【機器學習】李宏毅——生成式對抗網路GAN
1、基本概念介紹
1.1、What is Generator
在之前我們的網路架構中,都是對於輸入x得到輸出y,只要輸入x是一樣的,那麼得到的輸出y就是一樣的。
但是Generator不一樣,它最大的特點在於多了另外一個具有隨機性的輸入,如下圖:
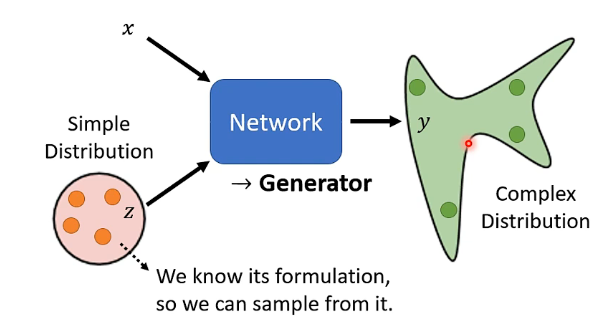
其中輸入除了x之外,還有一個z,而z是從一個已知的分佈之中進行取樣得到的,例如高斯分佈等等。那麼由於z具有一定的隨機性,那麼由x與z獲得的輸出y也就不再只是一個確定的值,而是一個複雜的分佈。
1.2、Why distribution
為什麼需要將輸出y變成一個分佈呢?來看下面這個例子:
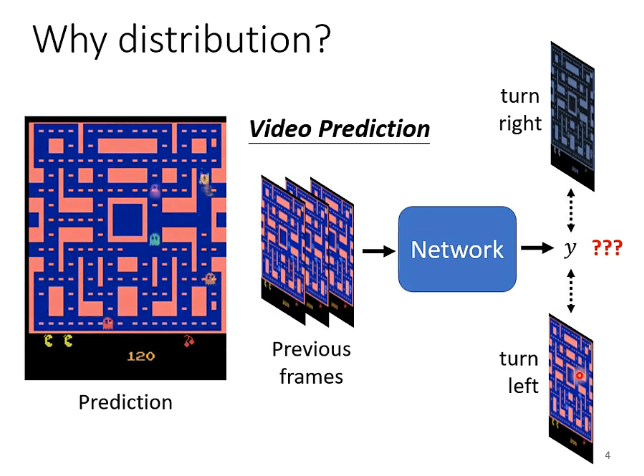
假設我們現在正在做一個畫面預測的任務,根據以前的畫面資料預測接下來裡面的小精靈會往哪裡走動。但是以往的資料中可能會存在衝突的資料,即例如同一隻小精靈在相同的轉角處它選擇了不同的選擇,某次向左某次向右,這就相當於告訴機器它做出向左向右的預測都是對的,但是它為了擬合這兩份資料它就可能在預測的時候直接將一隻小精靈進行復制,一隻向左一隻向右來同時滿足最小化誤差的學習。但這在我們看來是不合理的。因此我們可以給網路增加一個輸入z,由某個分佈中取樣得到的z來使得y也是一個分佈,那麼y就根據取樣得到的z來決定我這一次是向左轉還是向右轉。
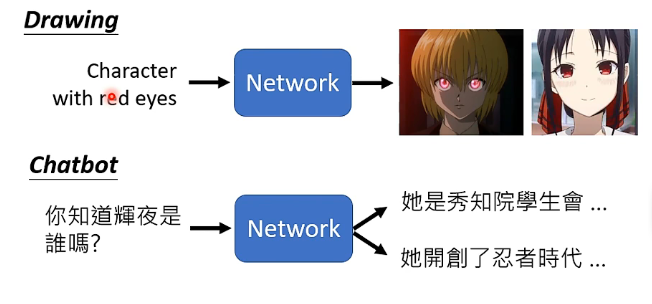
那麼實際上在一些需要一定的創造力的任務中就需要輸出是一個分佈,即某一些任務並不是只有唯一的答案,它面對相同的輸入可以有很多個正確的答案,那麼這個時候我們就希望y可以是一個分佈,如下圖:
1.3、Generative Adversarial Network(GAN)
先介紹一下Contional Generation和Uncontional(無條件、無限制) Generation這兩者的差別,前者就是之前講的網路的輸入有x和z,而後者就是網路的輸入單純只有z而已。下面我們將以Uncontional Generation用來生成動漫人臉的例子來進行介紹。
