RocketMQ Schema——讓訊息成為流動的結構化資料
本文作者:許奕斌,阿里雲智慧高階研發工程師。
Why we need schema
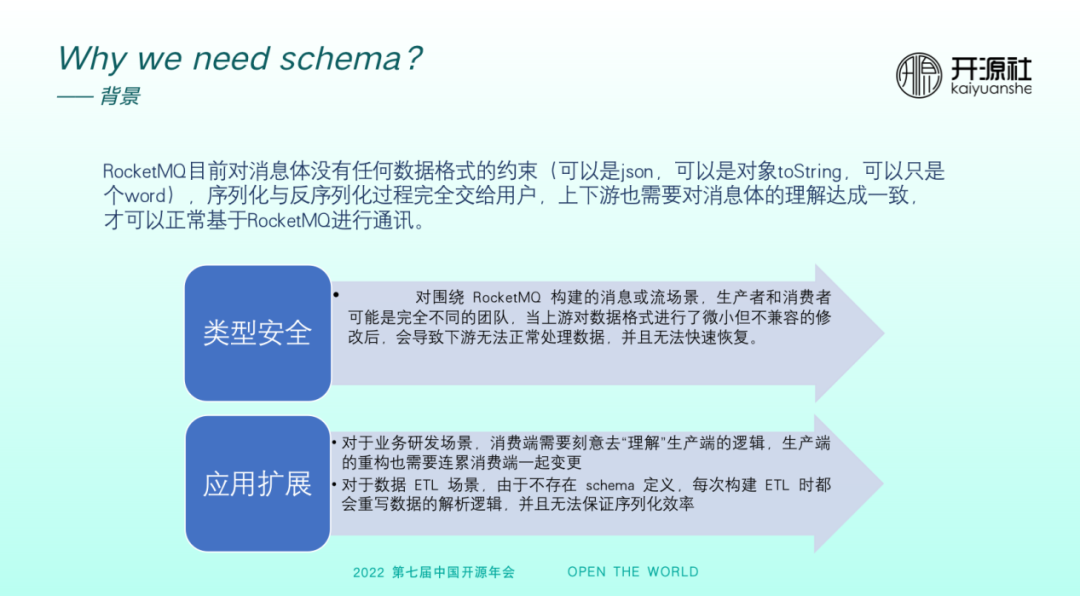
RocketMQ 目前對於訊息體沒有任何資料格式的約束,可以是 JSON ,可以是物件 toString ,也可以只是 word 或一段紀錄檔,序列化與反序列化過程完全交給使用者。業務上下游也需要對於訊息體的理解達成一致,方可基於 RocketMQ 進行通訊。而以上現狀會導致兩個問題。
首先,型別安全問題。假如生產者或消費者來自完全不同的團隊,上游對資料格式進行了微小但不相容的改動,可能導致下游無法正常地處理資料,且恢復速度很慢。
其次,應用擴充套件問題。對於研發場景,雖然 RocketMQ 實現了鏈路上的解耦,但研發階段的上游與下游依然需要基於訊息理解做很多溝通和聯調,耦合依然較強,生產端的重構也需要連累消費端一起變更。對於資料流場景,如果沒有 schema 定義,每次在構建ETL時需要重寫整個資料解析邏輯。

RocketMQ schema 提供了對訊息的資料結構託管服務,同時也為原生使用者端提供了較為豐富的序列化/反序列化 SDK ,包括 Avro、JSON、PB等,補齊了 RocketMQ 在資料治理和業務上下游解耦方面的短板。
如上圖所示,在商業版 Kafka 上建立 topic 時,會提醒維護該 topic 相關 schema。如果維護了 schema ,業務上下游看到該 topic 時,能夠清晰地瞭解到需要傳入什麼資料,有效提升研發效率。
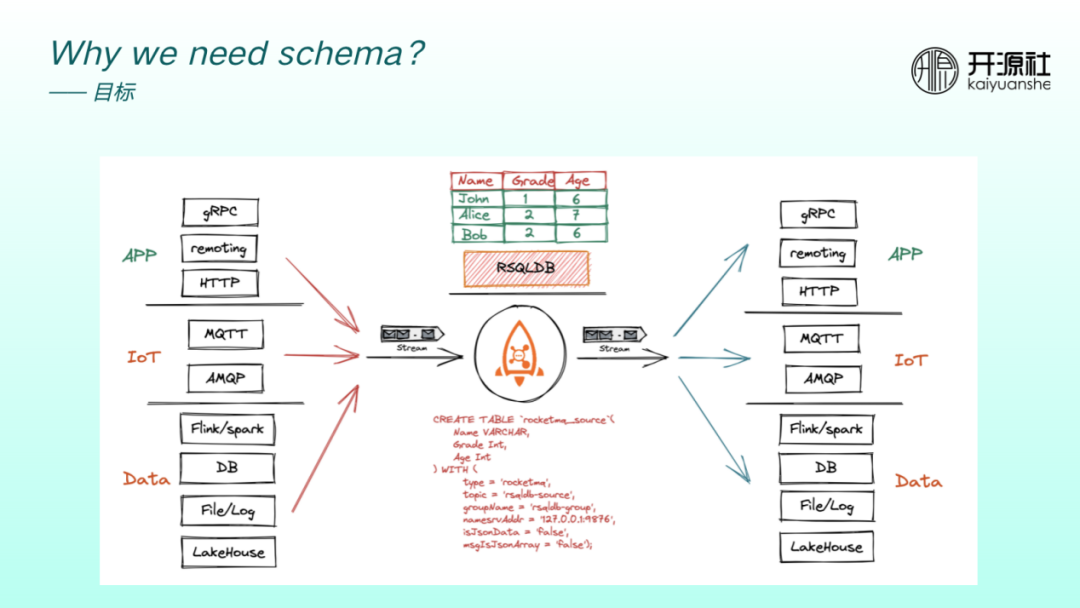
我們希望 RocketMQ 既能夠面向 App 業務場景,也能夠面向 IoT 微訊息場景,還能面向巨量資料場景,以成為整個企業的業務中樞。
