一次TiDB GC阻塞引發的效能問題分析
背景
前不久從專案一線同學得到某叢集的告警資訊,某個時間段 TiDB duration 突然異常升高,持續時間6小時左右,需要定位到具體原因。
分析過程
第一招,初步判斷
由於專案條件苛刻,歷經苦難才拿到監控,在此之前只能靠現場同學的口述排查,oncall人太難了。。
既然是duration升高,那就先看看叢集的心電圖,試圖找出一點線索。一般來說,duration升高會有以下兩種情況。
第一種是高百分位(比如99、999)明顯升高,類似這種:
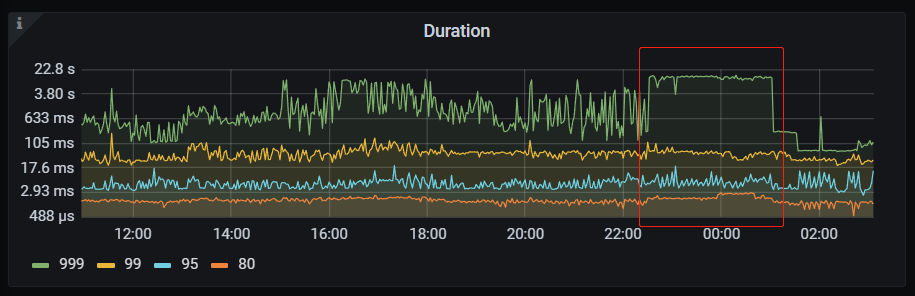
它的特點是除了高百分位異常,低分位線沒有明顯波動,這是典型的長尾反應,分位線越高波動越大,說明叢集那段時間慢SQL變多,重點關注慢查詢輔助排查其他監控即可。
第二種是所有分位線都有明顯升高,類似這種:

這說明叢集內部受到了影響,慢SQL不是導致duration上升的根本原因,而是叢集異常表現出來的結果。但是慢查詢依然是我們著手排查的方向之一,慢紀錄檔裡面記錄了慢的一些主要原因,可以作為參考依據。
這個案例碰到的就是第二種。
第二招,用監控還原SQL流程
如果暫時沒有什麼明確排查目標,可以先按SQL讀寫流程看一下主要的監控。通常在一個業務系統裡,讀請求是明顯要多於寫請求的,所以可以從讀流程開始排查,先是TiDB再是TiKV。
推薦參考社群的Trouble Shooting系列文章,非常實用:
詳細流程不再贅述。把這一招用完,基本就能定位到問題了,再結合一些非資料庫因素,查明真相指日可待。
針對本次案例中,說一下監控排查結論:
1、問題時間段TPS、QPS相較正常情況無明顯波動,各項資源使用率平穩,排除TiDB Server的問題
2、問題時間段TiKV節點負載變大,CPU、磁碟、出口頻寬使用率明顯上升,可判定查詢壓力大
3、當前GC safe point無推進,阻塞在約4小時前,排查歷史監控經常出現類似情況(TiKV Details -> GC -> TiKV Auto GC SafePoint)
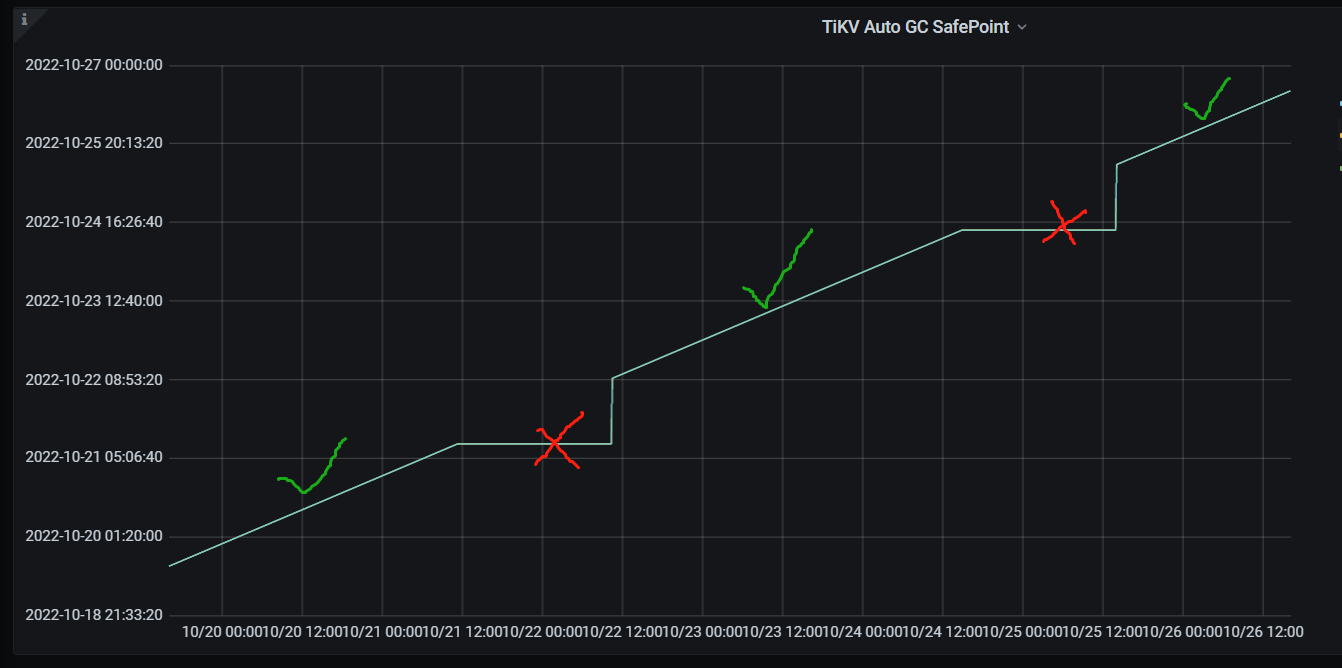
初步斷定GC執行異常導致歷史版本堆積,引發查詢效率變慢。
下一步找出證據佐證這個猜想。
第三招,確認非預期的操作