需要注意的是一般來說z都是一個較為低緯度的向量,而輸出的y如果是一張圖片那麼將是一個高維的向量,這中間的轉換就是由Generator來實現
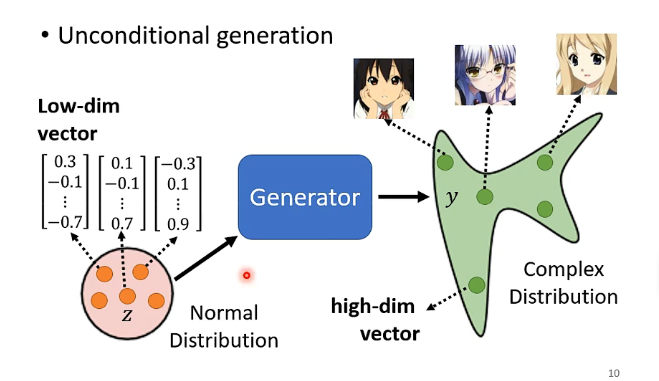
而在訓練這個生成器之前呢,我們還需要訓練一個discriminator,也是一個網路架構,其功能就是輸入一張圖片,然後輸出結果表示這張圖片是動漫人臉的可能性有多大,例如:
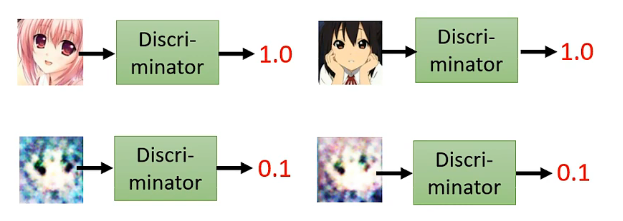
其內部具體的結構取決於你自己的設計,例如是CNN或者Transformer等都可以。
1.4、Basic Idea of GAN
在最開始GAN的訓練方式是:
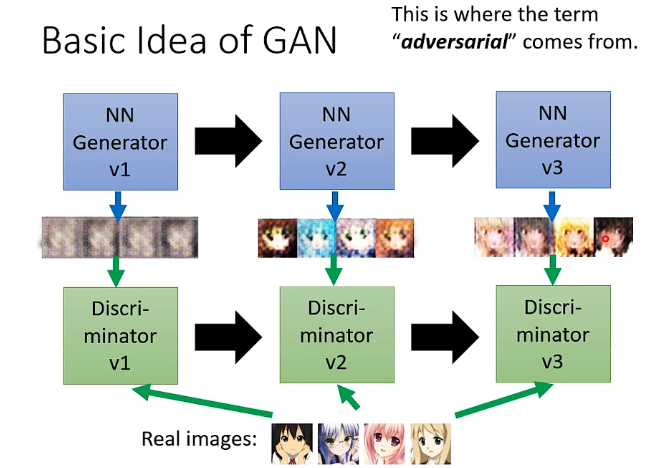
- 有一個Generator和一個Discriminator,那麼一開始生成器的引數基本都是隨機化的,那麼它所產生的影象也很難接近真實的動漫人臉,而辨別器的主要任務就是找出生成器生成的圖片與真實的動漫圖片之間的不同,例如在下面的圖片中它第一次辨認的依據是眼睛
- 那麼第二輪呢生成器就學習到應該要產生出眼睛來騙過辨別器,那麼其引數調整後就生成出有眼睛的動漫人臉,那麼辨別器就需要找出更多的特別來進行辨認,例如嘴巴、頭髮
- 第三輪呢生成器就再次調整,生成出嘴巴、頭髮等,那麼這時候辨別器就需要再次調整尋找新的特徵
- 因此生成器和辨別器就是在這個對抗的過程中不斷進步
1.5、訓練的方法
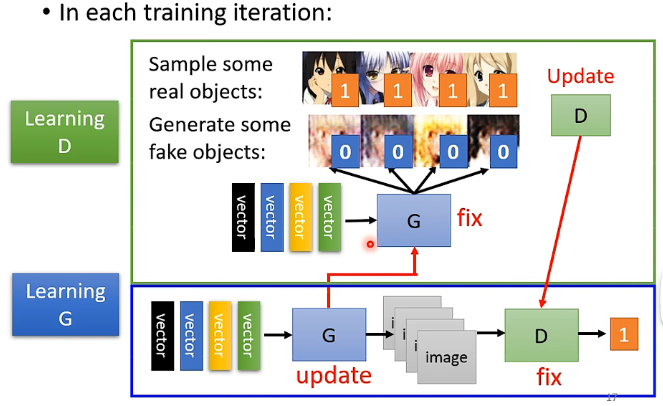
生成器和辨別器具體的訓練步驟如下所示:
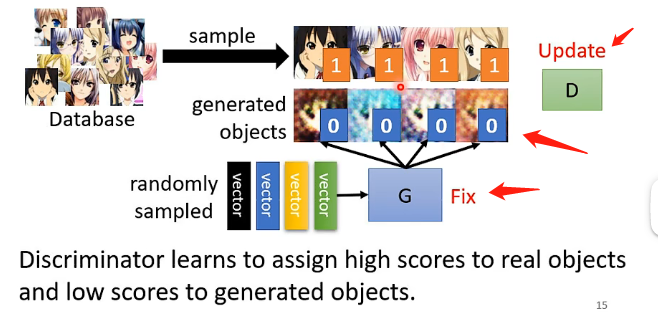
Step1:隨機初始化生成器和辨別器的引數,並固定住生成器的引數,讓生成器接受向量併產生一些影象的輸出;另外在真實動漫人臉資料庫中取樣一些樣本出來標識為1,而生成器生成的假圖示識為0,然後用這些樣本去訓練辨別器,讓它輸出一個0到1之間的數值,1代表越接近於真實的圖片。如下所示:
Step2:固定住辨別器的引數,讓生成器生成一張圖片並傳給辨別器得到一個輸出,代表該圖片為真實圖片的可能性,然後調整生成器的引數使辨別器的輸出越高越好,那麼這裡調整的方法跟普通的神經網路類似, 可以把生成器和辨別器連在一起看成一個大的網路,是接受一個向量的輸入然後輸出一個數值,那麼就同樣可以採用梯度下降等的方式來調整生成器的引數。這個步驟也可以看成是生成器在學習如何欺騙辨別器。
