圖解B樹及C#實現(2)資料的讀取及遍歷
前言
本文為系列文章
- B樹的定義及資料的插入
- 資料的讀取及遍歷(本文)
- 資料的刪除
前一篇文章為大家介紹了 B樹 的基本概念及其插入演演算法。本文將基於前一篇的內容,為大家介紹插入到 B樹 中的資料該怎麼讀取及遍歷,
本文的程式碼基於前一篇文章的程式碼,已經實現的功能可能會被省略,只介紹新增的功能。
在本文開始前,再次複習下 B樹 的順序特性:
- 每個 節點 中的 Item 按 Key 有序排列(規則可以是自定義的)。
- 升序排序時,每個 Item 左子樹 中的 Item 的 Key 均小於當前 Item 的 Key。
- 升序排序時,每個 Item 右子樹 中的 Item 的 Key 均大於當前 Item 的 Key。
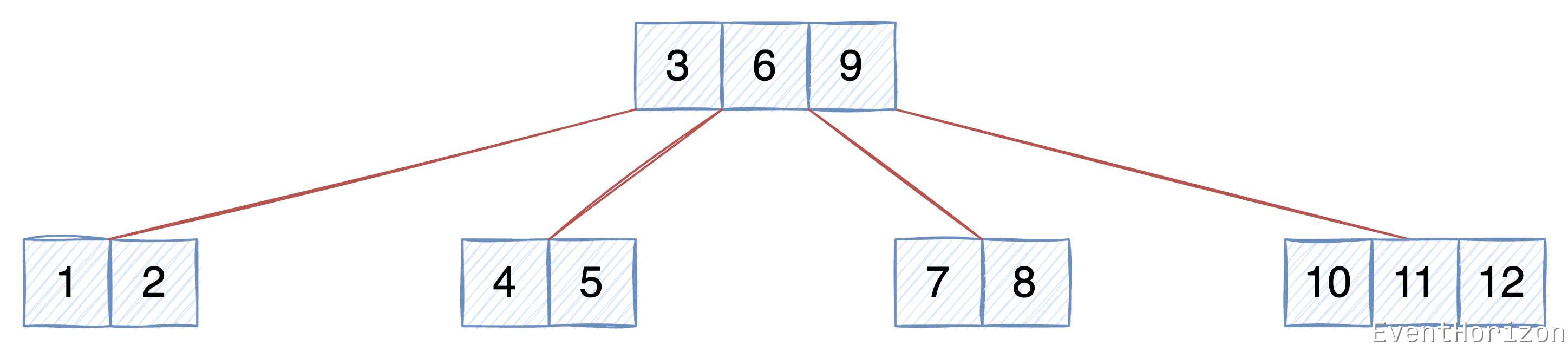
理解資料的順序性對本文的理解至關重要。
查詢資料
演演算法說明
B樹 是基於二分查詢演演算法進行設計的,某些資料中你也會看到用 多路搜尋樹 來歸類 B樹。
在 B樹 中查詢資料時,二分體現在兩個方面:
- 在節點中查詢資料時,使用二分查詢演演算法。
- 當節點中找不到資料時,使用二分查詢演演算法找到下一個節點。
具體的查詢過程如下:
- 從根節點開始,在節點中使用二分查詢演演算法查詢資料。
- 如果沒有找到資料,則根據查詢的 Key 值與節點中的 Key 值的大小關係,決定下一個節點的位置。
- 重複步驟 1 和 2,直到找到資料或者找到葉子節點。如果在葉子節點中也沒有找到資料,則說明資料不存在。
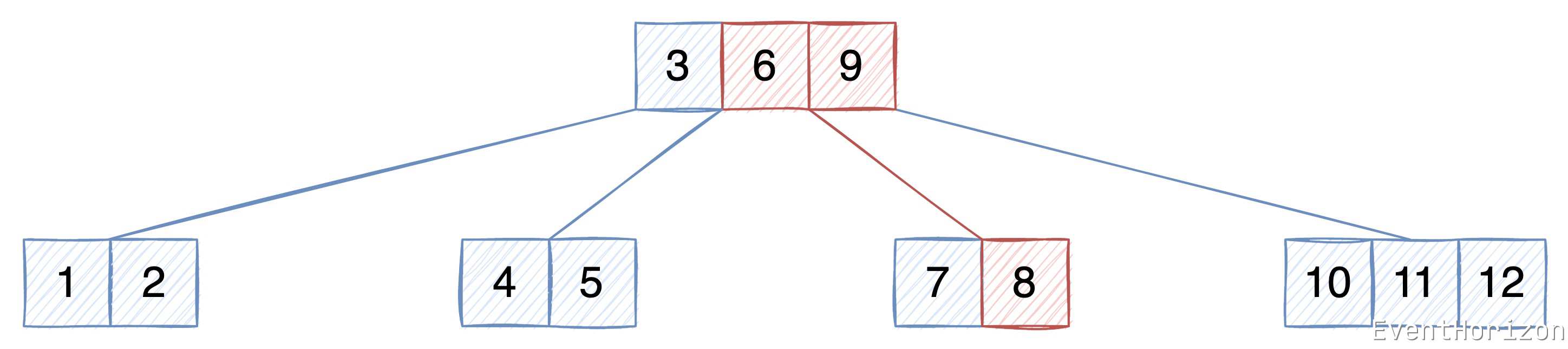
舉例說明:
在下面的 B樹 中,查詢 Key 為 8 的資料。
- 從根節點開始,使用二分查詢演演算法沒有找到資料
- 根據 Key 值與節點中的 Key 值的大小關係,決定下一個節點的位置應該在 6 和 9 之間,也就是 6 的右子樹。
- 在 6 的右子樹中,使用二分查詢演演算法找到了資料。
程式碼實現
前一篇文章我們定義了 Items 類,用於儲存節點中的資料,並且在一開始就定義了一個二分查詢演演算法,用於在 Items 查詢 Item。
前一篇用它來找到合適的插入位置,現在我們用尋找已經存在的資料。
在當前節點找到 Item 時,index 對應的就是 Item 的位置。沒找到時則代表下一個子樹的索引。
理解程式碼時請參考下圖:
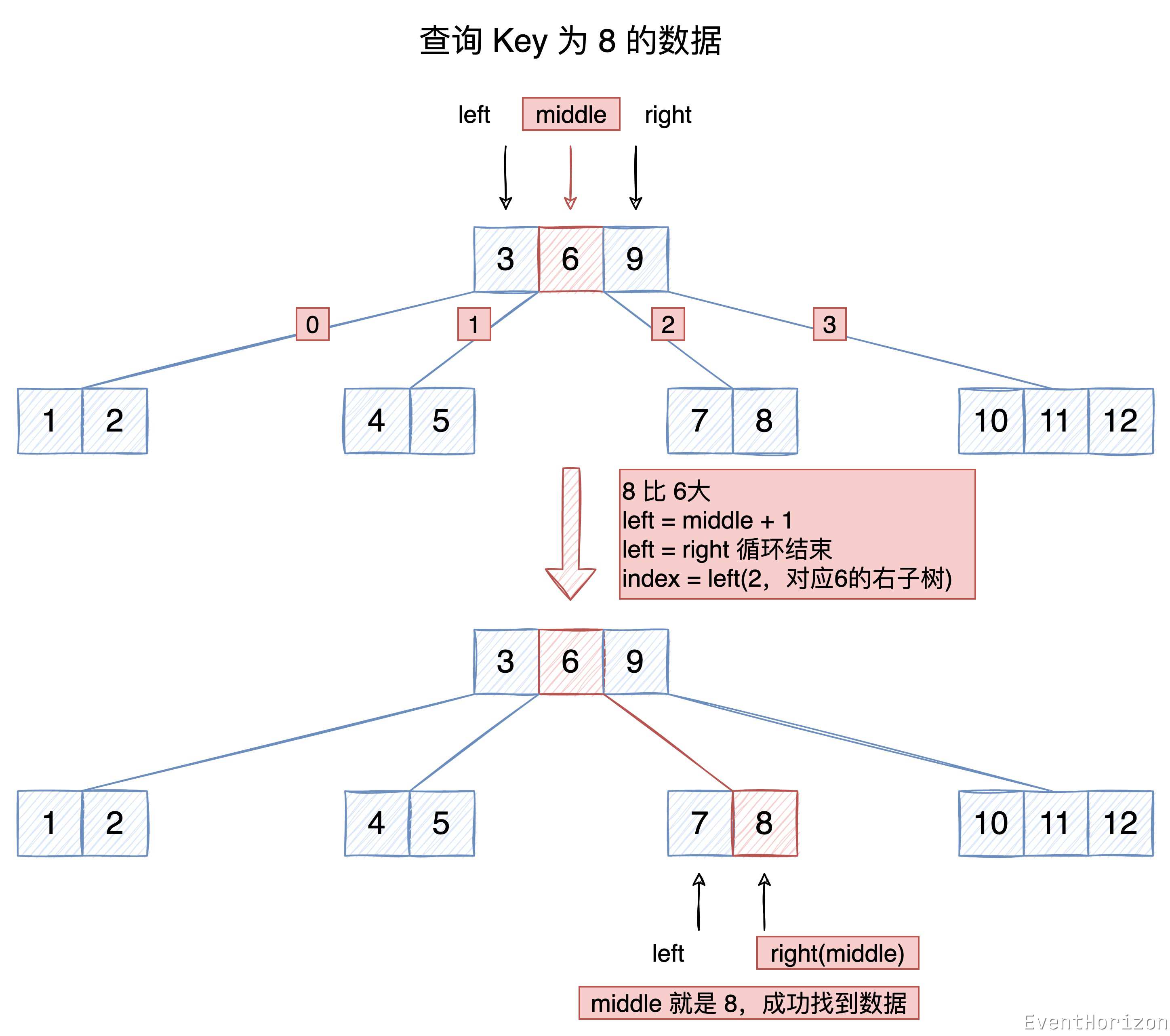
internal class Items<TKey, TValue>
{
public bool TryFindKey(TKey key, out int index)
{
if (_count == 0)
{
index = 0;
return false;
}
// 二分查詢
int left = 0;
int right = _count - 1;
while (left <= right)
{
int middle = (left + right) / 2;
var compareResult = _comparer.Compare(key, _items[middle]!.Key);
if (compareResult == 0)
{
index = middle;
return true;
}
if (compareResult < 0)
{
right = middle - 1;
}
else
{
left = middle + 1;
}
}
index = left;
return false;
}
}
在 Node 中,我們需要找到合適的子樹,然後遞迴呼叫子節點的 TryFind 方法。
internal class Node<TKey, TValue>
{
public bool TryFind(TKey key, out Item<TKey, TValue?> item)
{
if (_items.TryFindKey(key, out int index))
{
item = _items[index];
return true;
}
if (IsLeaf)
{
item = default!;
return false;
}
return _children[index].TryFind(key, out item);
}
}
BTree 類中,我們只需要呼叫根節點的 TryFind 方法即可。
public sealed class BTree<TKey, TValue> : IEnumerable<KeyValuePair<TKey, TValue?>>
{
public bool TryGetValue([NotNull] TKey key, out TValue? value)
{
ArgumentNullException.ThrowIfNull(key);
if (_root == null)
{
value = default;
return false;
}
if (!_root.TryFind(key, out var item))
{
value = default;
return false;
}
value = item.Value;
return true;
}
}
查詢最值
演演算法說明
B樹的順序性使得我們可以很方便的找到最值。
- 最小值:從根節點開始,一直往左子樹走,直到葉子節點。
- 最大值:從根節點開始,一直往右子樹走,直到葉子節點。

可以看到,B樹 尋找最值的時間複雜度只和樹的高度有關,而不是資料的個數,如果樹的高度為 h,那麼時間複雜度為 O(h)。只要樹的 度(degree) 足夠,每層能放的資料其實是很多的,那麼樹的高度就會很小,查詢最值的時間複雜度也很小。
程式碼實現
internal class Node<TKey, TValue>
{
public Item<TKey, TValue?> Max()
{
// 沿著右子樹一直走,直到葉子節點,葉子節點的最大值就是最大值
if (IsLeaf)
{
return _items[ItemsCount - 1];
}
return _children[ChildrenCount - 1].Max();
}
public Item<TKey, TValue?> Min()
{
// 沿著左子樹一直走,直到葉子節點,葉子節點的最小值就是最小值
if (IsLeaf)
{
return _items[0];
}
return _children[0].Min();
}
}
BTree 類中,我們只需要呼叫根節點的 Max 和 Min 方法即可。
public sealed class BTree<TKey, TValue> : IEnumerable<KeyValuePair<TKey, TValue?>>
{
public KeyValuePair<TKey, TValue?> Max()
{
if (_root == null)
{
throw new InvalidOperationException("BTree is empty.");
}
var maxItem = _root.Max();
return new KeyValuePair<TKey, TValue?>(maxItem.Key, maxItem.Value);
}
public KeyValuePair<TKey, TValue?> Min()
{
if (_root == null)
{
throw new InvalidOperationException("BTree is empty.");
}
var minItem = _root.Min();
return new KeyValuePair<TKey, TValue?>(minItem.Key, minItem.Value);
}
}
B樹的遍歷
演演算法說明
B樹的遍歷和二元樹的遍歷是相通的,都可以分為深度遍歷和廣度遍歷。深度遍歷又分為先序遍歷、中序遍歷和後序遍歷。
本文將以中序遍歷為例介紹 B樹 的遍歷,通過中序遍歷可以對 B樹 中的資料從小到大進行排序。
其他遍歷方式的也都可以理解成 二元樹 遍歷方式的拓展,有興趣的讀者朋友可以自行嘗試實現一下。
不過,B樹的遍歷和二元樹的遍歷還是有一些區別的,我們先來看一下二元樹的中序遍歷。
二元樹的中序遍歷分為下面幾步:
- 先遍歷左子樹。
- 存取當前節點。
- 遍歷右子樹。
在每個子樹中,重複上面的步驟。
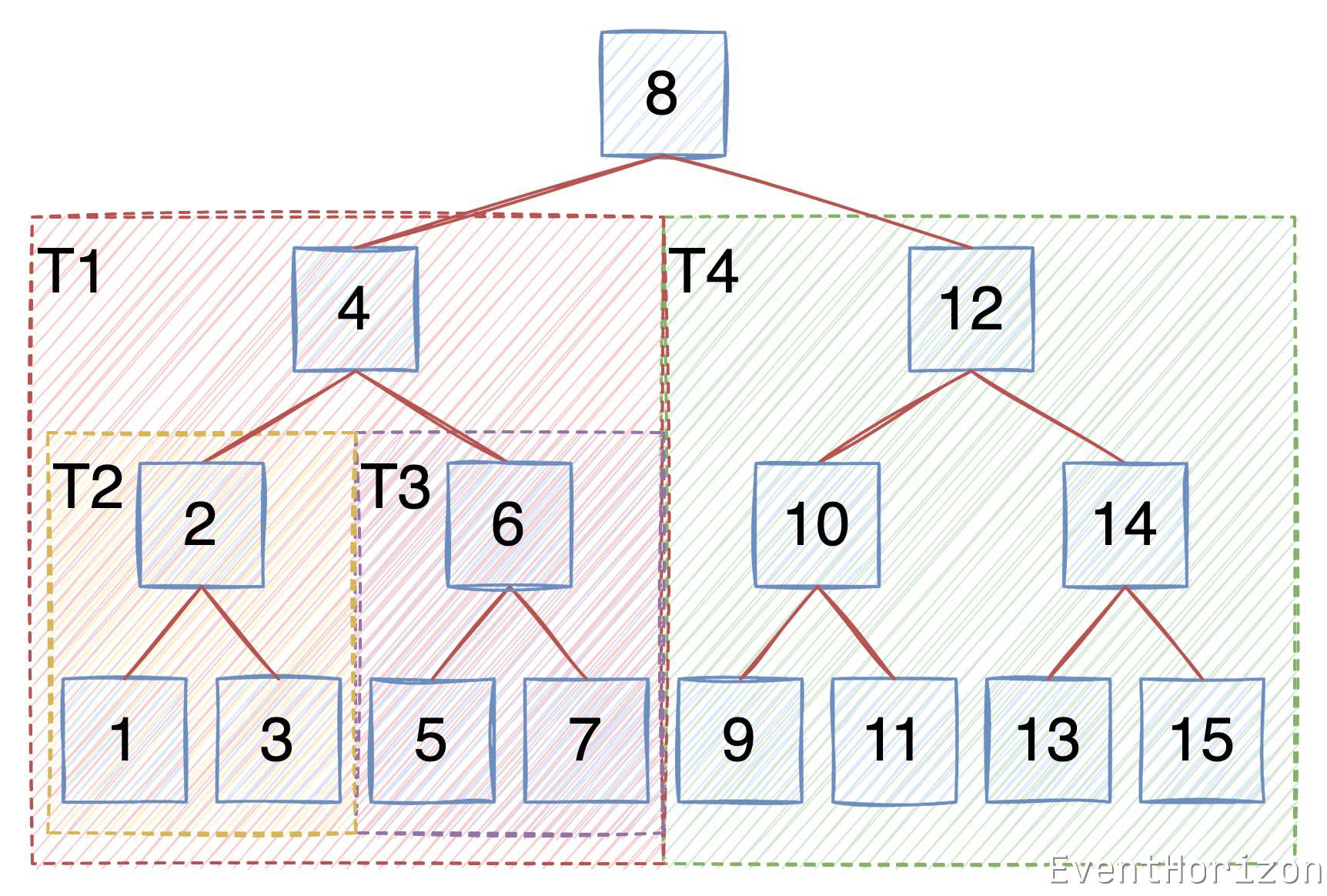
以下面的二元樹為例再次說明一遍:
-
先遍歷 8 的左子樹 T1
-
在 T1 中先遍歷 4 的左子樹 T2
-
在 T2 中先遍歷 2 的左子樹,只有一個節點,直接存取 1,
-
在 T2 中存取 2
-
在 T2 中遍歷 2 的右子樹,只有一個節點,直接存取 3,T2 遍歷完畢
-
在 T1 中存取 4
-
在 T1 中遍歷 4 的右子樹 T3
-
... 以此類推,直到遍歷完整棵樹。
B樹的中序遍歷也是類似的,只不過 B樹 的節點中有多個 Item 和 多個 子樹,我們需要遍歷每個 Item 的 左右子樹以及 Item 。
B樹的中序遍歷分為下面幾步:
- 遍歷節點中的第一個子樹,也就是第一個 Item 的左子樹。
- 遍歷節點中的第一個 Item。
- 遍歷節點中的第二個子樹,也就是第一個 Item 的右子樹。
- 直至遍歷完所有的 Item,遍歷節點中的最後一個子樹。
在每個子樹中,重複上面的步驟。
如下圖所示,我們以中序遍歷的方式遍歷 B樹,會先遍歷 3 的左子樹,然後存取 3,再遍歷 3 的右子樹,直至遍歷完 9 的右子樹。
程式碼實現
遍歷每個節點的 Item 和 子樹,我們可以使用遞迴的方式實現,程式碼如下:
internal class Node<TKey, TValue>
{
public IEnumerable<Item<TKey, TValue?>> InOrderTraversal()
{
var itemsCount = ItemsCount;
var childrenCount = ChildrenCount;
if (IsLeaf)
{
for (int i = 0; i < itemsCount; i++)
{
yield return _items[i];
}
yield break;
}
// 左右子樹並不是相當於當前的 node 而言,而是相對於每個 item 來說的
for (int i = 0; i < itemsCount; i++)
{
if (i < childrenCount)
{
foreach (var item in _children[i].InOrderTraversal())
{
yield return item;
}
}
yield return _items[i];
}
// 最後一個 item 的右子樹
if (childrenCount > itemsCount)
{
foreach (var item in _children[childrenCount - 1].InOrderTraversal())
{
yield return item;
}
}
}
}
BTree 實現了 IEnumerable 介面,以便我們可以使用 foreach 迴圈來遍歷 BTree 中的所有 Item,其程式碼只要呼叫 Node 的 InOrderTraversal 方法即可:
public sealed class BTree<TKey, TValue> : IEnumerable<KeyValuePair<TKey, TValue?>>
{
public IEnumerator<KeyValuePair<TKey, TValue?>> GetEnumerator()
{
foreach (var item in _root!.InOrderTraversal())
{
yield return new KeyValuePair<TKey, TValue?>(item.Key, item.Value);
}
}
IEnumerator IEnumerable.GetEnumerator()
{
return GetEnumerator();
}
}
Benchmarks
最後,我們來看一下 Degree 對 BTree 的效能的影響。
注意,我們這裡只考慮 B樹的資料量遠大於 Degree 的情況。
我們使用 BenchmarkDotNet 來測試,測試程式碼如下:
public class BTreeWriteBenchmarks
{
[Params(2, 3, 4, 5, 6)] public int Degree { get; set; }
private HashSet<int> _randomKeys;
[GlobalSetup]
public void Setup()
{
_randomKeys = new HashSet<int>();
var random = new Random();
while (_randomKeys.Count < 1000)
{
_randomKeys.Add(random.Next(0, 100000));
}
}
[Benchmark]
public void WriteSequential()
{
var bTree = new BTree<int, int>(Degree);
for (var i = 0; i < 1000; i++)
{
bTree.Add(i, i);
}
}
[Benchmark]
public void WriteRandom()
{
var bTree = new BTree<int, int>(Degree);
foreach (var key in _randomKeys)
{
bTree.Add(key, key);
}
}
}
public class BenchmarkConfig : ManualConfig
{
public BenchmarkConfig()
{
Add(DefaultConfig.Instance);
Add(MemoryDiagnoser.Default);
ArtifactsPath = Path.Combine(AppContext.BaseDirectory, "artifacts", DateTime.Now.ToString("yyyy-mm-dd_hh-MM-ss"));
}
}
new BenchmarkSwitcher(new[]
{
typeof(BTreeReadBenchmarks),
}).Run(args, new BenchmarkConfig());
我們測試了 4 項效能指標,分別是順序讀、隨機讀、最小值、最大值、遍歷,測試結果如下:

可以看到,在相同的資料量下,Degree 越大,效能越好,這是因為 Degree 越大,BTree 的高度越小,所以每次查詢的時候,需要遍歷的節點越少,效能越好。
但是不是真的 Degree 越大就越好呢,我們再來看下寫入效能的測試結果:
public class BTreeWriteBenchmarks
{
[Params(2, 3, 4, 5, 6)] public int Degree { get; set; }
private HashSet<int> _randomKeys;
[GlobalSetup]
public void Setup()
{
_randomKeys = new HashSet<int>();
var random = new Random();
while (_randomKeys.Count < 1000)
{
_randomKeys.Add(random.Next(0, 100000));
}
}
[Benchmark]
public void WriteSequential()
{
var bTree = new BTree<int, int>(Degree);
for (var i = 0; i < 1000; i++)
{
bTree.Add(i, i);
}
}
[Benchmark]
public void WriteRandom()
{
var bTree = new BTree<int, int>(Degree);
foreach (var key in _randomKeys)
{
bTree.Add(key, key);
}
}
}
測試結果如下:
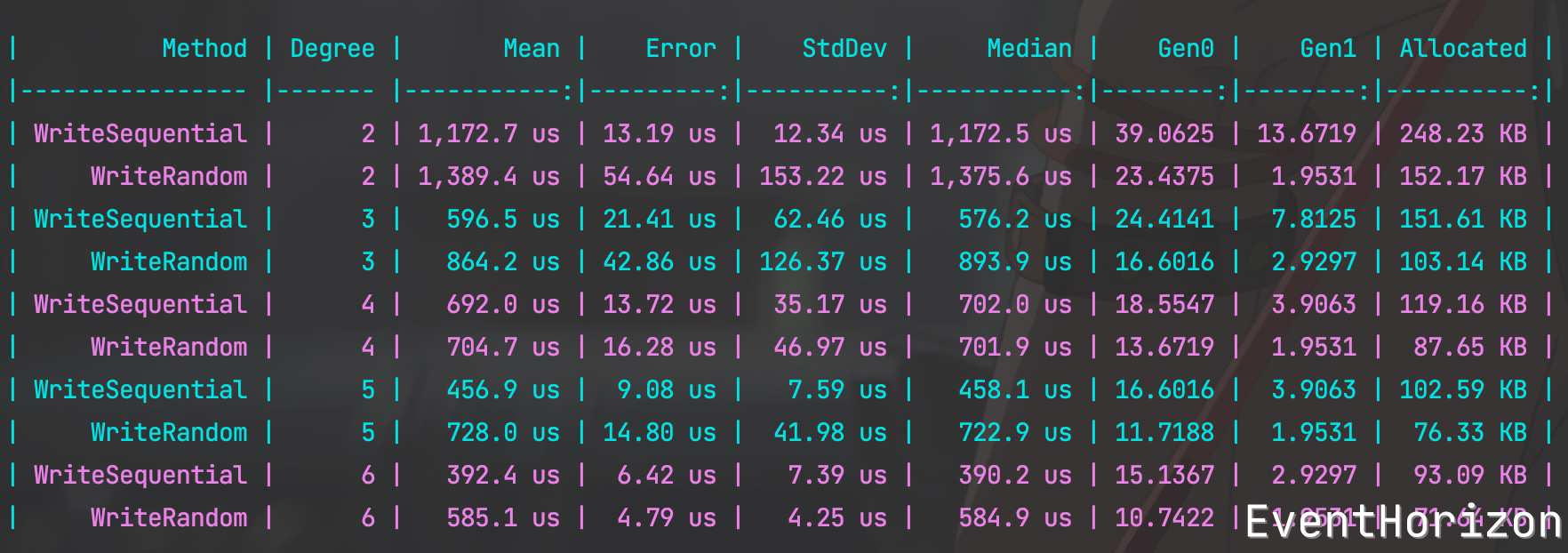
可以看到,Degree 越大,寫入效能也越好,每個節點的容量夠大,需要分裂的次數就變少了。
總結
- B樹是一種多路平衡查詢樹,可以基於二分查詢的思路來查詢資料。
- B樹的資料量遠大於 Degree 的情況下,B樹的 Degree 越大,讀寫效能越好。如果是磁碟中的實現,每個節點要考慮到磁碟頁的大小,Degree 會有上限。
參考資料
Google 用 Go 實現的記憶體版 B樹 https://github.com/google/btree