深度學習煉丹-資料預處理和增強
前言
一般機器學習任務其工作流程可總結為如下 pipeline。
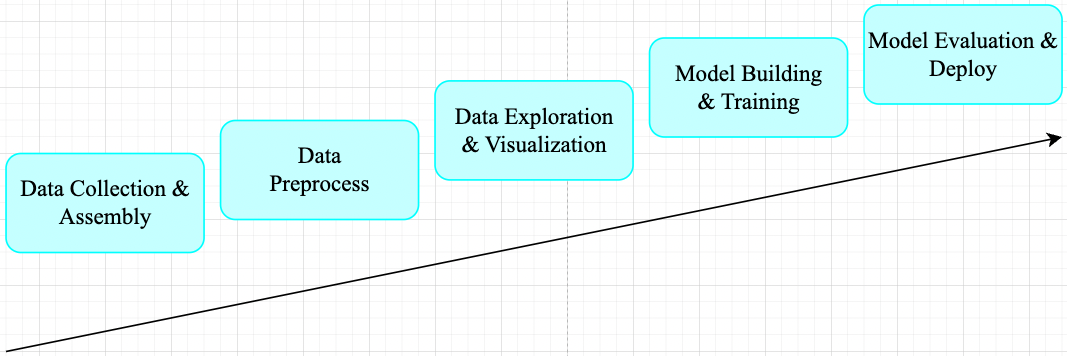
在工業界,資料預處理步驟對模型精度的提高的發揮著重要作用。對於機器學習任務來說,廣泛的資料預處理一般有四個階段(視覺任務一般只需 Data Transformation): 資料淨化(Data Cleaning)、資料整合(Data Integration)、資料轉換(Data Transformation)和資料縮減(Data Reduction)。
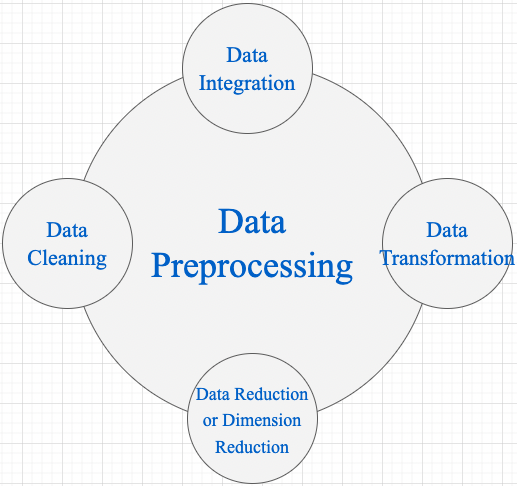
1,Data Cleaning 資料清理是資料預處理步驟的一部分,通過填充缺失值、平滑噪聲資料、解決不一致和刪除異常值來清理資料。
2,Data Integration 用於將存在於多個源中的資料合併到一個更大的資料儲存中,如資料倉儲。例如,將來自多個醫療節點的影象整合起來,形成一個更大的資料庫。
3,在完成 Data Cleaning 後,我們需要通過使用下述資料轉換策略更改資料的值、結構或格式。
Generalization: 使用概念層次結構將低階或粒度資料轉換為高階資訊。例如將城市等地址中的原始資料轉化為國家等更高層次的資訊。Normalization: 目的是將數位屬性按比例放大或縮小以適合指定範圍。Normalization常見方法:- Min-max normalization
- Z-Score normalization
- Decimal scaling normalization
4,Data Reduction 資料倉儲中資料集的大小可能太大而無法通過資料分析和資料探勘演演算法進行處理。一種可能的解決方案是獲得資料集的縮減表示,該資料集的體積要小得多,但會產生相同質量的分析結果。常見的資料縮減策略如下:
Data cube aggregationDimensionality reduction: 降維技術用於執行特徵提取。資料集的維度是指資料的屬性或個體特徵。該技術旨在減少我們在機器學習演演算法中考慮的冗餘特徵的數量。降維可以使用主成分分析(PCA)等技術來完成。Data compression: 通過使用編碼技術,資料的大小可以顯著減小。Discretization: 資料離散化用於將具有連續性的屬性劃分為具有區間的資料。這樣做是因為連續特徵往往與目標變數相關的可能性較小。例如,屬性年齡可以離散化為 18 歲以下、18-44 歲、44-60 歲、60 歲以上等區間。
對於計算機視覺任務來說,在訓練 CNN 模型之前,對於輸入資料特徵做歸一化(normalization)預處理(data preprocessing)操作是最常見的步驟。
一,Normalization 概述
這裡沒有翻譯成中文,是因為目前中文翻譯有些歧義,根據我查閱的部落格資料,翻譯為「歸一化」比較多,僅供可參考。
1.1,Normalization 定義
Normalization 操作被用於對資料屬性進行縮放,使其落在較小的範圍之內(即變化到某個固定區間中),比如 [-1,1] 和 [0, 1],簡單理解就是特徵縮放過程。很多機器學習演演算法都受益於 Normalization 操作,比如:
- 通常對分類演演算法有用。
- 在梯度下降等機器學習演演算法的核心中使用的優化演演算法很有用。
- 對於加權輸入的演演算法(如迴歸和神經網路)以及使用距離度量的演演算法(如 K 最近鄰)也很有用。
1.2,什麼情況需要 Normalization
