Python函數用法和底層分析
Python函數用法和底層分析
函數是可重用的程式程式碼塊。函數的作用,不僅可以實現程式碼的複用,更能實現程式碼的一致性。一致性指的是,只要修改函數的程式碼,則所有呼叫該函數的地方都能得到體現。
在編寫函數時,函數體中的程式碼寫法和我們前面講述的基本一致,只是對程式碼實現了封裝,並增加了函數呼叫、傳遞引數、返回計算結果等內容。
為了讓大家更容易理解,掌握的更深刻。我們也要深入記憶體底層進行分析。絕大多數語言記憶體底層都是高度相似的,這樣大家掌握了這些內容也便於以後學習其他語言
函數的基本概念
- 一個程式由一個個任務組成;函數就是代表一個任務或者一個功能。
- 函數是程式碼複用的通用機制。
Python 函數的分類
Python 中函數分為如下幾類:
- 內建函數
我們前面使用的 str()、list()、len()等這些都是內建函數,我們可以拿來直接使用。
- 標準庫函數
我們可以通過 import 語句匯入庫,然後使用其中定義的函數
- 第三方庫函數
Python 社群也提供了很多高質量的庫。下載安裝這些庫後,也是通過 import 語句匯入,然後可以使用這些第三方庫的函數
- 使用者自定義函數
使用者自己定義的函數,顯然也是開發中適應使用者自身需求定義的函數。
核心要點
Python 中,定義函數的語法如下:
def 函數名 ([參數列]) :
'''檔案字串'''
函數體/若干語
要點:
- 我們使用 def 來定義函數,然後就是一個空格和函數名稱;
(1) Python 執行 def 時,會建立一個函數物件,並繫結到函數名變數上。
- 參數列
(1) 圓括號內是形式參數列,有多個引數則使用逗號隔開'
(2) 形式引數不需要宣告型別,也不需要指定函數返回值型別
(3) 無引數,也必須保留空的圓括號
(4) 實參列表必須與形參列表一一對應
- return 返回值
(1) 如果函數體中包含 return 語句,則結束函數執行並返回值;
(2) 如果函數體中不包含 return 語句,則返回 None 值。
- 呼叫函數之前,必須要先定義函數,即先呼叫 def 建立函數物件
(1) 內建函數物件會自動建立
(2) 標準庫和第三方庫函數,通過 import 匯入模組時,會執行模組中的 def 語
形參和實參
【操作】定義一個函數,實現兩個數的比較,並返回較大的值
def print_max(a,b):
'''實現兩個數的比較,並返回較大的值'''
if a > b:
print(a,'MAX')
else:
print(b,'MAX')
print_max(10, 20)
print_max(99, -99)
#result
#20 MAX
#99 MAX
上面的 printMax 函數中,在定義時寫的 print_max(a,b)。a 和 b 稱為「形式引數」,
簡稱「形參」。也就是說,形式引數是在定義函數時使用的。 形式引數的命名只要符合「識別符號」命名規則即可。
在呼叫函數時,傳遞的引數稱為「實際引數」,簡稱「實參」。上面程式碼中,
printMax(10,20),10 和 20 就是實際引數。
檔案字串(函數的註釋)
程式的可讀性最重要,一般建議在函數體開始的部分附上函數定義說明,這就是「檔案字串」,也有人成為「函數的註釋」。我們通過三個單引號或者三個雙引號來實現,中間可以加入多行文字進行說明
【操作】測試檔案字串的使用
def print_max(a,b):
'''實現兩個數的比較,並返回較大的值'''
if a > b:
print(a,'MAX')
else:
print(b,'MAX')
print(help(print_max.__doc__))
#result
#No Python documentation found for '實現兩個數的比較,並返回較大的值'.
#Use help() to get the interactive help utility.
#Use help(str) for help on the str class.
