二階段目標檢測網路-Faster RCNN 詳解
本文為學習筆記,部分內容參考網上資料和論文而寫的,內容涉及
Faster RCNN網路結構理解和程式碼實現原理。
Faster RCNN 網路概述
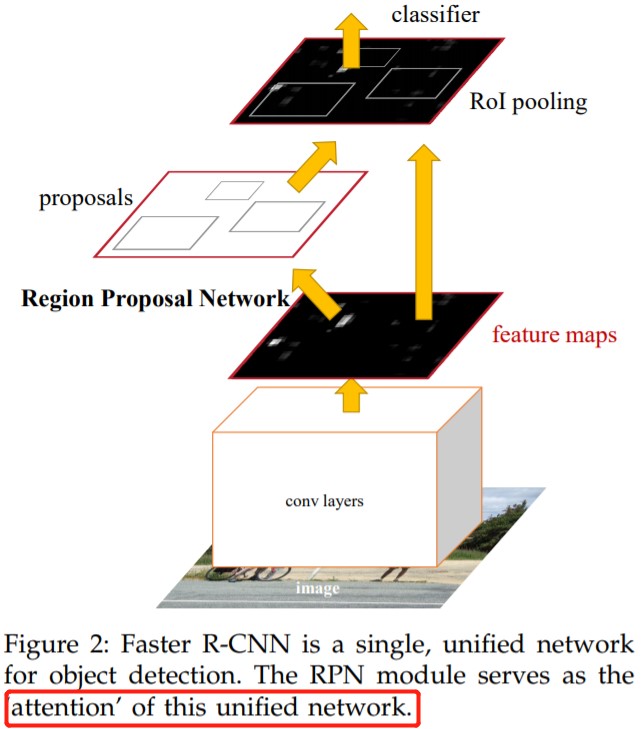
backbone 為 vgg16 的 faster rcnn 網路結構如下圖所示,可以清晰的看到該網路對於一副任意大小 PxQ 的影象,首先縮放至固定大小 MxN,然後將 MxN 影象送入網路;而 Conv layers 中包含了 13 個 conv 層 + 13 個 relu 層 + 4 個 pooling 層;RPN 網路首先經過 3x3 折積,再分別生成 positive anchors 和對應 bounding box regression 偏移量,然後計算出 proposals;而 Roi Pooling 層則利用 proposals 從 feature maps 中提取 proposal feature 送入後續全連線和 softmax 網路作 classification(即分類: proposal 是哪種 object)。
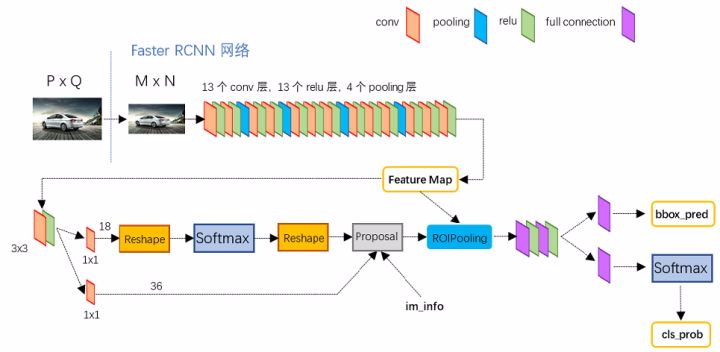
Conv layers
論文中
Faster RCNN雖然支援任意圖片輸入,但是進入Conv layers網路之前會對圖片進行規整化尺度操作,如可設定影象短邊不超過 600,影象長邊不超過 1000,我們可以假定 \(M\times N=1000\times 600\)(如果圖片少於該尺寸,可以邊緣補 0,即影象會有黑色邊緣)。
13個conv層:kernel_size=3, pad=1, stride=1,折積公式:N = (W − F + 2P )/S+1,所以可知conv層不會改變圖片大小13個relu層: 啟用函數,增加非線性,不改變圖片大小4個pooling層:kernel_size=2,stride=2,pooling層會讓輸出圖片變成輸入圖片的 1/2。
所以經過 Conv layers,圖片大小變成 \((M/16) \ast (N/16)\),即:\(60\ast 40(1000/16≈60,600/16≈40)\);則 Feature Map 尺寸為 \(60\ast 40\ast 512\)-d (注:VGG16 是512-d, ZF 是 256-d,d 是指特徵圖通道數,也叫特徵圖數量),表示特徵圖的大小為 \(60\ast 40\),數量為 512。
RPN 網路
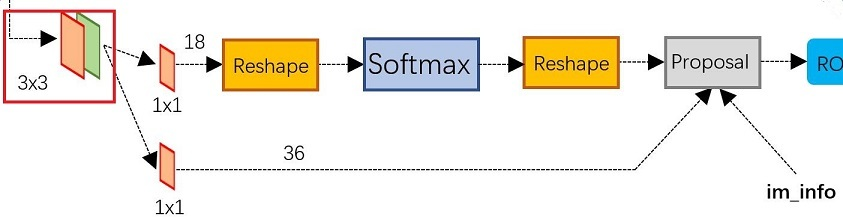
RPN 在 Extractor(特徵提取 backbone )輸出的 feature maps 的基礎之上,先增加了一個 3*3 折積(用來語意空間轉換?),然後利用兩個 1x1 的折積分別進行二分類(是否為正樣本)和位置迴歸。RPN 網路在分類和迴歸的時候,分別將每一層的每一個 anchor 分為背景和前景兩類,以及迴歸四個位移量,進行分類的折積核通道數為9×2(9 個 anchor,每個 anchor 二分類,使用交叉熵損失),進行迴歸的折積核通道數為 9×4(9個anchor,每個 anchor 有 4 個位置引數)。RPN是一個全折積網路(fully convolutional network),這樣對輸入圖片的尺寸就沒有要求了。
RPN 完成 positive/negative 分類 + bounding box regression 座標迴歸兩個任務。
Anchors
在RPN中,作者提出了anchors,在程式碼中,anchors 是一組由 generate_anchors.py 生成的矩形框列表。執行官方程式碼的 generate_anchors.py 可以得到以下範例輸出.這裡生成的座標是在原圖尺寸上的座標,在特徵圖上的一個畫素點,可以對應到原圖上一個 \(16\times 16\)大小的區域。
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
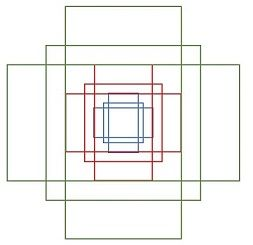
其中每行的 4 個值 \((x_{1}, y_{1}, x_{2}, y_{2})\) 表矩形左上和右下角點座標。9 個矩形共有 3 種形狀,長寬比為大約為 \(width:height \epsilon \{1:1, 1:2, 2:1\}\) 三種,如下圖。實際上通過 anchors 就引入了檢測中常用到的多尺度方法。
注意,
generate_anchors.py生成的只是 base anchors,其中一個 框的左上角座標為 (0,0) 座標(特徵圖左上角)的 9 個 anchor,後續還需網格化(meshgrid)生成其他 anchor。同一個 scale,但是不同的 anchor ratios 生成的 anchors 面積理論上是要一樣的。
然後利用這 9 種 anchor 在特徵圖左右上下移動(遍歷),每一個特徵圖上的任意一個點都有 9 個 anchor,假設原圖大小為 MxN,經過 Conv layers 下取樣 16 倍,則每個 feature map 生成 (M/16)*(N/16)*9個 anchor。例如,對於一個尺寸為 62×37 的 feature map,有 62×37×9 ≈ 20000 個 anchor,並輸出特徵圖上面每個點對應的原圖 anchor 座標。這種做法很像是暴力窮舉,20000 多個 anchor,哪怕是蒙也能夠把絕大多數的 ground truth bounding boxes 蒙中。
因此可知,anchor 的數量和 feature map 大小相關,不同的 feature map 對應的 anchor 數量也不一樣。
生成 RPN 網路訓練集
在這個任務中,RPN 做的事情就是利用(AnchorTargetCreator)將 20000 多個候選的 anchor 選出 256 個 anchor 進行分類和迴歸位置。選擇過程如下:
- 對於每一個 ground truth bounding box (
gt_bbox),選擇和它重疊度(IoU)最高的一個anchor作為正樣本; - 對於剩下的 anchor,從中選擇和任意一個 gt_bbox 重疊度超過
0.7的 anchor ,同樣作為正樣本;特殊情況下,如果正樣本不足128(256 的 1/2),則用負樣本湊。 - 隨機選擇和
gt_bbox重疊度小於0.3的 anchor 作為負樣本。
本和正樣本的總數為256,正負樣本比例1:1。
positive/negative 二分類
由 \(1\times 1\) 折積實現,折積通道數為 \(9\times 2\)(每個點有 9 個 anchor,每個 anchor 二分類,使用交叉熵損失),後面接 softmax 分類獲得 positive anchors,也就相當於初步提取了檢測目標候選區域 box(一般認為目標在 positive anchors 中)。所以可知,RPN 的一個任務就是在原圖尺度上,設定了大量的候選 anchor,並通過 AnchorTargetCreator 類去挑選正負樣本比為 1:1 的 256 個 anchor,然後再用 CNN (\(1\times 1\) 折積,折積通道數 \(9\times 2\)) 去判斷挑選出來的 256 個 anchor 哪些有目標的 positive anchor,哪些是沒目標的 negative anchor。
在挑選 1:1 正負樣本比例的 anchor 用作 RPN 訓練集後,還需要計算訓練集資料對應的標籤。對於每個 anchor, 對應的標籤是 gt_label 和 gt_loc。gt_label 要麼為 1(前景),要麼為 0(背景),而 gt_loc 則是由 4 個位置引數 \((t_x,t_y,t_w,t_h)\) 組成,它們是 anchor box 與 ground truth bbox 之間的偏移量,因為迴歸偏移量比直接回歸座標更好。在 Faster RCNN原文,positive anchor 與 ground truth 之間的偏移量 \((t_{x}, t_{y})\) 與尺度因子 \((t_{w}, t_{h})\) 計算公式如下:
引數解釋:where \(x, y, w,\) and \(h\) denote the box’s center coordinates and its width and height. Variables \(x, x_{a}\),and \(x^{*}\) are for the predicted box, anchor box, and groundtruth box respectively (likewise for \(y, w, h\)).
計算分類損失用的是交叉熵損失,計算迴歸損失用的是 Smooth_L1_loss。在計算迴歸損失的時候,只計算正樣本(前景)的損失,不計算負樣本的位置損失。RPN 網路的 Loss 計算公式如下:
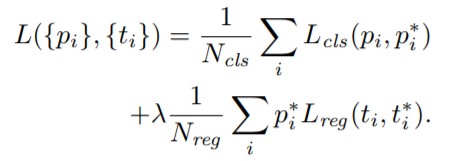
公式解釋:Here, \(i\) is the index of an anchor in a mini-batch and \(p_{i}\) is the predicted probability of anchor i being an object. The ground-truth label \(p_i^{\ast}\) is 1 if the anchor is positive, and is 0 if the anchor is negative. \(t_{i}\) is a vector representing the 4 parameterized coordinates of the predicted bounding box, and \(t_i^*\) is that of theground-truth box associated with a positive anchor.
RPN 生成 RoIs(Proposal Layer)
RPN 網路在自身訓練的同時,還會由 Proposal Layer 層產生 RoIs(region of interests)給 Fast RCNN(RoIHead)作為訓練樣本。RPN 生成 RoIs 的過程( ProposalCreator )如下:
- 對於每張圖片,利用它的
feature map, 計算(H/16)× (W/16)×9(大概 20000)個anchor屬於前景的概率,以及對應的位置引數,並選取概率較大的12000個 anchor; - 利用迴歸的位置引數,修正這
12000個anchor的位置,得到RoIs; - 利用非極大值((Non-maximum suppression, NMS)抑制,選出概率最大的
2000個RoIs。
在 RPN 中,從上萬個 anchor 中,選一定數目(2000 或 300),調整大小和位置生成
RoIs,用於 ROI Head/Fast RCNN 訓練或測試,然後ProposalTargetCreator再從RoIs中會中選擇128個RoIs用以 ROIHead 的訓練)。
注意:RoIs 對應的尺寸是原圖大小,同時在 inference 的時候,為了提高處理速度,12000 和 2000 分別變為 6000 和 300。Proposal Layer 層,這部分的操作不需要進行反向傳播,因此可以利用 numpy/tensor 實現。
RPN 網路總結
- RPN 網路結構:生成 anchors -> softmax 分類器提取 positvie anchors -> bbox reg 迴歸 positive anchors -> Proposal Layer 生成 proposals
- RPN 的輸出:
RoIs(region of interests)(形如2000×4或者300×4的tensor)
ROIHead/Fast R-CNN
RPN 只是給出了 2000 個 候選框,RoI Head 在給出的 2000 候選框之上繼續進行分類和位置引數的迴歸。ROIHead 網路包括 RoI pooling + Classification(全連線分類)兩部分,網路結構如下:
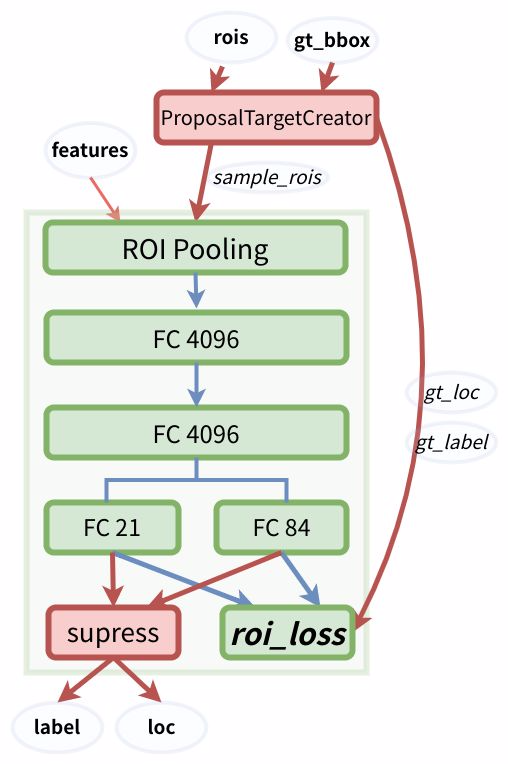
由於 RoIs 給出的 2000 個 候選框,分別對應 feature map 不同大小的區域。首先利用 ProposalTargetCreator 挑選出 128 個 sample_rois, 然後使用了 RoI Pooling 將這些不同尺寸的區域全部 pooling 到同一個尺度 \(7\times 7\) 上,並輸出 \(7\times 7\) 大小的 feature map 送入後續的兩個全連線層。兩個全連線層分別完成類別分類和 bbox 迴歸的作用:
FC 21用來分類,預測RoIs屬於哪個類別(20個類+背景)FC 84用來回歸位置(21個類,每個類都有4個位置引數)
論文中之所以設定為 pooling 成 7×7 的尺度,其實是為了網路輸出是固定大小的
vector or matrix,從而能夠共用 VGG 後面兩個全連線層的權重。當所有的 RoIs 都被pooling 成(512×7×7)的 feature map 後,將它 reshape 成一個一維的向量,就可以利用 VGG16 預訓練的權重來初始化前兩層全連線(FC 4096)。
Roi pooling
RoI pooling 負責將 128 個 RoI 區域對應的 feature map 進行擷取,而後利用 RoI pooling 層輸出 \(7\times 7\) 大小的 feature map,送入後續的全連線網路。從論文給出的 Faster R-CNN 網路結構圖中,可以看到 Rol pooling 層有 2 個輸入:
- 原始的
feature maps RPN輸出的RoIs(proposal boxes, 大小各不相同)
RoI Pooling 的兩次量化過程:
(1) 因為 proposals是對應 \(M\times N\) 的原圖尺寸,所以在原圖上生成的 region proposal 需要對映到 feature map 上(座標值縮小 16 倍),需要除以 \(16/32\)(下取樣倍數),這時候邊界會出現小數,自然就需要量化。
(2) 將 proposals 對應的 feature map 區域水平劃分成 \(k\times k\) (\(7\times 7\)) 的 bins,並對每個 bin 中均勻選取多少個取樣點,然後進行 max pooling,也會出現小數,自然就產生了第二次量化。
Mask RCNN 演演算法中的 RoI Align 如何改進:
ROI Align 並不需要對兩步量化中產生的浮點數座標的畫素值都進行計算,而是設計了一套優雅的流程。如下圖,其中虛線代表的是一個 feature map,實線代表的是一個 roi (在這個例子中,一個 roi 是分成了 \(2\times 2\) 個 bins),實心點代表的是取樣點,每個 bin 中有 4 個取樣點。我們通過雙線性插值的方法根據取樣點周圍的四個點計算每一個取樣點的值,然後對著四個取樣點執行最大池化操作得到當前 bin 的畫素值。
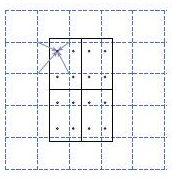
RoI Align 具體做法:假定取樣點數為 4,即表示,對於每個 \(2.97\times 2.97\) 的 bin,平分四份小矩形,每一份取其中心點位置,而中心點位置的畫素,採用雙線性插值法進行計算,這樣就會得到四個小數座標點的畫素值。
更多細節內容可以參考 RoIPooling、RoIAlign筆記。
ROI Head 訓練
RPN 會產生大約 2000 個 RoIs ,ROI Head 在給出的 2000 個 RoIs 候選框基礎上繼續分類(目標分類)和位置引數迴歸。注意,這 2000 個 RoIs 不是都拿去訓練,而是利用 ProposalTargetCreator(官方原始碼可以檢視類定義) 選擇 128 個 RoIs 用以訓練。選擇的規則如下:
- 在和
gt_bboxes的IoU大於0.5的RoIs內,選擇一些(比如32個)作為正樣本 - 在和
gt_bboxes的IoU小於等於0(或者0.1)RoIs內,的選擇一些(比如 \(128 - 32 = 96\) 個)作為負樣本
選擇出的 128 個 RoIs,其正負樣本比例為 3:1,在原始碼中為了便於訓練,還對他們的 gt_roi_loc 進行標準化處理(減去均值除以標準差)。
- 對於分類問題, 和
RPN一樣,直接利用交叉熵損失。 - 對於位置的迴歸損失,也採用 Smooth_L1 Loss, 只不過只對正樣本計算損失,而且是隻對正樣本中的對應類別的 \(4\) 個引數計算損失。舉例來說:
- 一個
RoI在經過FC84後會輸出一個84維的loc向量。 如果這個RoI是負樣本, 則這84維向量不參與計算L1_Loss。 - 如果這個
RoI是正樣本,且屬於 類別 \(k\), 那麼向量的第 \((k×4,k×4+1 ,k×4+2, k×4+3)\) 這 \(4\) 位置的值參與計算損失,其餘的不參與計算損失。
- 一個
ROI Head 測試
ROI Head 測試的時候對所有的 RoIs(大概 300 個左右) 計算概率,並利用位置引數調整預測候選框的位置,然後再用一遍極大值抑制(之前在 RPN 的ProposalCreator 也用過)。這裡注意:
- 在
RPN的時候,已經對anchor做了一遍NMS,在Fast RCNN測試的時候,還要再做一遍,所以在Faster RCNN框架中,NMS操作總共有 2 次。 - 在
RPN的時候,已經對anchor的位置做了迴歸調整,在Fast RCNN階段還要對RoI再做一遍。 - 在
RPN階段分類是二分類,而Fast RCNN/ROI Head階段是21分類。
概念理解
在閱讀 Faster RCNN 論文和原始碼中,我們經常會涉及到一些概念的理解。
四類損失
在訓練 Faster RCNN 的時候有四個損失:
RPN分類損失:anchor是否為前景(二分類)RPN位置迴歸損失:anchor位置微調RoI分類損失:RoI所屬類別(21分類,多了一個類作為背景)RoI位置迴歸損失:繼續對RoI位置微調
四個損失相加作為最後的損失,反向傳播,更新引數。
三個 creator
Faster RCNN 官方原始碼中有三個 creator 類分別實現不同的功能,不能弄混,各自功能如下:
AnchorTargetCreator: 負責在訓練RPN的時候,從上萬個anchors中選擇一些(比如256)進行訓練,並使得正負樣本比例大概是1:1。同時給出訓練的位置引數目標,即返回gt_rpn_loc和gt_rpn_label。ProposalTargetCreator: 負責在訓練RoIHead/Fast R-CNN的時候,從RoIs選擇一部分(比如128個,正負樣本比例1:3)用以訓練。同時給定訓練目標, 返回(sample_RoI,gt_RoI_loc,gt_RoI_label)。ProposalCreator: 在RPN中,從上萬個anchor中,選擇一定數目(2000或者300),調整大小和位置,生成RoIs,用以Fast R-CNN訓練或者測試。
其中 AnchorTargetCreator 和 ProposalTargetCreator 類是為了生成訓練的目標,只在訓練階段用到,ProposalCreator 是 RPN 為 Fast R-CNN 生成 RoIs ,在訓練和測試階段都會用到。三個 creator 的共同點在於他們都不需要考慮反向傳播(因此不同框架間可以共用 numpy 實現)。