比Sqoop功能更加強大開源資料同步工具DataX實戰
@
概述
定義
DataX 官網地址 https://maxwells-daemon.io/
DataX GitHub原始碼地址 https://github.com/alibaba/DataX
DataX 是Alibaba集團下阿里雲 DataWorks資料整合的開源版本,用作異構資料來源離線同步工具或平臺;其實現瞭如 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、HBase、ClickHouse 等各種異構資料來源之間穩定高效的資料同步功能。本文全部內容只對最新框架3.0系列說明,最新版本為datax_v202210
為了解決異構資料來源同步問題,DataX將複雜的網狀的同步鏈路變成了星型資料鏈路,DataX作為中間傳輸載體負責連線各種資料來源。當需要接入一個新的資料來源的時候,只需要將此資料來源對接到DataX,便能跟已有的資料來源做到無縫資料同步;基於外掛式擴充套件能力上可以說DataX框架具備支援任意資料來源型別的資料同步工作的能力。
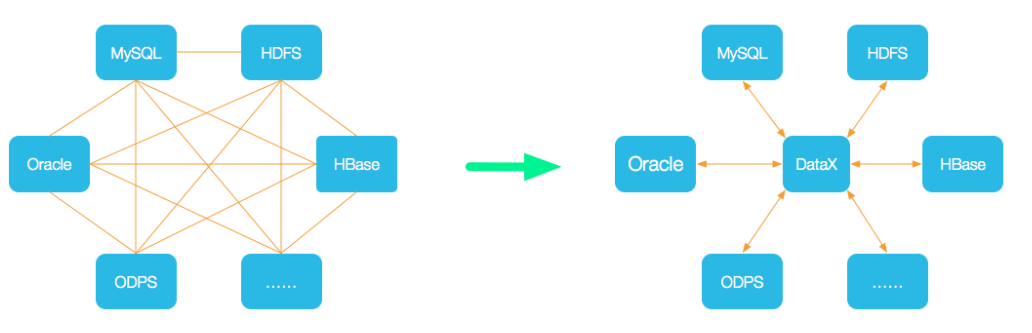
與Sqoop對比
Apache Sqoop(TM)是一種用於在Apache Hadoop和結構化資料儲存(如關聯式資料庫)之間高效傳輸批次資料的工具,最新的穩定版本是1.4.7,而其Sqoop2的最新版本是1.99.7,但是1.99.7與1.4.7不相容,而且特性不完整,因此Sqoop2不用於生產部署。Sqoop1.4.7在2017年後就沒有再更新,不是說Sqoop不好,是官方已沒有需要修復的問題,穩定,據說專案PMC也都解散了。如果業務只需要對關聯式資料庫同步的HDFS(還包括hive、hbase),使用sqoop也是可以的。Sqoop也可以實現增量資料同步,比如通過查詢的sql中增加時間過濾欄位,也可以結合自身job記住帶有單調遞增的編號欄位實現增量同步。
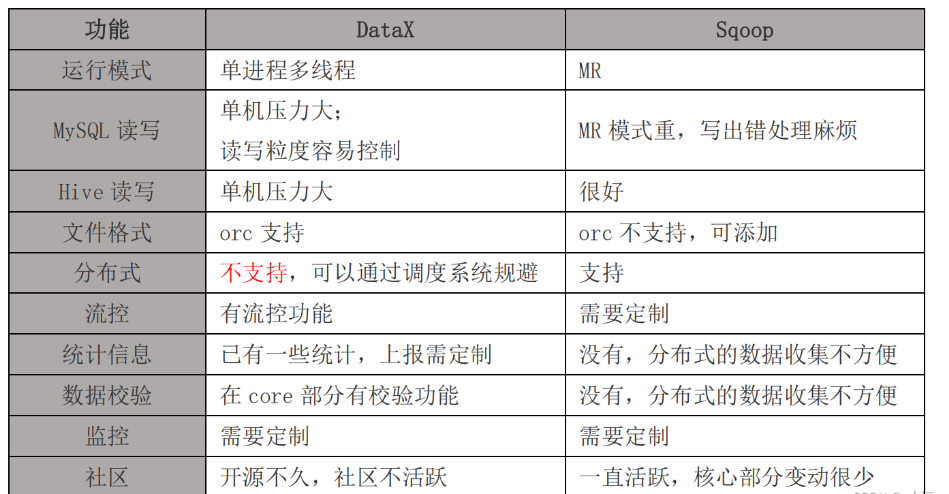
雖然說DataX是單機版壓力大,但可以通過手工排程系統佈置多個節點分開設定來實現類似多臺分散式處理,提高處理能力。
框架設計
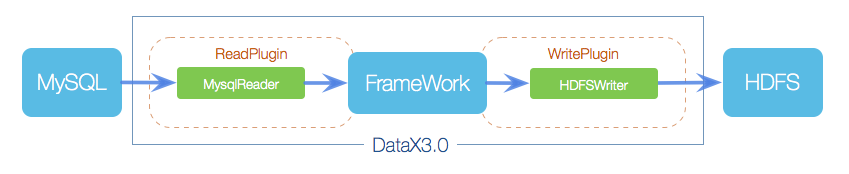
