一階段目標檢測網路-RetinaNet 詳解
摘要
Retinanet 是作者 Tsung-Yi Lin 和 Kaiming He(四作) 於 2018 年發表的論文 Focal Loss for Dense Object Detection.
作者深入分析了極度不平衡的正負(前景背景)樣本比例導致 one-stage 檢測器精度低於 two-stage 檢測器,基於上述分析,提出了一種簡單但是非常實用的 Focal Loss 焦點損失函數,並且 Loss 設計思想可以推廣到其他領域,同時針對目標檢測領域特定問題,設計了 RetinaNet 網路,結合 Focal Loss 使得 one-stage 檢測器在精度上能夠達到乃至超過 two-stage 檢測器。
1,引言
作者認為一階段檢測器的精度不能和兩階段檢測相比的原因主要在於,訓練過程中的類別不平衡,由此提出了一種新的損失函數-Focal Loss。
R-CNN(Fast RCNN) 類似的檢測器之所以能解決類別不平衡問題,是因為兩階段級聯結構和啟發式取樣。提取 proposal 階段(例如,選擇性搜尋、EdgeBoxes、DeepMask、RPN)很快的將候選物件位置的數量縮小到一個小數目(例如,1-2k),過濾掉大多數背景樣本(其實就是篩選 anchor 數量)。在第二個分類階段,執行啟發式取樣(sampling heuristics),例如固定的前景背景比(1:3),或線上難樣本挖掘(OHEM),以保持前景和背景之間的平衡。
相比之下,單級檢測器必須處理在影象中定期取樣的一組更大的候選物件位置。實際上,這通常相當於列舉 ∼100k 個位置,這些位置密集地覆蓋空間位置、尺度和縱橫。雖然也可以應用類似的啟發式取樣方法,但效率低下,因為訓練過程仍然由易於分類的背景樣本主導。
2,相關工作
Two-stage Detectors: 與之前使用兩階段的分類器生成 proposal 不同,Faster RCNN 模型的 RPN 使用單個折積就可以生成 proposal。
One-stage Detectors:最近的一些研究表明,只需要降低輸入影象解析度和 proposal 數量,兩階段檢測器速度就可以變得更快。但是,對於一階段檢測器,即使提高模型計算量,其最後的精度也落後於兩階段方法[17]。同時,作者強調,Reinanet 達到很好的結果的原因不在於網路結構的創新,而在於損失函數的創新。
論文 [17] Speed/accuracy trade-offs for modern convolutional object detectors(注重實驗). 但是,從這幾年看,一階段檢測器也可以達到很高的精度,甚至超過兩階段檢測器,這幾年的一階段檢測和兩階段檢測器有相互融合的趨勢了。
Class Imbalance: 早期的目標檢測器 SSD 等在訓練過程中會面臨嚴重的類別不平衡(class imbalance)的問題,即正樣本太少,負樣本太多,這會導致兩個問題:
- 訓練效率低下:大多數候選區域都是容易分類的負樣本,並沒有提供多少有用的學習訊號。
- 模型退化:易分類的負樣本太多會壓倒訓練,導致模型退化。
通常的解決方案是執行某種形式的難負樣本挖掘,如在訓練時進行難負樣本取樣或更復雜的取樣/重新稱重方案。相比之下,Focla Loss 自然地處理了單級檢測器所面臨的類別不平衡,並且允許在所有範例上有效地訓練,而不需要取樣,也不需要容易的負樣本來壓倒損失和計算的梯度。
Robust Estimation: 人們對設計穩健的損失函數(例如 Huber loss)很感興趣,該函數通過降低具有大錯誤的範例(硬範例)的損失來減少對總損失的貢獻。相反, Focal Loss 對容易樣本(inliers)減少權重來解決(address)類別不平衡問題(class imbalance),這意味著即使容易樣本數量大,但是其對總的損失函數貢獻也很小。換句話說,Focal Loss 與魯棒損失相反,它側重於訓練稀疏的難樣本。
3,網路架構
retinanet 的網路架構圖如下所示。

3.1,Backbone
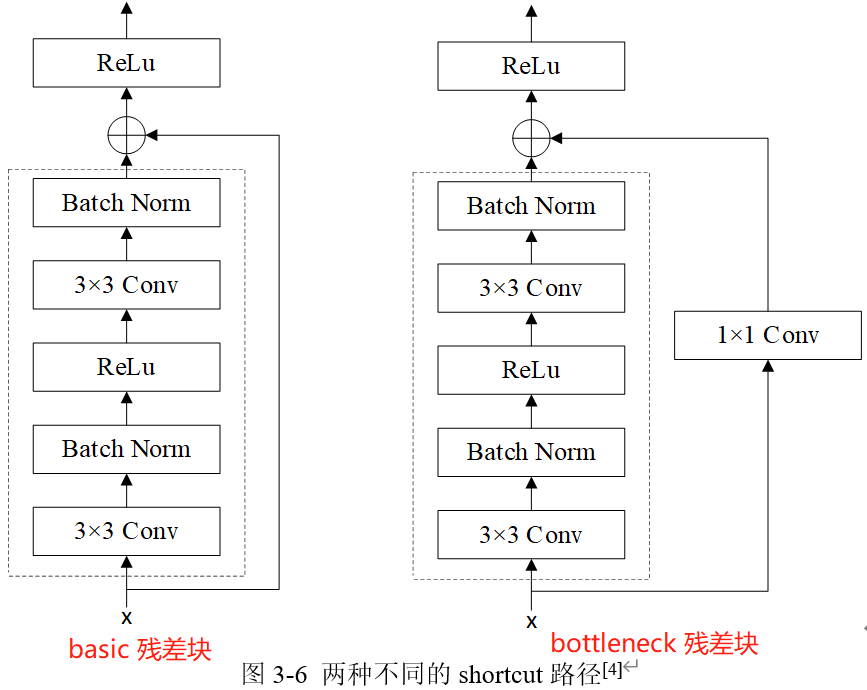
Retinanet 的 Backbone 為 ResNet 網路,ResNet 一般從 18 層到 152 層(甚至更多)不等,主要區別在於採用的殘差單元/模組不同或者堆疊殘差單元/模組的數量和比例不同,論文主要使用 ResNet50。
兩種殘差塊結構如下圖所示,ResNet50 及更深的 ResNet 網路使用的是 bottleneck 殘差塊。
3.2,Neck
Neck 模組即為 FPN 網路結構。FPN 模組接收 c3, c4, c5 三個特徵圖,輸出 P2-P7 五個特徵圖,通道數都是 256, stride 為 (8,16,32,64,128),其中大 stride (特徵圖小)用於檢測大物體,小 stride (特徵圖大)用於檢測小物體。P6 和 P7 目的是提供一個大感受野強語意的特徵圖,有利於大物體和超大物體檢測。注意:在 RetinaNet 的 FPN 模組中只包括折積,不包括 BN 和 ReLU。
