【機器學習】李宏毅——自監督式學習
1、BERT簡介
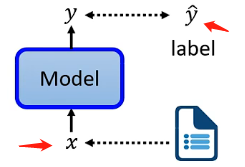
首先需要介紹什麼是自監督學習。我們知道監督學習是有明確的樣本和對應的標籤,將樣本丟進去模型訓練並且將訓練結果將標籤進行比較來修正模型,如下圖:
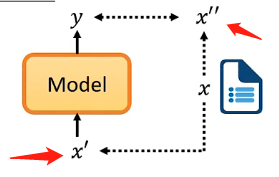
而自監督學習就是沒有標籤也要自己建立監督學習的條件,即當前只有樣本x但是沒有標籤\(\hat{y}\),那具體的做法就是將樣本x分成兩部分\(x\prime\)和\(x\prime \prime\),其中一部分作為輸入模型的樣本,另一部分來作為標籤:
如果覺得很抽象也沒關係,請繼續往下閱讀將會逐漸清晰這個定義。
1.1、BERT的masking
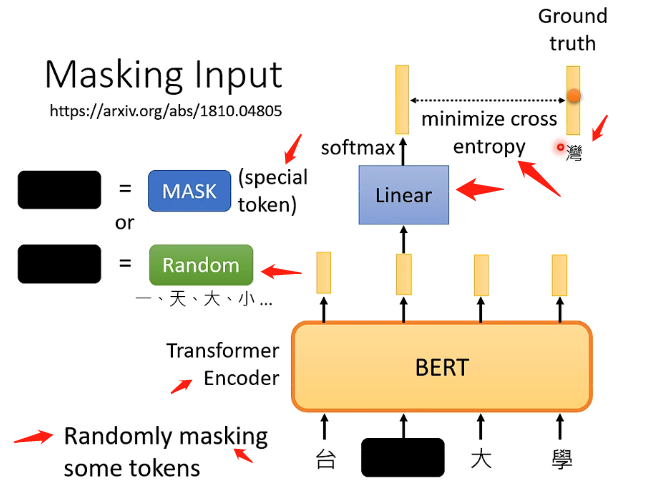
BERT的架構可以簡單地看成跟Transformer中的Encoder的架構是相同的(可以參考我這篇文章[點此]([機器學習]李宏毅——Transformer - 掘金 (juejin.cn))),其實現的功能都是接受一排向量,並輸出一排向量。而BERT特別的地方在於它對於接受的一排輸入的向量(通常是文字或者語音等)會隨機選擇某些向量進行「遮擋」(mask),而進行遮擋的方式又分為兩種:
- 第一種是將該文字用一個特殊的字元來進行替代
- 第二種是將該文字用一個隨機的文字來進行替代
而這兩種方法的選擇也是隨機的,因此就是隨機選擇一些文字再隨機選擇mask的方案來進行遮擋。然後就讓BERT來讀入這一排向量並輸出一排向量,那麼訓練過程就是將剛才遮擋的向量其對應的輸出向量,經過一個線性變換模型(乘以一個矩陣)再經過softmax模組得到一個result,包含該向量取到所有文字的所有概率,雖然BERT不知道被遮擋的向量代表什麼文字但我們是知道的,因此我們就拿答案的文字對應的one-hat-vector來與向量result最小化交叉熵,從而來訓練BERT和這個線性變換模組,總體可以看下圖:
1.2、Next Sentence Prediction
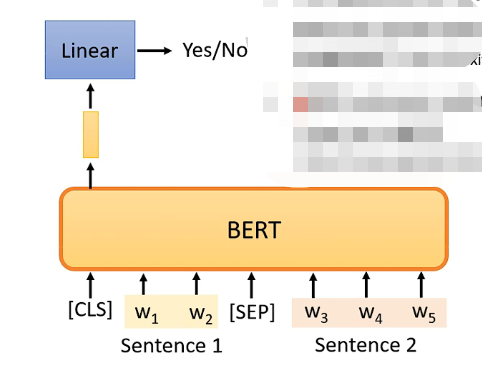
這個任務是判別兩個句子它們是不是應該連線在一起,例如判斷「我愛」和「中國」是不是應該連在一起,那麼在BERT中具體的做法為:
- 先對兩個句子進行處理,在第一個句子的前面加上一個特殊的成為CLS的向量,再在兩個句子的中間加上一個特殊的SEP的向量作為分隔,因此就拼成了一個較長的向量集
- 將該長向量集輸入到BERT之中,那麼就會輸出相同數目的向量
- 但我們只關注CLS對應的輸出向量,因此我們將該向量同樣經過一個線性變換模組,並讓這個線性變換模組的輸出可以用來做一個二分類問題,就是yes或者no,代表這兩個句子是不是應該拼在一起
具體如下圖:
而前面我們介紹了兩種BERT的應用場景,看起來似乎都是填空題或者判斷題,那麼是否BERT只能夠用於這種場景之下呢?當然不是!BERT具有強大的能力,它不僅可以用來解決我們感興趣的下游任務,更有趣的是,它只需要將剛才訓練(Pre-train)完成的可以處理填空題任務的簡單BERT進行微調(Fine-tune)就可以用來高效地解決一些下游、複雜的任務。也就是說BERT只需要先用簡單的任務來進行Pre-train,然後再進行微調就可以用於我們感興趣的下游複雜任務!
這裡補充一個知識點,因為BERT這類模型可以進行微調來解決各種下游任務,因此有一個任務集為GLUE,裡面包好了9種自然語言處理的任務,一般評判BERT這種模型就是將BERT分為微調來處理這9個任務然後對正確率等進行平均。9個任務如下:

1.3、How to ues BERT
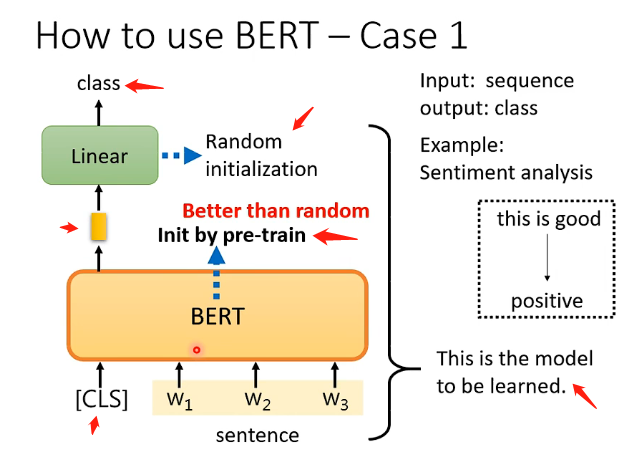
Case 1
Case 1 是接受一個向量,輸出一個分類,例如做句子的情感分析,對一個句子判斷它是積極的還是消極的。那麼如何用BERT來解決這個問題呢,具體的流程如下:
- 在句子對應的一排向量之前再加上CLS這個特殊字元所對應的向量,然後將這一整排向量放入BERT之中
- 我們只關注CLS對應的輸出向量,將該向量經過一個線性變換(乘上一個矩陣)後再經過一個softmax,輸出一個向量來表示分類的結果,表示是積極的還是消極的
而重要的地方在於線性變換模組的引數是隨機初始化的,而BERT中的引數是之前就pre-train的引數,這樣會比隨機初始化的BERT更加高效。而這也代表我們需要很多句子情感分析的樣本和標籤來讓我們可以通過梯度下降來訓練線性變換模組和BERT的引數。如下圖:
一般我們是將BERT和線型變換模組一起稱為Sentiment analysis。
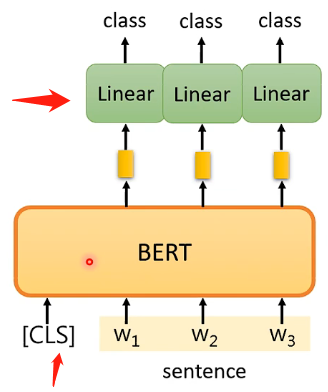
Case 2
這個任務是輸入一排向量,輸出是和輸入相同數目的向量,例如詞性標註問題。那麼具體的方法也是很類似的,BERT的引數也是經過pre-train得到的,而線性變化的引數是隨機初始化的,然後就通過一些有標註的樣本進行學習,如下圖:
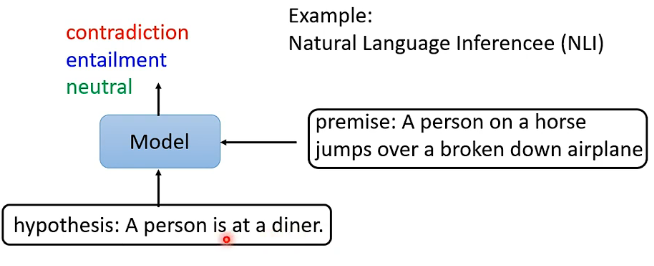
Case 3
在該任務中,輸入是兩個句子,輸出是一個分類,例如自然語言推斷問題,輸入是一個假設和一個推論,而輸出就是這個假設和推論之間是否是衝突的,或者是相關的,或者是沒有關係的:
那麼BERT對這類任務的做法也是類似的,因為要輸出兩個句子,因此在兩個句子之間應該有一個SEP的特殊字元對應的向量,然後在開頭也有CLS特殊字元對應的向量,並且由於輸出是單純一個分類,那關注的也是CLS對應的輸出向量,將其放入線性變換模組再經過softmax就得到分類結果了。引數的設定跟之前都是一樣的。如下圖:
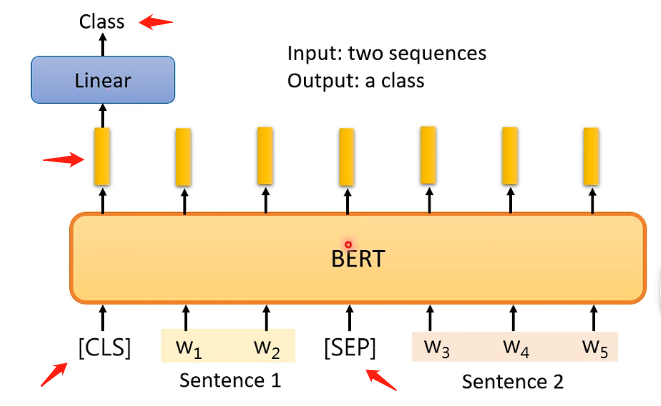
Case 4
BERT還可以用來做問答模型!但是對這個問答模型具有一定的限制,即需要提供給它一篇文章和一系列問題,並且要保證這些問題的答案都在文章之間出現過,那麼經過BERT處理之後將會對一個問題輸出兩個正整數,這兩個正整數就代表問題的答案在文章中的第幾個單詞到第幾個單詞這樣截出來的句子,即下圖的s和e就能夠擷取出正確答案。
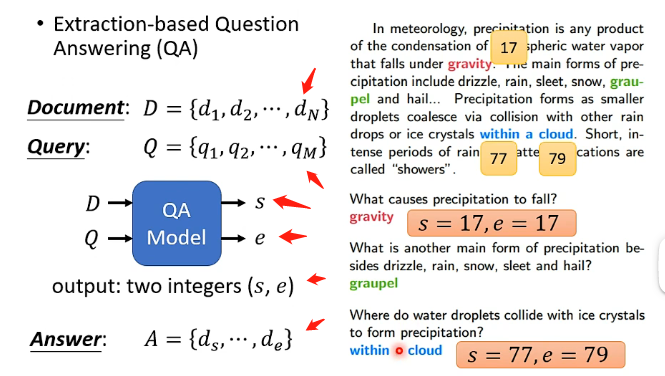
那麼BERT具體在做這件事時,也是將文章和問題看成兩個向量集,那麼同樣在它們中間要加上SEP,在開頭要加上CLS,然後經過BERT之後會產生相同數目的向量。那麼關鍵地方在於會初始化兩個向量稱為A和B,它們的長度和BERT輸出的向量的長度相同,那首先拿A和文章對應的所有輸出向量逐個進行點乘,每一個都得到一個數位,再全部經過softmax,然後看看哪一個最終的結果最大,最大的就是對應s的取值;B也是同理經過相同的處理最後取最大的作為e的取值,那麼得到s和e之後就可以去文章中取答案了!如下圖:
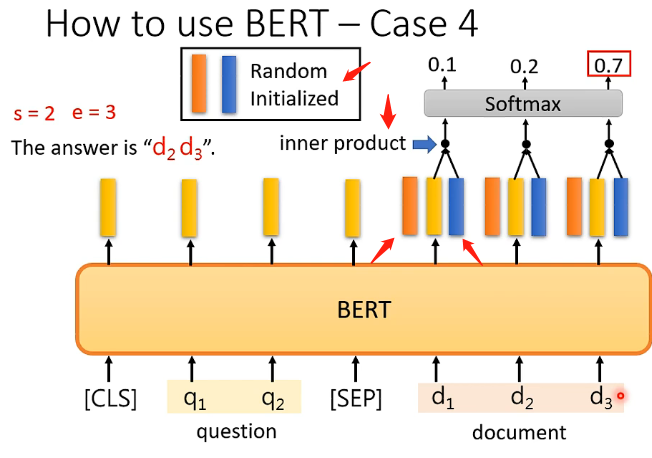
那麼我們要訓練的就是隨機初始化的兩個向量和已經pre-train的BERT。
1.4、Pre-train seq2seq model
前面介紹的BERT的各種應用場景都沒有用在seq2seq的場景,那麼如果要將BERT用於這個場景呢還需要再加上一個Dncoder,即:
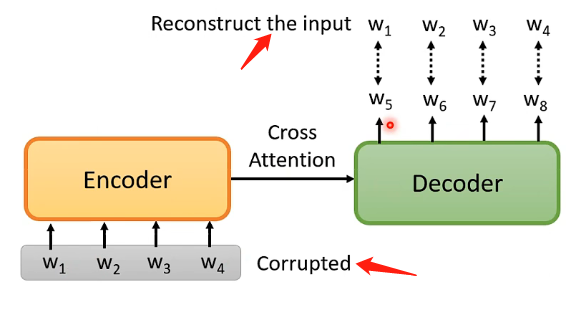
先將原始的輸入加入一定的干擾,然後經過Encoder和Decoder之後呢輸出的向量是和原來的輸入具有相同的數目,那麼目的就是希望輸出向量能夠和未加干擾之前的向量集足夠接近。
具體的干擾方法也是多種多樣:
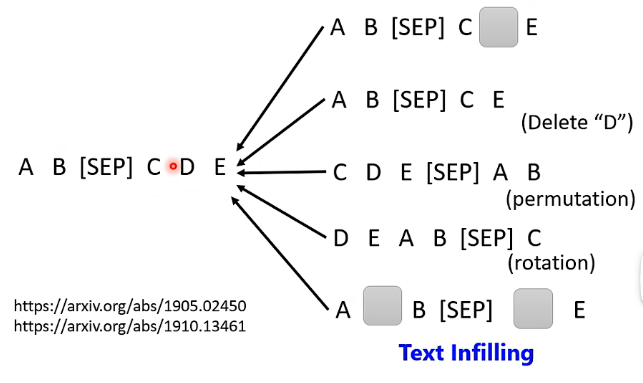
2、BERT的奇聞軼事
2.1 Why does BERT work?
先從一個事實來說明為什麼BERT能夠在文書處理中如此有效。
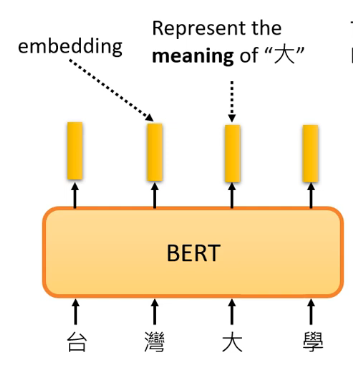
在BERT中,如果我們給它一個句子,也就是一排向量,那麼它對應輸出的向量可以認為裡面包含了對應輸入向量文字的含義,怎麼理解呢?看下面的例子,例如我們給輸入」臺灣大學「,那麼BERT的對應」大「的輸出其實可以認為它是知道其含義的。這麼說明可能有點抽象,我們需要通過下一個例子來解釋。
由於中文中常常存在一詞多意,那麼現在假設蘋果的蘋的兩個含義,收集關於蘋果的各種句子和關於蘋果手機的各種句子讓BERT先進行訓練, 然後再輸入關於蘋果的五條句子和關於蘋果手機的五條句子,如下圖:
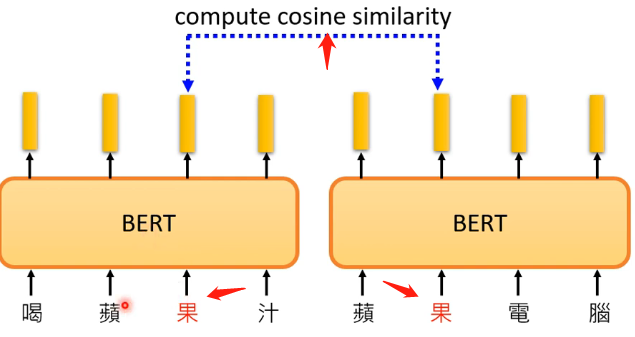
然後我們就來檢查,兩個意義中的「蘋」字對應的輸出向量之間的相似性,結果如下圖:
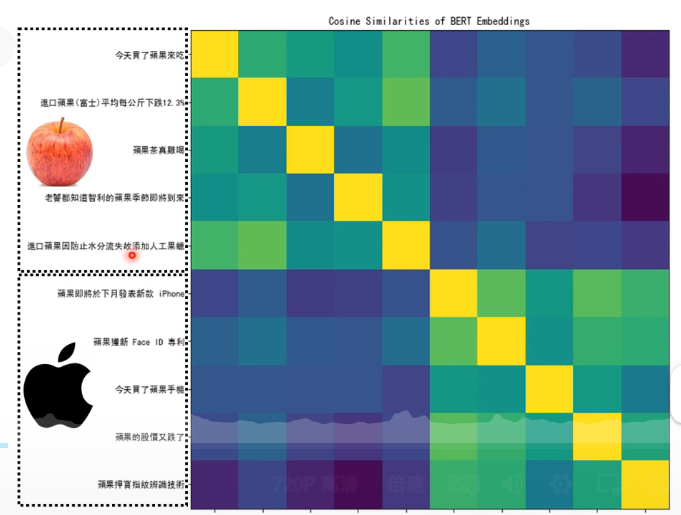
可以看到,關於吃的蘋果的句子之中「蘋」的對應輸出向量,它們彼此之間相似性較高;關於蘋果手機的也是;但是如果是不同的「蘋「那麼相似性則較低。
為什麼會有這種神奇的現象呢?難道是BERT學會了這個文字的多個含義嗎?
實際上是因為在訓練的時候我們將」蘋「遮住的話,BERT要從上下文來分析做出預測,它會發現這兩種不同的」蘋「所對應的上下文經常是不一樣的,因此它做出預測的輸出向量也就會存在差異!在許多論文上都是這個說法的。或者也可以認為由於上下文給這個遮掉的單詞賦予了一定的意義,那麼有可能,具有類似含義的單詞在上下文就會比較接近(例如食物的話上下文可能都跟餐具有關),那麼在做出預測的時候就向量比較接近。
2.2、Multi-lingual BERT
這個模型也就是用很多種語言來訓練一個模型:
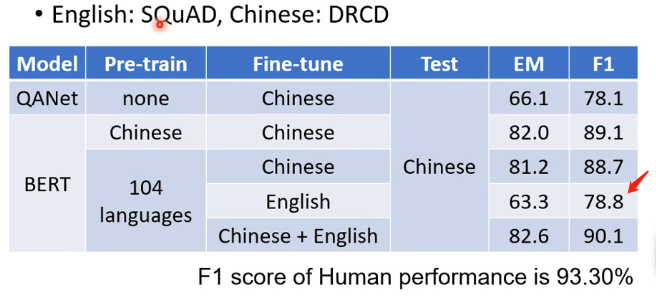
那麼有一個實驗室表現了BERT的神奇之處,也就是用了104種語言Pre-trainBERT,也就是教BERT做填空題,然後再用英文的問答資料來教BERT做英文的問答題,再在測試集中用中文的問答題來測試BERT,它的結果如下,可以達到這個正確率真的很令人吃驚!因為在BERT之前最好的是QANet,它的正確率比這樣的BERT還低!
2.3、語言的資訊
經過上述中英文的訓練,現在思考的問題是:為什麼你給的是英文的訓練集,在測試集的中文中,它不會給你在預測的地方預測出英文呢?那麼這是否可以說明在BERT中實際上它是能夠區分不同語言之間的差別,而不是單純的將其看做一個向量呢?那麼來做下面這個實驗:如果把所有中文都放進去BERT得到輸出然後平均得到一個向量,英文也是相同做法得到一個向量,然後將這兩個向量進行相減得到一個差值的向量;再將英文一句話丟進去BERT,得到輸出後加上這個差值的向量,會出現這個神奇的現象:
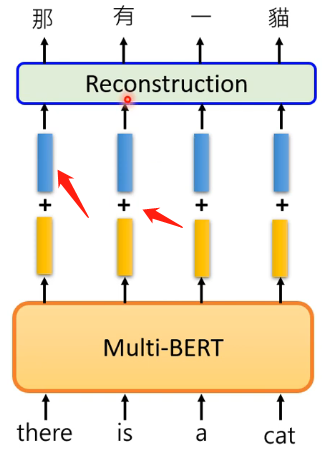
可以發現居然可以直接實現了翻譯的功能!再來看更復雜的例子:

可以看到雖然BERT不能夠完全地將中文轉為英文,但是在某些單詞上還是能夠正確的轉換的!這也表達了BERT的強大之處。
3、GPT的野望
GPT做的事情和BERT所做的填空題是不一樣的,GPT具體做的是根據當前的輸入預測下一個時刻可能的token,例如下圖:
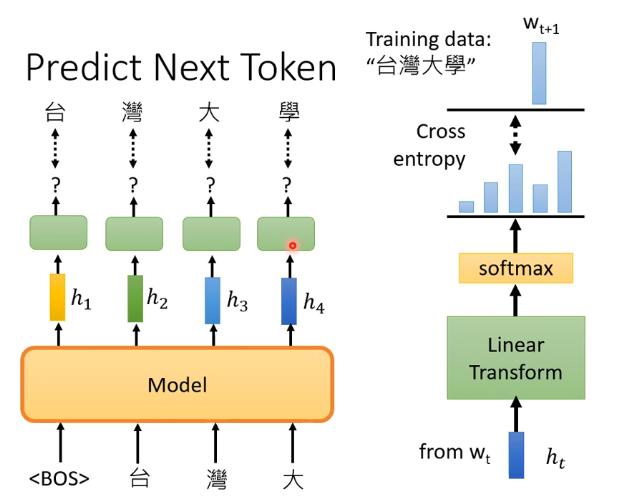
即給出Begin of Sequence,就預測出臺,然後給出BOS和臺就預測出灣,以此類推。對輸出向量的處理就是右邊那部分,先經過一個線性變化後再經過softmax得到結果向量,再跟理想結果來計算交叉熵,然後是最小化交叉熵來訓練的。
那麼要注意的地方是它預測的時候看到的只有上文而已,即不知道後面的句子是什麼。