分散式註冊服務中心etcd在雲原生引擎中的實踐
作者:王雷
etcd是什麼
etcd是雲原生架構中重要的基礎元件,由CNCF孵化託管。ETCD是用於共用設定和服務發現的分散式,一致性的KV儲存系統,是CoreOS公司發起的一個開源專案,授權協定為Apache。etcd 基於Go語言實現,主要用於共用設定,服務發現,叢集監控,leader選舉,分散式鎖等場景。在微服務和 Kubernates 叢集中不僅可以作為服務註冊發現,還可以作為 key-value 儲存的中介軟體。
提到鍵值儲存系統,在巨量資料領域應用最多的當屬ZOOKEEPER,而ETCD可以算得上是後起之秀了。在專案實現,一致性協定易理解性,運維,安全等多個維度上,ETCD相比Zookeeper都佔據優勢。
ETCD vs ZK
| ETCD | ZK | |
|---|---|---|
| 一致性協定 | Raft協定 | ZAB(類Paxos協定) |
| 運維方面 | 方便運維 | 難以運維 |
| 專案活躍度 | 活躍 | 沒有etcd活躍 |
| API | ETCD提供HTTP+JSON, gRPC介面,跨平臺跨語言 | ZK需要使用其使用者端 |
| 存取安全方面 | ETCD支援HTTPS存取 | ZK在這方面不支援 |
etcd的架構
etcd 是一個分散式的、可靠的 key-value 儲存系統,它用於儲存分散式系統中的關鍵資料,這個定義非常重要。
通過下面這個指令,瞭解一下etcd命令的執行流程,其中etcdctl:是一個使用者端,用來操作etcd。
etcdctl put key test
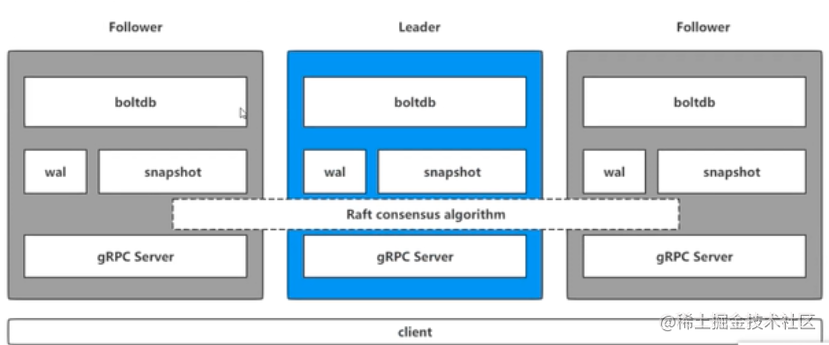
通常etcd都是以叢集的方式來提供服務的,etcdctl操作命令的時候,會對應到leader當中的gRPC Server
gRPC Server
用來接收使用者端具體的請求進行處理,但是不僅僅是處理使用者端的連線,它同時負責處理叢集當中節點之間的通訊。
wal: Write Ahead Log(預寫式紀錄檔)
etcd 的資料儲存方式。除了在記憶體中存有所有資料的狀態以及節點的索引以外,etcd 就通過 WAL 進行持久化儲存。WAL 中,所有的資料提交前都會事先記錄紀錄檔。實現事務紀錄檔的標準方法;執行寫操作前先寫紀錄檔,跟mysql中redo類似,wal實現的是順序寫。
當執行put操作時,會修改etcd資料的狀態,執行具體的修改的操作,wal是一個紀錄檔,在修改資料庫狀態的時候,會先修改紀錄檔。put key test會在wal記錄紀錄檔,然後會進行廣播,廣播給叢集當中其他的節點設定key的紀錄檔。其他節點之後會返回leader是否同意資料的修改,當leader收到一半的請求,就會把值刷到磁碟中。
snapshot
etcd 防止 WAL 檔案過多而設定的快照,用於儲存某一時刻etcd的所有資料。Snapshot 和 WAL 相結合,etcd 可以有效地進行資料儲存和節點故障恢復等操作。
boltdb
相當於mysql當中的儲存引擎,etcd中的每個key都會建立一個索引,對應一個B+樹。
etcd重要的特性
•儲存:資料分層儲存在檔案目錄中,類似於我們日常使用的檔案系統;
•Watch 機制:Watch 指定的鍵、字首目錄的更改,並對更改時間進行通知;
•安全通訊:支援 SSL 證書驗證;
•高效能:etcd 單範例可以支援 2K/s 讀操作,官方也有提供基準測試指令碼;
•一致可靠:基於 Raft 共識演演算法,實現分散式系統內部資料儲存、服務呼叫的一致性和高可用性;
•Revision 機制:每個 Key 帶有一個 Revision 號,每進行一次事務便加一,因此它是全域性唯一的,如初始值為 0,進行一次 Put 操作,Key 的 Revision 變為 1,同樣的操作,再進行一次,Revision 變為 2;換成 Key1 進行 Put 操作,Revision 將變為 3。這種機制有一個作用,即通過 Revision 的大小就可知道寫操作的順序,這對於實現公平鎖,佇列十分有益;
•lease機制:lease 是分散式系統中一個常見的概念,用於代表一個分散式租約。典型情況下,在分散式系統中需要去檢測一個節點是否存活的時,就需要租約機制。
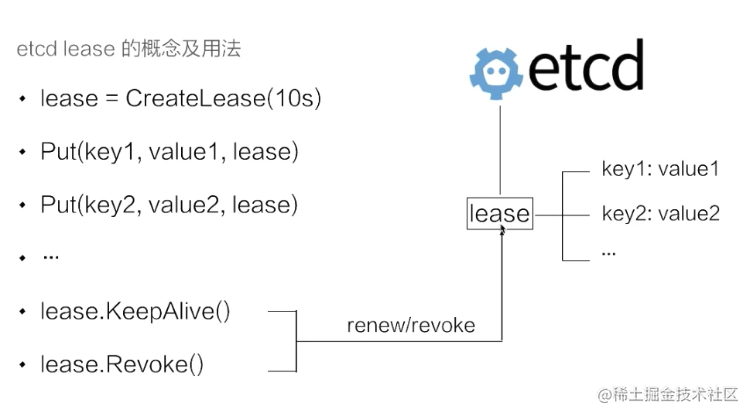
首先建立了一個 10s 的租約,如果建立租約後不做任何的操作,那麼 10s 之後,這個租約就會自動過期。接著將 key1 和 key2 兩個 key value 繫結到這個租約之上,這樣當租約過期時 etcd 就會自動清理掉 key1 和 key2,使得節點 key1 和 key2 具備了超時自動刪除的能力。
如果希望這個租約永不過期,需要週期性的呼叫 KeeyAlive 方法重新整理租約。比如說需要檢測分散式系統中一個程序是否存活,可以在程序中去建立一個租約,並在該程序中週期性的呼叫 KeepAlive 的方法。如果一切正常,該節點的租約會一致保持,如果這個程序掛掉了,最終這個租約就會自動過期。