3.3,Head
Head 即預測頭網路。
YOLOv3 的 neck 輸出 3 個分支,即輸出 3 個特徵圖, head 模組只有一個分支,由折積層組成,該折積層完成目標分類和位置迴歸的功能。總的來說,YOLOv3 網路的 3 個特徵圖有 3 個預測分支,分別預測 3 個框,也就是分別預測大、中、小目標。
Retinanet 的 neck 輸出 5 個分支,即輸出 5 個特徵圖。head 模組包括分類和位置檢測兩個分支,每個分支都包括 4 個折積層,但是 head 模組的這兩個分支之間引數不共用,分類 Head 輸出通道是 A*K,A 是類別數;檢測 head 輸出通道是 4*K, K 是 anchor 個數, 雖然每個 Head 的分類和迴歸分支權重不共用,但是 5 個輸出特徵圖的 Head 模組權重是共用的。
4,Focal Loss
Focal Loss 是在二分類問題的交叉熵(CE)損失函數的基礎上引入的,所以需要先學習下交叉熵損失的定義。
4.1,Cross Entropy
可額外閱讀文章 理解交叉熵損失函數。
在深度學習中我們常使用交叉熵來作為分類任務中訓練資料分佈和模型預測結果分佈間的代價函數。對於同一個離散型隨機變數 \(\textrm{x}\) 有兩個單獨的概率分佈 \(P(x)\) 和 \(Q(x)\),其交叉熵定義為:
P 表示真實分佈, Q 表示預測分佈。
但在實際計算中,我們通常不這樣寫,因為不直觀。在深度學習中,以二分類問題為例,其交叉熵損失(CE)函數如下:
其中 \(p\) 表示當預測樣本等於 \(1\) 的概率,則 \(1-p\) 表示樣本等於 \(0\) 的預測概率。因為是二分類,所以樣本標籤 \(y\) 取值為 \(\{1,0\}\),上式可縮寫至如下:
為了方便,用 \(p_t\) 代表 \(p\),\(p_t\) 定義如下:
則\((3)\)式可寫成:
前面的交叉熵損失計算都是針對單個樣本的,對於所有樣本,二分類的交叉熵損失計算如下:
其中 \(m\) 為正樣本個數,\(n\) 為負樣本個數,\(N\) 為樣本總數,\(m+n=N\)。當樣本類別不平衡時,損失函數 \(L\) 的分佈也會發生傾斜,如 \(m \ll n\) 時,負樣本的損失會在總損失占主導地位。又因為損失函數的傾斜,模型訓練過程中也會傾向於樣本多的類別,造成模型對少樣本類別的效能較差。
再衍生以下,對於所有樣本,多分類的交叉熵損失計算如下:
其中,\(M\) 表示類別數量,\(y_{ic}\) 是符號函數,如果樣本 \(i\) 的真實類別等於 \(c\) 取值 1,否則取值 0; \(p_{ic}\) 表示樣本 \(i\) 預測為類別 \(c\) 的概率。
對於多分類問題,交叉熵損失一般會結合 softmax 啟用一起實現,PyTorch 程式碼如下,程式碼出自這裡。
import numpy as np
# 交叉熵損失
class CrossEntropyLoss():
"""
對最後一層的神經元輸出計算交叉熵損失
"""
def __init__(self):
self.X = None
self.labels = None
def __call__(self, X, labels):
"""
引數:
X: 模型最後fc層輸出
labels: one hot標註,shape=(batch_size, num_class)
"""
self.X = X
self.labels = labels
return self.forward(self.X)
def forward(self, X):
"""
計算交叉熵損失
引數:
X:最後一層神經元輸出,shape=(batch_size, C)
label:資料onr-hot標註,shape=(batch_size, C)
return:
交叉熵loss
"""
self.softmax_x = self.softmax(X)
log_softmax = self.log_softmax(self.softmax_x)
cross_entropy_loss = np.sum(-(self.labels * log_softmax), axis=1).mean()
return cross_entropy_loss
def backward(self):
grad_x = (self.softmax_x - self.labels) # 返回的梯度需要除以batch_size
return grad_x / self.X.shape[0]
def log_softmax(self, softmax_x):
"""
引數:
softmax_x, 在經過softmax處理過的X
return:
log_softmax處理後的結果shape = (m, C)
"""
return np.log(softmax_x + 1e-5)
def softmax(self, X):
"""
根據輸入,返回softmax
程式碼利用softmax函數的性質: softmax(x) = softmax(x + c)
"""
batch_size = X.shape[0]
# axis=1 表示在二維陣列中沿著橫軸進行取最大值的操作
max_value = X.max(axis=1)
#每一行減去自己本行最大的數位,防止取指數後出現inf,性質:softmax(x) = softmax(x + c)
# 一定要新定義變數,不要用-=,否則會改變輸入X。因為在呼叫計算損失時,多次用到了softmax,input不能改變
tmp = X - max_value.reshape(batch_size, 1)
# 對每個數取指數
exp_input = np.exp(tmp) # shape=(m, n)
# 求出每一行的和
exp_sum = exp_input.sum(axis=1, keepdims=True) # shape=(m, 1)
return exp_input / exp_sum
4.2,Balanced Cross Entropy
對於正負樣本不平衡的問題,較為普遍的做法是引入 \(\alpha \in(0,1)\) 引數來解決,上面公式重寫如下:
對於所有樣本,二分類的平衡交叉熵損失函數如下:
其中 \(\frac{\alpha}{1-\alpha} = \frac{n}{m}\),即 \(\alpha\) 引數的值是根據正負樣本分佈比例來決定的,
4.3,Focal Loss Definition
雖然 \(\alpha\) 引數平衡了正負樣本(positive/negative examples),但是它並不能區分難易樣本(easy/hard examples),而實際上,目標檢測中大量的候選目標都是易分樣本。這些樣本的損失很低,但是由於難易樣本數量極不平衡,易分樣本的數量相對來講太多,最終主導了總的損失。而本文的作者認為,易分樣本(即,置信度高的樣本)對模型的提升效果非常小,模型應該主要關注與那些難分樣本(這個假設是有問題的,是 GHM 的主要改進物件)
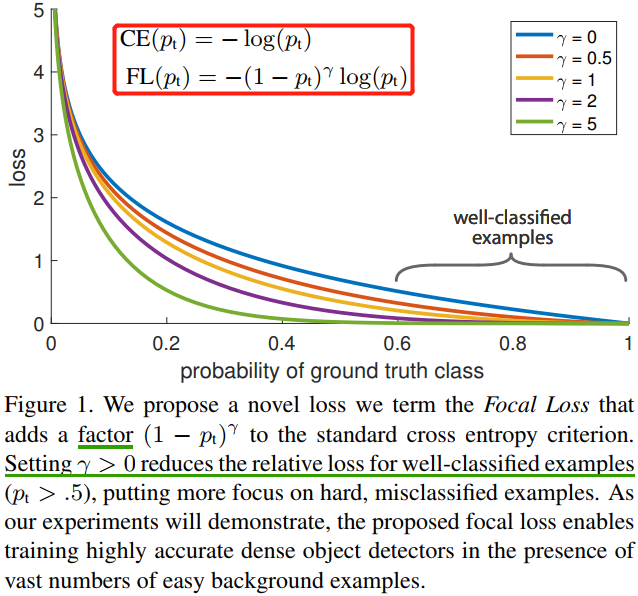
Focal Loss 作者建議在交叉熵損失函數上加上一個調整因子(modulating factor)\((1-p_t)^\gamma\),把高置信度 \(p\)(易分樣本)樣本的損失降低一些。Focal Loss 定義如下:
Focal Loss 有兩個性質:
- 當樣本被錯誤分類且 \(p_t\) 值較小時,調變因子接近於
1,loss幾乎不受影響;當 \(p_t\) 接近於1,調質因子(factor)也接近於0,容易分類樣本的損失被減少了權重,整體而言,相當於增加了分類不準確樣本在損失函數中的權重。 - \(\gamma\) 引數平滑地調整容易樣本的權重下降率,當 \(\gamma = 0\) 時,
Focal Loss等同於CE Loss。 \(\gamma\) 在增加,調變因子的作用也就增加,實驗證明 \(\gamma = 2\) 時,模型效果最好。
直觀地說,調變因子減少了簡單樣本的損失貢獻,並擴大了樣本獲得低損失的範圍。例如,當\(\gamma = 2\) 時,與 \(CE\) 相比,分類為 \(p_t = 0.9\) 的樣本的損耗將降低 100 倍,而當 \(p_t = 0.968\) 時,其損耗將降低 1000 倍。這反過來又增加了錯誤分類樣本的重要性(對於 \(pt≤0.5\) 和 \(\gamma = 2\),其損失最多減少 4 倍)。在訓練過程關注物件的排序為正難 > 負難 > 正易 > 負易。

在實踐中,我們常採用帶 \(\alpha\) 的 Focal Loss:
作者在實驗中採用這種形式,發現它比非 \(\alpha\) 平衡形式(non-\(\alpha\)-balanced)的精確度稍有提高。實驗表明 \(\gamma\) 取 2,\(\alpha\) 取 0.25 的時候效果最佳。
網上有各種版本的 Focal Loss 實現程式碼,大多都是基於某個深度學習框架實現的,如 Pytorch和 TensorFlow,我選取了一個較為清晰的通用版本程式碼作為參考,程式碼來自 這裡。
後續有必要自己實現以下,有時間還要去看看
Caffe的實現。這裡的 Focal Loss 程式碼與後文不同,這裡只是純粹的用於分類的 Focal_loss 程式碼,不包含 BBox 的編碼過程。
# -*- coding: utf-8 -*-
# @Author : LG
from torch import nn
import torch
from torch.nn import functional as F
class focal_loss(nn.Module):
def __init__(self, alpha=0.25, gamma=2, num_classes = 3, size_average=True):
"""
focal_loss損失函數, -α(1-yi)**γ *ce_loss(xi,yi)
步驟詳細的實現了 focal_loss損失函數.
:param alpha: 阿爾法α,類別權重. 當α是列表時,為各類別權重,當α為常數時,類別權重為[α, 1-α, 1-α, ....],常用於 目標檢測演演算法中抑制背景類 , retainnet中設定為0.25
:param gamma: 伽馬γ,難易樣本調節引數. retainnet中設定為2
:param num_classes: 類別數量
:param size_average: 損失計算方式,預設取均值
"""
super(focal_loss,self).__init__()
self.size_average = size_average
if isinstance(alpha,list):
assert len(alpha)==num_classes # α可以以list方式輸入,size:[num_classes] 用於對不同類別精細地賦予權重
print(" --- Focal_loss alpha = {}, 將對每一類權重進行精細化賦值 --- ".format(alpha))
self.alpha = torch.Tensor(alpha)
else:
assert alpha<1 #如果α為一個常數,則降低第一類的影響,在目標檢測中為第一類
print(" --- Focal_loss alpha = {} ,將對背景類進行衰減,請在目標檢測任務中使用 --- ".format(alpha))
self.alpha = torch.zeros(num_classes)
self.alpha[0] += alpha
self.alpha[1:] += (1-alpha) # α 最終為 [ α, 1-α, 1-α, 1-α, 1-α, ...] size:[num_classes]
self.gamma = gamma
def forward(self, preds, labels):
"""
focal_loss損失計算
:param preds: 預測類別. size:[B,N,C] or [B,C] 分別對應與檢測與分類任務, B 批次, N檢測框數, C類別數
:param labels: 實際類別. size:[B,N] or [B],為 one-hot 編碼格式
:return:
"""
# assert preds.dim()==2 and labels.dim()==1
preds = preds.view(-1,preds.size(-1))
self.alpha = self.alpha.to(preds.device)
preds_logsoft = F.log_softmax(preds, dim=1) # log_softmax
preds_softmax = torch.exp(preds_logsoft) # softmax
preds_softmax = preds_softmax.gather(1,labels.view(-1,1))
preds_logsoft = preds_logsoft.gather(1,labels.view(-1,1))
self.alpha = self.alpha.gather(0,labels.view(-1))
loss = -torch.mul(torch.pow((1-preds_softmax), self.gamma), preds_logsoft) # torch.pow((1-preds_softmax), self.gamma) 為focal loss中 (1-pt)**γ
loss = torch.mul(self.alpha, loss.t())
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss
mmdetection 框架給出的 focal loss 程式碼如下(有所刪減):
# This method is only for debugging
def py_sigmoid_focal_loss(pred,
target,
weight=None,
gamma=2.0,
alpha=0.25,
reduction='mean',
avg_factor=None):
"""PyTorch version of `Focal Loss <https://arxiv.org/abs/1708.02002>`_.
Args:
pred (torch.Tensor): The prediction with shape (N, C), C is the
number of classes
target (torch.Tensor): The learning label of the prediction.
weight (torch.Tensor, optional): Sample-wise loss weight.
gamma (float, optional): The gamma for calculating the modulating
factor. Defaults to 2.0.
alpha (float, optional): A balanced form for Focal Loss.
Defaults to 0.25.
reduction (str, optional): The method used to reduce the loss into
a scalar. Defaults to 'mean'.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
"""
pred_sigmoid = pred.sigmoid()
target = target.type_as(pred)
pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
focal_weight = (alpha * target + (1 - alpha) *
(1 - target)) * pt.pow(gamma)
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction='none') * focal_weigh
return loss
5,程式碼解讀
程式碼來源這裡。
5.1,Backbone
RetinaNet 演演算法採用了 ResNet50 作為 Backbone, 並且考慮到整個目標檢測網路比較大,前面部分網路沒有進行訓練,BN 也不會進行引數更新(來自 OpenMMLab 的經驗)。
ResNet 不僅提出了殘差結構,而且還提出了骨架網路設計正規化即 stem + n stage+ cls head,對於 ResNet 而言,其實際 forward 流程是 stem -> 4 個 stage -> 分類 head,stem 的輸出 stride 是 4,而 4 個 stage 的輸出 stride 是 4,8,16,32。
stride表示模型的下取樣率,假設圖片輸入是320x320,stride=10,那麼輸出特徵圖大小是32x32,假設每個位置anchor是9個,那麼這個輸出特徵圖就一共有32x32x9個anchor。
5.2,Neck
ResNet 輸出 4 個不同尺度的特徵圖(c2,c3,c4,c5),stride 分別是(4,8,16,32),通道數為(256,512,1024,2048)。
Neck 使用的是 FPN 網路,且輸入是 3 個來自 ResNet 輸出的特徵圖(c3,c4,c5),並輸出 5 個特徵圖(p3,p4,p5,p6,p7),額外輸出的 2 個特徵圖的來源是骨架網路輸出,而不是 FPN 層本身輸出又作為後面層的輸入,並且 FPN 網路輸出的 5 個特徵圖通道數都是 256。值得注意的是,Neck 模組輸出特徵圖的大小是由 Backbone 決定的,即輸出的 stride 列表由 Backbone 確定。
FPN 結構的程式碼如下。
class PyramidFeatures(nn.Module):
def __init__(self, C3_size, C4_size, C5_size, feature_size=256):
super(PyramidFeatures, self).__init__()
# upsample C5 to get P5 from the FPN paper
self.P5_1 = nn.Conv2d(C5_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P5_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P5_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# add P5 elementwise to C4
self.P4_1 = nn.Conv2d(C4_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P4_upsampled = nn.Upsample(scale_factor=2, mode='nearest')
self.P4_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# add P4 elementwise to C3
self.P3_1 = nn.Conv2d(C3_size, feature_size, kernel_size=1, stride=1, padding=0)
self.P3_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=1, padding=1)
# "P6 is obtained via a 3x3 stride-2 conv on C5"
self.P6 = nn.Conv2d(C5_size, feature_size, kernel_size=3, stride=2, padding=1)
# "P7 is computed by applying ReLU followed by a 3x3 stride-2 conv on P6"
self.P7_1 = nn.ReLU()
self.P7_2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, stride=2, padding=1)
def forward(self, inputs):
C3, C4, C5 = inputs
P5_x = self.P5_1(C5)
P5_upsampled_x = self.P5_upsampled(P5_x)
P5_x = self.P5_2(P5_x)
P4_x = self.P4_1(C4)
P4_x = P5_upsampled_x + P4_x
P4_upsampled_x = self.P4_upsampled(P4_x)
P4_x = self.P4_2(P4_x)
P3_x = self.P3_1(C3)
P3_x = P3_x + P4_upsampled_x
P3_x = self.P3_2(P3_x)
P6_x = self.P6(C5)
P7_x = self.P7_1(P6_x)
P7_x = self.P7_2(P7_x)
return [P3_x, P4_x, P5_x, P6_x, P7_x]
5.3,Head
RetinaNet 在特徵提取網路 ResNet-50 和特徵融合網路 FPN 後,對獲得的五張特徵圖 [P3_x, P4_x, P5_x, P6_x, P7_x],通過具有相同權重的框迴歸和分類子網路,獲得所有框位置和類別資訊。
目標邊界框迴歸和分類子網路(head 網路)定義如下:
class RegressionModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, feature_size=256):
super(RegressionModel, self).__init__()
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
# 最後的輸出層輸出通道數為 num_anchors * 4
self.output = nn.Conv2d(feature_size, num_anchors * 4, kernel_size=3, padding=1)
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
# out is B x C x W x H, with C = 4*num_anchors = 4*9
out = out.permute(0, 2, 3, 1)
return out.contiguous().view(out.shape[0], -1, 4)
class ClassificationModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, num_classes=80, prior=0.01, feature_size=256):
super(ClassificationModel, self).__init__()
self.num_classes = num_classes
self.num_anchors = num_anchors
self.conv1 = nn.Conv2d(num_features_in, feature_size, kernel_size=3, padding=1)
self.act1 = nn.ReLU()
self.conv2 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act2 = nn.ReLU()
self.conv3 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act3 = nn.ReLU()
# 最後的輸出層輸出通道數為 num_anchors * num_classes(coco資料集9*80)
self.conv4 = nn.Conv2d(feature_size, feature_size, kernel_size=3, padding=1)
self.act4 = nn.ReLU()
self.output = nn.Conv2d(feature_size, num_anchors * num_classes, kernel_size=3, padding=1)
self.output_act = nn.Sigmoid()
def forward(self, x):
out = self.conv1(x)
out = self.act1(out)
out = self.conv2(out)
out = self.act2(out)
out = self.conv3(out)
out = self.act3(out)
out = self.conv4(out)
out = self.act4(out)
out = self.output(out)
out = self.output_act(out)
# out is B x C x W x H, with C = n_classes + n_anchors
out1 = out.permute(0, 2, 3, 1)
batch_size, width, height, channels = out1.shape
out2 = out1.view(batch_size, width, height, self.num_anchors, self.num_classes)
return out2.contiguous().view(x.shape[0], -1, self.num_classes)
5.4,先驗框Anchor賦值
1,生成各個特徵圖對應原圖大小的所有 Anchors 座標的程式碼如下。
import numpy as np
import torch
import torch.nn as nn
class Anchors(nn.Module):
def __init__(self, pyramid_levels=None, strides=None, sizes=None, ratios=None, scales=None):
super(Anchors, self).__init__()
if pyramid_levels is None:
self.pyramid_levels = [3, 4, 5, 6, 7]
if strides is None:
self.strides = [2 ** x for x in self.pyramid_levels]
if sizes is None:
self.sizes = [2 ** (x + 2) for x in self.pyramid_levels]
if ratios is None:
self.ratios = np.array([0.5, 1, 2])
if scales is None:
self.scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
def forward(self, image):
image_shape = image.shape[2:]
image_shape = np.array(image_shape)
image_shapes = [(image_shape + 2 ** x - 1) // (2 ** x) for x in self.pyramid_levels]
# compute anchors over all pyramid levels
all_anchors = np.zeros((0, 4)).astype(np.float32)
for idx, p in enumerate(self.pyramid_levels):
anchors = generate_anchors(base_size=self.sizes[idx], ratios=self.ratios, scales=self.scales)
shifted_anchors = shift(image_shapes[idx], self.strides[idx], anchors)
all_anchors = np.append(all_anchors, shifted_anchors, axis=0)
all_anchors = np.expand_dims(all_anchors, axis=0)
if torch.cuda.is_available():
return torch.from_numpy(all_anchors.astype(np.float32)).cuda()
else:
return torch.from_numpy(all_anchors.astype(np.float32))
def generate_anchors(base_size=16, ratios=None, scales=None):
"""生成的 `9` 個 `base anchors`
Generate anchor (reference) windows by enumerating aspect ratios X
scales w.r.t. a reference window.
"""
if ratios is None:
ratios = np.array([0.5, 1, 2])
if scales is None:
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
num_anchors = len(ratios) * len(scales)
# initialize output anchors
anchors = np.zeros((num_anchors, 4))
# scale base_size
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T
# compute areas of anchors
areas = anchors[:, 2] * anchors[:, 3]
# correct for ratios
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
# transform from (x_ctr, y_ctr, w, h) -> (x1, y1, x2, y2)
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchors
def shift(shape, stride, anchors):
shift_x = (np.arange(0, shape[1]) + 0.5) * stride
shift_y = (np.arange(0, shape[0]) + 0.5) * stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((
shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel()
)).transpose()
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
A = anchors.shape[0]
K = shifts.shape[0]
all_anchors = (anchors.reshape((1, A, 4)) + shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4))
return all_anchors
shift 函數是將 generate_anchors 函數生成的 9 個 base anchors 按固定長度進行平移,然後和其對應特徵圖的 cell進行對應。經過對每個特徵圖(5 個)都做類似的變換,就能生成全部anchor。具體過程如下圖所示。
anchor 平移圖來源這裡
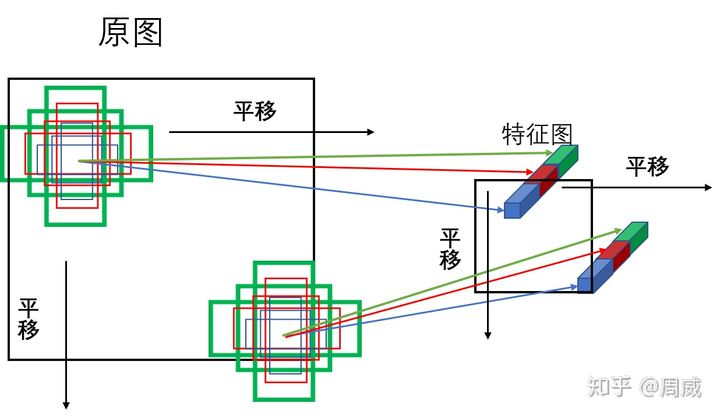
2,計算得到輸出特徵圖上面每個點對應的原圖 anchor 座標輸出特徵圖上面每個點對應的原圖 anchor 座標後,就可以和 gt 資訊計算每個 anchor 的正負樣本屬性。具體過程總結如下:
- 如果 anchor 和所有 gt bbox 的最大 iou 值小於 0.4,那麼該 anchor 就是背景樣本;
- 如果 anchor 和所有 gt bbox 的最大 iou 值大於等於 0.5,那麼該 anchor 就是高質量正樣本;
- 如果 gt bbox 和所有 anchor 的最大 iou 值大於等於 0(可以看出每個 gt bbox 都一定有至少一個 anchor 匹配),那麼該 gt bbox 所對應的 anchor 也是正樣本;
- 其餘樣本全部為忽略樣本即 anchor 和所有 gt bbox 的最大 iou 值處於 [0.4,0.5) 區間的 anchor 為忽略樣本,不計算 loss
5.5,BBox Encoder Decoder
在 anchor-based 演演算法中,為了利用 anchor 資訊進行更快更好的收斂,一般會對 head 輸出的 bbox 分支 4 個值進行編解碼操作,作用有兩個:
- 更好的平衡分類和迴歸分支
loss,以及平衡bbox四個預測值的loss。 - 訓練過程中引入
anchor資訊,加快收斂。 RetinaNet採用的編解碼函數是主流的DeltaXYWHBBoxCoder,在OpenMMlab程式碼中的設定如下:bbox_coder=dict( type='DeltaXYWHBBoxCoder', target_means=[.0, .0, .0, .0], target_stds=[1.0, 1.0, 1.0, 1.0]),
target_means 和 target_stds 相當於對 bbox 迴歸的 4 個 tx ty tw th 進行變換。在不考慮 target_means 和 target_stds 情況下,其編碼公式如下:
\({x}^{\ast },y^{\ast}\) 是 gt bbox 的中心 xy 座標, \(w^{\ast },h^{\ast }\) 是 gt bbox 的 wh 值, \(x_{a},y_{a}\) 是 anchor 的中心 xy 座標, \(w_{a},h_{a}\) 是 anchor 的 wh 值, \(t^{\ast }\) 是預測頭的 bbox 分支輸出的 4 個值對應的 targets。可以看出 \(t_x,t_y\) 預測值表示 gt bbox 中心相對於 anchor 中心點的偏移,並且通過除以 anchor 的 \(wh\) 進行歸一化;而 \(t_w,t_h\) 預測值表示 gt bbox 的 \(wh\) 除以 anchor 的 \(wh\),然後取 log 非線性變換即可。
Variables \(x\), \(x_a\), and \(x^{\ast }\) are for the predicted box, anchor box, and groundtruth box respectively (likewise for y; w; h).
1,考慮編碼過程存在 target_means 和 target_stds 情況下,則 anchor 的 bbox 對應的 target 編碼的核心程式碼如下:
dx = (gx - px) / pw
dy = (gy - py) / ph
dw = torch.log(gw / pw)
dh = torch.log(gh / ph)
deltas = torch.stack([dx, dy, dw, dh], dim=-1)
# 最後減掉均值,處於標準差
means = deltas.new_tensor(means).unsqueeze(0)
stds = deltas.new_tensor(stds).unsqueeze(0)
deltas = deltas.sub_(means).div_(stds)
2,解碼過程是編碼過程的反向,比較容易理解,其核心程式碼如下:
# 先乘上 std,加上 mean
means = deltas.new_tensor(means).view(1, -1).repeat(1, deltas.size(1) // 4)
stds = deltas.new_tensor(stds).view(1, -1).repeat(1, deltas.size(1) // 4)
denorm_deltas = deltas * stds + means
dx = denorm_deltas[:, 0::4]
dy = denorm_deltas[:, 1::4]
dw = denorm_deltas[:, 2::4]
dh = denorm_deltas[:, 3::4]
# wh 解碼
gw = pw * dw.exp()
gh = ph * dh.exp()
# 中心點 xy 解碼
gx = px + pw * dx
gy = py + ph * dy
# 得到 x1y1x2y2 的 gt bbox 預測座標
x1 = gx - gw * 0.5
y1 = gy - gh * 0.5
x2 = gx + gw * 0.5
y2 = gy + gh * 0.5
5.6,Focal Loss
Focal Loss 屬於 CE Loss 的動態加權版本,其可以根據樣本的難易程度(預測值和 label 的差距可以反映)對每個樣本單獨加權,易學習樣本在總的 loss 中的權重比較低,難樣本權重比較高。特徵圖上輸出的 anchor 座標列表的大部分都是屬於背景且易學習的樣本,雖然單個 loss 比較小,但是由於數目眾多最終會主導梯度,從而得到次優模型,而 Focal Loss 通過指數效應把大量易學習樣本的權重大大降低,從而避免上述問題。
為了便於理解,先給出 Focal Loss 的核心程式碼。
pred_sigmoid = pred.sigmoid()
# one-hot 格式
target = target.type_as(pred)
pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
focal_weight = (alpha * target + (1 - alpha) *
(1 - target)) * pt.pow(gamma)
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction='none') * focal_weight
loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
return loss
結合 BBox Assigner(BBox 正負樣本確定) 和 BBox Encoder (BBox target 計算)的程式碼,可得完整的 Focla Loss 程式碼如下所示。
class FocalLoss(nn.Module):
#def __init__(self):
def forward(self, classifications, regressions, anchors, annotations):
alpha = 0.25
gamma = 2.0
batch_size = classifications.shape[0]
classification_losses = []
