帶你讀AI論文丨針對文字識別的多模態半監督方法
摘要:本文提出了一種針對文字識別的多模態半監督方法,具體來說,作者首先使用teacher-student網路進行半監督學習,然後在視覺、語意以及視覺和語意的融合特徵上,都進行了一致性約束。
本文分享自華為雲社群《一種針對文字識別的多模態半監督方法》,作者: Hint 。

摘要
直到最近,公開的真實場景文字影象的數量仍然不足以訓練場景文字識別器。因此,當前大多數的訓練方法都依賴於合成資料並以全監督的方式執行。然而,最近公開的真實場景文字影象的數量顯著增加,包括大量未標記的資料。利用這些資源需要半監督方法;然而,這些方法不能直接適配文字識別這類視覺語言的多模態結構。因此,本文提出了半監督多模態文字識別器(SemiMTR),它在訓練階段中,利用每個模態的未標記資料。此外,本文的方法並不需要額外的訓練階段,保持了當前的三階段多模態訓練策略。
首先,在視覺模型方面,本文提出了一個將自監督預訓練和強監督訓練結合的單階段訓練模型。然後,語言模型是在一個大型文字語料庫上進行自監督預訓練。得到兩個模態的預訓練模型之後,對文字識別進行半監督訓練。本文采用的是teacher-student的結構,具體來說,對一張文字影象分別進行弱資料擴增和強資料擴增,然後對兩個網路不同模態的輸出進行一致性約束。大量實驗證實本文的方法優於當前的訓練方案,並在多個場景文字識別基準上取得了最先進的結果。
方法
1. 識別模型框架:
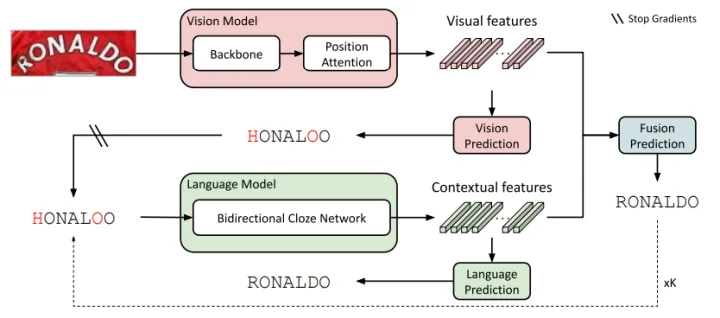
首先,本文的文字識別框架採用的是ABINet。大致流程如下:首先,視覺模型首先提取影象的特徵序列並將其解碼成字元序列;接著,將字元序列輸入給語言模型,得到文字的語意特徵;最後,使用一個融合模組,將視覺和語意特徵進行融合,得到最終的識別結果。為了進一步提高識別效能,可以採用迭代的方式,多次對識別結果進行微調。
2. 視覺模型預訓練