#None
返回值
return 返回值要點:
- 如果函數體中包含 return 語句,則結束函數執行並返回值;
- 如果函數體中不包含 return 語句,則返回 None 值。
- 要返回多個返回值,使用列表、元組、字典、集合將多個值「存起來」即可
【操作】計算a + b 不設定返回值
def print_star(a,b):
a + b
c = print_star(4,10)
print(c)
#result
#None
【操作】計算a + b 設定返回值
def print_star(a,b):
c = a + b
return c
c = print_star(4,10)
print(c)
#result
#14
函數也是物件,記憶體底層分析
Python 中,「一切都是物件」。實際上,執行 def 定義函數後,系統就建立了相應的函數物件。我們執行如下程式,然後進行解釋:
def print_star(n):
print("*"*n)
print(print_star)
print(id(print_star))
c = print_star
c(3)
#result
#<function print_star at 0x0000000002BB8620>
#45844000
#***
上面程式碼執行 def 時,系統中會建立函數物件,並通過 print_star 這個變數進行參照:

我們執行「c=print_star」後,顯然將 print_star 變數的值賦給了變數 c,記憶體圖變成了:
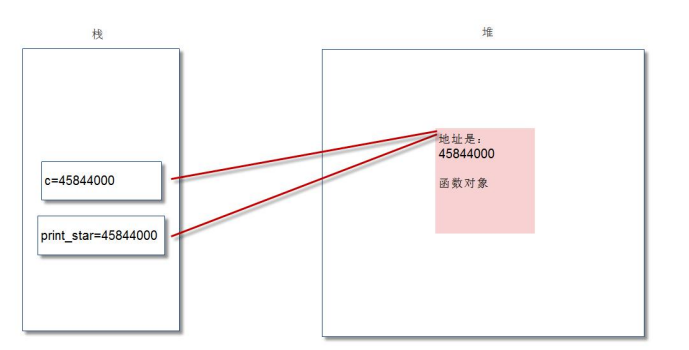
顯然,我們可以看出變數 c 和 print_star 都是指向了同一個函數物件。因此,執行 c(3)和執行 print_star(3)的效果是完全一致的。 Python 中,圓括號意味著呼叫函數。在沒有圓括號的情況下,Python 會把函數當做普通物件。
變數的作用域(全域性變數和區域性變數)
變數起作用的範圍稱為變數的作用域,不同作用域內同名變數之間互不影響。變數分為:全域性變數、區域性變數。
全域性變數:
- 在函數和類定義之外宣告的變數。作用域為定義的模組,從定義位置開始直到模組結束。
- 全域性變數降低了函數的通用性和可讀性。應儘量避免全域性變數的使用。
- 全域性變數一般做常數使用。
- 函數內要改變全域性變數的值,使用 global 宣告一下
區域性變數:
- 在函數體中(包含形式引數)宣告的變數。
- 區域性變數的參照比全域性變數快,優先考慮使用。
- 如果區域性變數和全域性變數同名,則在函數內隱藏全域性變數,只使用同名的區域性變數
【操作】全域性變數的作用域測試
def f1():
global a #如果要在函數內改變全域性變數的值,增加 global 關鍵字宣告
print(a) #列印全域性變數 a 的值
a = 300
f1()
print(a)
#result
#100
#300
【操作】全域性變數和區域性變數同名測試
a=100
def f1():
a = 3 #同名的區域性變數
print(a)
f1()
print(a) #a 仍然是 100,沒有變
#result
#3
#100
【操作】 輸出區域性變數和全域性變
a = 100
def f1(a, b, c):
print(a, b, c)
print(locals())
print('*' * 20)
print(globals())
f1(1, 2, 3)
#result
#1 2 3
#{'a': 1, 'b': 2, 'c': 3} 返回一個字典
#********************
#{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000023F0086CA10>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'c:\\Users\\chenh\\OneDrive\\Data Learn\\Python 基礎\\課堂筆記\\05\\Book_code.py', '__cached__': None, 'a': 100, 'f1': <function f1 at 0x0000023F00810680>}
部變數和全域性變數效率測試
區域性變數的查詢和存取速度比全域性變數快,優先考慮使用,尤其是在迴圈的時候。在特別強調效率的地方或者回圈次數較多的地方,可以通過將全域性變數轉為區域性變數提高執行速度
【操作】測試區域性變數和全域性變數效率
#測試區域性變數、全域性變數的效率
