圖計算引擎分析——Gemini
前言
Gemini 是目前 state-of-art 的分散式記憶體圖計算引擎,由清華陳文光團隊的朱曉偉博士於 2016 年發表的分散式靜態資料分析引擎。Gemini 使用以計算為中心的共用記憶體圖分散式 HPC 引擎。通過自適應選擇雙模式更新(pull/push),實現通訊與計算負載均衡 [1]。圖計算研究的圖是資料結構中的圖,非圖片。
實際應用中遇到的圖,如社群網路中的好友關係、蛋白質結構、電商等 [2] 等,其特點是資料量大(邊多,點多),邊服從指數分佈(power-law)[7],通常滿足所謂的二八定律:20% 的頂點關聯了 80% 的邊,其中 1% 的點甚至關聯了 50% 的邊。
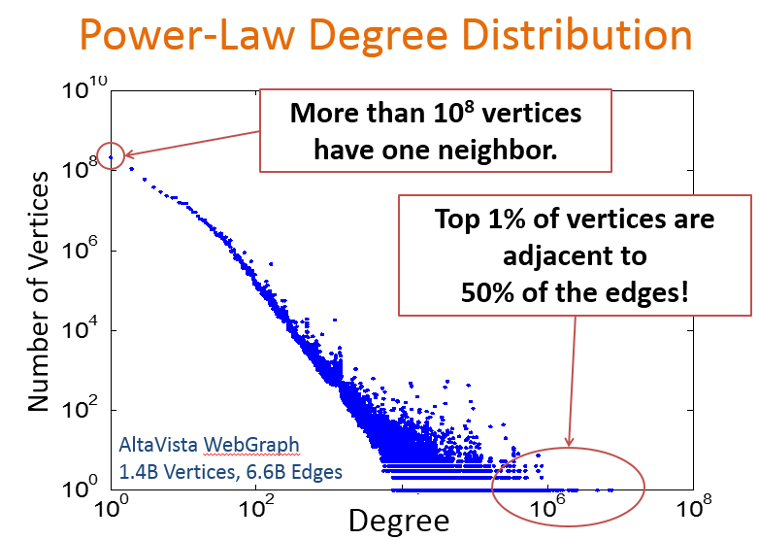
如何儲存大圖
隨著社交媒體、零售電商等業務的發展。圖資料的規模也在急劇增長。如標準測試資料集 clueweb-12,生成後的文字資料大小 780+GB。單機儲存已經不能滿足需求。必須進行圖切分。常見的圖切分方式有:切邊、切點。
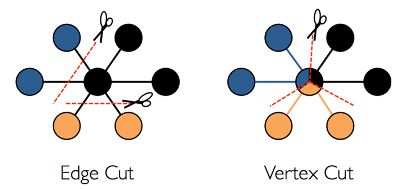
切點:又稱 「以邊為中心的切圖」,保證邊不被切開,一條邊在一臺機器上被儲存一次,被切的點建立多個副本,副本點所在的機器不清楚關於此點的相關邊。如上圖所示,中間點被分別儲存三個版本,此點會分別出現在三臺機器上,在做更新時需要更新三次。
切邊:又稱以 「頂點為中心的切圖」,相比於切點,保證點不被切開。邊會被儲存兩次,作為副本點所在機器能清楚感知到此點的相關邊。如上圖所示資訊只進行一次更新。
Gemini 採用切邊的方式進行儲存。
定義抽象圖為 G (V,E),Gemini 定義了主副本(master)與映象副本(mirror),計算時是以 master 為中心進行計算。如下圖所示,叢集每臺機器上僅儲存 mirror 到 master 的子圖拓撲結構,而 mirror 點並未被實際儲存(比如權重值),每臺機器負責一部分 master 儲存(
 )。
)。
如下圖所示,Gemini 將圖按照 partition 演演算法切分到 2 個不同的機器。其中 mirror 作為邏輯結構,沒有為其分配實際儲存空間;但每條邊被儲存了兩次。
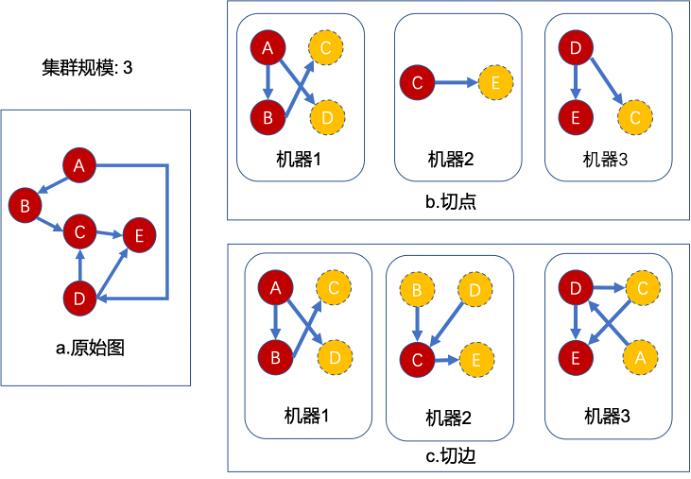
優點:單機可以完整獲取 master 的拓撲結構,不需要全域性維護節點狀態。
圖儲存
圖的常見儲存方式:鄰接矩陣、鄰接表、十字連結串列,此處不作詳細解釋,有興趣可參照 [3]。
| 表示方法 | 鄰接矩陣 | 鄰接表 | 十字連結串列 |
|---|---|---|---|
| 優點 | 儲存結構簡單,存取速度快,順序遍歷邊 | 節省空間,存取速度較快 | 在鄰接表基礎上進一步,節省儲存空間。 |
| 缺點 | 佔用空間很大(n*n 儲存空間) | 儲存使用指標,隨遍歷邊結構,為提高效率,需要同時儲存出邊入邊資料。 | 表示很複雜,大量使用了指標,隨機遍歷邊,存取慢。 |
分析上表優缺點,可見:上述三種表示方式都不適合冪律分佈的 graph 儲存。
壓縮矩陣演演算法
圖計算問題其實是一個 HPC(High Performance Computing)問題,HPC 問題一般會從計算機系統結構的角度來進行優化,特別在避免隨機記憶體存取和快取的有效利用上。有沒有一種既保證存取效率,又能滿足記憶體的區域性性,還能節省空間的演演算法呢?壓縮矩陣儲存。
