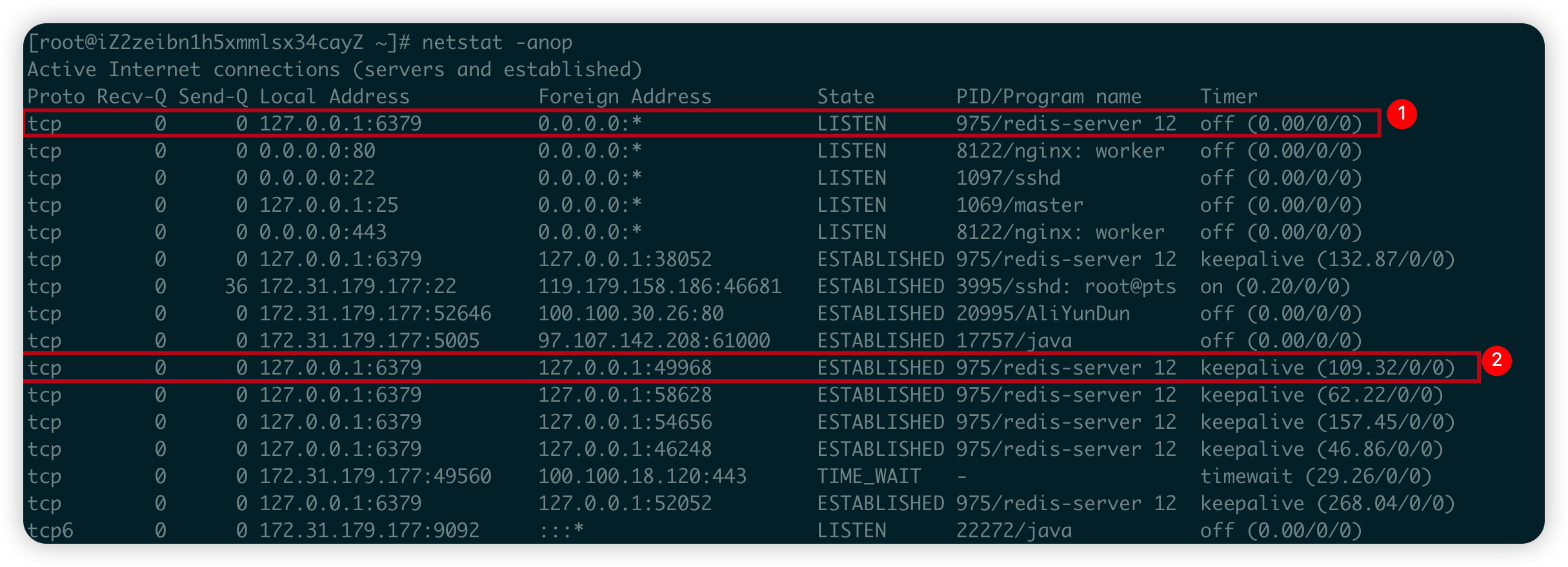
這兩條都是redis-server的socket資訊,第1條表示redis-server服務正在IP為127.0.0.1,埠為6379的主機上等待遠端使用者端連線,因為Foreign address為0.0.0.0:*,表示通訊還未開始,IP無法確定,因此State為LISTEN狀態;第2條表示redis-server服務已經建立了與IP為127.0.0.1的使用者端之間的連線,且使用者端使用49968的埠號,目前該socket的狀態為ESTABLISHED。
協定棧建立完socket之後,會返回一個描述符給應用程式。描述符用來識別不同的socket,可以將描述符理解成某個socket的編號,就好比你去洗澡的時候,前臺會發給你一個手牌,原理差不多。
之後對socket進行的任何操作,只要我們出示自己的手牌,啊呸,描述符,協定棧就能知道我們想通過哪個socket進行資料收發了。
至於為什麼不直接返回socket的記憶體地址以及其他細節,可以參考我之前寫的文章《2>&1到底是什麼意思》
3.1.2. 何為連線?
connect(<描述符>, <伺服器IP地址和埠號>, ...);
socket剛建立的時候,裡邊沒啥有用的資訊,別說自己即將通訊的物件長啥樣了,就是叫啥,現在在哪兒也不知道,更別提協定棧,自然是啥也知道!
因此,第1件事情就是應用程式需要把伺服器的IP地址和埠號告訴協定棧,有了街道和門牌號,接下來協定棧就可以去找伺服器了。
對於伺服器也是一樣的情況,伺服器也有自己的socket,在接收到使用者端的資訊的同時,伺服器也得知道使用者端的IP和埠號啊,要不然只能單線聯絡了。因此對使用者端做的第1件事情就有了要求,必須把使用者端自己的IP以及埠號告知伺服器,然後兩者就可以愉快的聊天了。
這就是3次握手。
一句話概括連線的含義:連線實際上是通訊的雙方交換控制資訊,並將必要的控制資訊儲存在各自的socket中的過程。
連線過後,每個socket就被4個資訊唯一標識,通常我們稱為四元組:

趁熱打鐵,我們趕緊再說一說伺服器端建立socket以及接受連線的過程。
3.2. 伺服器端的socket流程
public class BIOServerSocket {
public static void main(String[] args) {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8099);
System.out.println("啟動服務:監聽埠:8099");
// 等待使用者端的連線過來,如果沒有連線過來,就會阻塞
while (true) {
// 表示阻塞等待監聽一個使用者端連線,返回的socket表示連線的使用者端資訊
Socket socket = serverSocket.accept();
System.out.println("使用者端:" + socket.getPort());
// 表示獲取使用者端的請求報文
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// 讀操作也是阻塞的
String clientStr = bufferedReader.readLine();
System.out.println("收到使用者端傳送的訊息:" + clientStr);
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("ok\n");
bufferedWriter.flush();
}
} catch (IOException e) {
// 錯誤處理
} finally {
// 其他處理
}
}
}
上面一段是非常簡單的Java BIO的伺服器端程式碼,程式碼的含義就是:
- 建立socket;
- 將socket設定為等待連線狀態;
- 接受使用者端連線;
- 收發資料。
這些步驟呼叫的底層程式碼的虛擬碼如下:
// 建立socket
<Server描述符> = socket(<使用IPv4>, <使用TCP>, ...);
// 繫結埠號
bind(<Server描述符>, <埠號等>, ...);
// 設定socket為等待連線狀態
listen(<Server描述符>, ...);
// 接受使用者端連線
<新描述符> = accept(<Server描述符>, ...);
// 從使用者端連線中讀取資料
<讀取的資料長度> = read(<新描述符>, <接受緩衝區>, <緩衝區長度>);
// 向用戶端連線中寫資料
write(<新描述符>, <傳送的資料>, <傳送的資料長度>);
3.2.1. 建立socket
建立socket這一步和使用者端沒啥區別,不同的是這個socket我們稱之為等待連線socket(或監聽socket)。
3.2.2. 繫結埠號
bind()函數會將埠號寫入上一步生成的監聽socket中,這樣一來,監聽socket就完整儲存了伺服器端的IP和埠號。
3.2.3. listen()的真正作用
listen(<Server描述符>, <最大連線數>);
很多小夥伴一定會對這個listen()有疑問,監聽socket都已經建立完了,埠也已經繫結完了,為什麼還要多呼叫一個listen()呢?
我們剛說過監聽socket和使用者端建立的socket沒什麼區別,問題就出在這個沒什麼區別上。
socket被建立出來的時候都預設是一個主動socket,也就說,核心會認為這個socket之後某個時候會呼叫connect()主動向別的裝置發起連線。這個預設對使用者端socket來說很合理,但是監聽socket可不行,它只能等著使用者端連線自己,因此我們需要呼叫listen()將監聽socket從主動設定為被動,明確告訴核心:你要接受指向這個監聽socket的連線請求!
此外,listen()的第2個引數也大有來頭!監聽socket真正接受的應該是已經完整完成3次握手的使用者端,那麼還沒完成的怎麼辦?總得找個地方放著吧。於是核心為每一個監聽socket都維護了兩個佇列:
- 半連線佇列(未完成連線的佇列)
這裡存放著暫未徹底完成3次握手的socket(為了防止半連線攻擊,這裡存放的其實是佔用記憶體極小的request _sock,但是我們直接理解成socket就行了),這些socket的狀態稱為SYN_RCVD。
- 已完成連線佇列
每個已完成TCP3次握手的使用者端連線對應的socket就放在這裡,這些socket的狀態為ESTABLISHED。
文字太多了,有點幹,上個圖!
解釋一下動圖中的內容:
- 使用者端呼叫
connect()函數,開始3次握手,首先傳送一個SYN X的報文(X是個數位,下同); - 伺服器端收到來自使用者端的
SYN,然後在監聽socket對應的半連線佇列中建立一個新的socket,然後對使用者端發回響應SYN Y,捎帶手對使用者端的報文給個ACK; - 直到使用者端完成第3次握手,剛才新建立的socket就會被轉移到已連線佇列;
- 當程序呼叫
accept()時,會將已連線佇列頭部的socket返回;如果已連線佇列為空,那麼程序將被睡眠,直到已連線佇列中有新的socket,程序才會被喚醒,將這個socket返回。
第4步就是阻塞的本質啊,朋友們!
3.3. 答疑時間
3.3.1. Q1.佇列中的物件是socket嗎?
呃。。。乖,咱就把它當成socket就好了,這樣容易理解,其實具體裡邊存放的資料結構是啥,我也很想知道,等我寫完這篇文章,我研究完了告訴你。
3.3.2. Q2.accept()這個函數你還沒講是啥意思呢?
accept()函數是由伺服器端呼叫的,用於從已連線佇列中返回一個socket描述符;如果socket為阻塞式的,那麼如果已連線佇列為空,accept()程序就會被睡眠。BIO恰好就是這個樣子。
3.3.3. Q3.accept()為什麼不直接把監聽socket返回呢?
因為在佇列中的socket經過3次握手過程的控制資訊交換,socket的4元組的資訊已經完整了,用做socket完全沒問題。
監聽socket就像一個客服,我們給客服打電話,然後客服找到解決問題的人,幫助我們和解決問題的人建立聯絡,如果直接把監聽socket返回,而不使用連線socket,就沒有socket繼續等待連線了。
哦對了,accept()返回的socket也有個名字,叫連線socket。
3.4. BIO究竟阻塞在哪裡
拿Server端的BIO來說明這個問題,阻塞在了serverSocket.accept()以及bufferedReader.readLine()這兩個地方。有什麼辦法可以證明阻塞嗎?
簡單的很!你在serverSocket.accept(); 的下一行打個斷點,然後debug模式執行BIOServerSocket,在沒有使用者端連線的情況下,這個斷點絕不會觸發!同樣,在bufferedReader.readLine();下一行打個斷點,在已連線的使用者端傳送資料之前,這個斷點絕不會觸發!
readLine()的阻塞還帶來一個非常嚴重的問題,如果已經連線的使用者端一直不傳送訊息,readLine()程序就會一直阻塞(處於睡眠狀態),結果就是程式碼不會再次執行到accept(),這個ServerSocket沒辦法接受新的使用者端連線。
解決這個問題的核心就是別讓程式碼卡在readLine()就可以了,我們可以使用新的執行緒來readLine(),這樣程式碼就不會阻塞在readLine()上了。
3.5. 改造BIO
改造之後的BIO長這樣,這下子伺服器端就可以隨時接受使用者端的連線了,至於啥時候能read到使用者端的資料,那就讓執行緒去處理這個事情吧。
public class BIOServerSocketWithThread {
public static void main(String[] args) {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(8099);
System.out.println("啟動服務:監聽埠:8099");
// 等待使用者端的連線過來,如果沒有連線過來,就會阻塞
while (true) {
// 表示阻塞等待監聽一個使用者端連線,返回的socket表示連線的使用者端資訊
Socket socket = serverSocket.accept(); //連線阻塞
System.out.println("使用者端:" + socket.getPort());
// 表示獲取使用者端的請求報文
new Thread(new Runnable() {
@Override
public void run() {
try {
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(socket.getInputStream())
);
String clientStr = bufferedReader.readLine();
System.out.println("收到使用者端傳送的訊息:" + clientStr);
BufferedWriter bufferedWriter = new BufferedWriter(
new OutputStreamWriter(socket.getOutputStream())
);
bufferedWriter.write("ok\n");
bufferedWriter.flush();
} catch (Exception e) {
//...
}
}
}).start();
}
} catch (IOException e) {
// 錯誤處理
} finally {
// 其他處理
}
}
}
事情的順利進展不禁讓我們飄飄然,我們居然是使用高階的多執行緒技術解決了BIO的阻塞問題,雖然目前每個使用者端都需要一個單獨的執行緒來處理,但accept()總歸不會被readLine()卡死了。
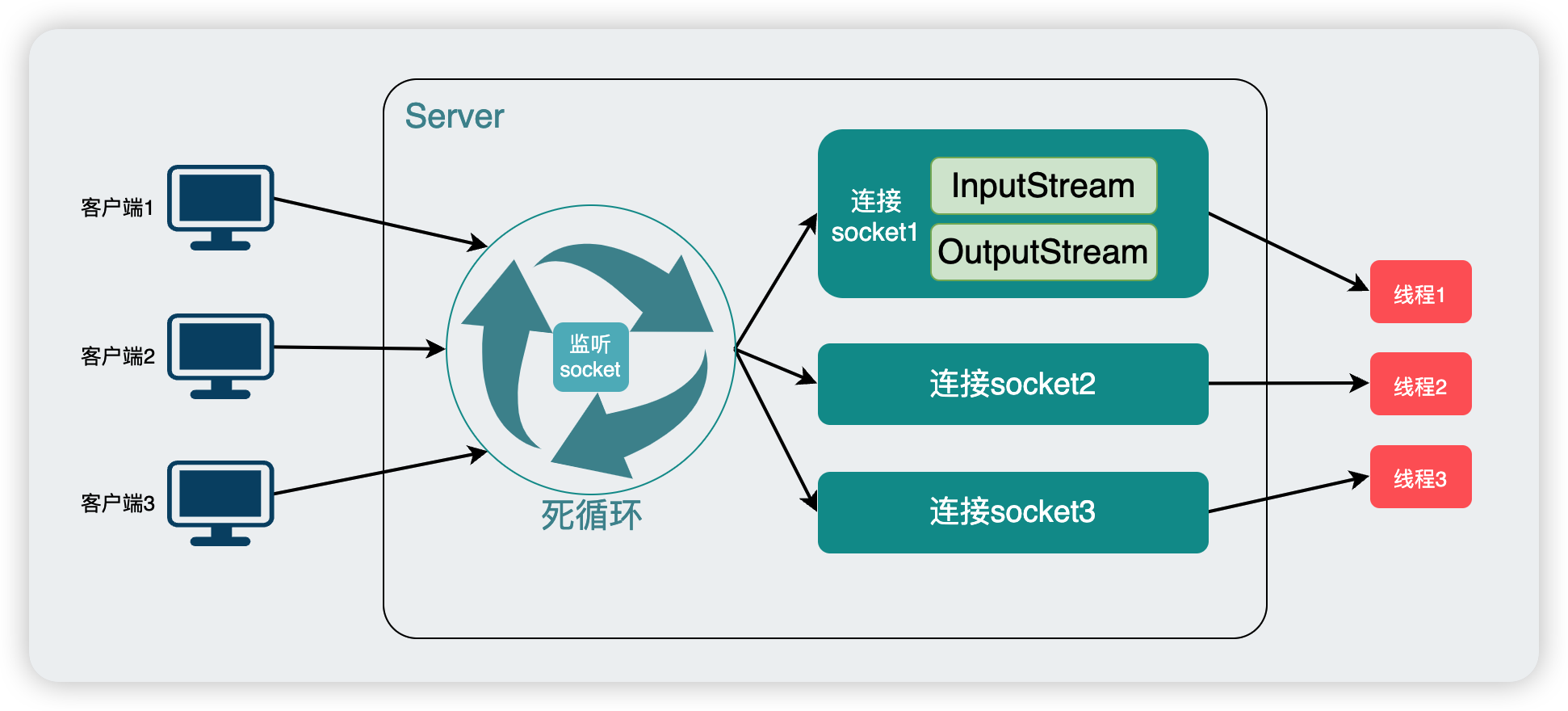
所以我們改造完之後的程式是不是就是非阻塞IO了呢?
想多了。。。我們只是用了點奇技淫巧罷了,改造完的程式碼在系統呼叫層面該阻塞的地方還是阻塞,說白了,Java提供的API完全受限於作業系統提供的系統呼叫,在Java語言級別沒能力改變底層BIO的事實!

3.6. 掀開BIO的遮羞布
接下來帶大家看一下改造之後的BIO程式碼在底層都呼叫了哪一些系統呼叫,讓我們在底層上對上文的內容加深一下理解。
給大家打個氣,接下來的內容其實非常好理解,大家跟著文章一步步地走,一定能看得懂,如果自己動手操作一遍,那就更好了。
對了,我下來使用的JDK版本是JDK8。
strace是Linux上的一個程式,該程式可以追蹤並記錄引數後邊執行的程序對核心進行了哪些系統呼叫。
strace -ff -o out java BIOServerSocketWithThread
其中:
-o:
將系統呼叫的追蹤資訊輸出到out檔案中,不加這個引數,預設會輸出到標準錯誤stderr。
-ff
如果指定了-o選項,strace會追蹤和程式相關的每一個程序的系統呼叫,並將資訊輸出到以程序id為字尾的out檔案中。舉個例子,比如BIOServerSocketWithThread程式執行過程中有一個ID為30792的程序,那麼該程序的系統呼叫紀錄檔會輸出到out.30792這個檔案中。
我們執行strace命令之後,生成了很多個out檔案。
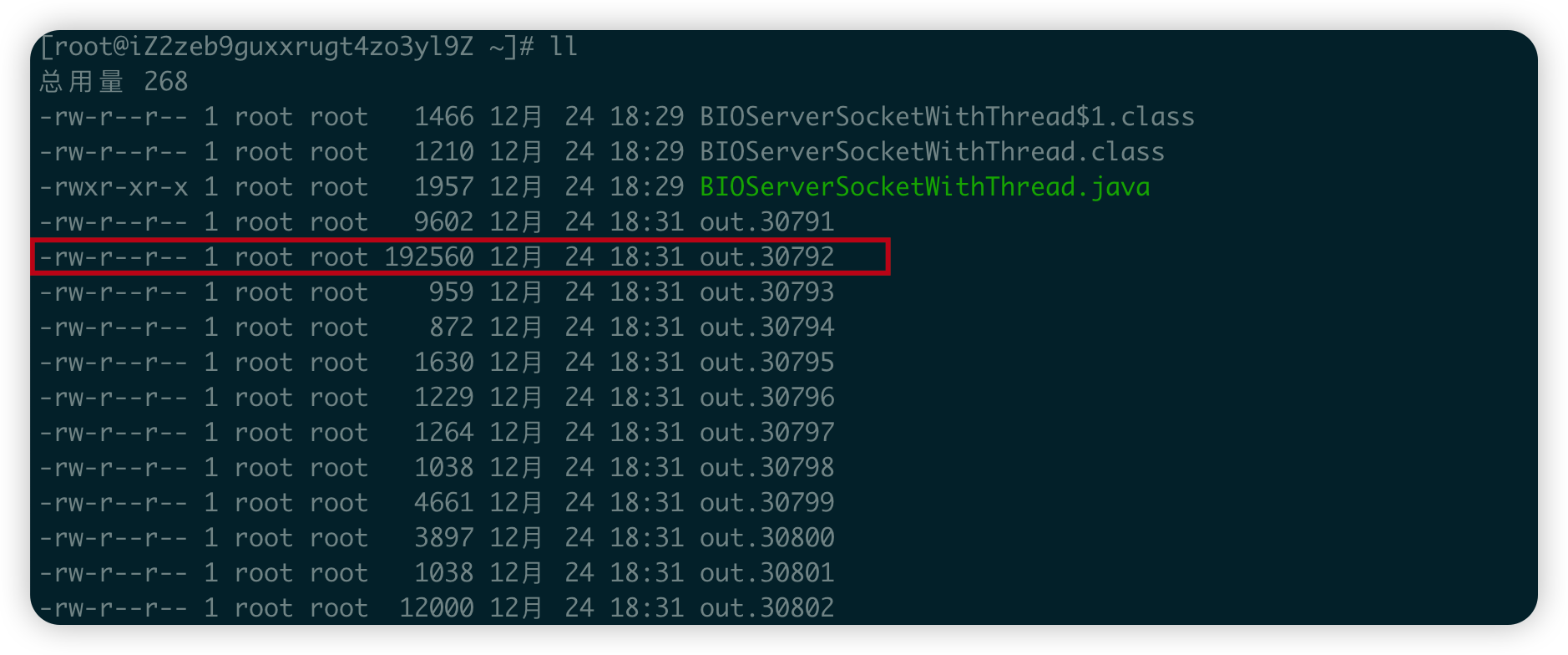
這麼多程序怎麼知道哪個是我們需要追蹤的呢?我就挑了一個容量最大的檔案進行檢視,也就是out.30792,事實上,這個檔案也恰好是我們需要的,擷取一下里邊的內容給大家看一下。
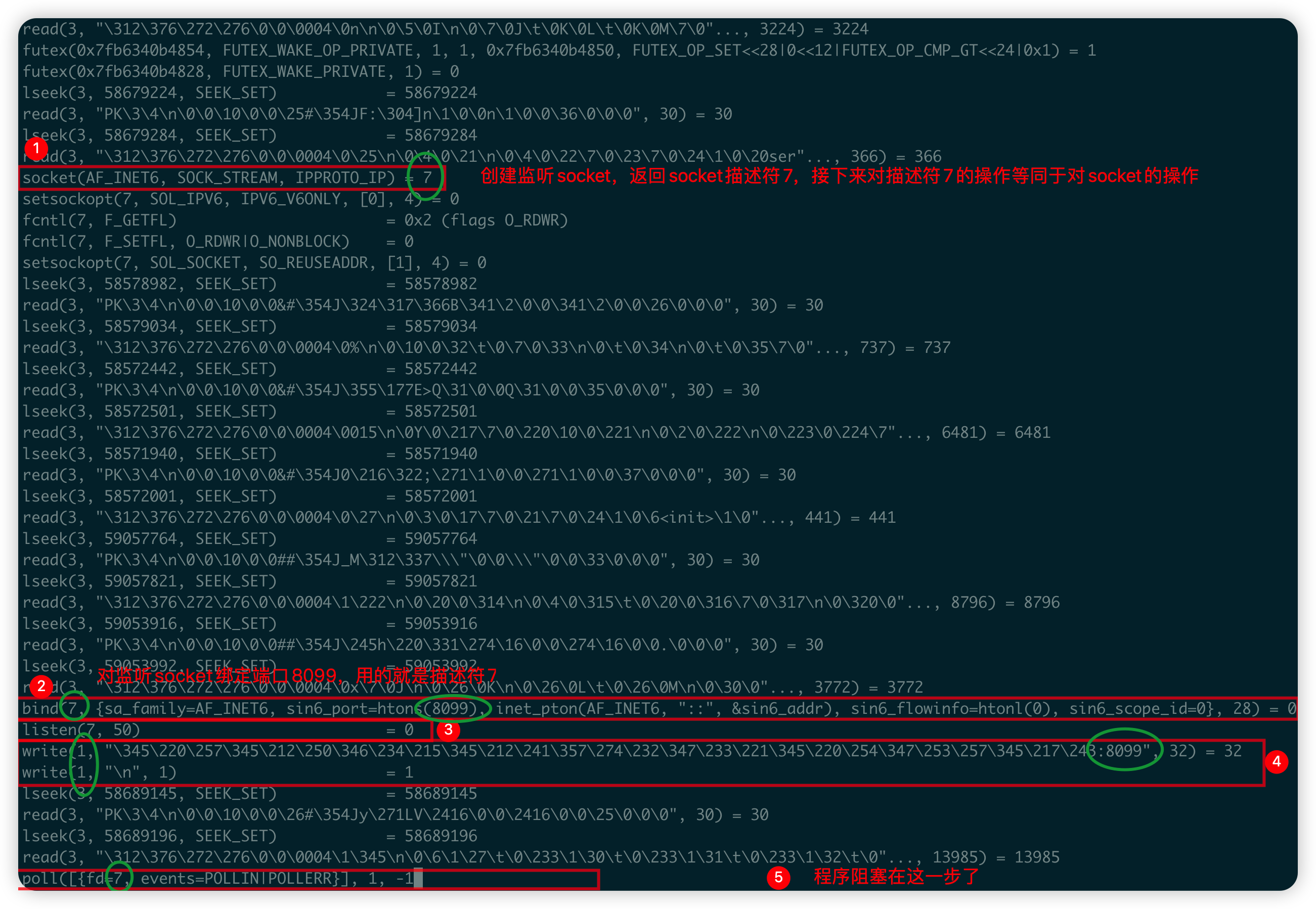
可以看到圖中的有非常多的行,說明我們寫的這麼幾行程式碼其實默默呼叫了非常多的系統呼叫,拋開細枝末節,看一下上圖中我重點標註的系統呼叫,是不是就是上文中我解釋過的函數?我再詳細解釋一下每一步,大家聯絡上文,會對BIO的底層理解的更加通透。
- 生成監聽socket,並返回socket描述符
7,接下來對socket進行操作的函數都會有一個引數為7; - 將
8099埠繫結到監聽socket,bind的第一個引數就是7,說明就是對監聽socket進行的操作; listen()將監聽socket(引數為7)設定為被動接受連線的socket,並且將佇列的長度設定為50;- 實際上就是
System.out.println("啟動服務:監聽埠:8099");這一句的系統呼叫,只不過中文被編碼了,所以我特意把:8099圈出來證明一下;
額外說兩點:
其一:可以看到,這麼一句簡單的列印輸出在底層實際呼叫了兩次
write系統呼叫,這就是為什麼不推薦在生產環境下使用列印語句的原因,多少會影響系統效能;其二:
write()的第一個引數為1,也是檔案描述符,表示的是標準輸出stdout,關於標準輸入、標準輸出、標準錯誤和檔案描述符之間的關係可以參見《2>&1到底是什麼意思》。
- 系統呼叫阻塞在了
poll()函數,怎麼看出來的阻塞?out檔案的每一行執行完畢都會有一個= 返回值,而poll()目前沒有返回值,因此阻塞了。實際上poll()系統呼叫對應的Java語句就是serverSocket.accept();。
不對啊?為什麼底層呼叫的不是accept()而是poll()?poll()應該是多路複用才是啊。在JDK4之前,底層確實直接呼叫的是accept(),但是之後的JDK對這一步進行了優化,除了呼叫accept(),還加上了poll()。poll()的細節我們下文再說,這裡可以起碼證明了poll()函數依然是阻塞的,所以整個BIO的阻塞邏輯沒有改變。
接下來我們起一個使用者端對程式發起連線,直接用Linux上的nc程式即可,比較簡單:
nc localhost 8099
發起連線之後(但並未主動傳送資訊),out.30792的內容發生了變化:
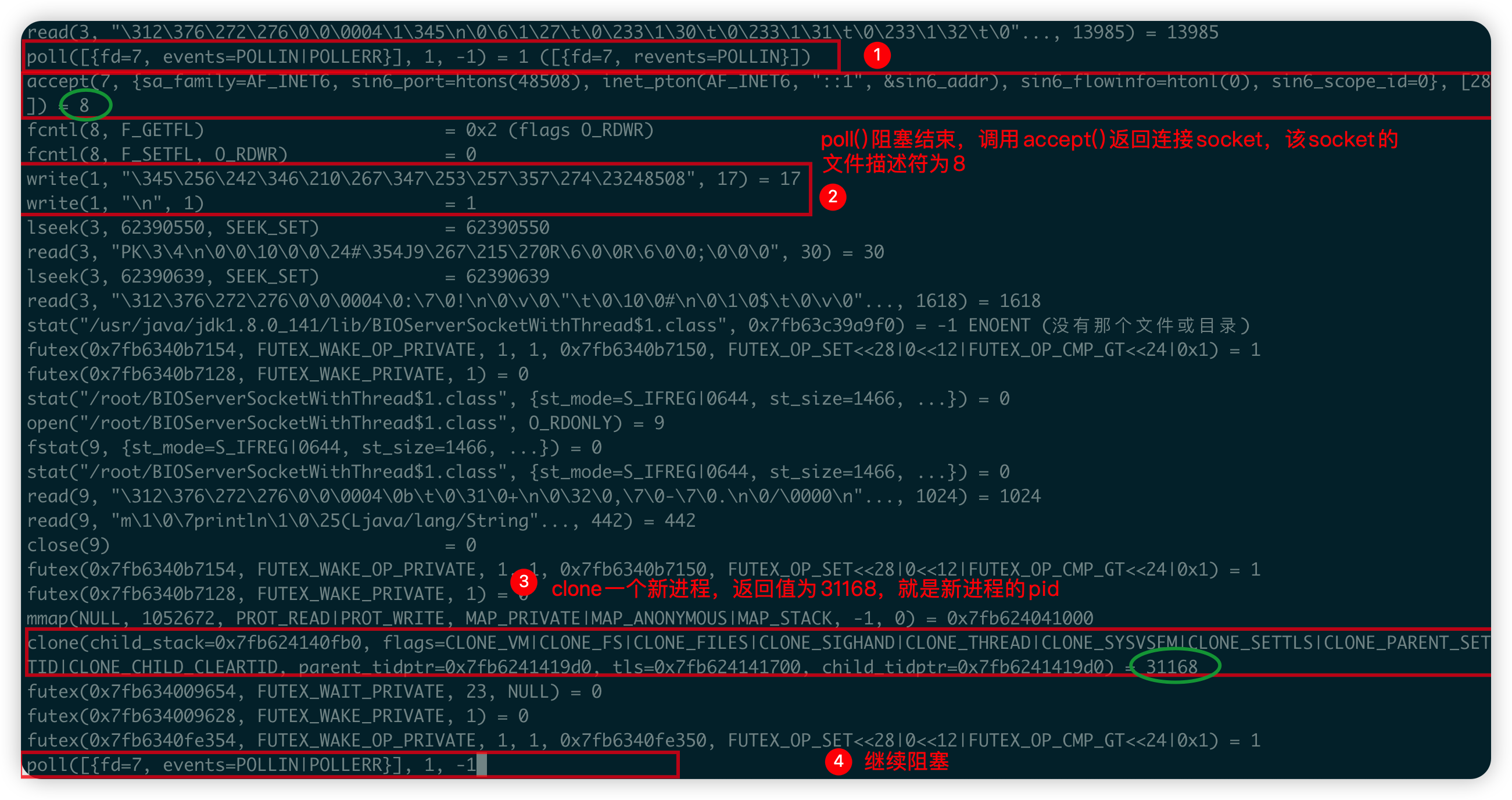
poll()函數結束阻塞,程式接著呼叫accept()函數返回一個連線socket,該socket的描述符為8;- 就是
System.out.println("使用者端:" + socket.getPort());的底層呼叫; - 底層使用
clone()創造了一個新程序去處理連線socket,該程序的pid為31168,因此JDK8的執行緒在底層其實就是輕量級程序; - 回到
poll()函數繼續阻塞等待新使用者端連線。
由於建立了一個新的程序,因此在目錄下對多出一個out.31168的檔案,我們看一下該檔案的內容:
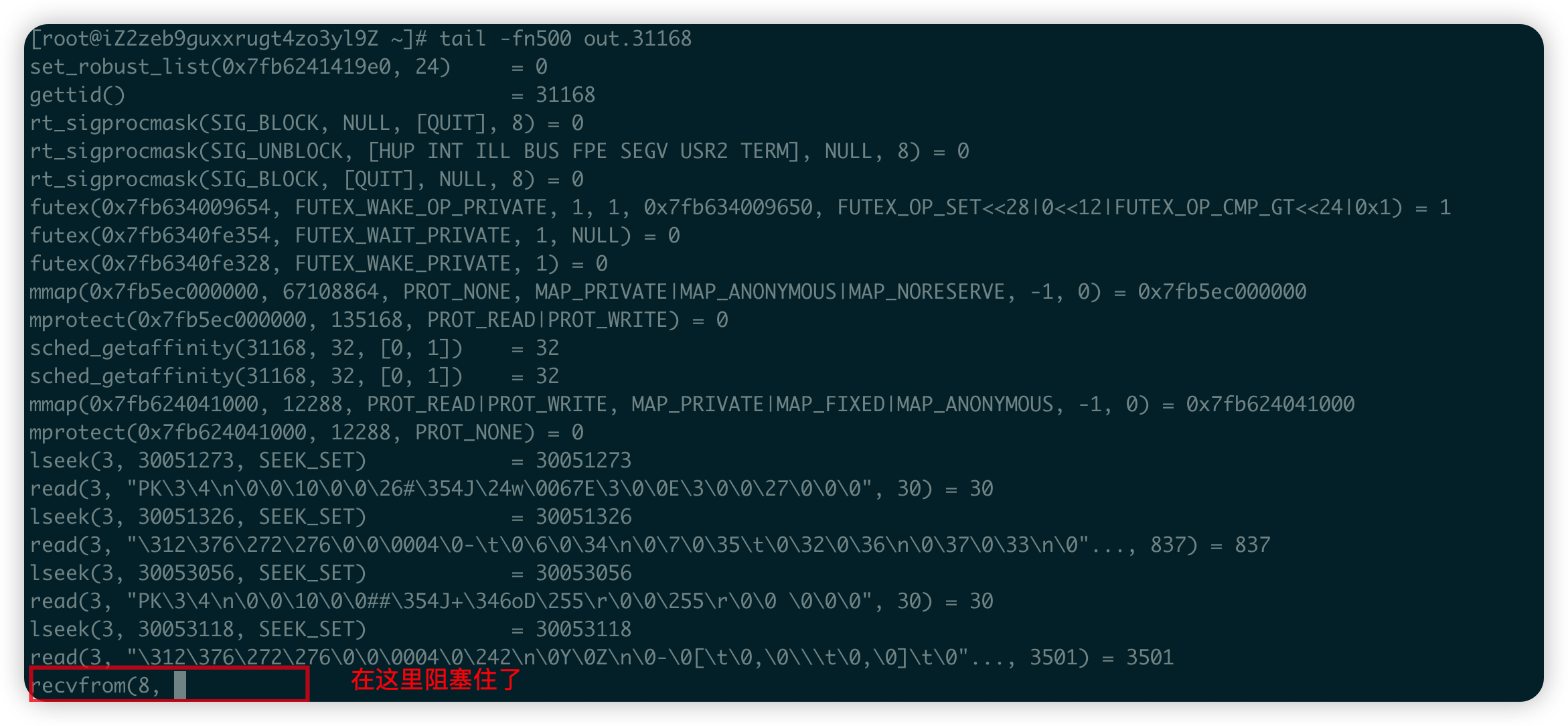
發現子程序阻塞在了recvfrom()這個系統呼叫上,對應的Java原始碼就是bufferedReader.readLine();,直到使用者端主動給伺服器端傳送訊息,阻塞才會結束。
3.7. BIO總結
到此為止,我們就通過底層的系統呼叫證明了BIO在accept()以及readLine()上的阻塞。最後用一張圖來結束BIO之旅。
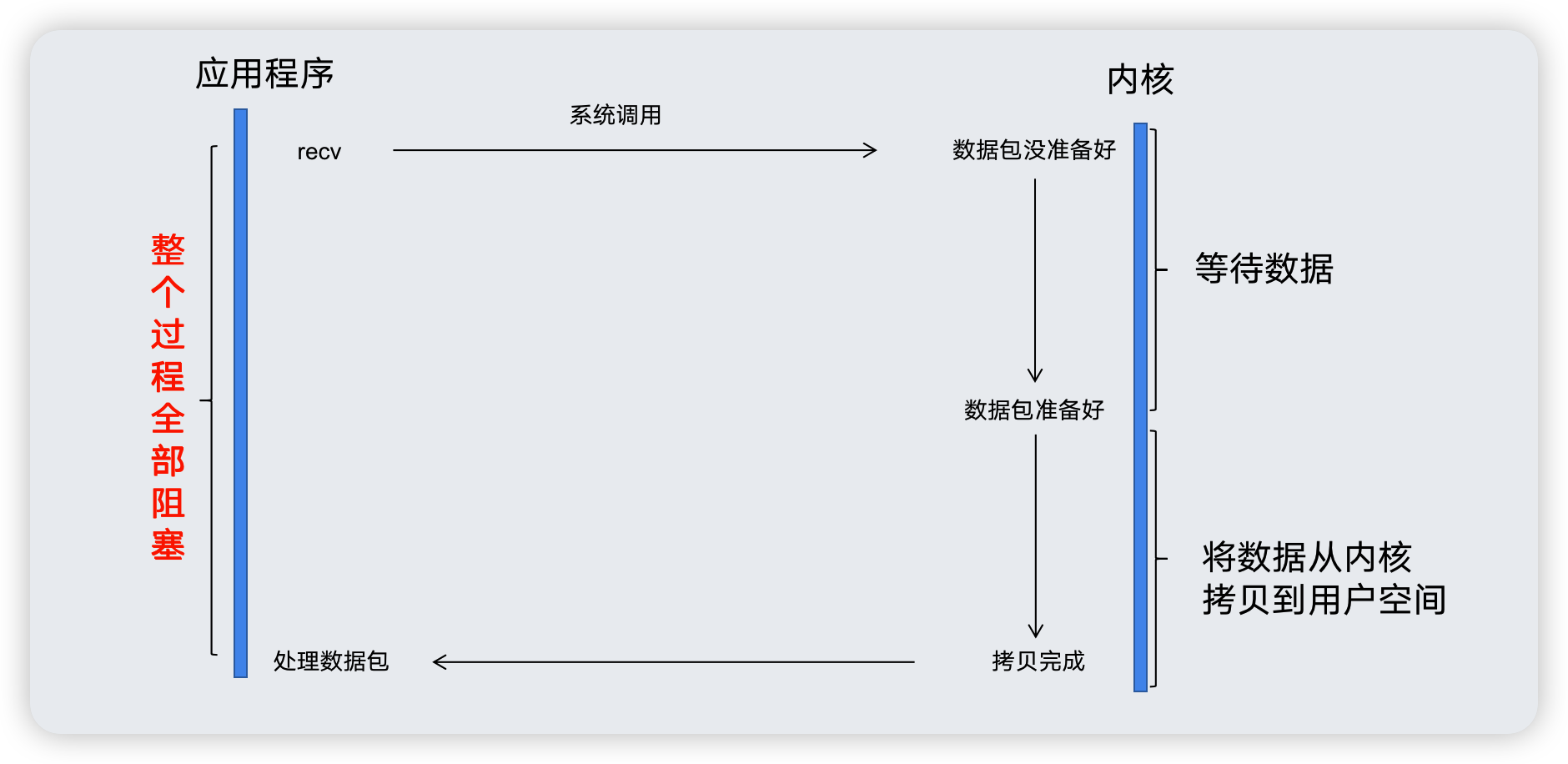
BIO之所以是BIO,是因為系統底層呼叫是阻塞的,上圖中的程序呼叫recv,其系統呼叫直到封包準備好並且被複制到應用程式的緩衝區或者發生錯誤為止才會返回,在此整個期間,程序是被阻塞的,啥也幹不了。
4. 非阻塞I/O(NonBlocking I/O)
上文花了太多的筆墨描述BIO,接下來的非阻塞IO我們只抓主要矛盾,其餘參考BIO即可。
如果你看過其他介紹非阻塞IO的文章,下面這個圖片你多少會有點眼熟。
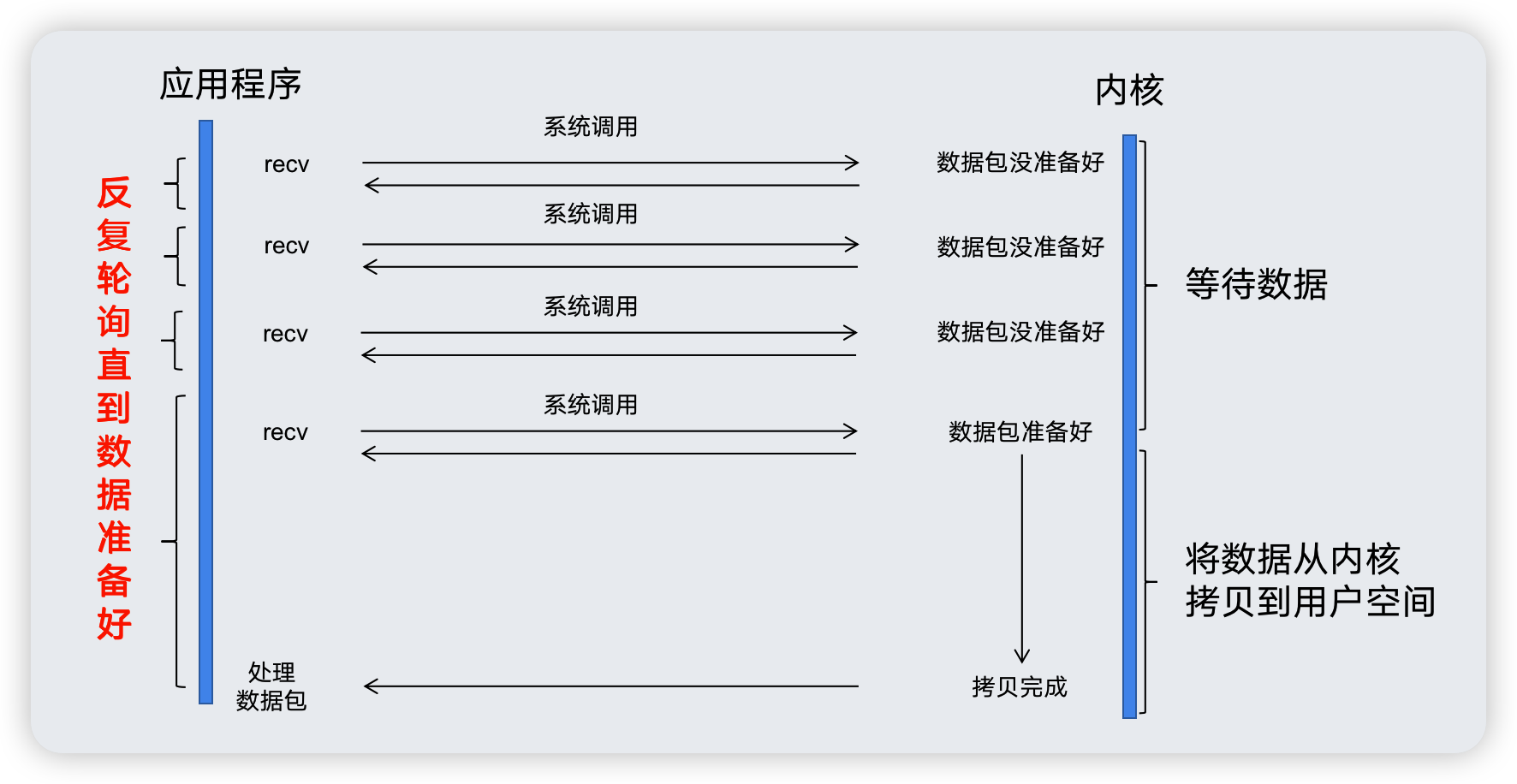
非阻塞IO指的是程序發起系統呼叫之後,核心不會將程序投入睡眠,而是會立即返回一個結果,這個結果可能恰好是我們需要的資料,又或者是某些錯誤。
你可能會想,這種非阻塞帶來的輪詢有什麼用呢?大多數都是空輪詢,白白浪費CPU而已,還不如讓程序休眠來的合適。
4.1. Java的非阻塞實現
這個問題暫且擱置一下,我們先看Java在語法層面是如何提供非阻塞功能的,細節慢慢聊。
public class NoBlockingServer {
public static List<SocketChannel> channelList = new ArrayList<>();
public static void main(String[] args) throws InterruptedException {
try {
// 相當於serverSocket
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 將監聽socket設定為非阻塞
serverSocketChannel.configureBlocking(false);
serverSocketChannel.socket().bind(new InetSocketAddress(8099));
while (true) {
// 這裡將不再阻塞
SocketChannel socketChannel = serverSocketChannel.accept();
if (socketChannel != null) {
// 將連線socket設定為非阻塞
socketChannel.configureBlocking(false);
channelList.add(socketChannel);
} else {
System.out.println("沒有使用者端連線!!!");
}
for (SocketChannel client : channelList) {
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// read也不阻塞
int num = client.read(byteBuffer);
if (num > 0) {
System.out.println("收到使用者端【" + client.socket().getPort() + "】資料:" + new String(byteBuffer.array()));
} else {
System.out.println("等待使用者端【" + client.socket().getPort() + "】寫資料");
}
}
// 加個睡眠是為了避免strace產生大量紀錄檔,否則不好追蹤
Thread.sleep(1000);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
Java提供了新的API,ServerSocketChannel以及SocketChannel,相當於BIO中的ServerSocket和Socket。此外,通過下面兩行的設定,將監聽socket和連線socket設定為非阻塞。
// 將監聽socket設定為非阻塞
serverSocketChannel.configureBlocking(false);
// 將連線socket設定為非阻塞
socketChannel.configureBlocking(false);
我們上文強調過,Java自身並沒有將socket設定為非阻塞的本事,一定是在某個時間點上,作業系統核心提供了這個功能,才使得Java設計出了新的API來提供非阻塞功能。
之所以需要上面兩行程式碼的顯式設定,也恰好說明了核心是預設將socket設定為阻塞狀態的,需要非阻塞,就得額外呼叫其他系統呼叫。我們通過man命令檢視一下socket()這個方法(截圖的中間省略了一部分內容):
man 2 socket
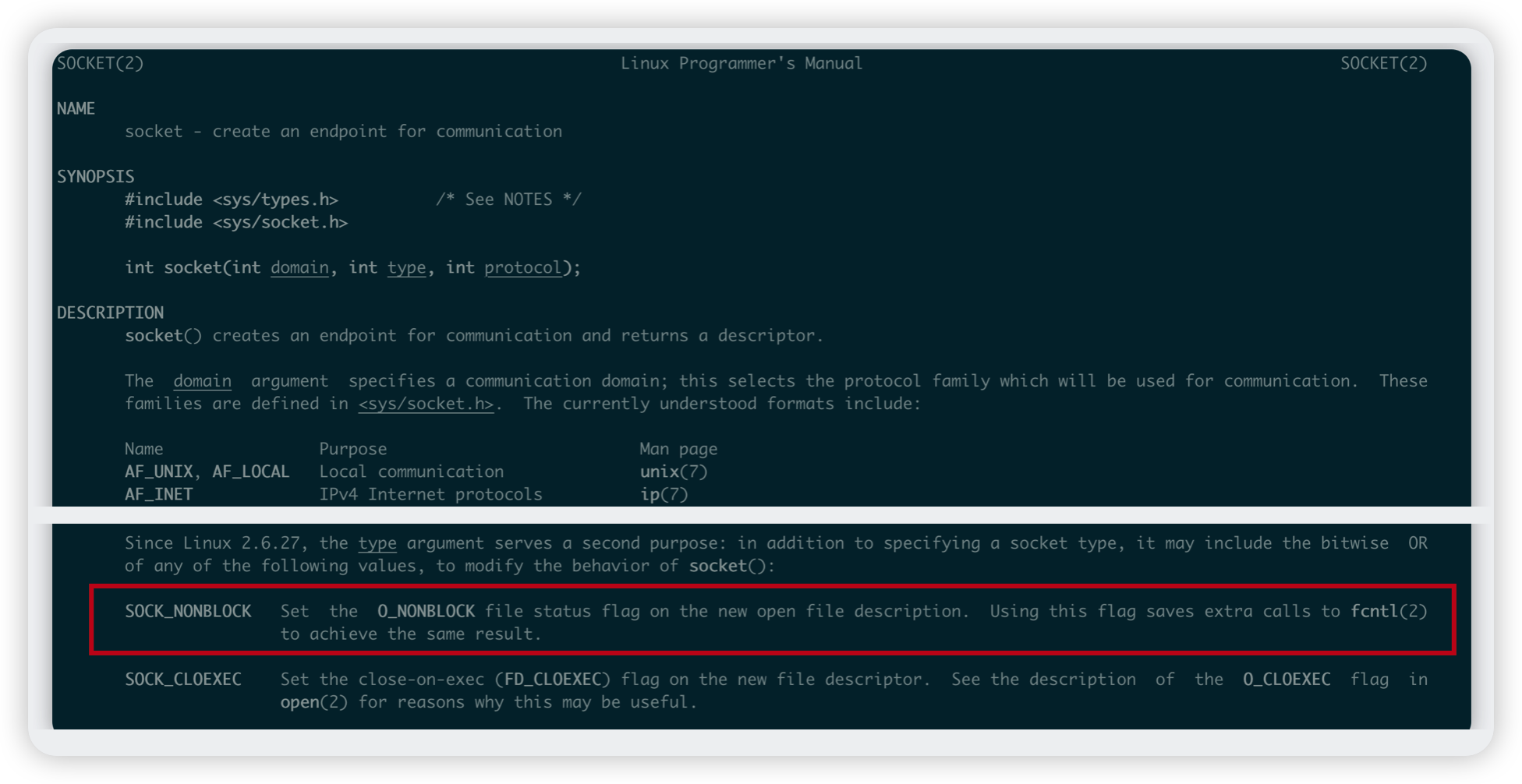
我們可以看到socket()函數提供了SOCK_NONBLOCK這個型別,可以通過fcntl()這個方法將socket從預設的阻塞修改為非阻塞,不管是對監聽socket還是連線socket都是一樣的。
4.2. Java的非阻塞解釋
現在解釋上面提到的問題:這種非阻塞帶來的輪詢有什麼用?觀察一下上面的程式碼就可以發現,我們全程只使用了1個main執行緒就解決了所有使用者端的連線以及所有使用者端的讀寫操作。
serverSocketChannel.accept();會立即返回撥用結果。
返回的結果如果是一個SocketChannel物件(系統呼叫底層就是個socket描述符),說明有使用者端連線,這個SocketChannel就表示了這個連線;然後利用socketChannel.configureBlocking(false);將這個連線socket設定為非阻塞。這個設定非常重要,設定之後對連線socket所有的讀寫操作都變成了非阻塞,因此接下來的client.read(byteBuffer);並不會阻塞while迴圈,導致新的使用者端無法連線。再之後將該連線socket加入到channelList佇列中。
如果返回的結果為空(底層系統呼叫返回了錯誤),就說明現在還沒有新的使用者端要連線監聽socket,因此程式繼續向下執行,遍歷channelList佇列中的所有連線socket,對連線socket進行讀操作。而讀操作也是非阻塞的,會理解返回一個整數,表示讀到的位元組數,如果>0,則繼續進行下一步的邏輯處理;否則繼續遍歷下一個連線socket。
下面給出一張accept()返回一個連線socket情況下的動圖,希望對大家理解整個流程有幫助。

4.3. 掀開非阻塞IO的底褲
我將上面的程式在CentOS下再次用strace程式追蹤一下,具體步驟不再贅述,下面是out紀錄檔檔案的內容(我忽略了絕大多數沒用的)。
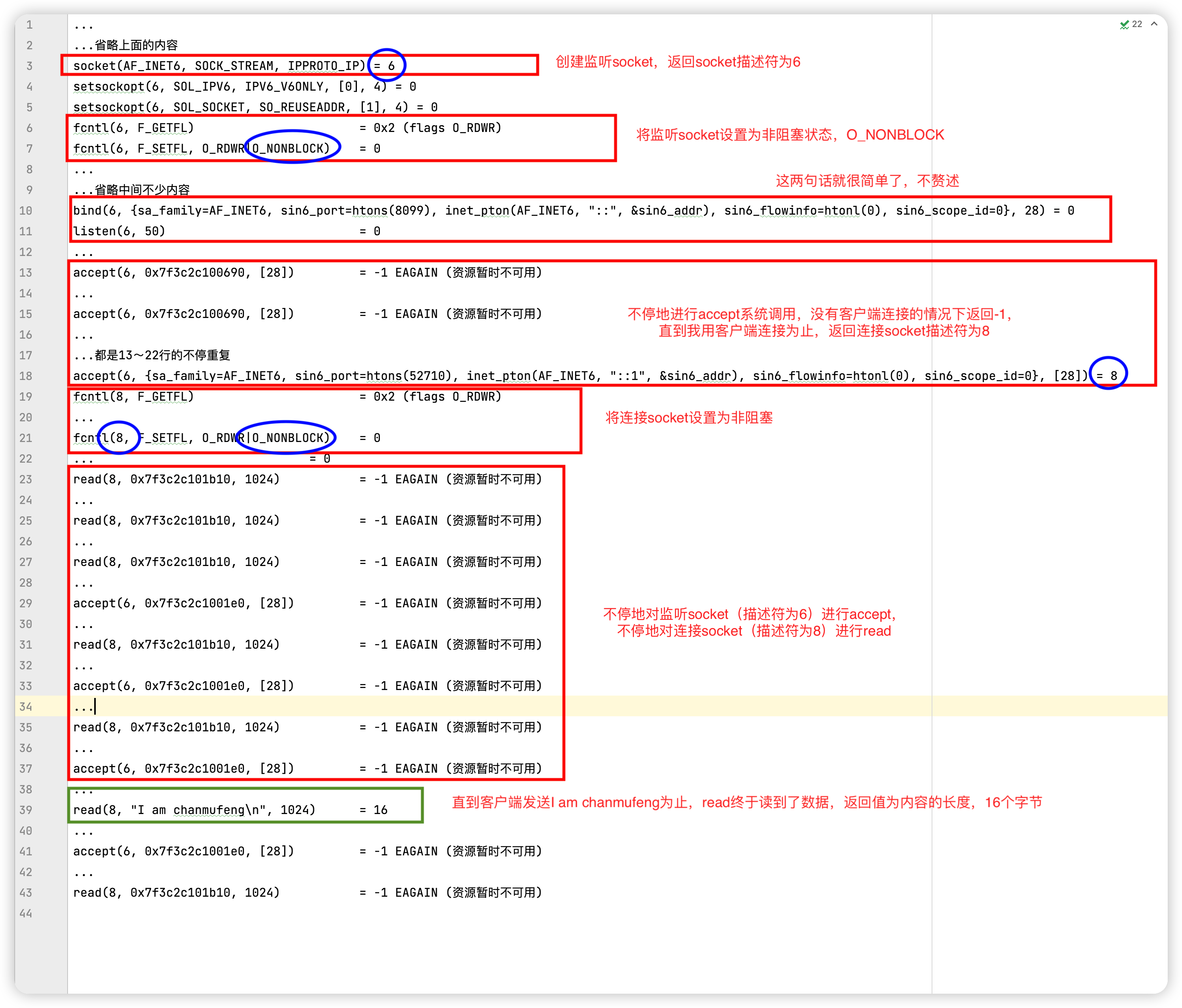
4.4. 非阻塞IO總結
再放一遍這個圖,有一個細節需要大家注意,系統呼叫向核心要資料時,核心的動作分成兩步:
-
等待資料(從網路卡緩衝區拷貝到核心緩衝區)
-
拷貝資料(資料從核心緩衝區拷貝到使用者空間)
只有在第1步時,系統呼叫是非阻塞的,第2步程序依然需要等待這個拷貝過程,然後才能返回,這一步是阻塞的。
非阻塞IO模型僅用一個執行緒就能處理所有操作,對比BIO的一個使用者端需要一個執行緒而言進步還是巨大的。但是他的致命問題在於會不停地進行系統呼叫,不停的進行accept(),不停地對連線socket進行read()操作,即使大部分時間都是白忙活。要知道,系統呼叫涉及到使用者空間和核心空間的多次轉換,會嚴重影響整體效能。
所以,一個自然而言的想法就是,能不能別讓程序瞎輪詢。
比如有人告訴程序監聽socket是不是被連線了,有的話程序再執行accept();比如有人告訴程序哪些連線socket有資料從使用者端傳送過來了,然後程序只對有資料的連線socket進行read()。
這個方案就是I/O多路複用。
剩下的內容另起一篇吧,現在處於發燒狀態,八成是陽了,小夥伴們注意身體,下期見~