系統建設-資料遷移
隨著業務發展,我們的系統可能面臨著改造升級。改造過程中往往避免不了資料模型的變動,這時候需要將老表老模型遷移到新表新模型,並且還要保證歷史資料的遷移以及對映。
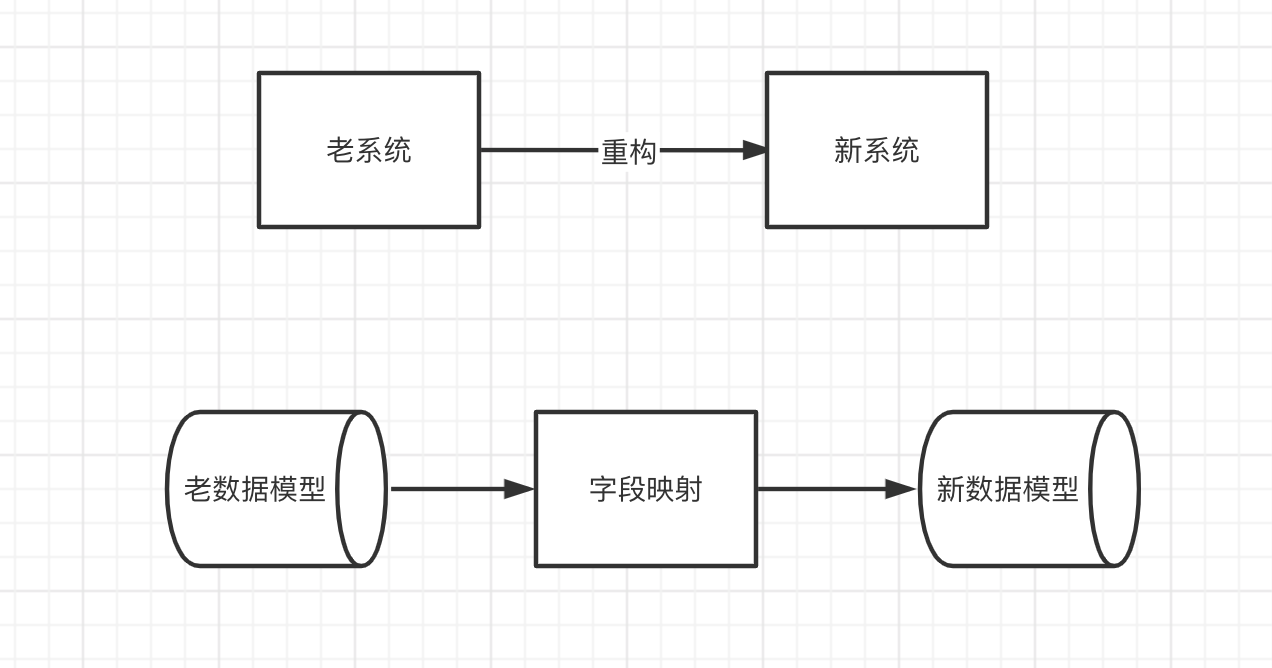
這就帶來了一個問題,老表老模型如何遷移到新表新模型,以下是常用的兩種方案
| 方案 | 是否支援回切 | 優點 | 缺點 |
|---|---|---|---|
| 雙寫 | 是 | 1.簡單易操作2.無需中介軟體支援3.無延遲 | 1.對業務侵入大,需要在新老系統維護對應的資料同步邏輯 |
| 監聽binlog,資料雙向同步 | 是 | 1.對業務0侵入2.方便客製化化邏輯 | 1.需要中介軟體支援2.具有一定延遲性 |
資料同步很少有隻同步單向的。除非是資料庫的壓力大了要將表拆分出,這時候存在表模型一樣的情況。更常見的是在灰度階段,新老系統同時都在執行,這時候就需要同時維護新老資料,因此需要採取雙向同步的策略。
雙寫
