Pytorch框架詳解之一
Pytorch基礎操作
numpy基礎操作
- 定義陣列(一維與多維)
- 尋找最大值
- 維度上升與維度下降
- 陣列計算
- 矩陣reshape
- 矩陣維度轉換
程式碼實現
import numpy as np
a = np.array([1, 2, 3, 4, 5, 6]) # array陣列
b = np.array([8, 7, 6, 5, 4, 3])
print(a.shape, b.shape) # shape為陣列的格式
aa = np.reshape(a, (2, 3)) # reshape為格式轉換,格式轉換為2行3列的二維陣列
print(aa, aa.shape)
bb = np.reshape(b, (1, 1, 1, 6)) # 轉換為 1*1*1*6 格式的陣列
print(bb, bb.shape)
a1 = np.squeeze(aa) # squeeze方法會將只有 1 的維度去掉,只保留大於 1 的維度
b1 = np.squeeze(bb)
print(a1, a1.shape)
print(b1, b1.shape)
a2 = np.transpose(aa, (1, 0)) # transpose陣列轉置,原行列式形式為(0,1),後面的引數(1,0)表示將行列交換位置變為(1,0)格式
print(a2, a2.shape)
b_index = np.argmax(b) # argmax函數表示獲取該陣列中的最大值索引
bb_index = np.argmax(bb)
aa_index = np.argmax(aa[0]) # argmax函數可以獲取多維陣列中任意維度中最大值的索引,沒有輸入維度時會將多維陣列轉換為一維獲取索引
print(b_index, b[b_index])
print(bb_index, bb[0][0][0][bb_index])
print(aa_index)
a3 = np.reshape(aa, -1) # 引數-1表示恢復成一維陣列
print(a3, a3.shape)
# zeros函數以0填充生成指定行列大小的陣列,陣列數值型別預設為float64,可手動設定int8,uint8(無符號二進位制整型),float16,float32,float64等
m1 = np.zeros((6, 6), dtype=np.uint8)
m2 = np.linspace(6, 10, 100) # linspace函數,以均勻步長生成數位序列,linspace(start,end,nums)
print(m1)
print(m2)
OpenCV-Python基礎操作
- 讀寫影象與灰度轉換
- 讀取視訊與顯示
- 歸一化與顯示
- 建立空白影象
- 提取ROI與分離、合併通道
程式碼實現
import cv2 as cv
import numpy as np
src = cv.imread("D:/images/lena.jpg")
h, w, c = src.shape # 獲取到影象的型別為HWC
print(h, w, c)
src1 = np.transpose(src, (2, 0, 1)) # 將輸入影象的通道型別進行轉置
print(src1.shape)
float_src = np.float32(src) / 255.0 # 將影象變成0-1的浮點數型別
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
rgb = cv.cvtColor(src, cv.COLOR_BGR2RGB) # opencv讀取的影象預設為BGR三通道,轉換為RGB三通道影象
dst = cv.resize(src, (224, 224))
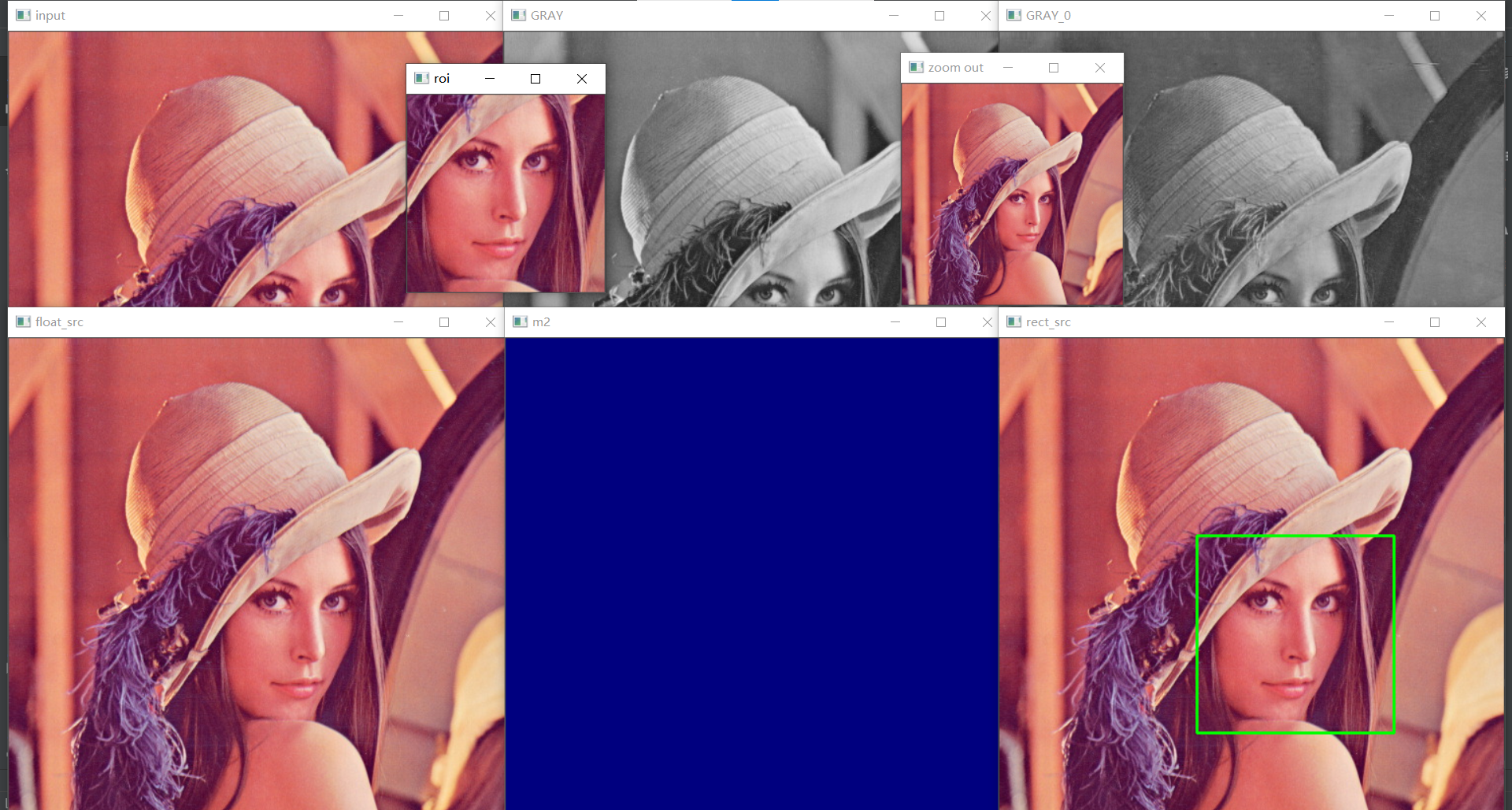
cv.imshow("input", src)
cv.imshow("float_src", float_src)
cv.imshow("GRAY", gray)
cv.imshow("GRAY_0", src[:, :, 0]) # 進入影象第一個通道,前面兩個:表示尺寸512
# cv.imshow("GRAY_1", src[:, :, 1]) # 進入影象第一個通道
# cv.imshow("GRAY_2", src[:, :, 2]) # 進入影象第一個通道
# cv.imshow("GRAY_3", src[:, :, :]) # 獲取影象三個通道
cv.imshow("zoom out", dst) # zoom in放大,zoom out縮小
box = [50, 50, 100, 100] # x, y, w, h
roi = src[200:400, 200:400, :] # 擷取目標區域 src[y1:y2, x1:x2, :] 灰度圖則不需要最後的通道數:
cv.imshow("roi", roi)
m1 = np.zeros((512, 512), dtype=np.uint8) # 建立空白單通道灰度影象
m2 = np.zeros((512, 512, 3), dtype=np.uint8) # 建立空白三通道彩色影象
m2[:, :, :] = (127, 0, 0) # 對影象的三通道進行賦值
cv.imshow("m1", m1)
cv.imshow("m2", m2)
cv.rectangle(src, (200, 200), (400, 400), (0, 255, 0), 2, 8) # 對選定的左上角座標與右下角座標之間繪製矩形
cv.imshow("rect_src", src)
cap = cv.VideoCapture("D:/images/video/face_detect.mp4")
while True:
ret, frame = cap.read()
if ret is not True: # ret為布林型別,表示是否獲取到下一幀影象
break
cv.imshow("video", frame)
c = cv.waitKey(50) # waitKey方法是等待一定的時間獲取鍵盤輸入,引數為等待的毫秒數,預設可設為1
# c = cv.waitKey(1)
if c == 27: # 如果按下ESC則退出迴圈
break
cv.waitKey(0)
cv.destroyWindow()
效果:
Pytorch基礎操作
- 定義常數與變數
- Tensor與numpy轉換
- 資料reshape與最大值索引
- 亂資料生成
- 基本算術操作
- 基本折積操作
- GPU檢測與支援
- 網格化與cat
程式碼實現
import torch
import numpy
x = torch.empty(2, 2)
x1 = torch.zeros(2, 2)
x2 = torch.randn(2, 2) # 隨機生成指定大小的tensor
print(x)
print(x1)
print(x2)
y = torch.tensor([1, 2, 3, 4, 5, 6, 7, 8, 9, 0])
z = torch.tensor([11, 12, 13, 14, 15, 16, 17, 18, 19, 20])
print(y)
print(z)
res01 = torch.add(y, z)
res02 = y.add(z)
print(res01)
print(res02)
