RocketMQ Connect 構建流式資料處理平臺
本文作者:孫曉健,Apache RocketMQ Committer
01 RocketMQ Connect
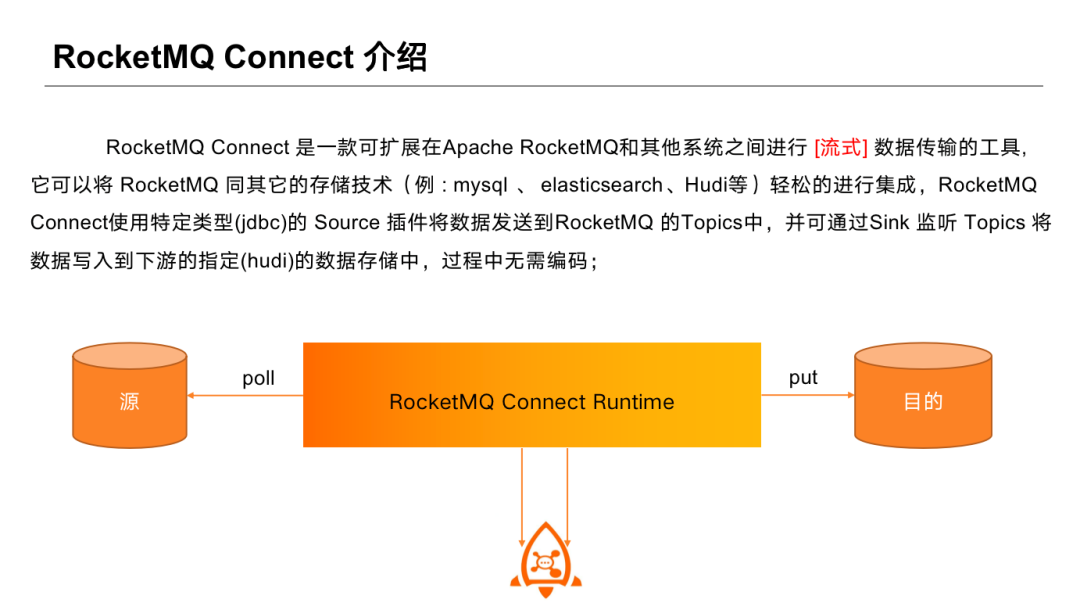
RocketMQ Connect 是一款可延伸的在 RocketMQ 與其他系統之間做流式資料傳輸的工具,能夠輕鬆將 RocketMQ 與其他儲存技術進行整合。RocketMQ Connect 使用特定的 Source 外掛型別,將資料傳送到 RocketMQ Topics 中,並通過 Sink 監聽 Topics 將資料寫到下游指定資料儲存中。使用過程中 Connector 可以通過 JSON 方式進行設定,無需編碼。資料流轉過程從源到目的,通過 RocketMQ 進行橋接。

RocketMQ Connect 具有以下特性:
①通用性:Connect 制定了標準 API,包括 Connector、Task、Converter、 Transform, 開發者可以通過標準 API 擴充套件自己外掛,達到自己需求。
②Offset 自動管理(斷點續傳):Source方面——使用者在開發 Connect 時,可以通過 Offset 進行增量資料拉取。系統內部會自動對 Offset 做管理,會將上次拉取 Offset 資訊進行持久化。下次任務重啟時,可以通過上次提交的 Offset 繼續進行資料增量拉取,無需從頭進行資料同步 ;Sink 方面——基於 RocketMQ 自身的 Offset 提交策略,在內部實現了自動提交方式,任務執行時會自動處理,允許使用者設定 Offset 提交間隔;如果系統自帶 offset 已經可以滿足需求,則無須另外維護 Offset;如果系統自帶 Offset 無法滿足需求,則可以通過 Task API 進行維護。Task API 中自帶 Offset 維護能力,可以在 Connect 中自行決定 Offset 持久化邏輯,比如持久化到 MySQL、Redis 中。下次任務啟動時,可以自動從 Offset 儲存位點獲取下一次執行 Offset ,繼續做增量拉取。
③分散式、可延伸、容錯:可以分散式的方式進行部署,自帶容錯能力。Worker 宕機或新增 Worker 時,任務會自動做重新分配、執行,在各叢集 Worker 之間做平衡。任務失敗後, 也會自動重試。重試完可自動 Rebalance 到不同 Worker 機器上。
④運維和監控:Connect 提供了標準的叢集管理功能,包括 Connect 管理功能以及外掛管理功能。可以通過 API 方式對任務做啟停操作,也可以檢視任務在執行過程中的執行狀態以及異常狀態。並且可以進行指標上報,任務在資料拉取與資料寫入後,資料總量、資料速率等都可以通過 Metrics方式做資料上報。此外,Metrics 也提供了標準的上報API ,可以基於標準 API 做指標擴充套件和上報方式的擴充套件,比如上報到 RocketMQ topic 中、Prometheus等。
⑤批流一體:Source 在做資料拉取時,可以通過 JDBC 或 指定外掛 sdk 的方式,做批次資料拉取,轉換為流方式,也可以使用 CDC 方式,通過 增量快照 或類 Mysql binlog 監聽方式獲取源端全量與增量變更資料,推給 RocketMQ,下游可以通過 Flink 或 RocketMQ Stream進行流式處理做狀態計算, 也可直接落到資料儲存引擎中,如 Hudi、 Elasticsearch、 Mysql 等 。
⑥Standalone、Distributed模式:Standalone 模式主要用於測試環境,Distributed模式主要用於生產環境。在試用過程中可以用 Standalone 方式做部署,得益於其不會做 Config 儲存,每次啟動時都可以帶獨立任務,幫助偵錯。

Connect 元件包含以下幾類:
- Connector:作為任務協調的高階抽象,描述了 Task 執行方式以及如何做 Task 拆分。
- Task:負責實際資料拉取操作,並負責 offset 的維護和 Task Metrics 資料的收集。
- Worker :執行 Task 任務的程序。
- Record Converter:在 Source與 Sink 之間做資料轉換,Record 通過 Schema 制定資料契約,Schema 可以隨資料傳輸, 也可以通過 RocketMQ Schema Registry進行遠端儲存,目前支援了 Avro 和 JSON 兩種型別的 Converter。
- Transform:資料傳輸過程中做資料轉換。如進行欄位變更、型別變更、做空值或已知錯誤值過濾等;還可以通過擴充套件 groovy transform 、python transform 等指令碼對資料進行復雜的轉換, 亦可做遠端呼叫來進行靜態資料的補全或做函數計算。
- Dead Letter Queue:在資料從 Source端到 Sink 端的過程中,資料 Convert 轉化錯誤、網路超時、邏輯錯誤造成寫入失敗等情況,可以根據自己編寫的外掛邏輯來決定是將資料寫入到錯誤佇列中、或忽略錯誤繼續進行、或出現錯誤後停止任務等。寫入錯誤佇列中的資料,在不計較資料有序的情況下可自助進行非同步修復後再寫入。
- Metrics:提高任務執行過程中的可觀測性,任務在資料拉取與資料寫入時,需要監測任務拉取的資料量、寫入資料量、拉取速率、寫入速率、差值、記憶體佔用等,都可以通過 Metrics 進行指標上報,供系統運營和運維使用。
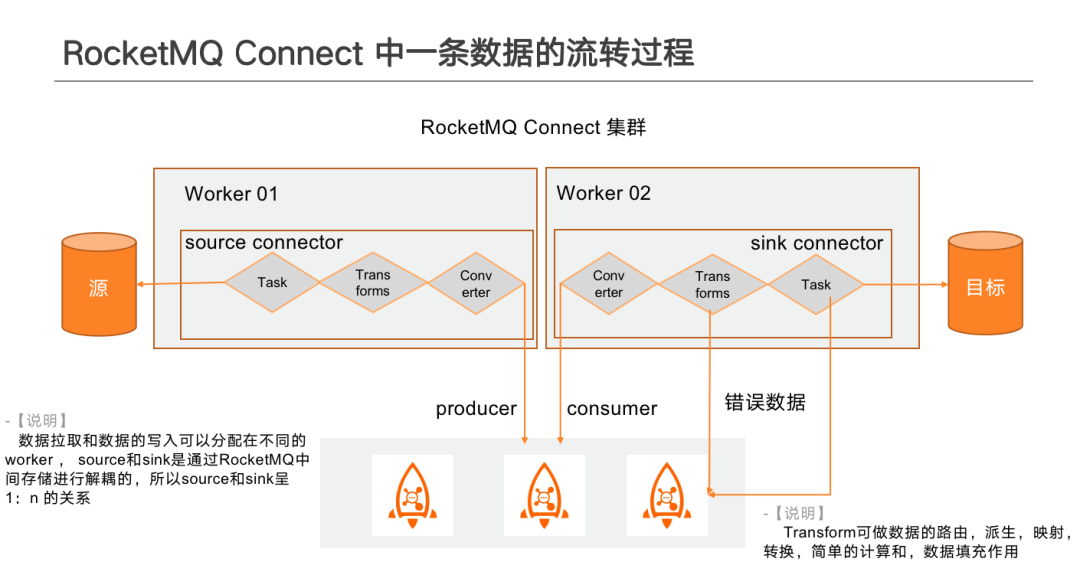
上圖為資料在 Connect 中的流轉過程。
分散式部署下,Source與 Sink 可以在不同 Worker中,不相互依賴,一個 Connector下可包含 Task、 Transform 、Converter 順序執行。Task 負責從源端拉取資料,Task並行數量由自定義外掛的分片方式決定。拉取到資料後,若中間設定了資料處理 Transform,資料會依次經過設定的一個或者多個 Transform 後,再將資料傳送給 Converter, Converter 會將資料進行重新組織成可傳輸的方式,若使用了 RocketMQ Schema Registry,則會進行 Schema 的校驗、註冊或升級,經過轉換後的資料,最終寫入至中間 Topic 中供下游 Sink 使用。下游 Sink 可以選擇性的監聽一個或者多個 Topic,Topic 中傳輸來的資料可以是相同儲存引擎中的,也可以是異構儲存引擎中的資料,資料在 Sink 轉換後,最終傳給流計算引擎或者直接寫入到目的儲存中。
在轉換過程中, Source Converter 與 Sink Converter 要保持一致。不同的 Converter 解析的 Schema 格式會有差異,若 Converter 不一致,會造成 Sink 解析資料的失敗。不同元件之間的差異化,可以通過自定義 Transform 來進行相容。
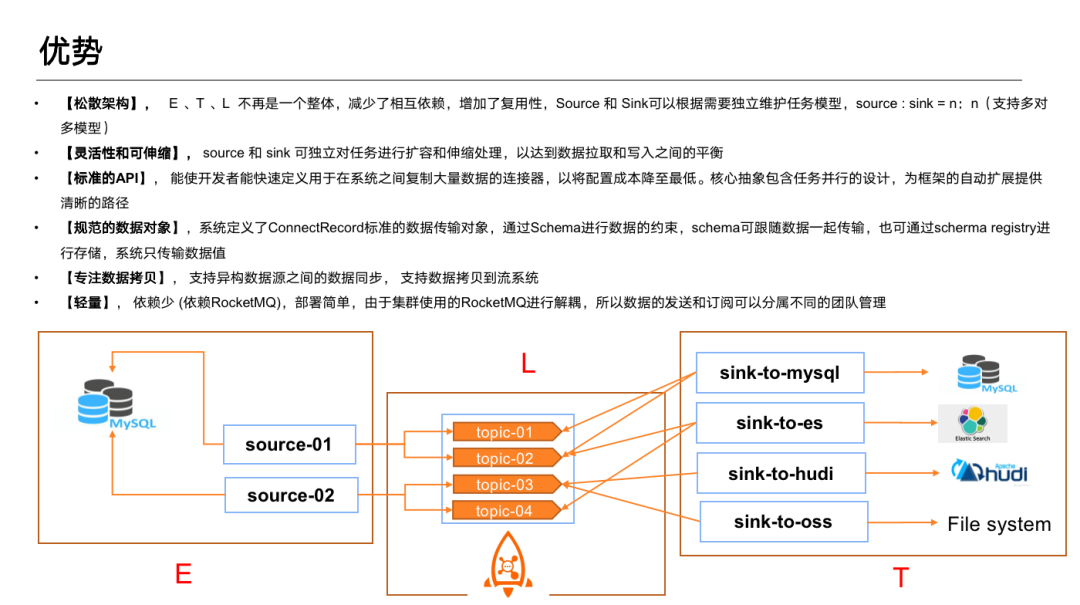
以上架構具有如下幾點優勢:
①鬆散架構:Source 與 Sink 之間通過 Topic 進行解耦,E、T、L 不再是一個整體。一般相同儲存引擎的資料的讀取和寫入QPS差距很大,所以一體化的 ETL 在資料的讀取時會受到目標庫寫入效能的制約。
而 RocketMQ Connect 中的 Source 和 Sink 解耦後, 可以做 Source 和 Sink 兩端獨立擴縮容,實現資料讀取和寫入的動態平衡,互不影響。
②標準 API:降低使用難度,擴充套件簡便,在 API 中抽象了編寫並行的具體方式,外掛開發者可自定義拆分。
③規範的資料抽象:使用 Topic 做解耦後,需要在 Source 和 Sink 之間建立資料契約。Connect 主要通過 Schema 進行資料約束。以此來支援異構資料來源之間的資料整合。
④專注資料拷貝:Connect 主要專注於與異構資料來源之間的資料整合,不做流計算,支援資料拷貝到流(Flink、 RocketMQ Stream)系統中,再做流計算。
⑤輕量:依賴少。如果叢集中已有 RocketMQ 叢集,可以直接部署 RocketMQ Connect做資料同步工作,部署非常簡單,無需額外部署排程元件。RocketMQ Connect 自帶任務分配元件,無需額外關注。
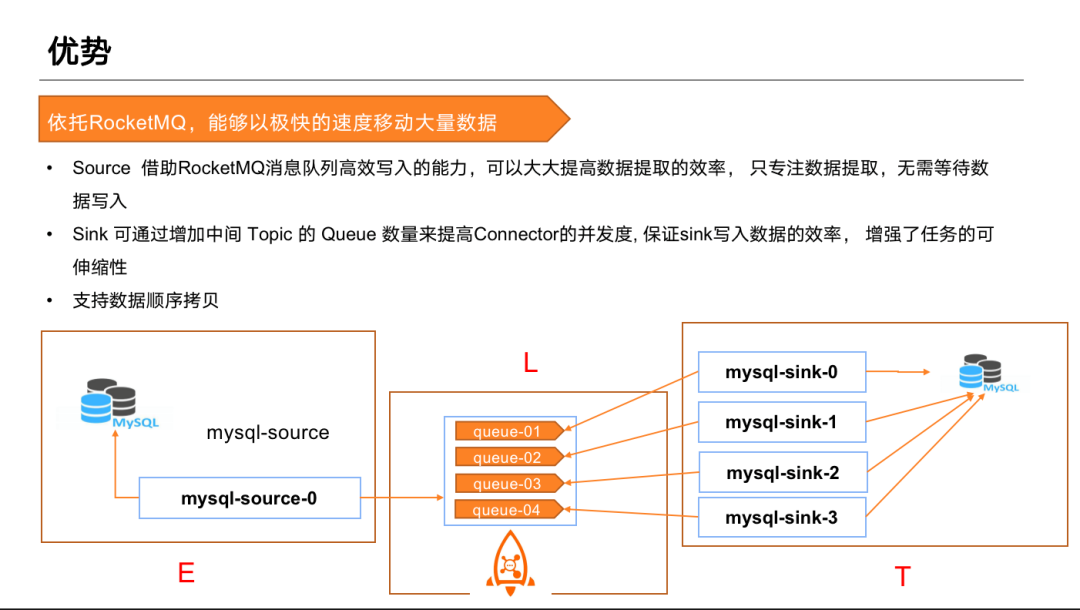
另外,依託 RocketMQ 強大的效能,可以在不同系統之間做大規模資料的遷移。Source 主要依賴於 RocketMQ 的寫入能力,無需等待事務尾端資料寫入。Sink 依託於 Topic 的擴充套件能力,可以根據中間 Topic 的分割區數量來決定下游 Sink 並行度,自動做擴充套件。任務做完擴充套件後,系統會對 Connector 進行重新分配 , 保證負載均衡,Offset 不會丟,可以基於上次執行狀態繼續向下執行,無需人工干預。也可以依賴 RocketMQ 的有序策略來做順序資料的同步。
02 RocketMQ Connect原理
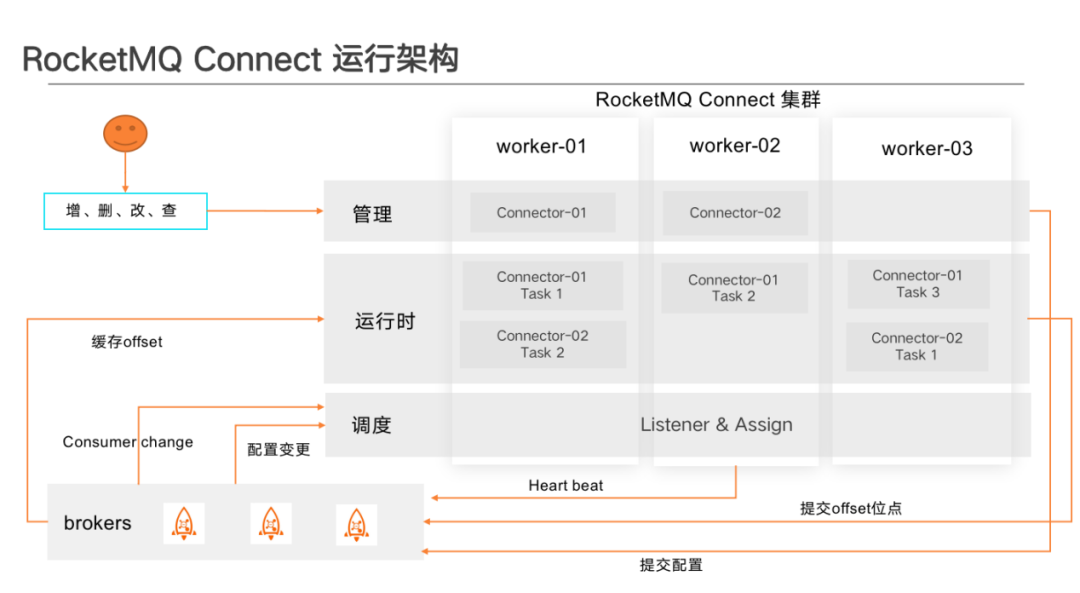
管理區 -- 主要做任務設定變更或查詢的接收, 包括建立、刪除、更新、啟停和檢視Connector 等操作。變更任務後,管理端會將任務提交到 RocketMQ 共用設定的 Topic 中。因為每一個 Worker 都監聽了相同 Topic ,所以每個 Worker 都能獲取 Config 資訊,然後觸發叢集 Rebalance 再重新做任務分配,最終達到全域性任務平衡。
執行時區--主要為已經被分配到當前 Worker 的 Task 提供執行空間。包括任務的初始化、資料拉取、Offset維護、任務啟停狀態上報、 Metrics 指標上報等。
排程區 -- Connect 自帶任務分配排程工具,通過 hash 或 一致性 hash 在 Worker 間進行任務平衡,主要監聽 Worker 和 Connector 的變更。比如 Worker 新增或刪除、 Connector 設定變更、任務啟停等。獲取狀態變更用來更新本地任務狀態,並決定是否進行下一輪 Rebalance 操作,以達到整個叢集的負載均衡。
管理端、執行時區與排程區存在每個叢集的每個 Worker 中,叢集 Worker 間通訊主要通過共用 Topic 來進行通知 ,Worker 之間無主節、備節點之分,這讓叢集運維起來非常的方便,只需要在 Broker 中建對應共用 Topic 即可,但由於 Task 狀態變化的動作只會發生在一個 Worker 中,叢集之間共用會存在短暫延遲,所以通過 Rest Api 查詢 Connector 狀態時可能會出現短暫不一致的現象。
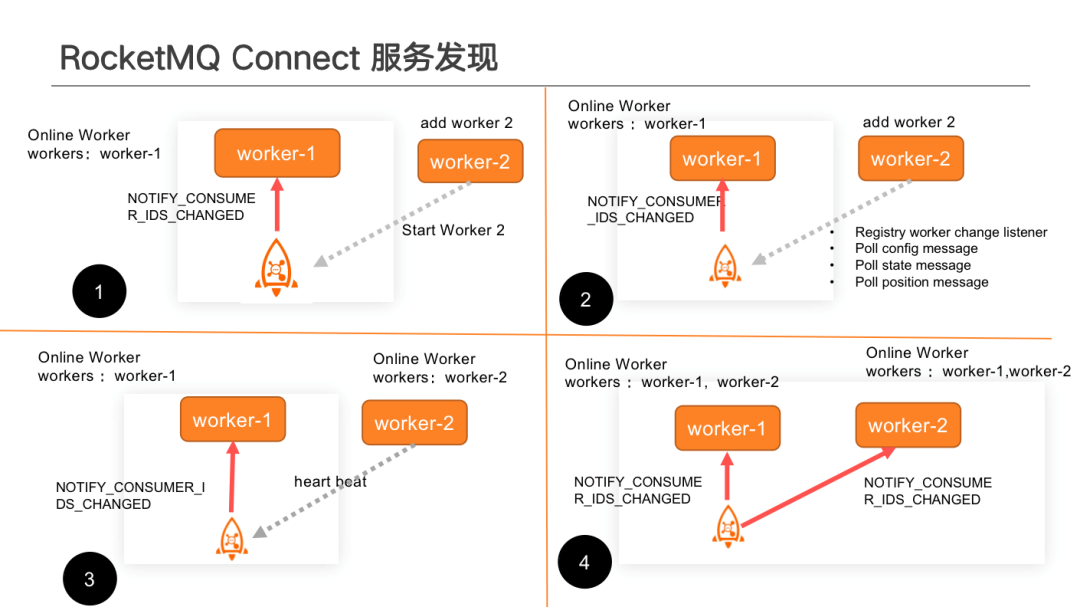
服務發現過程。有變更時,每一個 Worker 都可以發現節點變更,實現服務自動發現的效果。
①啟動新的 Worker 時, Worker 會向依賴的 RocketMQ Topic 註冊使用者端變更監聽。相同的 Consumer Group,當有新使用者端新增時,註冊了該事件的使用者端會收到變更通知, Worker 收到變更事件後,會主動更新當前叢集的 Worker 列表。
②當 Worker 宕機或者縮容時也會產生相同的效果。
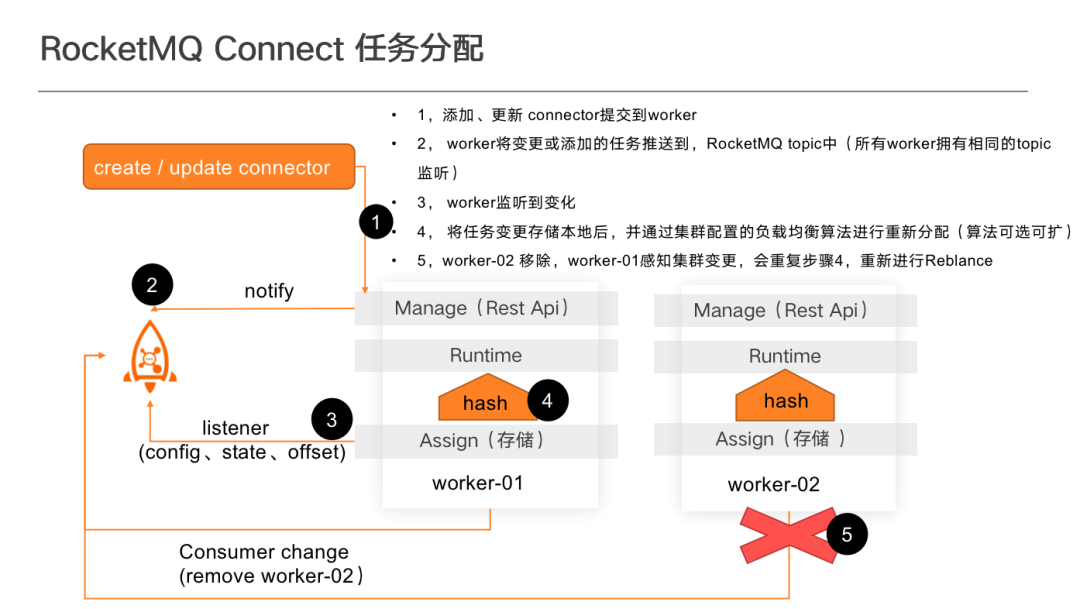
RocketMQ Connect 任務分配流程如下:
通過呼叫 Rest API 方式建立 Connector 。如果 Connector 不存在,則自動進行建立,若存在則更新。建立後,會向 Config Topic 傳送通知,通知 Worker 有任務變更。Worker 獲取任務變更後,再進行重新分配,以達到負載均衡的效果。停止任務也會產生相同的效果, 目前每個 Worker 都會儲存全量的任務及狀態, 但只執行分配給當前 Worker 的 Task。
目前系統預設提供了簡單 hash 或 一致性 hash 兩種任務分配模式,建議選擇一致性 hash 模式。因為在一致性 hash 情況下,做 Rebalance 時變更比普通 hash 變更範圍小,部分已經被分配好的任務不會再進行負載。
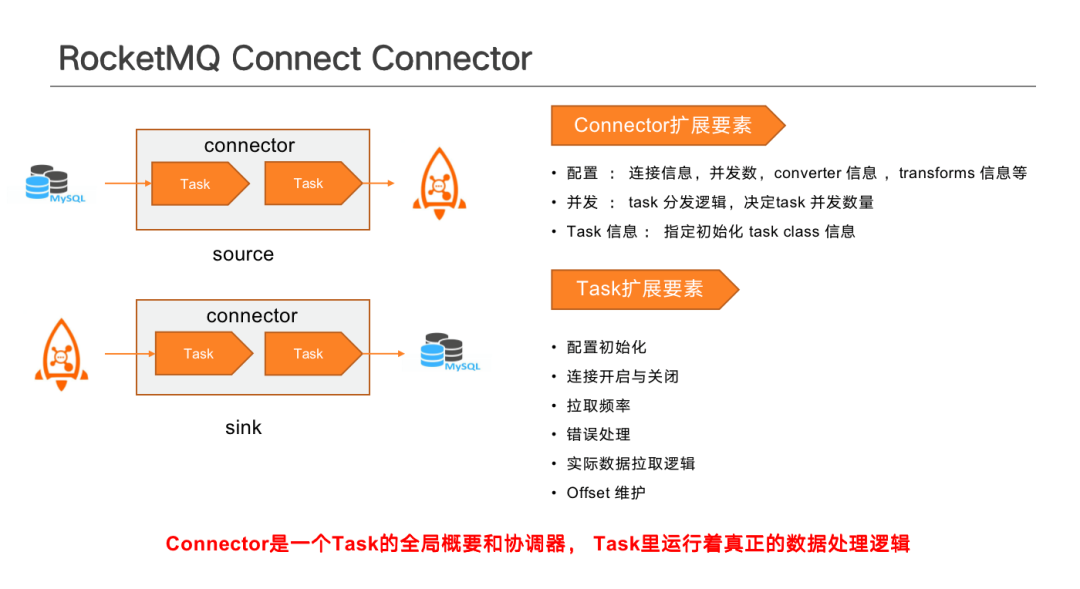
Connector 擴充套件要素分為自定義設定、並行和 Task 資訊。
自定義設定包含連線資訊(核心設定項)、Convertor 資訊、Transform資訊等。Connector 僅作為任務全域性概要和協調器,實際產生效果的依然是分配後的 Task。比如 1 億資料分為多個任務拉取,分別放在不同 Task 中執行,因此需要通過 Connector 去按照合理的邏輯做 Task 的拆分, 這些拆分的操作需要在宣告 Connector 時制定。Connecor 將設定拆分後,將實際資料拉取邏輯設定告知 Task , Task 決定資料拉取的具體方式。
Task 擴充套件要素包括設定初始化、連線開啟與關閉、拉取頻率、錯誤處理、實際資料拉取邏輯以及 Offset 維護。
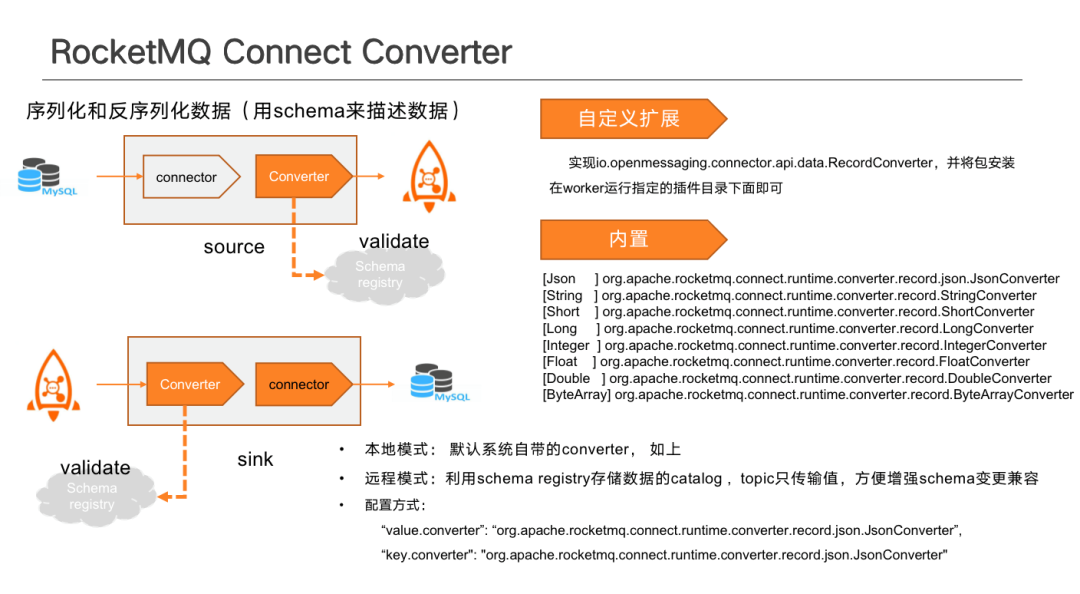
整個系統中全域性 Converter 轉換都使用同一套 API,分為兩種模式:
本地模式:從 Source Connect 拉取到資料後,由 Converter 做資料轉換。轉換過程中,本地操作會將 Schema 與 value 值合併為 Connect record 向下遊傳遞。下游通過相同 Converter 再將其轉換為 Record ,推給 Sink task 做資料寫入。中間通過 Convert Schema 做了資料契約,可以在 Source與 Sink 之間轉換。本地模式下,Schema與 Value 作為一個整體傳輸,資料 Body 非常臃腫,每一條資料都帶有 Schema資訊。但其優點為不存在版本相容問題。
遠端模式:在資料轉換時,會將 Schema 存到遠端 RocketMQ Schema Registry 系統中,在資料傳輸過程中只帶 Value 值,不帶 Schema 約束資訊。當 Sink 訂閱 Topic時,通過資訊頭帶有的 Record ID 獲取 Schema 資訊、進行 Schema 校驗,校驗後再做資料轉換。
Schema 維護在 RocketMQ Schema Registry 系統中。因此在轉換過程中可以在系統中手工更新 Schema,然後用指定的 SchemaID 做轉換,但是需要在 Converter 外掛中做資料相容。
Connect Converter 內建了擴充套件,有原生的 JSON 、普通資料型別 Converter 等。如果內建擴充套件無法滿足需求,可以通過 Record Converter API 自己進行擴充套件。擴充套件後,將 Converter 包置於 Worker 執行外掛目錄下,系統即可自動載入。
設定方式分為 Key 和 Value 兩種。其中 Key 標註資料的唯一,也可以是 Struct 結構化資料;Value 是真實傳輸的資料。
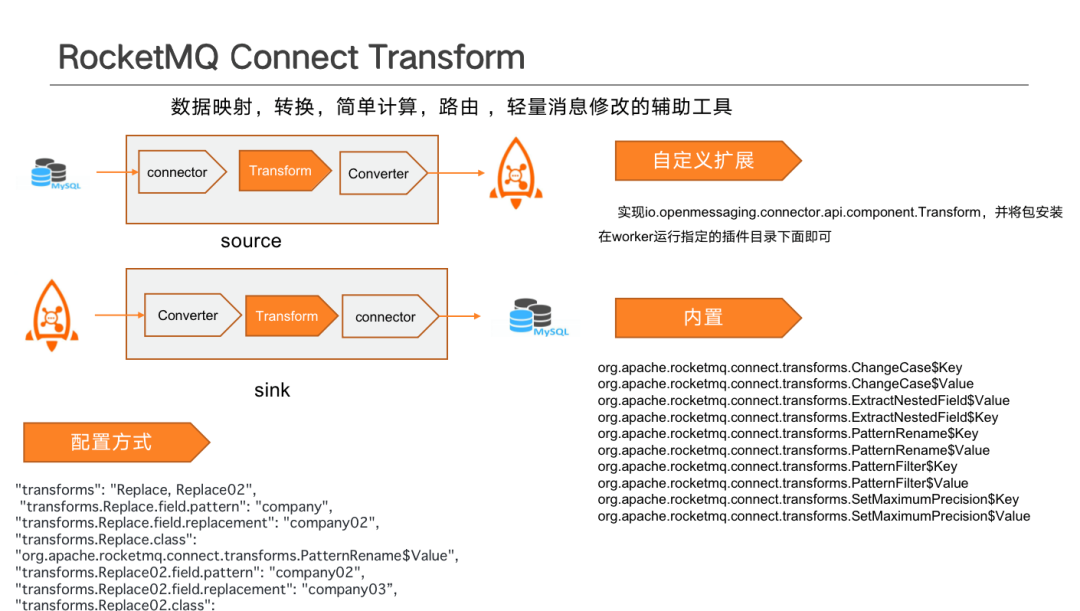
Transform 是在 Connector 與 Convertor 之間做資料對映轉換與簡單計算的輔助工具。當 Source Converter 與 Sink Connector 在使用過程中達不到業務需求時,可以通過編寫 Transform 外掛的方式做資料適配。比如不同業務、不同資料來源外掛之間的資料轉換,如欄位對映、 欄位派生、 型別轉換、 欄位補全、複雜函數計算等。
系統中內建的 Transform 模式有比如欄位擴充套件 、 替換等。如果不滿足需求,可以通過 API 自行擴充套件 Transform。部署時,只需將編寫後的擴充套件打好包放置對應外掛目錄下,即可自動載入。
具體設定方式如上圖左下方所示,Transform 的執行為序列,可以對一個值做多個轉換,可以設定多個 Transform。需要設定多個 Transform 的情況下,通過逗號進行分隔,名稱不能重複。
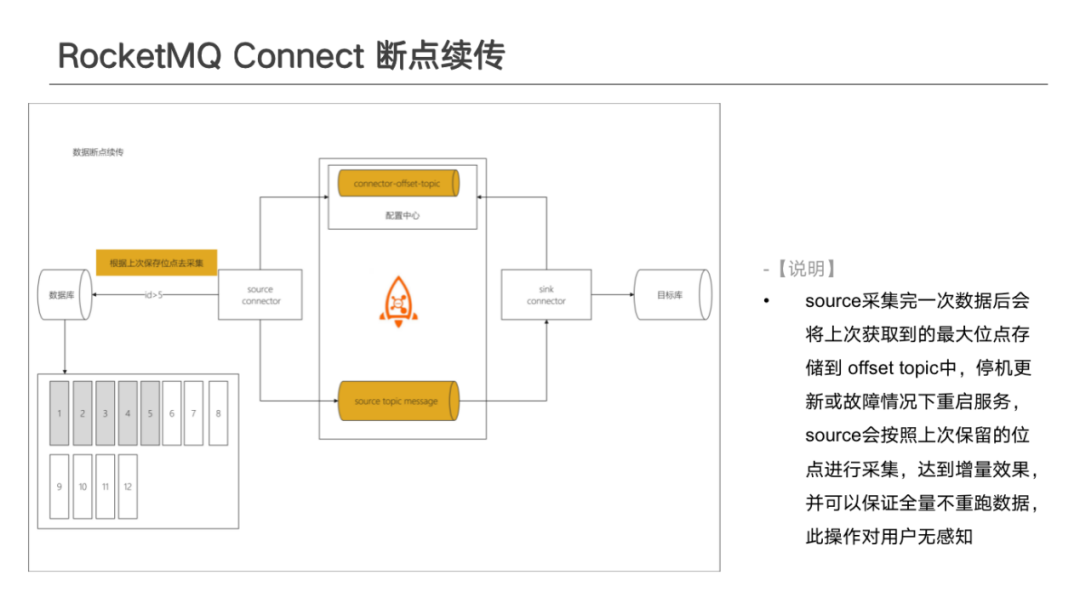
Source Task 做資料拉取或變更監聽時,例如,通過 JDBC Mysql 方式做資料增量拉取時,需要指定 Offset 增量拉取的方式,可以通過自增 ID 或 Modify time 的方式。每次資料拉取完成傳送成功後,會向 Offset writer 中提交增量資訊(id 或者 modify time),系統會非同步進行持久化。任務下次啟動時 ,會自動獲取 Offset,從上次位點開始處理資料,達到斷點續傳的效果。
封裝 Offset 時沒有固定模式,可以通過自己的方式拼接 Offset key 或 value 值,唯一依賴的是 RocketMQ 中的 Connect offset topic 資訊,主要為推播給其他 worker 做本地 Offset 更新。如果使用系統的 Offset 維護,則使用者只需要決定維護上報邏輯,無需關注如何保證 Offset 提交、Offset 回滾模式等,一切都由系統保證。
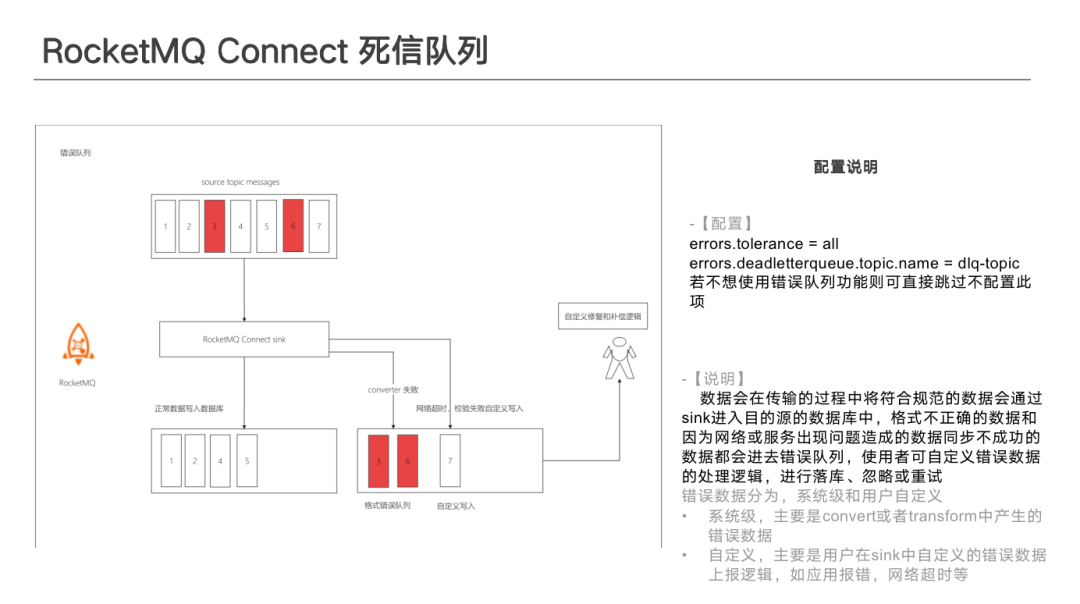
執行過程中,若開啟了死信佇列,正確的資料會輸送到目的端,錯誤資料會輸送到錯誤佇列中。業務方可以通過非同步方式做資料處理,但是該種情況下無法保證有序。如果要保證資料有序,需要在觸發報錯的情況下將 Task 停止,先進行資料修復,修復後再啟動 Task。