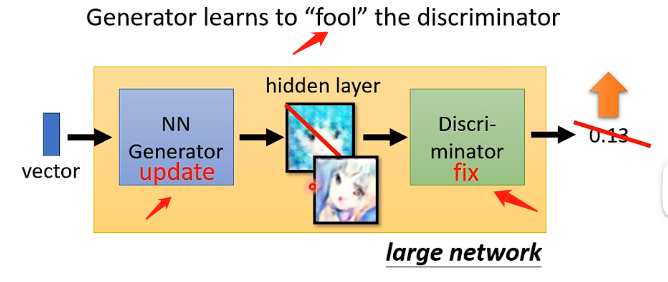
Step3:不斷重複Step1和Step2的訓練,直到生成器輸出的圖片能夠滿足要求
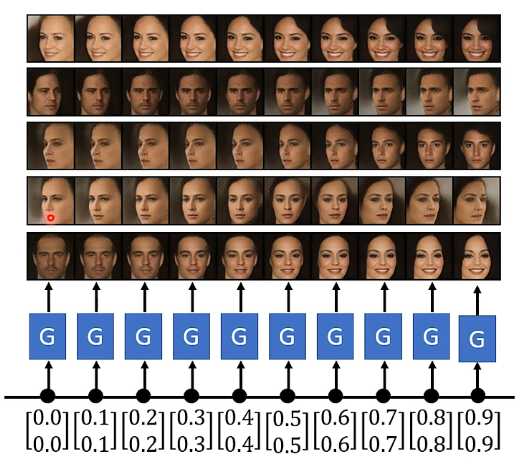
更有趣的應用,如果我們用來訓練產生真實人臉,可以實現兩張人臉之間的過度,具體我們可以看下圖,就是在兩張人臉對應的向量之間做插值,我相信這個效果也有很多小夥伴在網路上看過,我也是此刻才明白具體的原理,也就是用各式各樣的GAN來實現。
2、GAN的理論
2.1、基礎理論介紹
在GAN中,我們可以把我們的目標進行簡化,就比如下圖,我們希望能夠找到一組G的引數,它能夠對分佈z的輸入產生對應的分佈\(P_G\),而假設我們真實的分佈為\(P_{data}\),我們希望它們能夠越接近越好,即:
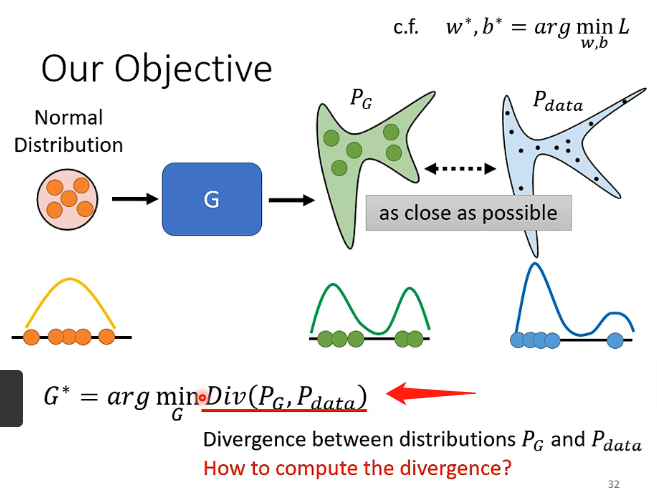
其中Div可以用來衡量兩個分佈之間的距離,例如KL散度等等。但是目前的問題是這個Div很可能寫出來是一個非常複雜的積分等等,因為我們根本不知道兩個分佈是什麼,我們根據就不知道怎麼表示出來或者說怎麼進行最小化,因此這也是GAN在訓練的時候會遇到的常見問題。而GAN告訴我們的解決方案就是:不需要知道兩個分佈的具體函數,只需要有辦法能夠從分佈中進行取樣即可,即\(P_G\)和\(P_{data}\)只需要知道怎麼取樣即可,如下圖:

具體的實現還是有辨別器來做到的。見下圖:

在訓練辨別器的時候,像我們之前說到的,使用了從真實資料中取樣的資料和生成的假的資料來分別加上標籤進行訓練,然後重點就在於損失函數的確定,從圖中可以看到損失函數的具體是式子為:
那麼實際上\(V(G,D)\)就是加了負號的交叉熵,那我們希望最大化\(V(G,D)\)就相當於最小化交叉熵,也就相當於將辨別器看成一個二分類的貝葉斯分類器來訓練。而另外一個需要注意的點是當你最大化\(V(G,D)\)的時候,解出來的這個\(V(G,D)\)的值實際上和\(JS ~divergence\)是有關的。這個觀點可以直觀地進行理解:
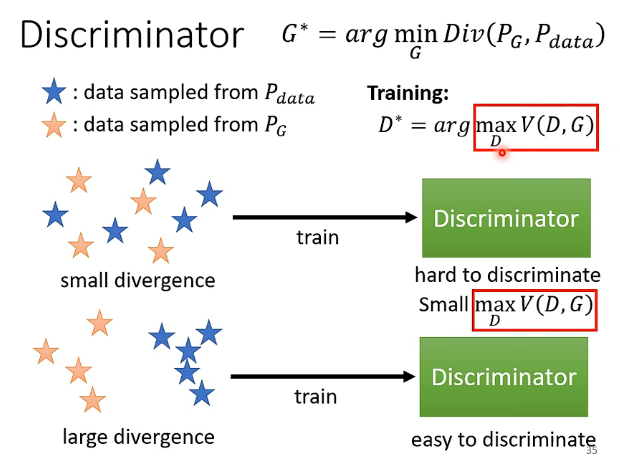
- 當兩個分佈很接近的時候,即它們之間的divergence很小的時候,辨別器很難完全地將它們分開,因此實際上它訓練引數之後得到的最大化的\(V(G,D)\)還是比較小的,那麼跟divergence比較小是對應的
- 當兩個分佈不接近,即它們之間的divergence很大的時候,辨別器就能夠輕易地將它們分開,因此實際上它訓練引數之後得到的最大化的\(V(G,D)\)就會比較大的,那麼跟divergence比較大是對應的
因此,divergence的值和\(V(G,D)\)的值之間可以認為存在一定的正比例關係,那麼我們在一開始中用到Div的目標函數就可以用\(V(G,D)\)進行替換,即:

而我們之前說到了G和D之間對抗不斷調整的過程實際上就是這個新的目標函數的求解過程。
2.2、JS divergence is not suitable
我們需要先了解一下為什麼JS divergence存在問題,之後再來了解著名的WGAN。
首先,我們要明確\(P_G\)和\(P_{data}\)它們之間相交的部分實在是太少了,具體的理由有兩個:
- 它們都是高維空間中的能夠表示為圖片(或者說我們想要的動漫人臉)的向量,但是在高維空間中滿足條件的向量只佔非常小的一部分,例如可以認為它們分別只佔二維空間中的一條直線或者曲線,那麼它們之間相交之處只能是幾個點而已(除非它們重合),那麼就可以認為它們之間相交的部分實在特別少
- 我們是對真實的兩個分佈之間進行取樣的,就算原始的真正的分佈它們之間存在重疊的部分,但如果我們取樣的不是特別多,不能夠完全地描述出兩個原來的分佈,那還是可以找到一個分界將這兩類取樣出來的點完全分開,那麼也可以認為它們是沒有相交的部分的。
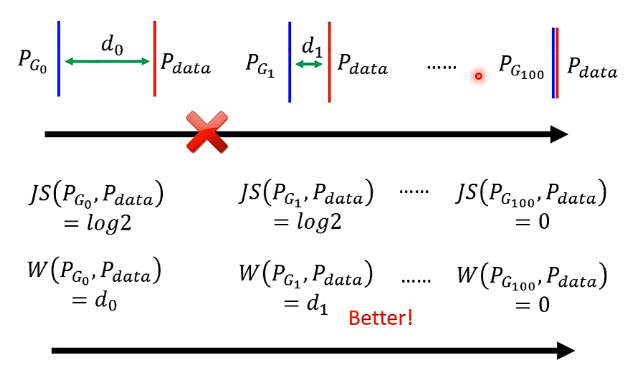
而JS divergence的特性在於如果兩個分佈沒有交疊,計算出來永遠時log2,可以看下圖:
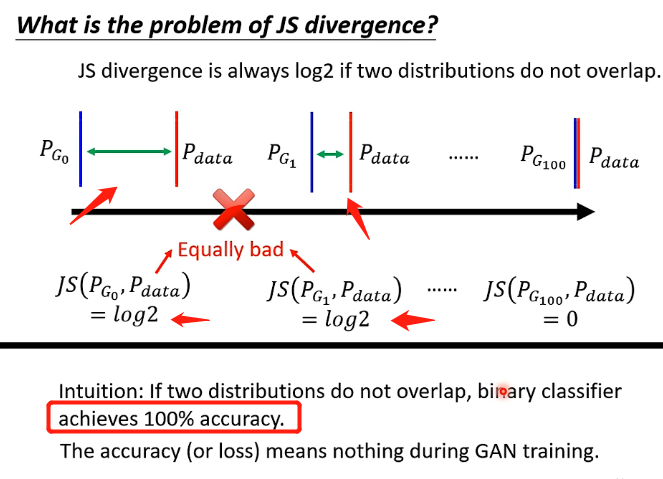