常見的圖壓縮矩陣演演算法有三種 coordinate list(COO)、Compressed sparse row(CSR)、Compressed sparse column (CSC) 演演算法進行壓縮 [8][9]。
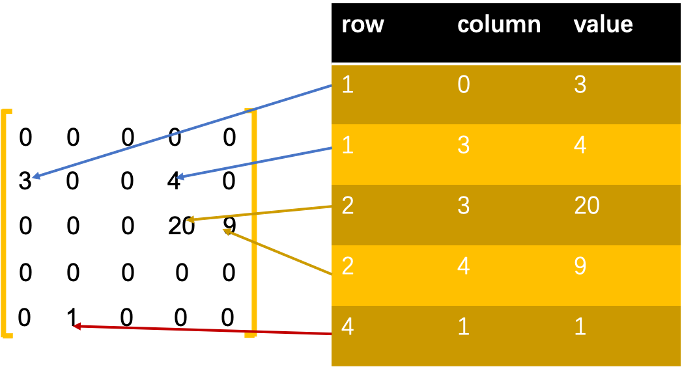
COO 壓縮演演算法
COO 使用了座標矩陣實現圖儲存(row,collumn,value),空間複雜度 3*|E|;對於鄰接矩陣來說,如果圖中的邊比較稀疏,那麼 COO 的價效比是比較高。
CSR/CSC 壓縮演演算法
CSC/CSR 都儲存了 column/row 列,用於記錄當前行 / 列與上一個行 / 列的邊數。Index 列儲存邊的所在 row/column 的 index。
CSC/CSR 是在 COO 基礎上進行了行 / 列壓縮,空間複雜度 2|E|+n,實際業務場景中的圖,邊往往遠多於點,所以 CSR/CSC 相對 COO 具有更好壓縮比。
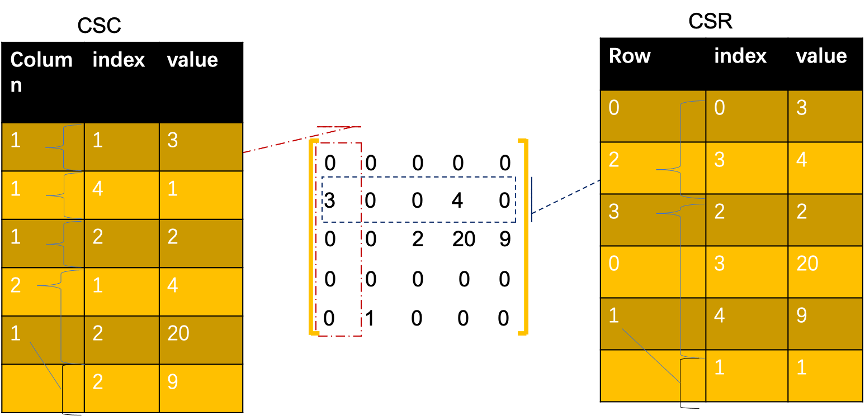
優點:儲存緊密,記憶體區域性性強;
缺點:遍歷邊時,需要依賴上一個點的最後一條邊的 index,所以只能單執行緒遍歷。
壓縮矩陣演演算法無法實時更新拓撲結構,所以壓縮矩陣演演算法只適用靜態或者對資料變化不敏感的場景。
| CSC 虛擬碼 | CSR 虛擬碼 |
|---|---|
| loc← 0 for vi←0 to colmns for idx ←0 to colmn [i] do // 輸出到指定行的列 edge [vi][index [idx]] ←value [loc] loc← loc+1 end end | loc← 0 for vi←0 to rows for idx ←0 to row [i] do // 輸出到指定列的行 edge [ index [idx]] [vi] ←value [loc] loc← loc+1 end end |
Gemini 的圖壓縮
Gemini 對 CSC/CSR 儲存並進行了改進,解釋了壓縮演演算法的原理。Gemini 在論文中指出,index 的儲存空間複雜度是 O (V),會成為系統的瓶頸。
引出了兩種演演算法:Bitmap Assisted Compressed Sparse Row(bitmap 輔助壓縮 CSR)和 Doubly Compressed Sparse Column(雙壓縮 CSC),空間複雜度降到 O (|V'|),|V'| 為含有入邊點的數量。
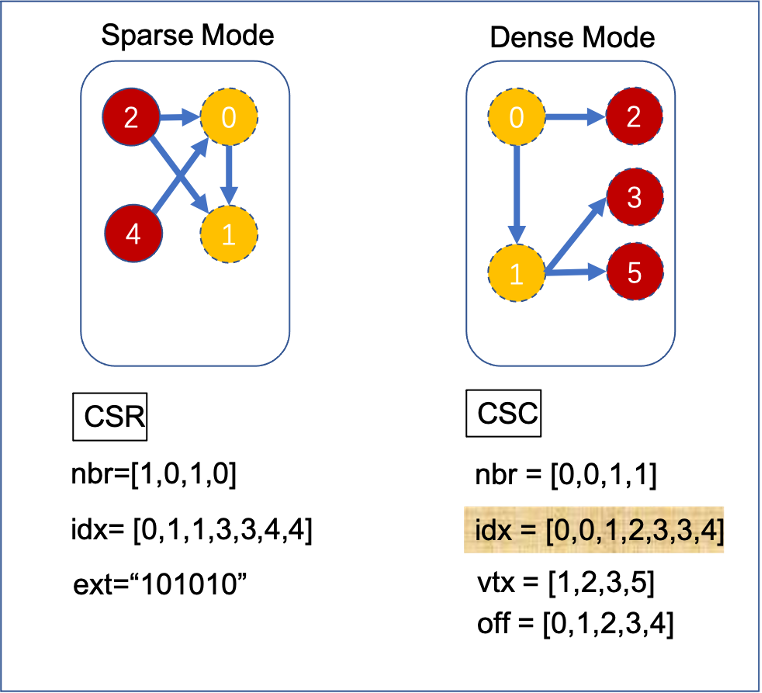
Gemini 改進後的 CSR 演演算法使用 bitmap 替換 CSR 原有的 Rows 結構:
• ext 為 bitmap,程式碼此 bit 對應的 vid 是否存在出邊,如上 id 為 0/2/4 的點存在出邊。
• nbr 為出邊 id;
• ndx 表示儲存了邊的 nbr 的 index 範圍;
如上圖 CSR 圖,點 0 存在出邊(ext [0] 為 1),通過 idx 的差值計算出 0 點存在一條出邊(idx [1]-idx [0]=1),相對於儲存 0 點第一條出邊的 nbr 的下標為 0(idx [0]);同理可推得點 1 無出邊。
