智慧語音之遠場關鍵詞識別實踐(二)
上篇(智慧語音之遠場關鍵詞識別實踐(一))講了「遠場關鍵詞識別」專案中後端上的實踐。本篇將講在前端上的一些實踐以及將前端和後端連起來形成一個完整的方案。下圖是其框圖:(麥克風陣列為圓陣且有四個麥克風,即有四個語音通道)
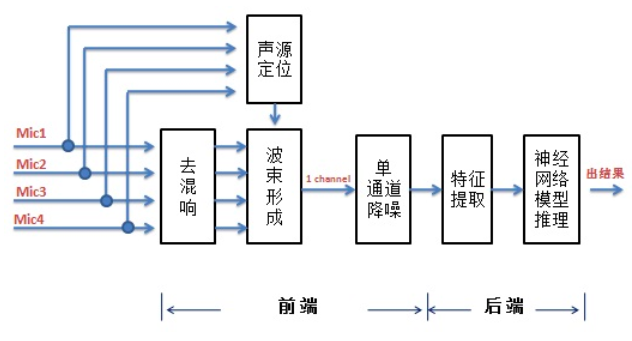
從上圖可以看出,前端主要包括去混響、聲源定位和波速形成(beamforming)、單通道降噪四大功能模組。每個模組的作用在上篇中已簡單描述過,這裡就不講了。每個模組由一個人負責,我負責做單聲道降噪。對於每個功能模組來說,通常都會有多種不同的實現演演算法,不同的演演算法在效能和運算複雜度上有優劣,因此先要去評估,選擇最適合我們專案的演演算法。評估主要從效能以及運算複雜度兩方面去做。評估下來後去混響選擇了WPE(Weighted prediction error,加權預測誤差)演演算法,聲源定位選擇了GCC-PHAT(Generalized Cross Correlation-Phase Transform,廣義互相關-相位變換)演演算法,波速形成選擇了MVDR(Minimum Variance Distortionless Response,最小方差無失真響應)演演算法。單聲道降噪不像其他模組只有幾種主流的演演算法,去評估後選擇一到兩種就可以了。單聲道降噪好多年前就研究了,有多種效果不錯的演演算法,且不斷有新的演演算法(比如基於深度學習的演演算法)提出來。它以前主要用在語音通話中,現在我們要把它用在遠場麥克風陣列的語音識別中。我深入的調研了一番,沒有文章公開說哪種演演算法在語音識別中效果較好,市面上主流的產品(比如小度音箱、天貓精靈等)也沒說用了哪種單聲道降噪演演算法,只能摸著石頭過河了。先前有同事找到了一篇傳統方法和深度學習相結合的單聲道降噪的文章,大家討論了一下,覺得有點符合潮流(深度學習),就決定先研究這個。經過一段時間的學習和實踐,有了一些輸出,也寫了關於這個演演算法理論和實踐的幾篇文章,具體見《語音降噪論文「A Hybrid Approach for Speech Enhancement Using MoG Model and Neural Network Phoneme Classifier」的研讀 》,《基於混合模型的語音降噪實踐 》,《基於混合模型的語音降噪效果提升 》。這個演演算法的降噪效果還可以,但是裡面有神經網路模型,且引數不少,要求一定的算力,在嵌入式上部署load有點吃緊。討論後這種演演算法留作備份,再去研究有沒有更適合的演演算法。考慮到基於深度學習的方法在嵌入式上都不太能部署,就在傳統方法中尋找。調研後發現基於MCRA-OMLSA的降噪演演算法效果很好且運算複雜度不高,討論後決定試試這種方法。依舊是先學習理論,然後用python實現和tuning看效果。實驗做下來效果還是挺好的,就決定用這個演演算法了。關於MCRA-OMLSA的降噪演演算法,我也寫了三篇文章。具體見《基於MCRA-OMLSA的語音降噪(一):原理 》,《基於MCRA-OMLSA的語音降噪(二):實現 》,《基於MCRA-OMLSA的語音降噪(三):實現(續) 》。
當前端的各個模組的演演算法都python實現完成後就開始把前端和後端串起來看效果,即把前端的輸出作為後端的輸入看識別率。不過模型是基於先前錄的單聲道的資料訓練的。測試下來發現識別率比先前的降很多。出問題就要找原因和解決方法。大家先分頭調查和思考,然後一起討論。討論後覺得原因很可能是這個:模型是基於先前單聲道的語料訓練的,而現在識別時的語音是多聲道語音經過前端各演演算法處理後得到的單聲道語音,兩者不匹配。要想得到好的識別率,應該基於第二次錄得的多聲道的語料做完前端各演演算法處理後得到的單聲道的語料來重新訓練模型。簡而言之,就是要讓模型學習一下前端中的各個演演算法處理。於是基於第二次錄得的多聲道的語料重新訓練模型。先把多聲道資料經過前端各演演算法處理得到單聲道資料,再做各種augmentation來增強語料庫,最後拿這些處理後的資料去訓練得到新的模型。新的模型用上後識別率有了很大的提升。經過實踐,我們的經驗是要想有好的識別率,模型一定要把pipeline中的各種演演算法都學習到。
在python下有了一個好的識別率,接下來就要看怎麼在嵌入式上部署了,即用C語言來做實現。後端的C語言實現已經做好,要做的就是前端各演演算法的C語言實現。先前負責前端各演演算法的同學負責實現同樣的演演算法,先用浮點實現。一段時間後各個演演算法的浮點實現都做好了,再與後端串起來看識別率,結果與python下的基本一致。後面要做的是演演算法的定點實現。由於team有了更高優先順序的任務,只得暫停這方面的工作。只差最後一步就能真正部署了,有點可惜。後面有時間再把它完成吧。
遠場關鍵詞識別的專案由於參與人少做了近兩年。正是因為人少,每個人做的東西就多一些,也就學到的東西多一些。就我自己而言,不僅學到了後端深度學習相關的(模型訓練、量化等),也學到了前端訊號處理演演算法相關的,同時通過實踐還累積了不少關鍵詞識別相關的經驗。