強化學習調參技巧二:DDPG、TD3、SAC演演算法為例:
1.訓練環境如何正確編寫
強化學習裡的 env.reset() env.step() 就是訓練環境。其編寫流程如下:
1.1 初始階段:
先寫一個簡化版的訓練環境。把任務難度降到最低,確保一定能正常訓練。記錄正常訓練的智慧體的分數,與隨機動作、傳統演演算法得到的分數做比較。
DRL演演算法的分數應該明顯高於隨機動作(隨機執行動作)。DRL演演算法不應該低於傳統演演算法的分數。如果沒有傳統演演算法,那麼也需要自己寫一個區域性最優的演演算法
評估策略的效能: 大部分情況下,可以直接是對Reward Function 給出的reward 進行求和得到的每輪收益episode return作為策略評分。有時候可以需要直接拿策略的實際分數作為評分
需要保證這個簡化版的程式碼:高效、簡潔、可拓展
1.2 改進階段:
讓任務難度逐步提高,對訓練環境env 進行緩慢的修改,時刻儲存舊版本的程式碼同步微調 Reward Function,可以直接代入自己的人類視角,為某些行為新增正負獎勵。注意獎勵的平衡(有正有負)。注意不要為Reward Function 新增太多額外規則,時常回過頭取消一些規則,避免過度矯正。
同步微調 DRL演演算法,只建議微調超引數,但不建議對演演算法核心進行修改。因為任務變困難了,所以需要調整超引數讓訓練變快。同時摸清楚在這個訓練環境下,演演算法對哪幾個超引數是敏感的。有時候為了節省時間,甚至可以為 off-policy 演演算法儲存一些典型的 trajectory(不建議在最終驗證階段使用)。
每一次修改,都需要跑一下記錄不同方法的分數,確保:隨機動作 < 傳統方法 < DRL演演算法。這樣才能及時發現程式碼邏輯上的錯誤。要極力避免程式碼中出現複數個的錯誤,因為極難排查。
1.3 收尾階段:
嘗試慢慢刪掉Reward Function 中一些比較複雜的東西,刪不掉就算了。
選擇高低兩組超引數再跑一次,確認沒有優化空間。
2. 超引數解釋分析
2.1 off-policy演演算法中常見的超引數
- 網路寬度: network dimension number。DRL 全連線層的寬度(特徵數量)
- 網路層數: network layer number。一個輸入張量到輸出需要乘上w的次數
- 隨機失活: dropout
- 批歸一化: batch normalization
- 記憶容量: 經驗回放快取 experimence replay buffer 的最大容量 max capacity
- 批次大小: batch size。使用優化器更新時,每次更新使用的資料數量
- 更新次數:update times。使用梯度下降更新網路的次數
- 折扣因子: discount factor、gamma
【網路寬度、網路層數】 越複雜的函數就需要越大容量的神經網路去擬合。在需要訓練1e6步的任務中,我一般選擇 寬度128、256,層數小於8的網路(請注意,乘以一個w算一層,一層LSTM等於2層)。使用ResNet等結構會有很小的提升。一般選擇一個略微冗餘的網路容量即可,把調整超引數的精力用在這上面不划算,我建議這些超引數都粗略地選擇2的N次方,
因為:防止過度調參,超引數選擇x+1 與 x-1並沒有什麼區別,但是 x與2x一定會有顯著區別
2的N次方大小的資料,剛好能完整地放進CPU或GPU的硬體中進行計算,如Tensor Core
過大、過深的神經網路不適合DRL,
因為:深度學習可以在整個訓練結束後再使用訓練好的模型。
而強化學習需要在幾秒鐘的訓練後馬上使用剛訓好的模型。
這導致DRL只能用比較淺的網路來保證快速擬合(10層以下)
並且強化學習的訓練資料不如有監督學習那麼穩定,無法劃分出訓練集測試集去避免過擬合,
因此DRL也不能用太寬的網路(超過1024),避免引數過度冗餘導致過擬合
【dropout、批歸一化】 她們在DL中得到廣泛地使用,可惜不適合DRL。如果非要用,那麼也要選擇非常小的 dropout rate(0~0.2),而且要注意在使用的時候關掉dropout。我不用dropout。
好處:在資料不足的情況下緩解過擬合;像Noisy DQN那樣去促進策略網路探索
壞處:影響DRL快速擬合的能力;略微增加訓練時間
【批歸一化】 經過大量實驗,DRL絕對不能直接使用批歸一化,如果非要用,那麼就要修改Batch Normalization的動量項超引數。
【記憶容量】 經驗回放快取 experimence replay buffer 的最大容量 max capacity,如果超過容量限制,它就會刪掉最早的記憶。在簡單的任務中(訓練步數小於1e6),對於探索能力強的DRL演演算法,通常在快取被放滿前就訓練到收斂了,不需要刪除任何記憶。然而,過大的記憶也會拖慢訓練速度,我一般會先從預設值 2 ** 17 ~ 2 ** 20 開始嘗試,如果環境的隨機因素大,我會同步增加記憶容量 與 batch size、網路更新次數,直到逼近伺服器的記憶體、視訊記憶體上限(放在視訊記憶體訓練更快)
【批次大小、更新次數】 一般我會選擇與網路寬度相同、或略大的批次大小batch size。我一般從128、256 開始嘗試這些2的N次方。在off-policy中,每往Replay 更新幾個資料,就對應地更新幾次網路,這樣做簡單,但效果一般。(深度學習裡)更優秀的更新方法是:根據Replay中資料數量,成比例地修改更新次數。Don't Decay the Learning Rate, Increase the Batch Size. ICLR. 2018 。,經過驗證,DRL也適用。
【折扣因子】 discount factor、discount-rate parameter 或者叫 gamma 。0.99
2.2 on-policy演演算法中常見的超引數
同策略(A3C、PPO、PPO+GAE)與異策略(DQN、DDPG、TD3、SAC)的主要差異是:
-
異策略off-policy:ReplayBuffer內可以存放「由不同策略」收集得到的資料用於更新網路
-
同策略on-policy:ReplayBuffer內只能存放「由相同策略」收集得到的資料用於更新網路
因此以下超引數有不同的選擇方法: -
記憶容量:經驗回放快取 experimence replay buffer 的最大容量 max capacity
-
批次大小:batch size。使用優化器更新時,每次更新使用的資料數量
-
更新次數:update times。使用梯度下降更新網路的次數
【記憶容量】 on-policy 演演算法每輪更新後都需要刪除「用過的資料」,所以on-policy的記憶容量應該大於等於【單輪更新的取樣步數】,隨機因素更多的任務需要更大的單層取樣步數才能獲得更多的 軌跡 trajectory,才能有足夠的資料去表達環境與策略的互動關係。詳見下面PPO演演算法的【單輪更新的取樣步數】
【批次大小】 on-policy 演演算法比off-policy更像深度學習,它可以採用稍大一點的學習率(2e-4)。因為【單輪更新的取樣步數】更大,所以它也需要搭配更大的batch size(29 ~ 212)。如果記憶體視訊記憶體足夠,我建議使用更大的batch size,我發現一些很難調的任務,在很大的batch size(2 ** 14) 面前更容易獲得單調上升的學習曲線(訓練慢但是及其穩定,多GPU分散式)。請自行取捨。
【更新次數】 一般我們不直接設定更新次數,而是通過【單輪更新的取樣步數】、【批次大小】和【資料重用次數】一同算出【更新次數】,詳見下面PPO演演算法的【資料重用次數】
3. TD3特有的超引數
- 探索噪聲方差 exploration noise std
- 策略噪聲方差 policy noise std
- 延遲更新頻率 delay update frequency
如果你擅長調參,那麼可以可以考慮TD3演演算法。如果你的演演算法的最優策略通常是邊界值,那麼你首選的演演算法就是TD3----最佳策略總在動作邊界
【TD3的探索方式】 讓其很容易在探索「邊界動作」:
- 策略網路輸出張量,經過啟用函數 tanh 調整到 (-1, +1)
- 為動作新增一個clip過的高斯噪聲,噪聲大小由人類指定
- 對動作再進行一次clip操作,調整到 (-1, +1)
好處: 一些任務的最優策略本就存在存在大量邊界動作,TD3可以很快學得很快。
壞處: 邊界動作都是 -1或 +1,這會降低策略的多樣性,網路需要在多樣性好資料上訓練才不容易過擬合。對於clip 到正負1之間的action,過大的噪聲方差會產生大量邊界動作 。
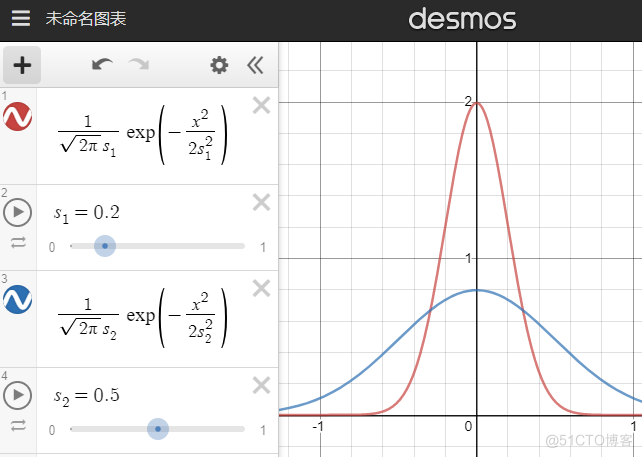
【探索噪聲方差 exploration noise std】 就是上圖中的s。需要先嚐試小的噪聲方差(如0.05),然後逐漸加大。大的噪聲方差刻意多探索邊界值,特定任務下能讓探索更快。且高噪聲下訓練出來的智慧體更robust(穩健、耐操)。
請注意:過大的噪聲方差(大於上圖藍線的0.5)並不會讓探索動作接近隨機動作,而是讓探索動作更接近單一的邊界動作。此外,過大的噪聲會影響智慧體效能,導致她不容易探索到某些state。
因此,合適的探索噪聲方差只能慢慢試出來,TD3適合願意調參的人使用。在做出錯誤動作後容易挽回的環境,可以直接嘗試較大的噪聲。
我們也可以模仿 epslion-Greedy,設定一個使用隨機動作的概率,或者每間隔幾步探索就不新增噪聲,甚至也在TD3中使用探索衰減。這些操作都會增加超引數的數量,慎用。
【策略噪聲方差 policy noise std】 確定了探索噪聲後,策略噪聲只需要比探索噪聲稍大(1~2倍)。TD3對策略噪聲的解釋是「計算Q值時,因為相似的動作的Q值也是相似的,所以TD3也為動作加一個噪聲,這能使Q值函數更加光滑,提高訓練穩定性 我們還能多使用幾個新增噪聲的動作,甚至使用加權重要性取樣去算出更穩定的Q值期望。在確定策略梯度演演算法裡的這種「在計算Q值時,為動作加noise的操作」,讓TD3變得有點像隨機策略梯度。無論是否有clip,策略噪聲方差最大也不該超過0.5。
【延遲更新頻率 delay update frequency】 TD3認為:引入目標網路進行 soft update 就是為了提高訓練穩定性,那麼既然 network 不夠穩定,那麼我們應該延遲更新目標網路 target network,即多更新幾次 network,然後再更新一次target network。從這個想法再拓展出去,我們甚至可以模仿TTUR的思想做得更細緻一點,針對雙層優化問題我們能做:
環境隨機因素多,則需要嘗試更大的延遲更新頻率,可嘗試的值有 1~8,預設值為2
提供策略梯度的critic可以多更新幾次,再更新一次actor,可嘗試的值有 1~4<
提供策略梯度的critic可以設計更大的學習率,例如讓critic的學習率是actor 的1~10倍
由於critic 需要處理比 actor 更多的資料,因此建議讓critic網路的寬度略大於actor
4. SAC特有的超引數
儘管下面列舉了4個超引數,但是後三個超引數可以直接使用預設值(預設值只會有限地影響訓練速度),第一個超引數甚至可以直接通過計算選擇出來,不需要調整。
- reward scale 按比例調整獎勵
- alpha 溫度係數 或 target entropy 目標 策略熵
- learning rate of alpha 溫度係數 alpha 的學習率
- initialization of alpha 溫度係數 alpha 的初始值
SAC有極少的超引數,甚至這些超引數可以在訓練開始前就憑經驗確定。
 任何存在多個loss相加的目標函數,一定需要調整係數 lambda,例如SAC演演算法、共用了actor critic 網路的A3C或PPO,使用了輔助任務的PPG。我們需要確定好各個 lambda 的比例。SAC的第二篇論文加入了自動調整 溫度係數 alpha 的機制,處於lambda2位置的溫度alpha 已經用於自動調整策略熵了,所以我們只能修改lambda1。
任何存在多個loss相加的目標函數,一定需要調整係數 lambda,例如SAC演演算法、共用了actor critic 網路的A3C或PPO,使用了輔助任務的PPG。我們需要確定好各個 lambda 的比例。SAC的第二篇論文加入了自動調整 溫度係數 alpha 的機制,處於lambda2位置的溫度alpha 已經用於自動調整策略熵了,所以我們只能修改lambda1。
reward scaling 是指直接讓reward 乘以一個常數k (reward scale),在不破壞reward function 的前提下調整reward值,從而間接調整Q值到合適的大小。 修改reward scale,相當於修改lambda1,從而讓可以讓 reward項 和 entropy項 它們傳遞的梯度大小接近。與其他超引數不同,只要我們知曉訓練環境的累計收益範圍,我們就能在訓練前,直接隨意地選定一個reward scaling的值,讓累計收益的範圍落在 -1000~1000以內即可,不需要精細調整:
【溫度係數、目標策略熵】 Temperature parameters (alpha)、target 'policy entropy'。SAC的第二篇論文加入了自動調整 溫度係數 alpha 的機制:通過自動調整溫度係數,做到讓策略的熵維持在目標熵的附近(不讓alpha過大而影響優化,也不讓alpha過小而影響探索)
策略熵的預設值是 動作的個數 的負log,詳見SAC的第二篇論文 section 5 Automating Entropy Adjustment for Maximum Entropy 。SAC對這個超引數不敏感,一般不需要修改。有時候策略的熵太大將導致智慧體無法探索到某些有優勢的state,此時需要將目標熵調小。
【溫度係數 alpha 的學習率】 learning rate of alpha 溫度係數alpha 最好使用 log 形式進行優化,因為alpha是表示倍數的正數。一般地,溫度係數的學習率和網路引數的學習率保持一致(一般都是1e-4)。當環境隨機因素過大,導致每個batch 算出來的策略熵 log_prob 不夠穩定時,我們需要調小溫度係數的學習率。
【溫度係數 alpha 的初始值】 initialization of alpha 溫度係數的初始值可以隨便設定,只要初始值不過於離奇,它都可以被自動調整為合適的值。一般偷懶地將初始值設定為 log(0) 其實過大了,這會延長SAC的預熱時間,我一般設定成更小的數值,詳見 The alpha loss calculating of SAC is different from other repo · Issue #10 · Yonv1943/ElegantRL 。
5. 自己模型訓練調參記錄(TD3)
5.1 模型環境引數
常規引數:
| 無人機初始位置 | 使用者初始位置 | 無人機覆蓋半徑(米) | 最大關聯數 | UAV飛行距離 |
|---|---|---|---|---|
| 【20,180】 | 【20,180】 | 【75,100】 | 【20,30】 | 【0,30】 |
| 時延記錄: | ||||
| 前景(MB) | 0.125 | 0.5 | 1 | 1.25 |
| -- | -- | -- | -- | -- |
| 背景(MB) | 0.5 | 2 | 4 | 5 |
| local(ms) | 13 | 52 | 105 | --- |
| UAV(ms) | 47 | 29.4 | 39.7 | --- |
| coop(ms) | 44 | 29.6 | 38.2 | ---- |
| 超引數: | ||||
| ACTOR_LR | CRITIC_LR | BATCH_SIZE | GAMMA | TAU |
| -- | -- | -- | -- | -- |
| 【1e-4 ,1e-5】 | 【1e-3 ,1e-4】 | 【256,512】 | 0.99】 | 0.005 |
| EXPL_NOISE | policy_noise | noise_clip | policy_freq | hid_size |
| 0.1、0.05 | 0.2、0.1 | 0.5 | 【1,8】預設:2 | 【128,512】 |
目前採用組合有如下:
- ACTOR_LR = 1e-4 # Actor網路的 learning rate 學習率 1e-3
- CRITIC_LR = 1e-3 # Critic網路的 learning rate 1e-3
- EXPL_NOISE = 0.05 # 動作噪聲方差
- self.hid_size=256
- self.hid1_size=128
- policy_noise=0.1,
- noise_clip=0.5,
- policy_freq=2
5.2 調參效果:
可以看到模型訓練的穩定性和收斂效果越來越好,調多了你也就知道哪些超引數影響的大了
5.3 造成波動的原因,然後採用對應的解決方案:
- 如果在策略網路沒有更新的情況下,Agent在環境中得到的分數差異過大。那麼這是環境發生改變造成的:
-1. 每一輪訓練都需要 env.reset(),然而,有時候重置環境會改變難度,這種情況下造成的波動無法消除。
-2. 有時候是因為DRL演演算法的泛化性不夠好。此時我們需要調大相關引數增加探索,以訓練出泛化性更好的策略。 - 如果在策略網路沒有更新的情況下,Agent在環境中得到的分數差異較小。等到更新後,相鄰兩次的分數差異很大。那麼這是環境發生改變造成的: 1. 把 learning rate 調小一點。2. 有時候是因為演演算法過度鼓勵探索而導致的,調小相關引數即可。