含辭未吐,聲若幽蘭,史上最強免費人工智慧AI語音合成TTS服務微軟Azure(Python3.10接入)
所謂文無第一,武無第二,雲原生人工智慧技術目前呈現三足鼎立的態勢,微軟,谷歌以及亞馬遜三大巨頭各擅勝場,不分伯仲,但目前微軟Azure平臺不僅僅只是一個PaaS平臺,相比AWS,以及GAE,它應該是目前提供雲端計算人工智慧服務最全面的一個平臺,尤其是語音合成領域,論AI語音的平順、自然以及擬真性,無平臺能出其右。
本次,我們通過Python3.10版本接入Azure平臺語音合成介面,打造一款原生的TTS服務(文字轉語音:Text To Speech)。
準備工作
在平臺上建立免費訂閱服務:https://azure.microsoft.com/zh-cn/free/cognitive-services/
免費訂閱成功後,進入資源建立環節,這裡我們存取網址,建立免費的語音資源:https://portal.azure.com/
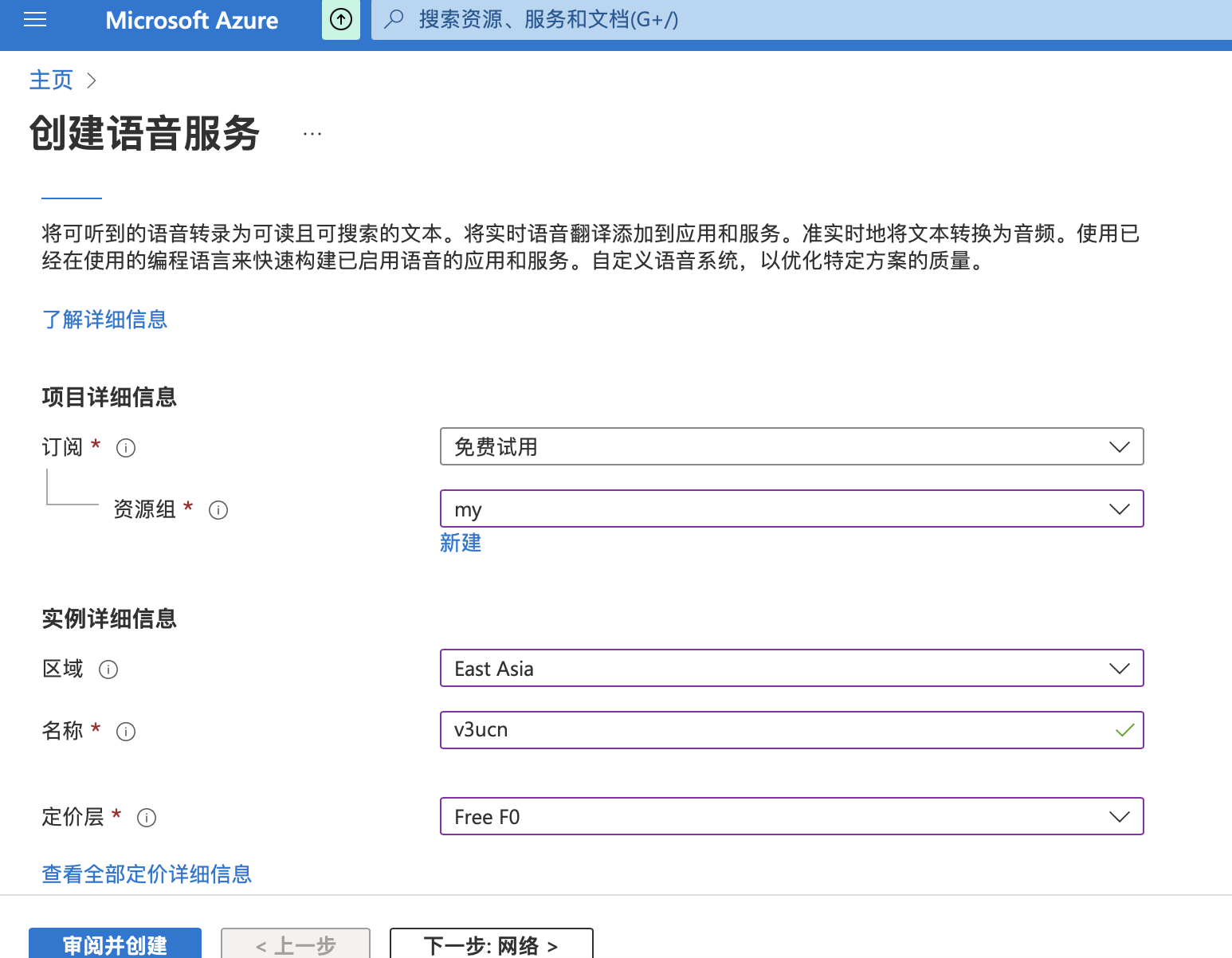
這裡注意訂閱選擇免費試用,使用區域選擇東亞,如果在國外可以選擇國外的對應區域。
建立語音服務資源成功後,轉到資源組列表,點選獲取資源祕鑰:

需要注意的是,任何時候都不要將祕鑰進行傳播,或者將祕鑰寫入程式碼並且提交版本。
這裡相對穩妥的方式是將祕鑰寫入本地系統的環境變數中。
Windows系統使用如下命令:
setx COGNITIVE_SERVICE_KEY 您的祕鑰
Linux系統使用如下命令:
export COGNITIVE_SERVICE_KEY=您的祕鑰
Mac系統的bash終端:
編輯 ~/.bash_profile,然後新增環境變數
export COGNITIVE_SERVICE_KEY=您的祕鑰
新增環境變數後,請從控制檯視窗執行 source ~/.bash_profile,使更改生效。
Mac系統的zsh終端:
編輯 ~/.zshrc,然後新增環境變數
export COGNITIVE_SERVICE_KEY=您的祕鑰
如此,前期準備工作就完成了。
本地接入
確保本地Python環境版本3.10以上,然後安裝Azure平臺sdk:
pip3 install azure-cognitiveservices-speech
建立test.py檔案:
`import azure.cognitiveservices.speech as speechsdk
import os
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('KEY'), region="eastasia")``audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)`
這裡定義語音的組態檔,通過os模組將上文環境變數中的祕鑰取出使用,region就是新建語音資源時選擇的地區,audio_config是選擇當前計算機預設的音箱進行輸出操作。
接著,根據官方檔案的設定,選擇一個語音機器人:https://learn.microsoft.com/zh-cn/azure/cognitive-services/speech-service/language-support?tabs=stt-tts
純文字 wuu-CN-XiaotongNeural1(女)
wuu-CN-YunzheNeural1(男) 不支援
yue-CN 中文(粵語,簡體) yue-CN 純文字 yue-CN-XiaoMinNeural1(女)
yue-CN-YunSongNeural1(男) 不支援
zh-CN 中文(普通話,簡體) zh-CN 音訊 + 人工標記的指令碼
純文字
結構化文字
短語列表 zh-CN-XiaochenNeural4、5、6(女)
zh-CN-XiaohanNeural2、4、5、6(女)
zh-CN-XiaomengNeural1、2、4、5、6(女)
zh-CN-XiaomoNeural2、3、4、5、6(女)
zh-CN-XiaoqiuNeural4、5、6(女)
zh-CN-XiaoruiNeural2、4、5、6(女)
zh-CN-XiaoshuangNeural2、4、5、6、8(女)
zh-CN-XiaoxiaoNeural2、4、5、6(女)
zh-CN-XiaoxuanNeural2、3、4、5、6(女)
zh-CN-XiaoyanNeural4、5、6(女)
zh-CN-XiaoyiNeural1、2、4、5、6(女)
zh-CN-XiaoyouNeural4、5、6、8(女)
zh-CN-XiaozhenNeural1、2、4、5、6(女)
zh-CN-YunfengNeural1、2、4、5、6(男)
zh-CN-YunhaoNeural1、2、4、5、6(男)
zh-CN-YunjianNeural1、2、4、5、6(男)
zh-CN-YunxiaNeural1、2、4、5、6(男)
zh-CN-YunxiNeural2、3、4、5、6(男)
zh-CN-YunyangNeural2、4、5、6(男)
