【機器學習】李宏毅——Adversarial Attack(對抗攻擊)
研究這個方向的動機,是因為在將神經網路模型應用於實際場景時,它僅僅擁有較高的正確率是不夠的,例如在異常檢測中、垃圾郵件分類等等場景,那些負類樣本也會想盡辦法來「欺騙」模型,使模型無法辨別出它為負類。因此我們希望我們的模型能夠擁有應對這種攻擊的能力。
How to Attack
通過影像辨識的例子來解釋如何進行攻擊。
假設我們已經訓練了一個影象的分類器,對於我們下圖中輸入的圖片它能夠分辨出來是一隻貓;那麼我們現在對原始的輸入進行一定的擾動,加入干擾項再輸入到模型中看看它是否會辨別成其中的東西(圖中這種擾動太大了,一般加入的擾動項是人眼無法辨別的):
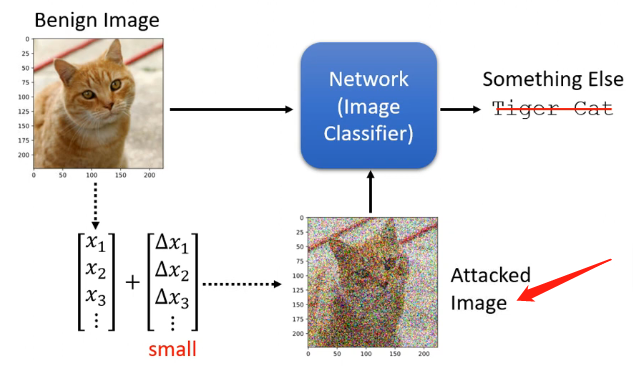
那麼這種攻擊又劃分為兩類:
- Non-targeted:這一類的攻擊只要求能夠讓模型無法辨認出來是貓就行
- targeted:這一類的模型是有目的性的,除了讓模型無法辨別出來是貓之外,還希望讓模型辨別出來是特定的物品
這裡有一個很神奇的現象,假設我們加入的雜訊比較大,我們人眼能夠直接觀察得到:

可以發現機器還是大部分能夠發現這是一隻貓,只不過可能品種不同而已。但如果加入的雜訊是我們特別準備的,並且肉眼看不出來的:

可以看到不僅分類錯誤了,連信心分數都激增,並且事實上我們可以調整我們的雜訊讓機器把這張看起來像一隻貓的圖片分辨成任何東西,因此這也是我們需要機器能夠對抗攻擊的原因之一。
那麼接下來我們就來認識一下是怎麼做到這種攻擊的。
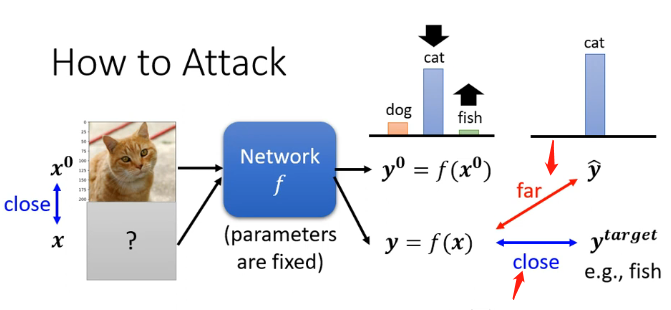
對於我們當前擁有的分類器,輸入一張貓的圖片\(x^0\)它輸出為一個向量,是每一個類別的信心分數,其中最高的為貓。
- 對於無目標的攻擊來說,我們在原始影象更換成一張圖片\(x\),它也經過分類器的處理後輸出一個向量,那希望是這個向量能夠和貓這個類別對應的One-hat-vector之間的距離越遠越好
- 對於有目標的攻擊來說,我們在原始影象更換成一張圖片\(x\),它也經過分類器的處理後輸出一個向量,那不僅希望是這個向量能夠和貓這個類別對應的One-hat-vector之間的距離越遠越好,還希望這個向量與目標類別的One-hat-vector之間的差距越小越好
而對於向量之間的差距我們可以用交叉熵來表示,因此得到:
那麼對於無目標的攻擊,可以設定其損失函數為:
對於有目標的攻擊可以設定其損失函數為:
因此優化目標為:
其中\(d(x^0,x)<\varepsilon\)代表我們希望加入的影象和原始的影象比較接近,這樣肉眼才看不出來。而這個距離的計算方式下面舉兩個例子:
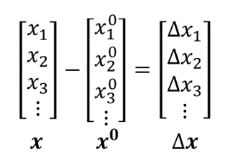
- L2-norm:\(d(x^0,x)=\lVert \Delta \vec{x}\rVert =\sum_{i=1}(\Delta x_i)^2\)
- L-infinity:\(d(x^0,x)=\lVert \Delta \vec{x} \rVert=max\{\Delta x_i\}\)
那麼這兩種距離計算方法的區別在於人眼的觀感程度,這也許聽起來很抽象但可以通過下面的例子解釋:
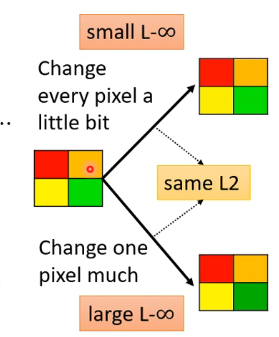
上方和下方的圖它們與原始的圖的L2-norm距離相同,只不過上方的圖距離都分散的每一個畫素,下方的圖集中在右下角的畫素,因此下方的圖我們能夠明顯感受出差別。
而這兩張圖的L-infinity差距是不同的,第一張圖顯然比第二張圖小。那麼為了要讓我們人眼無法辨認,我們需要對這個L-infinity進行限制,才可以讓我們無法看出來,因此一般是選擇L-infinity。
那麼下面的問題就是我們如何求解這個優化問題:
對於此問題,跟之前我們訓練模型時調整引數是一樣的,只不過調整的引數變成了輸入而已,同樣也可以採用梯度下降來求解,只不過要加上一定的限制而已:
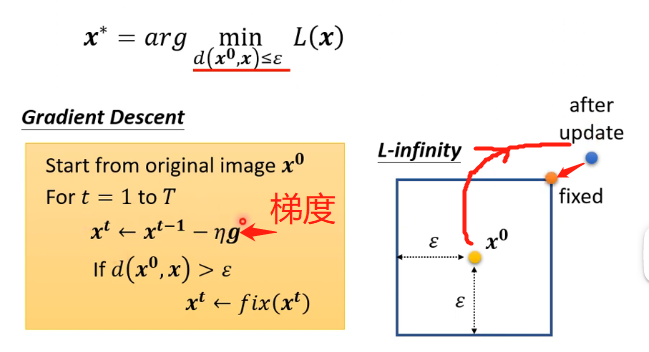
進行梯度更新的時候,我們要時刻檢查更新之後其距離是否會超過限制的範圍,如果超過了就要及時地將其修正回來。
有一個應用上述思想的簡單演演算法為FGSM,其特點在於:
- 它只迭代一次
- 它的學習率設為我們限制的距離大小
- 它的梯度計算出來後會對每一個分量加上一個Sign函數,使其成為正負1
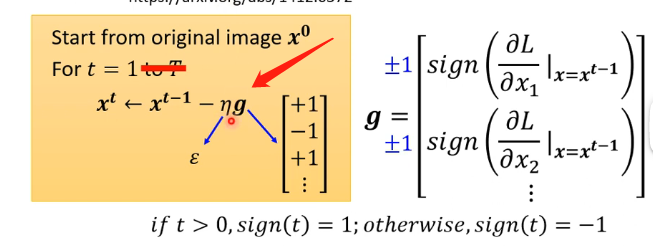
那麼可以看到,這樣更新一次是絕對不會超過範圍的,因此這樣找到的或許是可行的。
White Box v.s. Black Bos
在前面介紹的攻擊方法中我們需要計算梯度,而計算梯度則要求我們知道該模型內部的引數,因此這一種攻擊稱為White Box(白箱攻擊),這一種攻擊對於一些未知模型來說可能是無法進行的。但這不代表著不讓別人知道模型引數就是安全的,因為還有Black Bos(黑箱攻擊),這一類攻擊不需要知道模型內部的引數就可以發動攻擊。
對於黑箱攻擊來說,一種簡單的情況是我們知道這個未知的模型是由哪些訓練資料訓練出來的,那麼我們就可以用一個具有類似網路結構的模型也對這些訓練資料進行訓練,得到我們自己模型的引數,那麼再在這個模型上計算如何攻擊,最終將得到的攻擊應用到目標模型中就可能會成功,如下圖:
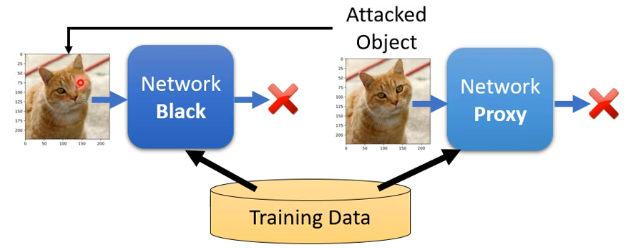
那麼複雜一點的情況就是我們也不知道訓練集,那麼可能可行的做法為用一大堆我們自己的資料放進去這個模型,相應會得到一大堆輸出,那麼將這些輸入和輸出來作為訓練集,就可以類比上面的做法進行訓練。
在實際上,黑箱攻擊和白箱攻擊都是很容易成功的,並且在一個模型上攻擊成功的x,用在另外的模型上也非常容易攻擊成功,那麼這就讓人有了研究的空間,但目前仍然沒有明確的答案,值得讓人信服的解釋是實際上攻擊是否成功主要取決於你的訓練資料而不是取決於你的模型,相同的訓練資料所訓練出來的不同模型在被攻擊時很可能呈現相同的結果,也就是說攻擊可以認為是「具有特徵性的」,也許你得到的這個攻擊向量看起來真的很像是雜訊, 但這可能就是機器從訓練資料中學習到的特徵。
這裡補充一個小知識點,因為我們之前說到的攻擊都說客製化的,即對於每一張圖片單獨計算它的攻擊向量,那麼假設影響場景為某個攝像頭,我們想要讓這個攝像頭對於輸入都辨認錯誤的話則要對每張圖片都計算,那麼運算量很大;那麼有沒有可能能夠有一個通用的攻擊向量,如果將它加入攝像頭攝取的每一個圖片的時候,都能夠使該圖片被辨認錯誤,那麼這樣的攻擊稱為Universal Adversarial Attack。這種是可能可以做到的。
