【機器學習】李宏毅——Transformer
Transformer具體就是屬於Sequence-to-Sequence的模型,而且輸出的向量的長度並不能夠確定,應用場景如語音辨識、機器翻譯,甚至是語音翻譯等等,在文字上的話例如聊天機器人、文章摘要等等,在分類問題上如果有問題是一些樣本同時屬於多個類也可以用這個的方法來求解。只要是輸入向量,輸出向量都可以用這個模型來求解。
那麼Seq2seq的大致結構如下:
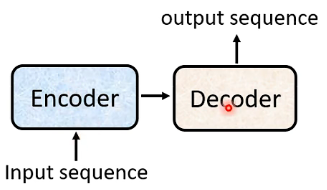
也就是有一個Encoder和一個Decoder,將輸入的向量給Encoder進行處理,處理後的結果交給Decoder,由Decoder來決定應該輸出一個什麼樣的向量。
Encoder
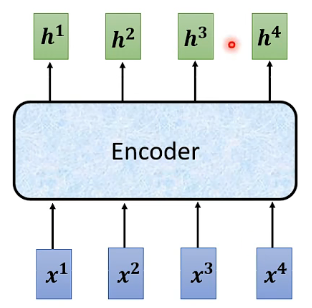
以上便是Encoder的作用,輸入一排向量,輸出也是一排向量,而這個功能呢實際上用自注意力機制、RNN等都可以實現(在Transformer中用的就是自注意力機制,可以檢視我這篇推部落格瞭解自注意力機制點此跳轉。我們將這個Encoder進行詳細解析,其內部結構可以看下圖:
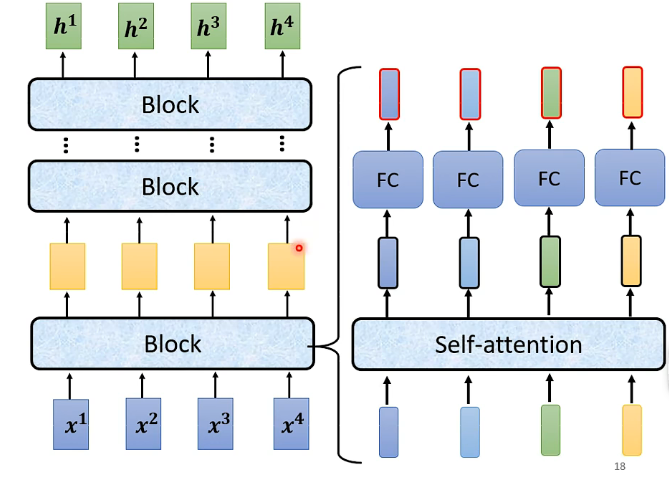
實際上一個Encoder裡面有很多個Block(一個Block不止有一層layer),而每一個Block實現的功能都是輸入一排向量然後也是輸出一排向量,而我們從圖的右邊可以看到每一個Block內部的實現,就是一排向量先經過自注意力機制後得到一排處理過的向量,那麼再逐個放於全連線的全向網路之中,最終的輸出也是一排向量。
但其實在Transformer中關於block的實現會更復雜一點:
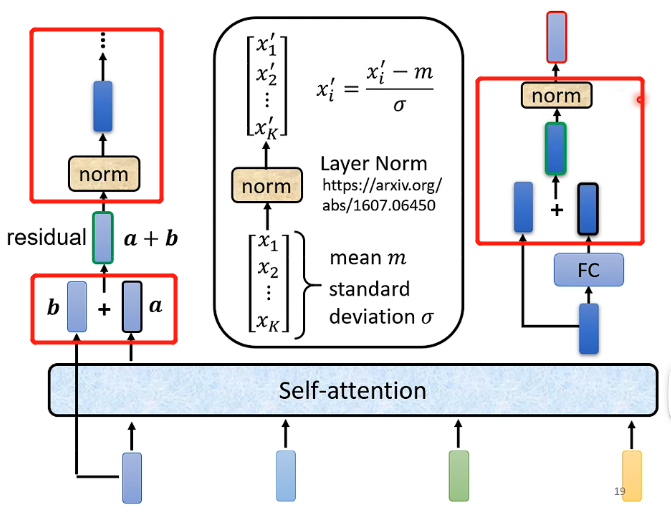
