手撕正規表示式
2022-12-22 21:00:26
我們先撕簡單的。a ab a|b aa* a(a|b)* 先不管匹配任意字元的. 重複>=1次的+ [^0-9]除0-9外 \digit數位等。
正規表示式(regular expression, re)為啥叫表示式,不叫正則字串之類?因為它是個表示式。3+5*2是個表示式;兩個字串可以有連線運算,如"a"+"b"或"a"."b"得到"ab"。
在正規表示式裡,a,b,c就像2,3,5,是被運算的數,. | * ()是運運算元。請注意:ab是a和b拼接,人們為了省事不把拼接運運算元寫出來。
(3+5)*2=16,3+(5*2)=13。如果沒有四則運算優先順序和括號,3+5*2等於16還是13?運運算元後置(字尾表示式)沒有歧義,例如35+2*是mul(add(3,5), 2),352+*是mul(3, add(5,2))。mul: multipy. What are infix, postfix and prefix expressions?
我們分3步走:
- 把a(a|b)*變成aab|*.這樣的字尾表示式,40行程式。ab是a和b拼接,是a.b的縮寫(中間有個.)
- 用Thompson演演算法把字尾表示式變成NFA,號稱4行 (case, case, case, default)
- 用NFA檢查是否匹配,號稱10行
第1步中綴變字尾請看程式碼。
第2步字尾變NFA。NFA可以像積木一樣拼起來。下面分別是a, ab, a|b, a*的NFA:
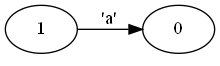

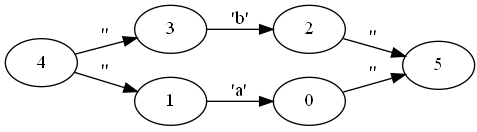
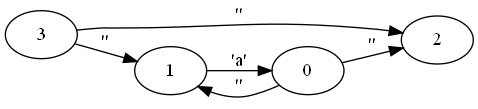
圖片是用dot - graphviz version 2.49.0畫的。如 dot -o ab.png -Tpng todot.txt 或 dot -Tpng todot.txt >ab.png 。dot -h看幫助。
拼接NFA的程式碼:
NFA postfix_to_nfa(const char* pfstr) { Stack<NFA> stk; for (const char* p = pfstr; *p; p++) { switch (*p) { case '.': stk.push(stk.pop() + stk.pop()); break; case '|': stk.push(stk.pop() | stk.pop()); break; case '*': stk.push(*stk.pop()); break; default: stk.push(*p); } } NFA nfa = stk.pop(); if (!stk.empty()) error; return nfa; }
運運算元函數也不長,含列印,匹配等全部程式碼180行:


// 從ChrisZZ([email protected])的程式改來的 #include <stdio.h> #include <string.h> #include <string> #include <stack> using namespace std; #define error throw __LINE__ template<class T>struct Stack : public stack<T> { T pop() { T t = top(); stack<T>::pop(); return t; } }; const char END = '\0', EPSILON = '\001'; // Epsilon (upper case Ε, lower case ε): empty struct State { // 像連結串列裡的node int id; // 自動加1的編號 State* next[2]; // 到next[0]的邊是epsilon;到next[1]的是char char ch; State(int ch_=256, State* p1=0, State* p0=0) : id(_id++), ch(ch_) { next[0] = p0; next[1] = p1; } static int _id; static char _visited[256]; // 下標是State的編號,僅print時用 }; int State::_id; char State::_visited[256]; struct NFA { State *start, *end; NFA() : start(0), end(0) {} NFA(char ch) { end = new State(END); start = new State(ch, end); } NFA operator + (NFA nfa) { end->ch = EPSILON; end->next[1] = nfa.start; end = nfa.end; return *this; } NFA operator | (NFA nfa) { State *head = new State(EPSILON, start, nfa.start), *tail = new State(END); end->ch = EPSILON; end->next[1] = tail; end = tail; start = head; nfa.end->ch = EPSILON; nfa.end->next[1] = tail; return *this; } NFA operator * () { State *tail = new State(END), *head = new State(EPSILON, start, tail); end->ch = EPSILON; end->next[0] = start; end->next[1] = tail; end = tail; start = head; return *this; } void print(const char* file_name); const char* elm; // point to the end of the longest match const char* match(const char* str) { elm = str; visit4m(start, str); return elm; } void visit4p(const State* s, FILE* fp); // visit for print void visit4m(const State* s, const char* str); // visit for match }; NFA postfix_to_nfa(const char* pfstr) { Stack<NFA> stk; for (const char* p = pfstr; *p; p++) { switch (*p) { case '.': stk.push(stk.pop() + stk.pop()); break; case '|': stk.push(stk.pop() | stk.pop()); break; case '*': stk.push(*stk.pop()); break; default: stk.push(*p); } } NFA nfa = stk.pop(); if (!stk.empty()) error; return nfa; } void NFA::print(const char* file_name) { // 同時輸出到螢幕和DOT檔案 puts(""); FILE* fp = fopen(file_name, "wt"); if (!fp) return; fputs("digraph {\n\"\"\n", fp); fputs("[shape = plaintext]\n", fp); fputs("\trankdir = LR\n", fp); memset(State::_visited, 0, sizeof(State::_visited)), visit4p(start, fp); fputs("}", fp), fclose(fp); } void NFA::visit4p(const State* st, FILE* fp) { if (State::_visited[st->id]) return; State::_visited[st->id] = 1; for (int i = 0; i < 2; i++) { if (State* p = st->next[i]) { char label[16]; if (st->ch == EPSILON) strcpy(label, "''"); else sprintf(label, "'%c'", st->ch); // DOT支援不帶BOM的UTF-8編碼的檔案。