如果單個 Task 處理資料包錯,只需停止出錯的 Task,其他 Task 不受影響。因為每個Task 在處理資料時消費的 Query 不一樣,如果指定了Key,會按照 Key 做資料分割區,然後保證分割區內每個 Query 有序,因此單個 Task 停止不會影響全域性有序性。
03 RocketMQ Connect使用場景
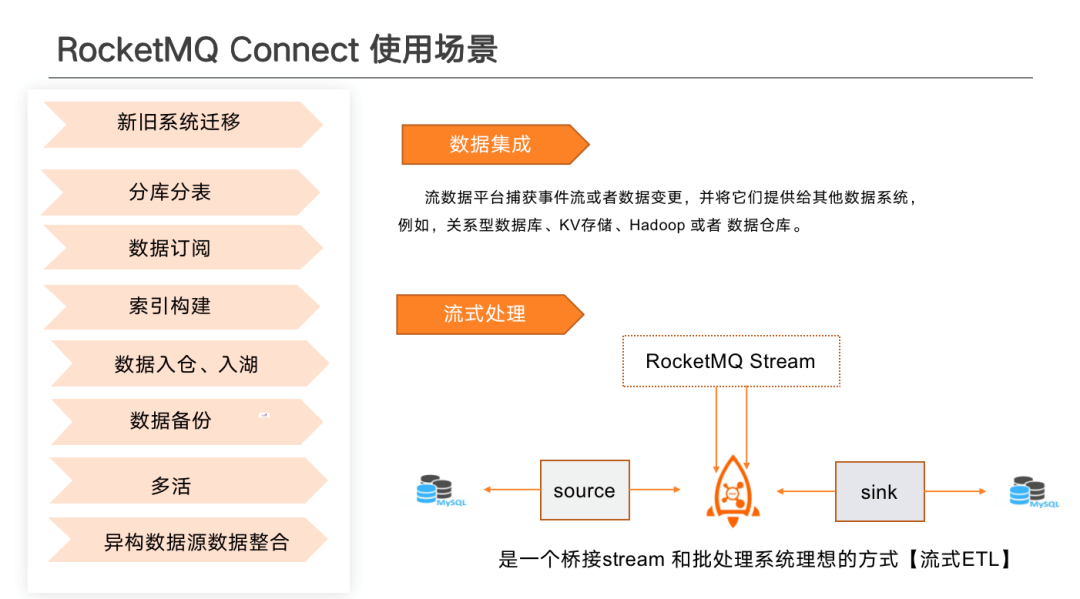
RocketMQ Connect 能夠適用於大部分傳統 ETL 適用的場景。另外,傳統 ETL無法實現的比如實時流傳輸、流批一體、快照功能等,RocketMQ Connect 亦能夠實現。
新舊系統遷移場景:業務部升級變更過程中出現了型別變更、表拆分或擴容操作、新增索引的情況下可能導致停機耗時非常久,可以通過 RocketMQ Connect 做資料重新搬遷。
分庫分表場景:當前市面上有很多分庫分表外掛,可以通過 Connect 適配開源分庫分表使用者端做分庫分表工作,也可以基於 RocketMQ 自己做分庫分表邏輯,源端與目的端不變。資料從單表中取出後,可以在 Transform 中做分庫分表邏輯。可以通過 Transform 做路由。路由到不同 Topic 中,在下游可以通過監聽不同 Topic 落到已經分好的庫表中。
多活:RocketMQ Connect 支援叢集間 Topic 及後設資料的拷貝,可保證多中心的 Offset 一致。
資料訂閱場景:通過 CDC 模式做資料監聽,向下遊做資料通知。供下游做資料訂閱以及即時資料更新。同時也可以將資料拉取後通過 HTTP 的方式直接推播到下游業務系統中,類似於 Webhook 的方式,但是需要對請求做驗權、限流等。
其次,還有資料入倉入湖、冷資料備份、異構資料來源資料整合等業務場景都可以通過RocketMQ Connect 作為資料處理方案
從整體使用場景來看,大致可以分為兩部分,資料整合和流式處理。資料整合主要為將資料從一個系統搬到另一個系統,可以在異構資料來源中進行資料同步。流式處理主要為將批次處理資訊通過批次資料拉取,或 CDC 模式將增量資料同步到對應流處理系統中,做資料聚合、視窗計算等操作,最終再通過 Sink 寫入到儲存引擎中。
04 RocketMQ Connect生態
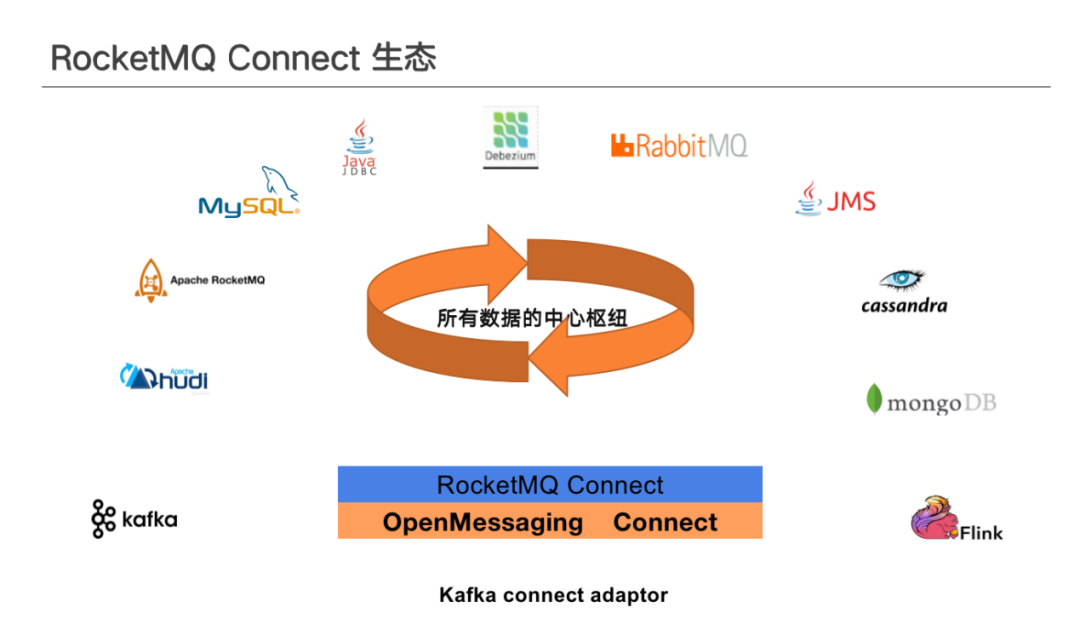
RocketMQ Connect 目前對上圖中產品均能夠提供支援,平臺也提供了 Kafka Connect 外掛的適配。