其中不同點我已經圈出來了,其具體的流程為:
- 一排向量經過Self-attention之後的輸出,需要和對應的輸出向量一一相加起來,如圖中的a需要和它對應的輸入b相加起來,這種網路架構(將輸出與輸入相加)稱為residual connection。
- 得到真正的輸出之後,需要經過一次Layer normolization,其特別的地方在於是直接對向量進行標準化(減去均值除以標準差),因為向量中的每個元素是屬於不同的維度的,屬於不同的特徵的。
- 將經過norm之後的向量作為全連線的前向網路的輸入,然後輸出需要再與輸入相加,並且再一次經過norm,才能夠真正作為這一層block的輸出。
因此,在Transformer中的Encoder就很容易理解了:
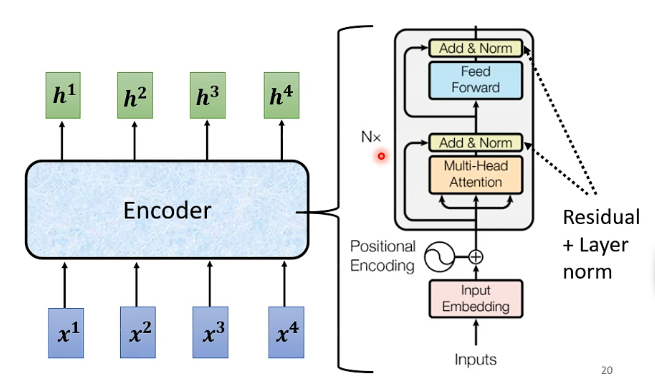
其中主要的不同就在於輸入的地方加入了一個Positional Encoding,這是因為在Transformer中需要明確各個向量之間的位置關係,但在輸入的時候有可能這個位置關係已經丟失了,那麼就通過這個模組來告訴模型這些向量彼此之間的順序關係。
Decoder
Decoder有兩種,分別是Autoregressive和Non-Autoregressive
Autoregressive
由前述可知,經過Encoder之後會得到一排輸出向量,那我們目前先假設存在某種方法能夠將這些向量作為Decoder的輸入,而要「啟動」Decoder,需要輸入一個向量特殊向量BEGIN,那麼Decoder結合Encoder的輸入,還有這個Begin的向量,就會輸出一個向量,再經過softmax之後就得到我們想要的向量,如下圖:
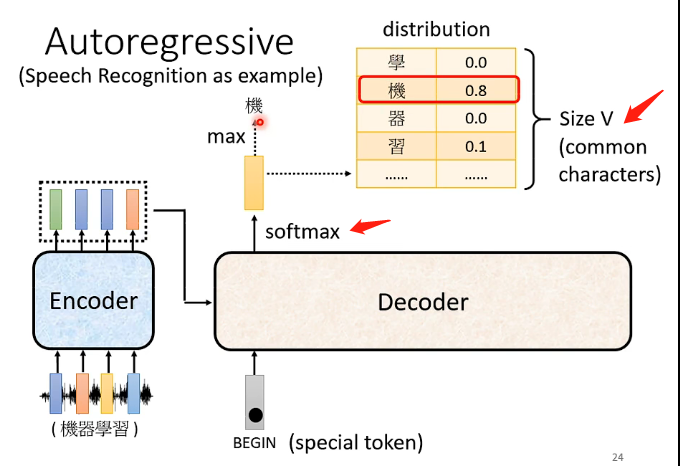