# x = x.view(-1, 4) # -1為自動補充,4表示轉置為4列的tensor,最終轉置成1行4列的tensor
x = torch.view_copy(x, (4, -1)) # 將x轉置為4行1列
print(x)
print(x.size()) # 獲取x的維度資訊
nx = x.numpy() # tensor轉換為numpy陣列
print(nx)
tensor_x = torch.from_numpy(nx.reshape((2, 2))) # numpy陣列轉換為tensor
print(tensor_x)
if torch.cuda.is_available(): # 使用GPU對tensor進行運算
print("GPU Detected")
result = x.cuda() + y.cuda()
print(result)
else:
print("GPU is not available")
訓練過程中關於LOSS的一些說明
- train loss 不斷下降,test loss 不斷下降,說明網路正在學習
- train loss 不斷下降,test loss 趨於不變,說明網路過擬合
- train loss 趨於不變,test loss 趨於不變,說明學習遇到瓶頸,需要減小學習率或者批次處理大小
- train loss 趨於不變,test loss 不斷下降,說明資料集100%有問題
- train loss 不斷上升,test loss 不斷上升(最終變為NaN),可能是網路結構設計不當,訓練超引數設定不當,程式bug等某個問題引起
自動梯度與迴歸
自動梯度
函數式的程式設計方式
- 所見即所得,定義類、方法、函數、引數
- 先檢查語法錯誤
- 再編譯與連結
- 生成可執行檔案
- 支援各種引數輸入與輸出,介面的互動操作
圖的程式設計方式(深度學習)
-
構建計算圖
-
早期 - 先定義再執行,現在 JIT(just in time即時編譯) 方式
-
靜態圖 VS 動態圖
-
輸入的資料 - 張量
-
圖中的每個節點 - OP
-
構建完成後即可執行
-
深度學習中的資料結構:tensor張量
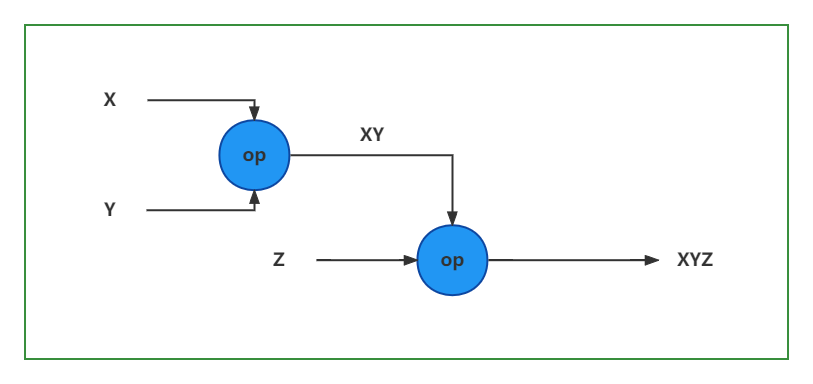
計算圖構建與執行
- 計算圖的構建 - 定義資料()與OP操作,通過鏈式求導法則
x, y, z輸入被稱為張量,整個計算過程定義被稱為圖的構建
自動梯度求導:
程式碼實現
import torch
x = torch.randn(1, 5, requires_grad=True) # randn()函數生成目標尺度的tensor,值隨機
y = torch.randn(5, 3, requires_grad=True)
z = torch.randn(3, 1, requires_grad=True)
print("x:\n", x, "\ny\n", y, "\nz\n", z)
xy = torch.matmul(x, y) # matmul()函數對兩個輸入的tensor張量矩陣計算乘積
print("xy\n", xy)
xyz = torch.matmul(xy, z)
xyz.backward() # backward()函數,自動計算xyz之前的梯度
print(x.grad, y.grad, z.grad) # grad方法獲取該tensor的梯度
zy = torch.matmul(y, z).view(-1, 5) # view()函數將矩陣轉置為目標形式
print(zy)
線性迴歸
- 根據輸入的資料擬合直線
X : 1, 2, 0.5, 2.5, 2.6, 3.1
Y : 3.7, 4.6, 1.65, 5.68, 5.98, 6.95
Y = kX + b
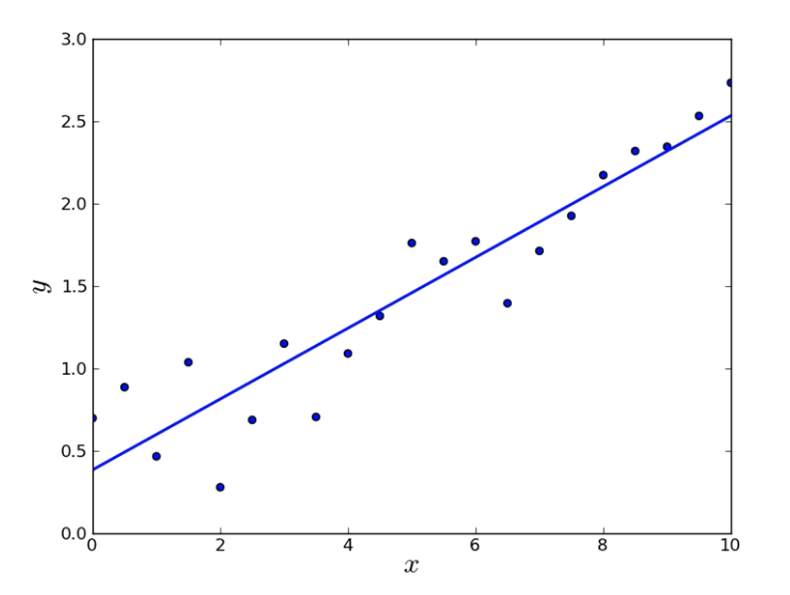
線性迴歸模型與擬合計算
- 構建模型
- 計算損失
- 更新引數(訓練)
資料 + 模型 + 損失 + 優化
隨機梯度下降法:
大多數機器學習或者深度學習演演算法都涉及某種形式的優化。 優化指的是改變 特徵x以最小化或最大化某個函數 f(x) 的任務。 我們通常以最小化 f(x) 指代大多數最佳化問題。 最大化可經由最小化演演算法最小化 -f(x) 來實現。我們把要最小化或最大化的函數稱為目標函數或準則。 當我們對其進行最小化時,我們也把它稱為損失函數或誤差函數。
下面,我們假設一個損失函數為:
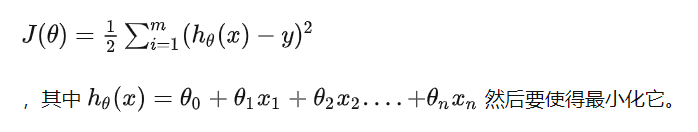
梯度下降:梯度的方向是函數在給定點上升最快的方向,那麼梯度的反方向就是函數在給定點下降最快的方向,因此我們在做梯度下降的時候,應該是沿著梯度的反方向進行權重的更新,可以有效的找到全域性的最優解。
隨機梯度下降法(stochastic gradient descent,SGD)演演算法是從樣本中隨機抽出一個,訓練後按梯度更新一次,然後再抽取一個,再更新一次,在樣本量及其大的情況下,可能不用訓練完所有的樣本就可以獲得一個損失值在可接受範圍之內的模型了。(重點:每次迭代使用一組樣本。)為什麼叫隨機梯度下降演演算法呢?這裡的隨機是指每次迭代過程中,樣本都要被隨機打亂,這個也很容易理解,打亂是有效減小樣本之間造成的引數更新抵消問題。
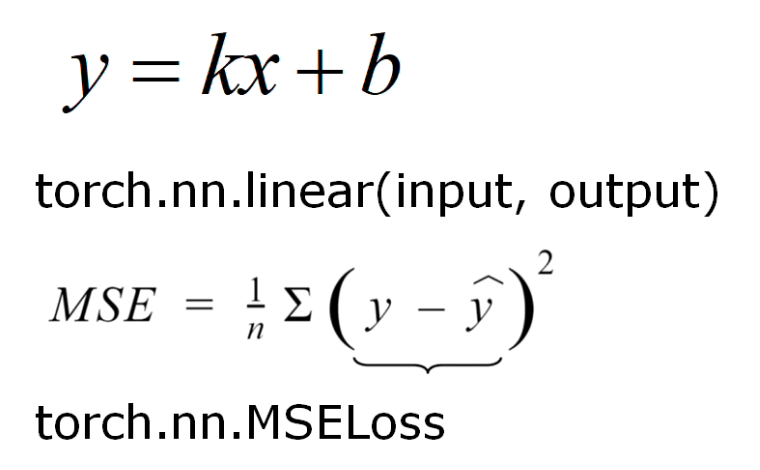
更新引數:
params = params - learning_rate * param_gradient
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr = learning+rate)
程式碼實現
- 使用torch.nn.Module構建模型
- 前向計算損失
- 反向梯度優化與訓練
- 使用訓練好的模型完成預測
import torch
import numpy as np
import matplotlib.pyplot as plt
x = np.array([1, 2, 0.5, 2.5, 2.6, 3.1], dtype=np.float32).reshape(-1, 1)
y = np.array([3.7, 4.6, 1.65, 5.68, 5.98, 6.95], dtype=np.float32).reshape(-1, 1)
class LinearRegressionModel(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim) # 根據輸入輸出資料維度初始化一個線性迴歸模型
def forward(self, x):
out = self.linear(x) # 根據輸入資料計算當前線性迴歸模型的輸出值
return out
input_dim = 1
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)
criterion = torch.nn.MSELoss() # 使用MSE(Mean Squared Error 均方誤差)方法計算模型輸出值與實際結果之間的差異
learning_rate = 0.01
# 使用SGD(stochastic gradient descent 隨機梯度下降法)按輸入的學習率優化模型引數
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(100):
epoch += 1
# 將numpy陣列轉換為torch型別tensor
inputs = torch.from_numpy(x).requires_grad_()
