Chaos 測試下的若干 NebulaGraph Raft 問題分析

Raft 是一種廣泛使用的分散式共識演演算法。NebulaGraph 底層採用 Raft 演演算法實現 metad 和 storaged 的分散式功能。Raft 演演算法使 NebulaGraph 中的 metad 和 storaged 能夠叢集化部署、實現了多副本和高可用,同時 storaged 通過 multi-raft 模組實現了資料分片,分散了系統的負載,提升系統的吞吐。
作為分散式系統的基石 Raft 有非常明顯的優勢,但這也伴隨著不小的挑戰 —— Raft 演演算法的實現及其容易出錯,同時演演算法的測試和偵錯也是一項巨大的挑戰。NebulaGraph 目前使用的是自研的 Raft,鑑於 Raft 本身的複雜性我們構造了諸多 Chaos 測試來保障 NebulaGraph Raft 演演算法的穩定性。本文介紹幾個我們使用 Chaos 測試發現的 NebulaGraph Raft 中比較有意思的問題。
Raft 背景知識
Raft 是一種廣泛使用的分散式共識演演算法。一個 Raft 叢集中的節點通過執行 Raft 演演算法保證各個節點之間複製紀錄檔序列。演演算法保證各個節點之間的紀錄檔序列是一致的,只要各個節點上的紀錄檔序列一致即可保證各個節點上資料的一致性。
Raft 是一種強主演演算法,系統通過選舉產生一個主節點,使用者向主節點提交紀錄檔,主節點再把紀錄檔複製到其他節點上。當一條紀錄檔複製到過半數的節點上後,Raft 即可認為這條紀錄檔已經提交成功,這條紀錄檔將無法被改寫,Raft 演演算法保證這條紀錄檔後續能被複制到所有節點上。當一個主節點出現故障時,如 Crash、網路中斷等,其他節點會在等待一段時間後發起新的一輪選舉選出主節點,後續由這個新的主節點協調叢集的工作。
Raft 中有一個 Term 概念,Term 是一個單調遞增的非負整數,每個節點都有一個 Term 值,節點在發起選舉前會先遞增原生的 Term。同一個 Term 內最多隻能有一個主節點,否則就意味著 Raft 出現腦裂。「腦裂」在 Raft 中是極其嚴重的故障,它意味著 Raft 的資料安全無法得到保障——兩個主節點可以同時向從節點複製不同的紀錄檔資料,而從節點無條件信任主節點的請求。Term 在 Raft 中是一個邏輯時鐘的概念,更高值的 Term 意味著 Raft 叢集已經進入新時代;當一個 Raft 節點看到更高的 Term 值時需要更新它原生的 Term 值(跟著別人進入新時代),同時轉變為從節點;忽略 Term 的更新可能會導致 Raft 叢集選舉異常,我們後面一個故障的例子即跟這點有關。
NebulaGraph Raft 踩坑記錄
在介紹了 Raft 的背景知識後,本節我們介紹幾個通過 Chaos 測試發現並處理的 NebulaGraph Raft 故障。
執行緒池死鎖問題
這是在 NebulaGraph v2.6 之前發現的一個很有意思的問題。具體情況是,在一個五節點的叢集中執行壓測程式,執行我們的設計好的 Chaos 測試,基本上十幾分鍾後就能看到一個儲存節點狀態變成離線狀態,但檢視離線離線節點卻發現儲存服務還在執行:
(root@nebula) [(none)]> show hosts;
+-----------------+-------+-----------+--------------+----------------------+------------------------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution |
+-----------------+-------+-----------+--------------+----------------------+------------------------+
| "192.168.15.11" | 33299 | "OFFLINE" | 0 | "No valid partition" | "ttos_3p3r:1" |
+-----------------+-------+-----------+--------------+----------------------+------------------------+
| "192.168.15.11" | 54889 | "ONLINE" | 0 | "No valid partition" | "ttos_3p3r:1" |
+-----------------+-------+-----------+--------------+----------------------+------------------------+
| "192.168.15.11" | 34679 | "ONLINE" | 1 | "ttos_3p3r:1" | "ttos_3p3r:1" |
+-----------------+-------+-----------+--------------+----------------------+------------------------+
| "192.168.15.11" | 57211 | "ONLINE" | 0 | "No valid partition" | "ttos_3p3r:1" |
+-----------------+-------+-----------+--------------+----------------------+------------------------+
| "192.168.15.11" | 35767 | "ONLINE" | 0 | "No valid partition" | "ttos_3p3r:1" |
+-----------------+-------+-----------+--------------+----------------------+------------------------+
| "Total" | | | 1 | "ttos_3p3r:1" | "ttos_3p3r:5" |
+-----------------+-------+-----------+--------------+----------------------+------------------------+
Got 6 rows (time spent 1094/12349 us)
Wed, 03 Nov 2021 11:23:48 CST
# ps aux | grep 33299 | grep -v grep
root 2470607 184 0.0 1385496 159800 ? Ssl 10:55 59:11 /data/src/wwl/nebula/build/bin/nebula-storaged --flagfile /data/src/wwl/test/etc/nebula-storaged.conf --pid_file /data/src/wwl/test/pids/nebula-storaged.pid.4 --meta_server_addrs 192.168.15.11:9559 --heartbeat_interval_secs 1 --raft_heartbeat_interval_secs 1 --minloglevel 3 --log_dir /data/src/wwl/test/logs/storaged.4 --local_ip 192.168.15.11 --port 33299 --ws_http_port 53553 --ws_h2_port 46147 --data_path /data/src/wwl/test/data/storaged.4
通過 gdb attach 到離線的儲存服務程序上,我們發現 Raft 向 peer 節點發訊息的模組卡在一個條件變數上:
Thread 37 (Thread 0x7fc8d23fd700 (LWP 2470643) "executor-pri3-3"):
...