Gemini 雙壓縮 CSC 演演算法將 idx 拆分成 vtx 及 off 兩個結構:
• vtx 代表存在入邊的點集合;
• nbr 為入邊陣列;
• Off 表示儲存入邊 nbr 的 index 偏移範圍;
如上圖 CSC 演演算法:vtx 陣列表示點 1,2,3,5 存在入邊,使用 5 個元素的 off 儲存每個點的偏移量。如點 2 存在由 0 指向自己的入邊 (0ff [2]-off [1]=1), 所以 nbr [1] 儲存的就是點 2 的入邊 id(0)。
Gemini 的雙模式更新
雙模式更新是 Gemini 的核心:Gemini 採用 BSP 計算模型,在通訊及計算階段獨創性地引入 QT 中的 signal、slot 的概念;計算模式上借鑑了 ligra 的設計 [5]。
Gemini 沿用 Ligra 對雙模式閾值定義:當活躍邊數量小於(|E|/20,|E | 為總邊數)時,下一輪計算將使用 push 模式(sparse 圖);否則採用 pull 模式(dense 圖)。這個值為經驗值,可根據場景進行調整。
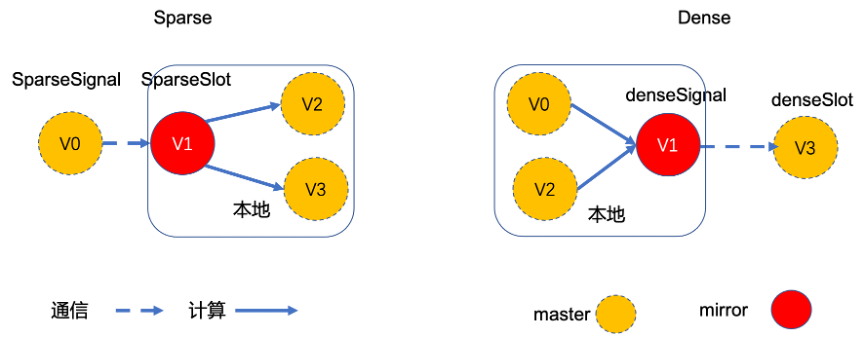
在開始計算前,都需要統計活躍邊的數量,確定圖模式。
在迭代過程中,每一個叢集節點只儲存部分計算結果。
在分散式系統中,訊息傳播直接涉及到通訊量,間接意味著閾值強相關網路頻寬和引擎的計算效率。雙模式直接平衡了計算負載與通訊負載。
圓角矩形標識操作是在本地完成的,Gemini 將大量的需通訊工作放在本地完成。
Gemini 節點構圖
Gemini 在實現上,增加 numa 特性。如何分配點邊,如何感知 master 在哪臺機器,哪個 socket 上,都直接影響到引擎計算效率。
location aware 和 numa aware 兩個 feature 去解決了上述問題;由於 Graph 冪律分佈的特點,執行時很難獲得很好的負載均衡效果,所以在 partition 時,也引入了平衡因子 α,達到通訊與計算負載均衡。
在 partition 階段通過增加 index 結構:partition_offset, local_partition_offset。(partition_offset 記錄跨機器的 vid offset,local_partition_offset 記錄跨 numa 的 vid offset)。
Location-aware
以邊平均演演算法為例,叢集規模 partitions = 4(臺),圖資訊見下表。
點邊分佈情況
| 點 s | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| Out Edge | 0 | 3 | 5 | 30 | 2 | 4 | 6 | 2 | 20 |
存在出邊 sum = 72
| 切圖輪次 | 1 | 2 | 3 |
|---|---|---|---|
| 剩餘邊 | 72 | 34 | 22 |
| 平均分配 | 18 | 12 | |
| Master 分配結果 | 0: 0~3 | ||
| 1: | 4~6 | ||
| 2: | 7~8 | ||
| 3: |
從上表分析可見:
• 編號為 0 的機器分配 4 點 38 條邊;
• 編號為 1 的機器分配 3 點 12 條邊;
• 編號為 2 的機器分配 2 點 22 條邊;