加入 RSQLDB 之後,使用者可以用 SQL 方式分析 RocketMQ 資料。RocketMQ 既可以作為通訊管道,具備管道的流特性,又可以作為資料沉澱,即具備資料庫特性。如果 RocketMQ 要同時向流式引擎和 DB 引擎靠近,其資料定義、規範以及治理變得異常重要。
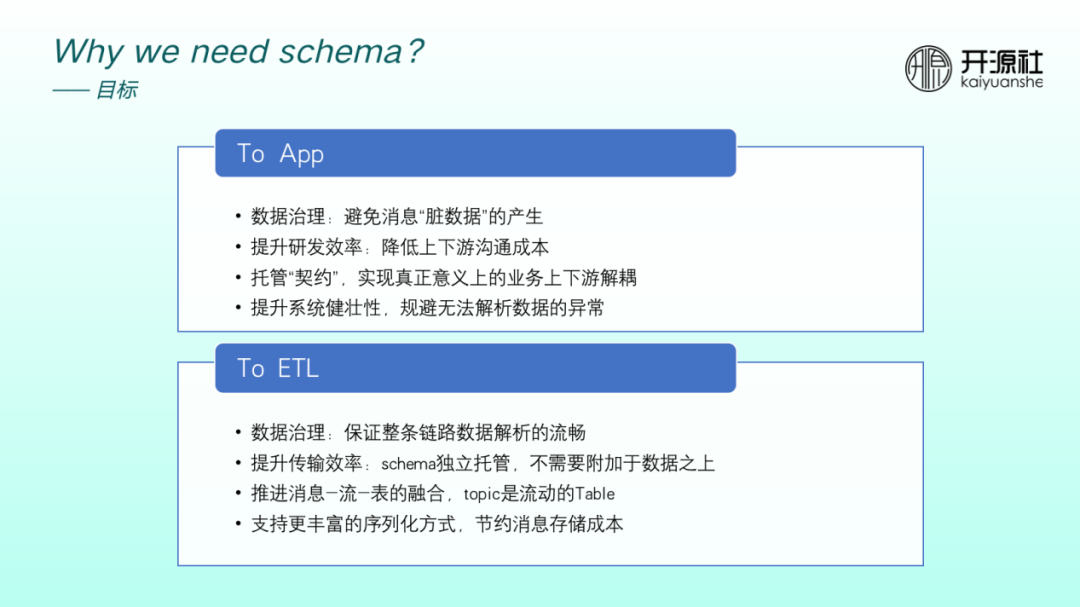
面對業務訊息場景時, 我們期望 RocketMQ 加入 schema 之後能夠擁有以下優勢:
①資料治理:避免訊息髒資料產生,避免 producer 產生格式不規範的訊息。
②提升研發效率:業務上下游研發階段或聯調階段溝通成本降低。
③託管「契約」:將契約託管後,可以實現真正意義上的業務上下游解耦。
④提升整個系統的健壯性:規避下游突然無法解析等資料異常。
面對流場景,我們期望 RocketMQ 具備下列優勢:
①資料治理:能夠保證整條鏈路資料解析的流暢性。
②提升傳輸效率:schema 獨立託管,無需附加到資料之上,提升了整個鏈路傳輸的效率。
③推進訊息-流-表的融合,topic 可以成為動態表。
④支援更豐富的序列化方式,節約訊息儲存成本。當前大部分業務場景均使用 JSON 解析資料,而巨量資料場景常用的 Avro 方式更能節省訊息儲存成本。
整體架構
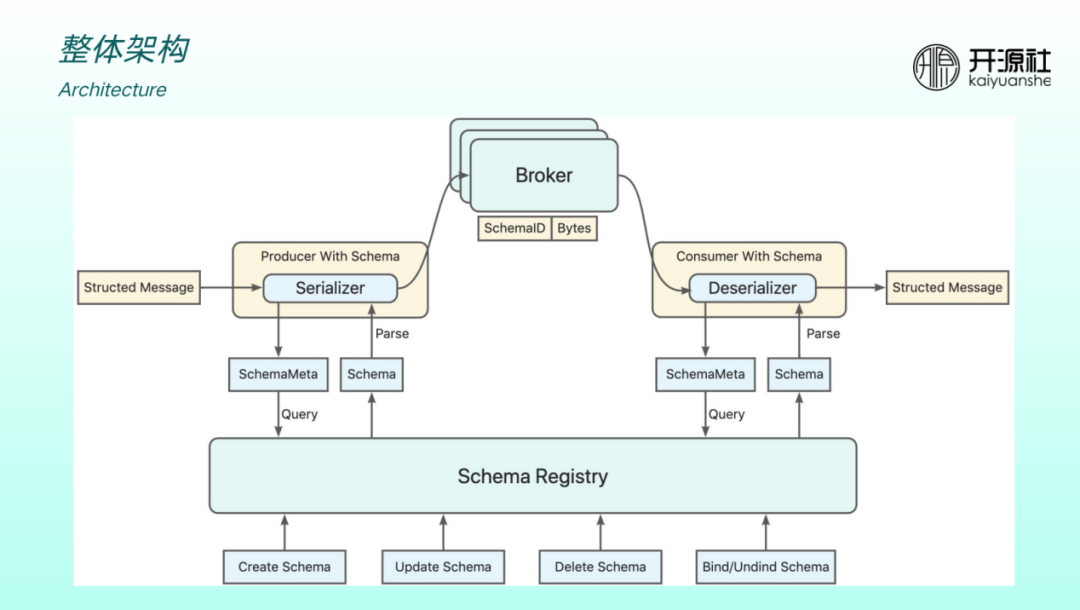
引入了 Schema Registry 後的整體架構如上圖所示。在原有最核心的 producer 、broker 和 Consumer 架構下引入 Schema Registry 用於託管訊息體的資料結構。