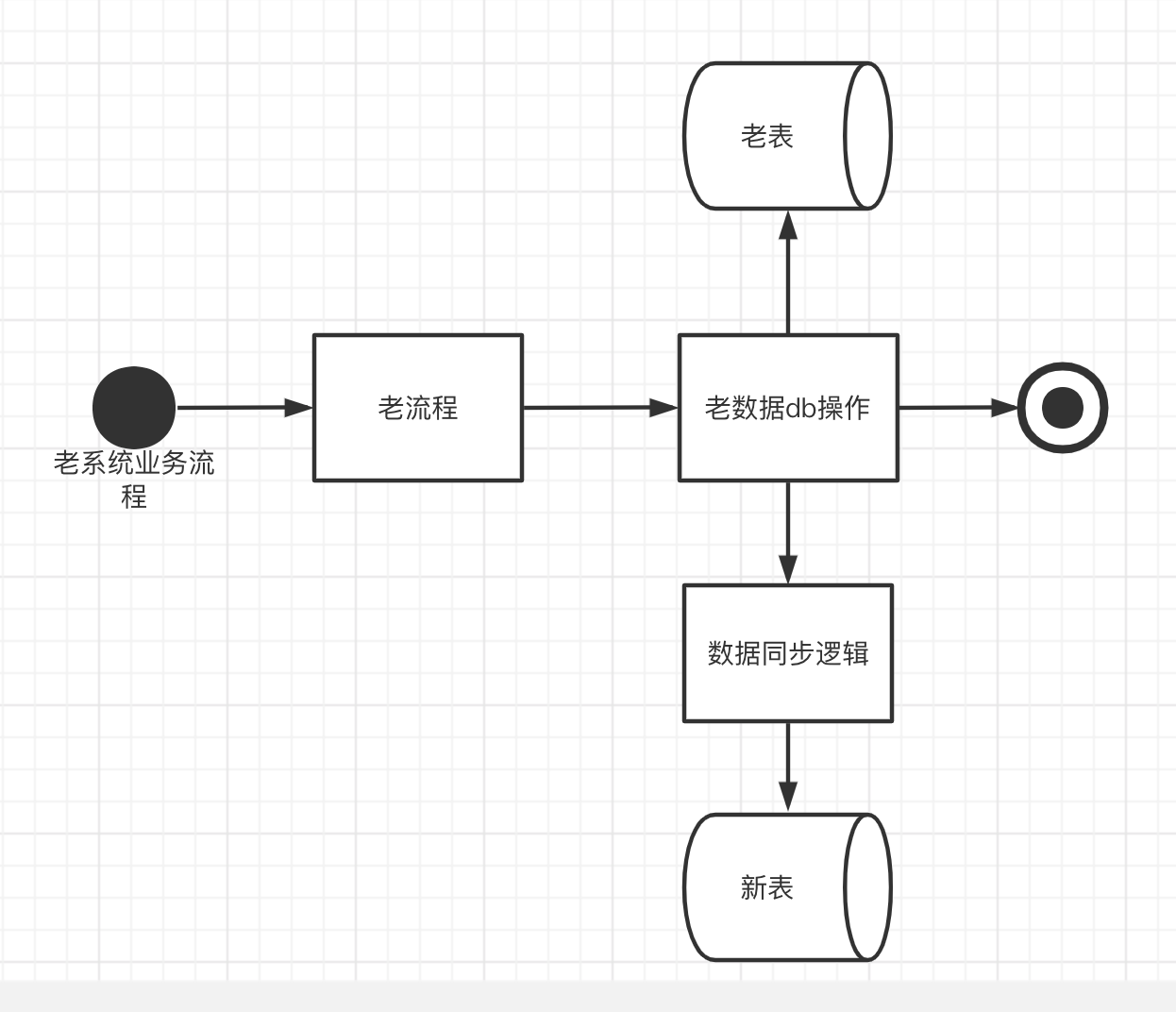
資料同步又分為增量資料同步、存量資料同步。一般來說我們會在老系統中所有更新表的地方將資料同步邏輯開發好,先上線,同步幾天存量資料,然後選擇某上線後的一天作為存量資料的截止時間,這是為了防止存量資料和增量資料中間有資料空洞,造成資料丟失的情況
增量資料
同步增量資料有幾個步驟
- 將老系統中所有新增、更新的地方都寫上資料同步邏輯
- 在同步資料的時候,除了新老模型欄位的對映邏輯以外,當操作是新增的時候,直接新增新表資料,當操作是更新的時候,如果新表沒有對應資訊,那麼查一下老表的資料,然後對映到新模型資料結構再新增到新表
- 更新新模型的時候可能存在並行問題,這時候我們插入的時候要檢查時間戳或者版本號,如果庫內資料早於自己,就更新,否則就丟棄。
存量資料
存量資料一般就是取數,取數有兩種比較常見的方式
- 通過sql掃表,如果表比較大可以按月或者按天掃,優點是操作簡單,缺點是需要人工一直介入,且掃表會對資料庫造成一定壓力,影響業務功能的穩定性
- 同步離線表取數,將離線表的資料傳送到mq或者kafaka,消費後進行資料同步
存量資料同步的時候也需要注意的是資料的版本問題,如果不存在就新增,如果存在就判斷時間戳或版本號,總之就是將最新的資料更新進去,老版本資料拋棄。
總結
從上面我們可以看出雙向同步的問題就是同步程式碼的複用性差,業務程式碼內部維護的增量邏輯和存量同步的邏輯不能複用,需要重複開發。還有一個問題就是當新老模型差距較大或者新資料來源的變動比較大的時候,比如從一種儲存媒介同步到另一種儲存媒介,這些複雜邏輯維護到了每個更新介面處,開發成本不可預估,因此此方案只適合公司沒有中介軟體支援並且又要做改造的情況下使用。
ps:如果存量資料有時效性,比如一個月以前的資料不要了,並且改造的週期比較長,那麼可以不需要同步存量資料,讓增量資料跑一個月即可。
binlog,資料雙向同步
我們都知道當資料變更的時候(新增、更新、刪除),db 都會記錄變更紀錄檔,並且同步到各個從庫中,這個紀錄檔就是我們耳聞能詳的 binlog。開源的工具主要有:Canal、otter等,基本原理就是解析binlog紀錄檔,然後傳送到訊息中介軟體,使用者端消費後進行處理。
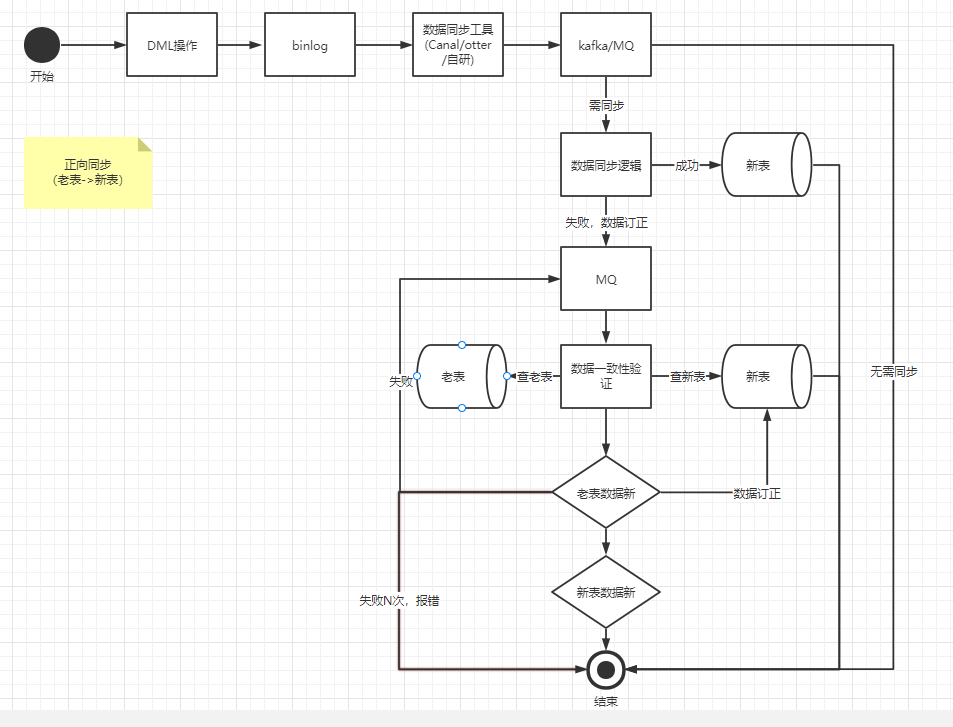
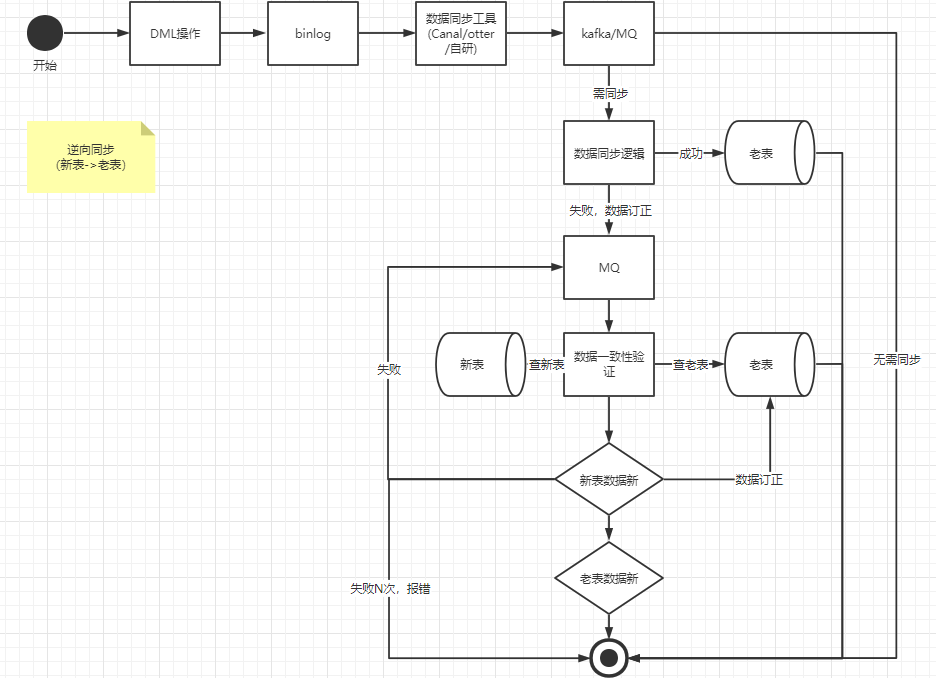
由於我們是線上新老系統一起在跑,因此我們需要進行資料雙向同步,也就是正向同步:老表到新表;逆向同步:新表到老表。
老表到新表增量同步
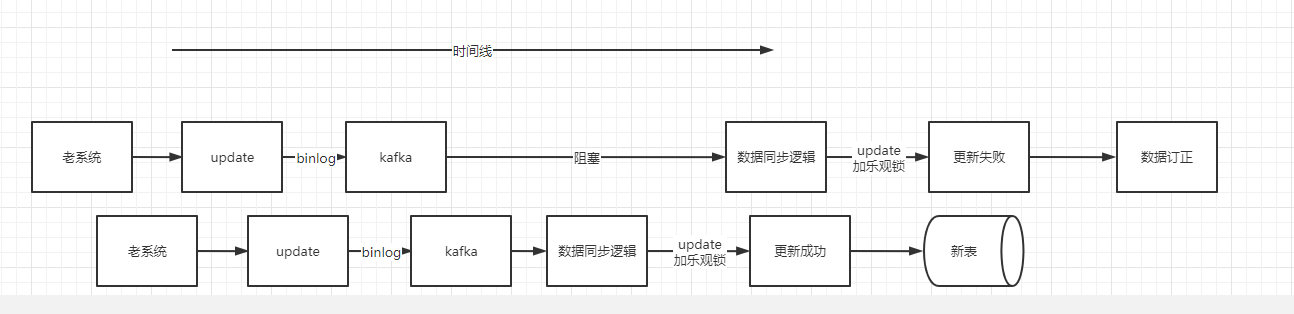
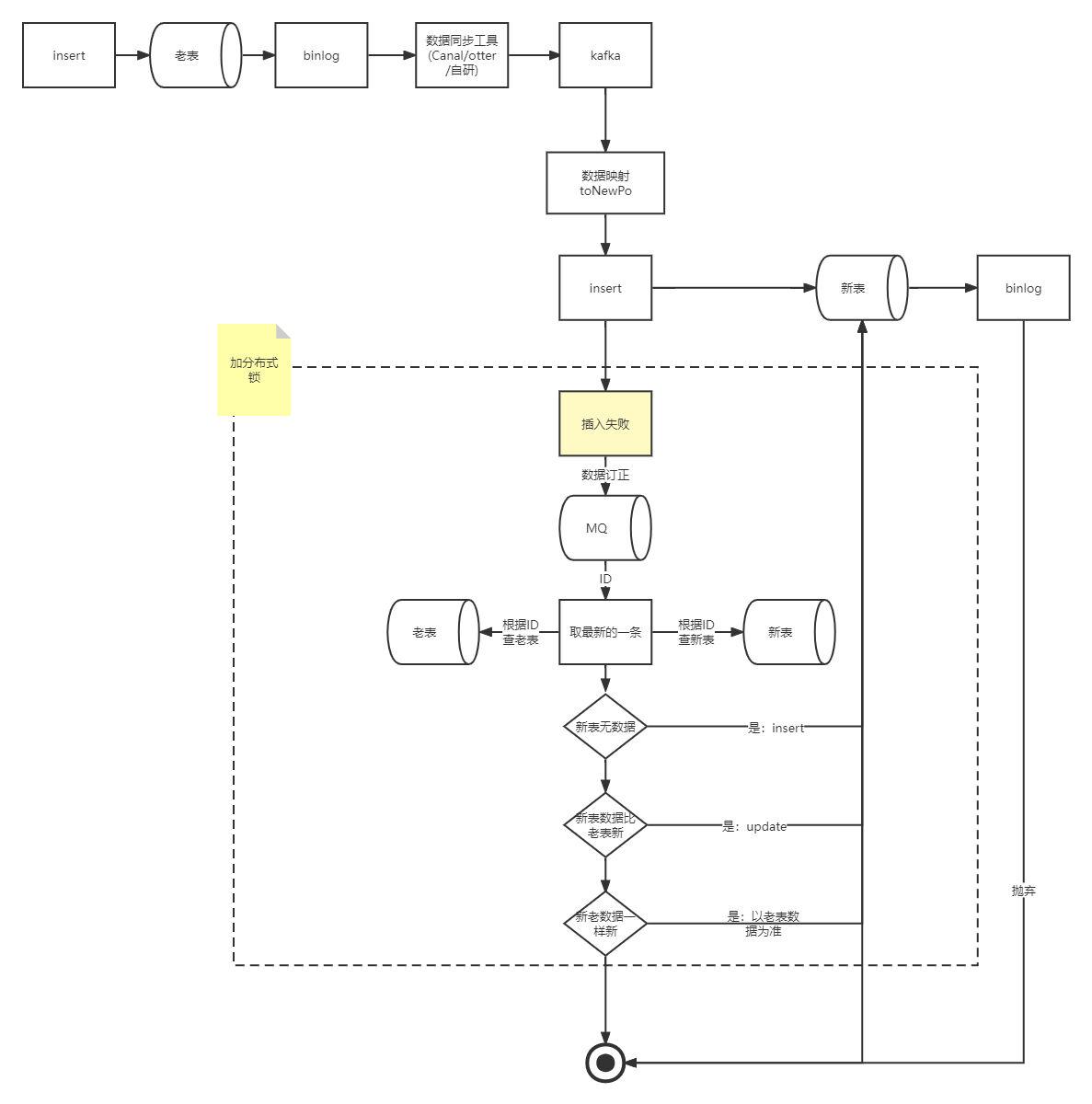
當老系統進行DML(insert、update,由於大部分業務都是採用邏輯刪的情況也就是update,因此這裡不考慮delete情況)操作的時候,老表會吐出相應的binlog,binlog 經過我們的資料同步工具會將對應的訊息投遞到kafka或者mq,在我們的 convert 資料同步邏輯內將對應的訊息對映成新資料模型後,會將訊息是 insert 還是 update 進行不同處理
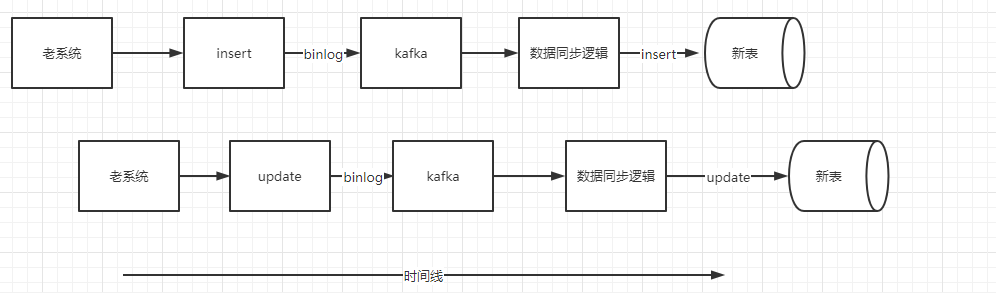
insert
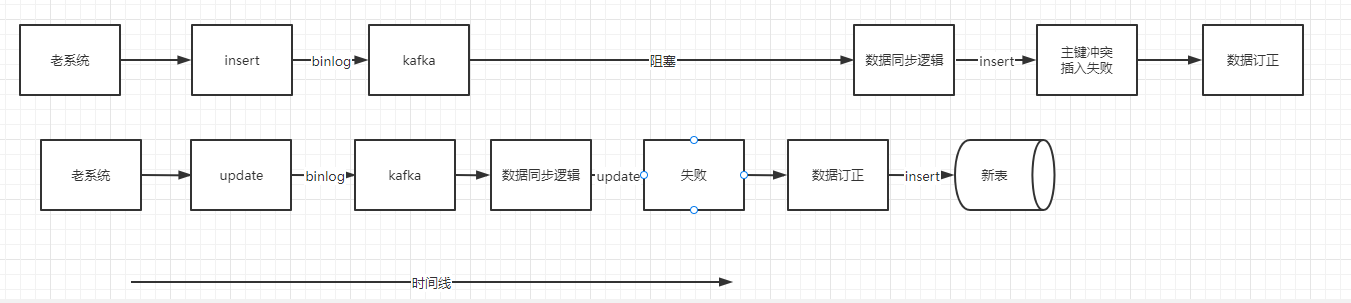
經過 convert 將訊息轉化成對應的新資料模型後,直接進行插入操作。這裡可能會出現一些異常場景,比較常見的是 insert 操作還沒插入新表,老系統就對該記錄操作了一次更新,然後也吐出了一條 binlog,這時候這條 binlog 先被使用者端消費,由於更新的時候如果新表內沒有資料,會更新失敗,更新失敗後會走資料訂正邏輯,資料訂正的時候如果新表沒有資料則會新增。這時候再操作 insert 操作就會報主鍵衝突。新增失敗的時候也會走資料訂正邏輯。
這裡可能有個疑問,直接在消費到的時候根據資料的主鍵ID加一把分散式鎖能不能解決問題。答案是不能解決,因為更新操作可能會更先被消費到,這時候還是會報主鍵重複,並且如果資料量大的情況下,加鎖還會導致資料同步效能問題。
正常流程:
異常流程:
update
使用者端收到 update 的binlog訊息後,會將訊息體內容經過 convert 邏輯轉化成新模型,也就是資料庫PO物件,然後進行 update 操作。但是不是無腦更新的,需要加個樂觀鎖(where update_time < #{updateTime}),如果表裡資料已經比你新了,那麼就不更新,更新失敗,走資料訂正邏輯。如果表裡資料比較老,那麼更新成功。
正常流程:
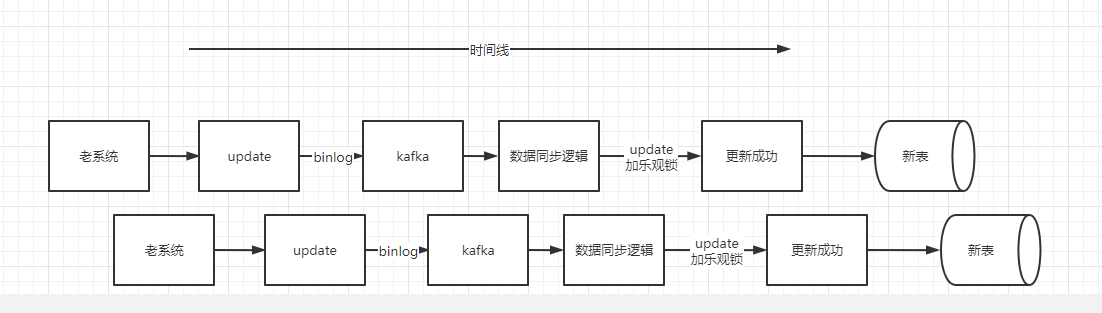
異常流程:
資料訂正
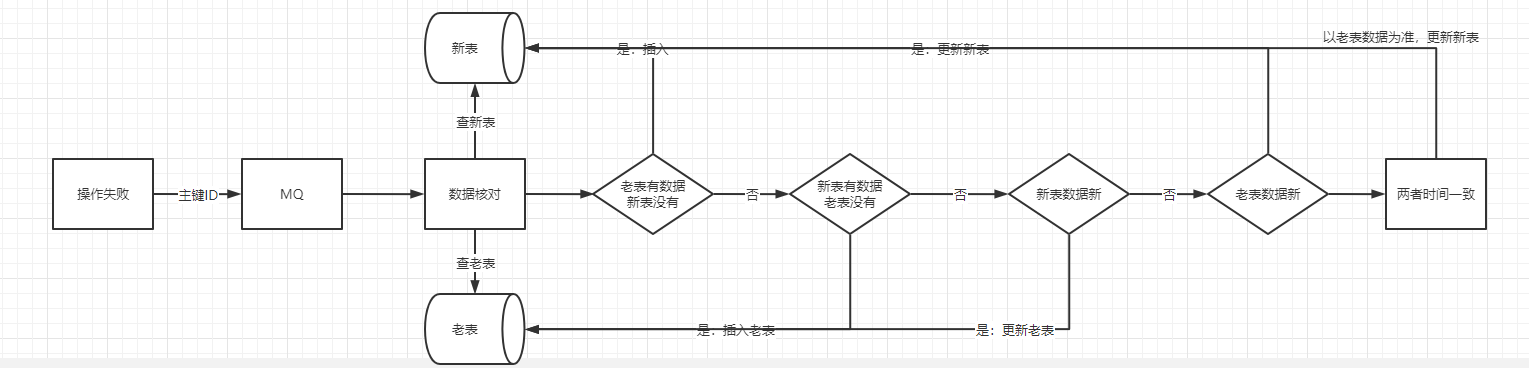
不管是 insert 操作還是 update 操作,當操作失敗了以後,我們都要進行資料訂正,這是為了保證最終資料一致性。
資料訂正的整個過程都需要根據主鍵ID來進行加分散式鎖,這是因為資料訂正的時候是拿主鍵ID去新老表查資料,然後進行比對後才決定如何進行訂正,這裡如果不加鎖的話會導致並行問題,從而訂正失敗。由於絕大多數的資料都是在同步流程中同步完畢,走入到資料訂正的資料其實是少部分的,因此在這裡加分散式鎖其實是沒太大影響的。
ps:新老表的主鍵ID要保持一致。
整體流程圖
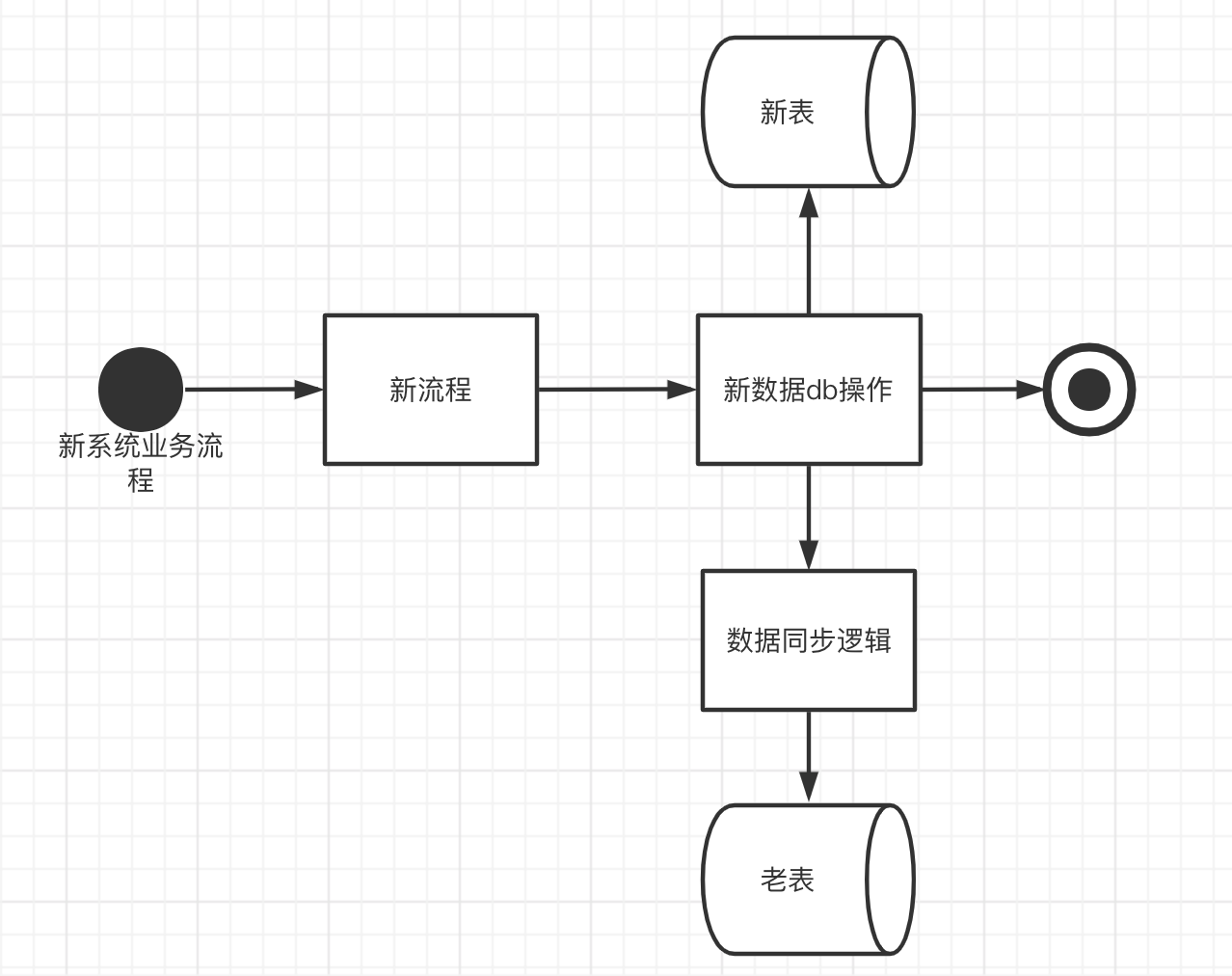
新表到老表增量同步
新表到老表也是一樣的操作,無非就是雙方角色互換下。新系統DML操作後,同步到老表,具體的同步邏輯還是一樣的。
ps
我們都注意到,當老表同步到新表,新表同步完成後,新表也會吐出相應的 binlog,這時候使用者端監聽後如果按照上面的流程走下去,那麼會陷入一個死迴圈,無限消費,那麼使用者端怎麼監聽這部分資料並且拋棄掉呢。
我們可以在新老表加個flag欄位,所有業務dml操作將該欄位置為1,那麼資料同步使用者端監聽到binlog訊息就進行資料同步。如果是資料同步的dml操作,將該欄位置為0,那麼資料同步使用者端監聽到binlog訊息就直接拋棄掉即可。
存量同步
為了降低資料庫壓力,我們取存量資料是取的離線表,離線表具有延遲性,離線表儲存的一半是t-1天的資料。為了防止丟資料,我們會先將老到新的增量同步邏輯先上線一兩天,然後再從離線表取數,這樣所有的資料都不會丟。假如我們先同步存量資料,再同步增量資料,或者增量資料同步邏輯一上線立馬同步存量資料,那麼t-1到t這中間就會有1天的資料缺口。
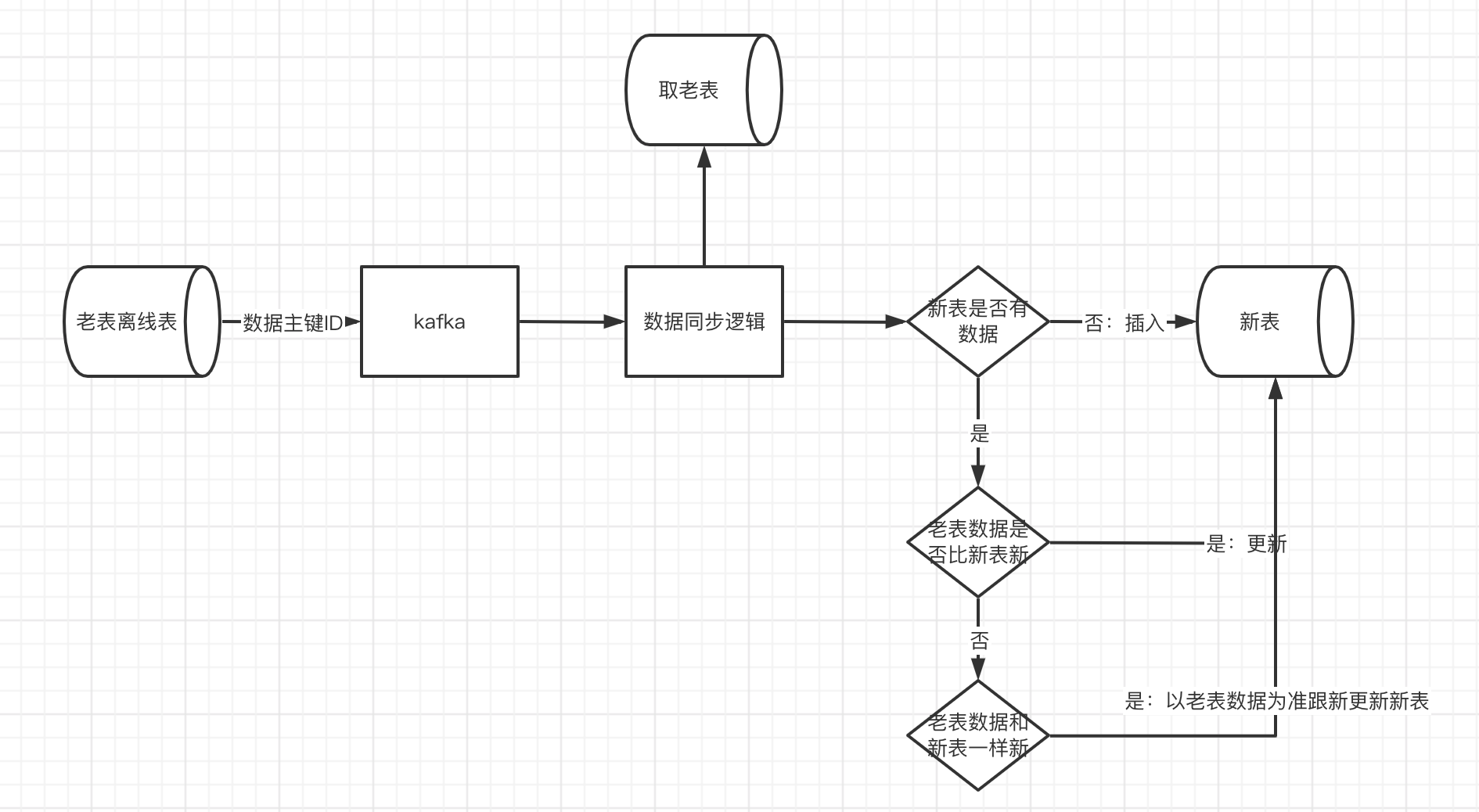
存量同步如果insert失敗或者update失敗和增量同步的邏輯一樣,都會走資料訂正邏輯,保證資料的最終一致性。
優缺點
採用binlog同步的優點就是針對所有的dml操作集中處理,解耦業務、可發揮空間大;缺點就是需要中介軟體支援,並且具有一定的延遲性。
當我們老系統多張表,融合到新系統只有一張表;或者老系統一張表,拆到新系統多張表;那麼這種場景就很適合用這種方式來同步,只需要在資料同步邏輯根據關聯的欄位查出對應的資訊進行insert或者update即可。
最後
同步的一定要做好監控!