Clickhouse表引擎探究-ReplacingMergeTree
作者:耿宏宇
1 表引擎簡述
1.1 官方描述
MergeTree 系列的引擎被設計用於插入極大量的資料到一張表當中。資料可以以資料片段的形式一個接著一個的快速寫入,資料片段在後臺按照一定的規則進行合併。相比在插入時不斷修改(重寫)已儲存的資料,這種策略會高效很多。
ReplacingMergeTree 引擎和 MergeTree 的不同之處在於它會刪除排序鍵值相同的重複項。
資料的去重只會在資料合併期間進行。合併會在後臺一個不確定的時間進行,因此你無法預先作出計劃。有一些資料可能仍未被處理。儘管你可以呼叫 OPTIMIZE 語句發起計劃外的合併,但請不要依靠它,因為 OPTIMIZE 語句會引發對資料的大量讀寫。
1.2 本地表語法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[PRIMARY KEY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
引數介紹
-
ver — 版本列。型別為 UInt*, Date 或 DateTime。可選引數。
在資料合併的時候,ReplacingMergeTree 從所有具有相同排序鍵的行中選擇一行留下:
1.如果 ver 列未指定,保留最後一條。
2.如果 ver 列已指定,保留 ver 值最大的版本。 -
PRIMARY KEY expr 主鍵。如果要 選擇與排序鍵不同的主鍵,在這裡指定,可選項。
預設情況下主鍵跟排序鍵(由 ORDER BY 子句指定)相同。 因此,大部分情況下不需要再專門指定一個 PRIMARY KEY 子句。 -
SAMPLE BY EXPR 用於抽樣的表示式,可選項
-
PARTITION BY expr 分割區鍵
-
ORDER BY expr 排序鍵
1.3 分割區表語法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
引數介紹
- cluster 叢集名
- table 遠端資料表名
- sharding_key 分片規則
- policy_name 規則名,它會被用作儲存臨時檔案以便非同步傳送資料
2 鍵的概念
Clickhouse的部署,分為單機模式和叢集模式,還可以開啟副本。兩種模式,資料表在建立語法、建立步驟和後續的使用方式上,存在一定的差異。

在定義表結構時,需要指定不同的鍵,作用如下。

分片:所有分片節點的權重加和得到S,可以理解為sharing動作取模的依據,權重X=W/S。分片鍵 Mod S 得到的值,與哪個分片節點匹配,則會寫入哪個分片。不同分片可能存在於不同的叢集節點,即便不同分片在同一節點,但ck在merge時,維度是同一分割區+同一分片,這是物理檔案的合併範圍。
如果我們權重分別設定為1,2,3 那麼總權重是6,那麼總區間就是[0,6),排在shard設定第一位的node01,權重佔比為1/6,所以屬於區間[0,1),排在shard設定第二位的node02,佔比2/6,所以區間為[1,3),至於最後的node03就是[3,6).所以如果rand()產生的數位除以6取餘落在哪個區間,資料就會分發到哪個shard,通過權重設定,可以實現資料按照想要的比重分配.
3 分片的作用
3.1 分片規則
在分散式模式下,ClickHouse會將資料分為多個分片,並且分佈到不同節點上。不同的分片策略在應對不同的SQL Pattern時,各有優勢。ClickHouse提供了豐富的- - - sharding策略,讓業務可以根據實際需求選用。
- random隨機分片:寫入資料會被隨機分發到分散式叢集中的某個節點上。
- constant固定分片:寫入資料會被分發到固定一個節點上。
- column value分片:按照某一列的值進行hash分片。
- 自定義表示式分片:指定任意合法表示式,根據表示式被計算後的值進行hash分片。
3.2 類比
以MySQL的分庫分表場景為例:
- 2個庫,1個表分4個子表,採用一主一從模式。
- db01包含tab-1和tab-2,db-2包含tab-3和tab-4;
- 在設定sharding規則時,需要設定分庫規則、分表規則;
一條記錄寫入時,會計算它要寫入哪個表、哪個庫,寫入的記錄會被從節點複製。
這個MySQL的例子,與CK的分割區+分片+副本在邏輯上基本一致。分割區理解為資料寫入哪個表,分片可以理解為資料寫入哪個庫,副本則是從節點的拷貝。
3.3 分片、分割區與副本
Clickhouse分片是叢集模式下的概念,可以類比MySQL的Sharding邏輯,副本是為了解決Sharing方案下的高可用場景所存在的。
下圖描述了一張Merge表的各類鍵的關係,也能反映出一條記錄的寫入過程。
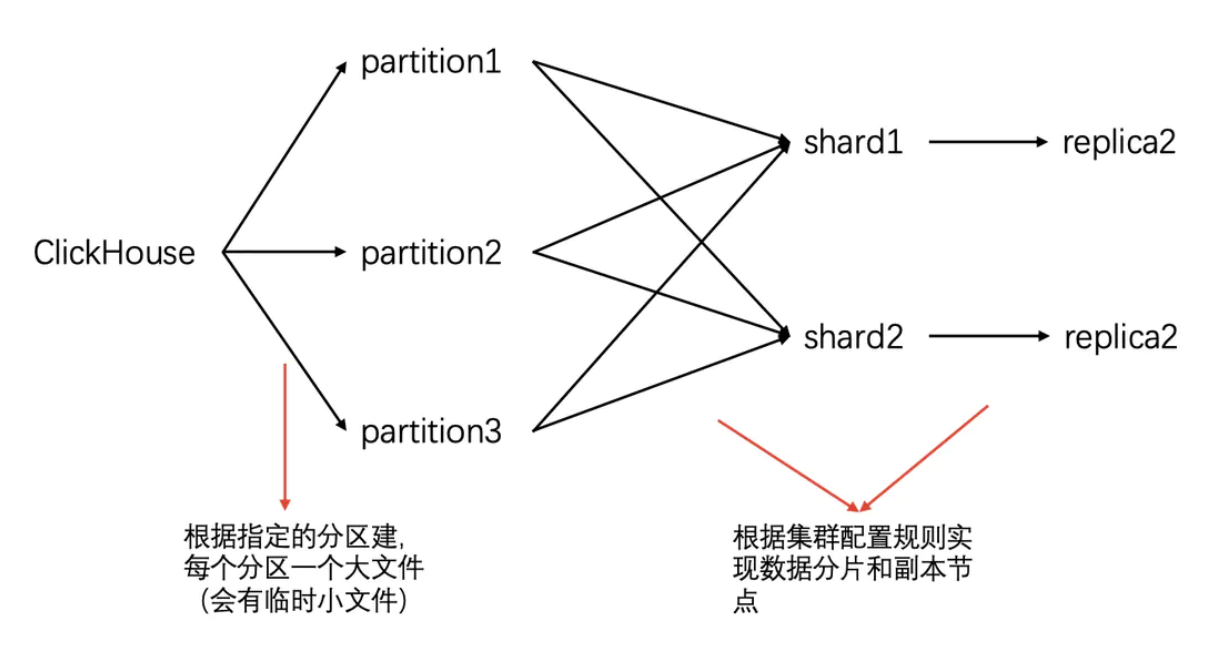
4 資料合併限制
理清了分割區與分片的概念,也就明白CK的資料合併,為什麼要限制相同分割區、相同分片,因為它們影響資料的儲存位置,merge操作只能針對相同物理位置(分割區目錄)的資料進行操作,而分片會影響資料儲存在哪個節點上。
一句話,使用CK的ReplacingMergeTree引擎的去重特性,期望去重的資料,必須滿足擁有 相同排序鍵、同一分割區、同一分片。
接下來針對這一要求,在資料上進行驗證。
5 資料驗證
5.1 場景設定
這裡是要驗證上面的結論,「期望去重的資料,必須滿足在相同排序鍵、同一分割區、同一分片」;
首先擁有相同排序鍵才會在merge操作時進行判斷為重複,因此保證測試資料的排序鍵相同;剩餘待測試場景則是分割區與分片。
由此進行場景設定:
- 相同記錄,能夠寫入同一分割區、同一分片
- 相同記錄,能夠寫入同一分割區,不同分片
- 相同記錄,能夠寫入不同分割區,不同分片
- 相同記錄,能夠寫入不同分割區、相同分片
再疊加同步寫入方式: - 直接寫本地表
- 直接寫分散式表
補充:分割區鍵與分片鍵,是否必須相同?
5.2 第一天測試
場景1: 相同記錄,能夠寫入同一分割區、同一分片
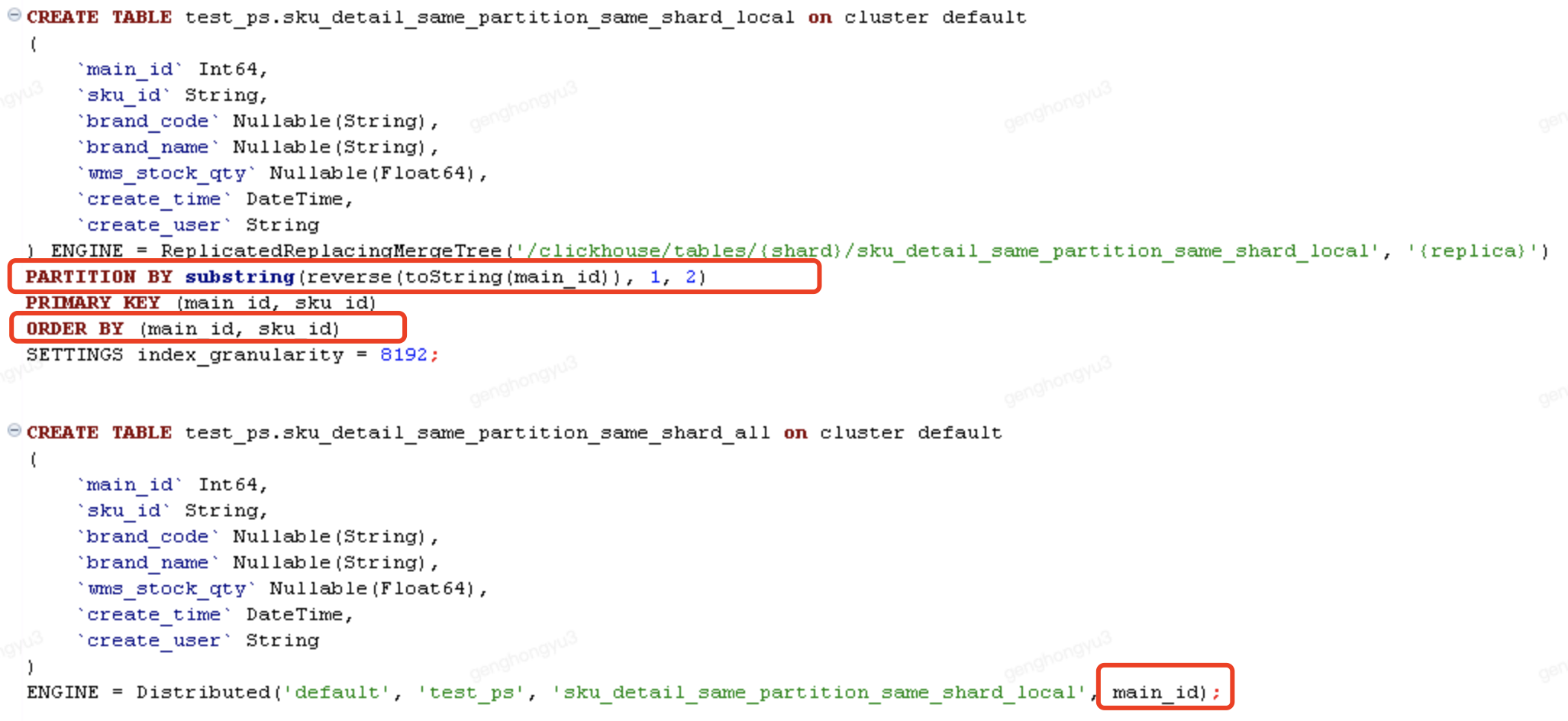
一次執行3條插入,插入本地表
[main_id=101,sku_id=SKU0002;barnd_code=BC01,BC02,BC03]
select * from test_ps.sku_detail_same_partition_same_shard_all;

分三次執行,插入本地表
[main_id=101,sku_id=SKU0001;barnd_code=BC01,BC02,BC03]
select * from test_ps.sku_detail_same_partition_same_shard_all;

分三次執行,插入分散式表
[main_id=101,sku_id=SKU0001;barnd_code=BC001,BC002,BC003]
select * from test_ps.sku_detail_same_partition_same_shard_all;

select * from test_ps.sku_detail_same_partition_same_shard_all final;

結論1
1.採用分散式表插入資料,保證分片鍵、分割區鍵的值相同,才能保證merge去重成功
排除本地表插入場景
2.採用本地表插入資料,在分片鍵、分割區鍵相同的情況下,無法保證merge去重
- 在一個session(一次提交)裡面包含多個記錄,直接會得到一條記錄,插入過程去重
在第一次insert時,準備的3條insert語句是一次執行的,查詢後只有1條記錄。 - 在多個session(多次提交)記錄,不會直接去重,但有可能寫到不同叢集節點,導致無法去重
分3次執行3條insert語句,查詢後有3條記錄,且通過final查詢後有2條記錄,合併去重的那2條記錄是寫入在同一叢集節點。【參考SKU0002的執行結果】
後面直接驗證插入分散式表場景。
場景2:相同記錄,能夠寫入同一分割區,不同分片
- 分片鍵採用的rand()方式,隨機生成。
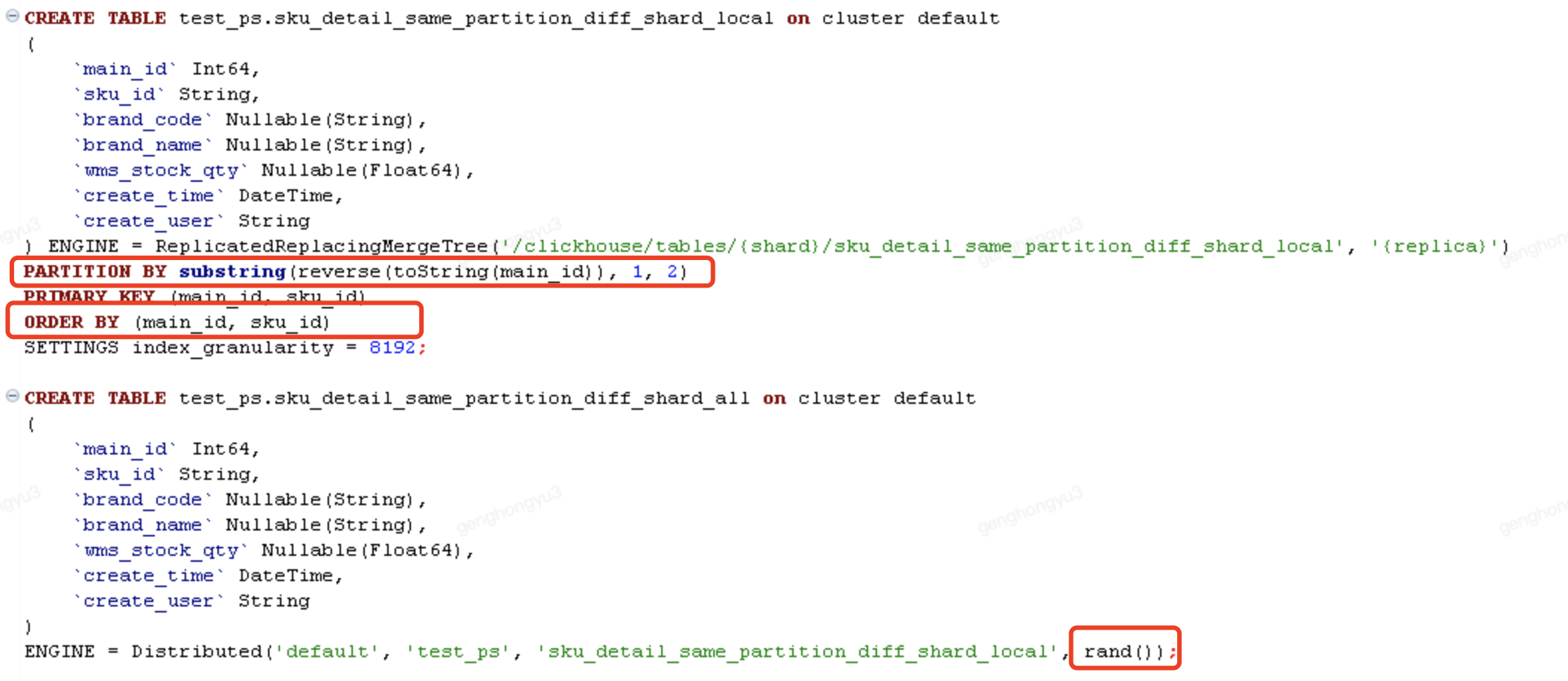
分三次執行,插入分散式表
[main_id=103,sku_id=SKU0003;barnd_code=BC301,BC302,BC303]
檢查資料插入狀態
select * from test_ps.sku_detail_same_partition_diff_shard_all where main_id =103 ;

檢查merge的去重結果
select * from test_ps.sku_detail_same_partition_diff_shard_all final where main_id =103 ;

分五次執行,插入分散式表
[main_id=104,sku_id=SKU0004;barnd_code=BC401,BC402,BC403,BC404,BC405]
檢查資料插入狀態
select * from test_ps.sku_detail_same_partition_diff_shard_all where main_id =104 ;

檢查merge的去重結果
select * from test_ps.sku_detail_same_partition_diff_shard_all final where main_id =104 ;

結論2
採用分散式表插入資料,保證分割區鍵的值相同、分片鍵的值隨機,無法保證merge去重
- 如果插入記錄時,通過rand()生成的數位取模後的值一樣,很幸運最終可以merge去重成功
- 如果插入記錄時,通過rand()生成的數位取模後的值不一樣,最終無法通過merge去重
場景3:相同記錄,能夠寫入不同分割區,不同分片
- 分片鍵採用的rand()方式,隨機生成;
- 分割區鍵為了方便測試,採用建立時間。
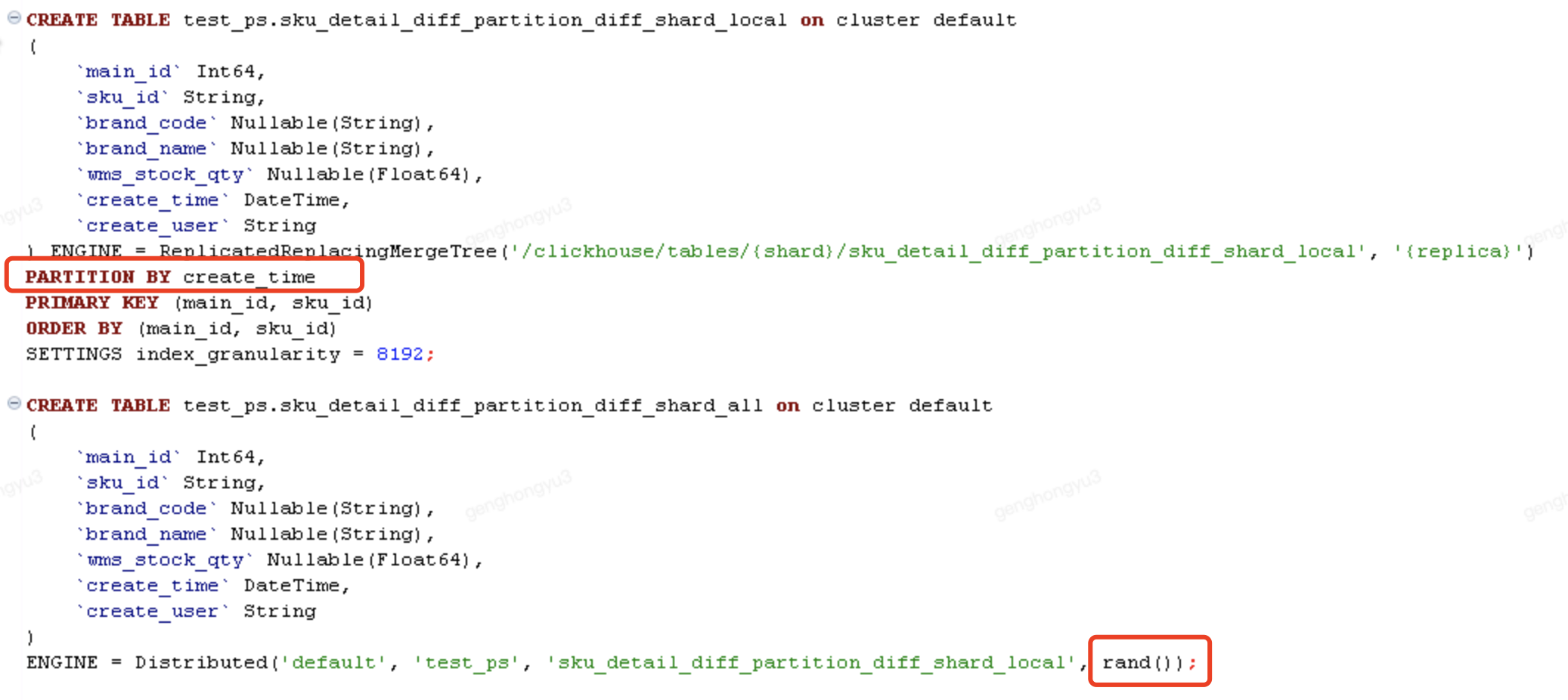
分五次執行,插入分散式表
[main_id=105,sku_id=SKU0005;barnd_code=BC501,BC502,BC503,BC504,BC505]
檢查資料插入狀態
select * from test_ps.sku_detail_diff_partition_diff_shard_all where main_id =105 ;

檢查merge的去重結果
select * from test_ps.sku_detail_diff_partition_diff_shard_all final where main_id =105;

結論3
採用分散式表插入資料,分割區鍵的值與排序鍵不一致、分片鍵的值隨機,無法保證merge去重
- 按當前測試結果,雖然create_time都不相同,也就是分割區不同,也發生了資料合併
- 資料發生合併,但結果並不是完全按排序鍵進行合併的
場景4:相同記錄,能夠寫入 不同分割區、相同分片
- 分片鍵採用main_id;
- 分割區鍵為了方便測試,採用建立時間。
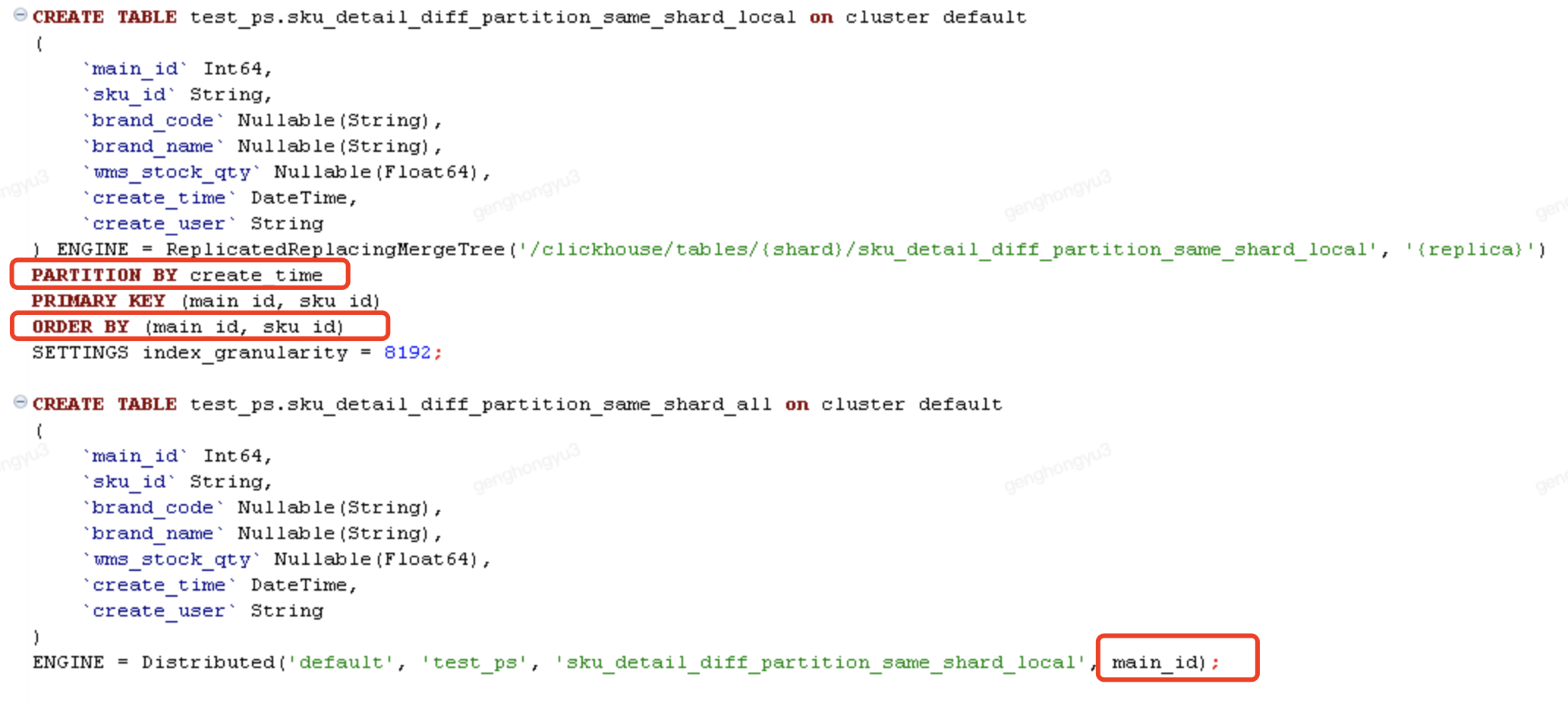
分六次執行,插入分散式表
[main_id=106,sku_id=SKU0006;barnd_code=BC601,BC602,BC603,BC604,BC605,BC606]
檢查資料插入狀態
select * from test_ps.sku_detail_diff_partition_same_shard_all where main_id =106 ;

檢查merge的去重結果
select * from test_ps.sku_detail_diff_partition_same_shard_all final where main_id =106;

此場景,經過第二天檢索,資料並沒有進行merge,而是用final關鍵字依然能檢索出去重後的結果。也就是說final關鍵字只是在記憶體中進行去重,由於所在分割區不同,檔案是沒有進行merge合併的,也就沒有去重。反觀相同分割區、相同分片的資料表,資料已經完成了merge合併,普通檢索只能得到一條記錄。
結論4
採用分散式表插入資料,分割區鍵的值與排序鍵不一致、分片鍵的值固定,無法實現merge去重
5.3 第二天檢查
以下均採用普通查詢,發現如下情況
- 分片不同的表,其資料沒有合併
- 分片相同、分割區不同的沒有合併
- 分片相同、分割區相同的已經完成了合併
select * from test_ps.sku_detail_same_partition_same_shard_all;

select * from test_ps.sku_detail_same_partition_diff_shard_all;

select * from test_ps.sku_detail_diff_partition_diff_shard_all;

select * from test_ps.sku_detail_diff_partition_same_shard_all;
6 總結
根據測試結果,在不同場景下的合併情況:
- 如果資料存在在相同分片,且相同分割區,絕對可以實現合併去重。
- 如果資料儲存在不同分片,不同分割區,將不會進行合併去重。
- 如果資料儲存在不同分片,但同一分片內保證在相同分割區,會進行此分片下的merge去重。
- 如果資料存在在相同分片,但不同分割區,不會進行merge去重,但通過final關鍵字可以在CK記憶體中對相同分割區、相同分片的資料進行去重。
在Clickhouse的ReplacingMergeTree進行merge操作時,是根據排序鍵(order by)來識別是否重複、是否需要合併。而分割區和分片,影響的是資料的儲存位置,在哪個叢集節點、在哪個檔案目錄。那麼最終ReplacingMergeTree表引擎在合併時,只會在當前節點、且物理位置在同一表目錄下的資料進行merge操作。
最後,我們在設計表時,如果期望利用到ReplacingMergeTree自動去重的特性,那麼必須使其儲存在相同分割區、相同分片下; 而在設定分割區鍵、分片鍵時,二者不要求必須相同,但必須穩定,穩定的含義是入參相同出參必須相同。