下層是 schema 的管理 API ,包括建立、更新、刪除、繫結等。與 producer 和 Consumer 的互動中,producer 傳送給 broker 之前會做序列化。序列化時會向 registey 查詢後設資料然後做解析。Consumer 側可以根據 ID 、topic 查詢,再做反序列化。RocketMQ 的使用者在收發訊息時只需要關心結構體,無需關心如何將資料序列化和反序列化。
伺服器端

Schema Registry 的部署方式與 NameServer 類似,與 broker 分離部署,因此 broker 不必強依賴於 Schema Registry ,採用了無狀態部署模式,可以動態擴縮容。持久化方面,預設使用 Compact Topic5.0 新特性,使用者也可自行實現儲存外掛,比如基於MySQL 或 Git 。管理介面上提供 Restful 介面做增刪改查,也支援 schema 與多個 topic 繫結\解綁。
應用啟動之後,提供了自帶 Swagger UI 做互動版本演進,提供 SchemaName 維度的版本演進和相應的相容性校驗,支援七種相容性策略。元資訊方面,每一個 schema 版本都會向用戶暴露全域性唯一 RecordID,使用者獲取到 RecordID 後可以到 registry 查詢唯一 schema 版本。
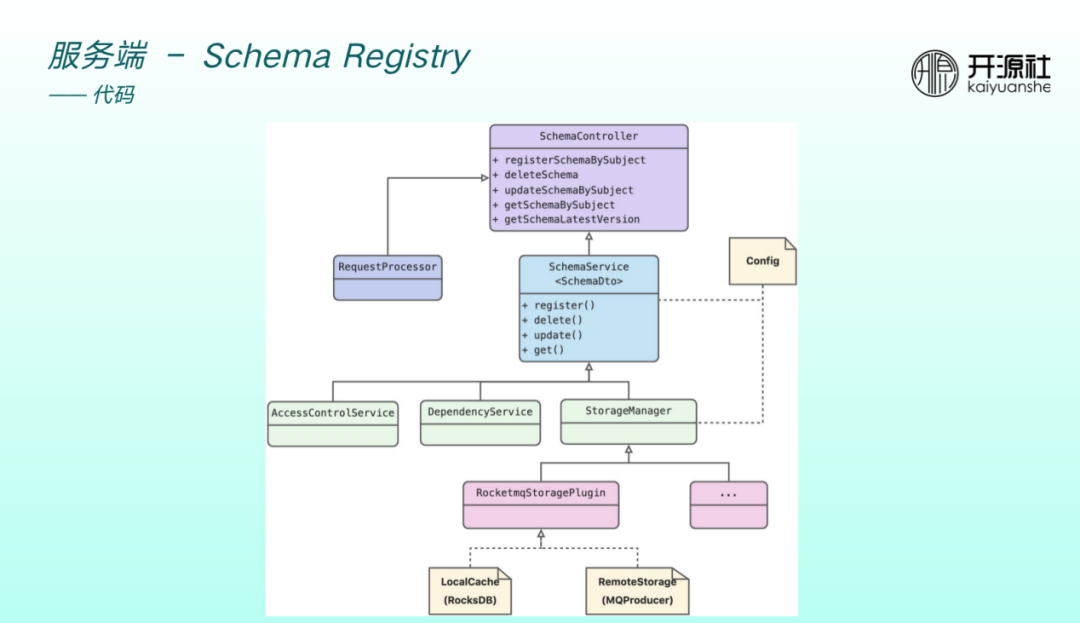
程式碼設計如上圖。主要為 spring boot 應用,暴露出一個 restful 介面。Controller 底下是 Service 層,涉及到許可權校驗、jar 包管理、StoreManager,其中 StoreManager 包括本地快取和遠端持久化。

Schema Registry 的核心概念與 RocketMQ 核心做了對齊。比如 registry 有 cluster 概念,對應核心中的 cluster,Tenant 對應 NameSpace 概念, subject 對應核心中的 topic。