架構與思維:再聊快取擊穿,面試是一場博弈
1 介紹
在之前的一篇文章《一次快取雪崩的災難覆盤》中,我們比較清晰的描述了快取雪崩、穿透、擊穿的各自特徵和解決方案,想詳細瞭解的可以移步。
最近在配合HR篩選候選人,作為大廠的業務方向負責人,招人主要也是我們自己團隊在用,而快取是必不可少的面試選項之一。下面我們就來聊一聊在特定業務場景下快取擊穿和雪崩的應對場景!
2 問題背景
- 一個核心的應用或者服務(比如微信、釘釘、百度APP),高峰QPS是百萬甚至是千萬
★ 分析:上述型別的應用具有很明顯的峰值 高斯分佈的特徵,就是9~10點是使用者早高峰。微信是,百度APP是,釘釘也是,釘釘一般給政企、教學等使用,通用是10點左右峰值期,每天的峰值如下:

- 應用快取了使用者的基本資訊,如(姓名、性別、職業、地址等),假設以為使用者Id為Cache的key,那每個使用者都有一個基礎資訊的快取。
- 因為不知名的原因,導致快取都丟了(可能是快取集體過期、故障導致快取失效、程式bug導致快取誤刪、伺服器重啟導致記憶體清理)。
- 恰巧是存取高峰期(比如9點早高峰),千百萬的請求狂奔而來,查不到快取,透過快取層直接投入資料庫。
- 基於磁碟的資料庫的存取效率,效能,抗擊打能力遠遜於快取記憶體,資料庫很容易被打垮,造成服務雪崩。
4 候選人的各種答案(綜合整理)
4.1 快取預熱
既然是可預見的峰值期,那麼快取預熱是一個好辦法,比如在9 ~ 10點是高峰期,在7 ~ 9點這兩個小時中,可以均勻的把部分快取做上。

缺點:這種僅僅只能解決可預見的快取失效情況。如果是突發快取失效情況,假設在10點高峰期因為某些原因(比如上面說的 故障導致快取失效、程式bug導致快取誤刪、伺服器重啟導致記憶體清理)是沒有效果的。
4.2 非一致的過期時間
快取既然大部分是在高峰期(9~10點)建立的(假設Cache的Expire Time都一樣,比如8h),那很有可能失效時間會很接近。幾乎同一時間一起失效,這樣確實也會引起群起建立的情況,也會導致上面說的擊穿的情況發生。
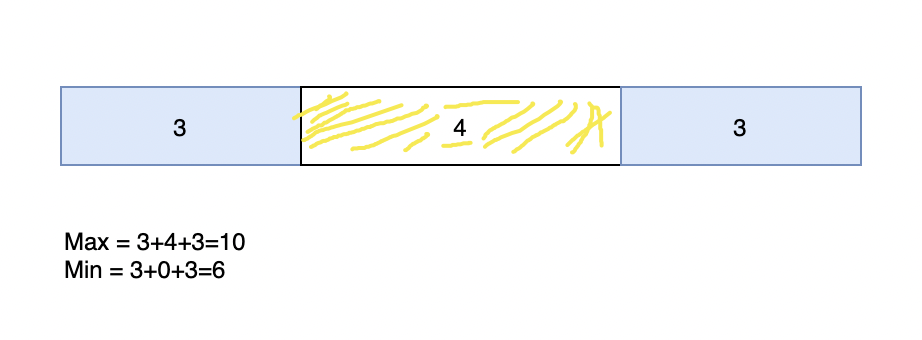
我們在建立同一型別的批次快取的時候,會採用3-4-3 分佈原則。比如一個快取的Expire Time 是 10H,
那麼就是3H + 4H * random() + 3h ,來進行錯開!