DataX框架設計也比較簡單,與其他資料採集框架如Flume相似,採用Framework + plugin架構構建;將資料來源讀取和寫入抽象成為Reader/Writer外掛,納入到整個同步框架中。
- Reader:為資料採集模組,負責採集資料來源的資料,將資料傳送給Framework。
- Writer:為資料寫入模組,負責不斷向Framework取資料,並將資料寫入到目的端。
- Framework:用於連線reader和writer,作為兩者的資料傳輸通道,並處理緩衝,流控,並行,資料轉換等核心技術問題。
支援外掛
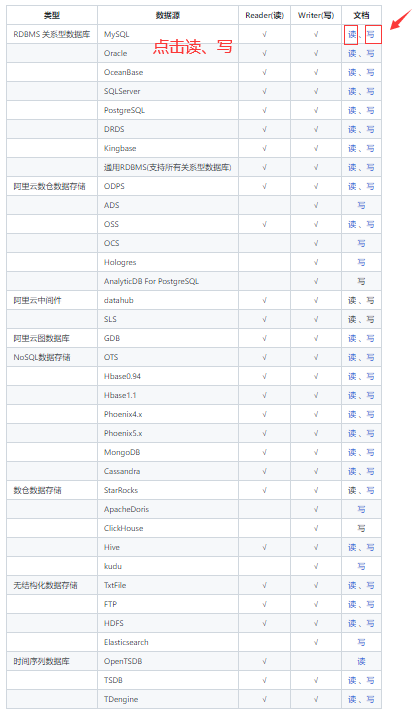
DataX目前已經有了比較全面的外掛體系,主流的RDBMS資料庫、NOSQL、巨量資料、時序資料庫等都已經接入;DataX Framework提供了簡單的介面與外掛互動,提供簡單的外掛接入機制,只需要任意加上一種外掛,就能無縫對接其他資料來源,具體資料來源使用說明根據需要點選讀或寫檢視使用詳細介紹。下面支援型別就在DataX GitHub主頁READERME上。
核心架構
DataX 支援單機多執行緒模式完成同步作業執行,這裡以一個DataX作業生命週期的時序圖,從整體架構設計非常簡要說明DataX各個模組相互關係。
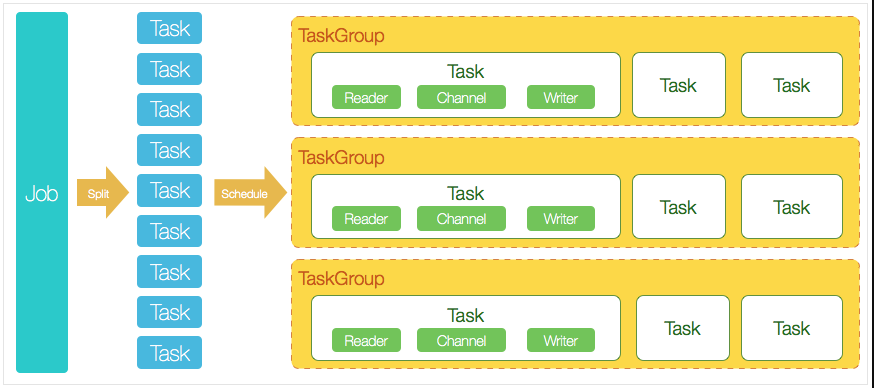
核心模組介紹:
- DataX中完成單個資料同步的作業稱之為Job,DataX接受到一個Job之後,將啟動一個程序來完成整個作業同步過程。DataX Job模組是單個作業的中樞管理節點,承擔了資料清理、子任務切分(將單一作業計算轉化為多個子Task)、TaskGroup管理等功能。
- DataX Job啟動後,會根據不同的源端切分策略,將Job切分成多個小的Task(子任務),以便於並行執行。Task便是DataX作業的最小單元,每一個Task都會負責一部分資料的同步工作。
- 切分多個Task之後,DataX Job會呼叫Scheduler模組,根據設定的並行資料量,將拆分成的Task重新組合,組裝成TaskGroup(任務組)。每一個TaskGroup負責以一定的並行執行完畢分配好的所有Task,預設單個任務組的並行數量為5。
- 每一個Task都由TaskGroup負責啟動,Task啟動後,會固定啟動Reader—>Channel—>Writer的執行緒來完成任務同步工作。
