C#多執行緒(四)並行程式設計篇之結構化
前言
在前三章中我們的案例大量使用到了Thread這個類,通過其原始API,對其進行建立、啟動、中斷、中斷、終止、取消以及例外處理,這樣的寫法不僅不夠優雅(對接下來這篇,我稱其為.NET現代化並行程式設計體系中出現的API而言),並且大部分的介面都是極度複雜和危險的。很幸運,如今.NET已經提供,並且普及了一系列多執行緒API來幫助我們,優雅且安全的達到相同的目的。
其中,Parallel和Task被一起稱為TPL(Task Parallel Library,任務並行庫),而這對雙子星也就是我們本章的主題之一。如果您對執行緒基礎、並行原理不是很瞭解,我還是強烈建議先學習前面的章節,萬丈高樓平地起是前提是地基打的足夠結實!
一、PFX
Parallel Framework,並行框架:用於並行程式設計,幫助你充分利用CPU的多個核心。
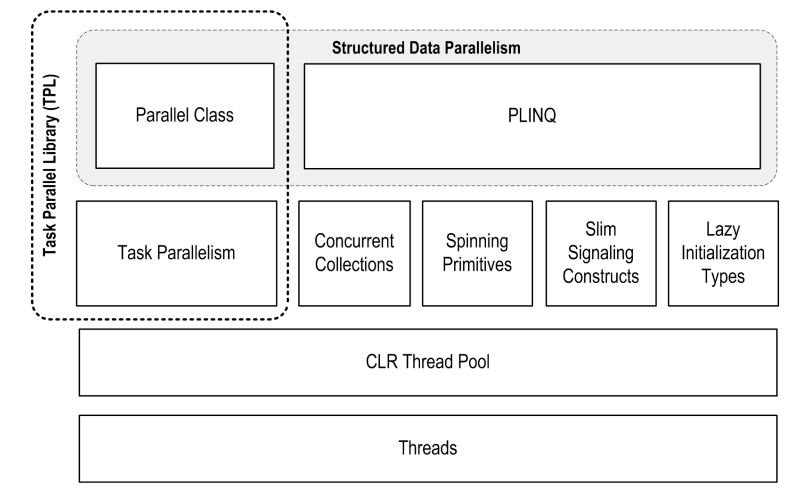
其中PLINQ提供最豐富的功能:它能夠自動化並行所有步驟--包括工作分解,多執行緒執行,並整理結果輸出一個序列。它是宣告式(declarative)的--你只需構造一個Linq,然後由框架來幫你完成剩下的工作。
Parallel和Task是指令式(imperative)的--你需要自己編寫程式碼來整理結果,甚至分解工作。
| Partitions work | Collates results | |
|---|---|---|
| PLINQ | Yes | Yes |
The Parallel class |
Yes | No |
| PFX’s task parallelism | No | No |
瘦訊號Slim Signaling 和 延遲初始化Lazy Initialization我們已經在前面的章節中講過了,並行集合Concurrent Collections 和 自旋基元Spinning Primitives事實上我們也模擬過,在本章會進一步來講。
這裡可能要解釋一下什麼是結構化:一切有條不紊、充滿合理邏輯和準則的。
在早期使用組合程式設計時,為了更加契合計算機執行的實際狀況,控制流分為「順序執行」和「跳轉」,這裡的跳轉也就是著名的--goto,無條件跳轉可能會使得程式碼執行雜亂無章,不可預測。Dijkstra著名的goto有害論的中翻地址:https://www.emon100.com/goto-translation/
一個定律
阿姆達爾定律 Amdahl's law,指出了固定負載(必須順序執行的部分)情況下,處理器並行運算的最大效能提升
討論:
綜上:
兩個密集
CPU密集型(CPU-bound)
也叫計算密集型,指的是系統的硬碟、記憶體效能相對CPU要好很多,此時,系統運作CPU讀寫IO(硬碟/記憶體)時,IO可以在很短的時間內完成,而CPU還有許多運算要處理,因此,CPU負載很高。
CPU密集表示該任務需要大量的運算,而沒有阻塞,CPU一直全速執行。CPU密集任務只有在真正的多核CPU上才可能得到加速(通過多執行緒),通常,執行緒數只需要設定為CPU核心數的執行緒個數就可以了。而在單核CPU上,無論你開幾個模擬的多執行緒該任務都不可能得到加速比,因為CPU總的運算能力就只有這麼多。
IO密集型(I/O bound)
IO密集型指的是系統的CPU效能相對硬碟、記憶體要好很多,此時,系統運作,大部分的狀況是CPU在等IO (硬碟/記憶體) 的讀寫操作,因此,CPU負載並不高。
IO密集型的程式一般在達到效能極限時,CPU佔用率仍然較低。這可能是因為任務本身需要大量I/O操作,而程式的邏輯做得不是很好,沒有充分利用處理器能力。通常就需要開CPU核心數數倍的執行緒。
CPU密集型 vs IO密集型
CPU密集型任務的特點就是需要進行大量計算(例如:計算圓周率、對視訊進行高清解碼、矩陣運算等情況)。 這一情況多出現在一些業務複雜的計算和邏輯處理過程中。比如說,現在的一些機器學習和深度學習的模型訓練和推理任務,包含了大量的矩陣運算。
IO密集型任務一般涉及到網路、磁碟IO,這類任務的特點是CPU消耗很少,任務的大部分時間都在等待IO操作完成(因為IO的速度遠遠低於CPU和記憶體的速度)。對於IO密集型任務,任務越多,CPU效率越高,但也有一個限度。常見的大部分任務都是IO密集型任務,比如Web應用。
兩個大類
使用PFX前需要檢查是否真的有必要並行,經過對阿姆達爾定律的瞭解,我們可以看出,並非使用更多的處理器,效能就能隨之水漲船高。如果順序執行的程式碼段佔了這個工作的三分之二,即使用無數核心,也無法獲得哪怕0.5倍的效能提升。
在並行中有可以分為兩大類
結構化並行
如果一個工作可以很容易被分解成多個任務,每個任務都能獨立高效的執行,那麼結構化並行無疑是非常合適的,例如圖片處理,光線追蹤,密碼暴力破解等。