這個目標向量它的長度跟機器當前認知的詞彙長度一樣長(機器認識多少個字就有多長),然後經過softmax之後相當於得到了每個漢字的輸出概率,那取其中的概率最大值對應的文字就可以作為當前這個向量所代表的輸出了,例如這裡是機。
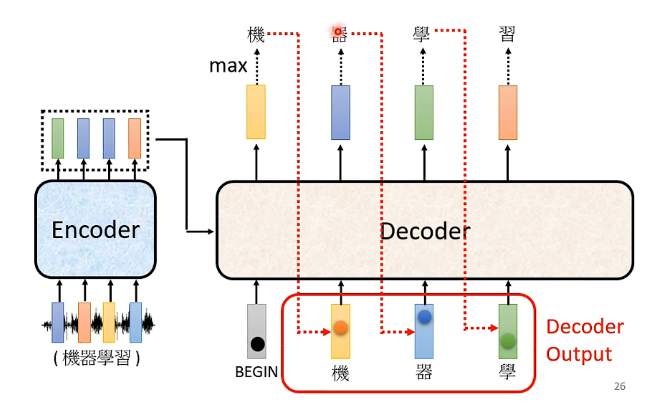
那麼接下來呢再將這個「機」的向量作為Decoder的輸入,同時它還會考慮BEGIN這個向量的輸入,以及Encoder的輸入,結合這三部分它再輸出一個經過softmax的向量,這個向量跟上一個輸出向量也是相同的性質,那我們同樣取其中概率最高的作為最終的輸出文字,如下圖中的「習」,以此類推不斷迴圈直到滿足要求:
那麼可以來看一下原始Transformer論文中Decoder的內部結構,大致如下:
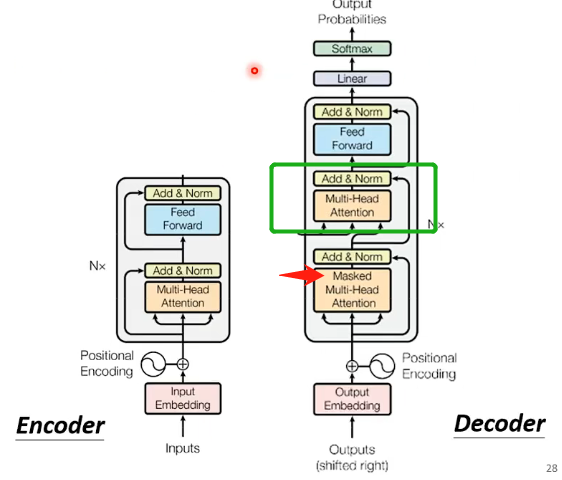
從上圖中可以看出,如果我們將綠色圈圈中的結構忽略掉的話,其實Encoder和Decoder的結構相差是不大的。但仍然需要注意我箭頭的地方,在Decoder中的自注意力機制變成了Masked版本的,那麼這個版本的特點在於:
原先的自注意力機制在考慮每一個向量的輸出時,都是綜合考慮了前後所有輸入的向量
但是在Masked中,每個向量要做輸出時只能夠考慮它之前的向量,不能夠考慮它之後的向量。
從下圖可以更直觀的理解:
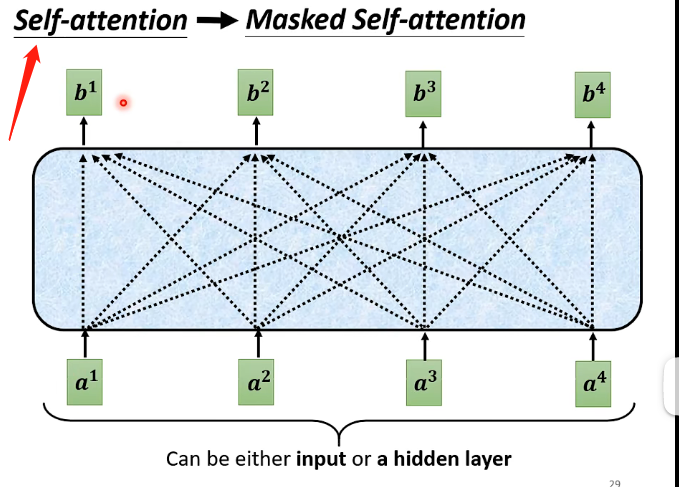
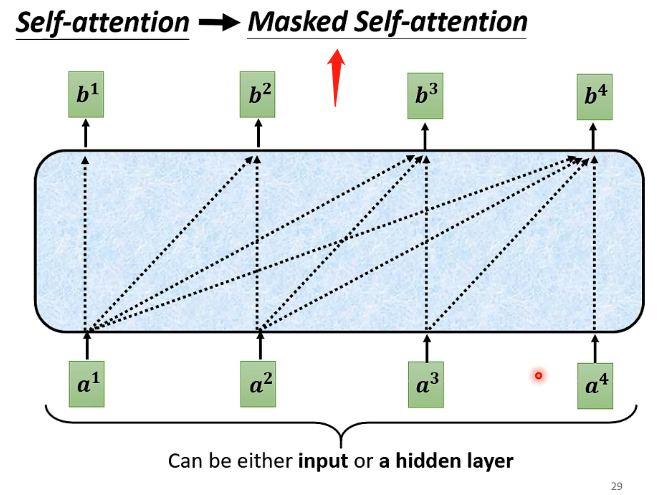