- DataX作業執行起來之後, Job監控並等待多個TaskGroup模組任務完成,等待所有TaskGroup任務完成後Job成功退出。否則,異常退出,程序退出值非0。
DataX排程流程拿一個舉例,比如使用者提交了一個DataX作業並設定了20個並行,目的是將一個100張分表的mysql資料同步到odps裡面。 DataX的排程決策思路是:
- DataXJob根據分庫分表切分成了100個Task。
- 根據20個並行,DataX計算共需要分配4個TaskGroup。
- 4個TaskGroup平分切分好的100個Task,每一個TaskGroup負責以5個並行共計執行25個Task。
核心優勢
- 可靠的資料質量監控
- 完美解決資料傳輸個別型別失真問題:支援所有的強資料型別,每一種外掛都有自己的資料型別轉換策略,讓資料可以完整無失真的傳輸到目的端。
- 提供作業全鏈路的流量、資料量執行時監控:DataX執行過程中可以將作業本身狀態、資料流量、資料速度、執行進度等資訊進行全面的展示,可以實時瞭解作業狀態;並可在作業執行過程中智慧判斷源端和目的端的速度對比情況,給予更多效能排查資訊。
- 提供髒資料探測:在大量資料的傳輸過程中,必定會由於各種原因導致很多資料傳輸報錯(比如型別轉換錯誤),這種資料DataX認為就是髒資料。DataX目前可以實現髒資料精確過濾、識別、採集、展示,提供多種的髒資料處理模式,準確把控資料質量大關。
- 豐富的資料轉換功能
- DataX作為一個服務於巨量資料的ETL工具,除了提供資料快照搬遷功能之外,還提供了豐富資料轉換的功能,讓資料在傳輸過程中可以輕鬆完成資料脫敏,補全,過濾等資料轉換功能,另外還提供了自動groovy函數,讓使用者自定義轉換函數。詳情請看DataX3的transformer詳細介紹。
- 精準的速度控制
- DataX提供了包括通道(並行)、記錄流、位元組流三種流控模式,可以隨意控制作業速度,讓作業在庫可以承受的範圍內達到最佳的同步速度。
- 強勁的同步效能
- DataX每一種讀外掛都有一種或多種切分策略,都能將作業合理切分成多個Task並行執行,單機多執行緒執行模型可以讓DataX速度隨並行成線性增長。在源端和目的端效能都足夠的情況下,單個作業一定可以打滿網路卡;效能測試相關詳情可以參照每單個資料來源的詳細介紹。
- 健壯的容錯機制
- DataX3可以做到執行緒級別、程序級別(暫時未開放)、作業級別多層次區域性/全域性的重試,保證使用者的作業穩定執行。
- 執行緒內部重試:DataX的核心外掛都經過全盤review,不同的網路互動方式都有不同的重試策略。
- 執行緒級別重試:目前DataX已經可以實現TaskFailover,針對於中間失敗的Task,DataX框架可以做到整個Task級別的重新排程。
- DataX3可以做到執行緒級別、程序級別(暫時未開放)、作業級別多層次區域性/全域性的重試,保證使用者的作業穩定執行。
- 極簡的使用體驗
- 易用:下載即可用,支援linux和windows,只需要短短几步驟就可以完成資料的傳輸。
- 詳細:DataX在執行紀錄檔中列印了大量資訊,其中包括傳輸速度,Reader、Writer效能,程序CPU,JVM和GC情況等等。
- 傳輸過程中列印傳輸速度、進度等。
- 傳輸過程中會列印程序相關的CPU、JVM等
- 在任務結束之後,列印總體執行情況
部署
基礎環境
- linux
- JDK(1.8以上,推薦1.8,最好也使用1.8,jdk11有些場景如hdfs會報錯)
- Python(2或3都可以)
- Apache Maven 3.x(如果需要原始碼編譯安裝)
安裝
# 下載最新版本datax_v202210的datax
wget https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz
# 解壓檔案
tar -xvf datax.tar.gz
# 進入根目錄
cd datax/
# 自檢指令碼
python ./bin/datax.py ./job/job.json
從stream讀取資料並列印到控制檯
建立json格式作業的組態檔,可以通過檢視設定模板範例
python bin/datax.py -r streamreader -w streamwriter
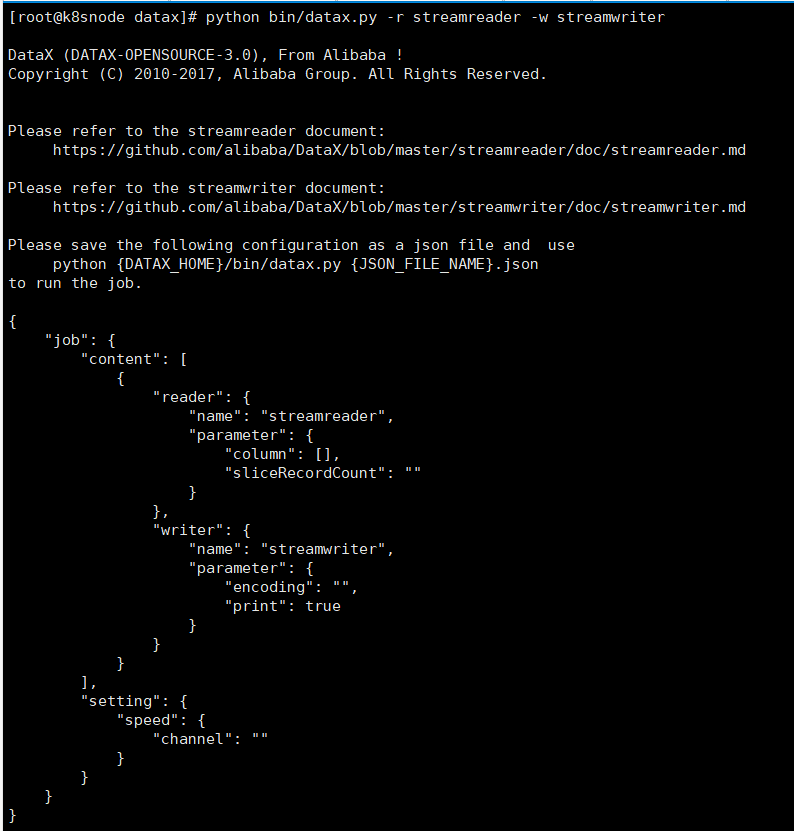
在job目錄下建立stream2stream.json,vim stream2stream.json
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [
{
"type": "long",
"value": "10"
},
{
"type": "string",
"value": "hello,welcome to DataX"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "UTF-8",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": 5
}
}
}
}
# 執行job
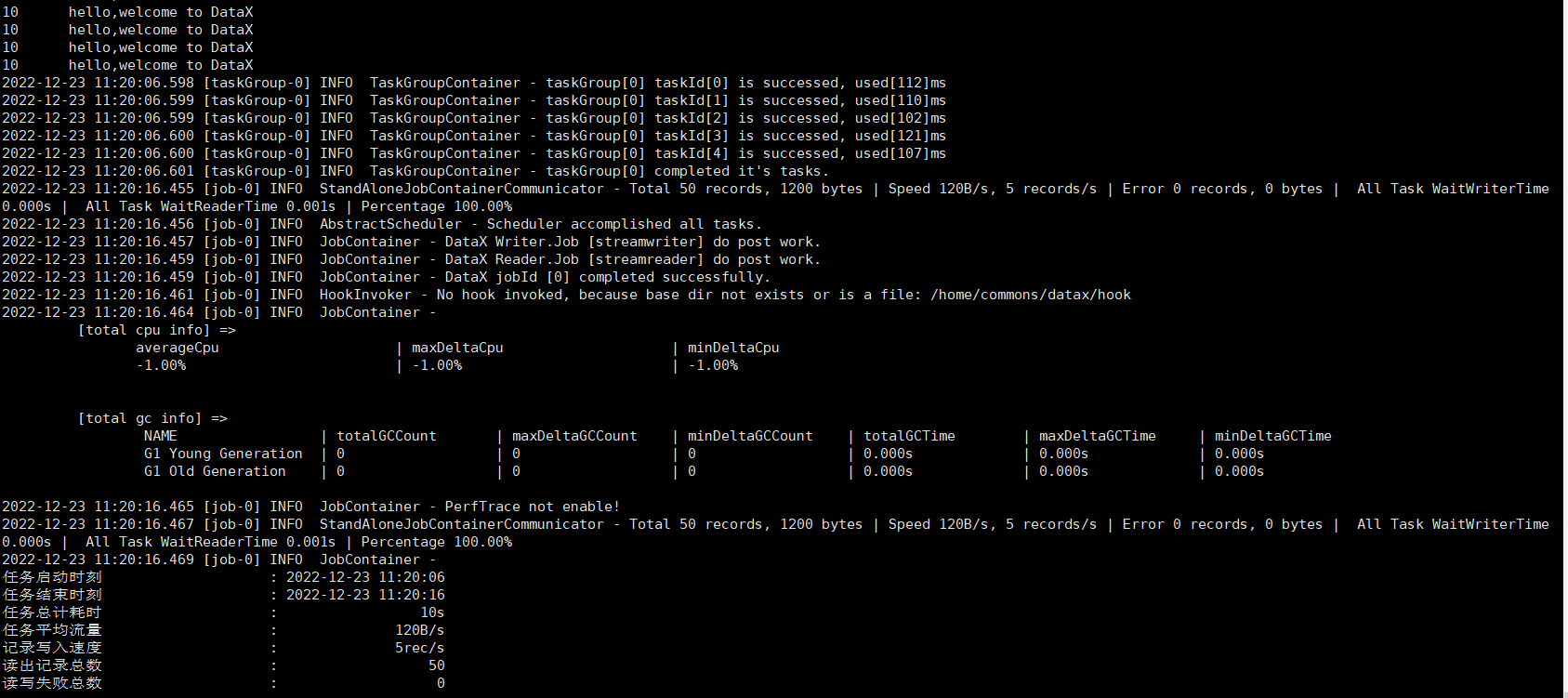
python bin/datax.py job/stream2stream.json
讀取MySQL寫入HDFS
可以通過GitHub找到支援資料通道並通過查閱讀、寫相關檔案,非常詳細,不僅包含實現原理、功能說明、約束限制,還對每一種資料通道提供了效能測試報告,可見DataX是把效能做到了極致。引數的說明
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-gtc3fCRv-1671803026649)(image-20221223135319256.png)]
需要同步資料表為test資料庫的student表

在job目錄下建立mysql2hdfs.json,vim job/mysql2hdfs.json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"name",
"age"
],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://hadoop3:3308/test"],
"table": ["student"]
}
],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "INT"
},
{
"name": "name",
"type": "STRING"
},
{
"name": "age",
"type": "INT"
}
],
"defaultFS": "hdfs://hadoop1:9000",
"fieldDelimiter": "\t",
"fileName": "student.txt",
"fileType": "text",
"path": "/",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
# 執行job
python bin/datax.py job/mysql2hdfs.json
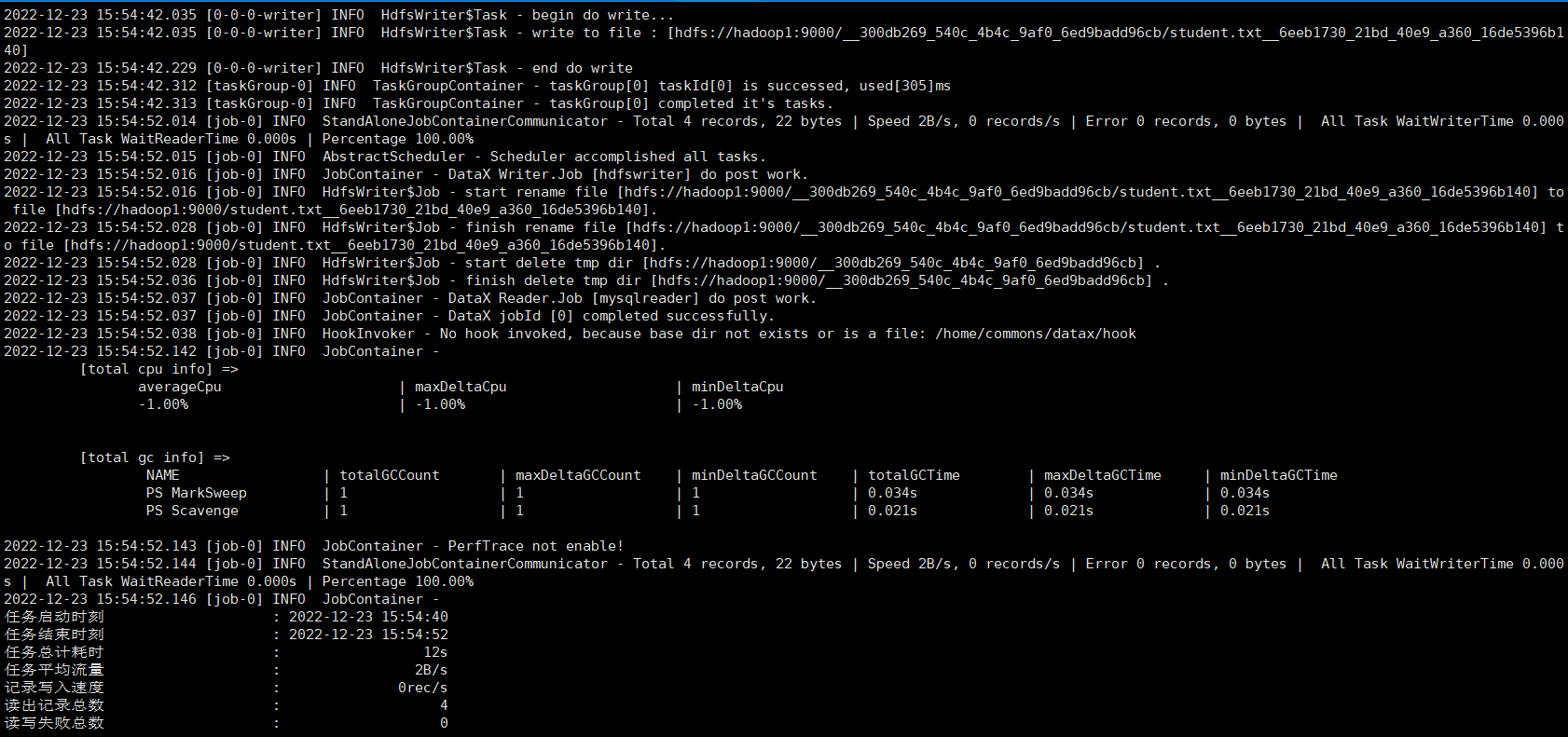
從控制檯的紀錄檔列印可以看到這個job寫入hdfs時先寫入臨時檔案,全部成功則修改檔名和路徑;如果個別失敗則整個job失敗,刪除臨時路徑。檢視hdfs上可以看到檔案已經寫入成功,並且固定加了一串字尾
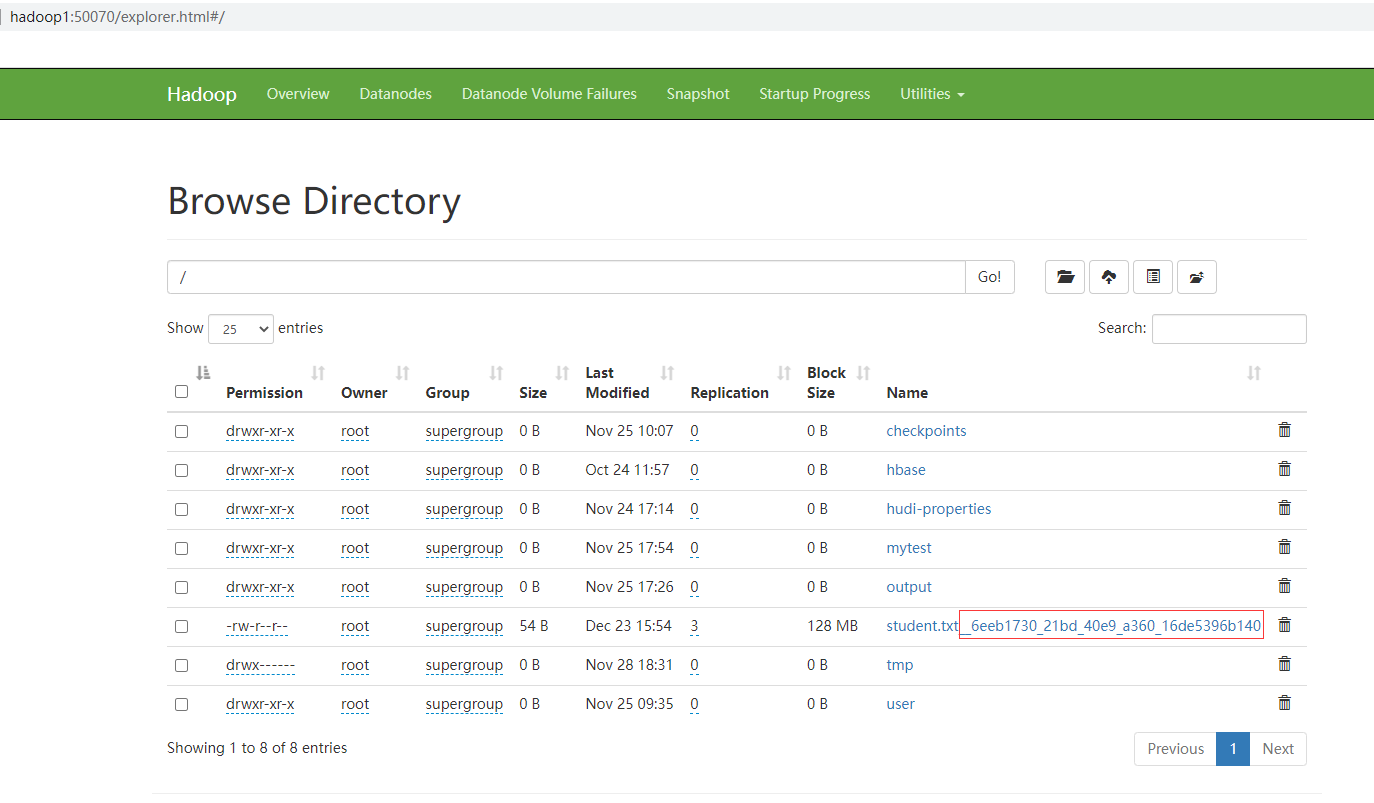
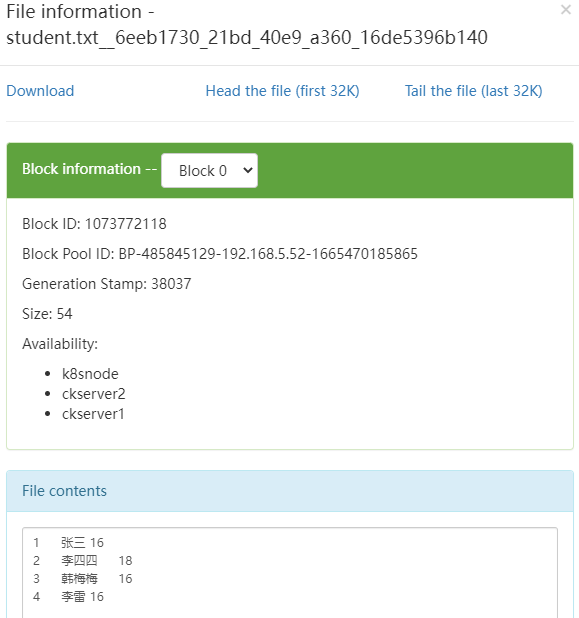
點選檔案檢視內容和間隔符也是正確的
如果是HA模式可以hadoopConfig裡設定
"hadoopConfig":{
"dfs.nameservices": "testDfs",
"dfs.ha.namenodes.testDfs": "namenode1,namenode2",
"dfs.namenode.rpc-address.aliDfs.namenode1": "",
"dfs.namenode.rpc-address.aliDfs.namenode2": "",
"dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
}
讀取HDFS寫入MySQL
建立一張同樣表結構的student1表,在job目錄下建立hdfs2mysql.json,vim job/hdfs2mysql.json
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"column": ["*"],
"defaultFS": "hdfs://hadoop1:9000",
"encoding": "UTF-8",
"fieldDelimiter": "\t",
"fileType": "text",
"path": "/student.txt__6eeb1730_21bd_40e9_a360_16de5396b140"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name",
"age"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://hadoop3:3308/test?useUnicode=true&characterEncoding=gbk",
"table": ["student1"]
}
],
"password": "123456",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
# 由於我的mysql是8,因此需要將plugin/writer/mysqlwriter/libs的mysql-connector-java-5.1.47.jar替換為高版本,這裡就直接使用mysql-connector-java-8.0.29.jar
rm plugin/writer/mysqlwriter/libs/mysql-connector-java-5.1.47.jar
cp mysql-connector-java-8.0.29.jar plugin/writer/mysqlwriter/libs/
# 執行job
python bin/datax.py job/hdfs2mysql.json
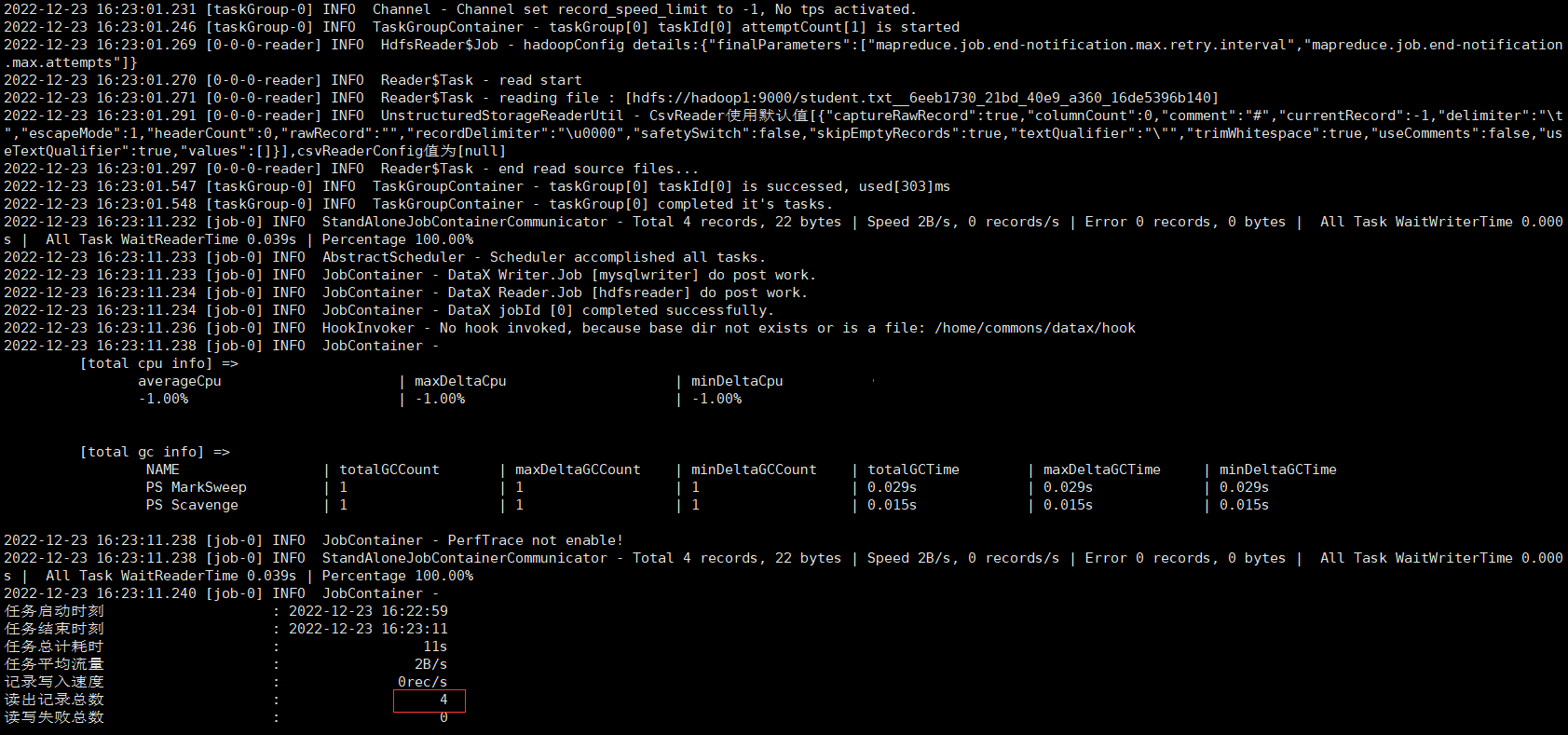
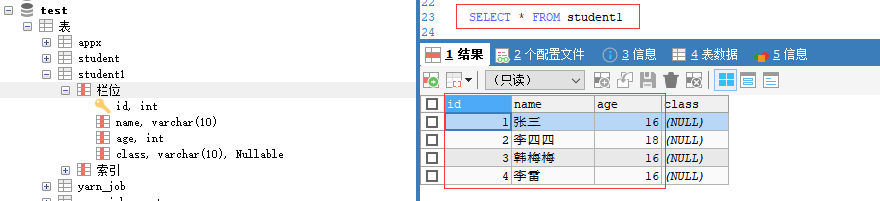
檢視student1表已經有4條包含指定3個欄位的資料
執行流程
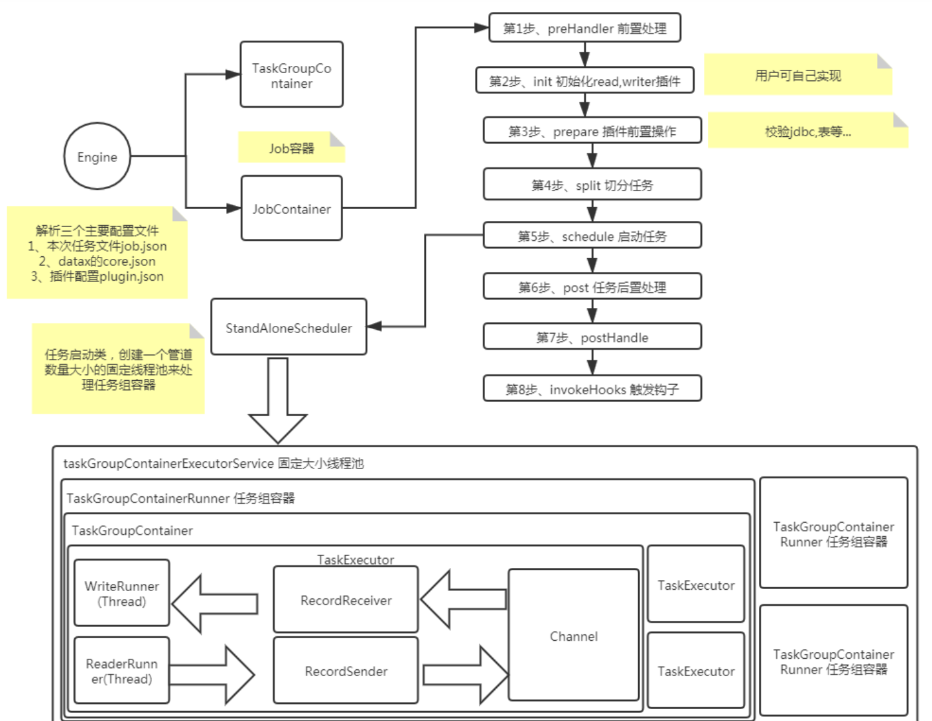
- 解析設定,包括job.json、core.json、plugin.json三個設定
- 設定jobId到configuration當中
- 啟動Engine,通過Engine.start()進入啟動程式
- 設定RUNTIME_MODE configuration當中
- 通過JobContainer的start()方法啟動
- 依次執行job的preHandler()、init()、prepare()、split()、schedule()、post()、postHandle()等方法。
- init()方法涉及到根據configuration來初始化reader和writer外掛,這裡涉及到jar包熱載入以及呼叫外掛init()操作方法,同時設定reader和writer的configuration資訊
- prepare()方法涉及到初始化reader和writer外掛的初始化,通過呼叫外掛的prepare()方法實現,每個外掛都有自己的jarLoader,通過整合URLClassloader實現而來
- split()方法通過adjustChannelNumber()方法調整channel個數,同時執行reader和writer最細粒度的切分,需要注意的是,writer的切分結果要參照reader的切分結果,達到切分後數目相等,才能滿足1:1的通道模型
- channel的計數主要是根據byte和record的限速來實現的,在split()的函數中第一步就是計算channel的大小
- split()方法reader外掛會根據channel的值進行拆分,但是有些reader外掛可能不會參考channel的值,writer外掛會完全根據reader的外掛1:1進行返回
- split()方法內部的mergeReaderAndWriterTaskConfigs()負責合併reader、writer、以及transformer三者關係,生成task的設定,並且重寫job.content的設定
- schedule()方法根據split()拆分生成的task設定分配生成taskGroup物件,根據task的數量和單個taskGroup支援的task數量進行設定,兩者相除就可以得出taskGroup的數量
- schdule()內部通過AbstractScheduler的schedule()執行,繼續執行startAllTaskGroup()方法建立所有的TaskGroupContainer組織相關的task,TaskGroupContainerRunner負責執行TaskGroupContainer執行分配的task。scheduler的具體實現類為ProcessInnerScheduler。
- taskGroupContainerExecutorService啟動固定的執行緒池用以執行TaskGroupContainerRunner物件,TaskGroupContainerRunner的run()方法呼叫taskGroupContainer.start()方法,針對每個channel建立一個TaskExecutor,通過taskExecutor.doStart()啟動任務。
- 本人部落格網站IT小神 www.itxiaoshen.com