資料驅動測試-從方法探研到最佳實踐
作者:劉紅妍
導讀
在自動化測試實踐中,測試資料是製造測試場景的必要條件,本文主要講述了在溝通自動化框架如何分層,資料如何儲存,以及基於單元測試pytest下如何執行。並通過實踐案例分享,提供資料驅動測試的具體落地方案。
基本概念
資料驅動測試(DDT)是一種方法,其中在資料來源的幫助下重複執行相同順序的測試步驟,以便在驗證步驟進行時驅動那些步驟的輸入值和/或期望值。在資料驅動測試的情況下,環境設定和控制不是寫死的。換句話說,資料驅動的測試是在框架中構建要與所有相關資料集一起執行的測試指令碼,該指令碼利用了可重用的測試邏輯。資料驅動的測試提供了可重複性,將測試邏輯與測試資料分離以及減少測試用例數量等優勢。
設計思路
2.1 測試資料
在測試過程中往往需要更加充分地測試場景,而建立資料測試。測試資料包括輸入輸出,對輸出的自動化驗證等。建立測試資料,可以通過手動拼裝,生產環境拷貝,或通過自動化工具生成。
2.2 資料儲存
資料驅動測試中使用的資料來源可以是Excel檔案,CSV檔案,Yaml檔案,資料池,ADO物件或ODBC源。
2.3 資料驅動優勢
-
如果應用程式開發還在進行當中,測試者仍然可以進行指令碼的編寫工作。
-
減少了冗餘和不必要的測試指令碼。
-
用較少的程式碼生成測試指令碼。
-
所有資訊,如輸入、輸出和預期結果,都以適當的文字記錄形式進行儲存。
-
為應用程式的維護提供利了靈活性條件。
-
如果功能發生了變化,只需要調整特定的函數指令碼。
實踐分享
基於Laputa框架現有測試指令碼,抽離測試資料與測試邏輯,實現資料驅動測試。
Laputa框架簡介:Laputa框架基於 Pytest 整合了對API介面自動化, 以及對 Web應用, 行動端應用和 Windows 桌面應用 UI 等自動化的能力。具有視覺化的Web介面工具, 便於設定執行規則,關聯執行指令碼, 觸發用例執行,檢視執行結果。提供CI整合服務,呼叫Jenkins API跟蹤持續整合結果,開放介面,實現流水線自動化測試。
3.1 環境依賴
3.2.1 引數化設定方式
pytest引數化有兩種方式:
@pytest.fixture(params=[])
@pytest.mark.parametrize()
兩者都會多次執行使用它的測試函數,但@pytest.mark.parametrize()使用方法更豐富一些,laputa更建議使用後者。
3.2.2 用 parametrize 實現引數化
parametrize( ) 方法原始碼:
【python】
def parametrize(self,argnames, argvalues, indirect=False, ids=None, scope=None):
- 主要引數說明
(1)argsnames :引數名,是個字串,如中間用逗號分隔則表示為多個引數名。
(2)argsvalues :引數值,引陣列成的列表,列表中有幾個元素,就會生成幾條用例。
- 使用方法
(1)使用 @pytest.mark.paramtrize() 裝飾測試方法;
(2)parametrize('data', param) 中的 「data」 是自定義的引數名,param 是引入的參數列;
(3)將自定義的引數名 data 作為引數傳給測試用例 test_func;
(4)在測試用例內部使用 data 的引數。
建立測試用例,傳入三組引數,每組兩個元素,判斷每組引數裡面表示式和值是否相等,程式碼如下:
【python】
@pytest.mark.parametrize("test_input,expected",[("3+5",8),("2+5",7),("7*5",30)])
def test_eval(test_input,expected):
# eval 將字串str當成有效的表示式來求值,並返回結果
assert eval(test_input) == expected
執行結果:
【python】
test_mark_paramize.py::test_eval[3+5-8]test_mark_paramize.py::test_eval[2+5-7]
test_mark_paramize.py::test_eval[7*5-35]
============================== 3 passed in 0.02s ===============================
整個執行過程中,pytest 將參數列 ("3+5",8),("2+5",7),("7*5",30) 中的三組資料取出來,每組資料生成一條測試用例,並且將每組資料中的兩個元素分別賦值到方法中,作為測試方法的引數由測試用例使用。
3.2.3 多次使用 parametrize
同一個測試用例還可以同時新增多個 @pytest.mark.parametrize 裝飾器, 多個 parametrize 的所有元素互相組合(類似笛卡兒乘積),生成大量測試用例。
場景:比如登入場景,使用者名稱輸入情況有 n 種,密碼的輸入情況有 m 種,希望驗證使用者名稱和密碼,就會涉及到 n*m 種組合的測試用例,如果把這些資料一一的列出來,工作量也是非常大的。pytest 提供了一種引數化的方式,將多組測試資料自動組合,生成大量的測試用例。範例程式碼如下:
【python】
@pytest.mark.parametrize("x",[1,2])@pytest.mark.parametrize("y",[8,10,11])
def test_foo(x,y):print(f"測試資料組合x: {x} , y:{y}")
執行結果:
【python】
test_mark_paramize.py::test_foo[8-1]
test_mark_paramize.py::test_foo[8-2]
test_mark_paramize.py::test_foo[10-1]
test_mark_paramize.py::test_foo[10-2]
test_mark_paramize.py::test_foo[11-1]
test_mark_paramize.py::test_foo[11-2]
分析如上執行結果,測試方法 test_foo( ) 新增了兩個 @pytest.mark.parametrize() 裝飾器,兩個裝飾器分別提供兩個引數值的列表,2 * 3 = 6 種結合,pytest 便會生成 6 條測試用例。在測試中通常使用這種方法是所有變數、所有取值的完全組合,可以實現全面的測試。
3.2.4 @pytest.fixture 與 @pytest.mark.parametrize 結合
下面講講結合 @pytest.fixture 與 @pytest.mark.parametrize 實現引數化。
如果測試資料需要在 fixture 方法中使用,同時也需要在測試用例中使用,可以在使用 parametrize 的時候新增一個引數 indirect=True,pytest 可以實現將引數傳入到 fixture 方法中,也可以在當前的測試用例中使用。
parametrize 原始碼:
【python】
def parametrize(self,argnames, argvalues, indirect=False, ids=None, scope=None):
indirect 引數設定為 True,pytest 會把 argnames 當作函數去執行,將 argvalues 作為引數傳入到 argnames 這個函數裡。建立「test_param.py」檔案,程式碼如下:
【python】
# 方法名作為引數
test_user_data = ['Tome', 'Jerry']
@pytest.fixture(scope="module")
def login_r(request):
# 通過request.param獲取引數
user = request.param
print(f"\n 登入使用者:{user}")return user
@pytest.mark.parametrize("login_r", test_user_data,indirect=True)
def test_login(login_r):
a = login_r
print(f"測試用例中login的返回值; {a}")
assert a != "
執行結果:
【plain】
登入使用者:Tome PASSED [50%]測試用例中login的返回值; Tome
登入使用者:Jerry PASSED [100%]測試用例中login的返回值; Jerry
上面的結果可以看出,當 indirect=True 時,會將 login_r 作為引數,test_user_data 被當作引數傳入到 login_r 方法中,生成多條測試用例。通過 return 將結果返回,當呼叫 login_r 可以獲取到 login_r 這個方法返回資料。
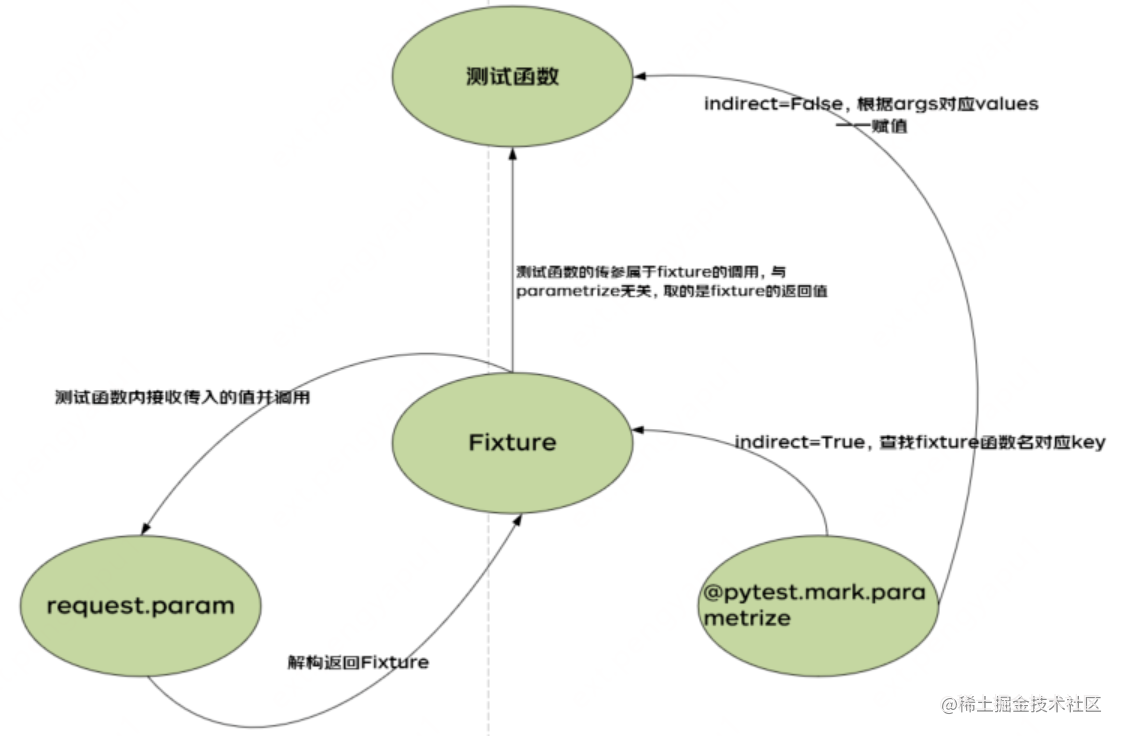
圖1 @pytest.fixture 與 @pytest.mark.parametrize 結合讀取資料圖例
3.2.5 conftest作用域
其作用範圍是當前目錄包括子目錄裡的測試模組。
(1)如果在測試框架的根目錄建立conftest.py檔案,檔案中的Fixture的作用範圍是所有測試模組。
(2)如果在某個單獨的測試資料夾裡建立conftest.py檔案,檔案中Fixture的作用範圍,就僅侷限於該測試資料夾裡的測試模組。
(3)該測試資料夾外的測試模組,或者該測試資料夾外的測試資料夾,是無法呼叫到該conftest.py檔案中的Fixture。
(4)如果測試框架的根目錄和子包中都有conftest.py檔案,並且這兩個conftest.py檔案中都有一個同名的Fixture,實際生效的是測試框架中子包目錄下的conftest.py檔案中設定的Fixture。
3.3 程式碼Demo
測試資料儲存yaml檔案:
【YAML】
測試流程:[
{"name":"B2B普貨運輸三方司機流程","senior":{"createTransJobResource":"B2B","createType":"三方","platformType":2}},
{"name":"B2B普貨運輸三方司機逆向流程","senior":{"isback":"True","createTransJobResource":"B2B","createType":"三方","platformType":2}},
]
測試資料準備,定義統一讀取測試資料方法:
【python】
def dataBuilder(key):dires = path.join(dires, "test_data.yaml")
parameters = laputa_util.read_yaml(dires)[key]
name = []
senior = []
for item in parameters:
name.append(item['name'] if 'name' in item else '')
senior.append(item['senior'] if 'senior' in item else '')
return name, senior
測試用例標識,通過@pytest.mark.parametrize方法驅動用例:
【python】
class TestRegression:
case, param = dataBuilder('測試流程')
@pytest.mark.parametrize("param", param, ids=case)
def test_regression_case(self, param):
# 排程
res = create_trans_bill(params)
trans_job_code = res['data']['jobcode']
carrier_type = params['createType'] if params['createType'] in ('自營', '三方') else '個體'
# 執行
work_info = select_trans_work_info_new(trans_job_code)
trans_work_code = work_info['trans_work_code']
if 'isback' in params and params['isback']:
execute_param.update(isBack=params['isback'])
execute_bill_core(**execute_param)
# 結算
if carrier_type != '自營':
trans_fee_code = CreateTransFeeBillBase.checkTF(trans_job_code)
receive_trans_bill_core(**bill_param)
總結
日常測試過程中,無論是通過手動執行或者指令碼執行,都需要利用資料驅動設計思路,這有助於提高測試場景覆蓋率,測試用例的健壯性和複用性,及需求測試效率。通過資料驅動測試不僅可以得到更好的投資回報率,還可以達到質效合一的測試流程。