import time
import math
def test01():
start = time.time()
for i in range(100000000):
math.sqrt(30)
end = time.time()
print('耗時{0}'.format(end - start))
def test02():
b = math.sqrt
start = time.time()
for i in range(100000000):
b(30)
end = time.time()
print('耗時{0}'.format(end - start))
test01()
test02()
#result
#耗時7.24362325668335
#耗時6.6801464557647705
引數的傳遞
函數的引數傳遞本質上就是:從實參到形參的賦值操作。 Python 中「一切皆物件」,所有的賦值操作都是「參照的賦值」。所以,Python 中引數的傳遞都是「參照傳遞」,不是「值傳遞」。具體操作時分為兩類:
- 對「可變物件」進行「寫操作」,直接作用於原物件本身。
- 對「不可變物件」進行「寫操作」,會產生一個新的「物件空間」,並用新的值填充這塊空間。(起到其他語言的「值傳遞」效果,但不是「值傳遞」)
可變物件有:
字典、列表、集合、自定義的物件等
不可變物件有:
數位、字串、元組、function
【操作】引數傳遞:傳遞可變物件的參照
b = [10,20]
def f2(m):
print("m:",id(m)) #b 和 m 是同一個物件
m.append(30) #由於 m 是可變物件,不建立物件拷貝,直接修改這個物件
f2(b)
print("b:",id(b))
print(b)
#result
#m: 1619876826368
#b: 1619876826368
#[10, 20, 30]
傳遞不可變物件的參照
傳遞引數是不可變物件(例如:int、float、字串、元組、布林值),實際傳遞的還是物件的參照。在」賦值操作」時,由於不可變物件無法修改,系統會新建立一個物件。
【操作】引數傳遞:傳遞不可變物件的參照
a = 100
def f1(n):
print("n:",id(n)) #傳遞進來的是 a 物件的地址
n = n + 200 #由於 a 是不可變物件,因此建立新的物件 n
print("n:",id(n)) #n 已經變成了新的物件
print(n)
f1(a)
print("a:",id(a)) #a的記憶體地址並沒有發生改變
#result
#n: 140717568683912
#n: 2640908885520
#300
#a: 140717568683912
顯然,通過 id 值我們可以看到 n 和 a 一開始是同一個物件。給 n 賦值後,n 是新的物件。
淺拷貝和深拷貝
為了更深入的瞭解引數傳遞的底層原理,我們需要講解一下「淺拷貝和深拷貝」。我們可以使用內建函數:copy(淺拷貝)、deepcopy(深拷貝)。
淺拷貝:不拷貝子物件的內容,只是拷貝子物件的參照。
深拷貝:會連子物件的記憶體也全部拷貝一份,對子物件的修改不會影響源物件
【操作】測試淺拷貝和深拷貝
#測試淺拷貝和深拷貝
import copy
def testCopy():
'''測試淺拷貝'''
a = [10, 20, [5, 6]]
b = copy.copy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("淺拷貝......")
print("a", a)
print("b", b)
def testDeepCopy():
'''測試深拷貝'''
a = [10, 20, [5, 6]]
b = copy.deepcopy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("深拷貝......")
print("a", a)
print("b", b)
testCopy()
print("*************")
testDeepCopy()
#result
'''
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
淺拷貝......
a [10, 20, [5, 6, 7]]
b [10, 20, [5, 6, 7], 30]
*************
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
深拷貝......
