【JVM故障問題排查心得】「記憶體診斷系列」Docker容器經常被kill掉,k8s中該節點的pod也被驅趕,怎麼分析?
背景介紹
最近的docker容器經常被kill掉,k8s中該節點的pod也被驅趕。
我有一個在主機中執行的Docker容器(也有在同一主機中執行的其他容器)。該Docker容器中的應用程式將會計算資料和流式處理,這可能會消耗大量記憶體。
該容器會不時退出。我懷疑這是由於記憶體不足,但不是很確定。我需要找到根本原因的方法。那麼有什麼方法可以知道這個集裝箱的死亡發生了什麼?
容器層級判斷檢測
提到docker logs $container_id檢視該應用程式的輸出。這永遠是我要檢查的第一件事。接下來,您可以執行docker inspect $container_id以檢視狀態的詳細資訊,例如:
"State": {
"Status": "exited",
"Running": false,
"Paused": false,
"Restarting": false,
"OOMKilled": false,
"Dead": false,
"Pid": 0,
"ExitCode": 2,
"Error": "",
"StartedAt": "2016-06-28T21:26:53.477229071Z",
"FinishedAt": "2016-06-28T21:26:53.478066987Z"
}
重要的一行是「 OOMKilled」,如果您超出了容器的記憶體限制,並且Docker殺死了您的應用程式,則該行將為true。您可能還需要查詢退出程式碼,以檢視其是否標識出您的應用退出的原因。
-
Docker內部,這僅表示docker本身是否會殺死您的程序,並要求您在容器上設定記憶體限制。
-
Docker外部,如果主機本身記憶體不足,Linux核心可以銷燬程序。發生這種情況時,Linux通常會在/ var / log中寫入紀錄檔。使用Windows和Mac上的Docker Desktop,您可以在docker設定中調整分配給嵌入式Linux VM的記憶體。
- 可以通過閱讀紀錄檔來了解容器內的程序是否被OOM殺死。OOMkill是由核心啟動的,因此每次發生時,都會在中包含很多行/var/log/kern.log,例如:
python invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=995
oom_kill_process+0x22e/0x450
Memory cgroup out of memory: Kill process 31204 (python) score 1994 or sacrifice child
Killed process 31204 (python) total-vm:7350860kB, anon-rss:4182920kB, file-rss:2356kB, shmem-rss:0kB
Linux作業系統的程序服務發生被killed的原因是什麼
在Linux中,經常會遇到一些重要的程序無緣無故就被killed,而大多數的經驗之談就是系統資源不足或記憶體不足所導致的。
當Linux系統資源不足時,Linux核心可以決定終止一個或多個程序,記憶體不足時會在系統的實體記憶體耗盡時觸發OOM killed,可以利用「dmesg | tail -N」命令來檢視killed的近N行紀錄檔。

常規的宕機監控之類
在服務宕機或者重啟之前我們的常規操作就是採用ps指令判定服務的增長趨勢以及展示真實使用的資源的大小的前幾位排名。
- Linux下顯示系統程序的命令ps,最常用的有ps -ef 和ps aux。這兩個到底有什麼區別呢?
ps -ef指令代表著'SystemV風格',而ps aux代表著’BSD風格‘。

由上圖所示,可以分析出對應的資料結構模型。
USER //使用者名稱
%CPU //程序佔用的CPU百分比
%MEM //佔用記憶體的百分比
VSZ //該程序使用的虛擬記憶體量(KB)
RSS //該程序佔用的固定記憶體量(KB)resident set size
STAT //程序的狀態
START //該程序被觸發啟動時間
TIME //該程序實際使用CPU執行的時間
其中CPU算是第3個位置、記憶體MEM算是第4個位置,虛擬記憶體VSZ是第5個位置,記住這個後面我們會使用這個方式進行排序。
檢視當前系統內CPU佔用最多的前10個程序(欄位屬於第3個)
ps auxw | sort -rn -k3 | head -10
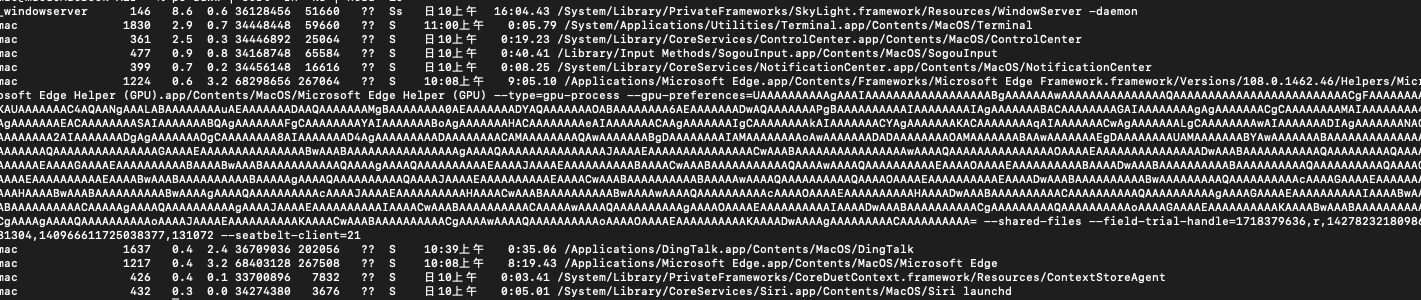
ps auxw指令(BSD風格)
- u:以使用者為主的格式來顯示程式狀況
- x:顯示所有程式,不以終端機來區分
- w:採用寬闊的格式來顯示程式狀況
sort排序指令
sort -rn -k5
-n是按照數位大小排序(-n 這代表著排除n行的操作處理),-r是以相反順序,-k是指定需要排序的欄位
ps auxw | head -1
記憶體消耗最多的前10個程序(欄位屬於第4個)
ps auxw | head -1;ps auxw|sort -rn -k4|head -10
虛擬記憶體使用最多的前10個程序(欄位屬於第5個)
ps auxw|head -1;ps auxw|sort -rn -k5|head -10
去掉x引數的結果
ps auw | head -1; ps auw|sort -rn -k4 | head -10
stat取值含義

D //無法中斷的休眠狀態(通常 IO 的程序);
R //正在執行可中在佇列中可過行的;
S //處於休眠狀態;
T //停止或被追蹤;
W //進入記憶體交換 (從核心2.6開始無效);
X //死掉的程序 (基本很少見);
Z //殭屍程序;
< //優先順序高的程序
N //優先順序較低的程序
L //有些頁被鎖進記憶體;
s //程序的領導者(在它之下有子程序);
l //多執行緒,克隆執行緒(使用 CLONE_THREAD, 類似 NPTL pthreads);
+ //位於後臺的行程群組;
dmesg的命令分析
有幾個工具/指令碼/命令 可以更輕鬆地從該虛擬裝置讀取資料,其中最常見的是 dmesg 和 journalctl。
輸入dmesg指令進行egrep正規表示式匹配killed的程序資訊,將輸出對應的程序資訊。
dmesg | egrep -i -B100 'killed process'
或
dmesg | grep -i -B100 'killed process'
以上的指令就可以輸出最近killed的資訊,其中-B100,表示 'killed process’之前的100行內容,與head的指令非常的相似。

如果我們看到了oom-kill的字樣之後,就可以判斷它是被記憶體不足所導致的kill,oom-kill之後,就是描述那個被killed的程式的pid和uid。
Out of memory: Killed process 1138439 (python3) total-vm:8117956kB, anon-rss:5649844kB,記憶體不夠
total_vm和rss的指標值

-
total_vm:總共使用的虛擬記憶體 Virtual memory use (in 4 kB pages),8117956/1024(得到MB)/1024(得到GB)=7.741GB
-
rss:常駐記憶體使用Resident memory use (in 4 kB pages) 5649844/1024/1024=5.388GB
案例1:檢視到pod被驅趕的原因
[3899860.525793] Out of memory: Kill process 64058 (nvidia-device-p) score 999 or sacrifice child
[3899860.526961] Killed process 64058 (nvidia-device-p) total-vm:126548kB, anon-rss:2080kB, file-rss:0kB, shmem-rss:0kB
案例2:檢視到docker容器被kill 的原因
[3899859.737598] Out of memory: Kill process 27562 (jupyter-noteboo) score 1000 or sacrifice child
[3899859.738640] Killed process 27562 (jupyter-noteboo) total-vm:215864kB, anon-rss:45928kB, file-rss:0kB, shmem-rss:0kB
journalctl命令 – 檢視指定的紀錄檔資訊
當記憶體不足時,核心會將相關資訊記錄到核心紀錄檔緩衝區中,該緩衝區可通過 /dev/kmsg 獲得。除了上面的dmesg之外,還有一個journalctl。
語法格式: journalctl [引數]
常用引數:
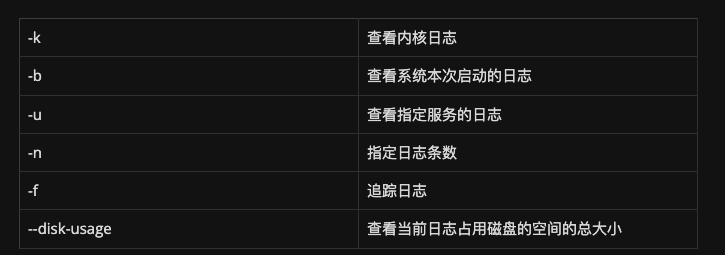
檢視Killed紀錄檔
使用sudo dmesg | tail -7命令(任意目錄下,不需要進入log目錄,這應該是最簡單的一種)而journalctl命令來自於英文片語「journal control」的縮寫,其功能是用於檢視指定的紀錄檔資訊。
journalctl指令介紹
在RHEL7/CentOS7及以後版本的Linux系統中,Systemd服務統一管理了所有服務的啟動紀錄檔,帶來的好處就是可以只用journalctl一個命令,檢視到全部的紀錄檔資訊了。
檢視所有紀錄檔(預設情況下 ,只儲存本次啟動的紀錄檔)
journalctl
檢視核心紀錄檔(不顯示應用紀錄檔)
journalctl -k
檢視系統本次啟動的紀錄檔
journalctl -b
journalctl -b -0
檢視上一次啟動的紀錄檔(需更改設定)
journalctl -b -1
檢視指定時間的紀錄檔
journalctl --since=「2021-09-16 14:22:02」
journalctl --since 「30 min ago」
journalctl --since yesterday
journalctl --since 「2021-01-01」 --until 「2021-09-16 13:40」
journalctl --since 07:30 --until 「2 hour ago」
顯示尾部的最新10行紀錄檔
journalctl -n
顯示尾部指定行數的紀錄檔
journalctl -n 15
實時捲動顯示最新紀錄檔
journalctl -f
檢視指定服務的紀錄檔
journalctl /usr/lib/systemd/systemd
比如檢視docker服務的紀錄檔
systemctl status docker
檢視某個 Unit 的紀錄檔
journalctl -u nginx.service
journalctl -u nginx.service --since today
實時捲動顯示某個 Unit 的最新紀錄檔
journalctl -u nginx.service -f
合併顯示多個 Unit 的紀錄檔
$ journalctl -u nginx.service -u php-fpm.service --since today
本文來自部落格園,作者:洛神灬殤,轉載請註明原文連結:https://www.cnblogs.com/liboware/p/16984760.html,任何足夠先進的科技,都與魔法無異。