每一個 schema 有唯一名稱 SchemaName,使用者可以將自己應用的 Java 類名稱或全路徑名稱作為 SchemaName ,保證全域性唯一即可,可以繫結到 subject 上。每一個 schema 有唯一 ID ,通過伺服器端雪花演演算法生成。SchemaVersion 的每一次更新都不會改變 ID,但是會生成單調遞增的版本號,因此一個 schema 可以具備多個不同版本。
ID 和 version 疊加在一起生成了一個新概念 record ID ,暴露給使用者用於唯一定位某一個 schema 版本。SchemaType 包括 Avro、Json、Protobuf等常用序列化型別,IDL用於具體描述 schema 的結構化資訊。
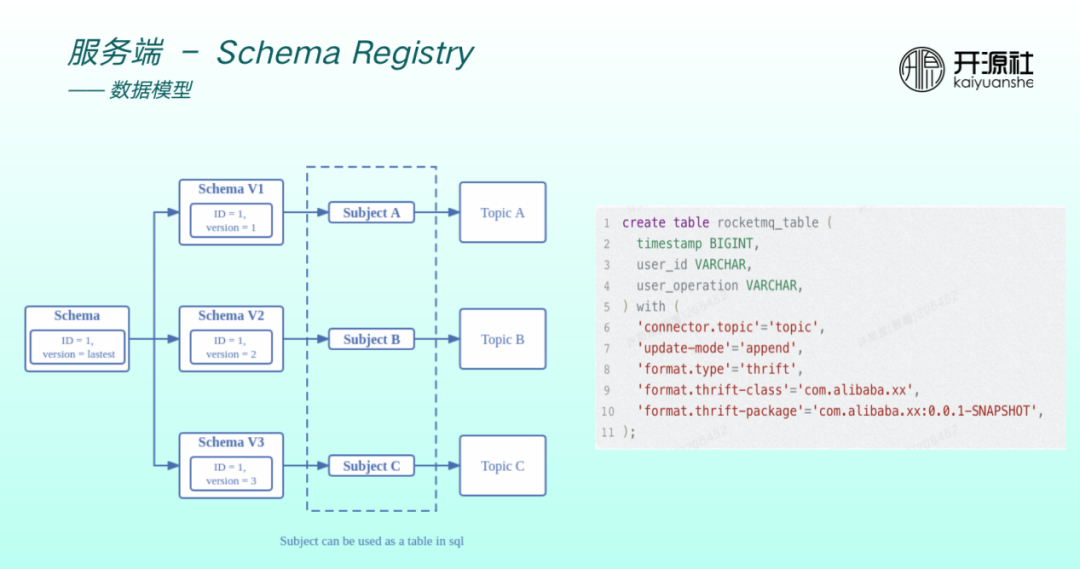
每一個 schema 有一個 ID,ID 保持不變,但可以有版本迭代,比如從 version 1 到 version 2 到 version 3,每一個 version 支援繫結不同的 subject 。Subject 可以近似地理解為 Flink table 。比如右圖為 使用Flink SQL 建立一張表,先建立 RocketMQ topic 註冊到 NameServer。因為有表結構,同時要建立 schema 註冊到 subject 上。因此,引入 schema 之後,可以與 Flink 等資料引擎做無縫相容。
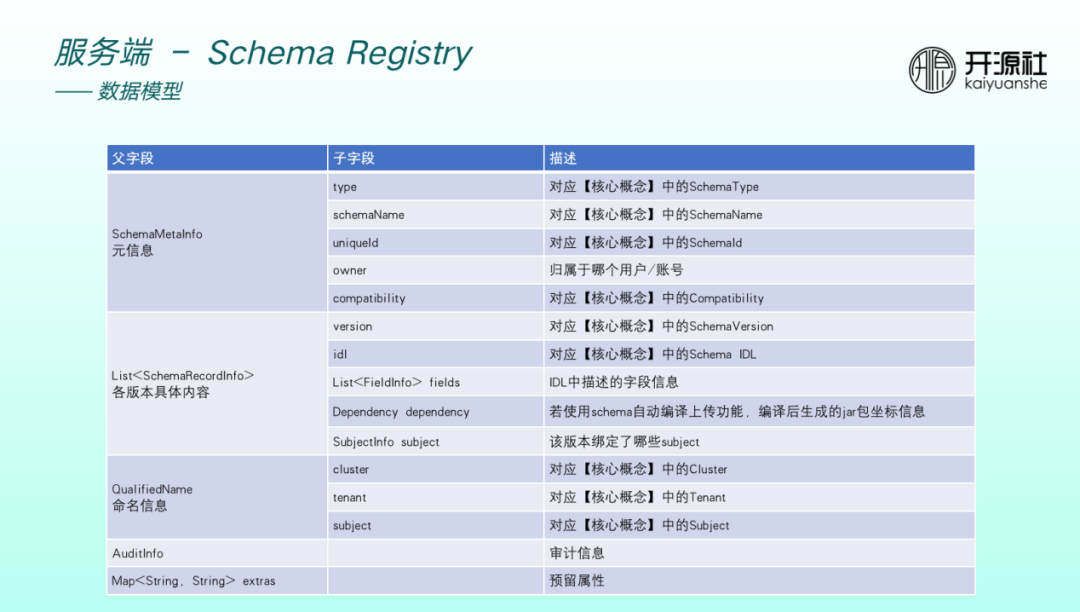
Schema 主要儲存以下型別的資訊。
- 元資訊:包括型別、名稱、 ID 、歸屬於以及相容性。
- 個版本具體內容:包括版本號、IDL、IDL中欄位、jar包資訊、繫結的 subject。
- 命名資訊:包括叢集、租戶、 subject。
- 審計資訊。
- 預留屬性。