labels = torch.from_numpy(y)
# 將優化器中的梯度清空
optimizer.zero_grad()
# 執行推理,獲取模型輸出
outputs = model(inputs)
# 計算模型輸出結果與實際結果的差異
loss = criterion(outputs, labels)
# 自動計算梯度
loss.backward()
# 更新引數
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))
# 將x陣列轉換為tensor放入迭代訓練好的模型獲取計算結果,並轉換為numpy陣列
predicted_y = model(torch.from_numpy(x).requires_grad_()).data.numpy()
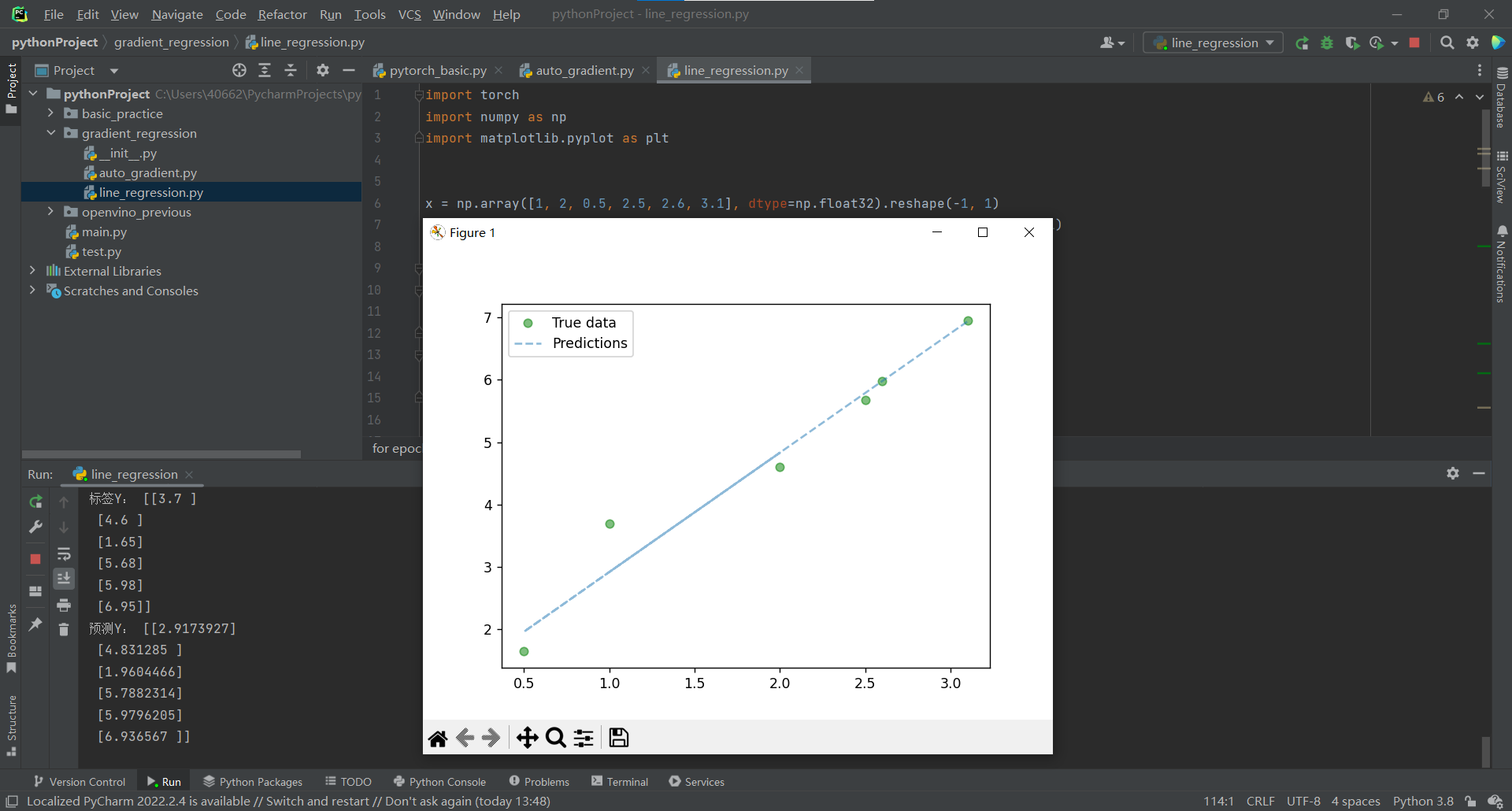
print("標籤Y:", y)
print("預測Y:", predicted_y)
plt.clf()
# 繪製實際x與y對應的點與模型預測直線
plt.plot(x, y, 'go', label='True data', alpha=0.5)
plt.plot(x, predicted_y, '--', label='Predictions', alpha=0.5)
plt.legend(loc='best')
plt.show()
效果:
邏輯迴歸
- 線上性組合的基礎上加上非線性變換
- 構建模型
- 計算損失
- 更新引數(訓練)
資料 + 模型 + 損失(二分類交叉熵損失函數BCE(Binary Cross Entropy)詳細內容可檢視部落格:一文搞懂熵(Entropy),交叉熵(Cross-Entropy)) + 優化

程式碼實現
- 使用torch.nn.Module構建模型
- 前向計算損失
- 反向梯度優化與訓練
- 使用訓練好的模型完成預測
import numpy as np
import torch
import matplotlib.pyplot as plt
x = np.linspace(-5, 5, 20, dtype=np.float32)
_b = 1/(1 + np.exp(-x))
y = np.random.normal(_b, 0.005) # 新增隨機值來初始化邏輯迴歸的輸入及目標值
x = np.float32(x.reshape(-1, 1))
y = np.float32(y.reshape(-1, 1))
class LogicRegressionModel(torch.nn.Module):
def __init__(self, input_dim, output_dim):
super(LogicRegressionModel, self).__init__()
self.linear = torch.nn.Linear(input_dim, output_dim)
def forward(self, x):
out = torch.sigmoid(self.linear(x))
return out
input_dim = 1
output_dim = 1
model = LogicRegressionModel(input_dim, output_dim) # 初始化邏輯迴歸模型
criterion = torch.nn.BCELoss() # 計算交叉熵損失函數
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 優化器優化模型引數
for epoch in range(1000):
epoch += 1
inputs = torch.from_numpy(x).requires_grad_()
labels = torch.from_numpy(y)
optimizer.zero_grad()
outputs = model(inputs) # 將獲取模型輸出值
loss = criterion(outputs, labels) # 計算loss
loss.backward() # 計算梯度
optimizer.step() # 優化模型引數
print('epoch {}, loss {}'.format(epoch, loss.item()))
predicted_y = model(torch.from_numpy(x).requires_grad_()).data.numpy()
print("標籤Y:", y)
print("預測Y:", predicted_y)
# 清除當前figure 的所有axes(容器),但是不關閉這個window,所以能繼續複用於其他的plot
plt.clf()
plt.plot(x, predicted_y, '--', label='Predictions', alpha=0.5)
plt.plot(x, y, 'go', label='True data', alpha=0.5)
plt.legend(loc='best') # 圖例自動放在座標平面圖示最少的位置
plt.show()
效果:
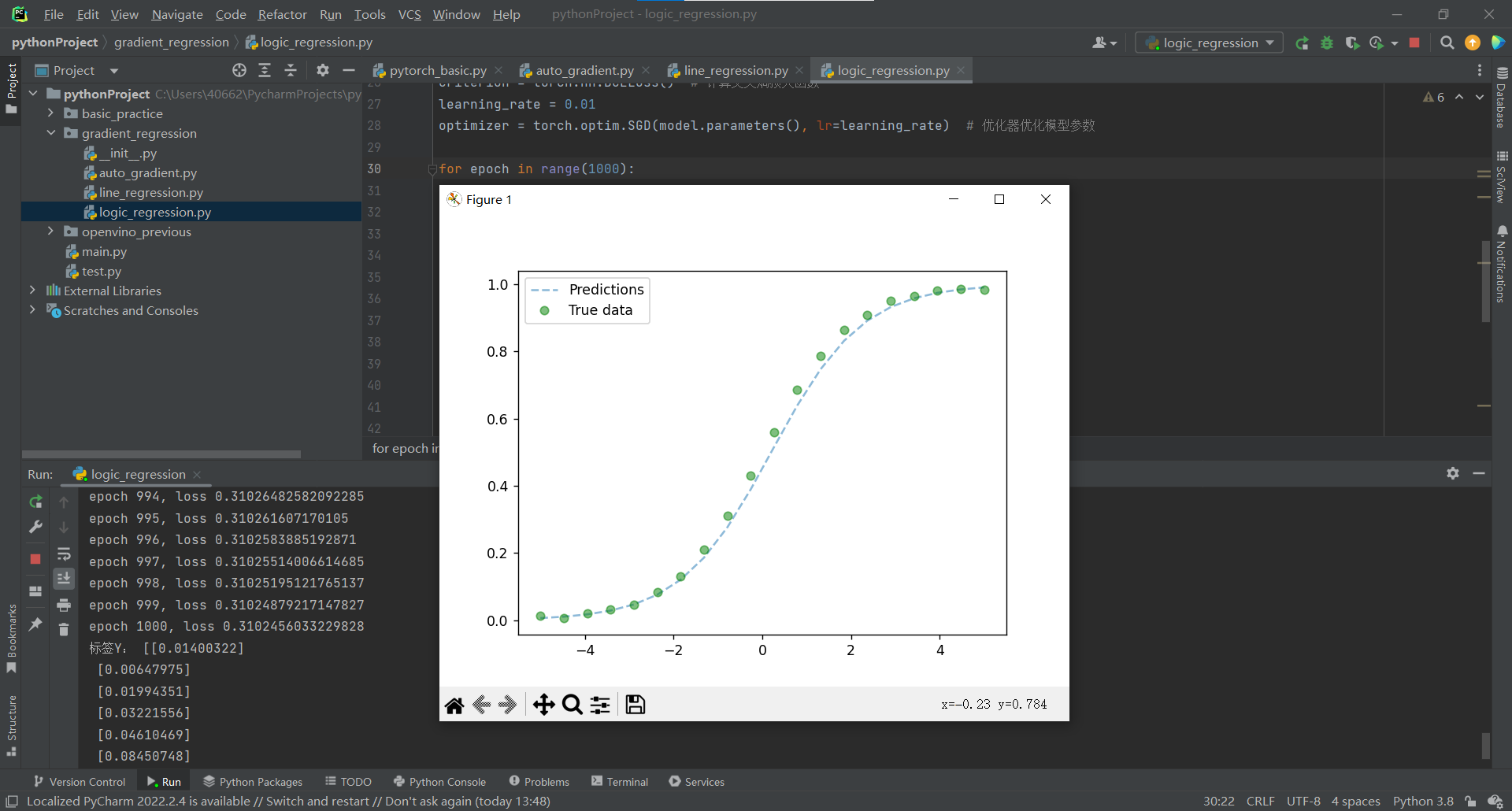
人工神經網路
人工神經網路基本概念
- 人工神經網路發展歷史
- 多層感知機
- 前向網路與反向網路
- 反向傳播演演算法
感知機(線性組合+非線性變換)
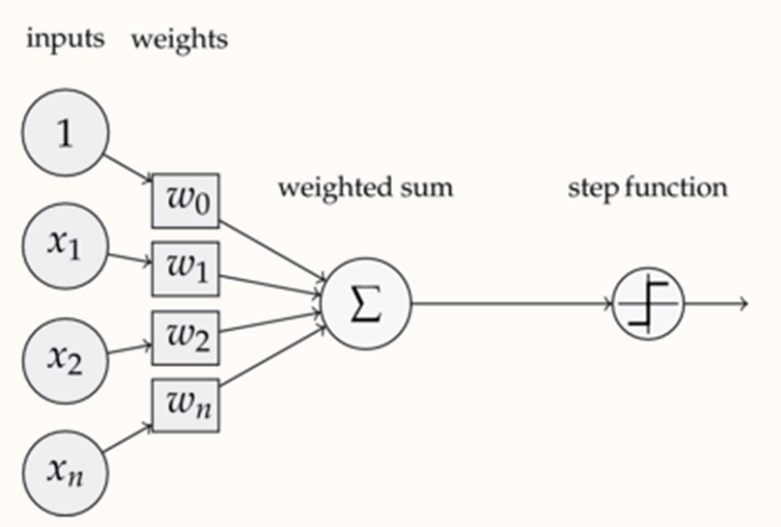
啟用函數
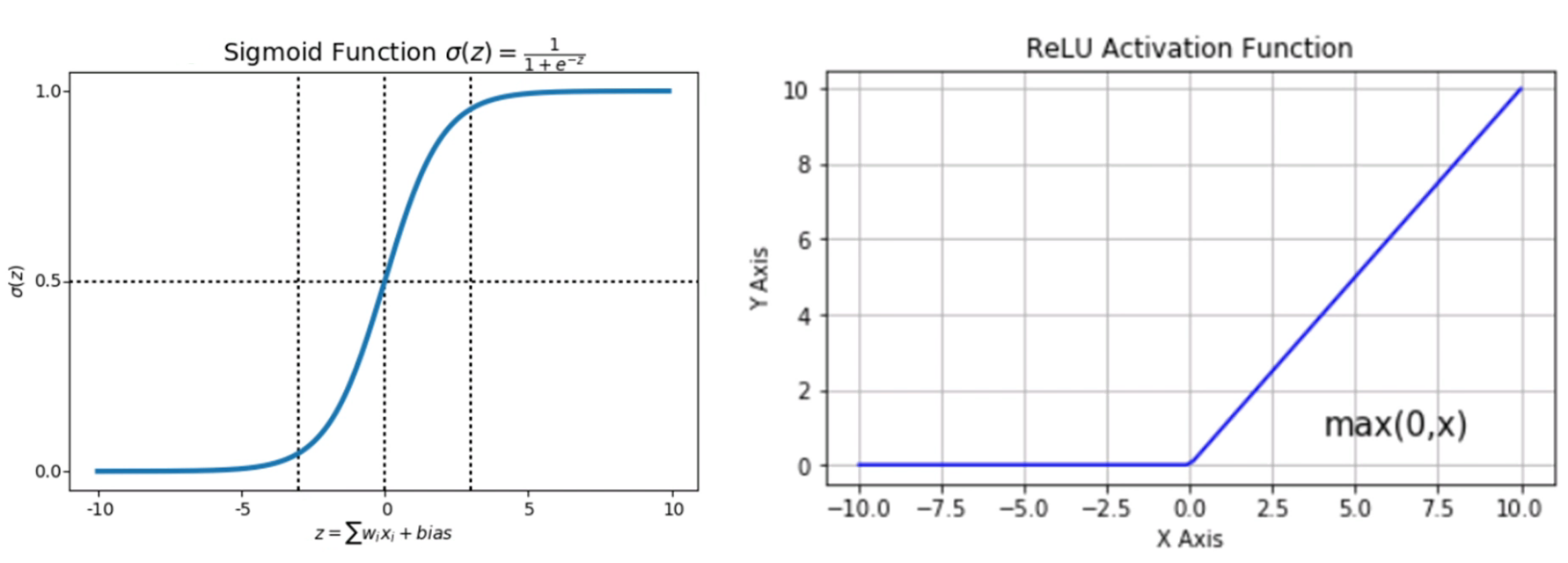
多層感知機(MLP,Multilayer Perceptron)
- 多層感知機,也叫人工神經網路(ANN,Artificial Neural Network)
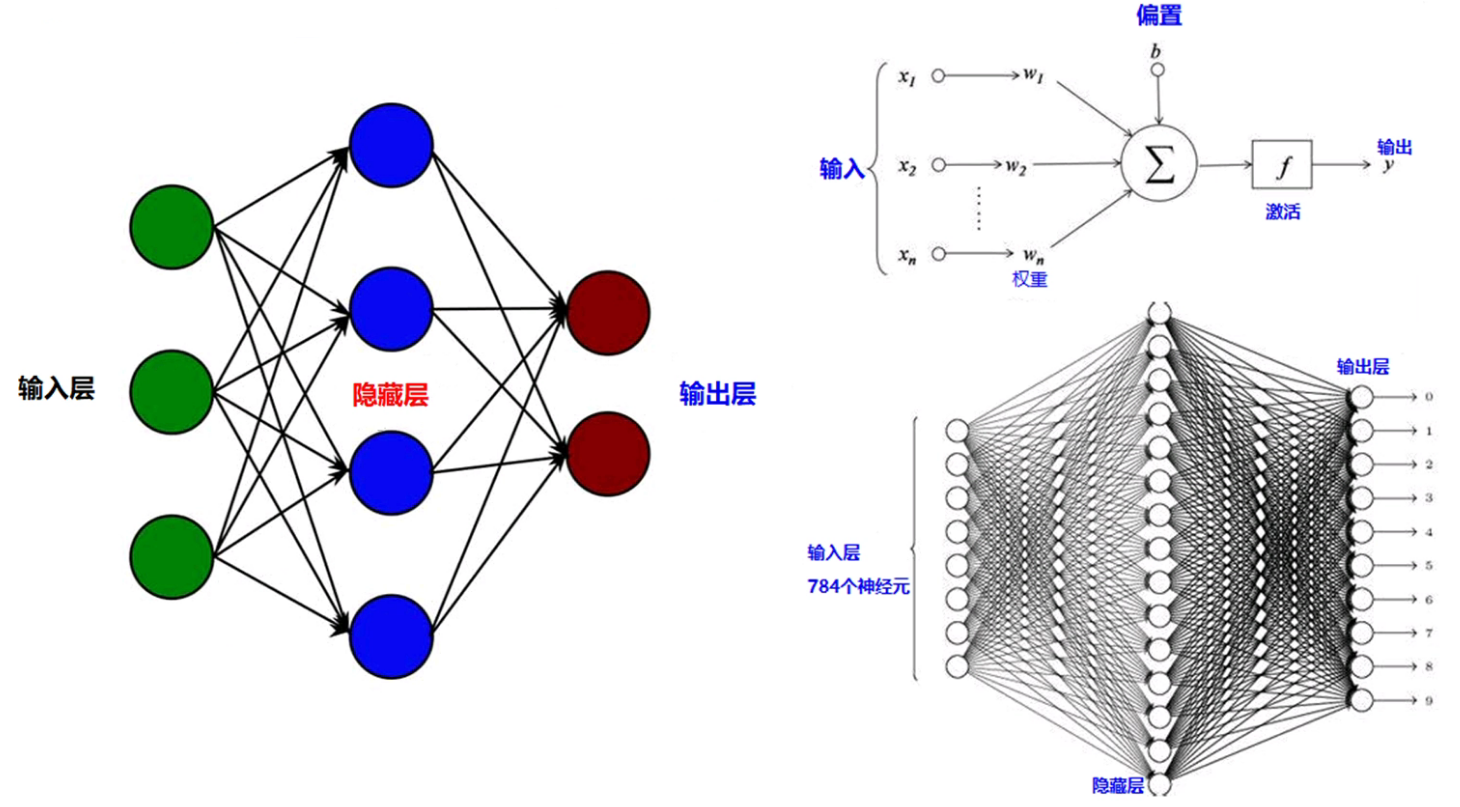
反向傳播演演算法
-
反向傳播演演算法
靜態反向傳播、迴圈反向傳播
-
兩個階段:
前向傳播階段、反向傳播階段
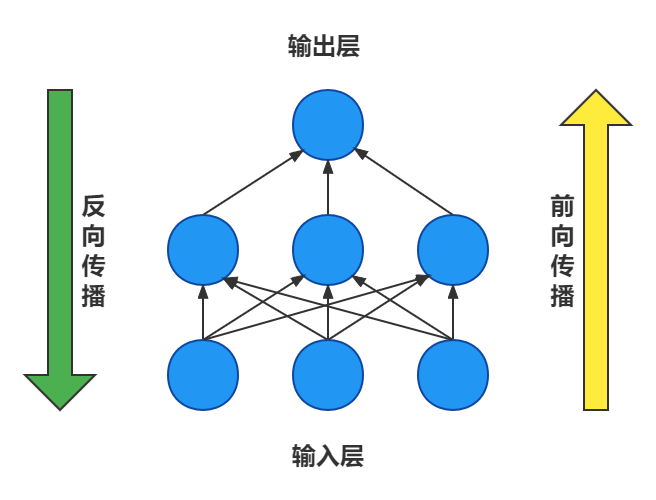
1、前向傳播:
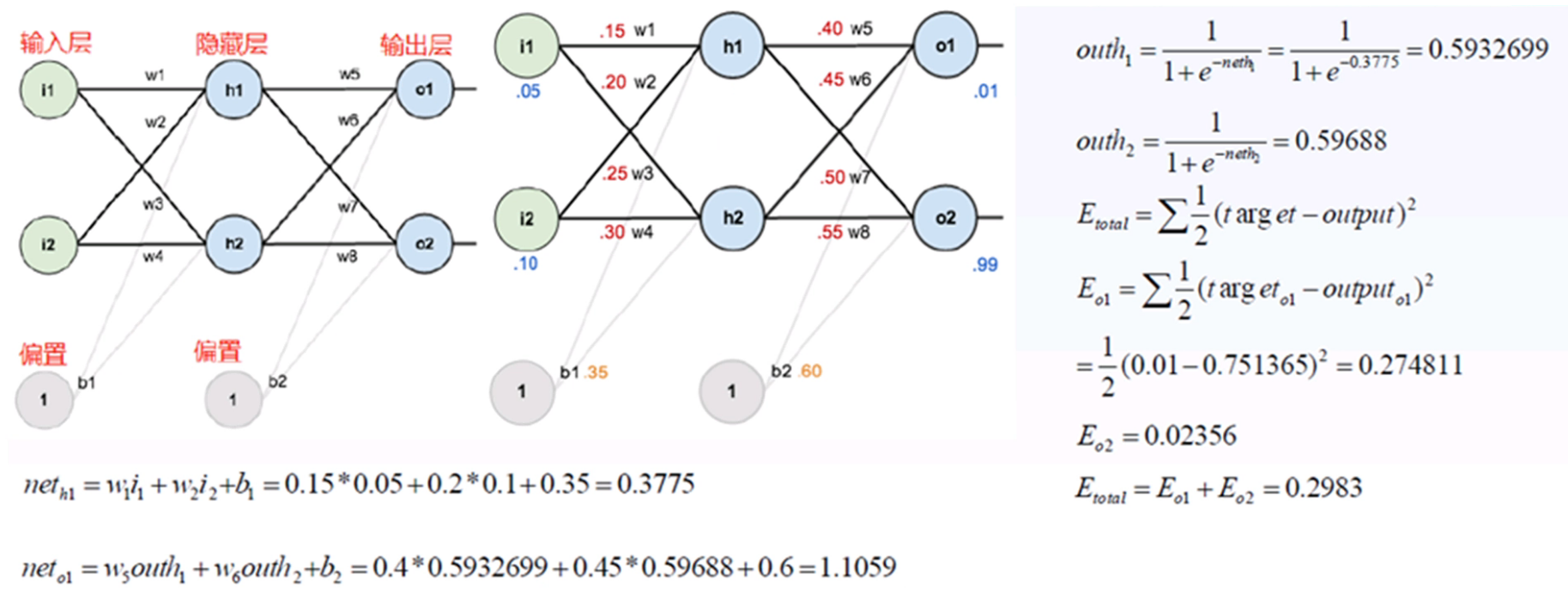
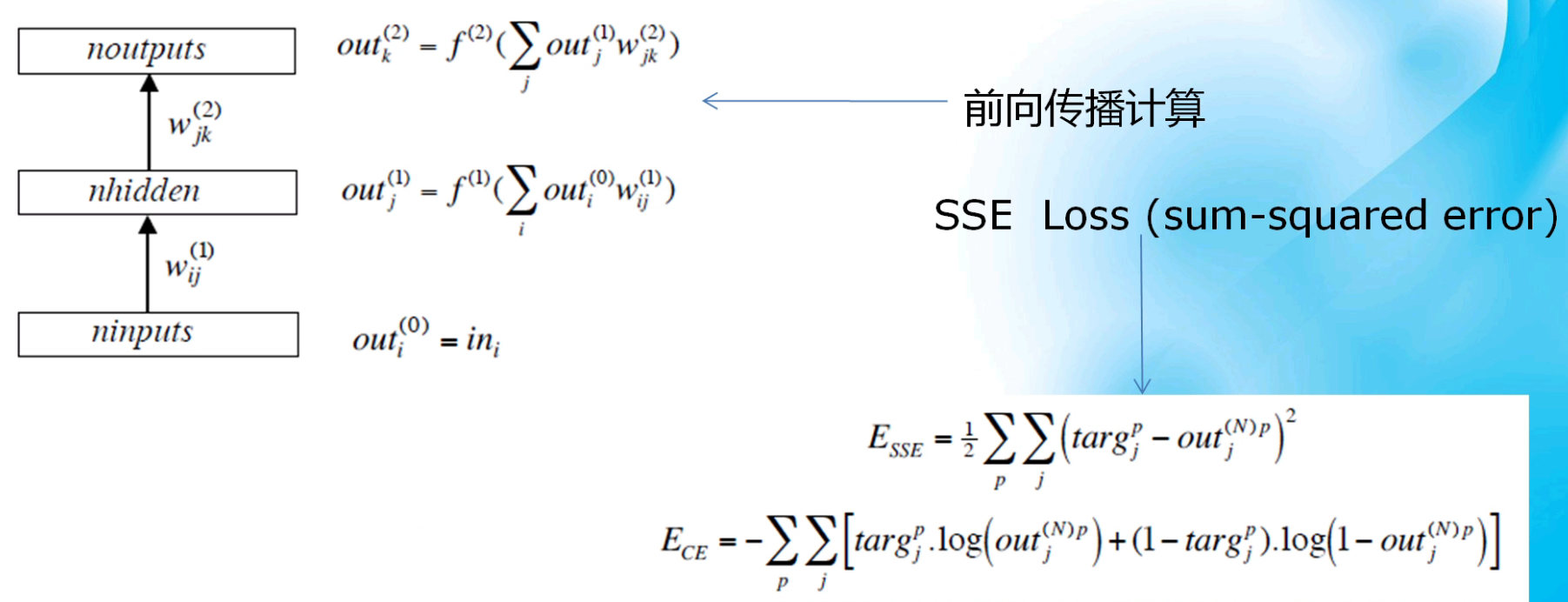
2、反向傳播(鏈式求導):
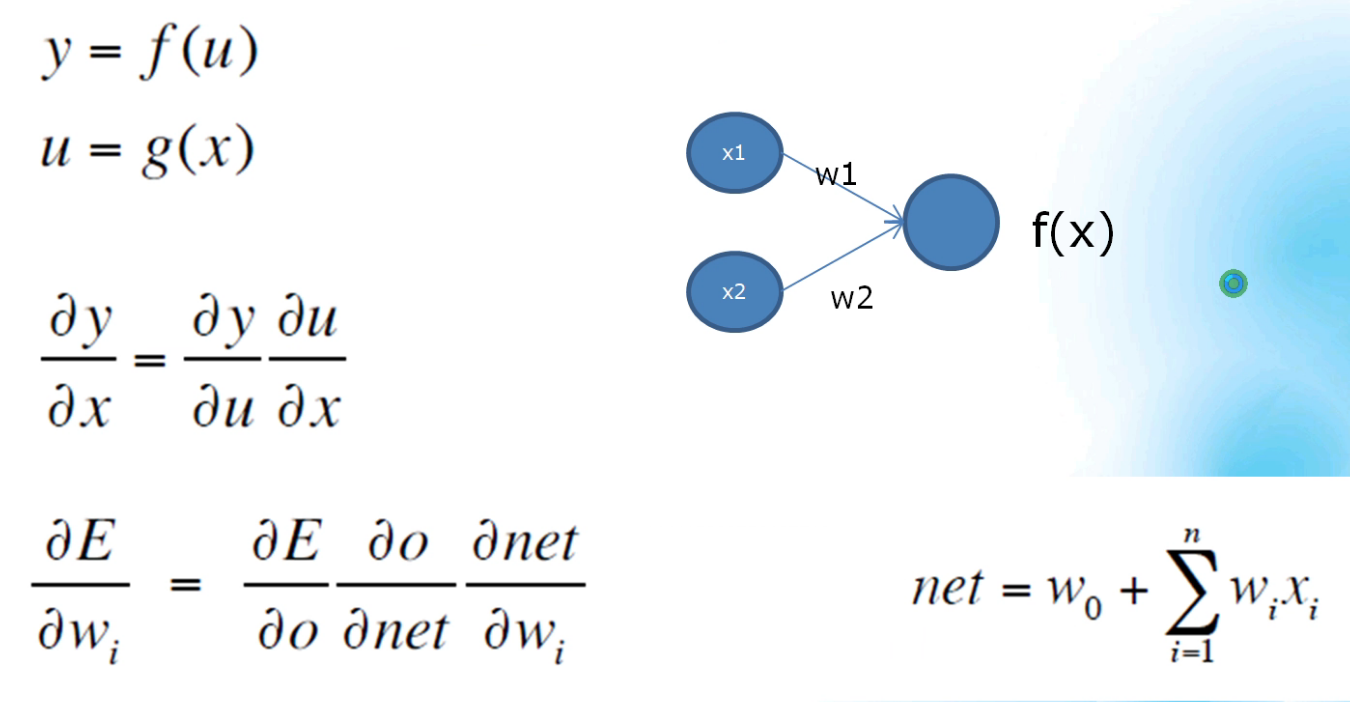

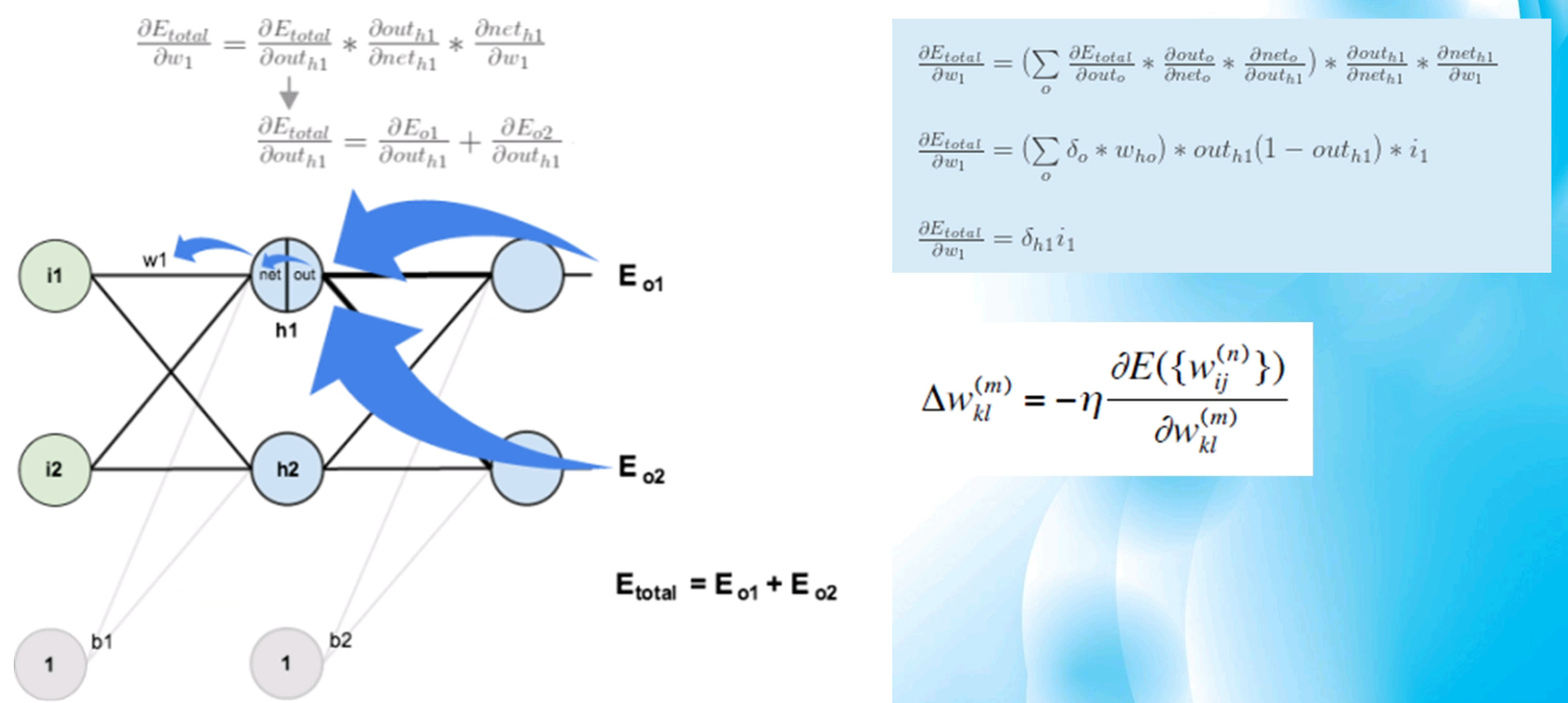
3、訓練方法
- 隨機/世故梯度下降
- 從m個樣本中每次隨機抽取1個進行梯度下降
- 批次梯度下降
- 從m個樣本中每次抽取所有樣本進行梯度下降
- Mini-batch梯度下降(小批次梯度下降)
- 從m個樣本中每次提取n個進行梯度下降(1<n<m)
Pytorch中的基礎資料集
-
資料是深度學習核心之一
- 深度學習的三個關鍵組成要素
- 資料對深度學習模型訓練的作用
- 資料來源與眾包
- 常見資料集Pascal VOC / COCO
-
Pytorch基礎資料集介紹
- torchvision.datasets 包
- Mnist/Fashion-Mnist/CIFAR
- ImageNet/Pascal VOC/MS-COCO
- Cityscapes/FakeData
-
載入/讀取/顯示/使用
-
資料集的讀取與載入
-
torch.utils.data.Dataset的子集