a [10, 20, [5, 6]]
b [10, 20, [5, 6, 7], 30]
'''
傳遞不可變物件包含的子物件是可變的情況
傳遞不可變物件時。不可變物件裡面包含的子物件是可變的。則方法內修改了這個可變物件,源物件也發生了變化
a = (10,20,[5,6])
print("a:",id(a))
def test01(m):
print("m:",id(m))
m[2][0] = 888
print(m)
print("m:",id(m))
test01(a)
print(a)
#result
'''
a: 3006159512640
m: 3006159512640
(10, 20, [888, 6])
m: 3006159512640
(10, 20, [888, 6])
'''
引數的幾種型別
位置引數
函數呼叫時,實參預設按位元置順序傳遞,需要個數和形參匹配。按位元置傳遞的引數,稱為:「位置引數」。
【操作】測試位置引數
def f1(a,b,c):
print(a,b,c)
f1(2,3,4)
f1(2,3) #報錯,位置引數不匹配
#result
'''
2 3 4
Traceback (most recent call last):
File "c:\Users\chenh\OneDrive\Data Learn\Python 基礎\課堂筆記\05\Book_code.py", line 4, in <module>
f1(2,3) #報錯,位置引數不匹配
^^^^^^^
TypeError: f1() missing 1 required positional argument: 'c'
'''
預設值引數
我們可以為某些引數設定預設值,這樣這些引數在傳遞時就是可選的。稱為「預設值引數」。預設值引數放到位置引數後面。
【操作】測試預設值引數
def f1(a, b, c=10, d=20): #預設值引數必須位於普通位置引數後面
print(a, b, c, d)
f1(9, 8)
f1(8, 9, 19)
f1(8, 9, 19, 29)
#result
'''
9 8 10 20
8 9 19 20
8 9 19 29
'''
命名引數
我們也可以按照形參的名稱傳遞引數,稱為「命名引數」,也稱「關鍵字引數」。
【操作】測試命名引數
def f1(a,b,c):
print(a,b,c)
f1(8, 9, 19) #位置引數
f1(c=10, a=20, b=30) #命名引數、
#result
'''
8 9 19
20 30 10
'''
可變引數
可變引數指的是「可變數量的引數」。分兩種情況:
- *param(一個星號),將多個引數收集到一個「元組」物件中。
- **param(兩個星號),將多個引數收集到一個「字典」物件中。
【操作】測試可變引數處理(元組、字典兩種方式
def f1(a,b,*c):
print(a,b,c)
f1(8, 9, 19, 20)
def f2(a,b,**c):
print(a,b,c)
f2(8, 9, name = 'gaoqi', age = 18)
def f3(a,b,*c,**d):
print(a,b,c,d)
f3(8, 9, 20, 30, name = 'gaoqi',age = 18)\
#result
'''
8 9 (19, 20) #將*c引數放在元組中
8 9 {'name': 'gaoqi', 'age': 18} #將**c引數放在字典中
8 9 (20, 30) {'name': 'gaoqi', 'age': 18}
'''
強制命名引數
在帶星號的「可變引數」後面增加新的引數,必須在呼叫的時候「強制命名引數」。
【操作】強制命名引數的使用
def f1(*a,b,c):
print(a,b,c)
#f1(2,3,4) #會報錯。由於 a 是可變引數,將 2,3,4 全部收集。造成 b 和 c 沒有賦值。
f1(2,b=3,c=4)
f1(2, 3, 4, b=10, c=100)
'''
result:
(2,) 3 4
(2, 3, 4) 10 100
'''
lambda 表示式和匿名函數
lambda 表示式可以用來宣告匿名函數。lambda 函數是一種簡單的、在同一行中定義函數的方法。lambda 函數實際生成了一個函數物件。
lambda 表示式只允許包含一個表示式,不能包含複雜語句,該表示式的計算結果就是函數的返回值。
ambda 表示式的基本語法如下:
lambda arg1,arg2,arg3... : <表示式>
arg1/arg2/arg3 為函數的引數。<表示式>相當於函數體。運算結果是:表示式的運算結果。
【操作】lambda 表示式使
f = lambda a, b, c : a + b + c
print(f)
print(f(2, 3, 4))
'''
result:
<function <lambda> at 0x0000024E1DBA0680>
9
'''
g = [lambda a : a*2, lambda b : b*3, lambda c : c*4]
print(g)
print(g[0](6),g[1](7),g[2](8))
'''
result:
[<function <lambda> at 0x0000019D11368E00>, <function <lambda> at 0x0000019D11368F40>, <function <lambda> at 0x0000019D11368FE0>]
12 21 32
'''
eval()函數
功能:將字串 str 當成有效的表示式來求值並返回計算結果。
語法引數:
eval(source[, globals[, locals]]) -> value
source:一個 Python 表示式或函數 compile()返回的程式碼物件
globals:可選。必須是 dictionary
locals:可選。任意對映物件
s = "print('abcde')"
eval(s)
a = 10
b = 20
c = eval("a + b")
print(c)
dict1 = dict(a = 100, b = 200)
d = eval("a+b",dict1)
print(d)
'''
result:
abcde
30
300
'''
eval 函數會將字串當做語句來執行,因此會被注入安全隱患。比如:字串中含有刪除檔案的語句。那就麻煩大了。因此,使用時候,要慎重!!!
遞迴函數
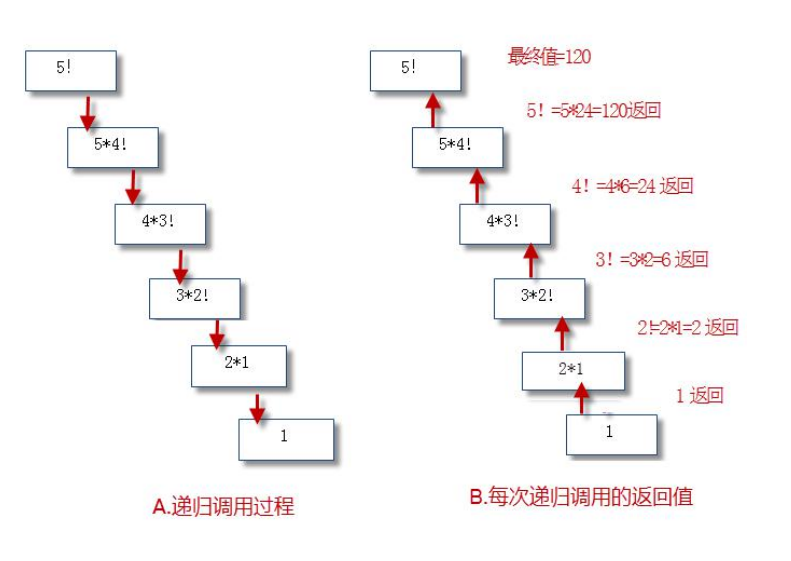
遞迴函數指的是:自己呼叫自己的函數,在函數體內部直接或間接的自己呼叫自己。遞迴類似於大家中學數學學習過的「數學歸納法」。 每個遞迴函數必須包含兩個部分:
- 終止條件
表示遞迴什麼時候結束。一般用於返回值,不再呼叫自己。
- 遞迴步驟
把第 n 步的值和第 n-1 步相關聯。
遞迴函數由於會建立大量的函數物件、過量的消耗記憶體和運算能力。在處理大量資料時,謹慎使用。
【操作】 使用遞迴函數計算階乘(factorial
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n-1)
for i in range(1,11):
print(i,'!=',factorial(i))
'''
result:
1 != 1
2 != 2
3 != 6
4 != 24
5 != 120
6 != 720
7 != 5040
8 != 40320
9 != 362880
10 != 3628800
'''