#11 0x00007fc8e0f159fd in clone () from /lib64/libc.so.6
Thread 36 (Thread 0x7fc8d24fe700 (LWP 2470642) "executor-pri3-2"):
#0 0x00007fc8e11f0a35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0
#1 0x0000000004ba7a3c in std::condition_variable::wait(std::unique_lock<std::mutex>&) ()
#2 0x0000000003da583e in std::condition_variable::wait<nebula::raftex::Host::reset()::{lambda()#1}>(std::unique_lock<std::mutex>&, nebula::raftex::Host::reset()::{lambda()#1}) (this=0x7fc8c543d3b0, __lock=..., __p=...) at /data/vesoft/toolset/gcc/7.5.0/include/c++/7.5.0/condition_variable:99
#3 0x0000000003d91965 in nebula::raftex::Host::reset (this=0x7fc8c543d310) at /root/nebula-workspace/nebula/src/kvstore/raftex/Host.h:44
#4 0x0000000003d9da15 in nebula::raftex::RaftPart::handleElectionResponses (this=0x7fc8c54df010, voteReq=..., resps=..., hosts=..., proposedTerm=45) at /root/nebula-workspace/nebula/src/kvstore/raftex/RaftPart.cpp:1145
#5 0x0000000003d9cde0 in nebula::raftex::RaftPart::<lambda(auto:132&&)>::operator()<folly::Try<std::vector<std::pair<long unsigned int, nebula::raftex::cpp2::AskForVoteResponse> > > >(folly::Try<std::vector<std::pair<unsigned long, nebula::raftex::cpp2::AskForVoteResponse>, std::allocator<std::pair<unsigned long, nebula::raftex::cpp2::AskForVoteResponse> > > > &&) (__closure=0x7fc8c4c11320, t=...) at /root/nebula-workspace/nebula/src/kvstore/raftex/RaftPart.cpp:1123
#6 0x0000000003db1421 in folly::Future<std::vector<std::pair<unsigned long, nebula::raftex::cpp2::AskForVoteResponse>, std::allocator<std::pair<unsigned long, nebula::raftex::cpp2::AskForVoteResponse> > > >::<lambda(folly::Executor::KeepAlive<folly::Executor>&&, folly::Try<std::vector<std::pair<long