一文聊透Apache Hudi的索引設計與應用
Hudi索引在資料讀和寫的過程中都有應用。讀的過程主要是查詢引擎利用MetaDataTable使用索引進行Data Skipping以提高查詢速度;寫的過程主要應用在upsert寫上,即利用索引查詢該紀錄是新增(I)還是更新(U),以提高寫入過程中紀錄的打標(tag)速度。
MetaDataTable
目前使能了"hoodie.metadata.enable"後,會在.hoodie目錄下生成一張名為metadata的mor表,利用該表可以顯著提升源表的讀寫效能。
該表目前包含三個分割區:files, column_stats, bloom_filters,分割區下檔案的格式為hfile,採用該格式的目的主要是為了提高metadata表的點查能力。
其中files分割區紀錄了源表各個分割區內的所有檔案列表,這樣hudi在生成源表的檔案系統檢視時就不必再依賴檔案系統的list files操作(在雲端儲存場景list files操作更有可能是效能瓶頸);TimeLine Server和上述設計類似,也是通過時間線伺服器來避免對提交後設資料進行list以生成hudi active timeline。
其中column_stats分割區紀錄了源表中各個分割區內所有檔案的統計資訊,主要是每個檔案中各個列的最大值,最小值,紀錄資料,空值數量等。只有在開啟了"hoodie.metadata.index.column.stats.enable"引數後才會使能column_stats分割區,預設源表中所有列的統計資訊都會紀錄,也可以通過"hoodie.metadata.index.column.stats.column.list"引數單獨設定。Hudi表每次提交時都會更新column_stats分割區內各檔案統計資訊(這部分統計資訊在提交前的檔案寫入階段便已經統計好)。
其中bloom_filters分割區紀錄了源表中各個分割區內所有檔案的bloom_filter資訊,只有在開啟了"hoodie.metadata.index.bloom.filter.enable"引數後才會使能bloom_filters分割區,預設紀錄源表中record key的bloomfilter, 也可以通過"hoodie.metadata.index.bloom.filter.column.list"引數單獨設定。
需要注意bloom_filter資訊不僅僅儲存在metadata表中(存在該表中是為了讀取加速,減少從各個base檔案中提取bloomfilter的IO開銷)。Hudi表在開啟了"hoodie.populate.meta.fields"引數後(預設開啟),在完成一個parquet檔案寫入時,會在parquet檔案的footerMetadata中填充bloomfilter相關引數, 其中"hoodie_bloom_filter_type_code"引數為過濾器型別,設定為預設的DYNAMIC_V0(可根據record key數量動態擴容);"org.apache.hudi.bloomfilter"引數為過濾器bitmap序列化結果;"hoodie_min_record_key"引數為當前檔案record_key最小值;"hoodie_max_record_key"引數為當前檔案record_key最大值。Hudi表提交時其Metadata表bloom_filters分割區內的bloom_filter資訊便提取自parquet檔案footerMetadata的"org.apache.hudi.bloomfilter".
寫入
Flink
對flink寫入而言就是通過bucket_idx進行打標(僅支援分割區內去重打標)或者bucket_assigner運算元使用flink state進行打標(支援分割區內以及全域性去重打標,可通過引數控制,如果要進行全域性去重需要使能index.global.enabled且不使能changelog.enabled),目前flink僅支援這兩種方式,具體可參考hoodieStreamWrite方法。
對於upsert寫入場景,flink state會隨著寫入資料量的增大而線性增大,導致越寫越慢(打標過程變慢)的現象;而bucket_idx由於沒有資料查詢過程(通過紀錄的record key直接雜湊得到對應的filegroup進行打標),因此寫入速度不會隨資料量增大而線性增大。
如果應用場景需要對分割區表進行全域性去重,則只能使用flink state。如果上層業務允許,我們也可以通過變更表結構,將分割區鍵加入到主鍵中作為主鍵的一部分來實現分割區間的天然去重。
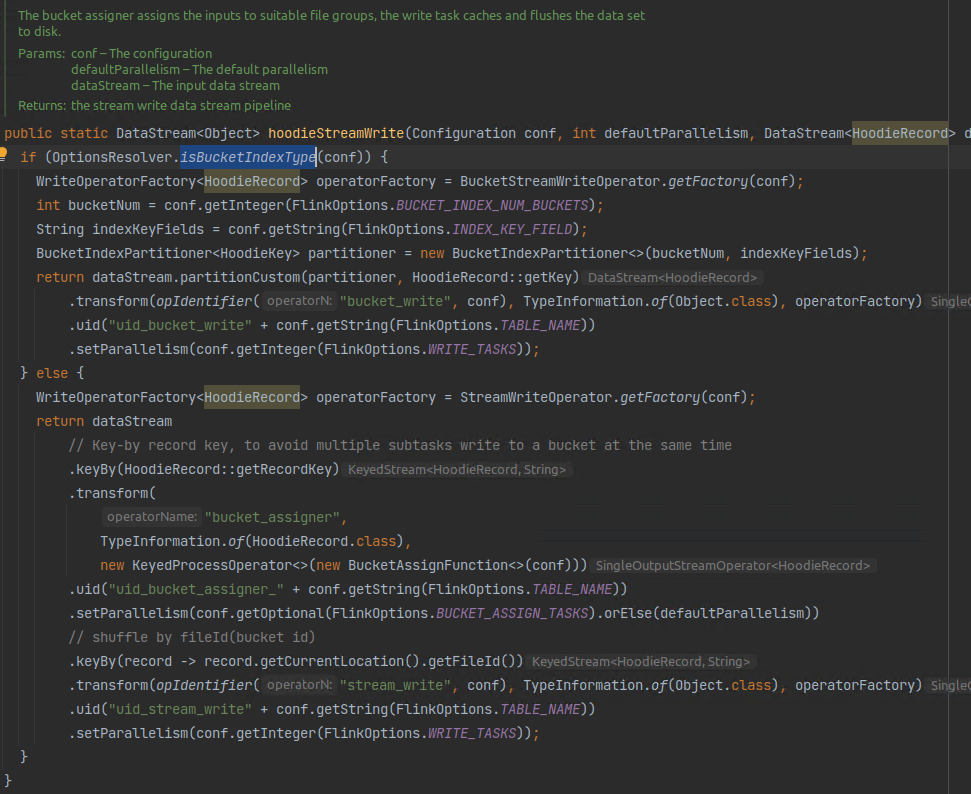
圖2. 1 flink寫入打標過程
對於metadata表而言,flink可以通過使能引數"hoodie.metadata.index.column.stats.enable"生成column_stats,flink可以在讀優化查詢時使用到列統計資訊進行data skipping。
對於metadata表而言,flink可以通過使能引數"hoodie.metadata.index.bloom.filter.enable"生成bloom_filters,但是flink
目前不支援在讀時使用bloomfilter進行data skipping,也不支援在寫時通過bloomfilter進行打標。
Spark
對spark寫入而言就是對每條紀錄呼叫index.tagLocation進行打標的過程。Spark目前支援SimpleIndex, GlobalSimpleIndex, BloomIndex, BucketIndex, HbaseIndex進行寫入打標。
SimpleIndex通過在每個分割區內進行InputRecordRdd left outer join ExistingRecordRdd的方式判斷輸入紀錄是否已經儲存在當前分割區內;GlobalSimpleIndex和SimpleIndex類似,只不過left outer join該表內所有已存在資料而不是當前分割區已存在資料。
BloomIndex通過column_stat_idx和bloom_filter_idx進行資料打標過濾:首先通過column_stat_idx(可以從metadata表中獲取,也可從parquet footer metadata中獲取,通過"hoodie.bloom.index.use.metadata"引數控制)的min,max值過濾掉紀錄肯定不存在的檔案(在record key遞增且資料經過clustering的情況下可以過濾出大量檔案)以獲得紀錄可能存在的檔案。然後在紀錄可能存在的檔案中依次使用每個檔案對應的bloomfilter(可以從metadata表中獲取,也可從parquet footer metadata中獲取,通過"hoodie.bloom.index.use.metadata"引數控制)判斷該紀錄是否一定不存在。最後得到每個檔案可能包含的紀錄列表,由於bloomfilter的誤判特性,需要將這些紀錄在檔案中進行精準匹配查詢以得到實際需要更新的紀錄及其對應的location.
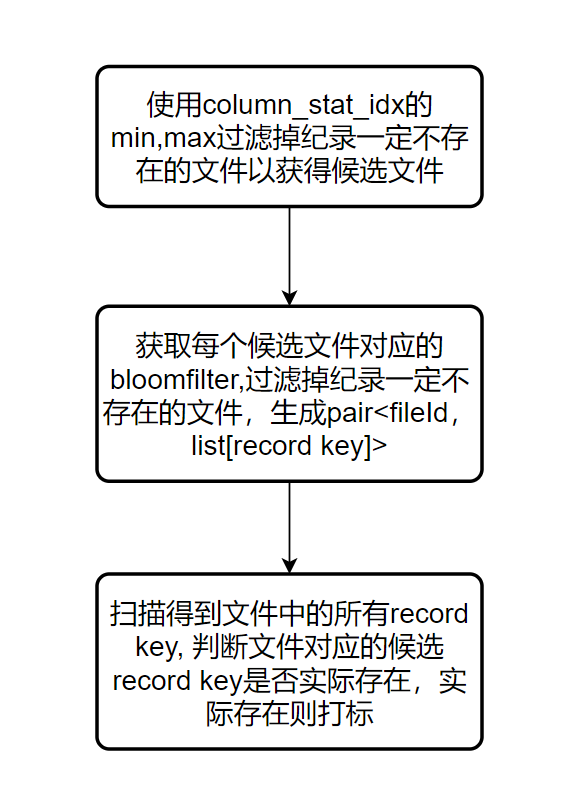
圖2. 2 spark寫入使用BloomIndex打標過程
BucketIndex和flink的bucket打標類似,通過hash(record_key) mod bucket_num的方式得到紀錄實際應該插入的檔案位置,如果該檔案不存在則為插入,存在則為更新。
HbaseIndex通過外部hbase服務儲存record key,因此打標過程需要和hbase服務進行互動,由於使用hbase儲存,因此該索引天然是全域性的。
讀取
Flink
flink讀取目前支援使用column_stats進行data skipping.建表時需要使能"metadata.enabled","hoodie.metadata.index.column.stats.enable","read.data.skipping.enabled",這三個引數。
Spark
spark讀取目前支援使用column_stats進行data skipping.建表時需要使能" hoodie.metadata.enabled","hoodie.metadata.index.column.stats.enable","read.data.skipping.enabled",這三個引數。
總結
寫入打標:
| column_stat_idx | bloom_filter_idx | bucket_idx | flink_state | Simple | Hbase_idx | |
|---|---|---|---|---|---|---|
| Spark | Y | Y | Y | N flink only | Y | Y |
| Flink | N | N | Y | Y | N spark only | N |
MetaDataTable表索引分割區構建:
| file_idx | column_stat_idx | bloom_filter_idx | |
|---|---|---|---|
| Spark | Y | Y | Y |
| Flink | Y | Y | Y |
讀取data skipping:
| column_stat_idx | bloom_filter_idx | bucket_idx | |
|---|---|---|---|
| Spark | Y | N | N |
| Flink | Y | N | N |
社群進展/規劃
Column Stats Index
RFC-27 Data skipping(column_stats) index to improve query performance
狀態:COMPLETED
簡述:列統計索引的rfc設計
原理:列統計索引儲存在metadata table中,使用hfile儲存索引資料
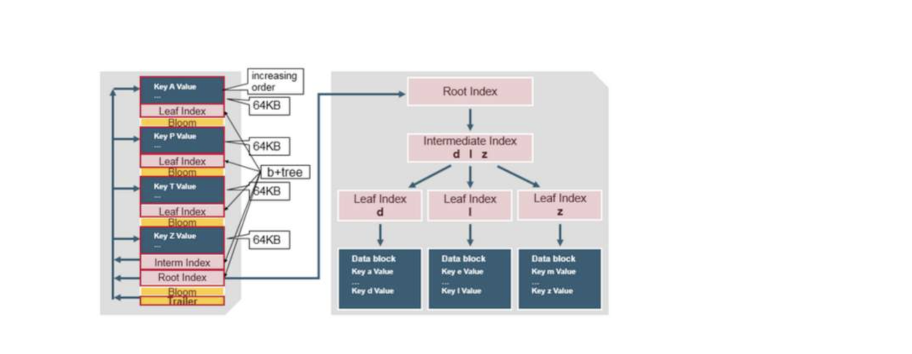
圖5. 1 hfile layout
HFile最大的優勢是資料按照key進行了排序,因此點查速度很快。
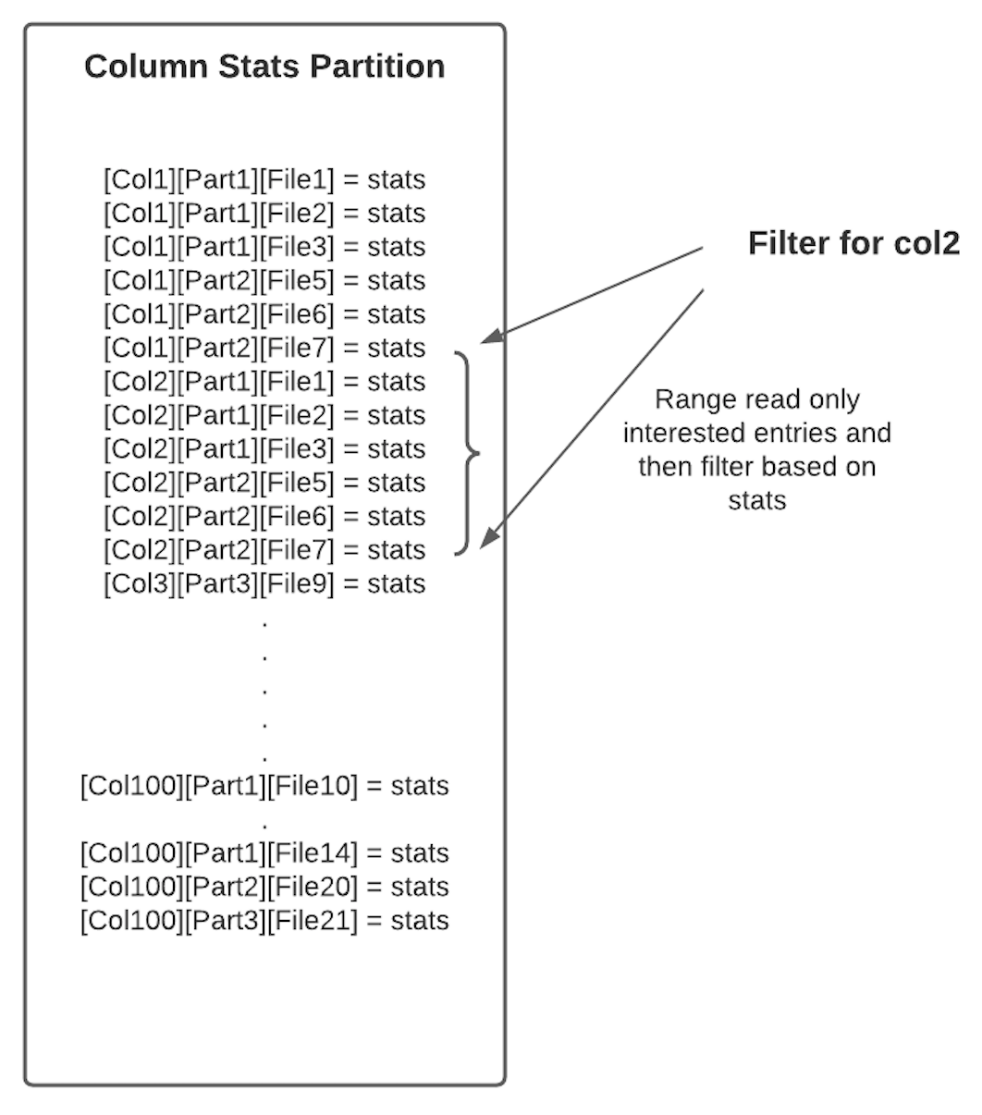
圖5. 2 column stats index storage format
由於HFile的字首搜尋速度很快,因此上述佈局(一個列的統計資訊在相鄰的data block中)可以快速拿到一個列在各個檔案中的統計資訊。
https://github.com/apache/hudi/blob/master/rfc/rfc-27/rfc-27.md
RFC-58 Integrate column stats index with all query engines
狀態:UNDER REVIEW
簡述:整合列統計索引到presto/trino/hive
原理:基於RFC-27 metadata table中的column_stats index來實現上述引擎的data skipping,當前有兩種可能的實現:基於列域(column domain, 域是一個列可能包含值的一個集合)的實現和基於hudiExpression的實現。

圖5. 3 HudiExpression sketch
https://github.com/apache/hudi/pull/6345/files?short_path=e681037
https://github.com/apache/hudi/pull/6345
Bucket Index
RFC-29 Hash(bucket) Index
狀態:COMPLETED
簡述:bucket index的rfc設計
原理:對主鍵做hash後取桶個數的模(hash(pk) mod bucket_num), 即資料在寫入時就按照主鍵進行了clustering,後續upsert可以直接通過hash找到對應的桶。
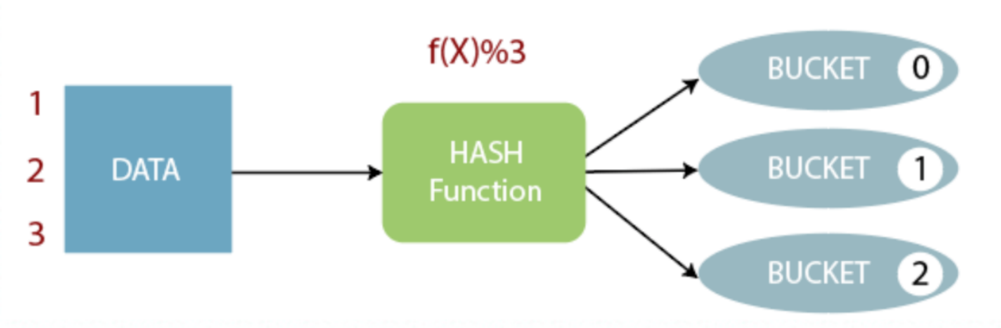
圖5. 4 hash process
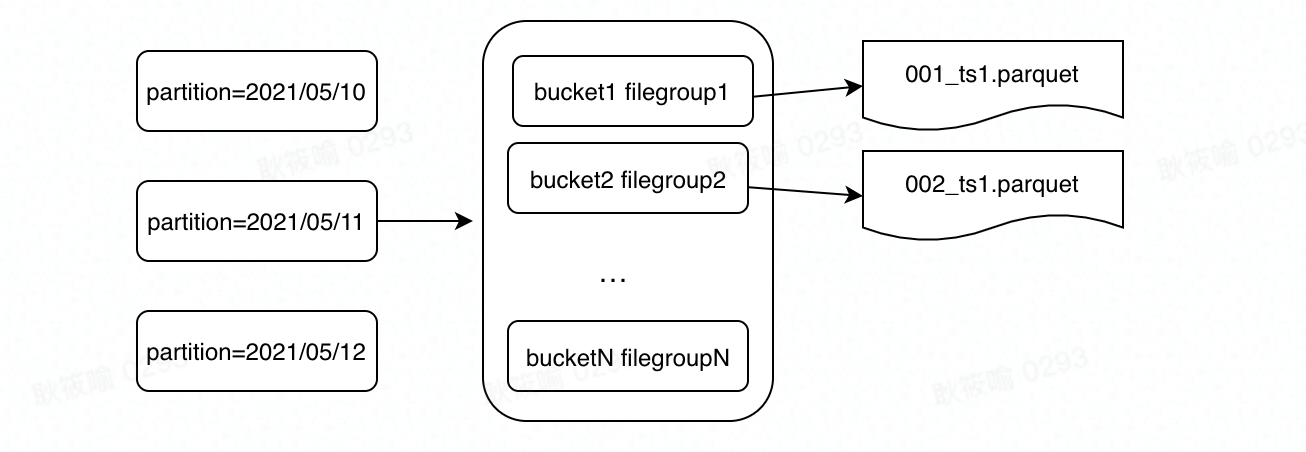
圖5. 5 bucket-filegroup mapping
目前一個桶和一個filegroup一一對應,資料檔案的字首會加上bucketId。
https://cwiki.apache.org/confluence/display/HUDI/RFC+-+29%3A+Hash+Index
RFC-42 Consistent hashing index for dynamic bucket numbers
狀態:ONGOING
簡述:bucket index一致性雜湊實現的rfc設計
原理:RFC-29實現的bucket index不支援動態修改桶個數,由此導致資料傾斜和一個file group size過大,採用一致性雜湊可以在不改變大多數桶的情況下完成桶的分裂/合併,以儘可能小的減小動態調整桶數量時對讀寫的影響。
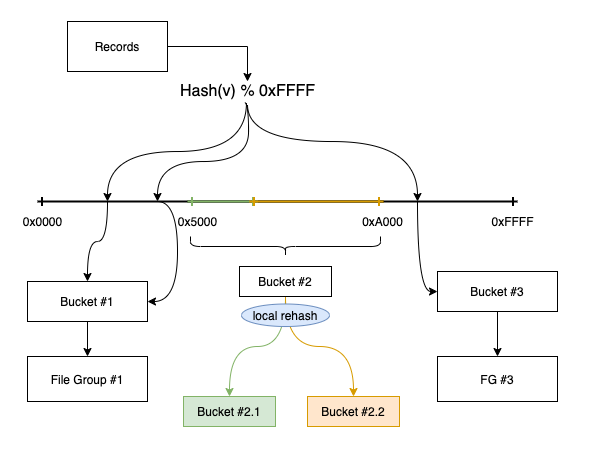
圖5. 6 一致性雜湊演演算法
通過Hash(v) % 0xFFFF得到一個範圍hash值,然後通過一個range mapping layer將雜湊值和桶關聯起來,可以看到如果bucket#2過大,可以將其對應的範圍0x5000-0xA000進行split分成兩個桶,僅需要在這個範圍內進行重新分桶/檔案重寫即可。
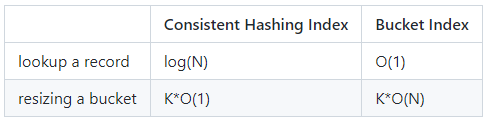
圖5. 7 演演算法複雜度對比
https://github.com/apache/hudi/blob/master/rfc/rfc-42/rfc-42.md
https://github.com/apache/hudi/pull/4958
https://github.com/apache/hudi/pull/6737
Bloom Index
RFC-37 Metadata based Bloom Index
狀態:COMPLETED
簡述:bloom index的rfc設計
原理:將base檔案內的bloom filter提取到metadata table中以減少IO,提升查詢速度
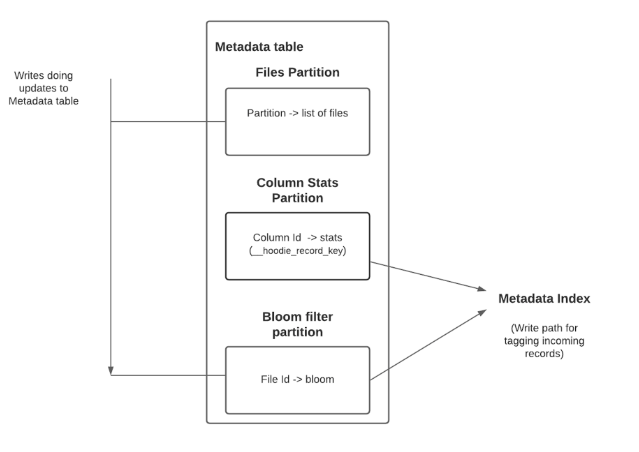
圖5. 8 bloom filter location in metadata table
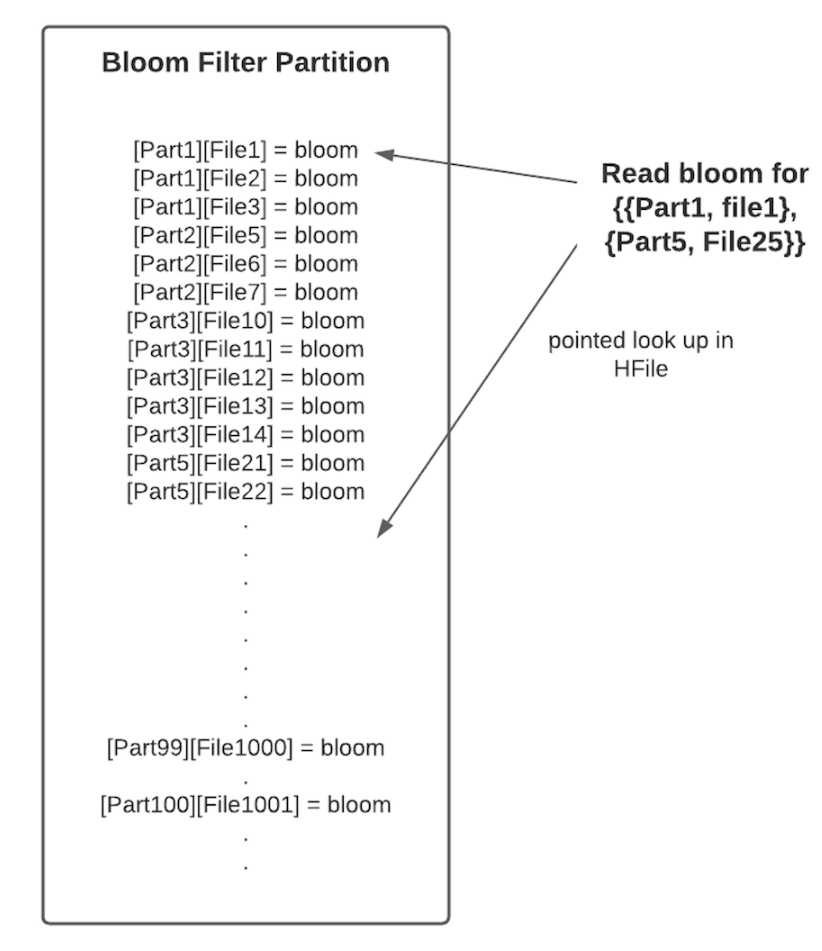
圖5. 9 bloom index storage format
Key的生成方式為:
key = base64_encode(concat(hash64(partition name), hash128(file name)))
因此一個分割區內的檔案天然的在HFile的相鄰data block中,採用base64編碼可以減少key的磁碟儲存空間。
https://github.com/apache/hudi/blob/master/rfc/rfc-37/rfc-37.md
Record-level Index
RFC-08 Record-level index to speed up UUID-based upserts and deletes
狀態:ONGOING
簡述:記錄級(主鍵)索引的rfc設計
原理:為每條記錄生成recordKey <-> partition, fileId的對映索引,以加速upsert的打標過程。
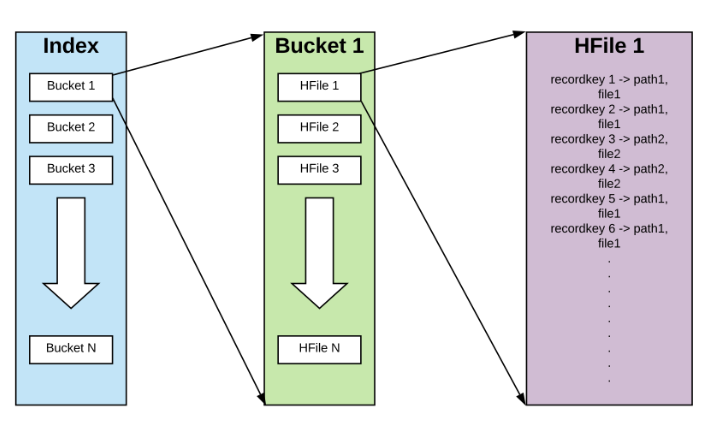
圖5. 10 行級索引實現
每條記錄被雜湊到對應的bucket中,每一個bucket中包含多個HFile檔案,每個HFile檔案的data block中包含recordKey <-> partition, fileId的對映。
https://issues.apache.org/jira/browse/HUDI-53
https://github.com/apache/hudi/pull/5581
Secondary Index
RFC-52 Secondary index to improve query performance
狀態:UNDER REVIEW
簡述:二級(非主鍵/輔助)索引的rfc設計
原理:二級索引可以精確匹配資料行(記錄級別索引只能定位到fileGroup),即提供一個column value -> row 的對映,如果查詢謂詞包含二級索引列就可以根據上述對映關係快速定位目標行。

圖5. 11 二級索引架構
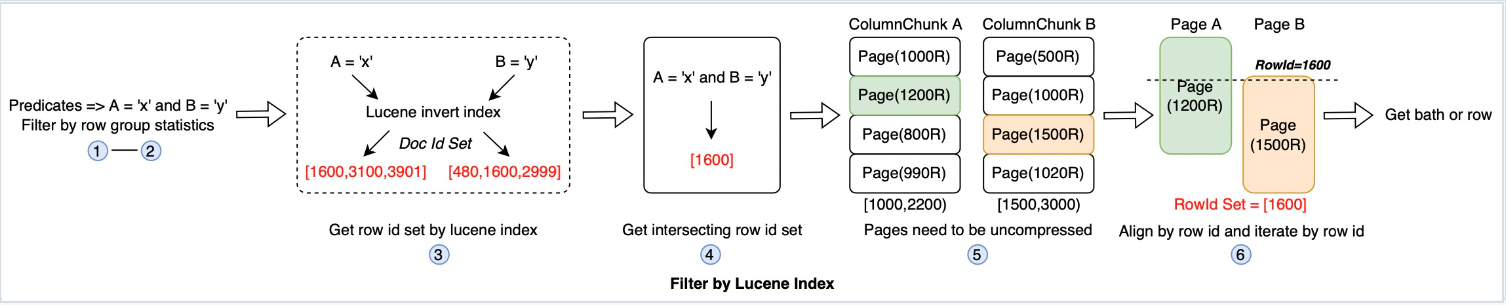
圖5. 12 使用Lucene index進行謂詞過濾
如上圖所示:先通過row group統計資訊進行首次過濾以載入指定page頁,然後通過lucene索引檔案(倒排索引,key為列值,value為row id集合)過濾出指定的行(以row id標識),合併各謂詞的row id,載入各個列的page頁並進行row id對齊,取出目標行。Lucene index只是二級索引框架下的一種可能實現。
https://github.com/apache/hudi/pull/5370
Function Index
RFC-63 Index on Function
狀態:UNDER REVIEW
簡述:函數索引的rfc設計
原理:通過sql或者hudi設定定義一個在某列上的函數作為函數索引,將其記錄到表屬性中,在資料寫入時索引函數可以作為排序域,由此每個資料檔案對應於索引函數值都有一個較小的min-max以進行有效的檔案過濾,同時metadata table中也會維護檔案級別的索引函數值對應的列統計資訊。資料檔案中不會新增索引函數值對應的列。
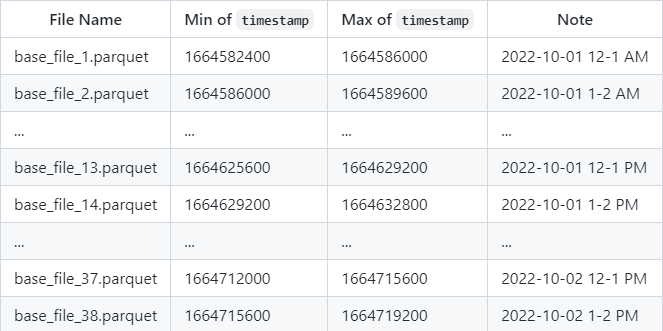
圖5. 13 帶timestamp的hudi表
如上圖所示,一個場景需要過濾出每天1點到2點的資料,由於把timestamp直接轉成小時將不會保序,就沒法直接使用timestamp的min,max進行檔案過濾,如果我們對timestamp列做一個HOUR(timestamp)的函數索引,然後將每個檔案對應的函數索引min,max值記錄到metadata table中,就可以快速的使用上述索引值進行檔案過濾。
https://github.com/apache/hudi/pull/5370
Support data skipping for MOR
Hudi當前還不支援針對MOR表中log檔案的索引,社群目前正在討論中:
https://issues.apache.org/jira/browse/HUDI-3866
https://cwiki.apache.org/confluence/display/HUDI/RFC+-+06+%3A+Add+indexing+support+to+the+log+file
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