缺點:同4.1類似,僅僅解決可預見的問題,對突發故障導致的無預期的快取失效毫無辦法。
4.3 訊息聚合快取
為什麼每個使用者的基本資訊都獨立儲存一個快取呢?可不可以按照使用者型別分片,一類的使用者合在一起不是隻要查詢一次,不會出現峰值期群起攻擊資料庫的情況。
說明:只有資訊修改率非常低的快取才適合聚合在一個快取值中,大部分情況下不會這麼做。比如你的快取中聚合了1W個人的資訊,Value非常大,但凡其中一個資訊修改,那麼這個快取就要更新,不然應用讀取到的資訊就沒有時效性,大Value的快取頻繁的存取是一個很不友好的事情。
使用者資訊還算修改頻率比較低的,你的積分資訊,購物車可是很高頻變動的,這種的就不能這麼幹了。
4.4 削峰、加鎖、限流
4.4.1 削峰
引進訊息佇列之類的中介軟體,將使用者的請求放入佇列,逐一執行,避免擁擠請求!
4.4.2 加鎖
同一個使用者的資訊查詢只讓第一個請求進入,進入之後加鎖,在獲取到資料庫資訊並更新快取之後釋放鎖,
這樣單一個資訊只請求一次!
4.4.3 限流
為了避免把伺服器端打掛,在上線前做一次無快取壓測,看資料庫與伺服器端能支撐的最大值。並設定成限流的閾值,保證不會超過服務所能承載的壓力,避免過載!
缺點:
- 但凡用鎖,排隊之類的方案,無一例外的會大幅度降低服務的吞吐率,造成使用者長時間等待,體驗感下降,這在各大型APP(淘寶、微信、百度APP)上是完全不允許的,也不會這麼幹。
- 限流也是一樣的道理,限流一般是對服務的限流,而難以細粒度到只對某個資訊型別的限流。而服務級別限流會誤傷其他操作,比如獲取排班、排課、獲取購物車等非瓶頸的寬鬆的查詢也被限了。當然,現在的限流也可以細粒度到某個或者某幾個介面,所以可以將查詢使用者資訊合在一個介面裡做一下限流。但是限流也代表部分使用者拿不到正確的資訊,是一種降級的行為。
備註:資料庫也有限流方案,細粒度到這個層級更好
4.5 短暫降級之備選快取
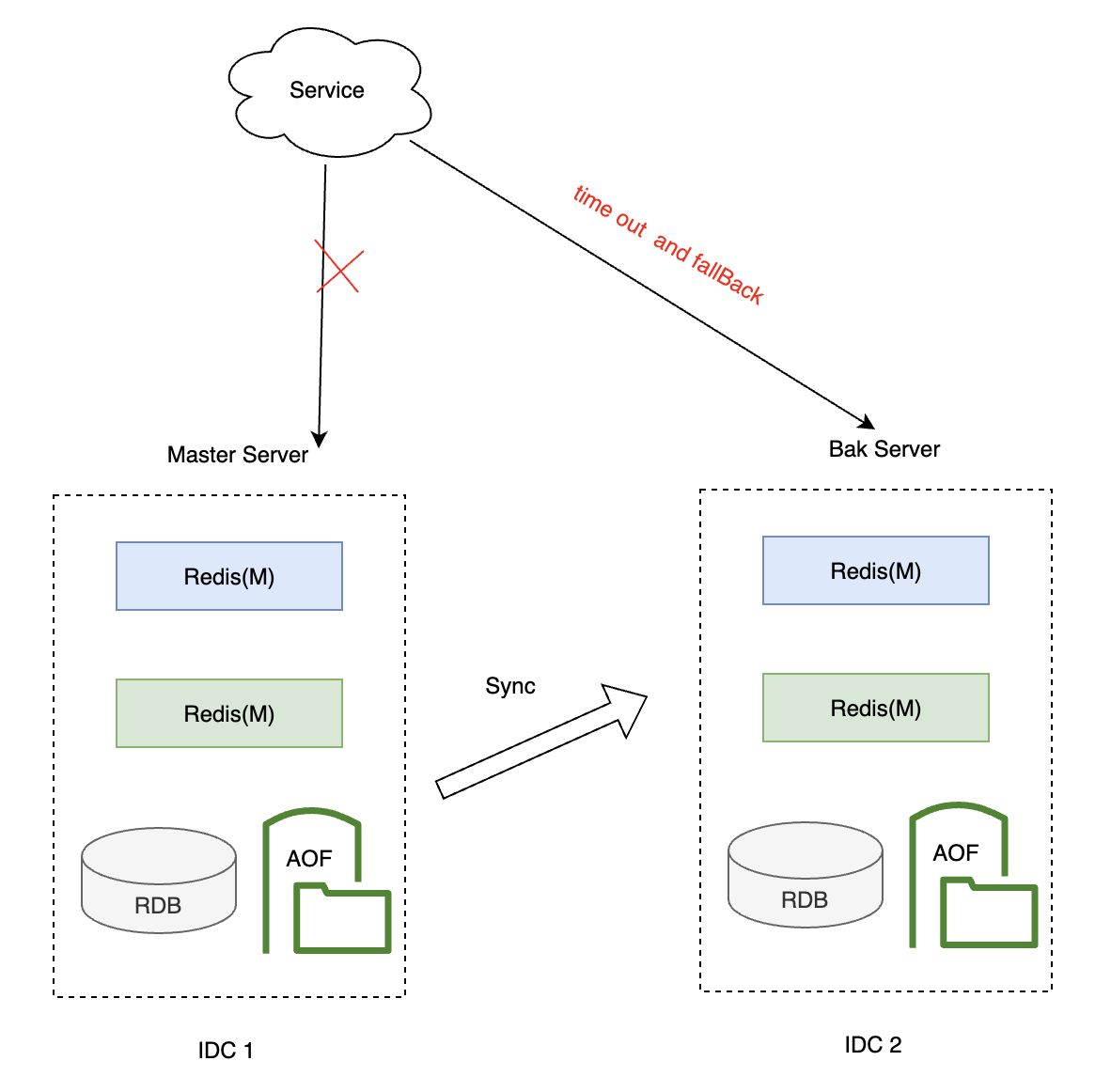
你的快取層存在主備場景,他們之間定時非同步同步,所以存在短暫資料不一致。
當你的主服務掛了之後,降級去讀備服務,資料時效性沒那麼高,但是也避免了資料庫被打穿的情況發生。
4.6 短暫降級值使用者端快取(Redis 6.0)
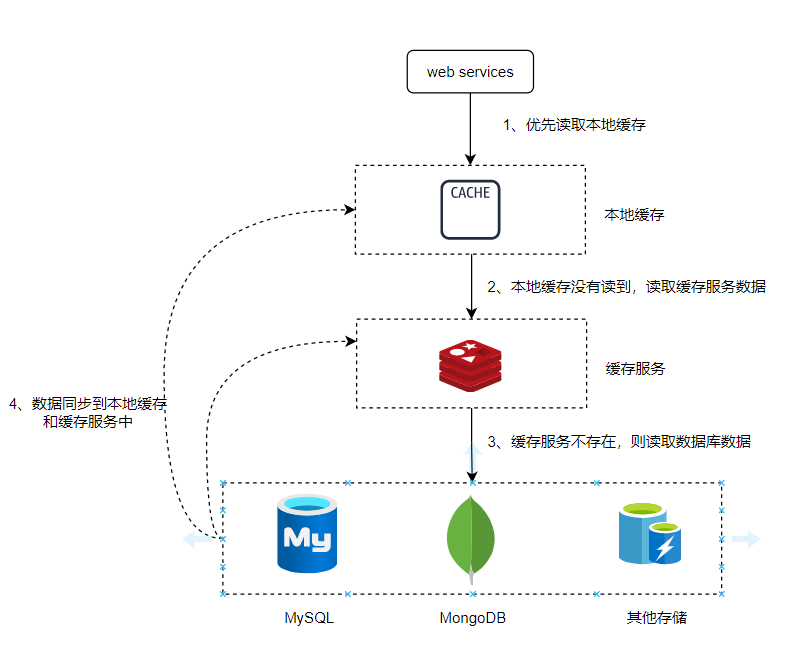
參考Redis 6.0的 Client Side Cache,看我這篇《追求效能極致:使用者端快取帶來的革命》。
類似4.5做法,使用者端快取時效性會差一點,畢竟存在訂閱跟同步的過程,資料沒那麼新。但是避免大量的請求直接上快取服務,又因無效的快取服務有把壓力轉移給資料庫。
4.7 短暫降級之空初始值
這是一種短暫降級的方式,大概流程如下:
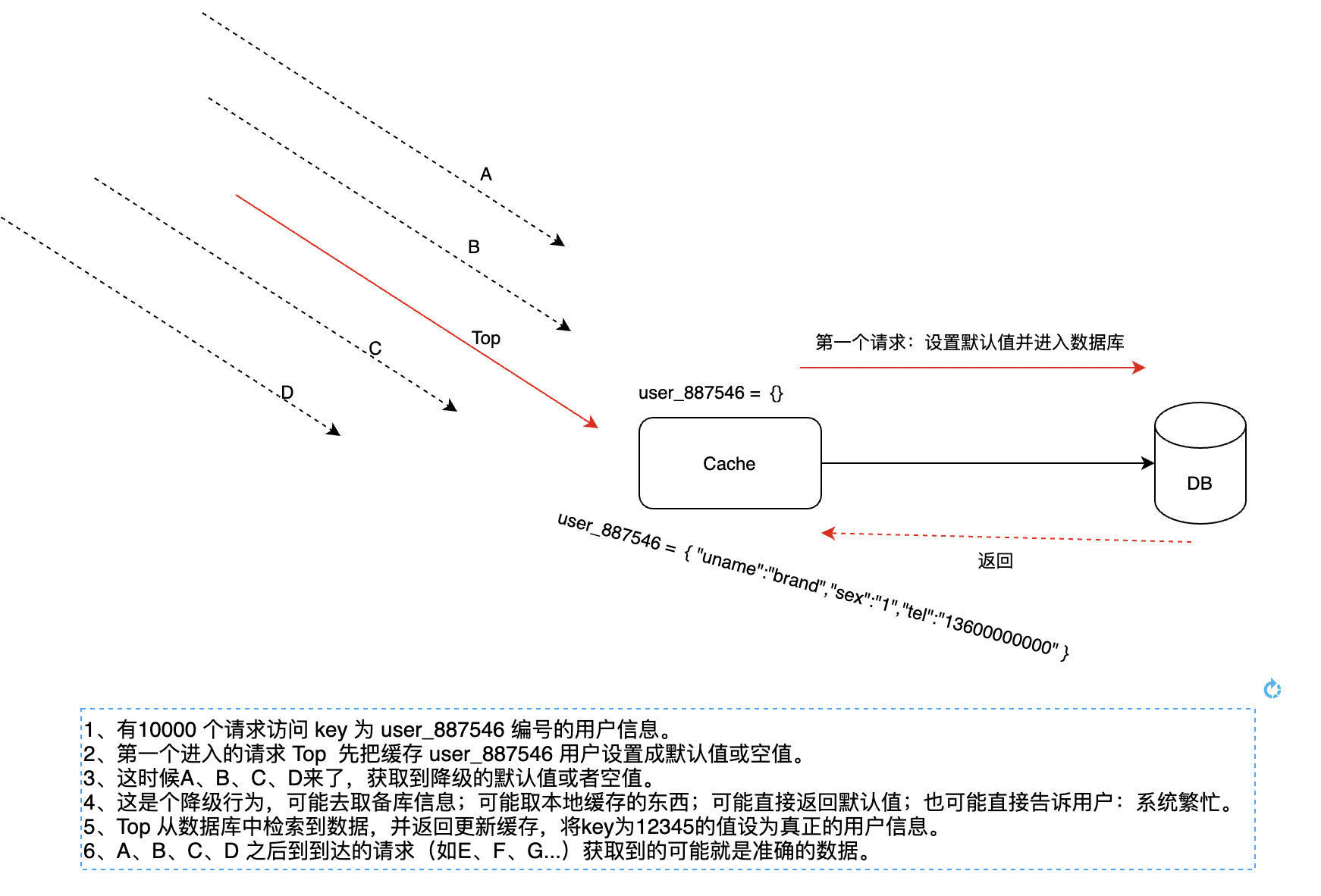
可以看出,整個過程中我們犧牲了A、B、C、D的請求,他們拿回了一個空值或者預設值,但是這區域性的降級卻保證整個資料庫系統不被擁堵的請求擊穿。
5 總結
在不同的場景下各種方法都有各自的優缺點,我們要做的就是根據實際的應用場景來判斷和抉擇。