• 編號為 3 的機器分配 0 點 0 條邊。
此方法分配會造成負載的偏斜,影響到引擎的計算效率。
Gemini 在切圖時,每個 partition 分配點個數遵循公式
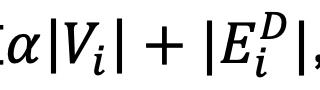
, 其中平衡因子定義為 α=8*(partitions-1)。
仍然以上圖為例,Gemini 通過ɑ因子平衡了邊的分佈。
| 切圖輪次 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 剩餘權重邊 | 288 | 208 | 128 | 44 |
| 平均分配 | 72 | 70 | 64 | 44 |
| Master 分配結果 | 0: 0~2 | |||
| 1: | 3~4 | |||
| 2: | 5~7 | |||
| 3: | 8 |
對比兩次切分的結果,新增 α 增加了出邊較少的點的權重。
通過實際場景應用發現:按照論文中 α 平衡因子設定,很可能出現記憶體的傾斜(記憶體分配上相差 20% 左右,造成 oom kill)。在實際生產場景中,我們根據時間場景和叢集設定,重新調整了 α 引數取值設定,記憶體分配基本浮動在 5% 左右。
Numa-aware
NUMA 介紹
根據處理器的存取記憶體的方式不同,可將計算機系統分類為 UMA(Uniform-Memory-Access,統一記憶體存取)和 NUMA(Non-Uniform Memory Access, 非一致性記憶體存取)。
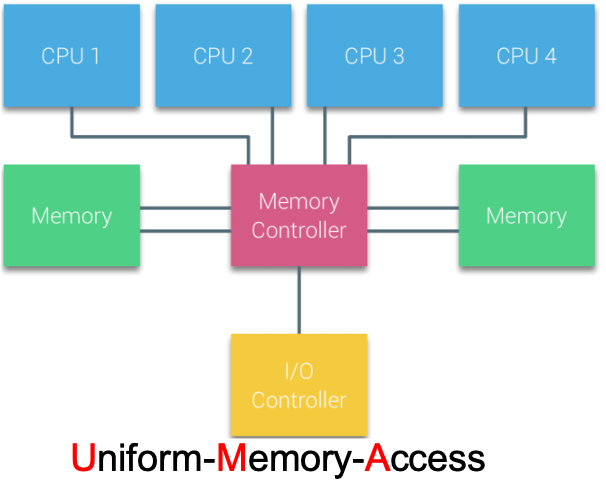
在 UMA 架構下,所有 cpu 都通過相同的匯流排以共用的方式存取記憶體。在物理結構上,UMA 就不利於 cpu 的擴充套件(匯流排長度、資料匯流排頻寬都限制 cpu 的上限)。
Numa (Non-Uniform Memory Access, 非一致性記憶體存取)是目前核心設計主流方向。每個 cpu 有獨立的記憶體空間(獨享),可通過 QPI(quick path Interconnect)實現互相存取。由於硬體的特性,所以跨 cpu 存取要慢 [11]。
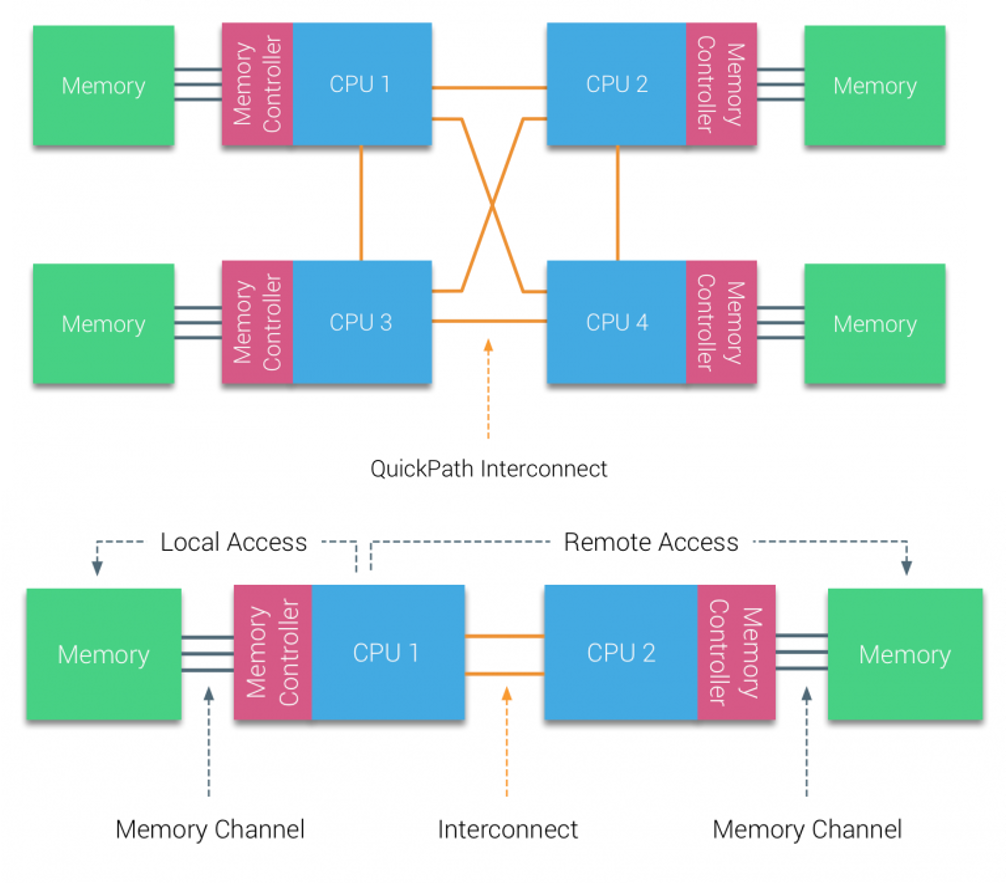
相對於 UMA 來說,NUMA 解決 cpu 擴充套件,提高資料匯流排寬度匯流排長度帶來的問題,每個 cpu 都有自己獨立的快取。
根據 NUMA 的硬體特性分析,NUMA 具有更高本地記憶體的存取效率,方便 CPU 擴充套件。HPC 需要資料存取的高效性,所以 NUMA 架構更適合 HPC 場景(UMA 與 NUMA 無優劣之分)。
Gemini 充分利用了 NUMA 對本 socket 記憶體存取低延遲、高頻寬的特性,將本機上的點跨多 socket 資料實現 NUMA-aware 切分(切分單位 CHUNKSIZE)。切分演演算法參考 Location-aware。
Gemini 的任務排程
Gemini 計算採用 BSP 模型(Bulk Synchronous Parallel)。為提高 CPU 和 IO 的利用率做了哪些工作呢?Gemini 提出了兩個設計:計算通訊協同排程、work stealing(偷任務)。
計算通訊系統排程
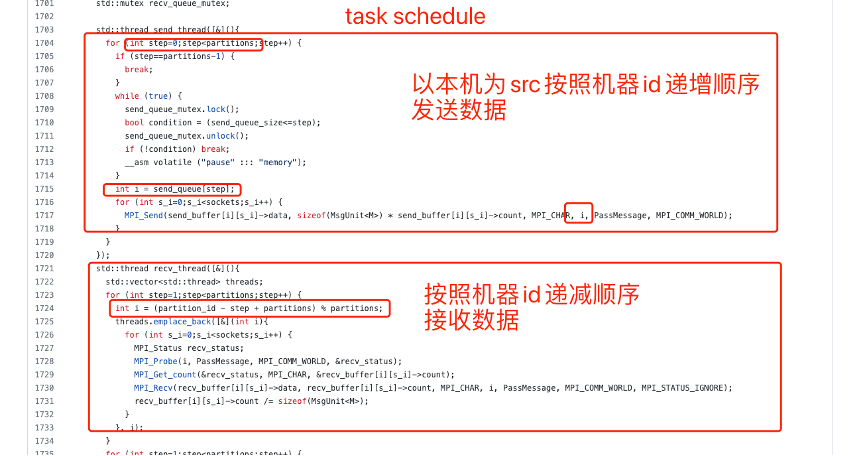
Geimini 在計算過程中引入了任務排程控制。他的排程演演算法設計比較簡單,可簡單理解為使用機器節點 ID 按照規定順序收發資料,避免收發任務碰撞。
Gemini 將一輪迭代過程稱為一個 step,把每一個 step 又拆分為多個 mini step(數量由叢集規模確定)。
• computation communication interleave
為了提高效率,減少執行緒排程的開銷,Gemini 將一次迭代計算拆分成了 computation 和 communication 兩個階段。在時間上,每一輪迭代都是先計算,再進行通訊,通訊任務排程不會摻雜任何計算的任務。
這樣設計的好處在於既保證上下文切換的開銷,又保證記憶體的區域性性(先計算再通訊)。缺點就在於需要開闢比較大的快取 buffer。
• Task Schedule
簡而言之:每個機器都按照特定的順序收發資料
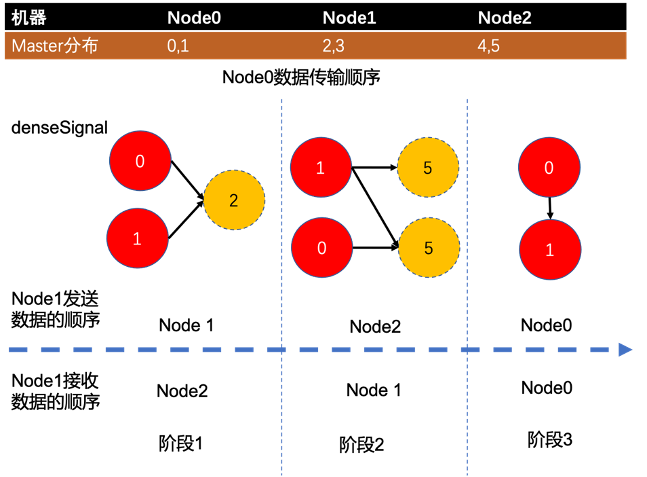
上圖列舉了叢集中 master 分佈情況,以 Node0 為例:
| 節點 | Node 0 |
|---|---|
| Master 範圍 | 0、1 |
| 階段 1 | 將資料向 Node1 傳送關於點 2 的資料,接收來自 Node2 資料 |
| 階段 2 | 將資料向 Node2 傳送關於點 5 的資料,接收來自 Node1 資料 |
| 階段 3 | 處理自身的資料(本地資料不經網路傳輸) |
在整個過程中,node0 按照機器 id 增序傳送,按照機器 id 降序接收,這個 feature 可以一定程度避免出現:同時多臺機器向同一臺機器傳送資料的情況,降低通訊通道競爭概率。
Work stealing
該設計是為了解決分散式計算系統中常見的 straggler 問題。
當某個 cpu task 處理完成所負責的 id,會先判斷同一個 socket 下的其他 cpu task 是否已完成。如果存在未完成任務,則幫助其他的 core 處理任務。(跨機器的 work stealing 沒有意義了,需要經歷兩次網路 io,而網路 io 延遲是大於處理延遲。)
Gemini 開原始碼中定義執行緒狀態管理結構,下圖參照了開原始碼的資料結構,並對變數進行了說明。

開始計算時,每個 core 均按照自己的 threadstate 進行處理資料,更大提升 cpu 使用效率。該設計是以點為單位進行的資料處理,但未解決熱點的難題(這也是業界難題,可以對熱點再次切分,也是需要突破的一個問題)。
下面是 2 core 的 work stealing 示意圖:
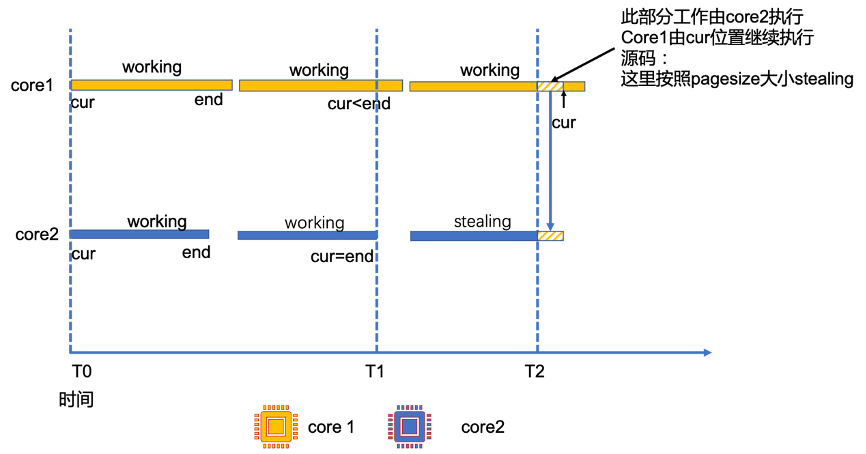
其中在初始情況 T0 時刻,core1 與 core2 同時開始執行,工作狀態都為 working;
在 T1 時刻, core2 的任務首先執行完成,core1 還未完成。
為了提高 core2 的利用率,就可以將 core1 的任務分配給 core2 去做。為了避免 core1、core2 存取衝突,此處使用原子操作獲取 stealing 要處理 id 範圍,處理完成之後,通過 socket 內部寫入指定空間。
在 T2 時刻,core2 更新工作狀態為 stealing,幫助 core1 完成任務。
在開原始碼中,在構圖設計 tune chunks 過程,可以實現跨機器的連續資料塊讀取,提升跨 socket 的效率。
注:開原始碼中,push 模式下並未使用到 tread state 結構,所以 tune chunks 中可以省略 push 模式 thread state 的初始化工作。其中在初始情況 T0 時刻,core1 與 core2 同時開始執行,工作狀態都為 working;
Gemini API 介面設計
API 設計上借鑑了 Ligra,設計了一種雙相訊號槽的分散式圖資料處理機制來分離通訊與計算的過程。
遮蔽底層資料組織和計算分散式的細節。演演算法移植更加方便,簡化開發難度。並且可以實現類 Pregel 系統的 combine 操作。
將圖的稀疏、稠密性作為雙模式區分標誌。
Gemini 演演算法呼叫使用 c++11 的 lambda 函數表示式,將演演算法實現與框架解耦。
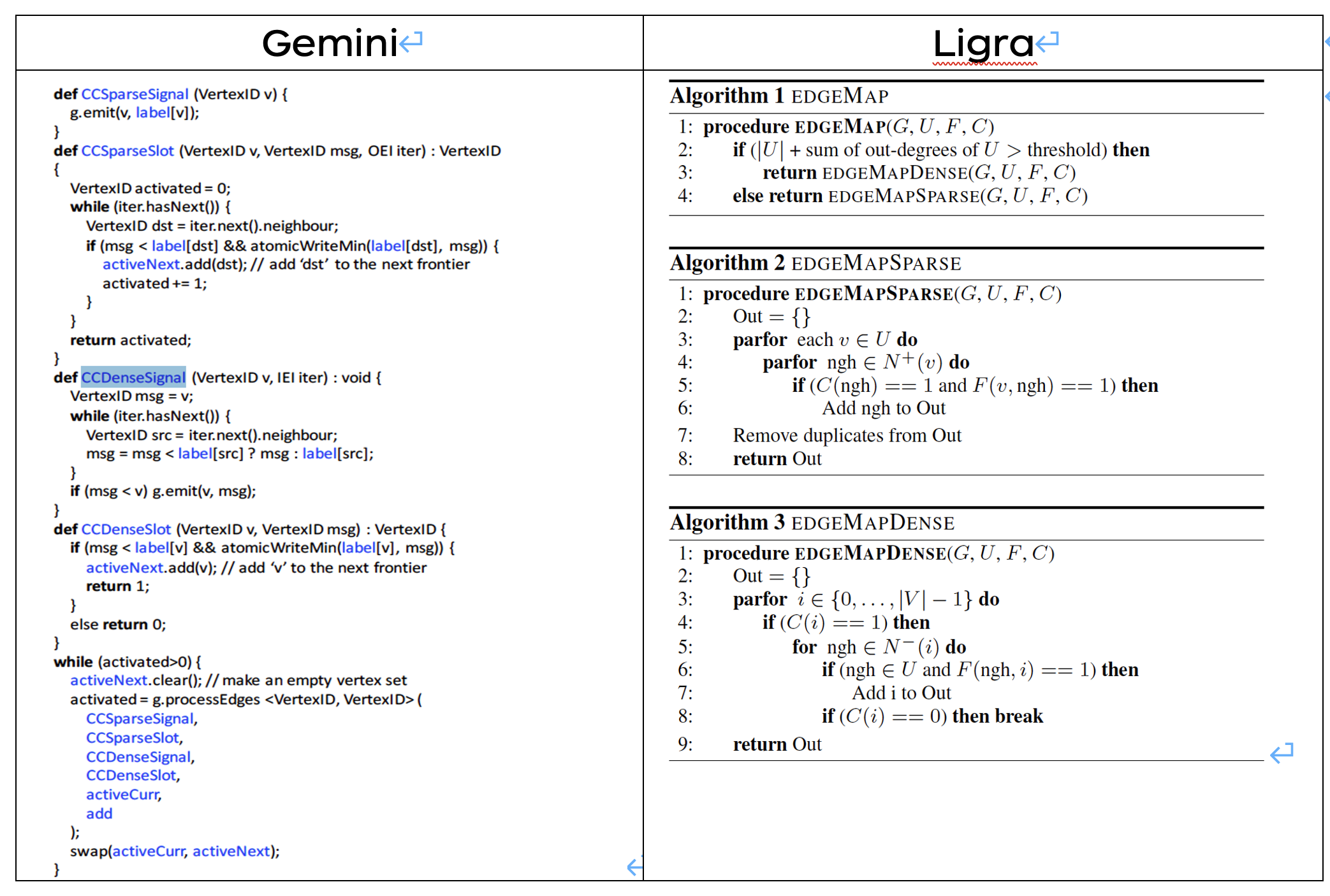
Gemini 在框架設計中創新的使用 signal、slot。將每輪迭代分為兩個階段:signal(資料傳送),slot(訊息處理),此處實現了通訊與資料處理過程的解耦。
Gemini 原始碼分析
Gemini 程式碼可以分為初始化,構圖,計算三部分。
初始化:設定叢集設定資訊,包括 mpi、numa、構圖時所需的 buffer 開銷的初始化;
構圖:依據演演算法輸入的資料特徵,實現有 / 無向圖的構造;
計算:在已構造完成的圖上,使用雙模式計算引擎計算。
Gemini 構圖程式碼分析
Gemini 在構圖時,需要事先統計每個點的出邊、入邊資訊,再依據統計資訊切圖,申請儲存圖所需的空間。
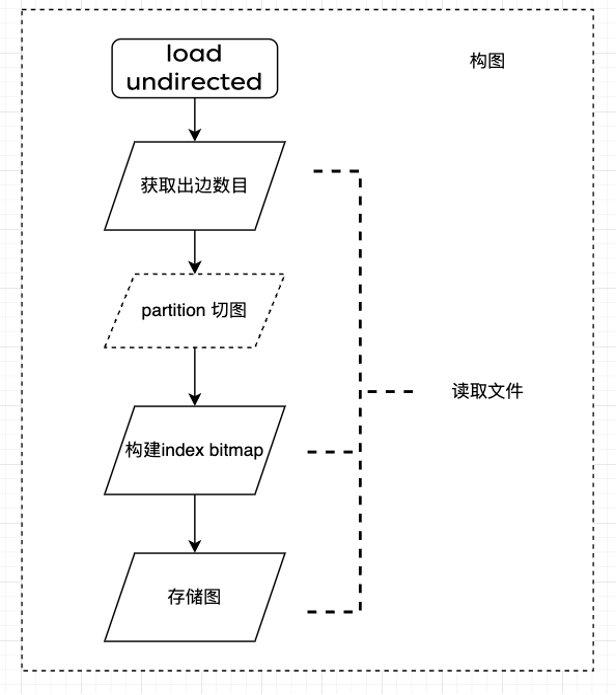
以無向圖構建為例,整個構圖過程經歷了 3 次檔案讀取:
1. 統計入邊資訊;
2. 生成圖儲存結構(bitmap、index);
3. 邊資料儲存。
入口函數:load_undirected_from_directed
開源原始碼 Gemini 叢集同時分段讀取同一份 binary 檔案,每臺機器都分段讀取一部分資料。
出邊資訊統計
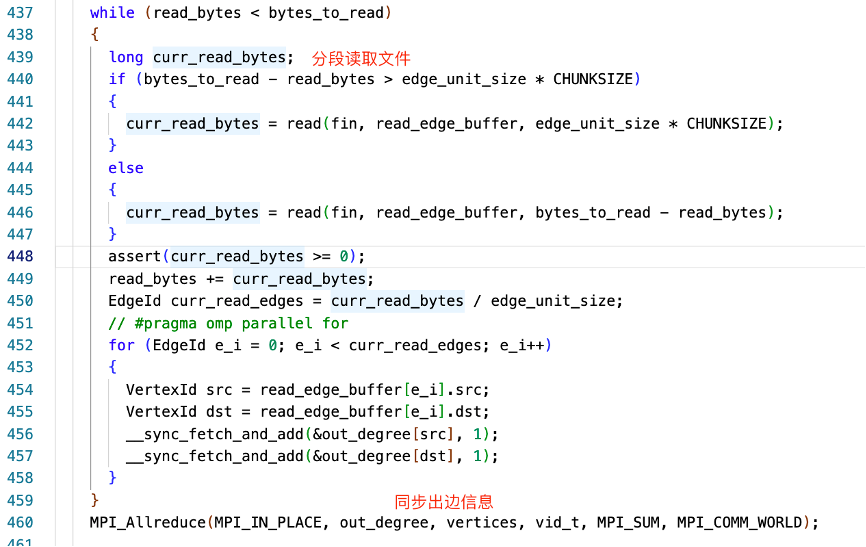
上圖程式碼分段讀取檔案,統計每個點的出邊資訊,見 line 456、457,通過 openmpi 通訊,聚合所有點出邊資訊 line 460。
Line 451:原理上可以使用 omp 並行,但由於原子操作鎖競爭比較大效率並不高。
Location aware 程式碼實現
Gemini 在 location aware 解決了地址感知,叢集負載平衡的工作。

解釋最後一行:owned_vertices 記錄當前機器 master 點個數,partition_offset [partition_id] 記錄 master 節點 vid 的下限,partition_offset [partition_id+1] 記錄 master 節點 vid 的上限。
好處:
1. 提升了記憶體的存取效率;
2. 減少了記憶體的零頭(在這個過程中,Gemini 為提高記憶體塊讀取的效率,使用 pagesize 進行記憶體對齊。)。
NUMA aware 程式碼實現
NUMA aware 作用是在 socket 上進行了 partition,平衡算力和 cpu 的負載,程式實現與 Location aware 過程類似。
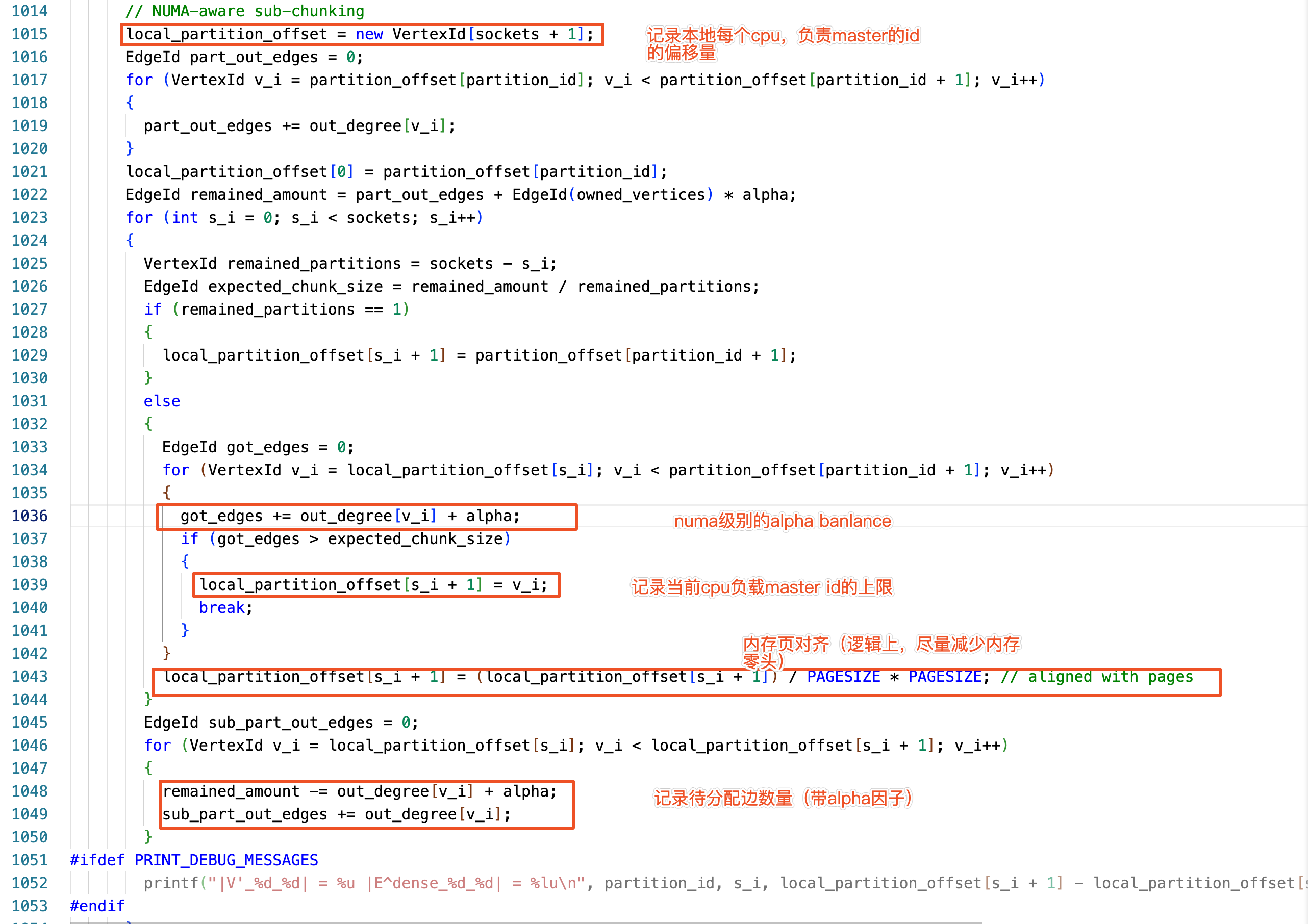
NUMA aware 也進行了 a 因子平衡和 pagesize 對齊。
總結:機器機器共用同一份出邊統計資料,所以在 location aware 和 numa aware 階段的結果都是相同的,partition 結果也不會出現衝突的情況。
注:aware 階段都是對 master 的切分,未統計 mirror 的狀態;而構圖過程是從 mirror 的視角實現的,所以下一個階段就需要統計 mirror 資訊。
構建邊管理結構
在完成 Location aware 和 NUMA aware 之後,需要考慮為邊 allocate 儲存空間。由於 Gemini 使用一維陣列儲存邊,所以必須事先確定所需的儲存空間,並 allocate 相應的記憶體管理結構。Gemini 使用二級索引實現點邊遍歷。
讀者很可能出現這樣的誤區:建立 master->mirror 關係對映。這樣會帶來什麼問題?超級頂點。也就意味著通訊和計算負載都會上升。這對圖計算引擎的效率影響很大。
可自行計算萬億級別點,每個 socket 上儲存的 index 佔用的空間。
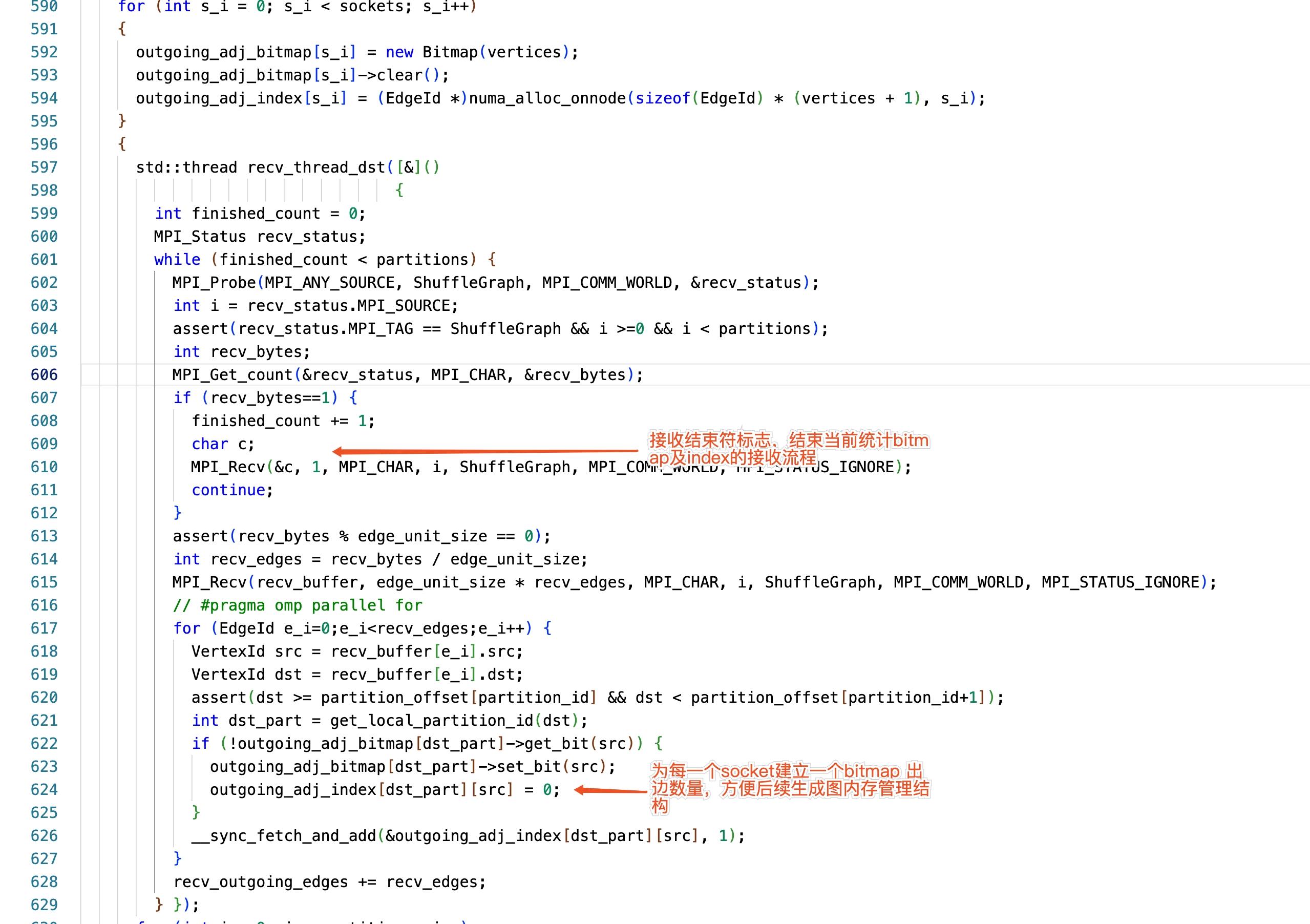
節點處理本地資料(按照 CHUNCKSIZE 大小,分批向叢集其他節點分發邊資料)。記錄 mirror 點的 bitmap 及出邊資訊。
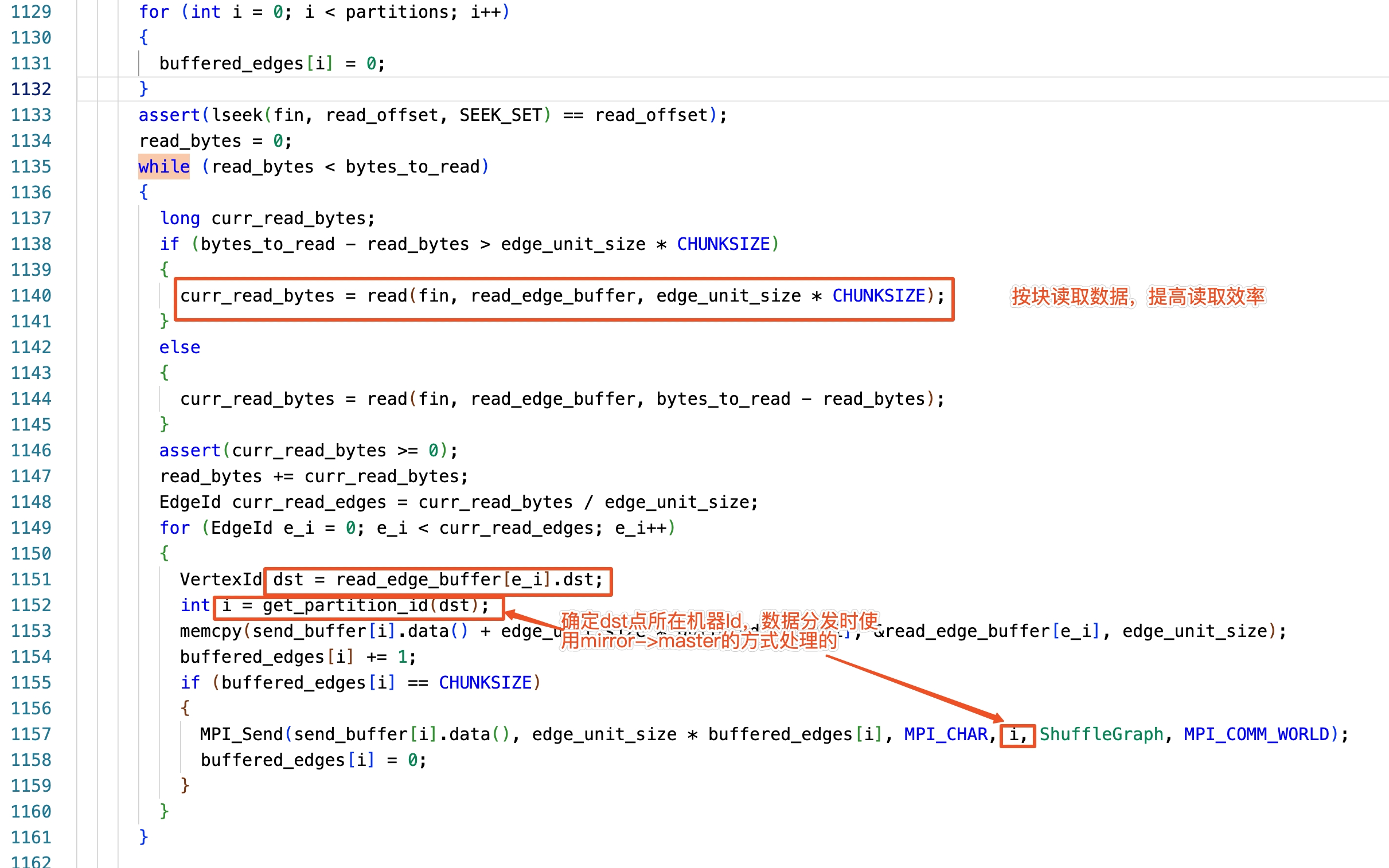
資料傳送過程是按照 CHUNCKSIZE 大小,分批傳送。
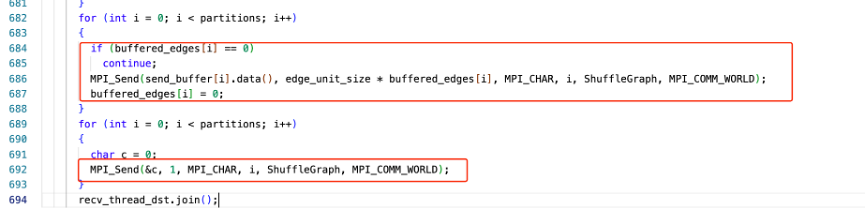
在傳送結束時,需確保所用的資料傳送完成,傳送字元‘\0‘作為結束符。
圖儲存
依據上一階段構建的管理結構實現邊的儲存,管理結構解釋:
Bitmap 的作用是確定在此 socket 下,此 mirror 點是否存在邊;
Index 標識邊的起始位置(見圖壓縮章節介紹)。
下圖註釋內容介紹了 index 的構建過程,構建過程中使用了單執行緒,cpu 利用率較低,可自行測試一下。
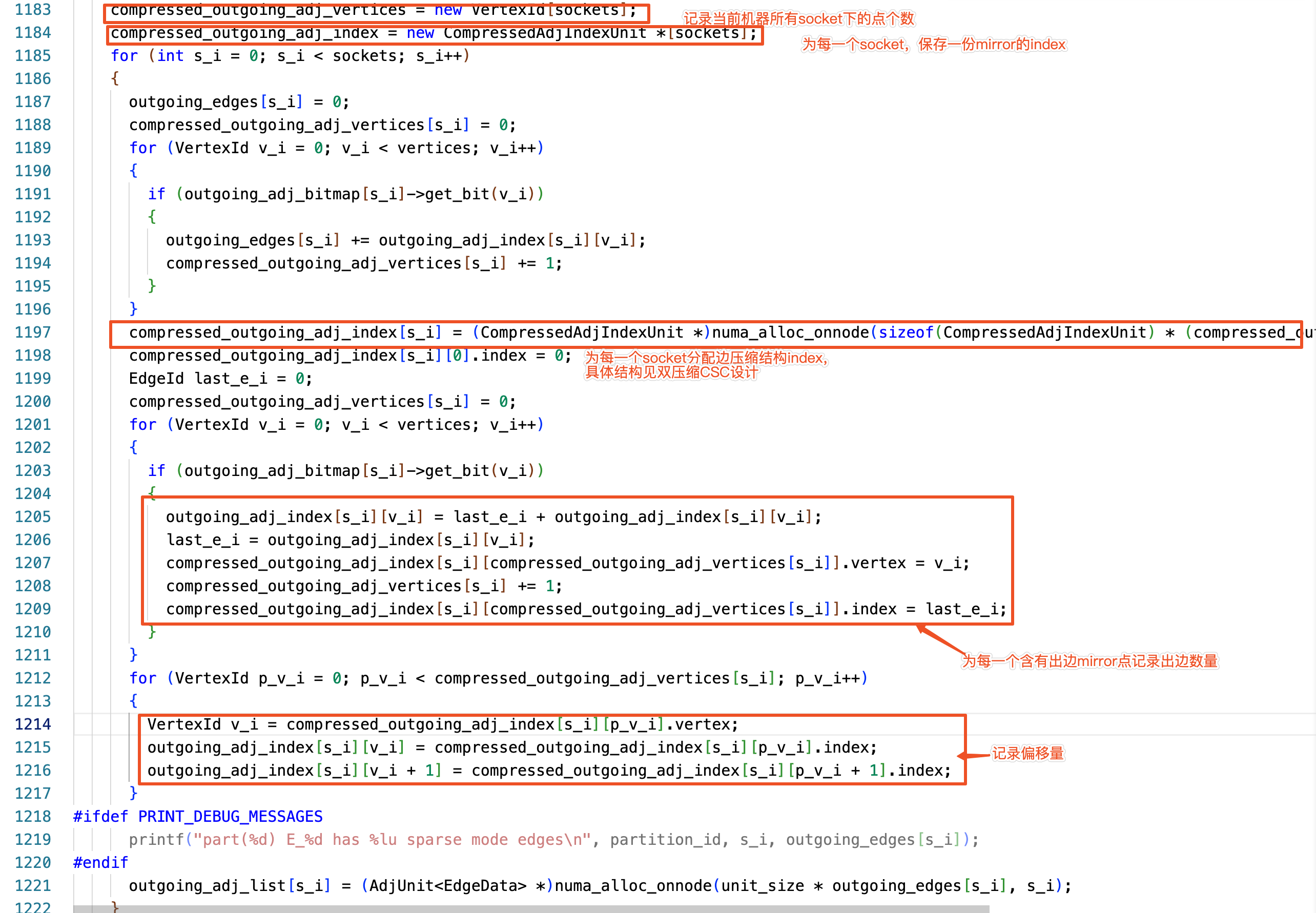
在邊儲存時,資料分發實現了並行傳輸。程式碼實現過程,見下圖程式碼註釋。

邊資料分發過程程式碼:

任務排程程式碼實現
構建任務排程資料結構 ThreadState, 引數設定 tune_chunks 程式碼實現,使用了 α 因子進行平衡。邏輯上將同一個 socket 的邊資料,按照執行緒進行二次劃分(balance)。
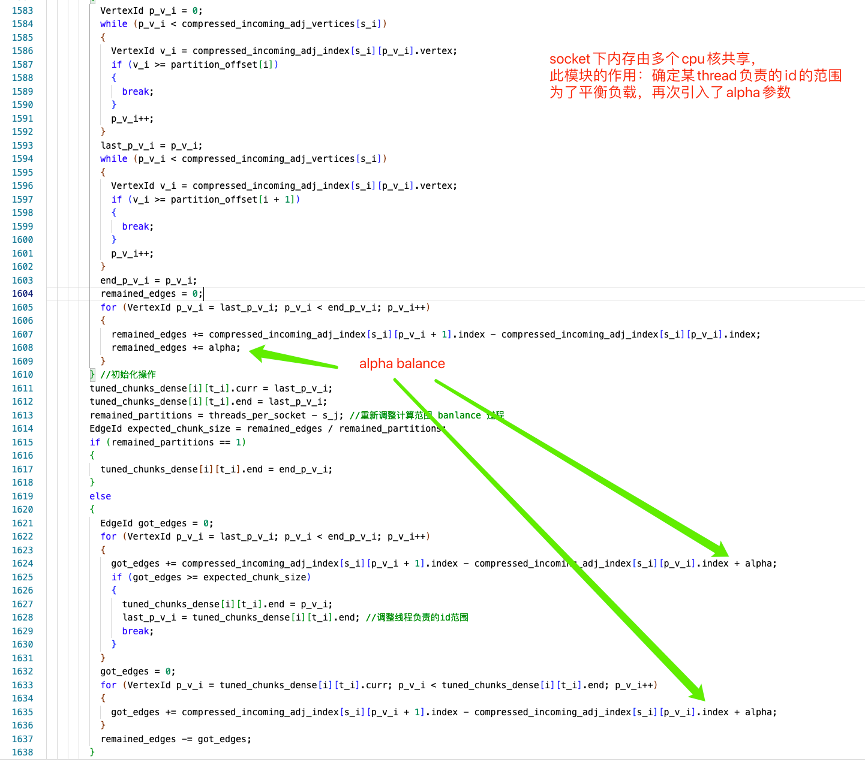
計算原始碼分析
雙模式的核心思想:儘可能將通訊放到本地記憶體,減少網路 IO 開銷。
以 dense 模式為例:pull 模式將叢集中的其他節點的部分結果 pull 到本地,實現同步計算。
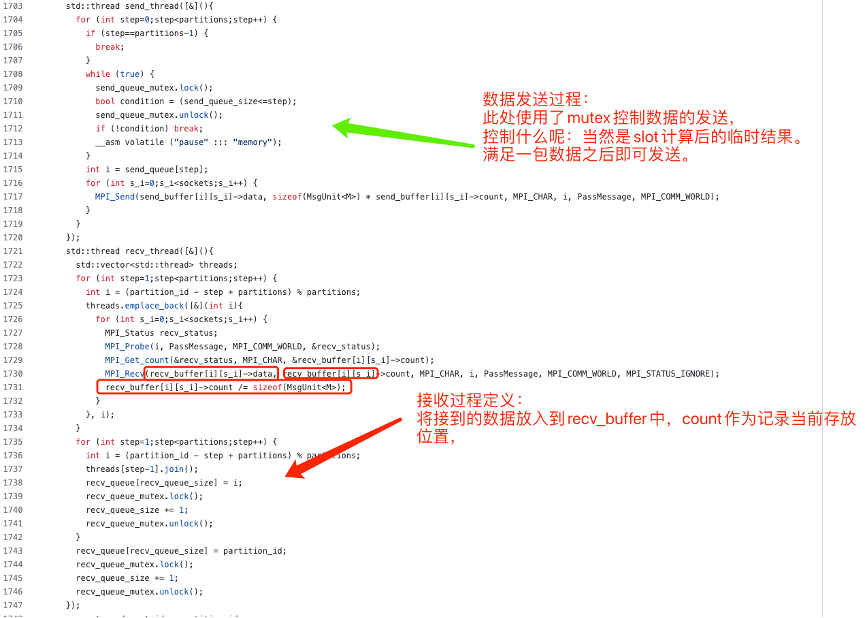
處理模組程式碼定義

注意:line1796 send_queue_mutex 的使用,通過鎖控制傳送模組的先後順序。
任務排程演演算法實現:
為保證每臺機器上的計算結果一致,所以在傳播過程中每個機器都會接收到相同的資料,在進行計算。
總結
Gemini 的關鍵設計:
• 自適應雙模式計算平衡了通訊和計算的負載問題;
• 基於塊的 Partition 平衡了叢集單機計算負載;
• 圖壓縮降低了記憶體的消耗。
Gemini 可繼續優化方向:
• Proces_edges 過程中,傳送 / 接收 buffer 開闢空間過大,程式碼如下:

在切換雙模運算時,呼叫了 resize 方法,此方法實現:當僅超過 capacity 時,才重新 alloc 記憶體空間,未實現進行縮容(空間
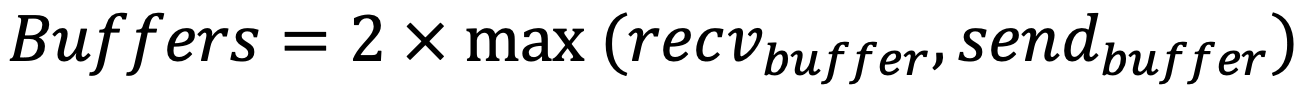
)。

a
• adj_index 會成為系統瓶頸
論文中也提到 adj_index 一級索引會佔用大部分空間(論文中也提到了會成為瓶頸)。改進後的 CSC 壓縮演演算法使用二級索引結構。在計算時會影響資料存取速度,無向圖中壓縮效果不好,遠高於一級索引的空間複雜度(冪律分佈決定,極大部分點存在 1 條以上的出邊,易得空間複雜度 2|V’|>|V|)。
• α 因子調整
α 因子應該根據圖的特徵進行動態調整,否則很容易造成記憶體 partition 偏斜。
• 動態更新
由於壓縮矩陣和 partition 方式都限制了圖的更新。可通過改變 parition 切分方式,犧牲 numa 特性帶來的區域性性,通過 snapshot 實現增量圖。
• 外存擴充套件
Gemini 是共用記憶體的分散式引擎。在實際生產環境中,通過暴力增加機器解決記憶體不足的問題,不是最優解。大容量外存不失為更好的解決方案。
參考文獻
11 1. Gemini: A Computation-Centric Distributed Graph Processing System 2. https://zh.wikipedia.org/wiki/%E5%9B%BE_(%E6%95%B0%E5%AD%A6) 3. https://oi-wiki.org/graph/save/ 4. https://github.com/thu-pacman/GeminiGraph.git 5. Ligra: A Lightweight Graph Processing Framework for Shared Memory 6. Pregel:a system for large-scale graph processing. 7. Powergraph: Distributed graph-parallel computation on natural graphs 8. https://en.wikipedia.org/wiki/Sparse_matrix#Coordinate_list_(COO) 9. https://programmer.ink/think/implementation-of-coo-and-csr-based-on-array-form-for-sparse-matrix.html 10. https://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series/ 11. https://frankdenneman.nl/2016/07/13/numa-deep-dive-4-local-memory-optimization/
內容來源:京東雲開發者社群 [https://www.jdcloud.com/]