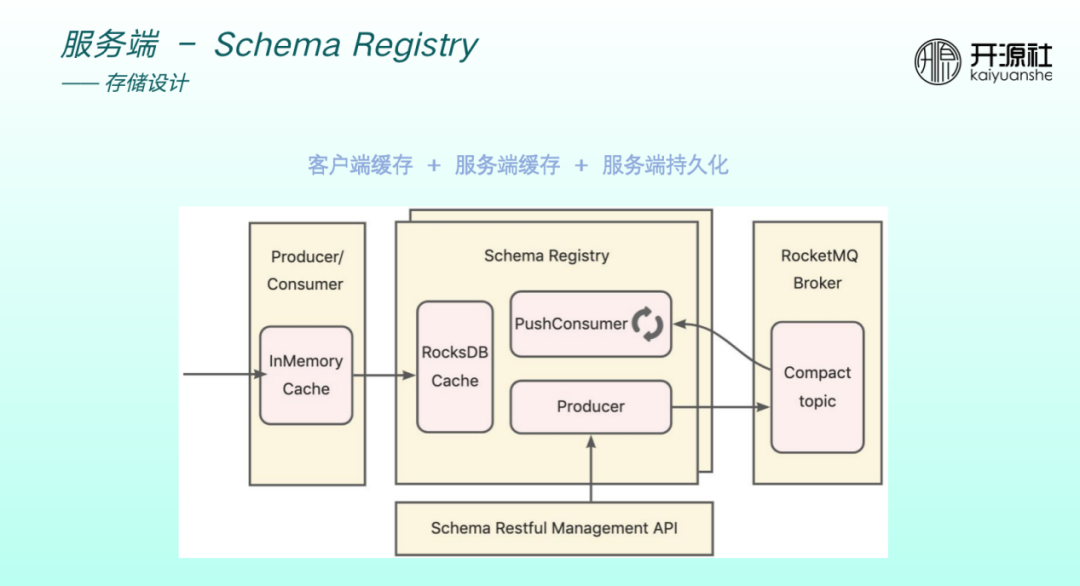
具體儲存設計分為三層。
使用者端快取:如果 producer Consumer 每一次收發訊息都要與 registy 互動,則非常影響效能和穩定性。因此RocketMQ實現了一層快取,schema 更新頻率比較低,快取可以滿足大部分收發訊息的請求。
伺服器端快取:通過 RocksDB 做了一層快取。得益於 RocksDB,服務重啟和升級均不會影響本身的資料。
伺服器端持久化:遠端儲存通過外掛化方式實現,使用 RocketMQ5.0 的 compact topic 特性,其本身能夠支援 KV 儲存的形式。
遠端持久化與本地快取同步通過 registey 的 PushConsumer 做監聽和同步。
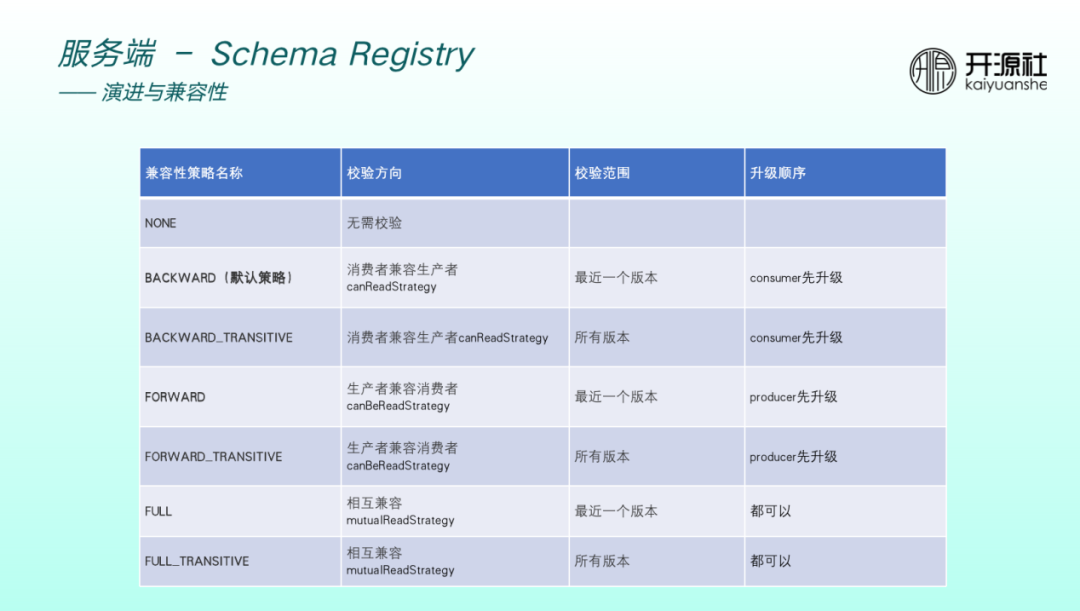
目前 Schema Registry 支援7種相容性策略。預設為 backward ,小米公司內部實踐也驗證了預設策略基本夠用。校驗方向為消費者相容生產者,即演進了 schema 之後,是需要先升級Consumer ,Consumer 的高版本可以相容生產者的低版本。
如果相容策略是 backward_transative ,則可以相容生產者的所有版本。

介面設計均遵循 Open Schema 標準,啟動 registry 服務之後,只要存取 local host 的 swagger UI 頁面即可發起http請求,自己做 schema 管理。
使用者端設計
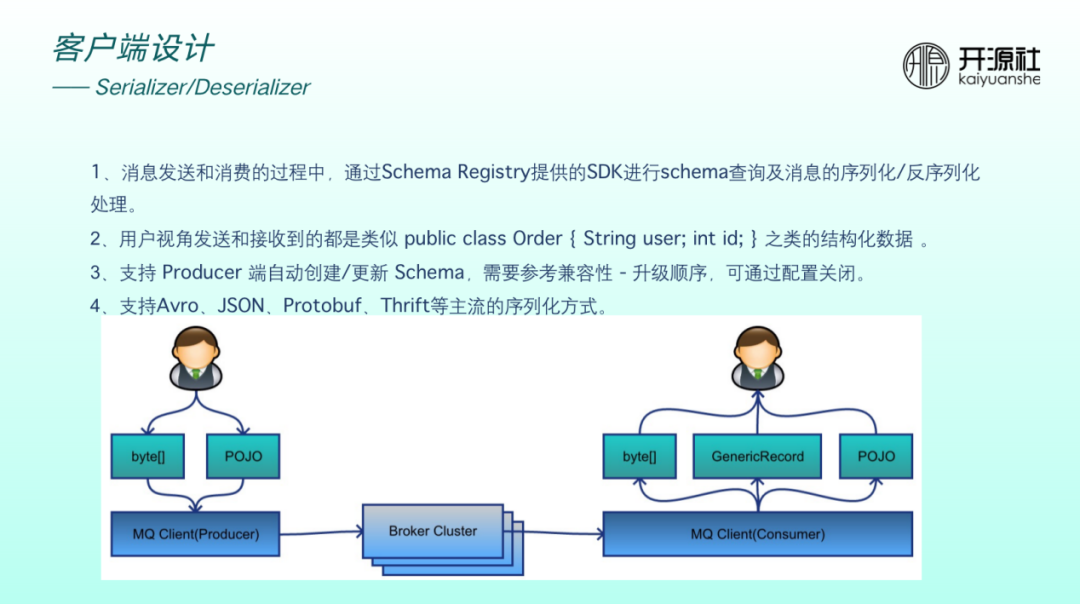
使用者端在訊息收發過程中,需要提供 SDK 做 schema 查詢以及訊息的序列化和反序列化處理。
如上圖,以前使用者在傳送時傳遞位元組陣列,接收時也是位元組陣列。現在我們希望傳送端關心一個物件,消費端也關心一個物件。如果消費端沒有感知到物件屬於什麼類,也可以通過 generate record 等通用型別理解訊息。因此,使用者視角傳送和接收到的均為類似於 public class Order 等結構化資料。
Producer 也可以支援自動建立和更新 schema ,也支援 Avro、JSON 等主流的序列化方式。

設計原則為不入侵原使用者端程式碼,不使用 schema 則訊息收發完全不受影響,使用者不感知 schema ,感知的是序列化和反序化型別。且支援在序列化過程中按最新版本解析、按指定 ID 解析。另外,為了滿足 streams 等非常強調輕量的場景,還支援了without Schema Registry 的訊息解析。
上圖程式碼為 schema 核心 API 序列化和反序列化。引數非常簡單,只要傳入 topic 、原始訊息物件,即可序列化為 message body 格式。反序列化同理,傳入 subject 和原始位元組陣列,即可將物件解析並傳遞給使用者。
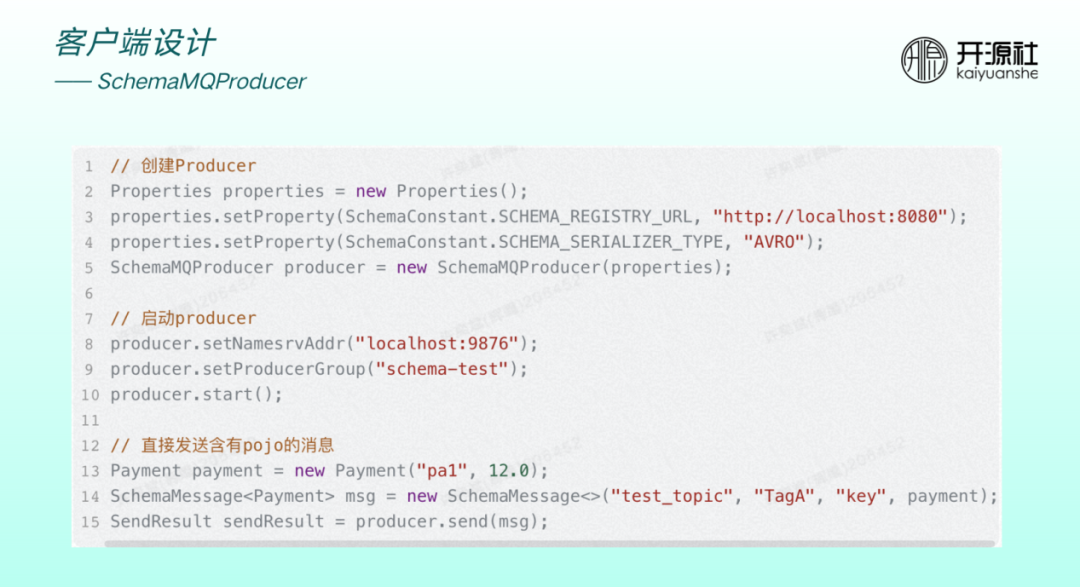
上圖為整合了 schema 之後的 producer 樣例。建立 producer 需要傳入registry URL和序列化型別。傳送時傳入的並非位元組陣列,而是原始物件。

消費端建立時,需指定 registry URL 和序列化型別,然後通過 getMessage 方法直接獲取泛型或實際物件。
ETL場景落地
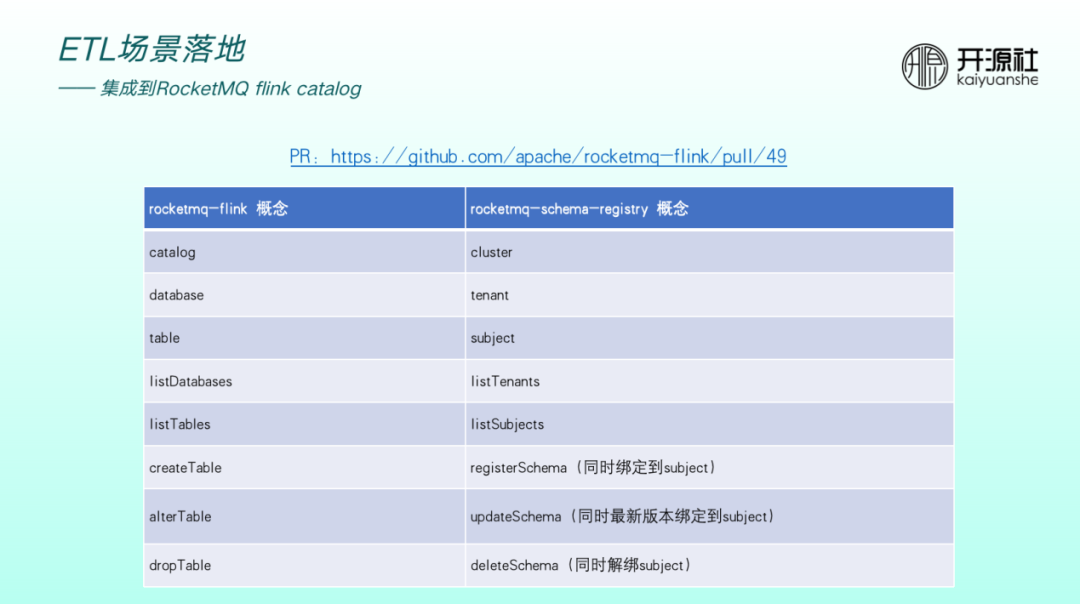
RocketMQ flink catlog 主要用於描述 RocketMQ Flink 的Table、Database等後設資料,因此基於 Schema Registry 實現時需要天然對齊一些概念。比如 catalog 對應 cluster , database 對應 Tenant, subject 對應 table 。
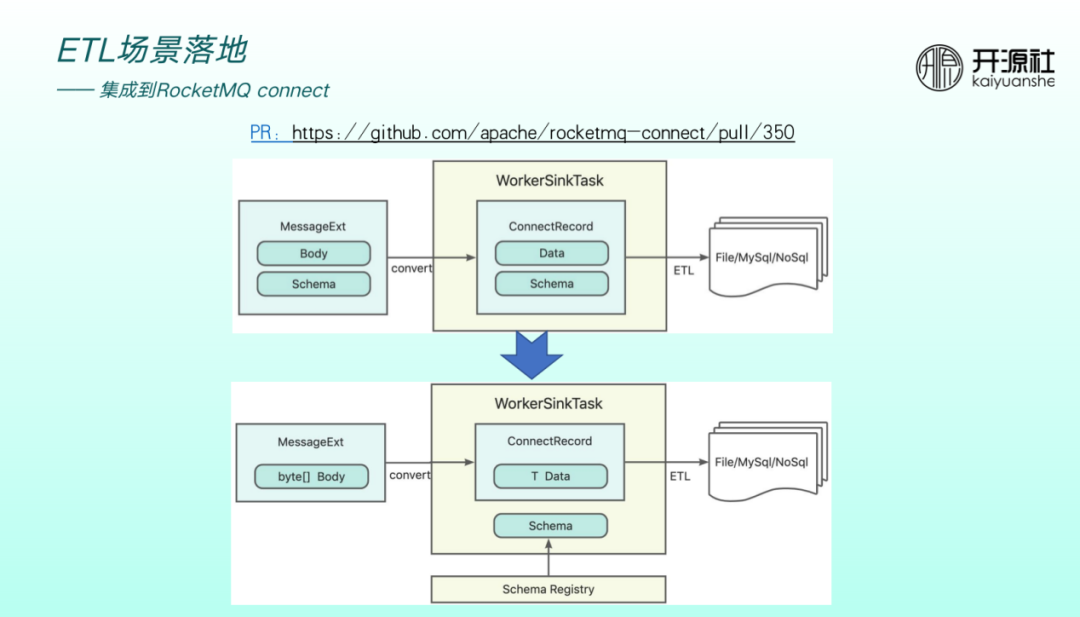
異構資料來源的轉化過程中,非常重要的一個環節為異構資料來源 schema 如何做轉換,涉及到 converter 。ConnectRecord 會將 data 和 schema 放在一起做傳輸,如果converter 依賴 registry 做 schema 的第三方託管,則ConnectRecord 無需將原來的 data 和 schema 放於一起,傳輸效率將會提高,這也是 connect 整合 Schema Registry 的出發點。

整合到 RocketMQ streams 場景的出發點在於希望RocketMQ streams API 的使用可以更加友好。沒有整合 schema 時,使用者需要主動將資料轉化成 JSON 。整合後,在流分析時,要靠近 Flink 或 streams 的使用習慣可以直接通過物件操作,使用者使用更友好。
上圖程式碼中新增了引數 schemaConfig 用於設定 schema ,包括序列化型別、目標 java 類,之後的 filter、map 以及 window 運算元的計算均可基於物件操作,非常方便。
另外,整合 streams 目前還可支援基本型別解析、訊息本身做 group by 操作以及自定義反序列化優化器。
後續規劃

未來,我們將在以下結果方面持續精進。
第一,社群SIG發展:小組剛經歷了從 0 到 1 的建設,還有很多 todo list 尚未實現,也有很多 good first issue 適合給社群新人做嘗試。
第二,強化Table概念。RocketMQ想要靠近流式引擎,需要不斷強化 table 概念。因此,引入 schema 之後是比較好的契機,可以將RocketMQ 的topic 概念提升至table 的概念,促進訊息和流表的深度融合。