當我們處理的資料具有不同尺度(範圍)(different scale)時,通常就需要進行 normalization 操作了,它可能會導致一個重要屬性(在較低尺度上)的有效性被稀釋,因為其他屬性具有更大範圍(尺度)的值,簡單點理解就是範圍(scale)大點屬性在模型當中更具優先順序,具體範例如下圖所示。
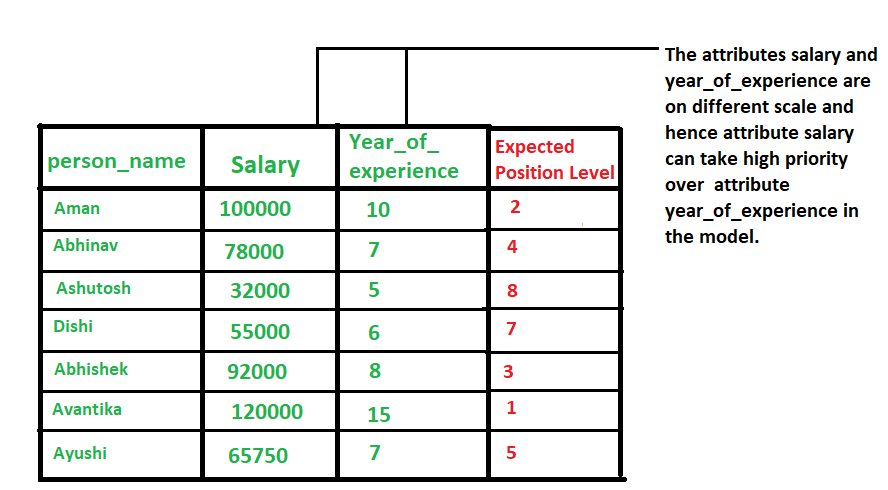
總而言之,就是當資料存在多個屬性但其值具有不同尺度(scale)時,這可能會導致我們在做資料探勘操作時資料模型表現不佳,因此執行 normalization 操作將所有屬性置於相同的尺寸內是很有必要的。
1.3,Data Normalization 方法
1,z-Score Normalization
zero-mean Normalization,有時也稱為 standardization,將資料特徵縮放成均值為 0,方差為 1 的分佈,對應公式:
其中 \(mean(x)\)(有些地方用 \(\mu =\frac{1}{N}\sum_{i=1}^{N} x_i\)) 表示變數 \(x\) 的均值,\(\sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N}(x_i - \mu)^2}\) 表示變數的標準差,\({x}'\) 是資料縮放後的新值。
2,Min-Max Normalization
執行線性操作,將資料範圍縮放到 \([0,1]\) 區間內,對應公式:
其中 \(max(x)\) 是變數最大值,\(min(x)\) 是變數最小值。
1.4,範例程式碼
1,以下是使用 Python 和 Numpy 庫實現 Min-Max Normalization 的範例程式碼:
# 匯入必要的庫
import numpy as np
# 定義資料集
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 計算資料集的最小值和最大值
Xmin = X.min()
Xmax = X.max()
# 計算最小-最大規範化
X_norm = (X - Xmin) / (Xmax - Xmin)
# 列印結果
print(X_norm)
程式輸出結果如下,可以看出原始陣列資料都被縮放到 \([0, 1]\) 範圍內了。

二,normalize images
2.1,影象 normalization 定義
當我們使用折積神經網路解決計算機視覺任務時,一般需要對輸入影象資料做 normalization 來完成預處理工作,常見的影象 normalization 方法有兩種: min-max normalization 和 zero-mean normalization。
1,以單張影象的 zero-mean Normalization 為例,它使得影象的均值和標準差分別變為 0.0 和 1.0。因為是多維資料,與純表格資料不同,它首先需要從每個輸入通道中減去通道平均值,然後將結果除以通道標準差。因此可定義兩種 normalization 形式如下所示:
# min-max Normalization
output[channel] = (input[channel] - min[channel]) / (max[channel] - min[channel])
# zero-mean Normalization
output[channel] = (input[channel] - mean[channel]) / std[channel]
2.2,影象 normalization 的好處
影象 normalization 有助於使資料處於一定範圍內並減少偏度(skewness),從而有助於模型更快更好地學習。歸一化還可以解決梯度遞減和爆炸的問題。
2.3,PyTorch 實踐影象 normalization
在 Pytorch 框架中,影象變換(image transformation)是指將影象畫素的原始值改變為新值的過程。其中常見的 transformation 操作是使用 torchvision.transforms.ToTensor() 方法將影象變換為 Pytorch 張量(tensor),它實現了將畫素範圍為 [0, 255] 的 PIL 影象轉換為形狀為(C,H,W)且範圍為 [0.0, 1.0] 的 Pytorch FloatTensor。另外,torchvision.transforms.normalize() 方法實現了逐 channel 的對影象進行標準化(均值變為 0,標準差變為 1)。總結如下:
min-max Normalization: 對應torchvision.transforms.ToTensor()方法zero-mean Normalization: 對應torchvision.transforms.Normalize()方法,利用用均值和標準差對張量影象進行 zero-mean Normalization。
ToTensor() 函數的語法如下:
"""
Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
Converts a PIL Image or numpy.ndarray (H x W x C) in the range
[0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0].
Args:
pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
Returns:
Tensor: Converted image.
"""
Normalize() 函數的語法如下:
Syntax: torchvision.transforms.Normalize()
Parameter:
* mean: Sequence of means for each channel.
* std: Sequence of standard deviations for each channel.
* inplace: Bool to make this operation in-place.
Returns: Normalized Tensor image.
在 PyTorch 中對影象執行 zero-mean Normalization 的步驟如下:
- 載入原影象;
- 使用 ToTensor() 函數將影象轉換為 Tensors;
- 計算 Tensors 的均值和方差;
- 使用 Normalize() 函數執行
zero-mean Normalization操作。
下面給出利用 PyTorch 實踐 Normalization 操作的詳細程式碼和輸出圖。
# import necessary libraries
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
def show_images(imgs, num_rows, num_cols, titles=None, scale=8.5):
"""Plot a list of images.
Defined in :numref:`sec_utils`"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
try:
img = np.array(img)
except:
pass
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
def normalize_image(image_path):
img = Image.open(img_path) # load the image
# 1, use ToTensor function
transform = transforms.Compose([
transforms.ToTensor()
])
img_tensor = transform(img) # transform the pIL image to tensor
# 2, calculate mean and std by tensor's attributes
mean, std = img_tensor.mean([1,2]), img_tensor.std([1,2])
# 3, use Normalize function
transform_norm = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
img_normalized = transform_norm(img) # get normalized image
img_np = np.array(img) # convert PIL image to numpy array
# print array‘s shape mean and std
print(img_np.shape) # (height, width, channel), (768, 1024, 3)
print("mean and std before normalize:")
print("Mean of the image:", mean)
print("Std of the image:", std)
return img_np, img_tensor, img_normalized
def convert_tensor_np(tensor):
img_arr = np.array(tensor)
img_tr = img_arr.transpose(1, 2, 0)
return img_tr
if __name__ == '__main__':
img_path = 'Koalainputimage.jpeg'
img_np, img_tensor, img_normalized = normalize_image(img_path)
# transpose tensor to numpy array and shape of (3,,) to shape of (,,3)
img_normalized1 = convert_tensor_np(img_tensor)
img_normalized2 = convert_tensor_np(img_normalized)
show_images([img_np, img_normalized1, img_normalized2], 1, 3, titles=["orignal","min-max normalization", "zero-mean normalization"])
1,程式輸出和兩種 normalization 操作效果視覺化對比圖如下所示:

2,原圖和兩種 normalization 操作後的影象畫素值分佈視覺化對比圖如下所示:
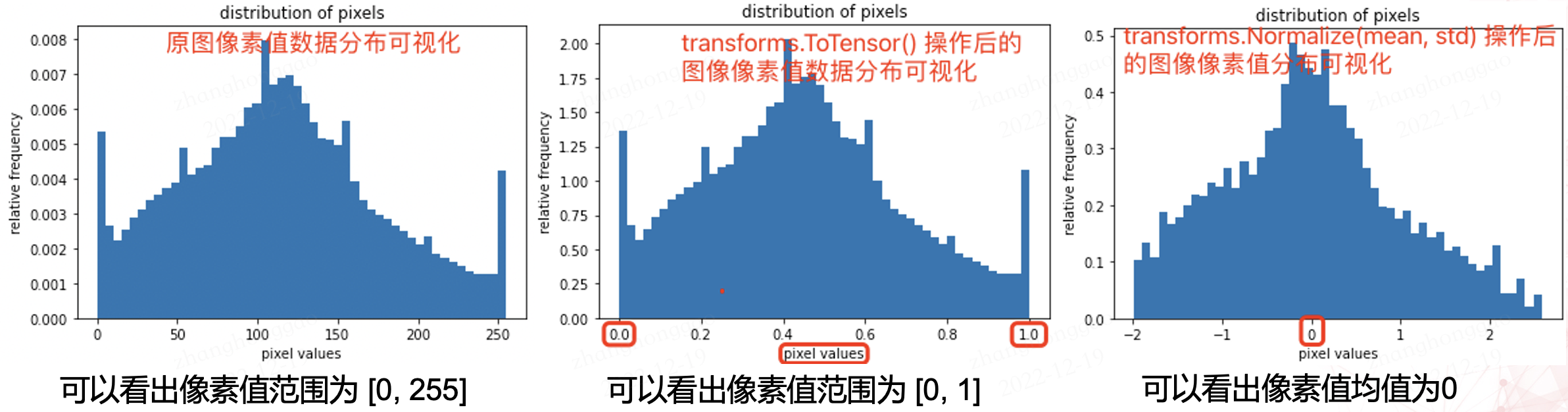
畫素值分佈視覺化用的程式碼如下。
# plot the pixel values
plt.hist(img_np.ravel(), bins=50, density=True)
plt.xlabel("pixel values")
plt.ylabel("relative frequency")
plt.title("distribution of pixels")
三,資料增強(擴增)
資料增強的目的是為了擴充資料和提升模型的泛化能力。有效的資料擴充不僅能擴充訓練樣本數量,還能增加訓練樣本的多樣性,一方面可避免過擬合,另一方面又會帶來模型效能的提升。
在機器學習管道(pipeline)框架中,我們需要在送入模型之前,進行資料增強,一般有兩種處理方式:
- 線下增強(offline augmentation): 適用於較小的資料集(smaller dataset)。
- 線上增強(online augmentation): 適用於較大的資料集(larger datasets)。
資料擴增幾種常用方法有: 影象水平/豎直翻轉、隨機摳取、尺度變換和旋轉。其中尺度變換(scaling)、旋轉(rotating)等方法用來增加折積折積神經網路對物體尺度和方向上的魯棒性。
在此基礎上,對原圖或已變換的影象(或影象塊)進行色彩抖動(color jittering)也是一種常用的資料擴充手段,即改變影象顏色的四個方面:亮度、對比度、飽和度和色調。色彩抖動是在 RGB 顏色空間對原有 RGB 色彩分佈進行輕微的擾動,也可在 HSV 顏色空間嘗試隨機改變影象原有 的飽和度和明度(即,改變 S 和 V 通道的值)或對色調進行微調(小範圍改變 該通道的值)。
HSV 表達彩色影象的方式由三個部分組成:
Hue(色調、色相)
Saturation(飽和度、色彩純淨度)
Value(明度)
3.1,opencv 影象處理
影象的幾何變換
OpenCV 提供的幾何變換函數如下所示:
1,拓展縮放: 拓展縮放,改變影象的尺寸大小
cv2.resize(): 。常用的引數有設定影象尺寸、縮放因子和插值方法。
2,平移: 將物件換一個位置。
cv2.warpAffine(): 函數第一個引數是原影象,第二個引數是移動矩陣,第三個引數是輸出影象大小 (width,height)。舉例,如果要沿 \((x,y)\) 方向移動,移動的距離是 \((tx ,ty)\),則以下面的方式構建移動矩陣:
3,旋轉: 對一個影象旋轉角度 \(\theta\)。
先使用 cv2.getRotationMatrix2D 函數構建旋轉矩陣 \(M\),再使用 cv2.warpAffine() 函數將物件移動位置。
getRotationMatrix2D 函數第一個引數為旋轉中心,第二個為旋轉角度,第三個為旋轉後的縮放因子
4,放射變換(也叫平面變換/徑向變換): 在仿射變換中,原圖中所有的平行線在結果影象中依舊平行。
為了找到變換矩陣,我們需要從輸入影象中得到三個點,以及它們在輸出影象中的對應位置。然後使用 cv2. getAffineTransform 先構建一個 2x3 變換矩陣,最後該矩陣將傳遞給 cv2.warpAffine 函數。
5,透視變換(也叫空間變換): 轉換之後,直線仍是直線。
原理: 透視變換(Perspective Transformation)是指利用透視中心、像點、目標點三點共線的條件,按透視旋轉定律使承影面(透視面)繞跡線(透視軸)旋轉某一角度,破壞原有的投影光線束,仍能保持承影面上投影幾何圖形不變的變換。-來源百度百科。
對於透視變換,需要先構建一個 3x3 變換矩陣。要找到此變換矩陣,需要在輸入影象上找 4 個點,以及它們在輸出影象中的對應位置。在這 4 個點中,其中任意 3 個不共線。然後可以通過函數 cv2.getPerspectiveTransform 找到變換矩陣,將 cv2.warpPerspective 應用於此 3x3 變換矩陣。
影象幾何變換的範例程式碼如下:
import cv2
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
# Some Geometric Transformation of Images
class GeometricTransAug(object):
def __init__(self, image_path):
img = Image.open(image_path) # load the image
self.img_np = np.array(img) # convert PIL image to numpy array
self.rows, self.cols, self.ch = self.img_np.shape
self.geometry_trans_aug_visual(self.img_np)
def resize_aug(self, img_np):
# 直接設定了縮放因子, 縮放原大小的2倍
res = cv2.resize(img_np, None, fx=2, fy=2, interpolation = cv2.INTER_CUBIC)
return res
def warpAffine_aug(self, img_np):
# 先構建轉換矩陣, 將影象畫素點整體進行(100,50)位移:
M = np.float32([[1,0,100],[0,1,50]])
res = cv2.warpAffine(img_np, M,(self.cols, self.rows))
return res
def rotation_aug(self, img_np):
rows, cols, ch = img_np.shape
# 先構建轉換矩陣,影象相對於中心旋轉90度而不進行任何縮放。
M = cv2.getRotationMatrix2D((self.cols/2, self.rows/2), 90, 1)
res = cv2.warpAffine(img_np, M, (self.cols, self.rows))
return res
def radial_trans_aug(self, img_np):
# 仿射變換需要從原影象中找到三個點以及他們在輸出影象中的位置
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
# 通過 getAffineTransform 建立一個 2x3 的轉換矩陣
M = cv2.getAffineTransform(pts1,pts2)
res = cv2.warpAffine(img_np, M, dsize = (self.cols, self.rows))
return res
def perspective_trans_aug(self, img_np):
# 透視變換需要一個 3x3 變換矩陣
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv2.getPerspectiveTransform(pts1,pts2)
# dsize: size of the output image.
res = cv2.warpPerspective(img_np, M, dsize = (300,300))
return res
def geometry_trans_aug_visual(self, img_np):
res1 = self.resize_aug(img_np)
res2 = self.warpAffine_aug(img_np)
res3 = self.rotation_aug(img_np)
res4 = self.radial_trans_aug(img_np)
res5 = self.perspective_trans_aug(img_np)
imgs = [res1, res2, res3, res4, res5]
aug_titles = ["resize_aug", "warpAffine_aug", "rotation_aug", "radial_trans_aug", "perspective_trans_aug"]
# show_images 函數前文已經給出,這裡不再複製過來
axes = show_images(imgs, 2, 3, titles=aug_titles, scale=8.5)
if __name__ == '__main__':
img_path = 'Koalainputimage.jpeg'
geometry_trans_aug = GeometricTransAug(img_path)
img_np2 = geometry_trans_aug.img_np
print(img_np2.shape)
程式執行後輸出的幾何變換增強效果如下所示:
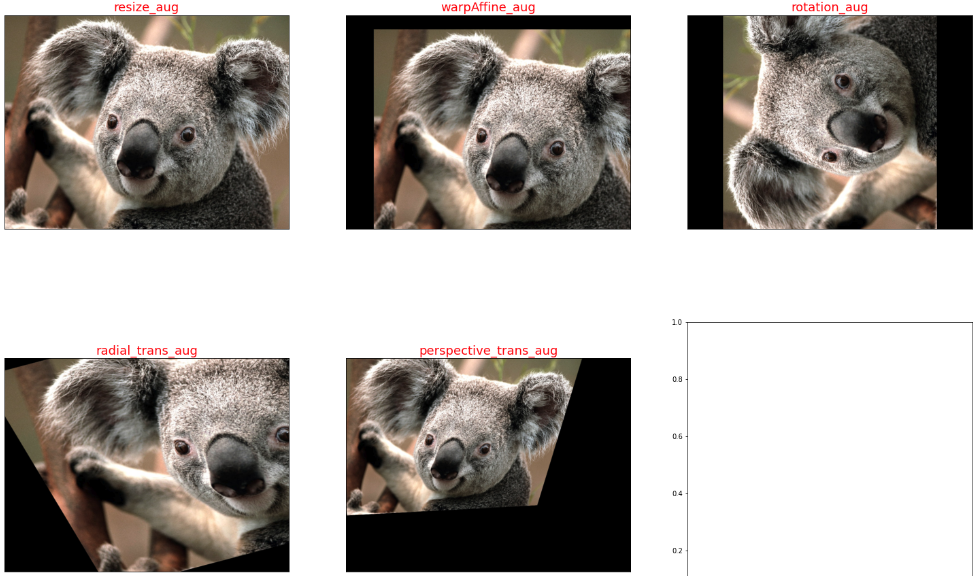
3.2,pytorch 影象增強
在 pytorch 框架中,transforms 類提供了 22 個資料增強方法,對應程式碼在 transforms.py 檔案中,它們既可以對 PIL Image 也能對 torch.*Tensor 資料型別進行增強。
api 的詳細介紹可以參考官網檔案-Transforming and augmenting images。本章只對 transforms 的 22 個方法進行簡要介紹和總結。
總的來說 transforms.py 中的各個預處理方法可以歸納為四大類:
1,裁剪-Crop
- 中心裁剪: transforms.CenterCrop
- 隨機裁剪: transforms.RandomCrop
- 隨機長寬比裁剪: transforms.RandomResizedCrop
- 上下左右中心裁剪: transforms.FiveCrop
- 上下左右中心裁剪後翻轉: transforms.TenCrop
2,翻轉和變換-Flip and Rotations
- 依概率 p 水平翻轉:transforms.RandomHorizontalFlip(p=0.5)
- 依概率 p 垂直翻轉:transforms.RandomVerticalFlip(p=0.5)
- 隨機旋轉:transforms.RandomRotation
3,影象變換
- resize: transforms.Resize
min-max Normalization: 對應torchvision.transforms.ToTensor()方法zero-mean Normalization: 對應torchvision.transforms.Normalize()方法- 填充: transforms.Pad
- 修改亮度、對比度和飽和度:transforms.ColorJitter
- 轉灰度圖: transforms.Grayscale
- 線性變換: transforms.LinearTransformation()
- 仿射變換: transforms.RandomAffine
- 依概率
p轉為灰度圖: transforms.RandomGrayscale - 將資料轉換為
PILImage: transforms.ToPILImage - transforms.Lambda: Apply a user-defined lambda as a transform.
4,對 transforms 操作,使資料增強更靈活
transforms.RandomChoice(transforms): 從給定的一系列 transforms 中選一個進行操作transforms.RandomApply(transforms, p=0.5): 給一個 transform 加上概率,依概率進行操作transforms.RandomOrder: 將 transforms 中的操作隨機打亂
這裡 resize 影象增強方法為例,視覺化其調整輸入影象大小的效果。
# 為了節省空間,這裡不再列出匯入相應庫的程式碼和show_images函數
img_PIL = Image.open('astronaut.jpeg')
print(img_PIL.size)
# if you change the seed, make sure that the randomly-applied transforms
# properly show that the image can be both transformed and *not* transformed!
torch.manual_seed(0)
# size 引數: desired output size.
resized_imgs = [transforms.Resize(size=size)(orig_img) for size in (30, 50, 100, orig_img.size)]
show_images(resized_imgs, 1, 4)
程式執行後的輸出圖如下。

3.3,imgaug 影象增強
imgaug 是一個用於機器學習實驗中影象增強的庫。 它支援廣泛的增強技術,允許輕鬆組合這些技術並以隨機順序或在多個 CPU 核心上執行它們,具有簡單而強大的隨機介面,不僅可以增強影象,還可以增強關鍵點/地標、邊界框、 熱圖和分割圖。
單個輸入影象的範例增強如下所示。

imgaug 的影象增強方法如下所示。
- Basics
- Keypoints
- Bounding Boxes
- Heatmaps
- Segmentation Maps and Masks
- Stochastic Parameters: 隨機引數
- Blending/Overlaying images: 混合/疊加影象
- Augmenters: 增強器概述
各個方法的使用請參考 imaug 官網。
參考資料
- A Simple Guide to Data Preprocessing in Machine Learning
- How to normalize images in PyTorch ?
- Data Normalization in Data Mining
- 《解析折積神經網路-第5、6章》
- 《OpenCV-Python-Toturial-中文版》
- scikit-learn-6.3. Preprocessing data
- numpy.ravel