上面的第一張圖是原來的版本,第二張圖是Masked版本,那麼就可以很直觀的看出區別了。那麼需要認識到為什麼要用到Masked的版本:因為在Decoder中,我們剛才認識到其工作流程是單個向量按照順序的輸入進去的,並不是跟Encoder一樣所有向量一起進入,因此在輸入當前的向量的時候它只知道之前已經輸入的向量,它不知道未來輸入的向量,那麼它就只能夠考慮之前的向量而不能夠考慮之後的向量。
那麼下一個問題就在於如何決定Decoder輸出的長度呢,如果不加限制的話上述的例子將會不斷重複下去,不斷找到下一個概率最大的文字並且輸出,這不是我們想要的結果。
具體的做法就是在前面所述的輸出向量的長度中,除了包含漢字以外還包含兩個特殊字元,一個就是剛才提及的BEGIN,另一個就是END,那麼具體結束的方式就承接上文那個例子:
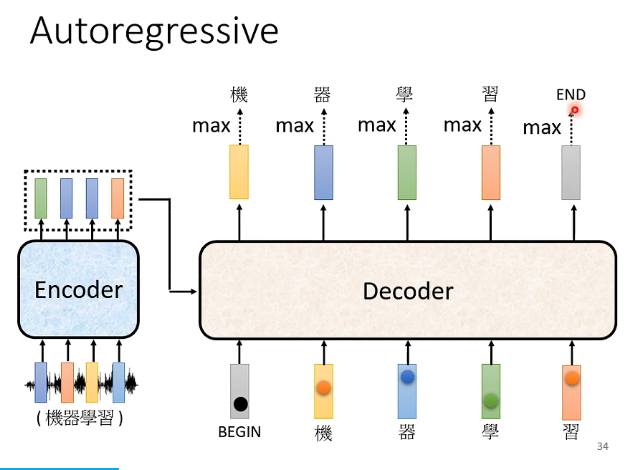
就是要讓機器學會看到Encoder的輸入加上BEGIN、機器學習這些之後,它就明白該結束了,因此它輸入「習」時輸出的向量中END的字元的概率最大,因此輸出為END,那麼就結束了這個過程。
Non-Autoregressive(NAT)
它與前面AT的不同在於,它的輸出並不是一個一個的字元產生的,它是一次性輸出所有字元,即:
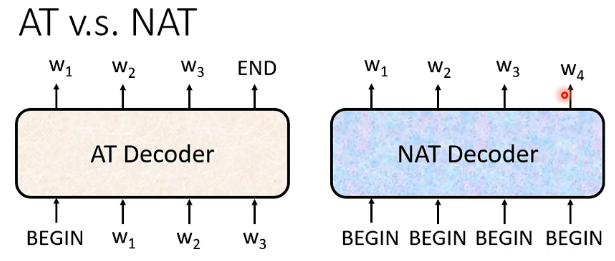
每一個輸入都是一個BEGIN,然後再根據Encoder輸出對應的字元,那麼現在的問題就在於我們如何確定這個Decoder要輸入多少個BEGIN呢?可能的做法有下面幾種:
- 增加一個分類器,這個分類器接受Encoder輸出的所有向量,然後它輸出為一個數位,這個數位就代表Decoder需要輸入幾個BEGIN
- 假設一個輸出長度的上限,然後每次給Decoder都是那個上限值數目對應的BEGIN,那麼也會輸出上限值對應的輸出個數,然後再在裡面找哪一個輸出對應字元END,這個字元后面的輸出就都不用考慮了