非結構化並行
比方說多執行緒快排,我們可能需要自己拆解任務然後收集結果
https://cloud.tencent.com/developer/article/1560871
https://github.com/stephen-wang/parallel_quick_sort
二、PINQ
PLINQ就是Parallel LNQ,熟悉LNQ的小夥伴幾乎沒有額外的學習成本。
只需要在集合後面加個AsParallel(),就可以像平時寫LNQ一樣繼續使用了,Framework會自動的進行工作分解,然後呼叫核心執行任務,最終將各個核心的結果整理並返回給你。
下面的例子利用PLINQ查詢3到100,000內的所有素數
注意:這一部分提供的所有程式碼都可以在 LINQPad 中試驗。
IEnumerable<int> numbers = Enumerable.Range(3, 100000 - 3);
var parallelQuery =
from n in numbers.AsParallel()
where Enumerable.Range(2, (int)Math.Sqrt(n)).All(i => n % i > 0)
select n;
int[] primes = parallelQuery.ToArray();
當然你也可以
var parallelQuery = numbers.AsParallel().Where(x => Enumerable.Range(2, (int)Math.Sqrt(x)).All(i => x % i > 0));
但一定不要,先操作再分割區等於分了個寂寞
var parallelQuery = numbers.Where(x => Enumerable.Range(2, (int)Math.Sqrt(x)).All(i => x % i > 0)).AsParallel();
這裡我不再過多討論語法上的東西,大家自己多嘗試。
注意事項:
- PLINQ僅適用於本地集合
- 查詢過程中各個分割區產生的異常會封送到
AggregateException然後重新丟擲 - 預設情況下是無序的,但可以使用
AsOrdered有序,但是效能也會有所消耗 - 執行過程必須是執行緒安全的,否則結果不可靠
- 並行化過程的任務分割區,結果整理,以及執行緒開闢和管理都需要成本
- 如果它認為並行化是沒有必要的,會使查詢更慢的,會轉為順序執行
- 預設情況下,PLINQ總會認為你執行的是CPU Bound,然後開啟核心數個任務
緩衝行為
PLINQ和LINQ一樣,也是延遲查詢。不同的是,
LINQ完全由使用方通過「拉」的方式驅動:每個元素都在使用方需要時從序列中被提取。
而PLINQ通常使用獨立的執行緒從序列中提取元素,然後通過查詢鏈並行處理這些元素,將結果儲存在一個小緩衝區中,以準備在需要的時候提供給使用方。如果使用方在列舉過程中暫停或中斷,查詢也會暫停或停止,這樣可以不浪費 CPU 時間或記憶體。
你可以通過在AsParallel之後呼叫WithMergeOptions來調整 PLINQ 的緩衝行為,ParallelMergeOptions有以下幾種模式
Default,預設使用AutoBuffered通常能產生最佳的整體效果NoBuffered,禁用緩衝,一旦計算出結果,該元素即對查詢的使用者可用AutoBuffered,由系統選擇緩衝區大小,結果會在可供使用前輸出到緩衝區FullyBuffered,完全緩衝,使用時可以得到全部計算結果(OrderBy,Reverse)。
順序性
PLINQ的結果預設就是無序的,無法像LINQ那樣保證輸出順序與輸入順序一致。如果你希望保持一致,可以在AsParallel()後新增AsOrdered()
var parallelQuery =
from n in numbers.AsParallel().AsOrdered()
where Enumerable.Range(2, (int)Math.Sqrt(n)).All(i => n % i > 0)
select n;
如何序列元素過多,AsOrdered會造成一定效能損失,因為 PLINQ 必須跟蹤每個元素的原始位置。你可以通過AsUnordered來取消AsOrdered的效果:這會引入一個「隨機洗牌點(random shuffle point)」,允許查詢從這裡開始不再跟蹤。
限制
目前,PLINQ 在能夠並行化的操作上有些實用性限制。
-
Aggregate操作符的帶種子(seed)的過載是不能並行化的,ForAll可以解決這個問題。其它所有操作符都是可以並行化的,然而使用這些操作符並不能確保你的查詢會被並行化。
-
預設情況PLINQ 將檢查查詢的結構,並且只有在可能導致加速的情況下才會並行化查詢。 如果查詢結構表明不可能獲得加速比,則 PLINQ 將執行查詢作為普通的 LINQ to Objects 查詢。你可以覆蓋這個預設行為,強制開啟並行化:
AsParallel().WithExecutionMode(ParallelExecutionMode.ForceParallelism) -
對於那些接受兩個輸入序列的查詢操作符,必須在這兩個序列必須都是
ParallelQuery(否則將丟擲異常)
Join、GroupJoin、Contact、Union、Intersect、Except和Zip- 這些操作可以並行化,但會使用代價高昂的雜湊分割區(Hash partitioning),有時可能比順序執行還慢。
- 大多數查詢操作都會改變元素的索引位置(包括可能移除元素的那些操作,例如
Where)。這意味著如果你希望使用這些操作,就要在查詢開始的地方使用。 - PLINQ會並行的在多個執行緒上執行,不要執行非執行緒安全的操作。雖然可以使用前面講過的同步構造來解決執行緒安全問題,但是為了達到最佳效能,確保並行能力不會受到限制。
CPU密集型案例
在這個案例中我們下載了約 150,000 個單詞放到HashSet中
if (!File.Exists("WordLookup.txt")) // 包含約 150,000 個單詞
{
var res = new HttpClient().GetByteArrayAsync(new Uri("http://www.albahari.com/ispell/allw
.GetAwaiter().GetResult();
File.WriteAllBytes("WordLookup.txt", res);
}
var wordLookup = new HashSet<string>(
File.ReadAllLines("WordLookup.txt"),
StringComparer.InvariantCultureIgnoreCase);
然後隨機生成一份100,0000萬單詞的測試資料,由於是並行生成,隨機需要考慮執行緒安全
string[] wordList = wordLookup.ToArray();
var localRandom = new ThreadLocal<Random>
( () => new Random (Guid.NewGuid().GetHashCode()) );
string[] wordsToTest = Enumerable.Range(0, 100_0000).AsParallel()
.Select(i => wordList[localRandom.Value.Next(0, wordList.Length)])
.ToArray();
wordsToTest[12345] = "woozsh"; // 引入兩個拼寫錯誤
wordsToTest[23456] = "wubsie";
現在,根據workLookup檢查每一個測試資料,最後輸出檢查到的錯誤拼寫
var query = wordsToTest
.AsParallel()
.Select((word, index) => new IndexedWord { Word = word, Index = index })
.Where(iword => !wordLookup.Contains(iword.Word))
.OrderBy(iword => iword.Index);
//query.Dump(); // 在 LINQPad 中顯示輸出
foreach (var item in query)
{
_testOutputHelper.WriteLine($"單詞:{item.Word} 拼寫錯誤,索引:{item.Index}");
}
其中IndexedWord是一個自定義的結構體。
struct IndexedWord { public string Word; public int Index; }
使用類也能獲得相同的結果,但是效能會有所下降。因為類是參照型別,在堆中分配,只後還有垃圾回收。
這個區別對LINQ而言影響並不是很大,但對於PLNQ而言,基於棧的記憶體分配相當有利。因為每個執行緒都有自己的獨立棧,可以高度並行化,而堆記憶體會使多個執行緒競爭同一個堆(競態),它是由單一的記憶體管理器和垃圾回收器管理的。
輸出,成功的找到了剛剛故意引入拼寫錯誤的兩個單詞
單詞:woozsh 拼寫錯誤,索引:12345
單詞:wubsie 拼寫錯誤,索引:23456
IO密集型案例
Ping
這個案例中我們希望同時ping 2個網站,如果我們執行在的是一個單核機器上,PLINQ 只會預設執行 1 個任務,顯然這不是我們希望的。
我們可以使用WithDegreeOfParallelism強制 PLINQ 同時執行指定數量的任務:
注意,PLINQ 切分的任務是由執行緒池執行緒執行,執行緒池的執行緒並不是取之不盡用之不竭的,具體在下一part講。
new[]
{
"www.oreilly.com",
"stackoverflow.com",
}
.AsParallel().WithDegreeOfParallelism(2).Select(site =>
{
var p = new Ping().Send(site);
return new
{
site,
Result = p.Status,
Time = p.RoundtripTime
};
}).ForAll(res =>
{
_testOutputHelper.WriteLine(res.site + $" coast {res.Time}:" + res.Result);
});
輸出:
stackoverflow.com coast 173ms : Success
www.oreilly.com coast 219ms : Success
監控系統
假設我們要實現一個,希望它不斷將來自 4 個安全攝像頭的影象合併成一個影象,並在閉路電視上顯示。使用下邊的Camera類來表示一個攝像頭:
class Camera
{
public readonly int CameraID;
public Camera(int cameraID)
{
CameraID = cameraID;
}
// 獲取來自攝像頭的影象: 返回一個字串來代替影象
public string GetNextFrame()
{
Thread.Sleep(123); // 模擬獲取影象的時間,真實情況下這部分應該是IO密集操作
return "Frame from camera " + CameraID;
}
}
要獲取一個合成影象,我們必須分別在 4 個攝像頭物件上呼叫GetNextFrame。假設操作主要是受 I/O 影響的,即使是在單核機器上,通過並行化我們都能將影格率提升 4 倍。
Camera[] cameras = Enumerable.Range(0, 4) // 建立 4 個攝像頭物件
.Select(i => new Camera(i))
.ToArray();
while (true)
{
string[] data = cameras
.AsParallel()
.AsOrdered() // 這裡這有四個元素,追蹤的成本幾乎可以忽略不計算
.WithDegreeOfParallelism(4)
.Select(c => c.GetNextFrame()).ToArray();
_testOutputHelper.WriteLine(string.Join(", ", data)); // 顯示資料...
}
在一個 PLINQ 中,僅能呼叫
WithDegreeOfParallelism一次。如果你需要再次呼叫它,必須再次呼叫AsParallel()強制進行查詢的合併和重新分割區
取消
Parallel切分多個任務,將任務交由執行緒池執行緒處理,執行緒池的任務是支援取消令牌(安全取消共同作業模式),Parallel同理支援CancellationToken。我們使用之前使用的找PLINQ 素數案例,然後起一個任務,在2ms後取消。
IEnumerable<int> numbers = Enumerable.Range(3, 1000000 - 3);
var cancelSource = new CancellationTokenSource();
var parallelQuery = numbers
.AsParallel()
//.WithMergeOptions(ParallelMergeOptions.FullyBuffered)
.WithCancellation(cancelSource.Token)
.Where(x => Enumerable.Range(2, (int)Math.Sqrt(x)).All(i => x % i > 0));
Task.Run(() => { Thread.Sleep(2); cancelSource.Cancel(); });
下面是消費者程式碼,為了防止列印太多,我們間隔500個列印一次
try
{
int cnt = 0;
foreach (var prime in parallelQuery)
{
if (cnt % 500 == 0) _testOutputHelper.WriteLine(prime.ToString());
cnt++;
}
}
catch (OperationCanceledException e)
{
_testOutputHelper.WriteLine("工作已經被取消");
}
結果是列印了一些後丟擲OperationCanceledException
23
9341
12941
16879
...