regression_losses = []
anchor = anchors[0, :, :]
anchor_widths = anchor[:, 2] - anchor[:, 0]
anchor_heights = anchor[:, 3] - anchor[:, 1]
anchor_ctr_x = anchor[:, 0] + 0.5 * anchor_widths
anchor_ctr_y = anchor[:, 1] + 0.5 * anchor_heights
for j in range(batch_size):
classification = classifications[j, :, :]
regression = regressions[j, :, :]
bbox_annotation = annotations[j, :, :]
bbox_annotation = bbox_annotation[bbox_annotation[:, 4] != -1]
classification = torch.clamp(classification, 1e-4, 1.0 - 1e-4)
if bbox_annotation.shape[0] == 0:
if torch.cuda.is_available():
alpha_factor = torch.ones(classification.shape).cuda() * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float().cuda())
else:
alpha_factor = torch.ones(classification.shape) * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
regression_losses.append(torch.tensor(0).float())
continue
IoU = calc_iou(anchors[0, :, :], bbox_annotation[:, :4]) # num_anchors x num_annotations
IoU_max, IoU_argmax = torch.max(IoU, dim=1) # num_anchors x 1
#import pdb
#pdb.set_trace()
# compute the loss for classification
targets = torch.ones(classification.shape) * -1
if torch.cuda.is_available():
targets = targets.cuda()
targets[torch.lt(IoU_max, 0.4), :] = 0
positive_indices = torch.ge(IoU_max, 0.5)
num_positive_anchors = positive_indices.sum()
assigned_annotations = bbox_annotation[IoU_argmax, :]
targets[positive_indices, :] = 0
targets[positive_indices, assigned_annotations[positive_indices, 4].long()] = 1
if torch.cuda.is_available():
alpha_factor = torch.ones(targets.shape).cuda() * alpha
else:
alpha_factor = torch.ones(targets.shape) * alpha
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
# cls_loss = focal_weight * torch.pow(bce, gamma)
cls_loss = focal_weight * bce
if torch.cuda.is_available():
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape).cuda())
else:
cls_loss = torch.where(torch.ne(targets, -1.0), cls_loss, torch.zeros(cls_loss.shape))
classification_losses.append(cls_loss.sum()/torch.clamp(num_positive_anchors.float(), min=1.0))
# compute the loss for regression
if positive_indices.sum() > 0:
assigned_annotations = assigned_annotations[positive_indices, :]
anchor_widths_pi = anchor_widths[positive_indices]
anchor_heights_pi = anchor_heights[positive_indices]
anchor_ctr_x_pi = anchor_ctr_x[positive_indices]
anchor_ctr_y_pi = anchor_ctr_y[positive_indices]
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights
# clip widths to 1
gt_widths = torch.clamp(gt_widths, min=1)
gt_heights = torch.clamp(gt_heights, min=1)
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
targets_dw = torch.log(gt_widths / anchor_widths_pi)
targets_dh = torch.log(gt_heights / anchor_heights_pi)
targets = torch.stack((targets_dx, targets_dy, targets_dw, targets_dh))
targets = targets.t()
if torch.cuda.is_available():
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]]).cuda()
else:
targets = targets/torch.Tensor([[0.1, 0.1, 0.2, 0.2]])
negative_indices = 1 + (~positive_indices)
regression_diff = torch.abs(targets - regression[positive_indices, :])
regression_loss = torch.where(
torch.le(regression_diff, 1.0 / 9.0),
0.5 * 9.0 * torch.pow(regression_diff, 2),
regression_diff - 0.5 / 9.0
)
regression_losses.append(regression_loss.mean())
else:
if torch.cuda.is_available():
regression_losses.append(torch.tensor(0).float().cuda())
else:
regression_losses.append(torch.tensor(0).float())
return torch.stack(classification_losses).mean(dim=0, keepdim=True), torch.stack(regression_losses).mean(dim=0, keepdim=True)
參考資料
- https://github.com/yhenon/pytorch-retinanet
- RetinaNet 論文和程式碼詳解
- 輕鬆掌握 MMDetection 中常用演演算法(一):RetinaNet 及設定詳解