NAT的優點在於平行化,速度相當於AT要更快;同時如果有一個控制輸出長度的分類器,那麼我們就可以很好的控制長度。但總體來說其表現不如AT。
Encoder-Decoder
本節講解的內容是Encoder如何將其資訊傳遞到Decoder。
實際上它們之間資訊的傳遞就是用到下圖中框框中的模組,該模組稱為Cross attention,可以看到該模組接受Encoder兩個輸入,接受Decoder一個輸入:
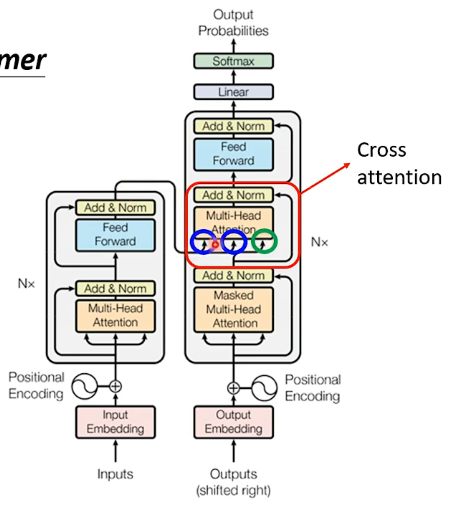
其具體的運作流程如下:
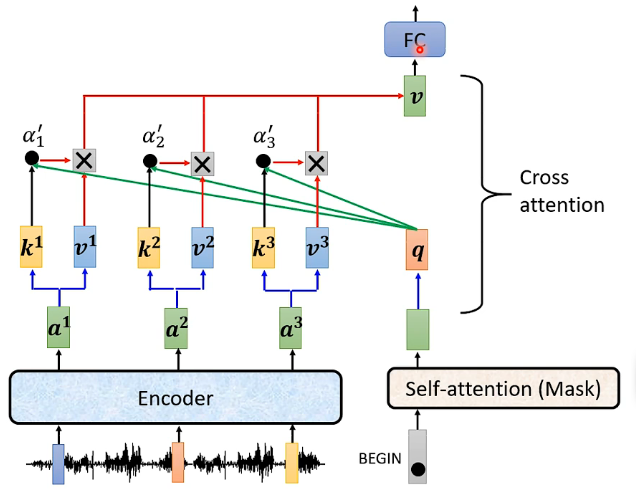
- 首先Encoder中接受了輸入之後產生了對應的輸出向量,而Decoder中最開始的自注意力機制(帶Mask)中也接受了BEGIN這個輸入,產生對應的向量,並將該向量乘以一個矩陣得到向量q
- Encoder中的輸出向量分別乘以矩陣K得到各個向量k,然後再將向量k個向量q去計算Attention的分數,這部分需要用到自注意力機制中計算分數\(\alpha\)的內容,具體可以參考我這篇博文點此跳轉,這裡我覺得是要將向量k和向量q進行點乘就得到了\(\alpha\),不確定用不用再乘以矩陣\(W^q\)和\(W^k\)。而圖片中加一個撇是表明這裡的\(\alpha\)可以去進softmax變換
- 將Encoder中的輸出向量分別乘以矩陣V得到各個向量v,然後再其與對應的\(\alpha\)相乘,並進行相加得到向量V(這裡\(\alpha\)是一個常數,因此可以看成各個向量v的加權和)
- 得到的這個向量V就是Cross attention的輸出,接下來會放入全連線的網路中進行處理
- 同樣的Decoder下一個輸入進入也是進行相同的流程