類比redis的expire,redis expore key ttl,如果key過期的話,到了過期時間,redis會刪除這個key。etcd的實現:將過期時間相同的key全部繫結一個全域性的物件,去管理過期,etcd只需要檢測這個物件的過期。通過多個 key 繫結在同一個 lease 的模式,我們可以將超時間相似的 key 聚合在一起,從而大幅減小租約重新整理的開銷,在不失靈活性同時能夠大幅提高 etcd 支援的使用規模。
在引擎中的場景
服務註冊發現
etcd基於Raft演演算法,能夠有力的保證分散式場景中的一致性。各個服務啟動時註冊到etcd上,同時為這些服務設定鍵的TTL時間。註冊到etcd上的各個服務範例通過心跳的方式定期續租,實現服務範例的狀態監控。服務提供方在 etcd 指定的目錄(字首機制支援)下注冊服務,服務呼叫方在對應的目錄下查詢服務。通過 watch 機制,服務呼叫方還可以監測服務的變化。
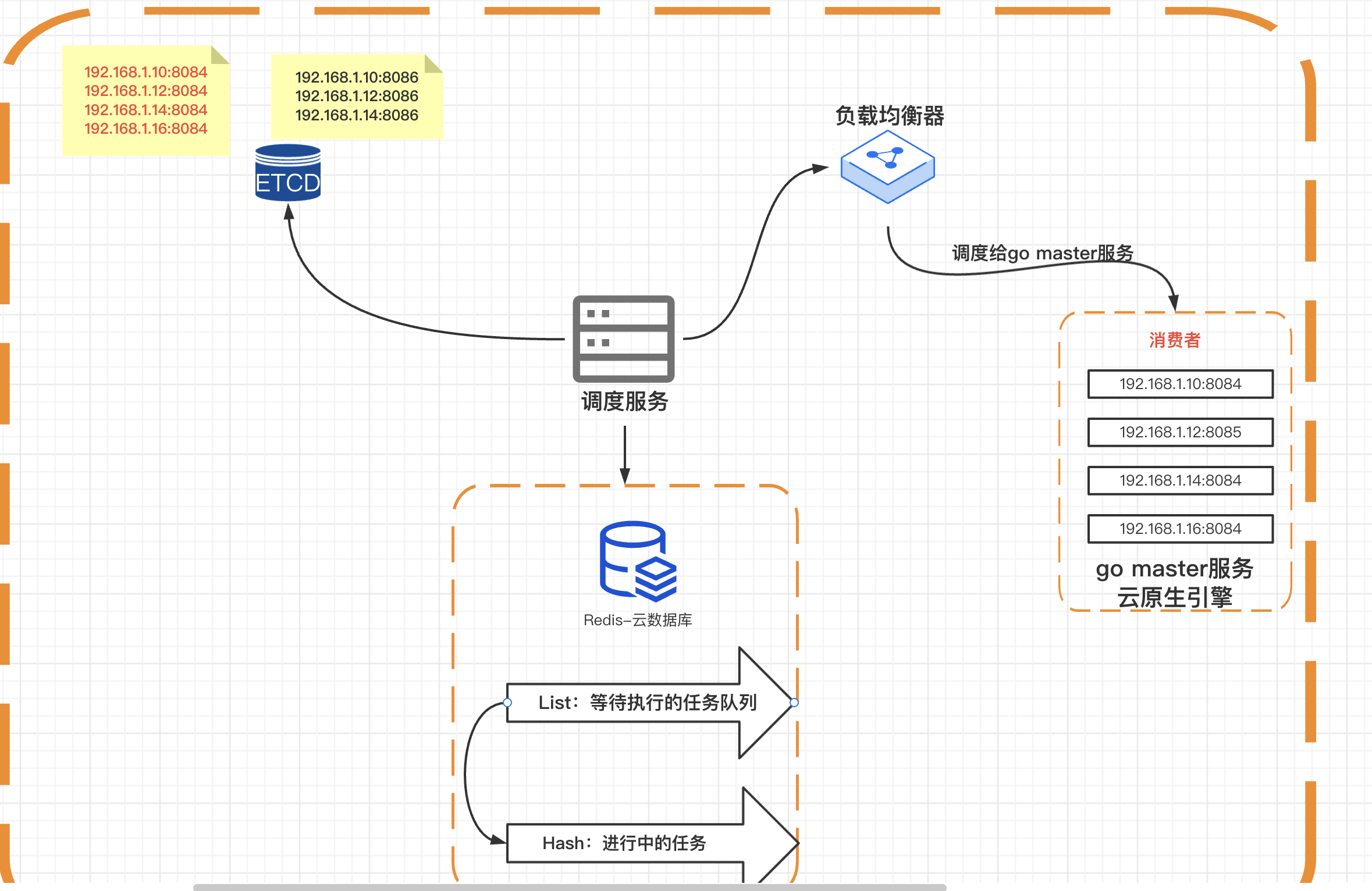
引擎服務包含兩大模組,一個是master服務,一個是排程服務。
master服務
master服務啟動成功後,向etcd註冊服務,並且定時向etcd傳送心跳
server, err := NewServiceRegister(key, serviceAddress, 5)
if err != nil {
logging.WebLog.Error(err)
}
定時向etcd傳送心跳
//設定續租 定期傳送需求請求
leaseRespChan, err := s.cli.KeepAlive(context.Background(), resp.ID)
排程服務
排程服務作為服務的消費者,監聽服務目錄:key=/publictest/pipeline/
// 從etcd中訂閱字首為 "/pipeline/" 的服務
go etcdv3client.SubscribeService("/publictest/pipeline/", setting.Conf.EtcdConfig)
監聽put和delete操作,同時在本地維護serverslist,如果有put或者delete操作,會更新原生的serverslist
使用者端發現指使用者端直接連線註冊中心,獲取服務資訊,自己實現負載均衡,使用一種負載均衡策略發起請求。優勢可以客製化化發現策略與負載均衡策略,劣勢也很明顯,每一個使用者端都需要實現對應的服務發現和負載均衡。
watch機制
etcd可以Watch 指定的鍵、字首目錄的更改,並對更改時間進行通知。BASE引擎中,快取的清除策略藉助etcd來實現。
快取過期策略:在編譯加速的實現中,每個需要快取的專案都有對應的快取key,通過etcd監控key,並且設定過期時間,例如7天,如果在7天之內再次命中key,則通過lease進行續約;7天之內key都沒有被使用,key就會過期刪除,通過監聽對應的字首,在過期刪除的時候,呼叫刪除快取的方法。
storage.Watch("cache/",
func(id string) {
//do nothing
},
func(id string) {
CleanCache(id)
})
除此之外,引擎在流水線取消和人工確認超時的場景中,也使用到了etcd的watch機制,監聽某一個字首的key,如果key發生了變化,進行相應的邏輯處理。
叢集監控與****leader選舉機制
叢集監控:通過 etcd 的 watch 機制,當某個 key 消失或變動時,watcher 會第一時間發現並告知使用者。節點可以為 key 設定租約(TTL),比如每隔 30 s 向 etcd 傳送一次心跳續約,使代表該節點的 key 保持存活,一旦節點故障,續約停止,對應的 key 將失效刪除。如此,通過 watch 機制就可以第一時間檢測到各節點的健康狀態,以完成叢集的監控要求。
Leader 競選:使用分散式鎖,可以很好地實現 Leader 競選(搶鎖成功的成為 Leader)。Leader 應用的經典場景是在搜尋系統中建立全量索引。如果每個機器分別進行索引建立,不僅耗時,而且不能保證索引的一致性。通過在 etcd 實現的鎖機制競選 Leader,由 Leader 進行索引計算,再將計算結果分發到其它節點。
類似kafka的controller選舉,引擎的排程服務啟動,所有的服務都註冊到etcd的/leader下面,其中最先註冊成功的節點成為leader節點,其他節點自動變成follow。
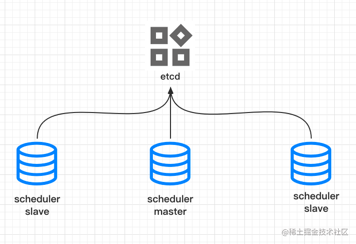
leader節點負責從redis中獲取任務,根據負載均衡演演算法,將任務派發給對應的go master服務。
follow節點監聽leader節點的狀態,如果leader節點服務不可用,對應節點刪除,follow節點會重新搶佔,成為新的leader節點。
同時leader設定在etcd中的leader標識設定過期時間為60s,leader每隔30s更新一次。follow每隔30s到etcd中通告自己存活,並檢查leader存活。