工作已經被取消
PLINQ 不會直接中止執行緒,因為這麼做是危險的。在取消時,它會等待所有工作執行緒處理完當前的元素,然後才丟擲
OperationCanceledException結束查詢。接下來我們會大量出現這種模式,這也是受益PFX底層設計保持高度一致。
聚合
PLINQ 可以在無需額外干預的情況下有效地並行化Sum、Average、Min和Max操作,但自定義聚合Aggregate是個例外。
我們先看一下LINQ 中用Aggregate 是如何實現Sum 的:
int sum = Enumerable.Range(1, 10).Aggregate((pre, cur) => pre + cur);
對於第一次見到Aggregate 的同學,可能會很難理解上面這段程式碼,那我們先來看一下原始碼:
public static TSource Aggregate<TSource>(
this IEnumerable<TSource> source,
Func<TSource, TSource, TSource> func)
{
if (source == null)
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.source);
if (func == null)
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.func);
using (IEnumerator<TSource> enumerator = source.GetEnumerator())
{
if (!enumerator.MoveNext())
ThrowHelper.ThrowNoElementsException();
TSource source1 = enumerator.Current;
while (enumerator.MoveNext())
source1 = func(source1, enumerator.Current);
return source1;
}
}
就這?是不是簡單的令人髮指。。沒錯就是拿到第一個元素,如果沒有就拋異常(帶seed引數的過載不會哦)然後開始迴圈迭代,每次迭代用上個元素pre的當前元素cur計算下一次迭代的pre
正因為他如此簡單,因為但凡能用Aggregate 解決的問題,都能用迴圈輕鬆解決。。那大家為啥不選後面這種更為熟悉的語法呢?其實啊,Aggregate 並非一無是處,在PLINQ 中他是大有可為的,為什麼?因為結構化並行啊 ^ v ^ ...
給大家看一個假象:
int sum = Enumerable.Range(1, 100_0000).AsParallel().Aggregate(0,(pre, cur) => pre + cur);
我們在限制中明確指明瞭,帶seed的Aggregate 是不支援並行的,因為多個分割區依賴同一個種子,解決方案是ForAll,這裡Aggregate其實還提供一種:指定種子工廠,形成區域性種子,每個執行緒獨立一個累加器,最終merge時,合併到主累加器
int sum = Enumerable.Range(1, 100_0000).AsParallel().Aggregate(
() => 0,
(pre, cur) => pre + cur,
(main, local) => main + local,
x => x);
不要拿大炮打蚊子
"Let’s suppose this is a really long string"
.AsParallel()
.Aggregate(
() => new int[26],
(pre, cur) =>
{
int index = char.ToUpper(cur) - 'A';
if (index is >= 0 and <= 26) pre[index]++;
return pre;
},
(main, local) => main.Zip(local, (a, b) => a + b).ToArray(),
x => x);
優化
輸入端優化
PLINQ有三種分割區策略,來將序列元素分配到各個任務
| Strategy | Element allocation | Relative performance |
|---|---|---|
| Chunk partitioning | Dynamic | Average |
| Range partitioning | Static | Poor to excellent |
| Hash partitioning | Static | Poor |
對於那些需要比較元素的查詢操作符(GroupBy、Join、GroupJoin、Intersect、Except、Union和Distinct),PLINQ 總是使用雜湊分割區(Hash partitioning)。雜湊分割區相對低效,因為它必須預先計算每個元素的雜湊值(Hash code)(擁有同樣雜湊值的元素會在同一個執行緒中被處理)。如果你發現執行太慢,唯一的選擇是呼叫AsSequential來禁止並行處理。
對於其它所有查詢操作符,你可以選擇使用範圍分割區(Range partitioning)或塊分割區(Chunk partitioning),預設情況下:
- 如果輸入序列可以通過索引存取(
Array或IList<T>的實現),PLINQ 選用範圍分割區,範圍分割區會為每個工作執行緒平均的分配元素。如果序列中每個元素處理時間接近,那範圍分割區是效率最高的分割區策略,因為他幾乎沒有額外的分割區成本。
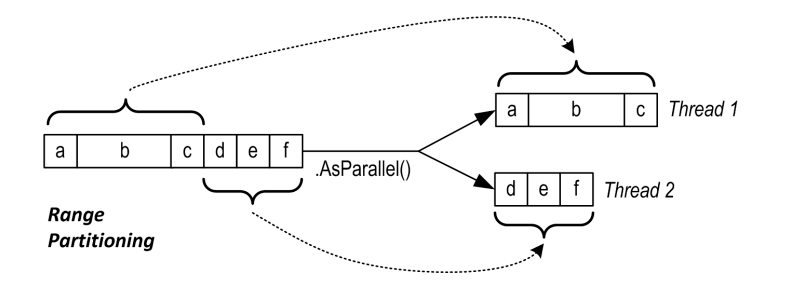
並不一定是相鄰分配,也可能採用條紋式(striping)策略
- 否則,PLINQ 選用塊分割區。塊分割區定期從序列中抓取小塊(一個或兩個元素),塊大小隨查詢的進度逐漸變大。如果一個工作執行緒恰好拿到了一些相對容易的塊,它最終會獲取更多塊,這個設計可以使核心負載均衡。但由於執行緒從序列中抓取塊是需要同步的,因此會有一定的開銷和競爭。
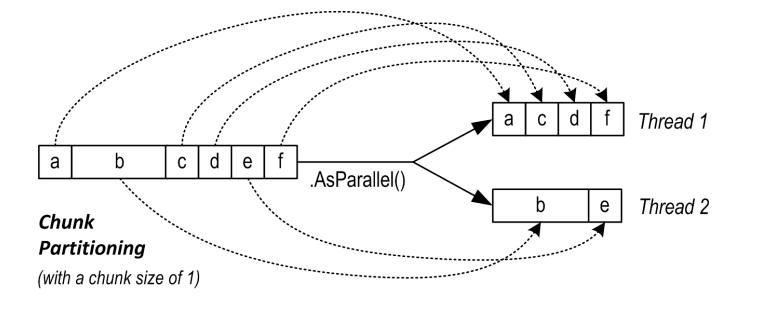
每個元素處理時間接近的適合範圍分割區,否則塊分割區更快,你也可以強制指定分割區策略:
-
強制使用範圍分割區
-
使用
ParallelEnumerable下的方法,可以主動啟用範圍分割區。ParallelEnumerable.Range(1,10); ParallelEnumerable.Repeat(1,10); ... -
在輸入序列上呼叫
ToList或ToArray,使其走預設的範圍分割區(顯然,你需要考慮在這裡產生的效能開銷)。使用
ParallelEnumerable中返回IParallelQuery的方法不需要再呼叫AsParallel(這裡有防呆設計)
-
-
強制使用塊分割區
-
呼叫名稱空間
System.Collection.Concurrent下Partitioner.Create來封裝輸入序列int[] numbers = { 3, 4, 5, 6, 7, 8, 9 }; var parallelQuery = Partitioner.Create(numbers, true) .AsParallel() ...第二個引數一定要傳
true,表示開啟負載均衡,使用動態分割區。否則用的是靜態索引做範圍分割區。到底是什麼分割區,用的時候還是建議自己去看一下原始碼,這一塊策略較多,講不完。
-
輸出端優化
PLINQ 的一個優點是它能夠很容易地將並行化任務的結果整理成一個輸出序列。有時,我們要在輸出序列的每個元素上執行一些方法:
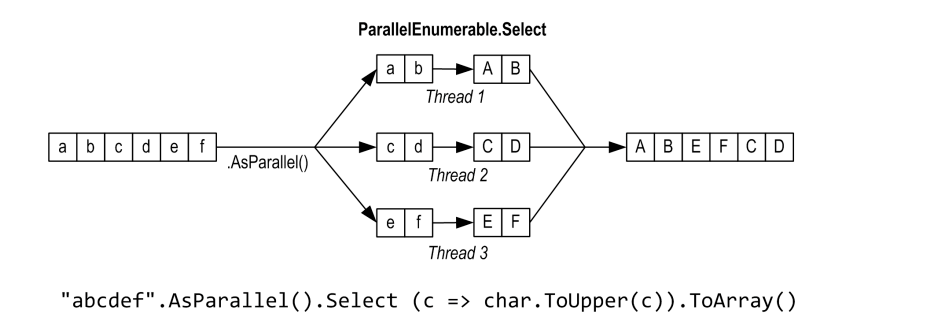
foreach (var item in "abcdef".AsParallel().Select (c => char.ToUpper(c)))
{
_testOutputHelper.WriteLine(item.ToString());
}
如果不不關心處理順序,那麼可以使用ForAll 跳過對結果的整理來提效:
"abcdef".AsParallel().Select (c => char.ToUpper(c)).ForAll(item => _testOutputHelper.WriteLine(item.ToString()));
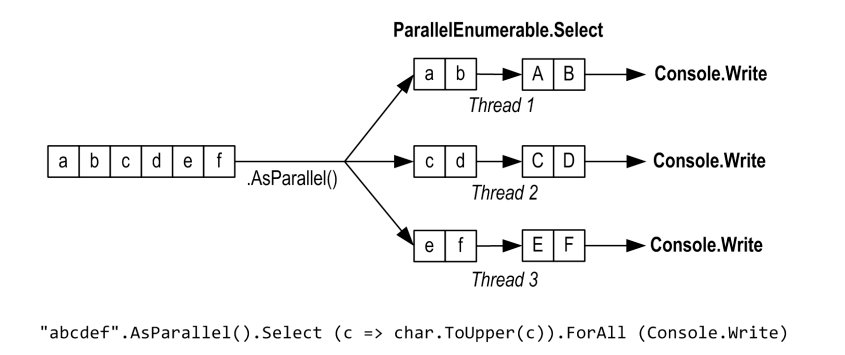
結果的整理和列舉開銷相對並不大,只有當序列非常大且執行迅速時才能體現,例如圖片處理,整理幾百萬個畫素到輸出序列可能形成效能瓶頸。更好的方法是把畫素直接寫入陣列或非託管的記憶體塊,然後使用
Parallel類或Task來管理多執行緒也可以直接使用ForAll來繞過結果整理。
.NET現代化並行程式設計系統的雙子星即將登場。。。
三、Parallel
名稱空間System.Threading.Tasks下的Parallel,API奇了怪的精簡
Parallel.Invoke並行執行一組任務ActionParallel.Forfor迴圈的並行版本Parallel.ForEachforeach迴圈的並行版本Parallel.ForEachAsyncforeach的非同步並行版本,返回一個Task
沒了,就這四種。。前面三個方法都會在全部工作完全前阻塞,類似PLINQ,如果發生異常,工作執行緒會在完成當前迭代後退出,然後講異常封送到AggregateException 最終拋給呼叫方。
這些API在你傳遞遠超於處理器核心數量的任務時仍然能夠高效功能,他們會對任務進行分割區,再對其分配底層的Task,而非對每一個任務建立獨立的Task
Invoke
Parallel.Invoke 並行執行一組任務Action,然後等待他們完成
Parallel.Invoke(
() => new Ping().Send("www.oreilly.com"),
() => new Ping().Send("stackoverflow.com"));
Parallel的所有方法都不會自行對結果收集,我們需要自己收集
var res = new List<string>();
Parallel.Invoke(
() =>
{
var p = new Ping().Send("www.oreilly.com");
res.Add(p.Address + $" coast {p.Status}ms : " + p.RoundtripTime);
},
() =>
{
var p = new Ping().Send("stackoverflow.com");
res.Add(p.Address + $" coast {p.Status}ms : " + p.RoundtripTime);
});
foreach (var item in res)
{
_testOutputHelper.WriteLine(item);
}
輸出:
151.101.193.69 coast Successms : 166
23.7.172.78 coast Successms : 227
上面這份程式碼有個陷阱,由於兩個任務之間沒有發生競態(他們相隔實在太遠啦),因此讓我們忽略了執行緒安全問題。哪怕是在收集資料,也請不要忽略,這兩個委託可能是在不同執行緒上執行的,對公共資料寫入當然會引發執行緒安全問題,這一點我們在前面的章節中已經講爛了。
只要將List 替換成ConcurrentBag即可,並行集合也屬於PFX的組成部分,下文再具體講。
var res = new ConcurrentBag<string>();
ParallelOptions
Parallel 的四種方法均提供過載接受一個引數ParallelOptions
new ParallelOptions
{
CancellationToken = default, // 取消令牌,預設CancellationToken.None,沒得
MaxDegreeOfParallelism = Environment.ProcessorCount, // 最大並行度,預設是CPU核心數
TaskScheduler = null // 任務排程器,預設TaskScheduler.Default,由執行緒池排程
},
取消
ok,我們給上面那個ping加個超時取消看看
...
var source = new CancellationTokenSource();
source.CancelAfter(1);
Parallel.Invoke(
new ParallelOptions
{
CancellationToken = source.Token,
},
...
結果是不管我在多久後取消,哪怕1ms後就取消令牌,結果都沒變化。。莫非取消令牌壞了嗎?當然不是啦,還記得我們從第一章講執行緒基礎的時候就提到的取消共同作業模式嗎,這種模式是安全的,他不會立即幹掉正在執行迭代中的執行緒,而是等待執行緒執行完本次迭代,這種思路貫徹整個執行緒取消設計。
For與ForEach
命名上大家就應該能看懂這在幹什麼了,沒錯,就是並行版本的迴圈
public static ParallelLoopResult For(int fromInclusive, int toExclusive, Action<int> body)
public static ParallelLoopResult ForEach<TSource>(IEnumerable<TSource> source, Action<TSource> body)
使用Parallel.For並行生成六組金鑰對
var keyPairs = new string[6];
Parallel.For(0, keyPairs.Length,
i => keyPairs[i] = RSA.Create().ToXmlString(true));
同樣可以使用PLINQ,他們在結構和結果上是一致的
string[] keyPairs =
ParallelEnumerable.Range(0, 6)
.Select(i => RSA.Create().ToXmlString(true))
.ToArray();
索引
Parallel.ForEach 中使用索引需要用另一個過載:
public static ParallelLoopResult ForEach<TSource>(IEnumerable<TSource> source, Action<TSource, ParallelLoopState, long> body)
第三個引數long型別的i,就是索引
Parallel.ForEach("Hello, worldmmmmmmmmmmmm", (c, state, i) =>
{
_testOutputHelper.WriteLine(i++ + c.ToString());
});
那我們繼續,用Parallel.ForEach 來改造一下之前的拼寫檢查。由於我們不需要在去Select一次了,這次不用結構體也無所謂,因為Add不會成為瓶頸。
var errors = new ConcurrentBag<(long Index, string Word)>();
Parallel.ForEach(wordsToTest, (word, state, i) =>
{
if (!wordLookup.Contains(word)) errors.Add((i, word));
});
跳出迴圈
Parallel迴圈 並不能像普通迴圈那樣使用 break 語句來跳出迴圈,不過它提供了 ParallelLoopState來幫助你完成這個需求
Parallel.ForEach("Hello, worldmmmmmmmmmmmmmmm", (c, state) =>
{
if (c == 'l') state.Stop();
_testOutputHelper.WriteLine(c.ToString());
}
你會發現輸出了核心數個字元。
使用Break也能跳出並行迴圈,但是可能會多輸出幾個。原因是Break傳達的:是希望系統在方便的時候儘早的跳出。而Stop傳達的是:立刻(遵循共同作業取消模式)。
ParallelLoopState 還提供了一些常用屬性:
ShouldExitCurrentIteration:收到任何退出迴圈的通知,這個屬性都會變成true,包括Stop、Break、取消、異常。IsExceptional:可以知曉是否有異常發生。
ParallelLoopResult
Parallel迴圈 返回的是一個結構體ParallelLoopResult,它有兩個屬性:
IsCompleted:表示迴圈是執行完成,False表示提前結束LowestBreakIteration:獲取Break呼叫出的元素索引,如果是通過Stop退出的,則為null
聚合
如果我們要計算1到1000萬的平方根之和,並行非常容易(加法滿足交換律和結合律)。但是求和就麻煩了,需要加鎖,這成為了程式的瓶頸。
var locker = new object();
double total = 0;
Parallel.For(1, 1000_0000, x =>
{
lock (locker)
{
total += Math.Sqrt(x);
}
});
在PLINQ 中,我們講聚合的時候提到一種區域性種子的方案,這裡是不是也能參考呢?事實上我們真的需要1000w次排隊累加嗎,我們難道不能在各個執行緒設定獨立的累加器,然後累加這些累加器嗎?Parallel的迴圈還真提供了這樣的過載:
var locker = new object();
double total = 0;
Parallel.For(1, 1000_0000,
() => 0.0,
(x, state, local) => local + Math.Sqrt(x),
local =>
{
lock (locker)
{
total += local;
}
});
簡單一跑,效能百倍提升~
這個案例只是為了說明Parallel,其實用PLINQ 更為簡單:
var res = ParallelEnumerable.Range(1, 1000_0000)
.Sum(x => Math.Sqrt(x));
ForEachAsync
為什麼單獨來一part ForEachAsync,這玩意看名字不就是ForEach的非同步版本嗎。nonono,這玩意我單獨拎出來給大家隆重介紹,NET6 引入的
public static Task ForEachAsync<TSource>(IEnumerable<TSource> source, Func<TSource, CancellationToken, ValueTask> body)
public static Task ForEachAsync<TSource>(IEnumerable<TSource> source, CancellationToken cancellationToken, Func<TSource, CancellationToken, ValueTask> body)
public static Task ForEachAsync<TSource>(IEnumerable<TSource> source, ParallelOptions parallelOptions, Func<TSource, CancellationToken, ValueTask> body)
你仔細想想,在NET6之前,Task的並行度你咋控制?你是不是這樣的
using var semaphore = new SemaphoreSlim(6, 6);
var tasks = Enumerable.Range(1, 100).Select(async x =>
{
try
{
await semaphore.WaitAsync();
await Task.Delay(1000);
_testOutputHelper.WriteLine("執行緒 " + Thread.CurrentThread.ManagedThreadId + " 幹了活" + x);
}
finally
{
semaphore.Release();
}
});
Task.WaitAll(tasks.ToArray());
現在有了Parallel提供的ForEachAsync,你只需要這樣:
await Parallel.ForEachAsync(Enumerable.Range(1, 100), new ParallelOptions()
{
MaxDegreeOfParallelism = 10
}, async (x, _) =>
{
await Task.Delay(1000);
_testOutputHelper.WriteLine("執行緒 " + Thread.CurrentThread.ManagedThreadId + " 幹了活" + x);
});
比較遺憾的是,ForEachAsync 並不像ForEach 那樣提供了索引。。