從圖中可以看到,第二個情況明明比第一個情況更加接近,但是實際上JS計算出來的值還是一直都是log2,除非它們真的出現了交疊,才會計算出新的值,這樣就導致假設我們在分佈中取樣的樣本數不是非常非常多,那我們用之前類似於貝葉斯的思想來訓練分類器的時候可以發現我們總是100%的正確率,因為根據這個JS就無法提供指導性的作用,它無法告訴機器說讓兩個分佈越來越接近可以讓損失函數越來越小,因此無法訓練成功。
2.3、Wasserstein distance
Wasserstein distance是另一種衡量兩個分佈之間的距離,可以通俗的想象成兩個分佈分別是兩堆土,如下圖:
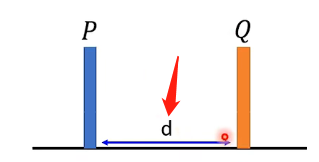
那麼兩個分佈之間的距離就是用推土機將分佈P推到分佈Q的位置時經過的距離。但實際上的分佈可能更復雜一點:
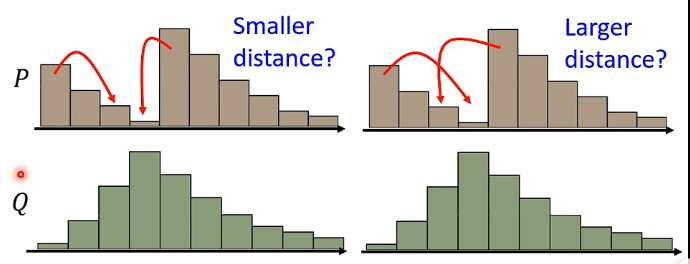
例如上圖,那麼從分佈P經過推土機的操作得到分佈Q可以有很多種方式,可以認為每一種方式的d都不一樣,那麼Wasserstein distance的定義就是窮舉所有的d,選取裡面最小的d來作為真正的Wasserstein distance。那麼也就是說我們還需要解這個Wasserstein distance的優化問題。
那麼將計算距離更換為Wasserstein distance,便可以讓我們發現在兩個分佈越來越接近的時候計算出來的距離越來越小,這樣就可以指導我們的網路往這個方向去調整。
2.4、WGAN
當用Wasserstein distance取代JS divergence的時候,此時的GAN就稱為WGAN。那麼現在的問題就在於Wasserstein distance這個距離應該怎麼距離計算呢?推導過於複雜,結論就是解下面這個函數,最終得到的值(目標函數的值)就是我們要計算的兩個分佈之前的Wasserstein distance:
這跟前面那個將目標函數Div更換成貝葉斯那個是同理的。
但是此處對於評估函數D還是有限制的,要求它是足夠平滑的,不能夠是具有劇烈變化的,否則例如下圖:
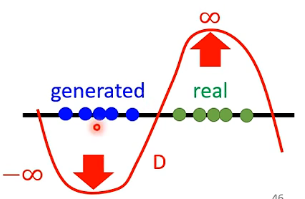
只要這兩堆沒有重疊,就會將取值推向兩個無窮的極端。
3、生成器效能評估與條件式生成
3.1、訓練的問題