另外一個值得注意的問題是Encoder有很多層,Decoder也有很多層,而在原始的論文中Decoder中的每一層的Cross attention都是用Encoder最後一層的輸出,但是也存在眾多對此的研究,嘗試各種方式。
Train
下面需要對Transformer 如何進行訓練進行講解:
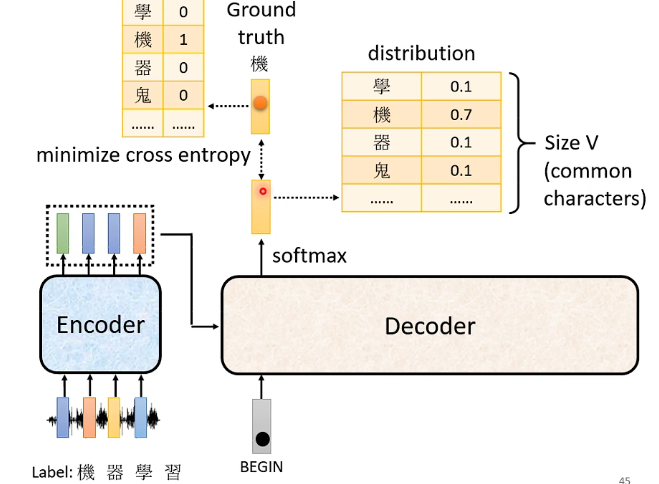
我們的輸出BEGIN後得到的輸出是一個分佈,其中代表著取到每一個漢字的概率,而我們希望它輸出的正確答案為一個One-hat-vector,那麼損失函數就是這個分佈和正確答案的向量之間的交叉熵,我們希望它們越接近越好,因此應該最小化它們之間的交叉熵。
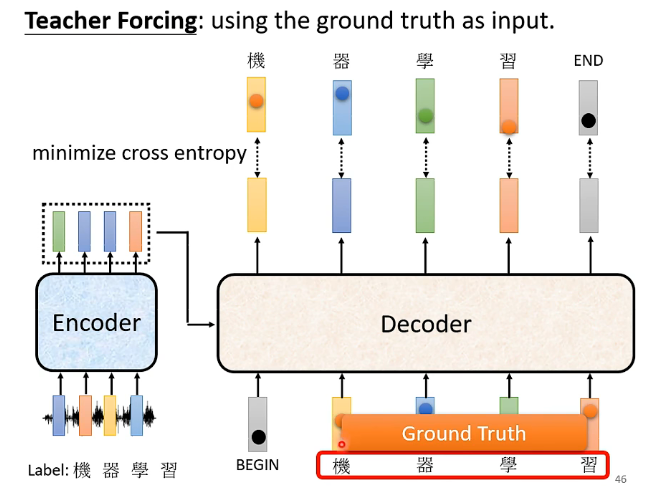
而在多個向量的時候也是同樣的道理,我們希望每一個輸出都能夠和正確答案對應的向量之間的交叉熵足夠小。但這邊需要注意的是在訓練的時候我們給Decoder看的是正確答案,例如上圖給Decoder輸入的是BEGIN、機器學習等都是正確的One-hat-vector,這種讓機器在學習的時候看到正確答案的方法稱為Teacher-Forcing,但在測試集的時候就不會給正確答案。
Tips(關於Sequence-to-Sequence模型的訓練注意事項)
Copy Mechanism
在Sequence-to-Sequence的任務中,很多時候我們並不需要機器完全從零開學會產生正確答案,在一些很複雜的詞語的時候我們可以讓機器學會複製輸入來進行輸出,例如:

對於機器來說「庫洛洛、不能使用念能力」這種詞彙是很難在訓練資料中看到並且學會的,因此在這種情況下就很難讓機器自己學會輸出這種詞語,因此我們可以訓練機器在例如看到我是某某某的時候就直接把某某某複製過來進行使用,這樣就不需要花費過多的時間精力去訓練各種複雜、奇怪的詞彙。另一種應用場景是在訓練機器讀文章寫摘要的過程中,因為摘要很多詞語都是從文章中直接摘錄出來的,因此並沒有必要讓機器從零產生這些詞語,學習複製更加重要。
Guided Attention
在做語音辨識、文字轉語音等任務中,我們無法看到Sequence-to-Sequence這個模型它內部訓練的好壞,但可能在結果會出乎意料,例如在語音辨識中經常會有一段語音機器沒有處理出結果,在文字轉語音中也會經常漏字等等,那這個時候就可以考慮是不是機器學習完成後再處理的過程中的順序不夠正確,例如下圖:
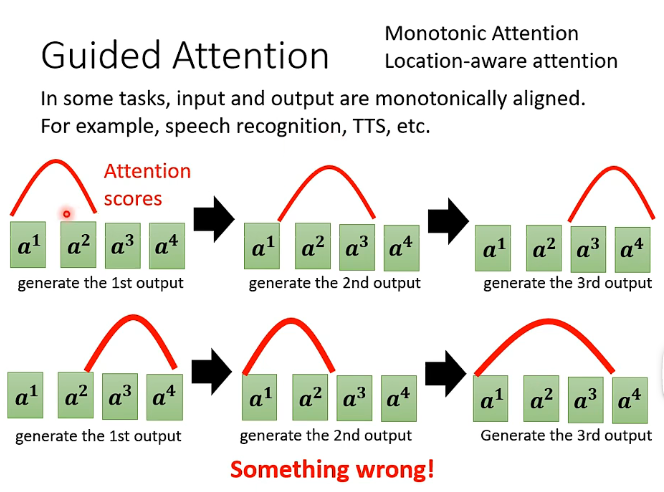
例如正確的順序是上部分,即計算Attention scores的時候應該是從左到右的順序依次計算,但在實際訓練過程中可能會出現下半部分的處理順序,那麼就說明機器學習到的處理順序並不正確,那麼處理方法就是我們可以用Guided Attention這項技術使得機器一定要學習到從左到右的這個處理順序。類似的演演算法在右上角。
Beam Search
假設當前輸出只有兩種可能性A和B,那麼在按照順序處理多個向量的時候如下圖:
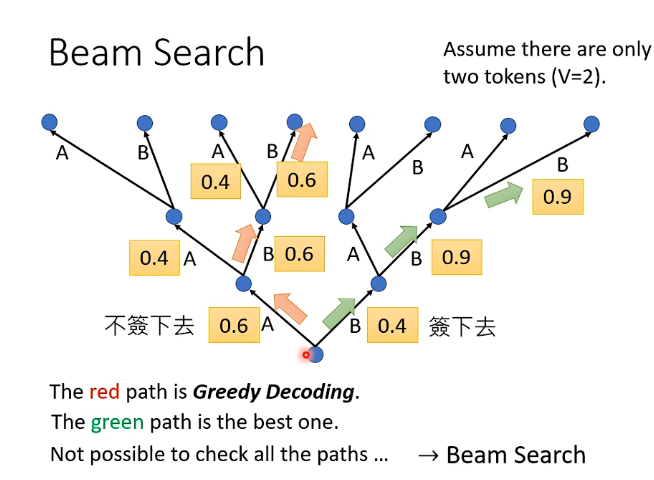
- 第一種思想就是每一次選擇的時候都考慮當前可選擇中的概率最大的那個,例如從最下面的點開始選擇ABB,每一步都是概率最大的點,這種稱為貪心思想。但是這種思想並不一定最終結果是最優的
- 另一種思想是:如果第一次選擇了概率較小的B,而發現後面的概率突然就很大了,那麼最終結果是BBB,這樣最終的概率為\(0.4\times 0.9\times 0.9 >0.6\times 0.6\times 0.6\),即最終的結果是更好的,即可能在某次選擇的時候選擇較差的概率,後面可能會得到更好的結果。
那麼我們應該如何確定什麼時候應該選擇概率最大而什麼時候應該選擇概率小的呢?一種可能的解決方案為Beam Search,它會提供一個可能不是那麼精確的解決方案來解決這個問題,但是有的時候有用,有的時候就沒用。例如在語音轉文字的時候因為它的答案只有一個,因此如果我們能夠找到概率最大的那個輸出可能其結果會更好一些。但是如果在文章續寫這種具有多個答案,需要隨機性的任務中使用Beam Search演演算法就很難得到好的結果。
優化評估策略
在訓練的時候我們用的是對每一個輸出向量進行交叉熵的形式來作為損失函數,但是在測試的時候並不是這樣,在測試的時候是用輸出的整個句子和正確的句子來計算BLEU score(評論文字的一個指標)來作為評價的好壞,如下圖:
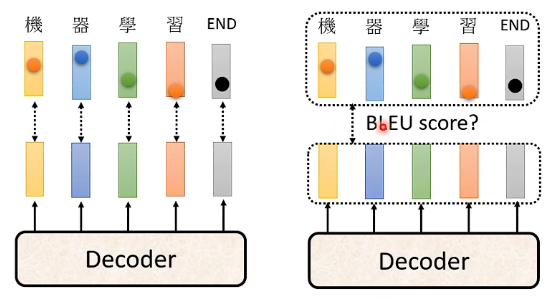
但我們在訓練的時候用的是最小化交叉熵的策略,其實這並不能夠保證就能夠最大化BLEU score,因此在驗證集的時候通常不是繼續考慮最小化交叉熵的那個模型,而是考慮能最大化BLEU score的那個模型。
而如果在訓練的時候就用這個BLEU score來作為損失函數的話是行不通的,因為這樣的損失函數是不可微分的。
exposure bias
前面我們已經提到了,在訓練的時候Decoder每次的輸入都是正確的東西,但是在測試的時候Decoder看到的是自己的輸出,這並不能夠保證一定正確,如果發生錯誤的話就可能會導致接下來都發生錯誤。那麼具體的辦法就是在訓練的時候不要讓Decoder看到的全都是正確的東西,可以偶爾讓它看到錯誤的東西,如下圖:
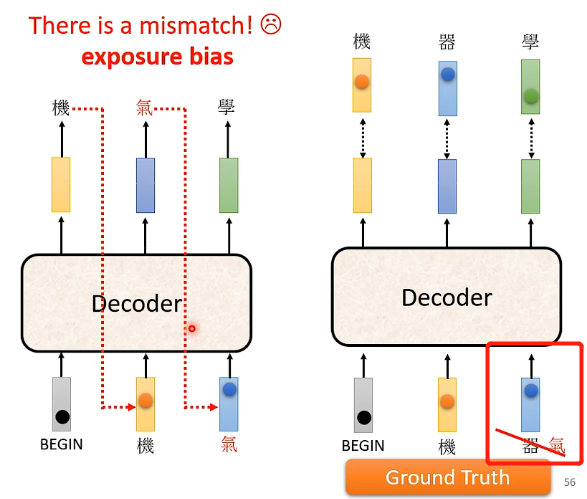
這個思想具體稱為Scheduled Sampling。