-
torch.utils.data.DataLoader載入資料集
Dataset只負責資料的抽象,一次呼叫getitem只返回一個樣本。在訓練神經網路時,最好是對一個batch的資料進行操作,同時還需要對資料進行shuffle和並行加速等。對此,PyTorch提供了DataLoader幫助我們實現這些功能。
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, *, prefetch_factor=2, persistent_workers=False)
-
-
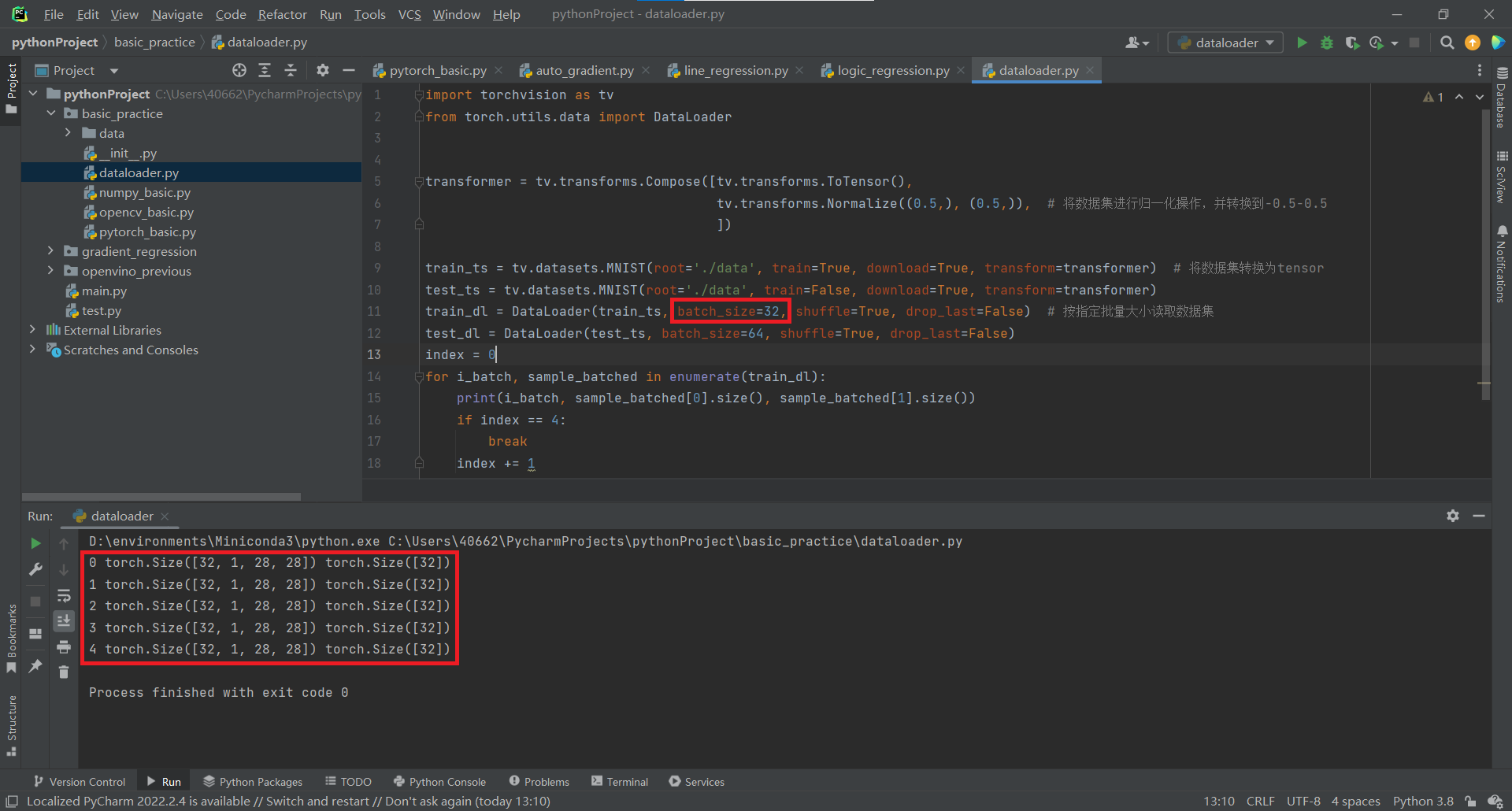
程式碼實現
import torchvision as tv
from torch.utils.data import DataLoader
transformer = tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,), (0.5,)), # 將資料集進行歸一化操作,並轉換到-0.5~0.5
])
train_ts = tv.datasets.MNIST(root='./data', train=True, download=True, transform=transformer) # 將資料集轉換為tensor
test_ts = tv.datasets.MNIST(root='./data', train=False, download=True, transform=transformer)
train_dl = DataLoader(train_ts, batch_size=32, shuffle=True, drop_last=False) # 按指定批次大小讀取資料集
test_dl = DataLoader(test_ts, batch_size=64, shuffle=True, drop_last=False)
index = 0
for i_batch, sample_batched in enumerate(train_dl):
print(i_batch, sample_batched[0].size(), sample_batched[1].size())
if index == 4:
break
index += 1
效果:
手寫數位識別人工神經網路
- Mnist資料集
- 資料集下載地址 - http://yann.lecun.com/exdb/mnist
- 訓練資料集 6W 張影象,測試資料集 1W 張影象,資料格式說明 28 * 28大小
- 構建模型(MLP構建)
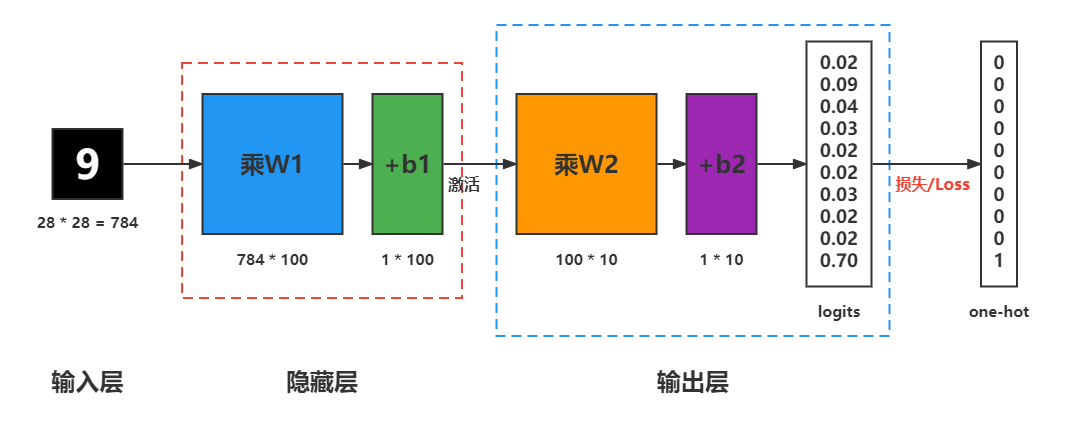
- 模型訓練
- 超引數設定(批次/學習率)
- 優化器選擇
- Adam(Adaptive Moment Estimation)對每個不同的引數調整不同的學習率,對頻繁變化的引數以更小的步長進行更新,而稀疏的引數以更大的步長進行更新。對梯度的一階矩估計(First Moment Estimation,即梯度的均值)和二階矩估計(Second Moment Estimation,即梯度的未中心化的方差)進行綜合考慮,計算出更新步長。
- 訓練epoch/step
程式碼實現
import torch
import torchvision
from torch.utils.data import DataLoader
transformer = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5,), (0.5,)),
])
train_ts = torchvision.datasets.MNIST(root='./data', train=True, transform=transformer, download=True)
test_ts = torchvision.datasets.MNIST(root='./data', train=False, transform=transformer, download=True)
train_dl = DataLoader(train_ts, batch_size=128, shuffle=True, drop_last=False)
test_dl = DataLoader(test_ts, batch_size=64, shuffle=True, drop_last=False)
model = torch.nn.Sequential(
torch.nn.Linear(784, 100), # 輸入784個值,輸出100個值
torch.nn.ReLU(), # 使用ReLU()啟用函數
torch.nn.Linear(100, 10), # 輸入100個值,輸出10個值
torch.nn.LogSoftmax(dim=1) # dim=1表示對每一行的值進行logsoftmax計算
)
# softmax為將每個輸入樣本中所有的值歸一化後累加和為1,則其中最大值所對應的標籤位置為該樣本的預測結果
# logsoftmax為對每個輸入樣本求取softmax函數(值域為[0,1])再取log(值域為(-∞,0])
# NLLLoss為將logsoftmax結果取反,再將每個樣本對應標籤位置的值累加後求平均值
loss_fn = torch.nn.NLLLoss(reduction="mean") # Negative Log Likelihood Loss
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # 自適應梯度優化
for s in range(5):
print("run in epoch : %d"%s)
for i, (x_train, y_train) in enumerate(train_dl):
x_train = x_train.view(x_train.shape[0], -1) # x_train轉置為batch_size行,y_train為每個樣本對應的標籤
y_pred = model(x_train)
train_loss = loss_fn(y_pred, y_train)
if (i + 1) % 100 == 0: # 每回圈100次輸出依次當前loss資料
print(i + 1, train_loss.item())
model.zero_grad()
train_loss.backward()
optimizer.step()
total = 0
correct_count = 0
for test_images, test_labels in test_dl:
for i in range(len(test_labels)):
image = test_images[i].view(1, 784)
# with 語句適用於對資源進行存取的場合,確保不管使用過程中是否發生異常都會執行必要的「清理」操作,釋放資源,比如檔案使用後自動關閉/執行緒中鎖的自動獲取和釋放等。
# 在pytorch中,tensor有一個requires_grad引數,如果設定為True,則反向傳播時,該tensor就會自動求導。
# with torch.no_grad的作用下,所有計算得出的tensor的requires_grad都自動設定為False。
with torch.no_grad():