慢查詢紀錄檔裡面有兩個和Coprocessor Task 相關的欄位可以驗證這個猜想,他們是:
Total_keys:表示 Coprocessor 掃過的 key 的數量。
Process_keys:表示 Coprocessor 處理的 key 的數量。相比 total_keys,processed_keys 不包含 MVCC 的舊版本。如果 processed_keys 和 total_keys 相差很大,說明舊版本比較多。
但是介入排查的時候離異常時間已經過去快一天了,使用者只保留了30個紀錄檔檔案,並且慢查詢閾值調到了100ms,也就意味著當時產生的Slow Query Log已經沒有了,難受。。
最後把希望寄託在tidb.log的 Expensive Query 上面,排查問題時間段發現了很多delete where limit 10000000這種操作,表資料量在千萬級,和應用端確認後是由手動執行產生。(DBA看了這種SQL想抄起眼前的鍵盤。。)
在排查了多條 Expensive Query 後發現,Total_keys普遍在幾億數量級,而Process_keys在百萬數量級,進一步驗證了前面的判斷。

下一步,要找出資料舊版本太多的原因。
第四招,紀錄檔分析
GC操作是由TiDB Server的gc worker模組發起的,這裡排查起來就比較方便,只需要去TiDB Server搜尋紀錄檔即可,最後定位到了如下的異常資訊:
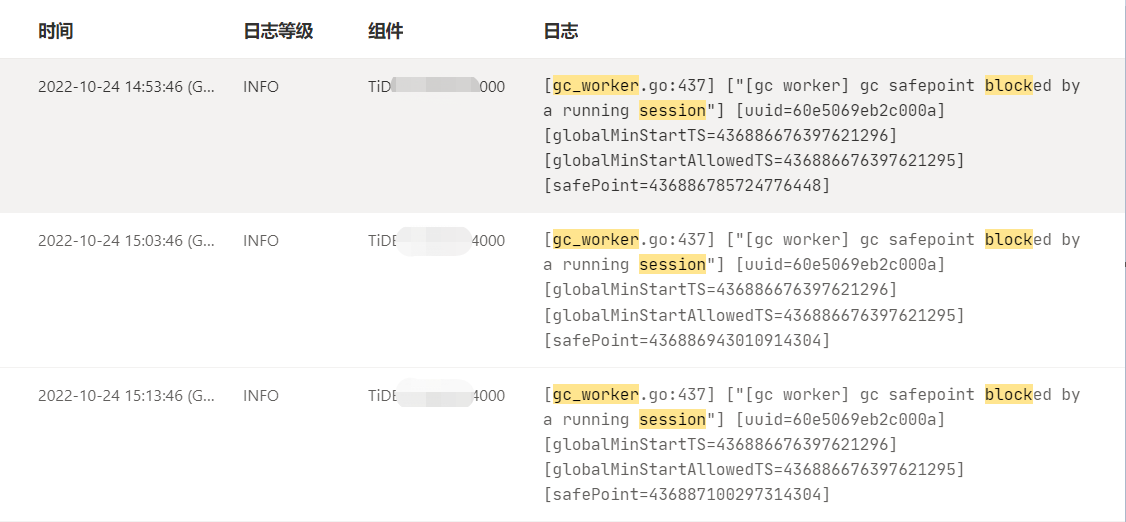
從上面可以判斷,GC在正常發起(每隔10分鐘列印一條紀錄檔),但是safepoint被一個執行中的對談阻塞了,並且給出了事務的開始時間戳(globalMinStartTS),根據這個資訊我們可以找到具體的session:
select instance,id,time,state,info,txnstart from information_schema.cluster_processlist where txnstart like '%xxxxxx%'
到這裡拿到session id以後可以根據實際情況判斷是否需要kill,但是也別高興的太早,因為有可能kill不掉。。。
關於kill不掉的問題在asktug吐槽的不少,據社群大佬說是kill成功了只是processlist查出來會殘留顯示,經過測試5.4.2徹底修復了。
如果真的真的真的kill了沒效果,就只能等著事務自己提交或回滾,要不然就得上重啟大法。
值得一提的是,上面的processlist查詢結果並不一定能查到根源SQL,也就是說info那一列是空值,這可能是單純由於事務卡著沒有提交,而不是某條慢SQL導致,這種情況下就要從應用端著手排查了。
第五招,還原真相
整理一下所有思路,得出以下結論:
- duration升高的原因是資料的歷史版本太多,前面說到的頻繁delete操作導致tikv節點資源壓力較大,從而影響其他SQL(從其他SQL的Coprocessor Task wait_time可以判定)
- 歷史版本堆積是因為gc safepoint被阻塞,有一個長期未提交的事務(從safepoint監控圖也可以驗證)
至此就破案了,一個gc引發的慘案浮出水面。而且,這種問題還會帶來一個連鎖反應,一旦safepoint恢復推進,大量的歷史版本瞬間被gc處理資源消耗極大,又要帶來第二波效能抖動,本案真實發生。
預防方案
首先從根源上,應用端要避免大事務操作,或者發起長期不提交的事務,及時提交或回滾。
其次,可以對TiDB GC做限流,降低GC對系統的整體影響:
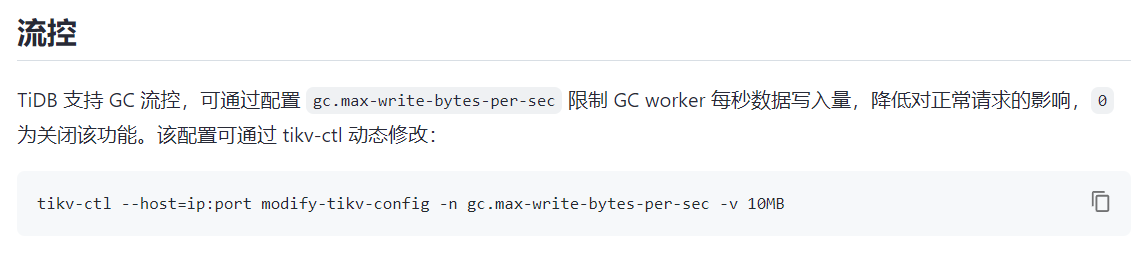
另外,從TiDB v5.1開始(建議使用5.1.3及以上),可以開啟 GC in Compaction Filter 特性(預設開啟,簡單來說就是做Compaction的時候順帶把GC給做了),能夠有效降低GC帶來的效能抖動問題。
總結
生產環境保留事故現場非常重要,對於紀錄檔檔案和監控資料條件允許的情況下儘量保留時間長一些,這對於後期排查問題起決定性作用。
另外,這個案例也告訴TiDB DBA,在對叢集做巡檢的時候,GC也是一個重要關注指標,一方面要確保GC的相關引數符合預期(比如gc_life_time臨時調大後忘了調回去),另一方面要確保GC執行正常,以免發生上述的效能問題。
文章作者:hoho 首發論壇:部落格園 文章出處:http://www.cnblogs.com/hohoa/ 歡迎大家一起討論分享,喜歡請點右下角的推薦鼓勵一下,我會有更多的動力來寫出好文章!歡迎持續關注我的部落格! 歡迎轉載,轉載的時候請註明作者和原文連結。