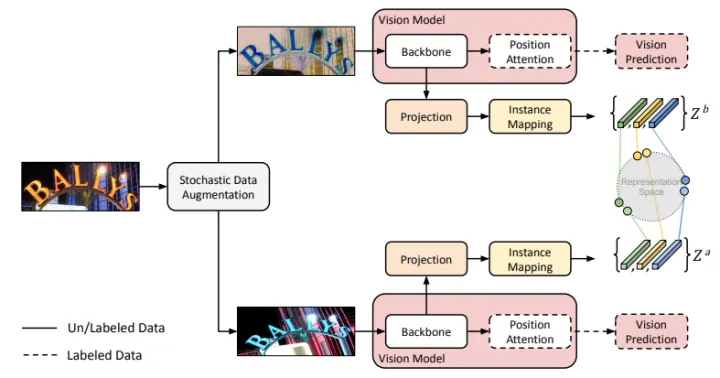
本文將自監督預訓練與強監督預訓練融合到了一個統一的框架下。自監督預訓練採用的是基於對比學習的方法,在自監督的同時,也會對這些資料進行有標註的強監督預訓練。
3. 基於一致性約束的半監督訓練
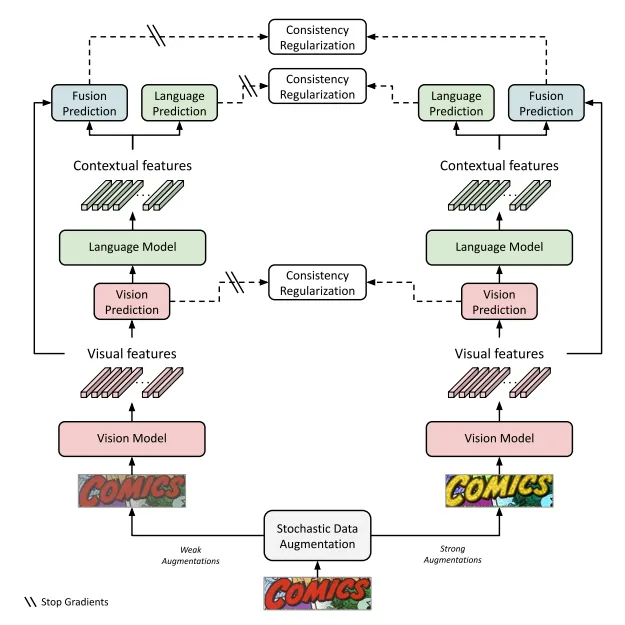
首先,本文采用的是一個常見的teacher-student網路,進行半監督訓練。具體來說,將前面得到的預訓練模型作為teacher和student網路的初始化模型,然後對同一張輸入影象進行弱資料擴增和強資料擴增,並分別輸入到teacher和student網路中;將teacher網路的預測結果作為偽標籤對student的輸出進行監督。區別於一般的半監督學習,本文的方法對識別模型的各個模態都進行不同程度的一致性約束,比如視覺模型,語言模型和融合模型的輸出。
實驗
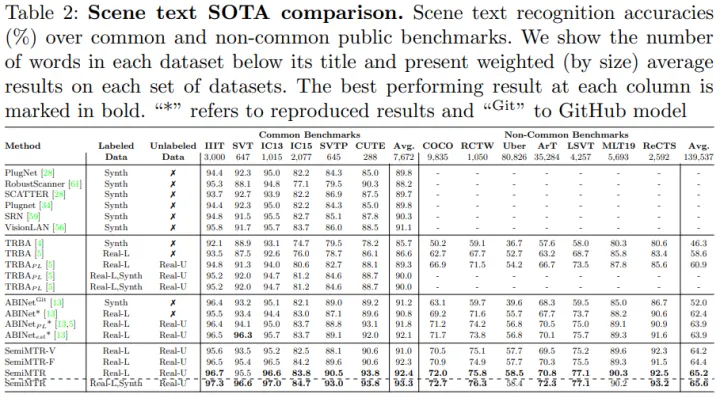
可以看到,本文的結果在多個資料集上取得了一致性的提升。

可以看到,在視覺預訓練階段,統一自監督預訓練和強監督預訓練比分階段的訓練效果要好。
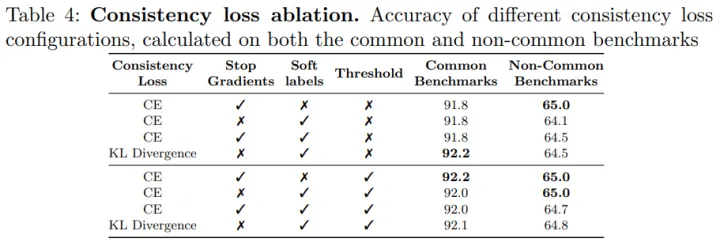
可以看到,使用交叉熵loss作為一致性約束loss效果最好。
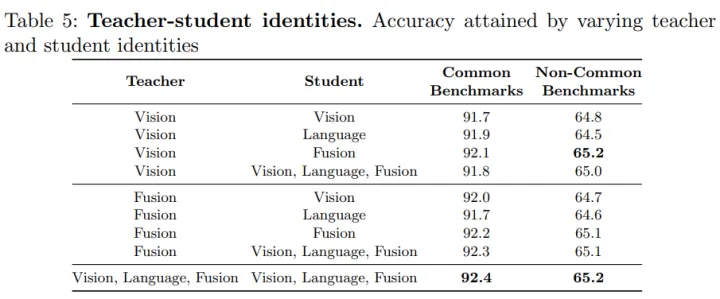
由於本文采用的識別模型,具有視覺、語言和融合的模態,所以在進行一致性約束的時候,teacher網路和student網路可以採用不同的特徵分別進行對齊。從上表可以看到,當teacher和student網路中的vision,language和fusion模組分別進行對齊的時候,效果最好。
論文連結:[2205.03873] Multimodal Semi-Supervised Learning for Text Recognition (arxiv.org)