pred_labels = model(image)
plabels = torch.exp(pred_labels) # 將pred_labels轉換到0~+∞,便於獲取最大值
probs = list(plabels.numpy()[0]) # 獲取第一行plabels最大值的索引值
pred_label = probs.index(max(probs))
print(test_labels)
true_label = test_labels.numpy()[i]
if pred_label == true_label:
correct_count += 1
total += 1
print("total acc : %.2f\n"%(correct_count / total))
torch.save(model, './nn_mnist_model.pt')
模型儲存與預測呼叫
-
模型儲存/載入
-
儲存整個模型
-
# 儲存模型 torch.save(model, PATH) # 載入模型 model = torch.load(PATH) model.eval()
-
-
儲存推理模型
-
在模型中,我們通常會加上Dropout層和batch normalization層,在模型預測階段,我們需要將這些層設定到預測模式,model.eval()就是幫我們一鍵搞定的,如果在預測的時候忘記使用model.eval(),會導致不一致的預測結果。
-
# 儲存模型 torch.save(model.state_dict(), PATH) # 載入模型 model = model.load_state_dict(torch.load(PATH)) model.eval()
-
-
-
模型預測
-
認識state_dict
-
state_dict是Python格式的字典資料
-
只儲存各層的引數相關資訊
-
可以通過model跟optimizer獲取
-
儲存檢查點
-
# 儲存檢查點 torch.save({ 'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': loss, ... }, PATH) # 恢復檢查點 model = TheModelClass(*args, **kwargs) optimizer = TheOptimizerClass(*args, **kwargs) checkpoint = torch.load(PATH) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) epoch = checkpoint['epoch'] loss = checkpoint['loss'] model.eval() # - or - model.train()
-
-
恢復/推理
-
import cv2 as cv import numpy # 推理 model = model.load_state_dict(torch.load("./nn_mnist_model.pt")) model.eval() input = cv.imread("D:/images/9.png", cv.IMREAD_GRAYSCALE) cv.imshow("input", input) img_f = numpy.float32(input) img_f = (img_f/255.0-0.5)/0.5 img_f = numpy.reshape(img_f, (1, 784)) pred_label = model(torch.from_numpy(img_f)) pred = torch.exp(pred_label) res = list(pred.detach().numpy()[0]) label = res.index(max(res)) print("predict digit number: ", label) cv.waitKey(0) cv.destroyAllWindows()
-
-
折積神經網路
折積的基本概念與術語
-
折積的基本概念
-
什麼是折積(輸入 + 脈衝 = 輸出)
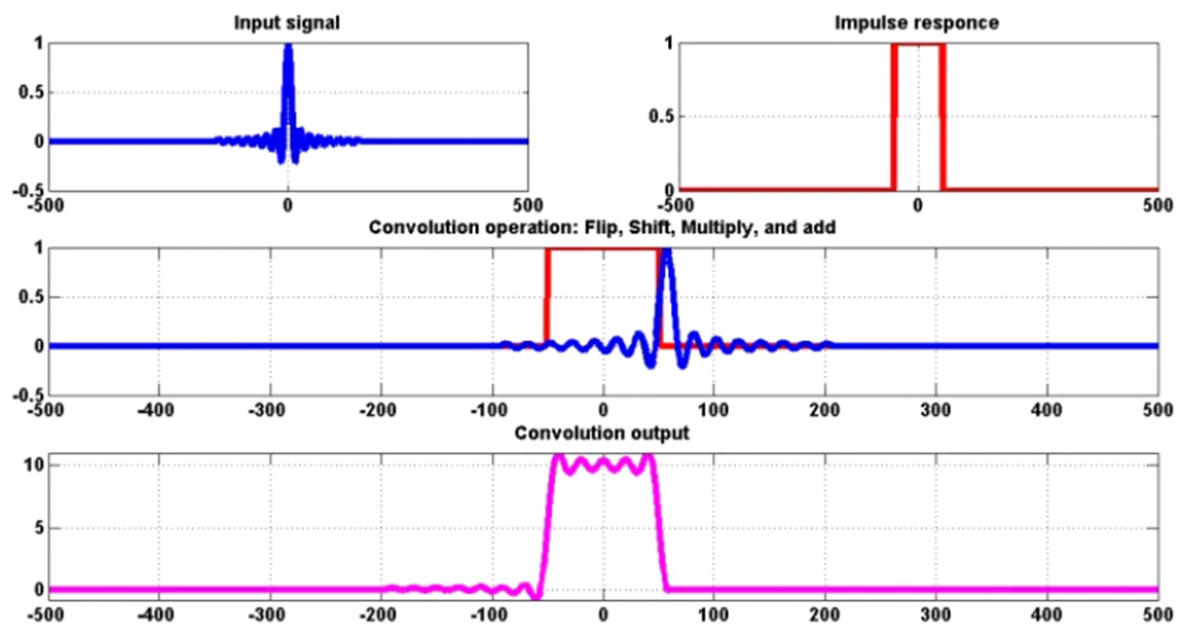
-
一維離散折積
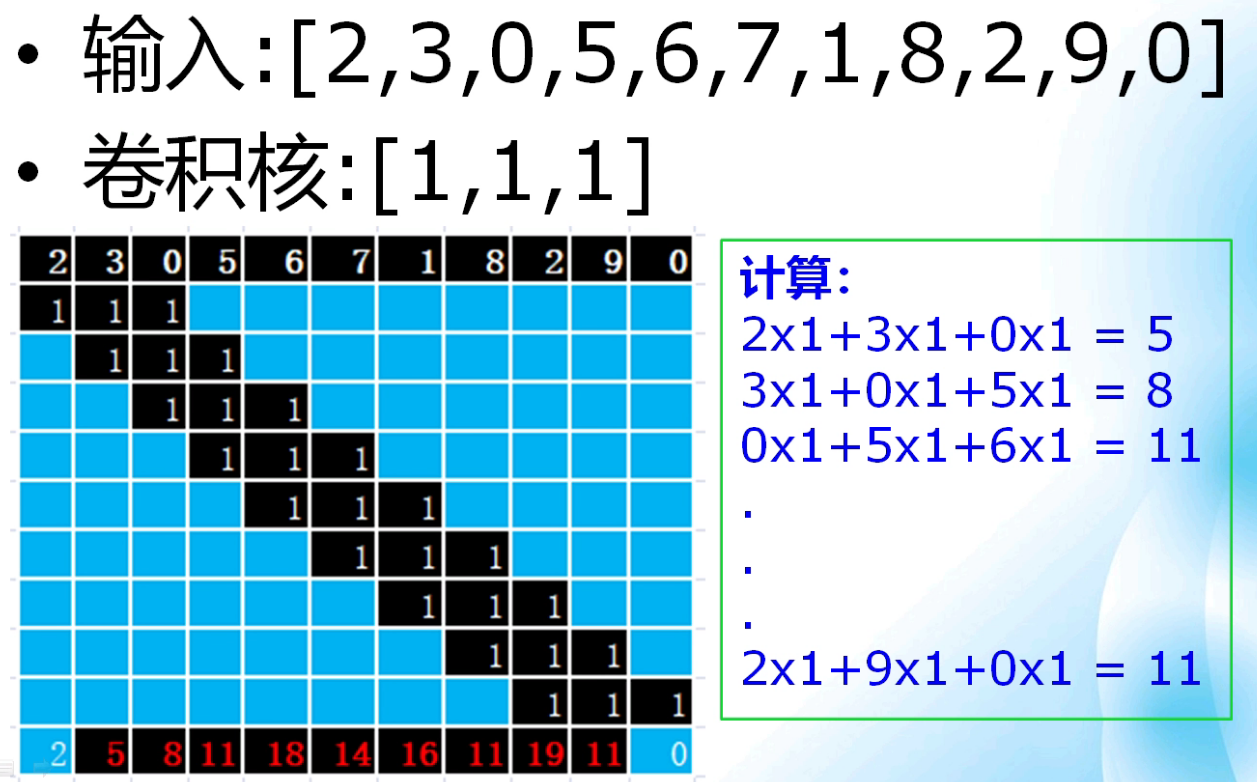
-
-
基本影象折積
-
基本影象折積,與之前寫的OpenCV中的內容完全一樣
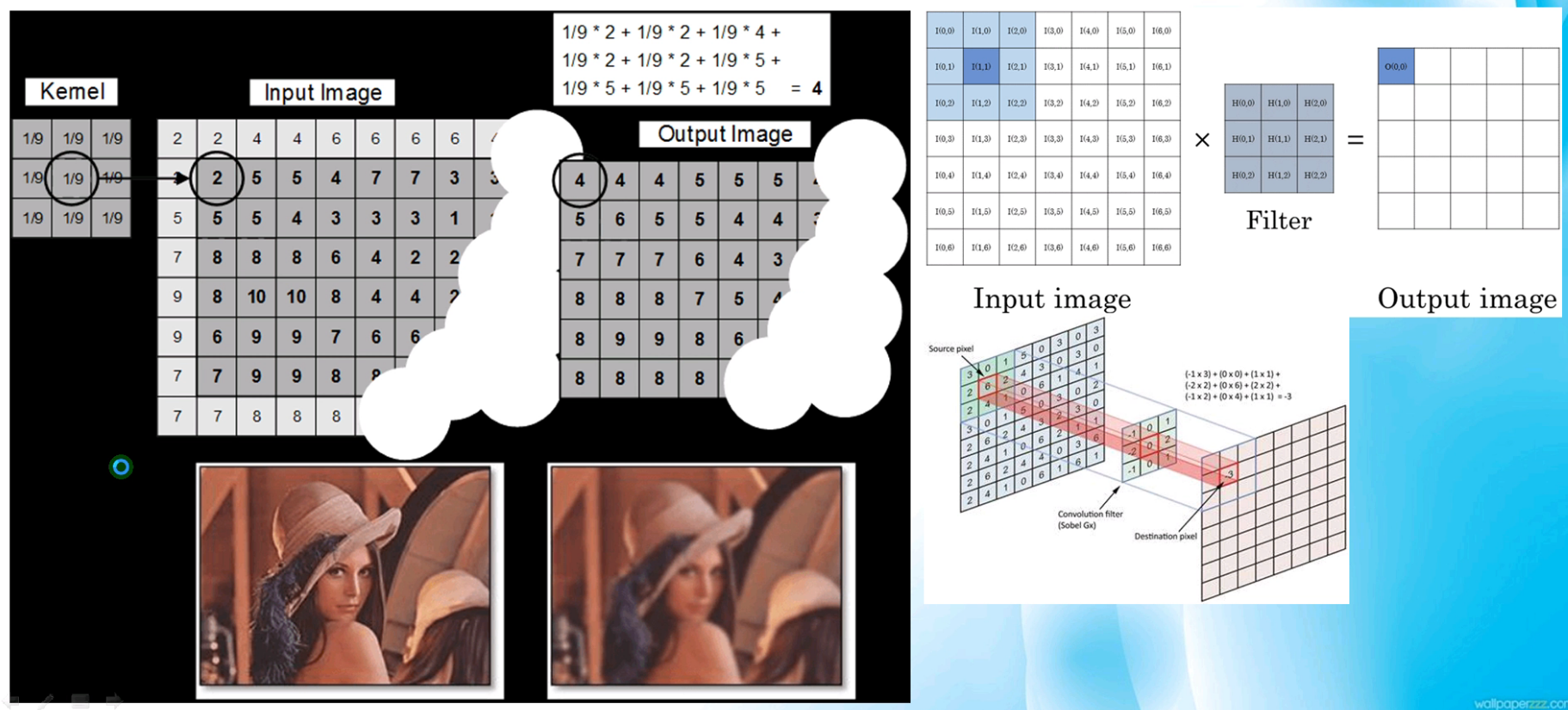
-
折積操作相關的專業術語
- 折積核/運算元/filter(一樣的kernel,不同叫法)
- 折積的錨定位置(預設中心位置)
- 折積的邊緣填充方式 valid/same
-
-
邊緣處理
- full(折積後周邊增加畫素)/same(折積後保持原圖大小)/valid(不填充畫素直接進行折積運算)

- 錨定位置(預設為(-1, -1))

-
Pytorch中的折積
-
torch.nn.functional.conv2d(2D影象折積)
-
程式碼實現
import cv2 as cv import torch import torch.nn.functional as F # 匯入torch.nn中的functional模組進行折積運算 import numpy input_img = cv.imread("D:/images/lena.jpg", cv.IMREAD_GRAYSCALE) # 以灰度圖模式讀取影象並顯示 cv.imshow("input", input_img) h, w = input_img.shape # 獲取輸入影象的寬高資訊(注意:此處shape不加括號,不是方法) img = numpy.reshape(input_img, (1, 1, h, w)) # 使用numpy轉換輸入影象為四個維度並轉換為浮點型 img = numpy.float32(img) # 自定義7 * 7大小的浮點折積核,因為求取的是49個畫素的計算後累加和,因此再除以49.0將結果值轉換到0-255範圍內 k = torch.ones((1, 1, 7, 7), dtype=torch.float) / 49.0 res = F.conv2d(torch.from_numpy(img), k, padding=3) # 折積運算輸入tensor格式資料,邊緣填充3個畫素 out = numpy.reshape(res.numpy(), (h, w)) # 將結果轉換為原圖大小的numpy陣列,並轉換為整數型別 cv.imshow("result", numpy.uint8(out)) cv.waitKey(0) cv.destroyAllWindows() -
效果:
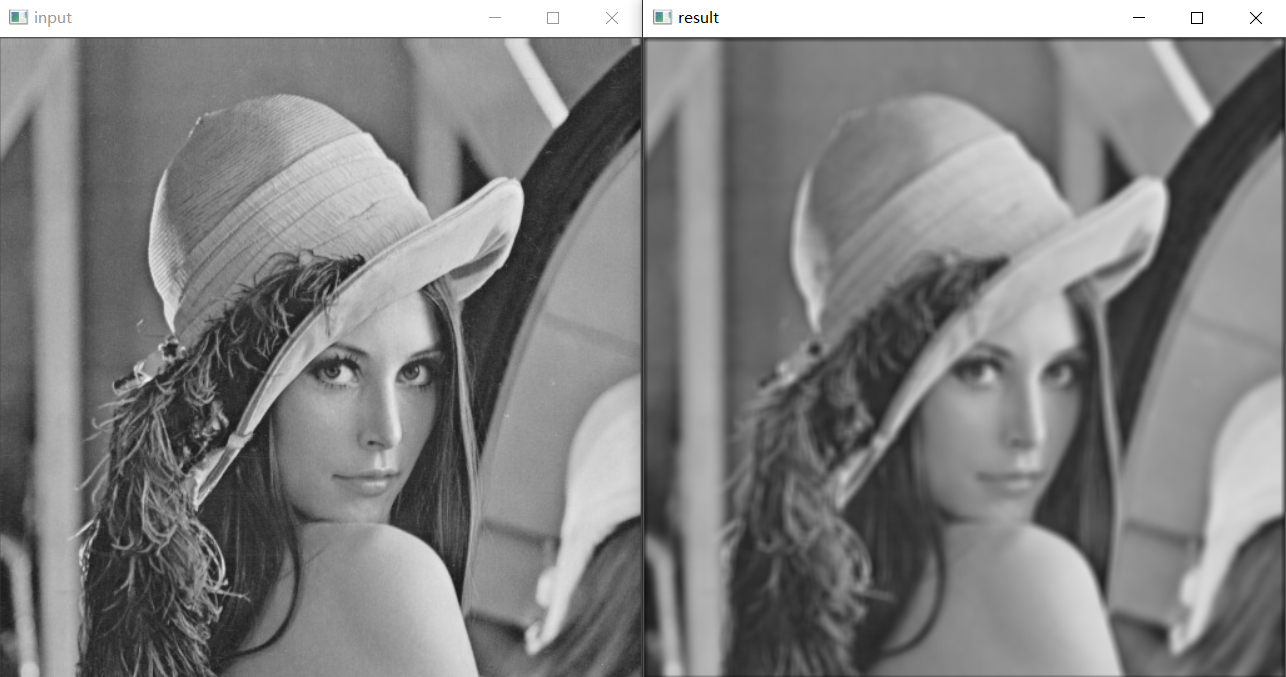
-
折積神經網路基本原理與引數
-
折積神經網路(CNN)基本原理
-
折積神經網路的好處:共用權重、畫素遷移、空間資訊提取
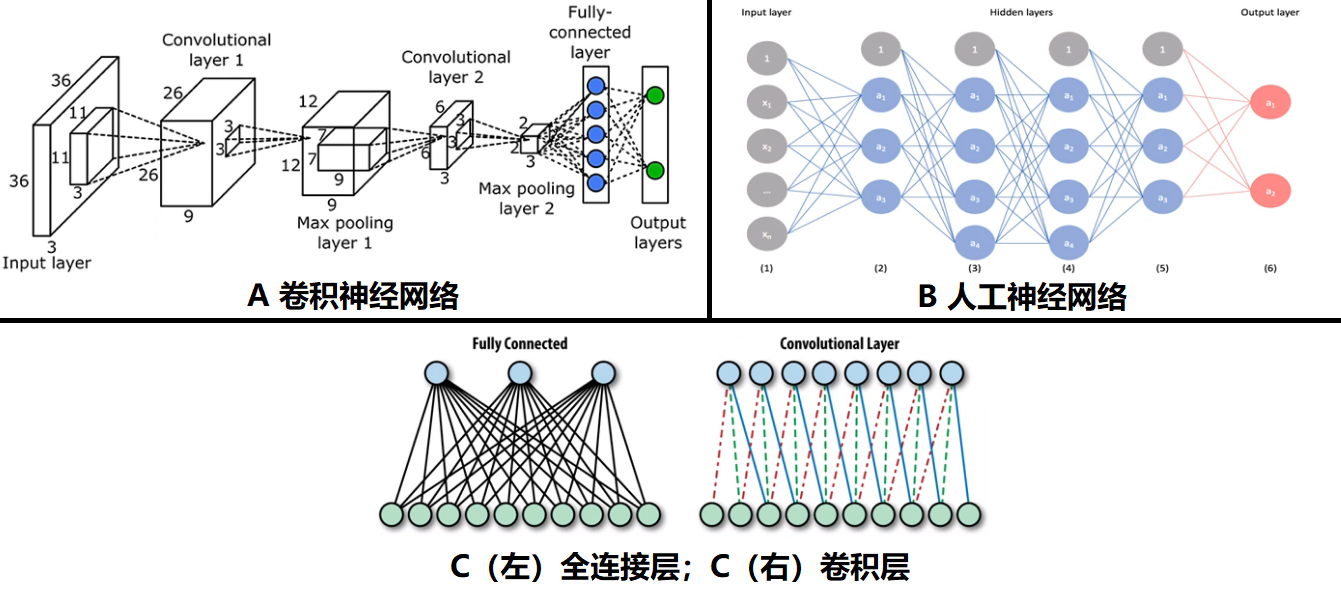
-
-
CNN中的層與引數
- 折積層,提取影象特徵
- 池化層,降低網路引數數量(layer增加,抵消降取樣帶來的空間和資訊損失)
-
折積層與池化層
-
折積層操作:
-
步長 stride = 1;填充 VALID;折積核 filter size = 3 * 3
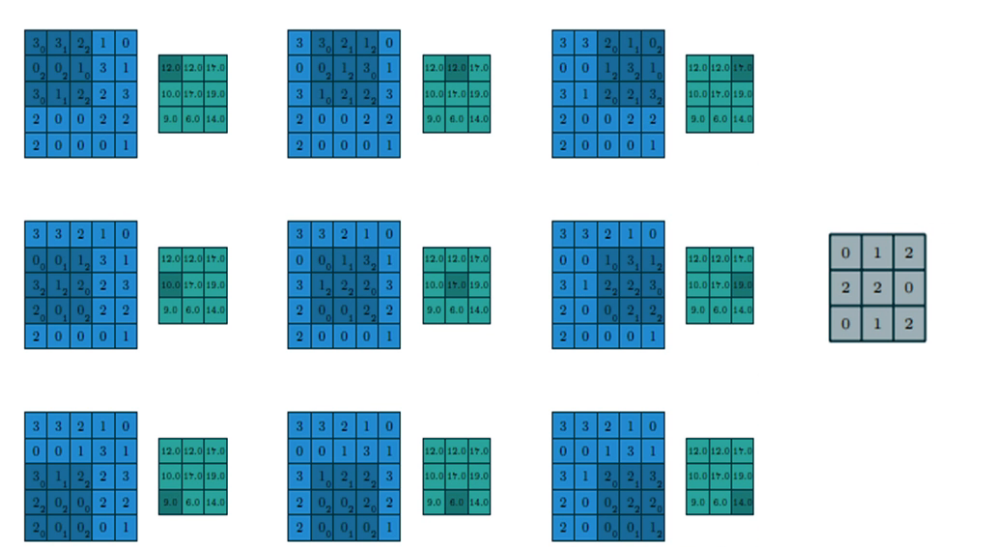
-
步長 stride = 2;填充 SAME;折積核 filter size = 3 * 3
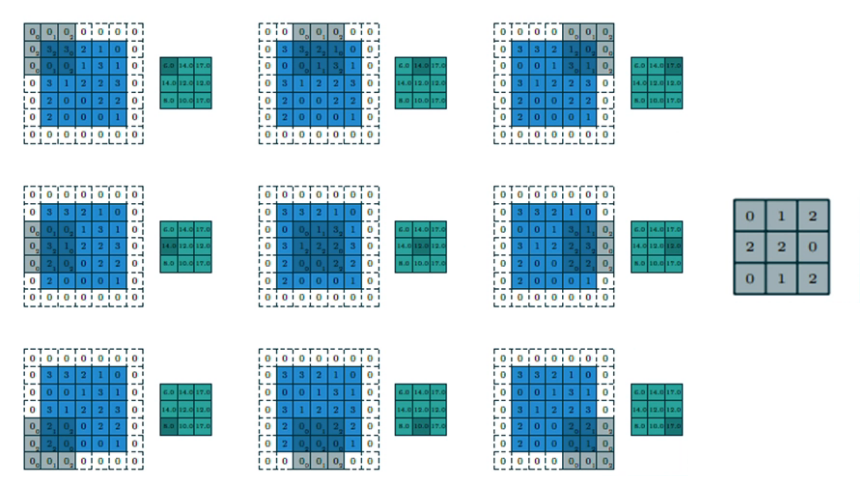
-
-
折積層輸出大小
-
W * W的feature map
-
Filter的大小為F * F
-
折積時填充邊緣P個畫素
-
折積步長(stride)為S
-
則輸出的大小為:
\[輸出大小\, =\, \frac {W\, -\, F\, +\, 2P} {S}\, +\, 1 \]
-
-
折積層詳解
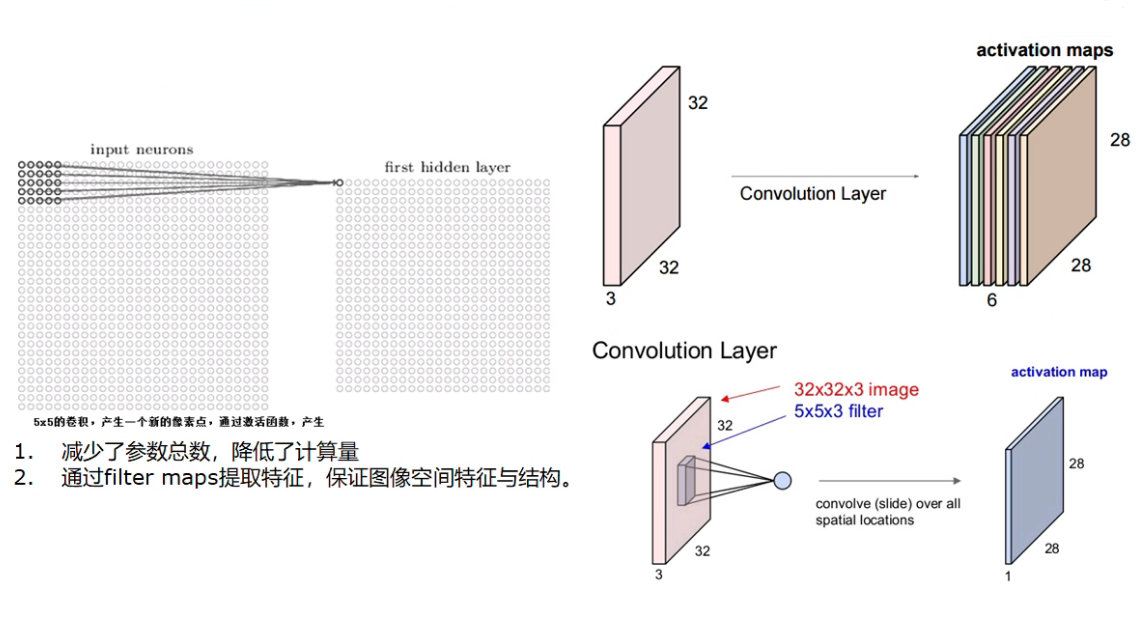
-
池化層詳解
- 重疊池化
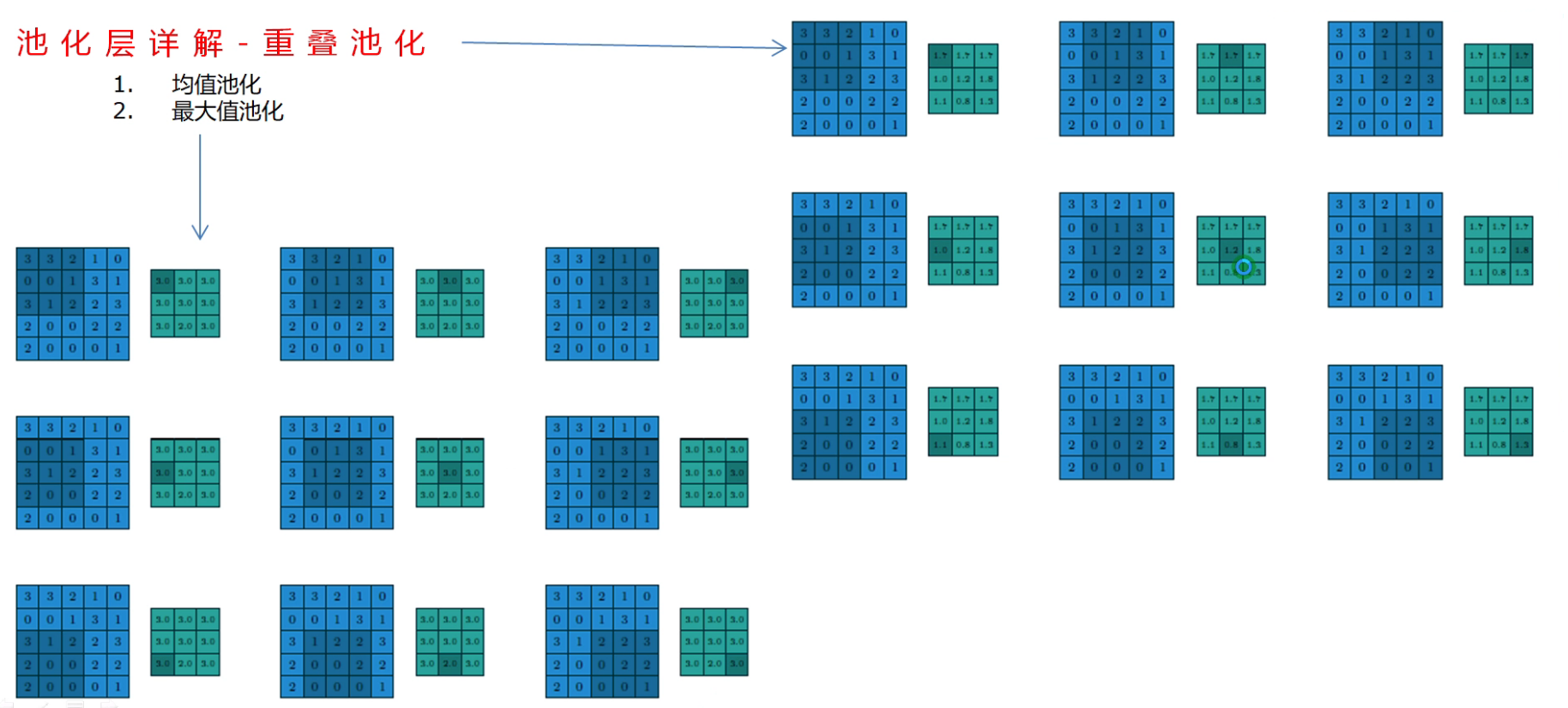
- 區域性池化
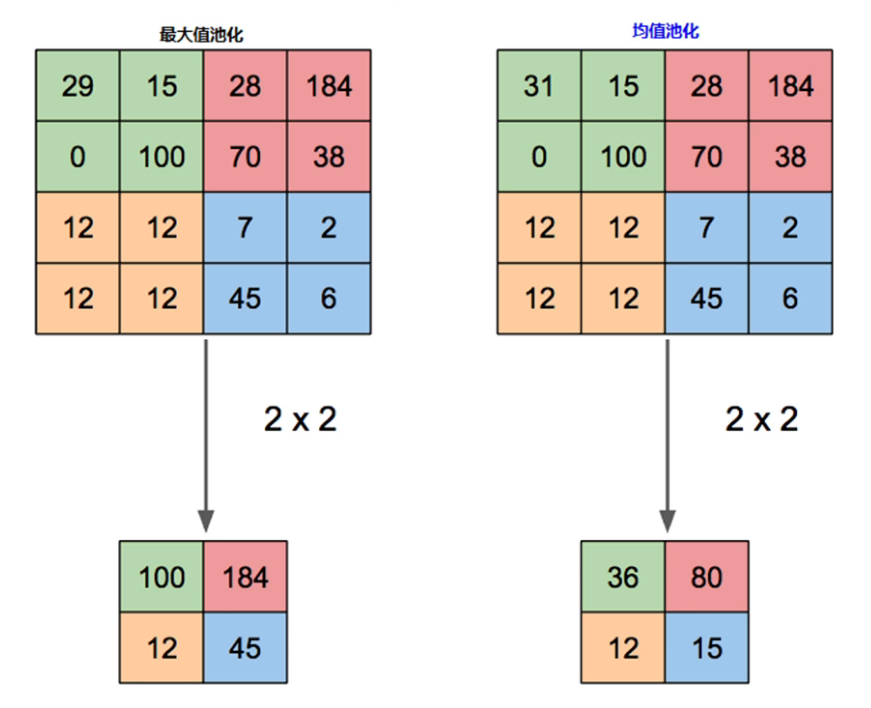
- 最大值池化與均值池化對比
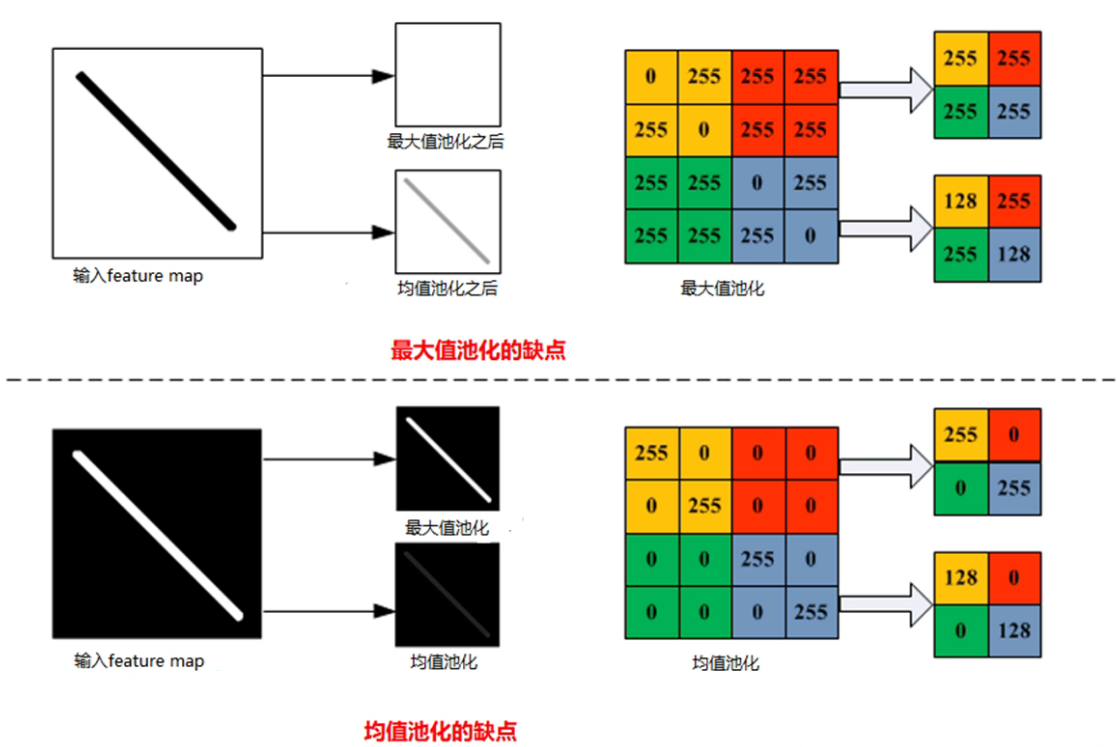
- 折積層特點
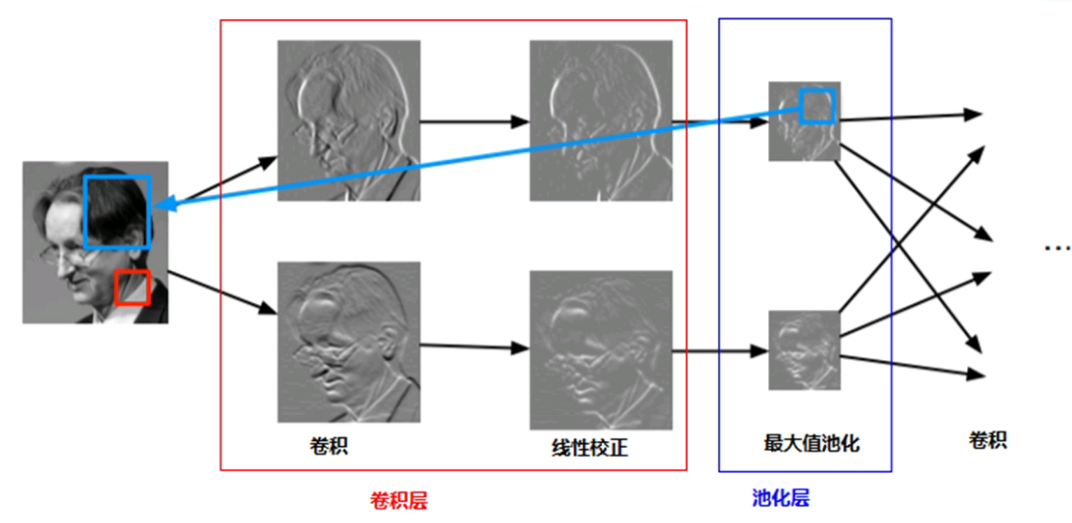
- 區域性感受野
- 權重共用機制
- 池化下取樣操作
- 獲取了影象的遷移、形變與尺度空間不變性特徵
-
折積神經網路構建、訓練與預測使用
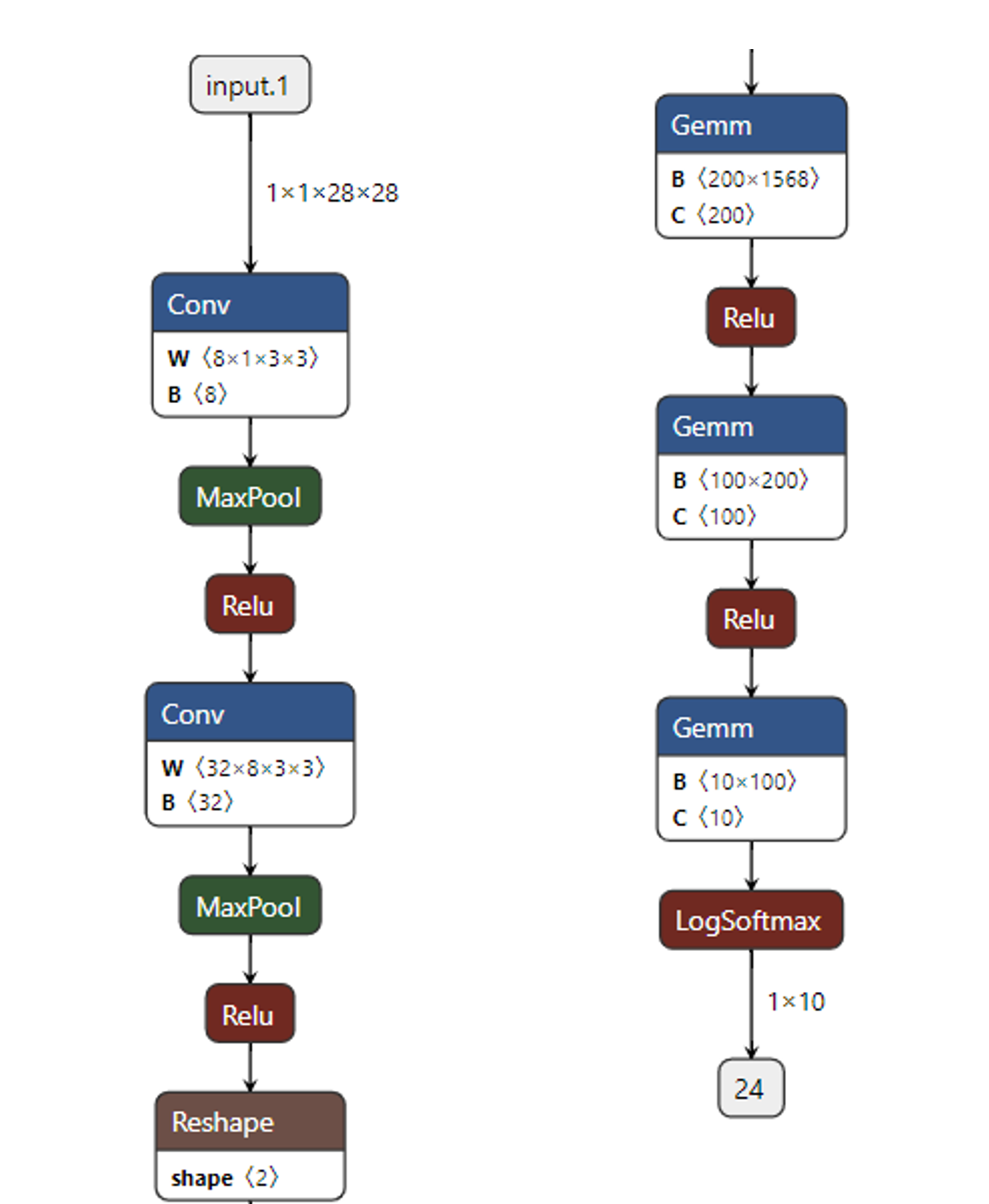
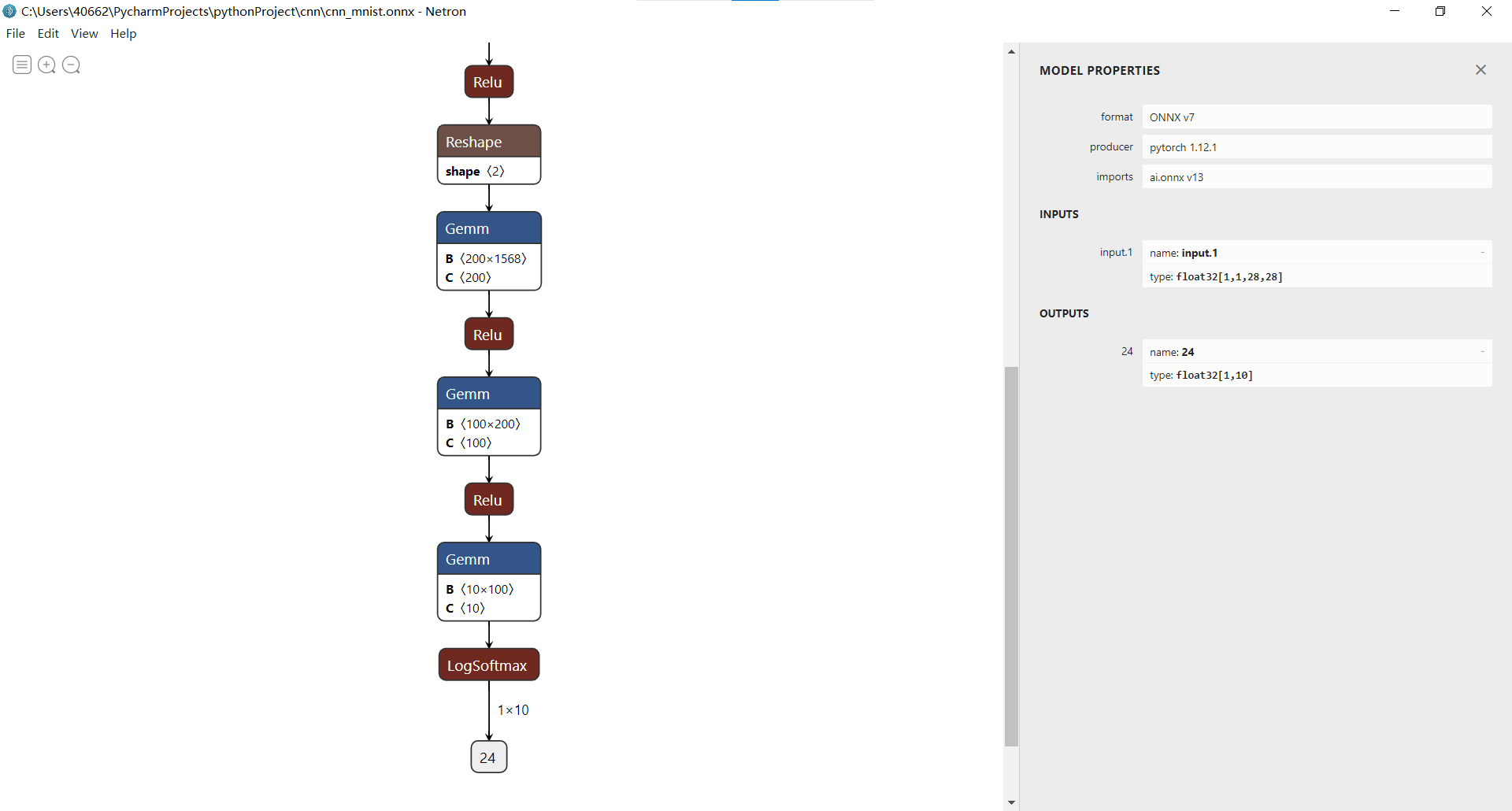
- CNN手寫數位識別網路結構:
- 折積層 + 池化層
- 全連線層
- 輸出層
使用Netron檢視網路結構
程式碼實現
import torch
import torchvision
import numpy
from torch.utils.data import DataLoader
transformers = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.5, ), (0.5, ))])
train_ts = torchvision.datasets.MNIST(root='./data', train=True, transform=transformers, download=True)
test_ts = torchvision.datasets.MNIST(root='./data', train=False, transform=transformers, download=True)
train_dl = DataLoader(train_ts, batch_size=64, shuffle=True, drop_last=False)
test_dl = DataLoader(test_ts, batch_size=32, shuffle=True, drop_last=False)
class CNN_Mnist(torch.nn.Module):
def __init__(self):
super(CNN_Mnist, self).__init__()
self.cnn_layers = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, stride=1, padding=1),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=8, out_channels=32, kernel_size=3, stride=1, padding=1),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.ReLU()
)
self.fc_layers = torch.nn.Sequential(
torch.nn.Linear(7*7*32, 200),
torch.nn.ReLU(),
torch.nn.Linear(200, 100),
torch.nn.ReLU(),
torch.nn.Linear(100, 10),
torch.nn.LogSoftmax(dim=1)
)
def forward(self, x):
out = self.cnn_layers(x)
out = out.view(-1, 7*7*32)
out = self.fc_layers(out)
return out
model = CNN_Mnist().cuda()
print("Model's state_dict: ")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for s in range(5):
print("run in epoch : %d"%s)
for i, (x_train, y_train) in enumerate(train_dl):
x_train = x_train.cuda()
y_train = y_train.cuda()
y_pred = model.forward(x_train)
train_loss = loss(y_pred, y_train)
if (i + 1) % 100 == 0: # 每回圈100次輸出依次當前loss資料
print(i + 1, train_loss.item())
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
torch.save(model.state_dict(), './cnn_mnist_model.pt')
model.eval()
total = 0
correct_count = 0
for test_images, test_labels in test_dl:
pred_labels = model(test_images.cuda())
predicted = torch.max(pred_labels, 1)[1]
correct_count += (predicted == test_labels.cuda()).sum()
total += len(test_labels)
print("total acc : %.2f\n"%(correct_count / total))
ONNX(Open Neural Network Exchange)格式模型匯出與推理
程式碼實現
import cv2 as cv
import numpy
import pyttsx3
# 推理
model = cv.dnn.readNetFromONNX("./cnn_mnist_model.onnx")
input = cv.imread("D:/images/9.png", cv.IMREAD_GRAYSCALE)
cv.imshow("input", input)
# 轉換為(1, 1, 28, 28)
blob = cv.dnn.blobFromImage(input, 0.00392, (28, 28), (127.0)) / 0.5 # 縮放比例,尺寸,減去的值
model.setInput(blob)
result = model.forward()
pred_label = numpy.argmax(result, 1) # 獲取最大概率的索引
print("predict label : %d"%pred_label)
engine = pyttsx3.init() # 語音播報預測結果
engine.say(str(pred_label))
engine.runAndWait()
cv.waitKey(0)
cv.destroyAllWindows()
Pytorch資料集與訓練視覺化
Pytorch中的資料與資料集類
-
Pytorch的資料集類
-
Pytorch資料類torch.util.data包
-
Dataset資料抽象類
-
支援Map-style與Iterable-style
-
Map-style完成方法:
- _ _ getitem() _ _
- _ _ len() _ _
-
存取 dataset[idx] 其中 idx 表示索引
-
DataLoader
- 支援載入 Map-style 與 Iterable-style資料
- 自定義資料集載入
- 自動batch提取
- 單個或者多個資料載入
- 自動記憶體固定
-
DataLoader函數解釋
torch.utils.data.DataLoader( dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, * , prefetch_factor=2, persistent_workers=False )import torch import numpy as np from torch.utils.data import Dataset, DataLoader from torchvision import transforms, utils import cv2 as cv class FaceLandmarksDataset(Dataset): def __init__(self, txt_file): self.transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]), transforms.Resize((64, 64)) ]) lines = [] with open(txt_file) as read_file: for line in read_file: # 逐行遍歷並新增到lines陣列中 line = line.replace('\n', '') lines.append(line) self.landmarks_frame = lines def __len__(self): return len(self.landmarks_frame) def num_of_samples(self): return len(self.landmarks_frame) def __getitem__(self, idx): if torch.is_tensor(idx): idx = idx.tolist() contents = self.landmarks_frame[idx].split('\t') image_path = contents[0] img = cv.imread(image_path) # BGR order h, w, c = img.shape # rescale # img = cv.resize(img, (64, 64)) # img = (np.float32(img) /255.0 - 0.5) / 0.5 landmarks = np.zeros(10, dtype=np.float32) for i in range(1, len(contents), 2): landmarks[i - 1] = np.float32(contents[i]) / w # w與h轉換為0~1 landmarks[i] = np.float32(contents[i + 1]) / h landmarks = landmarks.astype('float32').reshape(-1, 2) # 矩陣大小轉換為5行2列 # H, W C to C, H, W # img = img.transpose((2, 0, 1)) sample = {'image': self.transform(img), 'landmarks': torch.from_numpy(landmarks)} # 影象與其對應的標註資訊 return sample if __name__ == "__main__": ds = FaceLandmarksDataset("D:/facedb/Face-Annotation-Tool/landmark_output.txt") for i in range(len(ds)): sample = ds[i] print(i, sample['image'].size(), sample['landmarks'].size()) if i == 3: break dataloader = DataLoader(ds, batch_size=4, shuffle=True) # data loader for i_batch, sample_batched in enumerate(dataloader): print(i_batch, sample_batched['image'].size(), sample_batched['landmarks'].size()) -
資料集預處理
- torchvision.transform資料預處理
- ToTensor轉換為tensor資料取值0~1
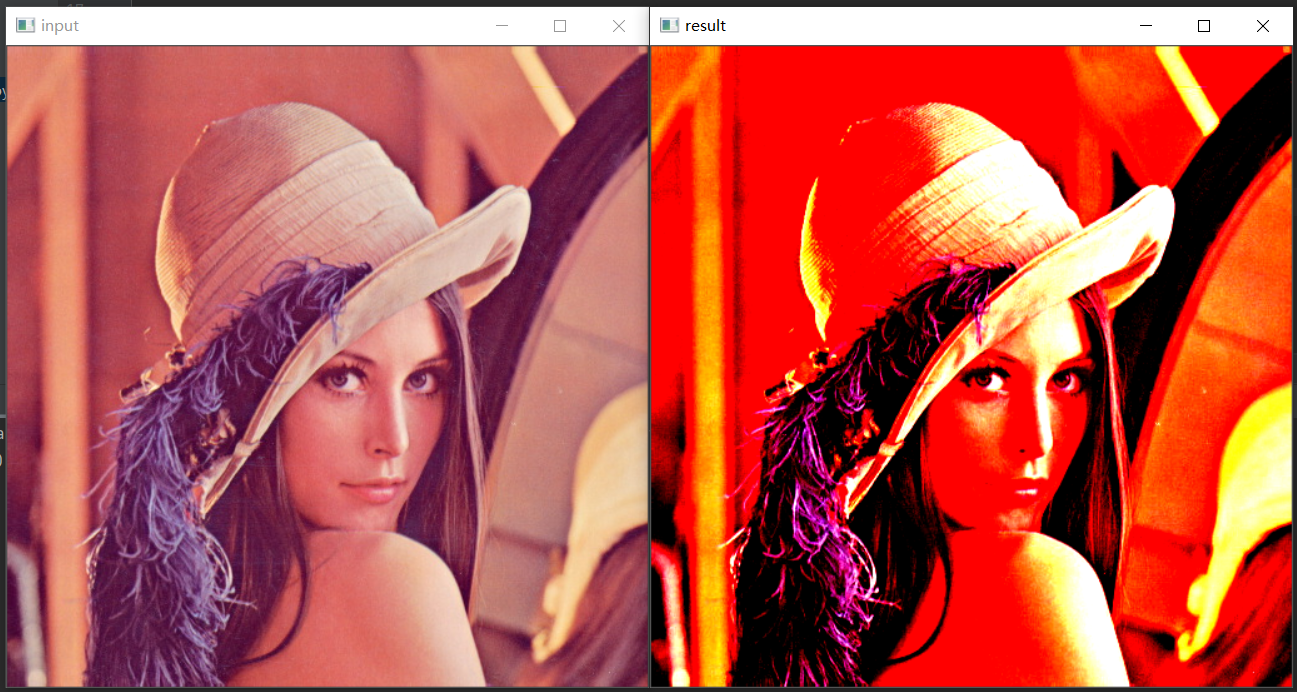
程式碼實現:
import torch import cv2 as cv import torchvision.transforms as tf torch.manual_seed(17) transforms = torch.nn.Sequential( tf.Grayscale() ) scripted_transforms = torch.jit.script(transforms) c_transforms = tf.Compose([ tf.ToTensor(), tf.Normalize(mean=[0.485, 0.456, 0.406], # 轉換為0~1,再減去均值mean,除以方差std std=[0.229, 0.224, 0.225]) ]) image = cv.imread("D:/images/lena.jpg") cv.imshow("input", image) # im_data = image.transpose((2, 0, 1)) # result = scripted_transforms(torch.from_numpy(numpy.float32(im_data)/255.0)) # 轉換為灰度圖 result = c_transforms(image) print(result.shape) result = result.numpy().transpose(1, 2, 0) # 對通道進行轉置 cv.imshow("result", result) cv.waitKey(0) cv.destroyAllWindows()效果:
-
-
Landmark資料集標註
-
自定義影象資料集類
Pytorch訓練視覺化
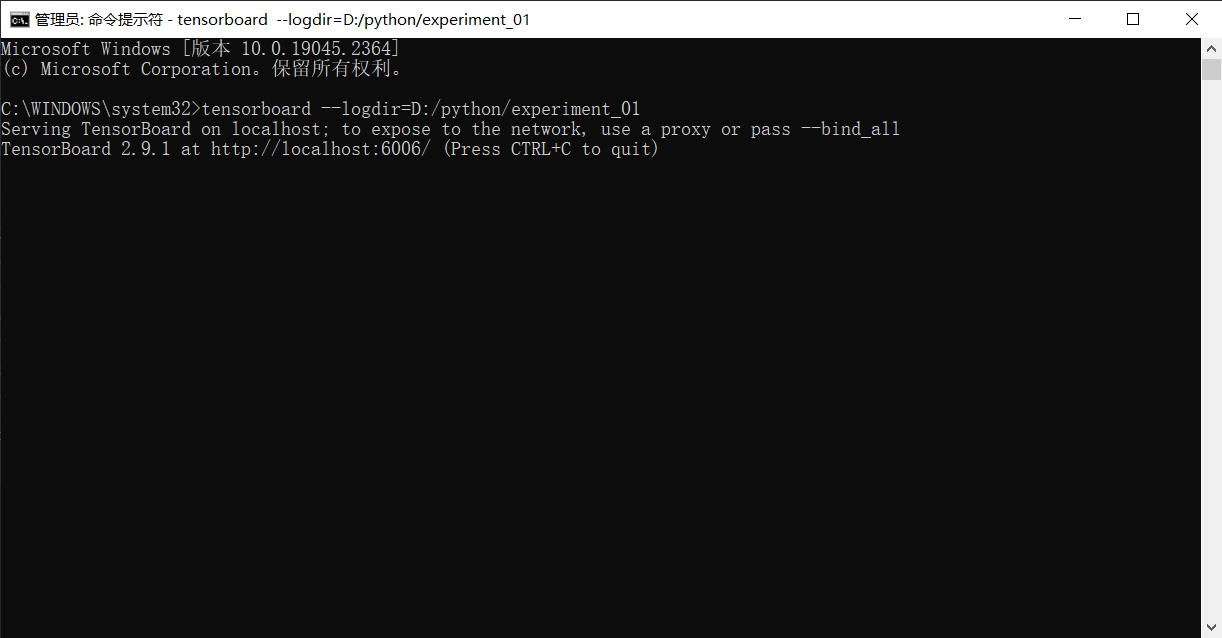
Tensorboard視覺化
-
來自tensorflow,torch.utils.tensorboard
-
啟動與存取:http://localhost:6006
-
pip install tensorboard
-
from torch.utils.tensorboard import SummaryWriter
-
tensorboard --logdir=D:/python/experiment_01
-
標量與影象儲存
-
writer.add_image(), writer.add_graph(), writer.add_scalar()
程式碼實現
import torch as t
from torch.utils.data import DataLoader
import torchvision as tv
from torch.utils.tensorboard import SummaryWriter
transform = tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5,), (0.5,)),
])
train_ts = tv.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_ts = tv.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_dl = DataLoader(train_ts, batch_size=32, shuffle=True, drop_last=False)
test_dl = DataLoader(test_ts, batch_size=64, shuffle=True, drop_last=False)
writer = SummaryWriter('D:/python/experiment_01') # 資料儲存路徑
# get some random training images
dataiter = iter(train_dl) # 將資料集中若干圖片展示在tensorboard中
images, labels = dataiter.next()
# create grid of images
img_grid = tv.utils.make_grid(images) # make_grid的作用是將若干幅影象拼成一幅影象。其中padding的作用就是子影象與子影象之間的pad有多寬
# write to tensorboard
writer.add_image('four_fashion_mnist_images', img_grid)
class CNN_Mnist(t.nn.Module):
def __init__(self):
super(CNN_Mnist, self).__init__()
self.cnn_layers = t.nn.Sequential(
t.nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, padding=1, stride=1),
t.nn.MaxPool2d(kernel_size=2, stride=2),
t.nn.ReLU(),
t.nn.Conv2d(in_channels=8, out_channels=32, kernel_size=3, padding=1, stride=1),
t.nn.MaxPool2d(kernel_size=2, stride=2),
t.nn.ReLU()
)
self.fc_layers = t.nn.Sequential(
t.nn.Linear(7*7*32, 200),
t.nn.ReLU(),
t.nn.Linear(200, 100),
t.nn.ReLU(),
t.nn.Linear(100, 10),
t.nn.LogSoftmax(dim=1)
)
def forward(self, x):
out = self.cnn_layers(x)
out = out.view(-1, 7*7*32)
out = self.fc_layers(out)
return out
def train_and_test():
model = CNN_Mnist().cuda()
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
loss = t.nn.CrossEntropyLoss()
optimizer = t.optim.Adam(model.parameters(), lr=1e-3)
writer.add_graph(model, images.cuda())
total = 0
correct_count = 0
for s in range(5):
m_loss = 0.0
print("run in epoch : %d" % s)
for i, (x_train, y_train) in enumerate(train_dl):
x_train = x_train.cuda()
y_train = y_train.cuda()
y_pred = model.forward(x_train)
train_loss = loss(y_pred, y_train)
m_loss += train_loss.item()
if (i + 1) % 100 == 0:
print(i + 1, train_loss.item())
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
writer.add_scalar('training/loss',
m_loss / 1000,
s * len(train_dl) + i)
count = 0
for test_images, test_labels in test_dl:
pred_labels = model(test_images.cuda())
predicted = t.max(pred_labels, 1)[1]
correct_count += (predicted == test_labels.cuda()).sum()
total += len(test_labels)
count += 1
writer.add_scalar('training/accuracy',
correct_count / total,
s * len(test_dl) + count)
t.save(model.state_dict(), './cnn_mnist_model_vis.pt')
model.eval()
total = 0
correct_count = 0
count = 0
for test_images, test_labels in test_dl:
pred_labels = model(test_images.cuda())
predicted = t.max(pred_labels, 1)[1]
correct_count += (predicted == test_labels.cuda()).sum()
total += len(test_labels)
writer.add_scalar('test/accuracy',
correct_count / total,
count)
count += 1
print("total acc : %.2f\n"%(correct_count / total))
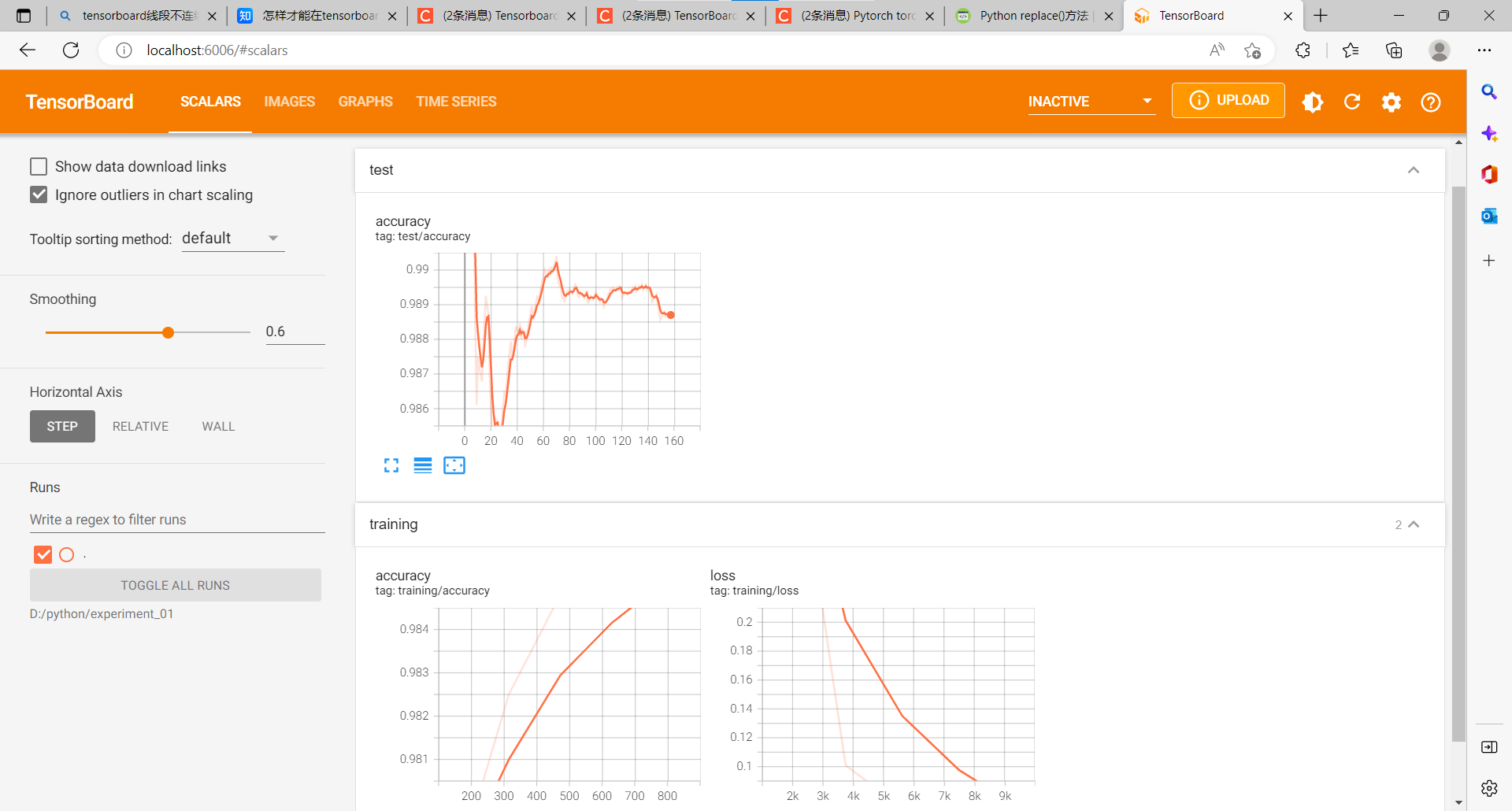
writer.close() # 使用完要關閉writer()
if __name__ == "__main__":
train_and_test()
效果: