正確理解和使用JAVA中的字串常數池
前言
研究表明,Java堆中物件佔據最大比重的就是字串物件,所以弄清楚字串知識很重要,本文主要重點聊聊字串常數池。Java中的字串常數池是Java堆中的一塊特殊儲存區域,用於儲存字串。它的實現是為了提高字串操作的效能並節省記憶體。它也被稱為String Intern Pool或String Constant Pool。那讓我來看看究竟是怎麼一回事吧。
歡迎關注微信公眾號「JAVA旭陽」交流和學習
理解字串常數池
當您從在類中寫一個字串字面量時,JVM將首先檢查該字串是否已存在於字串常數池中,如果存在,JVM 將返回對現有字串物件的參照,而不是建立新物件。我們通過一個例子更好的來理解。
比如下面的程式碼:
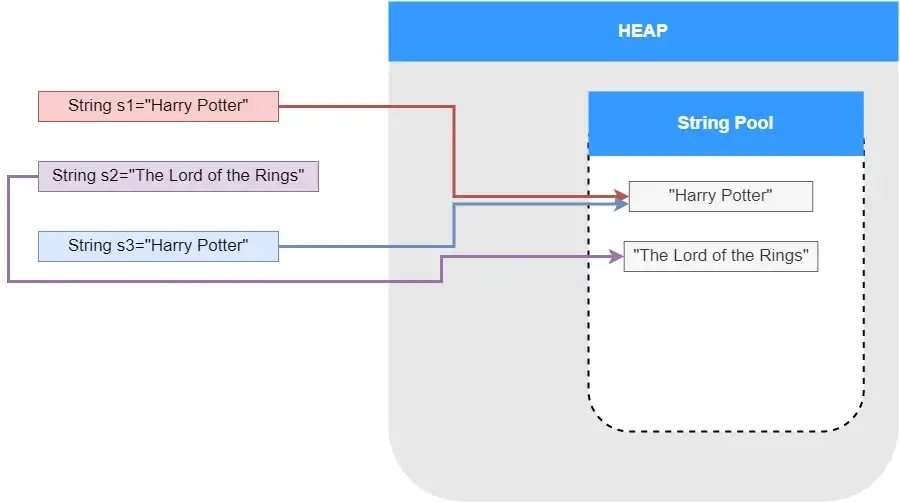
String s1 = "Harry Potter";
String s2 = "The Lord of the Rings";
String s3 = "Harry Potter";
在這段程式碼中,JVM 將建立一個值為「Harry Potter」的字串物件,並將其儲存在字串常數池中。s1和s3都將是對該單個字串物件的參照。
如果s2的字串內容「The Lord of the Rings」不存在於池中,則在字串池中生成一個新的字串物件。
兩種建立字串方式
在 Java 程式語言中有兩種建立 String 的方法。第一種方式是使用String Literal字串字面量的方式,另一種方式是使用new關鍵字。他們建立的字串物件是都在常數池中嗎?
- 字串字面量的方式建立
String s1 = "Harry Potter";
String s2 = "The Lord of the Rings";
String s3 = "Harry Potter";
new關鍵字建立
String s4 = new String("Harry Potter");
String s5 = new String("The Lord of the Rings");
我們來比較下他們參照的是否是同一個物件:
s1==s3 //真
s1==s4 //假
s2==s5 //假
使用 == 運運算元比較兩個物件時,它會比較記憶體中的地址。
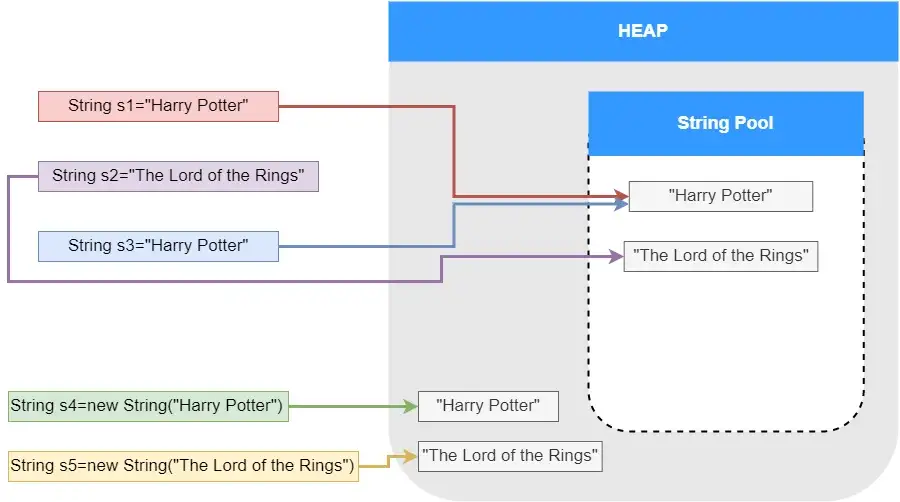
正如您在上面的圖片和範例中看到的,每當我們使用new運運算元建立字串時,它都會在 Java 堆中建立一個新的字串物件,並且不會檢查該物件是否在字串常數池中。
那麼我現在有個問題,如果是字串拼接的情況,又是怎麼樣的呢?
字串拼接方式
前面講清楚了通過直接用字面量的方式,也就是引號的方式和用new關鍵字建立字串,他們建立出的字串物件在堆中儲存在不同的地方,那麼我們現在來看看用+這個運運算元拼接會怎麼樣。
例子1
public static void test1() {
// 都是常數,前端編譯期會進行程式碼優化
// 通過idea直接看對應的反編譯的class檔案,會顯示 String s1 = "abc"; 說明做了程式碼優化
String s1 = "a" + "b" + "c";
String s2 = "abc";
// true,有上述可知,s1和s2實際上指向字串常數池中的同一個值
System.out.println(s1 == s2);
}
- 常數與常數的拼接結果在常數池,原理是編譯期優化。
例子2
public static void test5() {
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4); // true 編譯期優化
System.out.println(s3 == s5); // false s1是變數,不能編譯期優化
System.out.println(s3 == s6); // false s2是變數,不能編譯期優化
System.out.println(s3 == s7); // false s1、s2都是變數
System.out.println(s5 == s6); // false s5、s6 不同的物件範例
System.out.println(s5 == s7); // false s5、s7 不同的物件範例
System.out.println(s6 == s7); // false s6、s7 不同的物件範例
}
- 只要其中有一個是變數,結果就在堆中, 變數拼接的底層原理其實是
StringBuilder。
例子3:
public void test6(){
String s0 = "beijing";
String s1 = "bei";
String s2 = "jing";
String s3 = s1 + s2;
System.out.println(s0 == s3); // false s3指向物件範例,s0指向字串常數池中的"beijing"
String s7 = "shanxi";
final String s4 = "shan";
final String s5 = "xi";
String s6 = s4 + s5;
System.out.println(s6 == s7); // true s4和s5是final修飾的,編譯期就能確定s6的值了
}
- 不使用final修飾,即為變數。如s3行的s1和s2,會通過new StringBuilder進行拼接
- 使用final修飾,即為常數。會在編譯器進行程式碼優化。
妙用String.intern() 方法
前面提到new關鍵字建立出來的字串物件以及某些和變數進行拼接不會在字串常數池中,而是直接在堆中新建了一個物件。這樣不大好,做不到複用,節約不了空間。那有什麼好辦法呢?intern()就派上用場了,這個非常有用。
intern()方法的作用可以理解為主動將常數池中還沒有的字串物件放入池中,並返回此物件地址。
String s6 = new String("The Lord of the Rings").intern();
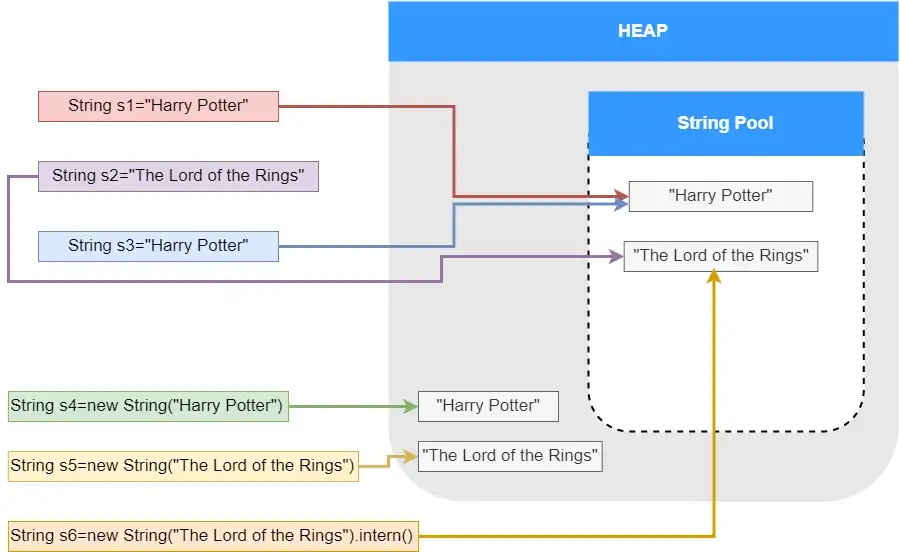
s2==s6 //真
s2==s5 //假
字串常數池有多大?
關於字串常數池究竟有多大,我也說不上來,但是講清楚它底層的資料結構,也許你就明白了。
字串常數池是一個固定大小的HashTable,雜湊表,預設值大小長度是1009。如果放進String Pool的String非常多,就會造成Hash衝突嚴重,從而導致連結串列會很長,而連結串列長了後直接會造成的影響就是當呼叫String.intern時效能會大幅下降。
使用-XX:StringTablesize可設定StringTable的長度
- 在jdk6中
StringTable是固定的,就是1009的長度,所以如果常數池中的字串過多就會導致效率下降很快。StringTable Size設定沒有要求 - 在jdk7中,StringTable的長度預設值是
60013,StringTable Size設定沒有要求
● 在jdk8中,設定StringTable長度的話,1009是可以設定的最小值
字串常數池的優缺點
字串池的優點
- 提高效能。由於 JVM 可以返回對現有字串物件的參照而不是建立新物件,因此使用字串池時字串操作更快。
- 共用字串,節省記憶體。字串池允許您在不同的變數和物件之間共用字串,通過避免建立不必要的字串物件來幫助節省記憶體。
字串池的缺點
- 它有可能導致效能下降。從池中檢索字串需要搜尋池中的所有字串,這可能比簡單地建立一個新的字串物件要慢。如果程式建立和丟棄大量字串,則尤其如此,因為每次使用字串時都需要搜尋字串池。
總結
其實在 Java 7 之前,JVM將 Java String Pool 放置在PermGen空間中,它具有固定大小——它不能在執行時擴充套件,也不符合垃圾回收的條件。在PermGen(而不是堆)中駐留字串的風險是,如果我們駐留太多字串,我們可能會從 JVM 得到一個OutOfMemory錯誤。從 Java 7 開始,Java String Pool存放在Heap空間,由 JVM進行垃圾回收。這種方法的優點是降低了OutOfMemory錯誤的風險,因為未參照的字串將從池中刪除,從而釋放記憶體。
現在通過本文的學習,你該知道如何更好的建立字串物件了吧。
歡迎關注微信公眾號「JAVA旭陽」交流和學習
更多學習資料請移步:程式設計師成神之路
本文來自部落格園,作者:JAVA旭陽,轉載請註明原文連結:https://www.cnblogs.com/alvinscript/p/17007014.html