雖然已經將評估分佈的距離更換成Wasserstein distance,但實際上GAN還是很難訓練的,主要原因是生成器和辨別器它們彼此之間是相互砥礪、相互進步的,只要其中有一個訓練發生了差錯,那麼另外一個肯定也無法繼續提升,即只要其中一個在某次更新過程中沒有更新,那麼可能整個訓練過程就壞掉了,無法再繼續提升下去了。
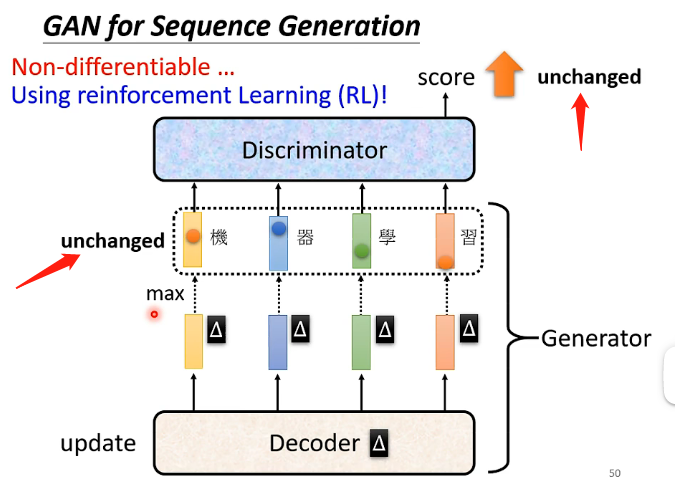
特別是在將GAN用於生成文字的時候更難訓練,例如在下圖的模型中,我們產生了一段文字然後讓辨別器檢視文字是否是機器生成的並且打分,那麼如果採用梯度下降的方法我們給生成器的引數帶來了一點微小的變動,但由於各個輸出向量都是採用取那個概率最大的文字作為輸出的方式,因此微小的變化計算能夠改變各個概率的值,但一般不會使得概率最大的文字改變,也就是輸出沒有發生改變,那麼也就沒有辦法進行微分。
另外一個需要注意的點是應該如何評估GAN這種模型所生成結果的好壞呢。
3.2、評估生成器的好壞
這個問題沒有一個標註性的答案,在GAN剛出現的時候,對於生成結果都是由人們自己來判斷效果,這樣主觀性太強而且不夠穩定。
現在對於生成影象的系統,可以再另外訓練一個影像辨識系統來進行驗證,例如生成的都是狗的圖片,那麼在這個影像辨識系統中接受輸入,並且輸出是概率分佈,那我們就希望這個概率分佈能夠有一個分類,其概率能夠越接近於1越好,就說明大部分圖片我們將其歸為一類,這樣就說明可能生成效果還是不錯的;而如果分成了很多類而且概率都差不多,那麼說明生成效果就不好了。但是在這個評估策略中可能會遇到一個問題,稱為Mode Collapse,可以通過下圖直觀理解,這種問題就是說雖然能夠產生出效果比較好的結果,但可能那些結果具有很高的相似性,例如左下方的紅色星星都集中的同一個點,很難像真實的分佈能夠較為廣闊;在右邊的例子中很可能產生的影象越來越相似,例如我指出來的那幾張基本上都一樣了,這種情況可能訓練到最後只能夠輸出這一張圖片而已。

產生這個現象的原因可以直觀理解為:例如左下方的例子中,聚集的地方可以稱為辨別器的盲點,只要產生在這附近的結果那麼辨別器就無法辨認出來是假的,因此生成器就會不斷產生這附近的圖片。
另外一個問題是Mode Dropping,它比上一個問題更難偵測到,先來直觀說明問題的內容,看下圖:

就是雖然產生的資料能夠不集中於某一處,分佈看起來也還行,但是隻學習到真實分佈的一部分,另外一部分完全沒有學習到,從下圖的例子中可以很明顯地看出來,雖然在兩次產生的影象集中看起來好像有分佈得很均勻,但是我們可以發現第一次只有白人,第二次只有黃種人,這就說明它沒有學習到真正的分佈,只學習到其中某一部分的分佈,黑色人種的圖片完全沒有學習到。

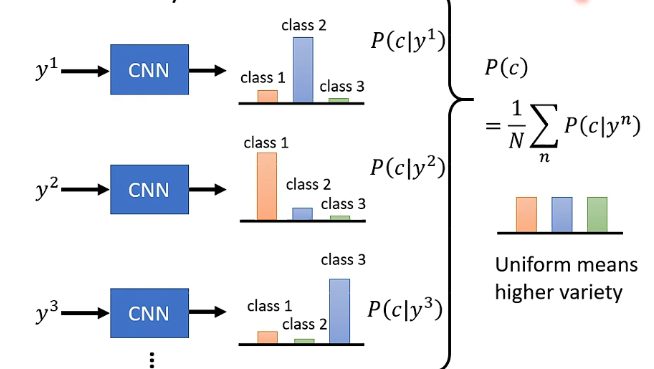
那麼評估結果多樣性的一個思路是:將產生的所有圖片都丟進去一個影象分類系統之中,那麼每張圖片就會產生對應的分佈,我們再將所有分佈求和取平均,那麼如果得到的最終分佈越平坦,就說明多樣性越好,如下圖:
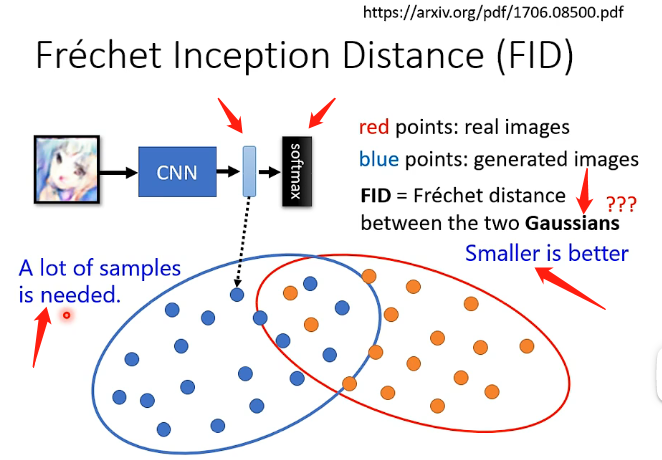
另外一種測量指標成為FID,其具體的做法為:將圖片放進去影像辨識系統之後,由於要進行分類因此肯定最後會經過一個softmax環節,我們將進入softmax之前的最後一層的的輸出的這個向量,用來代表這個圖片,那麼對於真實的圖片和生成的圖片就都可以得到很多的向量,再將這些向量來計算FID(具體的計算方法就不拓展了),那麼FID的評價標準是兩個分佈越接近其數值就越小,不過計算過程中會假設兩個都是高斯分佈。這個方法還有一個問題就是為了模擬出真實的分佈,它需要很多的樣本經過影像辨識系統得到的向量,因此計算量會很大。
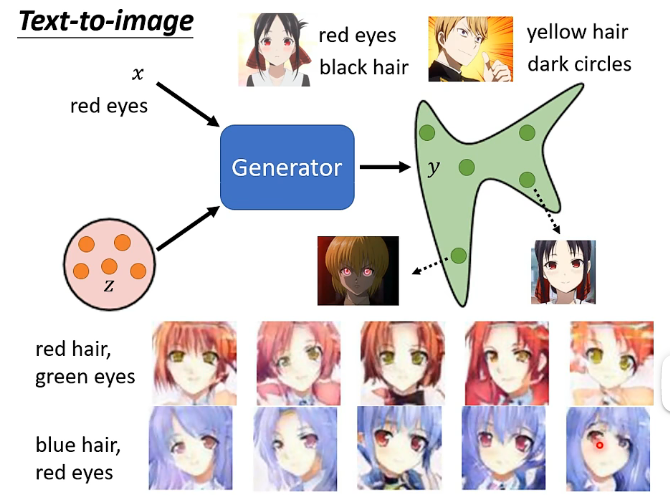
4、Conditional Generator
Conditional GAN就是輸入的時候除了之前從分佈中取樣得到的z之外,還有一個x,它可以用x來指定y的輸出,例如應用於文字轉影象的例子:
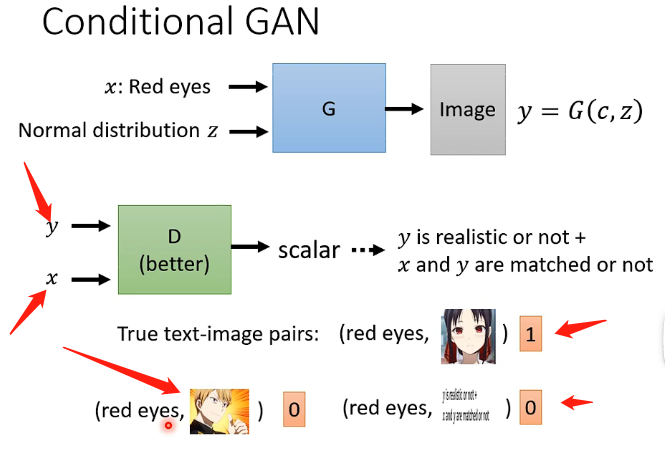
那麼這種情況下的訓練過程也要進行調整,在訓練辨別器的時候不僅僅要輸入產生的圖片,更要輸入原始輸入x,並且需要將它們進行配對,才能夠讓機器學習到看到這樣配對的文字和影象才能夠給高分,而往往在訓練辨別器時還要加入一部分特殊的訓練資料,即我們將原本資料中圖和文字已經配對好的樣本,都進行打亂,使得文字和影象並沒有關係,那麼用這種樣本告訴機器說看到這樣的樣本也要給低分,那麼機器才能夠一方面學習到影象要接近於真實動漫人臉,還學習到要滿足我們的輸入x,如下圖:
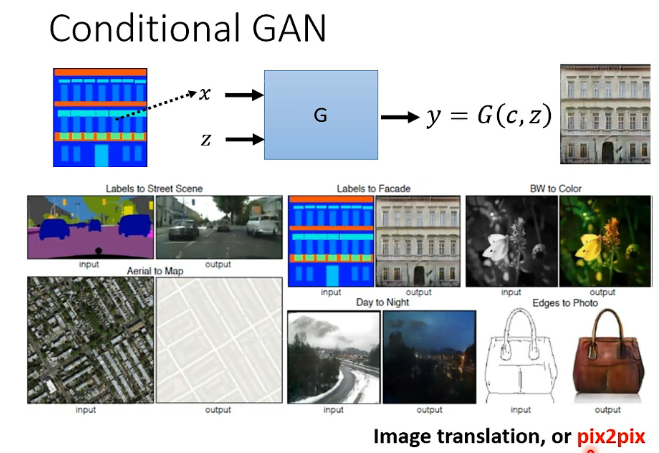
還有另外一種應用是輸入x是一張影像,然後希望能夠產生另一張圖片來滿足我們的需求,例如:
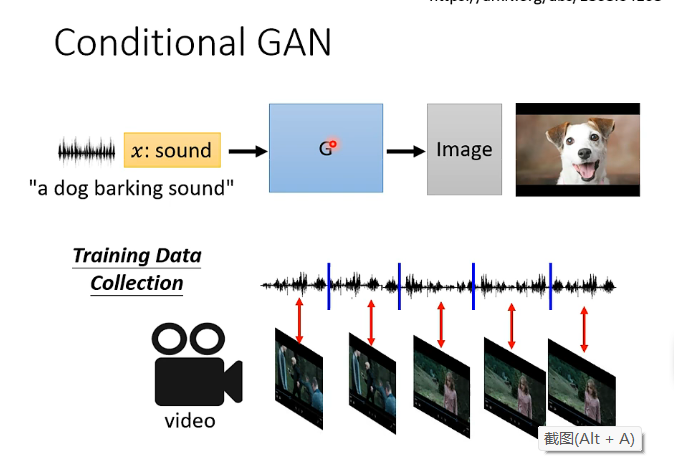
還有例如聽一段聲音然後產生一張圖片,即:
5、Cycle GAN
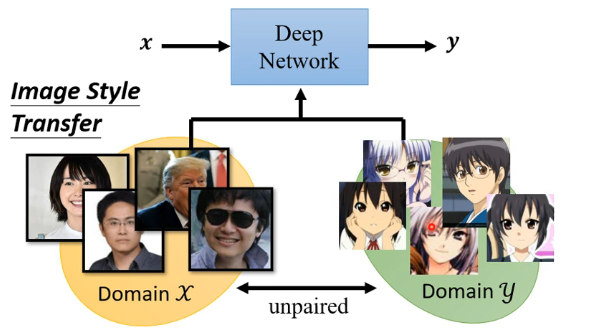
在之前的各種普通的網路結構中,一般樣本都是有對應的標註的,即x和y之前的成對的,但是在一些訓練任務中它們之間並沒有成對,例如下圖的影像風格轉換的任務中,x是真實的人臉,而y要求是人臉的動漫版本,那麼在這個任務中就不具有成對的x和y來進行訓練了:
那麼實際上,GAN在這種不成對的樣本的訓練任務中是可以發揮作用的。那麼應該怎麼應用呢?如果直接套用GAN的思想,如下圖:
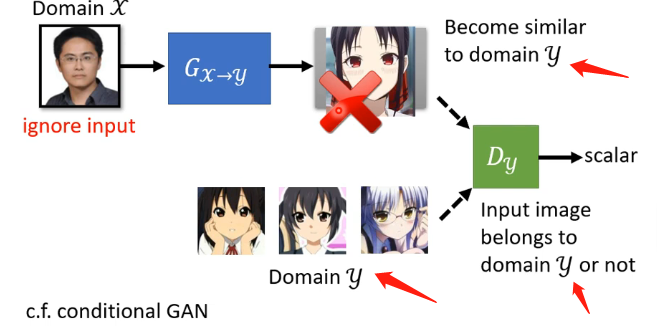
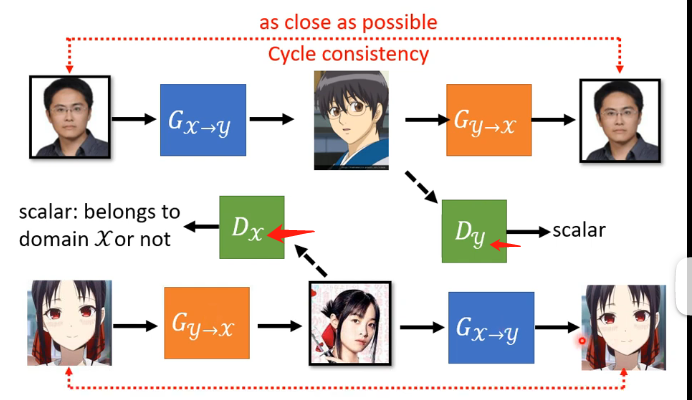
因為GAN的辨別器要求是辨別你生成器的輸出是不是y的那個分佈,那這個就會導致生成器發現只要生成一張是動漫人臉的圖片就可以讓辨別器打高分,而這個動漫人臉是否和輸入的人臉相似這並不重要,可以說生成器完全忽略了輸入,那麼怎麼解決這個問題呢?就用到了Cycle GAN,其具體的做法可以看下圖:
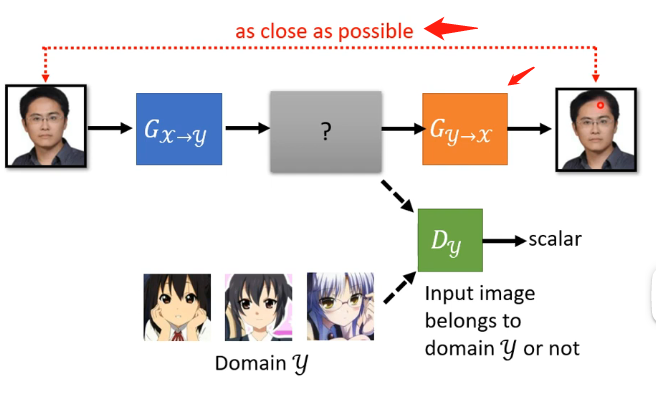
其最重要的特點在於訓練了兩個生成器,多出來的生成器用於將第一個生成器生成的動漫人臉還原成真實的人臉,而我們訓練的時候會要求原先的人臉和還原的人臉越接近越好。
但這個Cycle GAN好像並沒有限制中間產生的動漫人臉必須和原先的人臉非常地相像,例如機器可能學習到原始人臉戴著眼鏡就將眼睛去掉然後加上一顆痣,第二個生成器就學習到看到一顆痣就將痣去掉然後加上一副眼鏡,這說明在Cycle GAN是沒有對原始輸入和產生的動漫人臉的相似度進行限制,但在實際訓練中這種情況其實很少發生,可以認為網路架構不會去做這麼複雜的問題,它會盡量去輸出相似的東西而已,這也是在理論上和實際上的不同。
並且這個Cycle GAN可以是雙向的,例如下圖: