詳解視訊中動作識別模型與程式碼實踐
摘要:本案例將為大家介紹視訊動作識別領域的經典模型並進行程式碼實踐。
本文分享自華為雲社群《視訊動作識別》,作者:HWCloudAI。實驗目標
通過本案例的學習:
- 掌握 C3D 模型訓練和模型推理、I3D 模型推理的方法;
注意事項
-
本案例推薦使用TensorFlow-1.13.1,需使用 GPU 執行,請檢視《ModelArts JupyterLab 硬體規格使用指南》瞭解切換硬體規格的方法;
-
如果您是第一次使用 JupyterLab,請檢視《ModelArts JupyterLab使用指導》瞭解使用方法;
-
如果您在使用 JupyterLab 過程中碰到報錯,請參考《ModelArts JupyterLab常見問題解決辦法》嘗試解決問題。
實驗步驟
案例內容介紹
視訊動作識別是指對一小段視訊中的內容進行分析,判斷視訊中的人物做了哪種動作。視訊動作識別與影象領域的影象識別,既有聯絡又有區別,影象識別是對一張靜態圖片進行識別,而視訊動作識別不僅要考察每張圖片的靜態內容,還要考察不同圖片靜態內容之間的時空關係。比如一個人扶著一扇半開的門,僅憑這一張圖片無法判斷該動作是開門動作還是關門動作。
視訊分析領域的研究相比較影象分析領域的研究,發展時間更短,也更有難度。視訊分析模型完成的難點首先在於,需要強大的計算資源來完成視訊的分析。視訊要拆解成為影象進行分析,導致模型的資料量十分龐大。視訊內容有很重要的考慮因素是動作的時間順序,需要將視訊轉換成的影象通過時間關係聯絡起來,做出判斷,所以模型需要考慮時序因素,加入時間維度之後引數也會大量增加。
得益於 PASCAL VOC、ImageNet、MS COCO 等資料集的公開,影象領域產生了很多的經典模型,那麼在視訊分析領域有沒有什麼經典的模型呢?答案是有的,本案例將為大家介紹視訊動作識別領域的經典模型並進行程式碼實踐。
1. 準備原始碼和資料
這一步準備案例所需的原始碼和資料,相關資源已經儲存在 OBS 中,我們通過ModelArts SDK將資源下載到本地,並解壓到當前目錄下。解壓後,當前目錄包含 data、dataset_subset 和其他目錄檔案,分別是預訓練引數檔案、資料集和程式碼檔案等。
import os import moxing as mox if not os.path.exists('videos'): mox.file.copy("obs://ai-course-common-26-bj4-v2/video/video.tar.gz", "./video.tar.gz") # 使用tar命令解壓資源包 os.system("tar xf ./video.tar.gz") # 使用rm命令刪除壓縮包 os.system("rm ./video.tar.gz") INFO:root:Using MoXing-v1.17.3- INFO:root:Using OBS-Python-SDK-3.20.7
上一節課我們已經介紹了視訊動作識別有 HMDB51、UCF-101 和 Kinetics 三個常用的資料集,本案例選用了 UCF-101 資料集的部分子集作為演示用資料集,接下來,我們播放一段 UCF-101 中的視訊:
video_name = "./data/v_TaiChi_g01_c01.avi"
from IPython.display import clear_output, Image, display, HTML import time import cv2 import base64 import numpy as np def arrayShow(img): _,ret = cv2.imencode('.jpg', img) return Image(data=ret) cap = cv2.VideoCapture(video_name) while True: try: clear_output(wait=True) ret, frame = cap.read() if ret: tmp = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) img = arrayShow(frame) display(img) time.sleep(0.05) else: break except KeyboardInterrupt: cap.release() cap.release()

2. 視訊動作識別模型介紹
在影象領域中,ImageNet 作為一個大型影象識別資料集,自 2010 年開始,使用此資料集訓練出的影象演演算法層出不窮,深度學習模型經歷了從 AlexNet 到 VGG-16 再到更加複雜的結構,模型的表現也越來越好。在識別千種類別的圖片時,錯誤率表現如下:
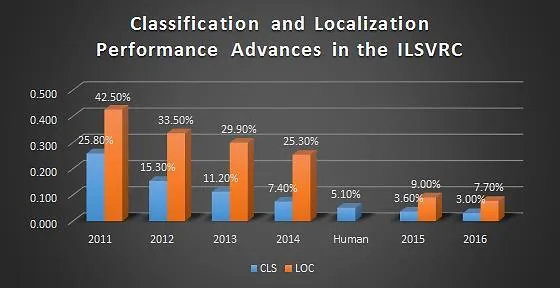
在影象識別中表現很好的模型,可以在影象領域的其他任務中繼續使用,通過複用模型中部分層的引數,就可以提升模型的訓練效果。有了基於 ImageNet 模型的影象模型,很多模型和任務都有了更好的訓練基礎,比如說物體檢測、範例分割、人臉檢測、臉部辨識等。
那麼訓練效果顯著的影象模型是否可以用於視訊模型的訓練呢?答案是 yes,有研究證明,在視訊領域,如果能夠複用影象模型結構,甚至引數,將對視訊模型的訓練有很大幫助。但是怎樣才能複用上影象模型的結構呢?首先需要知道視訊分類與影象分類的不同,如果將視訊視作是影象的集合,每一個幀將作為一個影象,視訊分類任務除了要考慮到影象中的表現,也要考慮影象間的時空關係,才可以對視訊動作進行分類。
為了捕獲影象間的時空關係,論文 I3D 介紹了三種舊的視訊分類模型,並提出了一種更有效的 Two-Stream Inflated 3D ConvNets(簡稱 I3D)的模型,下面將逐一簡介這四種模型,更多細節資訊請檢視原論文。
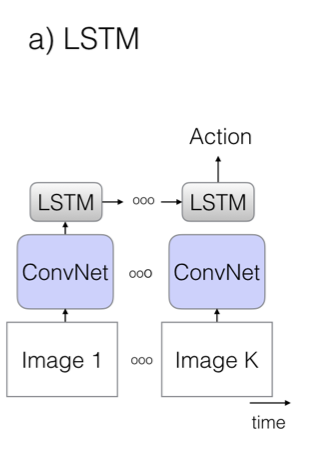
舊模型一:折積網路 + LSTM
模型使用了訓練成熟的影象模型,通過折積網路,對每一幀影象進行特徵提取、池化和預測,最後在模型的末端加一個 LSTM 層(長短期記憶網路),如下圖所示,這樣就可以使模型能夠考慮時間性結構,將上下文特徵聯絡起來,做出動作判斷。這種模型的缺點是隻能捕獲較大的工作,對小動作的識別效果較差,而且由於視訊中的每一幀影象都要經過網路的計算,所以訓練時間很長。
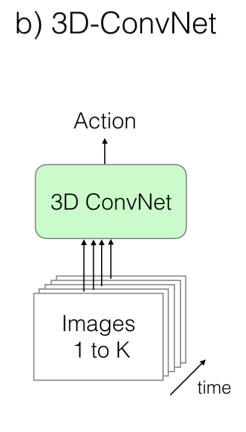
舊模型二:3D 折積網路
3D 折積類似於 2D 折積,將時序資訊加入折積操作。雖然這是一種看起來更加自然的視訊處理方式,但是由於折積核維度增加,引數的數量也增加了,模型的訓練變得更加困難。這種模型沒有對影象模型進行復用,而是直接將視訊資料傳入 3D 折積網路進行訓練。
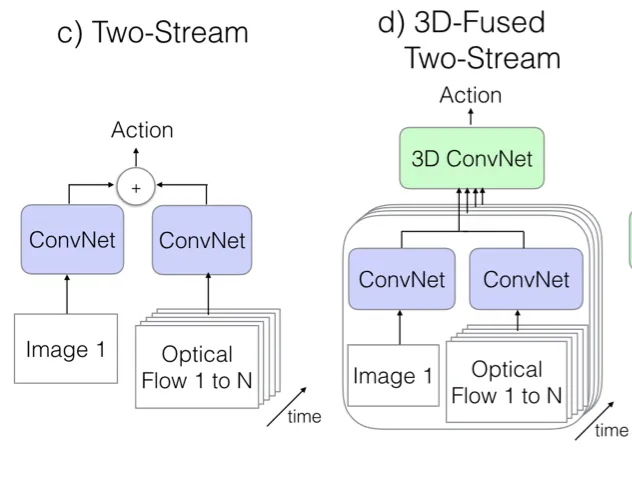
舊模型三:Two-Stream 網路
Two-Stream 網路的兩個流分別為 1 張 RGB 快照和 10 張計算之後的光流幀畫面組成的棧。兩個流都通過 ImageNet 預訓練好的影象折積網路,光流部分可以分為豎直和水平兩個通道,所以是普通圖片輸入的 2 倍,模型在訓練和測試中表現都十分出色。
光流視訊 optical flow video
上面講到了光流,在此對光流做一下介紹。光流是什麼呢?名字很專業,感覺很陌生,但實際上這種視覺現象我們每天都在經歷,我們坐高鐵的時候,可以看到窗外的景物都在快速往後退,開得越快,就感受到外面的景物就是 「刷」 地一個殘影,這種視覺上目標的運動方向和速度就是光流。光流從概念上講,是對物體運動的觀察,通過找到相鄰幀之間的相關性來判斷幀之間的對應關係,計算出相鄰幀畫面中物體的運動資訊,獲取畫素運動的瞬時速度。在原始視訊中,有運動部分和靜止的背景部分,我們通常需要判斷的只是視訊中運動部分的狀態,而光流就是通過計算得到了視訊中運動部分的運動資訊。
下面是一個經過計算後的原視訊及光流視訊。
原視訊

光流視訊
新模型:Two-Stream Inflated 3D ConvNets
新模型採取了以下幾點結構改進:
- 拓展 2D 折積為 3D。直接利用成熟的影象分類模型,只不過將網路中二維 $ N × N 的 filters 和 pooling kernels 直接變成的 filters 和 poolingkernels 直接變成 N × N × N $;
- 用 2D filter 的預訓練引數來初始化 3D filter 的引數。上一步已經利用了影象分類模型的網路,這一步的目的是能利用上網路的預訓練引數,直接將 2D filter 的引數直接沿著第三個時間維度進行復制 N 次,最後將所有引數值再除以 N;
- 調整感受野的形狀和大小。新模型改造了影象分類模型 Inception-v1 的結構,前兩個 max-pooling 層改成使用 $ 1 × 3 × 3 kernels and stride 1 in time,其他所有 max-pooling 層都仍然使用對此的 kernel 和 stride,最後一個 average pooling 層使用 kernelsandstride1intime,其他所有 max−pooling 層都仍然使用對此的 kernel 和 stride,最後一個 averagepooling 層使用 2 × 7 × 7 $ 的 kernel。
- 延續了 Two-Stream 的基本方法。用雙流結構來捕獲圖片之間的時空關係仍然是有效的。
最後新模型的整體結構如下圖所示:

好,到目前為止,我們已經講解了視訊動作識別的經典資料集和經典模型,下面我們通過程式碼來實踐地跑一跑其中的兩個模型:C3D 模型( 3D 折積網路)以及 I3D 模型(Two-Stream Inflated 3D ConvNets)。
C3D 模型結構
我們已經在前面的 「舊模型二:3D 折積網路」 中講解到 3D 折積網路是一種看起來比較自然的處理視訊的網路,雖然它有效果不夠好,計算量也大的特點,但它的結構很簡單,可以構造一個很簡單的網路就可以實現視訊動作識別,如下圖所示是 3D 折積的示意圖:

a) 中,一張圖片進行了 2D 折積, b) 中,對視訊進行 2D 折積,將多個幀視作多個通道, c) 中,對視訊進行 3D 折積,將時序資訊加入輸入訊號中。
ab 中,output 都是一張二維特徵圖,所以無論是輸入是否有時間資訊,輸出都是一張二維的特徵圖,2D 折積失去了時序資訊。只有 3D 折積在輸出時,保留了時序資訊。2D 和 3D 池化操作同樣有這樣的問題。
如下圖所示是一種 C3D 網路的變種:(如需閱讀原文描述,請檢視 I3D 論文 2.2 節)

C3D 結構,包括 8 個折積層,5 個最大池化層以及 2 個全連線層,最後是 softmax 輸出層。
所有的 3D 折積核為 $ 3 × 3 × 3$ 步長為 1,使用 SGD,初始學習率為 0.003,每 150k 個迭代,除以 2。優化在 1.9M 個迭代的時候結束,大約 13epoch。
資料處理時,視訊抽幀定義大小為:$ c × l × h × w,,c 為通道數量,為通道數量,l 為幀的數量,為幀的數量,h 為幀畫面的高度,為幀畫面的高度,w 為幀畫面的寬度。3D 折積核和池化核的大小為為幀畫面的寬度。3D 折積核和池化核的大小為 d × k × k,,d 是核的時間深度,是核的時間深度,k 是核的空間大小。網路的輸入為視訊的抽幀,預測出的是類別標籤。所有的視訊幀畫面都調整大小為是核的空間大小。網路的輸入為視訊的抽幀,預測出的是類別標籤。所有的視訊幀畫面都調整大小為 128 × 171 $,幾乎將 UCF-101 資料集中的幀調整為一半大小。視訊被分為不重複的 16 幀畫面,這些畫面將作為模型網路的輸入。最後對幀畫面的大小進行裁剪,輸入的資料為 $16 × 112 × 112 $
3.C3D 模型訓練
接下來,我們將對 C3D 模型進行訓練,訓練過程分為:資料預處理以及模型訓練。在此次訓練中,我們使用的資料集為 UCF-101,由於 C3D 模型的輸入是視訊的每幀圖片,因此我們需要對資料集的視訊進行抽幀,也就是將視訊轉換為圖片,然後將圖片資料傳入模型之中,進行訓練。
在本案例中,我們隨機抽取了 UCF-101 資料集的一部分進行訓練的演示,感興趣的同學可以下載完整的 UCF-101 資料集進行訓練。
UCF-101 下載
資料集儲存在目錄 dataset_subset 下
如下程式碼是使用 cv2 庫進行視訊檔到圖片檔案的轉換
import cv2 import os # 視訊資料集儲存位置 video_path = './dataset_subset/' # 生成的影象資料集儲存位置 save_path = './dataset/' # 如果檔案路徑不存在則建立路徑 if not os.path.exists(save_path): os.mkdir(save_path) # 獲取動作列表 action_list = os.listdir(video_path) # 遍歷所有動作 for action in action_list: if action.startswith(".")==False: if not os.path.exists(save_path+action): os.mkdir(save_path+action) video_list = os.listdir(video_path+action) # 遍歷所有視訊 for video in video_list: prefix = video.split('.')[0] if not os.path.exists(os.path.join(save_path, action, prefix)): os.mkdir(os.path.join(save_path, action, prefix)) save_name = os.path.join(save_path, action, prefix) + '/' video_name = video_path+action+'/'+video # 讀取視訊檔 # cap為視訊的幀 cap = cv2.VideoCapture(video_name) # fps為影格率 fps = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) fps_count = 0 for i in range(fps): ret, frame = cap.read() if ret: # 將幀畫面寫入圖片檔案中 cv2.imwrite(save_name+str(10000+fps_count)+'.jpg',frame) fps_count += 1
此時,視訊逐幀轉換成的圖片資料已經儲存起來,為模型訓練做準備。
4. 模型訓練
首先,我們構建模型結構。
C3D 模型結構我們之前已經介紹過,這裡我們通過 keras 提供的 Conv3D,MaxPool3D,ZeroPadding3D 等函數進行模型的搭建。
from keras.layers import Dense,Dropout,Conv3D,Input,MaxPool3D,Flatten,Activation, ZeroPadding3D from keras.regularizers import l2 from keras.models import Model, Sequential # 輸入資料為 112×112 的圖片,16幀, 3通道 input_shape = (112,112,16,3) # 權重衰減率 weight_decay = 0.005 # 型別數量,我們使用UCF-101 為資料集,所以為101 nb_classes = 101 # 構建模型結構 inputs = Input(input_shape) x = Conv3D(64,(3,3,3),strides=(1,1,1),padding='same', activation='relu',kernel_regularizer=l2(weight_decay))(inputs) x = MaxPool3D((2,2,1),strides=(2,2,1),padding='same')(x) x = Conv3D(128,(3,3,3),strides=(1,1,1),padding='same', activation='relu',kernel_regularizer=l2(weight_decay))(x) x = MaxPool3D((2,2,2),strides=(2,2,2),padding='same')(x) x = Conv3D(128,(3,3,3),strides=(1,1,1),padding='same', activation='relu',kernel_regularizer=l2(weight_decay))(x) x = MaxPool3D((2,2,2),strides=(2,2,2),padding='same')(x) x = Conv3D(256,(3,3,3),strides=(1,1,1),padding='same', activation='relu',kernel_regularizer=l2(weight_decay))(x) x = MaxPool3D((2,2,2),strides=(2,2,2),padding='same')(x) x = Conv3D(256, (3, 3, 3), strides=(1, 1, 1), padding='same', activation='relu',kernel_regularizer=l2(weight_decay))(x) x = MaxPool3D((2, 2, 2), strides=(2, 2, 2), padding='same')(x) x = Flatten()(x) x = Dense(2048,activation='relu',kernel_regularizer=l2(weight_decay))(x) x = Dropout(0.5)(x) x = Dense(2048,activation='relu',kernel_regularizer=l2(weight_decay))(x) x = Dropout(0.5)(x) x = Dense(nb_classes,kernel_regularizer=l2(weight_decay))(x) x = Activation('softmax')(x) model = Model(inputs, x) Using TensorFlow backend. /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:526: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:527: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:528: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:529: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:530: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:535: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version. Instructions for updating: Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
通過 keras 提供的 summary () 方法,列印模型結構。可以看到模型的層構建以及各層的輸入輸出情況。
model.summary()
此處輸出較長,省略
通過 keras 的 input 方法可以檢視模型的輸入形狀,shape 分別為 (batch size, width, height, frames, channels) 。
model.input <tf.Tensor 'input_1:0' shape=(?, 112, 112, 16, 3) dtype=float32>
可以看到模型的資料處理的維度與影象處理模型有一些差別,多了 frames 維度,體現出時序關係在視訊分析中的影響。
接下來,我們開始將圖片檔案轉為訓練需要的資料形式。
# 參照必要的庫 from keras.optimizers import SGD,Adam from keras.utils import np_utils import numpy as np import random import cv2 import matplotlib.pyplot as plt # 自定義callbacks from schedules import onetenth_4_8_12 INFO:matplotlib.font_manager:font search path ['/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/matplotlib/mpl-data/fonts/ttf', '/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/matplotlib/mpl-data/fonts/afm', '/home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/matplotlib/mpl-data/fonts/pdfcorefonts'] INFO:matplotlib.font_manager:generated new fontManager
引數定義
img_path = save_path # 圖片檔案儲存位置 results_path = './results' # 訓練結果儲存位置 if not os.path.exists(results_path): os.mkdir(results_path)
資料集劃分,隨機抽取 4/5 作為訓練集,其餘為驗證集。將檔案資訊分別儲存在 train_list 和 test_list 中,為訓練做準備。
cates = os.listdir(img_path) train_list = [] test_list = [] # 遍歷所有的動作型別 for cate in cates: videos = os.listdir(os.path.join(img_path, cate)) length = len(videos)//5 # 訓練集大小,隨機取視訊檔加入訓練集 train= random.sample(videos, length*4) train_list.extend(train) # 將餘下的視訊加入測試集 for video in videos: if video not in train: test_list.append(video) print("訓練集為:") print( train_list) print("共%d 個視訊\n"%(len(train_list))) print("驗證集為:") print(test_list) print("共%d 個視訊"%(len(test_list)))
此處輸出較長,省略
接下來開始進行模型的訓練。
首先定義資料讀取方法。方法 process_data 中讀取一個 batch 的資料,包含 16 幀的圖片資訊的資料,以及資料的標註資訊。在讀取圖片資料時,對圖片進行隨機裁剪和翻轉操作以完成資料增廣。
def process_data(img_path, file_list,batch_size=16,train=True): batch = np.zeros((batch_size,16,112,112,3),dtype='float32') labels = np.zeros(batch_size,dtype='int') cate_list = os.listdir(img_path) def read_classes(): path = "./classInd.txt" with open(path, "r+") as f: lines = f.readlines() classes = {} for line in lines: c_id = line.split()[0] c_name = line.split()[1] classes[c_name] =c_id return classes classes_dict = read_classes() for file in file_list: cate = file.split("_")[1] img_list = os.listdir(os.path.join(img_path, cate, file)) img_list.sort() batch_img = [] for i in range(batch_size): path = os.path.join(img_path, cate, file) label = int(classes_dict[cate])-1 symbol = len(img_list)//16 if train: # 隨機進行裁剪 crop_x = random.randint(0, 15) crop_y = random.randint(0, 58) # 隨機進行翻轉 is_flip = random.randint(0, 1) # 以16 幀為單位 for j in range(16): img = img_list[symbol + j] image = cv2.imread( path + '/' + img) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = cv2.resize(image, (171, 128)) if is_flip == 1: image = cv2.flip(image, 1) batch[i][j][:][:][:] = image[crop_x:crop_x + 112, crop_y:crop_y + 112, :] symbol-=1 if symbol<0: break labels[i] = label else: for j in range(16): img = img_list[symbol + j] image = cv2.imread( path + '/' + img) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image = cv2.resize(image, (171, 128)) batch[i][j][:][:][:] = image[8:120, 30:142, :] symbol-=1 if symbol<0: break labels[i] = label return batch, labels batch, labels = process_data(img_path, train_list) print("每個batch的形狀為:%s"%(str(batch.shape))) print("每個label的形狀為:%s"%(str(labels.shape))) 每個batch的形狀為:(16, 16, 112, 112, 3) 每個label的形狀為:(16,)
定義 data generator, 將資料批次傳入訓練函數中。
def generator_train_batch(train_list, batch_size, num_classes, img_path): while True: # 讀取一個batch的資料 x_train, x_labels = process_data(img_path, train_list, batch_size=16,train=True) x = preprocess(x_train) # 形成input要求的資料格式 y = np_utils.to_categorical(np.array(x_labels), num_classes) x = np.transpose(x, (0,2,3,1,4)) yield x, y def generator_val_batch(test_list, batch_size, num_classes, img_path): while True: # 讀取一個batch的資料 y_test,y_labels = process_data(img_path, train_list, batch_size=16,train=False) x = preprocess(y_test) # 形成input要求的資料格式 x = np.transpose(x,(0,2,3,1,4)) y = np_utils.to_categorical(np.array(y_labels), num_classes) yield x, y
定義方法 preprocess, 對函數的輸入資料進行影象的標準化處理。
def preprocess(inputs): inputs[..., 0] -= 99.9 inputs[..., 1] -= 92.1 inputs[..., 2] -= 82.6 inputs[..., 0] /= 65.8 inputs[..., 1] /= 62.3 inputs[..., 2] /= 60.3 return inputs # 訓練一個epoch大約需4分鐘 # 類別數量 num_classes = 101 # batch大小 batch_size = 4 # epoch數量 epochs = 1 # 學習率大小 lr = 0.005 # 優化器定義 sgd = SGD(lr=lr, momentum=0.9, nesterov=True) model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy']) # 開始訓練 history = model.fit_generator(generator_train_batch(train_list, batch_size, num_classes,img_path), steps_per_epoch= len(train_list) // batch_size, epochs=epochs, callbacks=[onetenth_4_8_12(lr)], validation_data=generator_val_batch(test_list, batch_size,num_classes,img_path), validation_steps= len(test_list) // batch_size, verbose=1) # 對訓練結果進行儲存 model.save_weights(os.path.join(results_path, 'weights_c3d.h5')) WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. Epoch 1/1 20/20 [==============================] - 442s 22s/step - loss: 28.7099 - acc: 0.9344 - val_loss: 27.7600 - val_acc: 1.0000
5. 模型測試
接下來我們將訓練之後得到的模型進行測試。隨機在 UCF-101 中選擇一個視訊檔作為測試資料,然後對視訊進行取幀,每 16 幀畫面傳入模型進行一次動作預測,並且將動作預測以及預測百分比列印在畫面中並進行視訊播放。
首先,引入相關的庫。
from IPython.display import clear_output, Image, display, HTML import time import cv2 import base64 import numpy as np
構建模型結構並且載入權重。
from models import c3d_model model = c3d_model() model.load_weights(os.path.join(results_path, 'weights_c3d.h5'), by_name=True) # 載入剛訓練的模型
定義函數 arrayshow,進行圖片變數的編碼格式轉換。
def arrayShow(img): _,ret = cv2.imencode('.jpg', img) return Image(data=ret)
進行視訊的預處理以及預測,將預測結果列印到畫面中,最後進行播放。
# 載入所有的類別和編號 with open('./ucfTrainTestlist/classInd.txt', 'r') as f: class_names = f.readlines() f.close() # 讀取視訊檔 video = './videos/v_Punch_g03_c01.avi' cap = cv2.VideoCapture(video) clip = [] # 將視訊畫面傳入模型 while True: try: clear_output(wait=True) ret, frame = cap.read() if ret: tmp = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) clip.append(cv2.resize(tmp, (171, 128))) # 每16幀進行一次預測 if len(clip) == 16: inputs = np.array(clip).astype(np.float32) inputs = np.expand_dims(inputs, axis=0) inputs[..., 0] -= 99.9 inputs[..., 1] -= 92.1 inputs[..., 2] -= 82.6 inputs[..., 0] /= 65.8 inputs[..., 1] /= 62.3 inputs[..., 2] /= 60.3 inputs = inputs[:,:,8:120,30:142,:] inputs = np.transpose(inputs, (0, 2, 3, 1, 4)) # 獲得預測結果 pred = model.predict(inputs) label = np.argmax(pred[0]) # 將預測結果繪製到畫面中 cv2.putText(frame, class_names[label].split(' ')[-1].strip(), (20, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 1) cv2.putText(frame, "prob: %.4f" % pred[0][label], (20, 40), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 1) clip.pop(0) # 播放預測後的視訊 lines, columns, _ = frame.shape frame = cv2.resize(frame, (int(columns), int(lines))) img = arrayShow(frame) display(img) time.sleep(0.02) else: break except: print(0) cap.release()

6.I3D 模型
在之前我們簡單介紹了 I3D 模型,I3D 官方 github 庫提供了在 Kinetics 上預訓練的模型和預測程式碼,接下來我們將體驗 I3D 模型如何對視訊進行預測。
首先,引入相關的包
import numpy as np import tensorflow as tf import i3d WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons If you depend on functionality not listed there, please file an issue.
進行引數的定義
# 輸入圖片大小 _IMAGE_SIZE = 224 # 視訊的幀數 _SAMPLE_VIDEO_FRAMES = 79 # 輸入資料包括兩部分:RGB和光流 # RGB和光流資料已經經過提前計算 _SAMPLE_PATHS = { 'rgb': 'data/v_CricketShot_g04_c01_rgb.npy', 'flow': 'data/v_CricketShot_g04_c01_flow.npy', } # 提供了多種可以選擇的預訓練權重 # 其中,imagenet系列模型從ImageNet的2D權重中拓展而來,其餘為視訊資料下的預訓練權重 _CHECKPOINT_PATHS = { 'rgb': 'data/checkpoints/rgb_scratch/model.ckpt', 'flow': 'data/checkpoints/flow_scratch/model.ckpt', 'rgb_imagenet': 'data/checkpoints/rgb_imagenet/model.ckpt', 'flow_imagenet': 'data/checkpoints/flow_imagenet/model.ckpt', } # 記錄類別檔案 _LABEL_MAP_PATH = 'data/label_map.txt' # 類別數量為400 NUM_CLASSES = 400
定義引數:
- imagenet_pretrained :如果為 True,則呼叫預訓練權重,如果為 False,則呼叫 ImageNet 轉成的權重
imagenet_pretrained = True # 載入動作型別 kinetics_classes = [x.strip() for x in open(_LABEL_MAP_PATH)] tf.logging.set_verbosity(tf.logging.INFO)
構建 RGB 部分模型
rgb_input = tf.placeholder(tf.float32, shape=(1, _SAMPLE_VIDEO_FRAMES, _IMAGE_SIZE, _IMAGE_SIZE, 3)) with tf.variable_scope('RGB', reuse=tf.AUTO_REUSE): rgb_model = i3d.InceptionI3d(NUM_CLASSES, spatial_squeeze=True, final_endpoint='Logits') rgb_logits, _ = rgb_model(rgb_input, is_training=False, dropout_keep_prob=1.0) rgb_variable_map = {} for variable in tf.global_variables(): if variable.name.split('/')[0] == 'RGB': rgb_variable_map[variable.name.replace(':0', '')] = variable rgb_saver = tf.train.Saver(var_list=rgb_variable_map, reshape=True)
構建光流部分模型
flow_input = tf.placeholder(tf.float32,shape=(1, _SAMPLE_VIDEO_FRAMES, _IMAGE_SIZE, _IMAGE_SIZE, 2)) with tf.variable_scope('Flow', reuse=tf.AUTO_REUSE): flow_model = i3d.InceptionI3d(NUM_CLASSES, spatial_squeeze=True, final_endpoint='Logits') flow_logits, _ = flow_model(flow_input, is_training=False, dropout_keep_prob=1.0) flow_variable_map = {} for variable in tf.global_variables(): if variable.name.split('/')[0] == 'Flow': flow_variable_map[variable.name.replace(':0', '')] = variable flow_saver = tf.train.Saver(var_list=flow_variable_map, reshape=True)
將模型聯合,成為完整的 I3D 模型
model_logits = rgb_logits + flow_logits
model_predictions = tf.nn.softmax(model_logits)
開始模型預測,獲得視訊動作預測結果。
預測資料為開篇提供的 RGB 和光流資料:
with tf.Session() as sess: feed_dict = {} if imagenet_pretrained: rgb_saver.restore(sess, _CHECKPOINT_PATHS['rgb_imagenet']) # 載入rgb流的模型 else: rgb_saver.restore(sess, _CHECKPOINT_PATHS['rgb']) tf.logging.info('RGB checkpoint restored') if imagenet_pretrained: flow_saver.restore(sess, _CHECKPOINT_PATHS['flow_imagenet']) # 載入flow流的模型 else: flow_saver.restore(sess, _CHECKPOINT_PATHS['flow']) tf.logging.info('Flow checkpoint restored') start_time = time.time() rgb_sample = np.load(_SAMPLE_PATHS['rgb']) # 載入rgb流的輸入資料 tf.logging.info('RGB data loaded, shape=%s', str(rgb_sample.shape)) feed_dict[rgb_input] = rgb_sample flow_sample = np.load(_SAMPLE_PATHS['flow']) # 載入flow流的輸入資料 tf.logging.info('Flow data loaded, shape=%s', str(flow_sample.shape)) feed_dict[flow_input] = flow_sample out_logits, out_predictions = sess.run( [model_logits, model_predictions], feed_dict=feed_dict) out_logits = out_logits[0] out_predictions = out_predictions[0] sorted_indices = np.argsort(out_predictions)[::-1] print('Inference time in sec: %.3f' % float(time.time() - start_time)) print('Norm of logits: %f' % np.linalg.norm(out_logits)) print('\nTop classes and probabilities') for index in sorted_indices[:20]: print(out_predictions[index], out_logits[index], kinetics_classes[index]) WARNING:tensorflow:From /home/ma-user/anaconda3/envs/TensorFlow-1.13.1/lib/python3.6/site-packages/tensorflow/python/training/saver.py:1266: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version. Instructions for updating: Use standard file APIs to check for files with this prefix. INFO:tensorflow:Restoring parameters from data/checkpoints/rgb_imagenet/model.ckpt INFO:tensorflow:RGB checkpoint restored INFO:tensorflow:Restoring parameters from data/checkpoints/flow_imagenet/model.ckpt INFO:tensorflow:Flow checkpoint restored INFO:tensorflow:RGB data loaded, shape=(1, 79, 224, 224, 3) INFO:tensorflow:Flow data loaded, shape=(1, 79, 224, 224, 2) Inference time in sec: 1.511 Norm of logits: 138.468643 Top classes and probabilities 1.0 41.813675 playing cricket 1.497162e-09 21.49398 hurling (sport) 3.8431236e-10 20.13411 catching or throwing baseball 1.549242e-10 19.22559 catching or throwing softball 1.1360187e-10 18.915354 hitting baseball 8.801105e-11 18.660116 playing tennis 2.4415466e-11 17.37787 playing kickball 1.153184e-11 16.627766 playing squash or racquetball 6.1318893e-12 15.996157 shooting goal (soccer) 4.391727e-12 15.662376 hammer throw 2.2134352e-12 14.9772005 golf putting 1.6307096e-12 14.67167 throwing discus 1.5456218e-12 14.618079 javelin throw 7.6690325e-13 13.917259 pumping fist 5.1929587e-13 13.527372 shot put 4.2681337e-13 13.331245 celebrating 2.7205462e-13 12.880901 applauding 1.8357015e-13 12.487494 throwing ball 1.6134511e-13 12.358444 dodgeball 1.1388395e-13 12.010078 tap dancing