zh-CN-YunyeNeural2、3、4、5、6(男)
zh-CN-YunzeNeural1、2、3、4、5、6(男) 神經網路客製化聲音專業版
神經網路客製化聲音精簡版(預覽版)
跨語言語音(預覽版)
zh-CN-henan 中文(中原河南普通話,中國大陸) 不支援 不支援 zh-CN-henan-YundengNeural1(男) 不支援
zh-CN-liaoning 中文(東北普通話,中國大陸) 不支援 不支援 zh-CN-liaoning-XiaobeiNeural1(女) 不支援
zh-CN-shaanxi 中文(中原陝西普通話,中國大陸) 不支援 不支援 zh-CN-shaanxi-XiaoniNeural1(女) 不支援
zh-CN-shandong 中文(冀魯普通話,中國大陸) 不支援 不支援 zh-CN-shandong-YunxiangNeural1(男) 不支援
zh-CN-sichuan 中文(西南普通話,簡體) zh-CN-sichuan 純文字 zh-CN-sichuan-YunxiNeural1(男) 不支援
zh-HK 中文(粵語,繁體) zh-HK 純文字 zh-HK-HiuGaaiNeural4、5、6(女)
zh-HK-HiuMaanNeural4、5、6(女)
zh-HK-WanLungNeural1、4、5、6(男) 神經網路客製化聲音專業版
zh-TW 中文(臺灣普通話) zh-TW 純文字 zh-TW-HsiaoChenNeural4、5、6(女)
zh-TW-HsiaoYuNeural4、5、6(女)
zh-TW-YunJheNeural4、5、6(男) 神經網路客製化聲音專業版
單以中文語音論,可選擇的範圍還是相當廣泛的。
繼續編輯程式碼:
import azure.cognitiveservices.speech as speechsdk
import os
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('KEY'), region="eastasia")
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
speech_config.speech_synthesis_voice_name='zh-CN-XiaomoNeural'
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
text = "hello 大家好,這裡是人工智慧AI機器人在說話"
speech_synthesis_result = speech_synthesizer.speak_text_async(text).get()
這裡我們選擇zh-CN-XiaomoNeural作為預設AI語音,並且將text文字變數中的內容通過音箱進行輸出。
如果願意,我們也可以將語音輸出為實體檔案進行儲存:
import azure.cognitiveservices.speech as speechsdk
import os
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('KEY'), region="eastasia")
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
file_config = speechsdk.audio.AudioOutputConfig(filename="./output.wav")
speech_config.speech_synthesis_voice_name='zh-CN-XiaomoNeural'
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=file_config)
text = "hello 大家好,這裡是人工智慧AI機器人在說話"
speech_synthesis_result = speech_synthesizer.speak_text_async(text).get()
這裡指定file_config設定為指令碼相對路徑下的output.wav檔案:
ls
output.wav
如此,音訊檔就可以被儲存起來,留作以後使用了。
語音調優
預設AI語音聽多了,難免會有些索然寡味之感,幸運的是,Azure平臺提供了語音合成標示語言 (SSML) ,它可以改善合成語音的聽感。
根據Azure官方檔案:https://learn.microsoft.com/zh-cn/azure/cognitive-services/speech-service/speech-synthesis-markup
通過調整語音的角色以及樣式來獲取客製化化的聲音:
語音 樣式 角色
en-GB-RyanNeural1 cheerful, chat 不支援
en-GB-SoniaNeural1 cheerful, sad 不支援
en-US-AriaNeural chat, customerservice, narration-professional, newscast-casual, newscast-formal, cheerful, empathetic, angry, sad, excited, friendly, terrified, shouting, unfriendly, whispering, hopeful 不支援
en-US-DavisNeural chat, angry, cheerful, excited, friendly, hopeful, sad, shouting, terrified, unfriendly, whispering 不支援
en-US-GuyNeural newscast, angry, cheerful, sad, excited, friendly, terrified, shouting, unfriendly, whispering, hopeful 不支援
en-US-JaneNeural angry, cheerful, excited, friendly, hopeful, sad, shouting, terrified, unfriendly, whispering 不支援
en-US-JasonNeural angry, cheerful, excited, friendly, hopeful, sad, shouting, terrified, unfriendly, whispering 不支援
en-US-JennyNeural assistant, chat, customerservice, newscast, angry, cheerful, sad, excited, friendly, terrified, shouting, unfriendly, whispering, hopeful 不支援
en-US-NancyNeural angry, cheerful, excited, friendly, hopeful, sad, shouting, terrified, unfriendly, whispering 不支援
en-US-SaraNeural angry, cheerful, excited, friendly, hopeful, sad, shouting, terrified, unfriendly, whispering 不支援
en-US-TonyNeural angry, cheerful, excited, friendly, hopeful, sad, shouting, terrified, unfriendly, whispering 不支援
es-MX-JorgeNeural1 cheerful, chat 不支援
fr-FR-DeniseNeural1 cheerful, sad 不支援
fr-FR-HenriNeural1 cheerful, sad 不支援
it-IT-IsabellaNeural1 cheerful, chat 不支援
ja-JP-NanamiNeural chat, customerservice, cheerful 不支援
pt-BR-FranciscaNeural calm 不支援
zh-CN-XiaohanNeural5 calm, fearful, cheerful, disgruntled, serious, angry, sad, gentle, affectionate, embarrassed 不支援
zh-CN-XiaomengNeural1、5 chat 不支援
zh-CN-XiaomoNeural5 embarrassed, calm, fearful, cheerful, disgruntled, serious, angry, sad, depressed, affectionate, gentle, envious YoungAdultFemale, YoungAdultMale, OlderAdultFemale, OlderAdultMale, SeniorFemale, SeniorMale, Girl, Boy
zh-CN-XiaoruiNeural5 calm, fearful, angry, sad 不支援
zh-CN-XiaoshuangNeural5 chat 不支援
zh-CN-XiaoxiaoNeural5 assistant, chat, customerservice, newscast, affectionate, angry, calm, cheerful, disgruntled, fearful, gentle, lyrical, sad, serious, poetry-reading 不支援
zh-CN-XiaoxuanNeural5 calm, fearful, cheerful, disgruntled, serious, angry, gentle, depressed YoungAdultFemale, YoungAdultMale, OlderAdultFemale, OlderAdultMale, SeniorFemale, SeniorMale, Girl, Boy
zh-CN-XiaoyiNeural1、5 angry, disgruntled, affectionate, cheerful, fearful, sad, embarrassed, serious, gentle 不支援
zh-CN-XiaozhenNeural1、5 angry, disgruntled, cheerful, fearful, sad, serious 不支援
zh-CN-YunfengNeural1、5 angry, disgruntled, cheerful, fearful, sad, serious, depressed 不支援
zh-CN-YunhaoNeural1、2、5 advertisement-upbeat 不支援
zh-CN-YunjianNeural1、3、4、5 Narration-relaxed, Sports_commentary, Sports_commentary_excited 不支援
zh-CN-YunxiaNeural1、5 calm, fearful, cheerful, angry, sad 不支援
zh-CN-YunxiNeural5 narration-relaxed, embarrassed, fearful, cheerful, disgruntled, serious, angry, sad, depressed, chat, assistant, newscast Narrator, YoungAdultMale, Boy
zh-CN-YunyangNeural5 customerservice, narration-professional, newscast-casual 不支援
zh-CN-YunyeNeural5 embarrassed, calm, fearful, cheerful, disgruntled, serious, angry, sad YoungAdultFemale, YoungAdultMale, OlderAdultFemale, OlderAdultMale, SeniorFemale, SeniorMale, Girl, Boy
zh-CN-YunzeNeural1、5 calm, fearful, cheerful, disgruntled, serious, angry, sad, depressed, documentary-narration OlderAdultMale, SeniorMale
這裡將語音文字改造為SSML的設定格式:
import os
import azure.cognitiveservices.speech as speechsdk
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('KEY'), region="eastasia")
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
file_config = speechsdk.audio.AudioOutputConfig(filename="./output.wav")
speech_config.speech_synthesis_voice_name='zh-CN-XiaomoNeural'
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=file_config)
#text = "hello 大家好,這裡是人工智慧AI機器人在說話"
#speech_synthesis_result = speech_synthesizer.speak_text_async(text).get()
text = """
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="zh-CN">
<voice name="zh-CN-XiaoxiaoNeural">
<mstts:express-as style="lyrical" role="YoungAdultFemale" >
<prosody rate="+12.00%">
hello 大家好,這裡是劉悅的技術部落格
大江東去,浪淘盡,千古風流人物。
故壘西邊,人道是,三國周郎赤壁。
亂石穿空,驚濤拍岸,捲起千堆雪。
江山如畫,一時多少豪傑。
</prosody>
</mstts:express-as>
</voice>
</speak>"""
result = speech_synthesizer.speak_ssml_async(ssml=text).get()
通過使用style和role標記進行客製化,同時使用rate屬性來提升百分之十二的語速,從而讓AI語音更加連貫順暢。注意這裡使用ssml=text來宣告ssml格式的文字。
結語
人工智慧AI語音系統完成了人工智慧在語音合成這個細分市場的落地應用,為網際網路領域內許多需要配音的業務節約了成本和時間。