ε的UTF-8編碼是\xce\xb5 printf("%d - %s -> %d\n", st->id, label, p->id); fprintf(fp, "%d -> %d [label = <%s>]\n", st->id, p->id, label); visit4p(p, fp); } } } void NFA::visit4m(const State* st, const char* str) { if (st == end) { if (str > elm) elm = str; return; } for (int i = 0; i < 2; i++) { if (State* p = st->next[i]) { if (st->ch == EPSILON) visit4m(p, str); if (st->ch == *str) visit4m(p, str + 1); } } } struct CountOf { int opnd; // a是opnd b是opnd ab.也是opnd int or; // | }; string re_to_postfix(const char* re) { string out; CountOf cntof = { 0 }; stack<CountOf> khdz; // KuoHao (parenthesis) 的棧 const char* p; for (p = re; *p; p++) { switch (char c = *p) { case '(': if (cntof.opnd > 1) out += '.'; // a(??? khdz.push(cntof); cntof.or = cntof.opnd = 0; break; case ')': if (cntof.opnd == 0 || khdz.empty()) error; // ) () while (--cntof.opnd > 0) out += '.'; // ((a|b)(c|d)) =1時不進迴圈 1個opnd不需要. while (cntof.or-- > 0) out += '|'; // =1時進迴圈 cntof = khdz.top(); khdz.pop(); ++cntof.opnd; // 如遇到(時還沒有opnd,遇到(a)的)時,知道了(a)是個opnd break; case '*': if (cntof.opnd ==0 ) error; out += c; break; case '|': // a|b變ab| a|b|c變ab|c| ab|c變ab.c| if (cntof.opnd == 0) error; while (--cntof.opnd > 0) out += '.'; ++cntof.or; break; default: // a變a ab變ab. abc變ab.c. if (cntof.opnd > 1) { --cntof.opnd; out += '.'; } out += c; ++cntof.opnd; } // switch // printf("%*c", 5, ' ')輸出5個空格 printf("%*c%s %d %d %s\n", p - re, ' ', p, cntof.opnd, cntof.or, out.c_str()); } // for if (!khdz.empty()) error; while (--cntof.opnd > 0) out += '.'; while (cntof.or-- > 0) out += '|'; printf("%*c%s %s\n", p - re, ' ', p, out.c_str()); return out; } int main(){ try { //const char* re = "a"; //const char* re = "a*"; //const char* re = "ab"; //const char* re = "a|b"; const char* re = "((a|b)(c|d))*"; NFA nfa = postfix_to_nfa(re_to_postfix(re).c_str()); nfa.print("todot.txt"); const char* s = "bdabc"; const char* p = nfa.match(s); printf("\nmatch: %.*s\n", p - s, s); } catch(int n) { printf("Error at line %d.\n", n); } getchar(); return 0; }
print和match都是遞迴遍歷圖。
- Brief intro to NFA, DFA and regexes
- Programming Thompson's algorithm: How to represent a NFA?
- Can any NFA be converted to a DFA? | NFA轉DFA
- Hopcroft's DFA minimization algorithm | Generates Regular Expressions That Match A Set of Strings
- Brzozowski's algebraic method to convert a DFA into a regular expression
- Grep - GNU Project regex.c getopt.c ... This is GNU grep 2.0, the "fastest grep in the west" (we hope)... GNU grep is based on a fast lazy-state deterministic matcher (about twice as fast as stock Unix egrep) hybridized with a Boyer-Moore-Gosper search for a fixed string that eliminates impossible text from being considered by the full regexp matcher without necessarily having to look at every character. The result is typically many times faster than Unix grep or egrep. (Regular expressions containing backreferencing will run more slowly, however.)
- The Difference Between grep, egrep, and fgrep
- How to create DFA from regular expression without using NFA? I asked this question to our professor but he told me that we can use intuition and kindly refused to provide any explanation. :-)
- Flex - a scanner generator (gnu.org)