第三,No-server 的 schema 管理。引入了 registry 元件後增加了一定的外部元件依賴。因此一些強調輕量化的場景依然希望做 no-server 的 schema 管理。比如直接與RocketMQ 互動,將資訊持久化到 compact topic 上,做直接讀、直接寫或基於 Git 儲存。
第四,列式查詢。整合到 streams 之後,我們發現可以按照欄位去消費訊息、理解訊息。當前的 RocketMQ 訊息按行理解,解析計算時需要消費整個訊息體。streams 目前按照欄位消費訊息已經基本實現,後續期望能夠實現按照條件查詢訊息、按欄位查詢訊息,將 RocketMQ 改造成查詢引擎。
第五,資料血緣/資料地圖。當 RocketMQ 通過分級儲存等特性延長訊息的生命週期,它將可以被視為企業的資料資產。目前的痛點在於 RocketMQ 提供的 dashboard 上,業務人員很難感知到 topic 背後的業務語意。如果做好資料血緣、理清資料 topic 上下游關係,比如誰在生產資料、被提供了哪些欄位、哪些資訊,則整個 dashboard 可以提供訊息角度的業務大盤,這其實具有很大的想象空間。
加入 Apache RocketMQ 社群
十年鑄劍,Apache RocketMQ 的成長離不開全球接近 500 位開發者的積极參與貢獻,相信在下個版本你就是 Apache RocketMQ 的貢獻者,在社群不僅可以結識社群大牛,提升技術水平,也可以提升個人影響力,促進自身成長。
社群 5.0 版本正在進行著如火如荼的開發,另外還有接近 30 個 SIG(興趣小組)等你加入,歡迎立志打造世界級分散式系統的同學加入社群,新增社群開發者:rocketmq666 即可進群,參與貢獻,打造下一代訊息、事件、流融合處理平臺。