其他攻擊型別綜述
Adversarial Reprogramming
這一個類別的攻擊在於直接攻擊模型,它像是寄生蟲一樣寄生於別的模型之上,然後讓其他已經訓練好的模型來做我們想做的任務
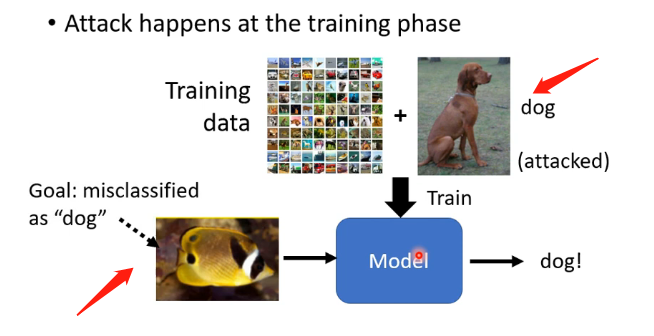
"Backdoor" in Model
這種開後門的方法是在訓練階段就已經攻擊了,例如在訓練階段加入特定的圖片,讓訓練完成後的模型看到某一張特定圖片的魚是會分辨成狗。但是這種訓練要保證我們加進去的特殊圖片它是人眼無法檢查出來的,不能說加入一大堆魚的圖片然後標準改成狗,這是不行的。
Defense
前面都是在講如何進行攻擊,那麼接下來進行介紹我們如何進行防禦
Passive Defense
這類防禦,訓練完模型之後就不改變模型,而是在將樣本輸入到模型之前,增加一個filter環節,如下:
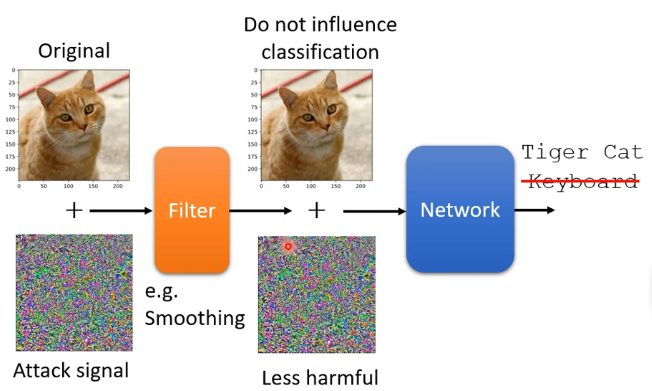
那麼這個Filter的作用可以認為是削減這個攻擊訊號的威力,使我們的模型仍然能夠正常的進行辨認。那麼這個Filter也不一定特別複雜,有時候例如進行模糊化就可以達到我們想要的效果,但要注意模糊化也有負作用,就是讓機器的信心分數降低:
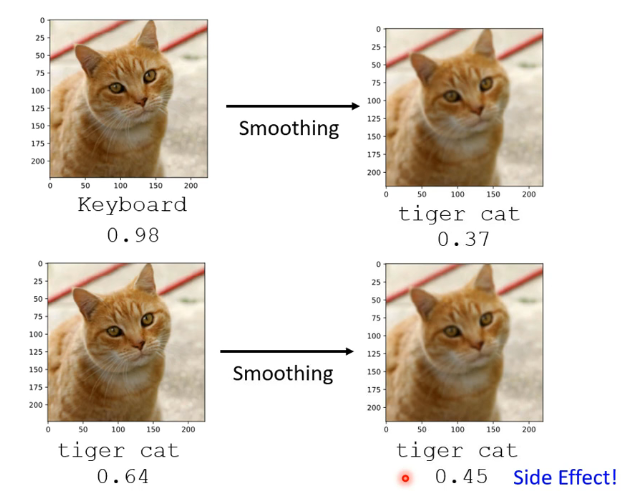
類似於這種方法還有很多,例如將影像進行壓縮和解壓縮,可能就可以讓攻擊訊號失去威力,或者通過AE自編碼器來重新生成,也可能可以過濾掉雜訊等等。而這種被動防禦一般來說如果被攻擊方明確你採用的防禦方法,那麼就非常容易被破解。
那麼可能的改進是加入隨機化,即在對影象處理處理的時候隨機選擇可選的處理策略,不過還是得保護住你隨機的分佈才可以保持防禦的有效性。
Proactive Defense
這種思想是在訓練時就訓練一個不容易被攻擊的模型。具體的做法是我們自己創造攻擊型別的向量來進行攻擊訓練,即對原始的樣本修改為攻擊的樣本,不過我們要加上它原來正確的標籤,將這些作為訓練資料來對模型進行訓練。

但這個問題主要是能夠抵擋你訓練過的那些攻擊的方法,對於未見過的攻擊演演算法很可能擋不住。