unsigned int, nebula::raftex::cpp2::AskForVoteResponse>, std::allocator<std::pair<long unsigned int, nebula::raftex::cpp2::AskForVoteResponse> > > >&&)>::operator()(folly::Executor::KeepAlive<folly::Executor> &&, folly::Try<std::vector<std::pair<unsigned long, nebula::raftex::cpp2::AskForVoteResponse>, std::allocator<std::pair<unsigned long, nebula::raftex::cpp2::AskForVoteResponse> > > > &&) (__closure=0x7fc8c4c11320, t=...) at /data/src/wwl/nebula/build/third-party/install/include/folly/futures/Future-inl.h:947
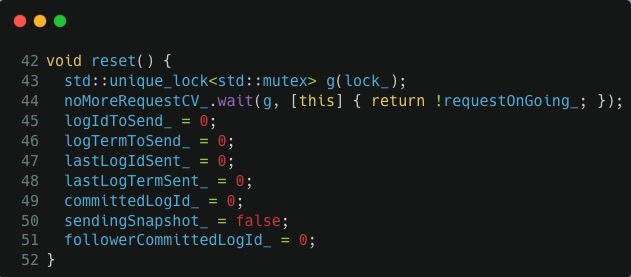
檢視 src/kvstore/raftex/Host.h:44 的具體程式碼,通過分析我們可以知道這個函數正在等待當前所有的 append log 請求結束,也就是 44 行對應的 noMoreRequestCV_.wait() 呼叫,它一直在等待 requestOnGoing_ 變為 false:
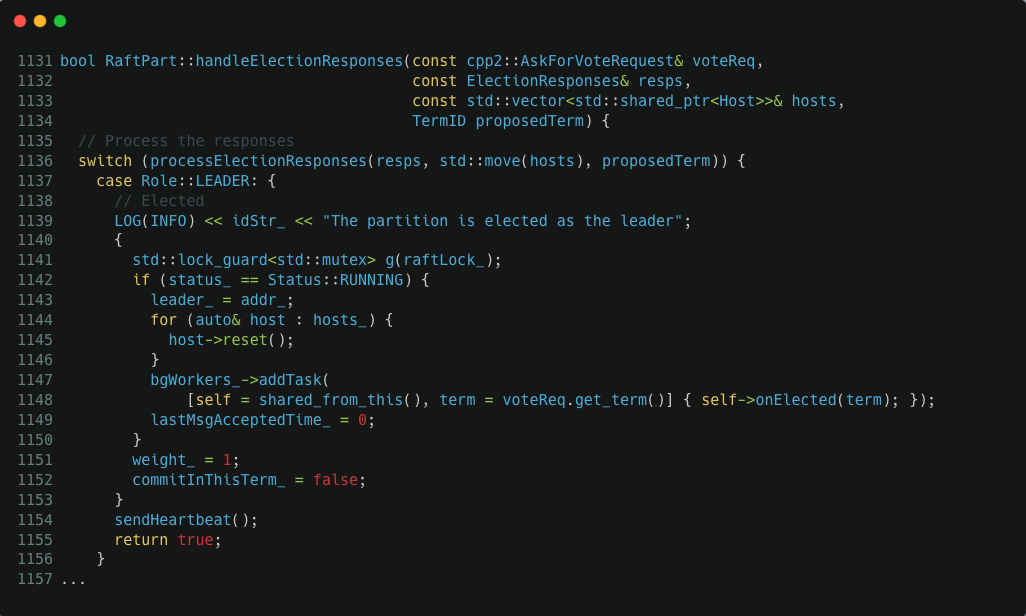
如果我們繼續看堆疊上的前一個呼叫,可以發現 Host.reset() 呼叫前,RaftPart::handleElectionResponses() 在 1141 這行程式碼獲取了 raftLock_ 這個鎖,我們看 src/kvstore/raftex/RaftPart.cpp:1145 中的具體程式碼:
程序不動,說明 requestOnGoing_ 一直都是 true 狀態,通過 gdb attach 進去我們驗證了這個猜測:
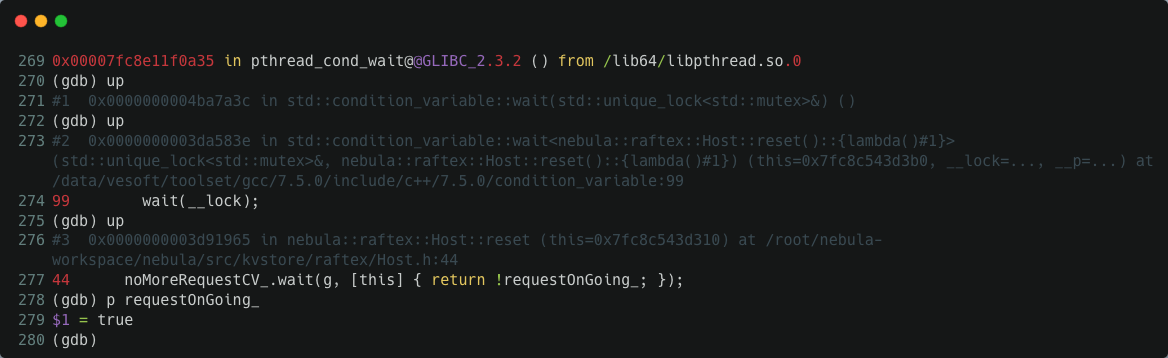
為什麼 requestOnGoing_ 一直都是 true 狀態呢?通過翻閱 src/kvstore/raftex/Host.cpp 中的程式碼,我們可以發現當存在 append log 請求時 requestOnGoing_ 在 Host::appendLogs() 函數中會被設定為 true,當 append log 請求都結束時,這個變數在 Host::appendLogsInternal() 函數中會被設定為 fasle。requestOnGoing_ 值一直不變,那麼,一個合理的猜測是某個 append log 請求卡在 Host::appendLogsInternal() 上了。這個函數本質上乾的活是:
- 通過
sendAppendLogRequest()向 raft peer 發起 append log rpc 請求 - 回撥處理 append log rpc 的結果,處理完了順便在這裡吧
requestOnGoing_變數設定為 false
卡住的一種可能是 rpc 回撥一直沒有返回,但是這邊不大可能。因為我們給 rpc 連結請求都設定了超時,所以這一點基本可以排除。再觀察這個函數,我們可以看到 sendAppendLogRequest(eb, req) 和它的回撥處理用的都是在同一個 eb(EventBase,即 IO 執行緒)中執行,會不會是回撥執行緒中的操作導致死鎖了?
翻了無數遍程式碼,看不出明顯的關聯關係,最後想到一個辦法是通過打紀錄檔進一步觀察執行細節。appendLogsInternal() 呼叫 sendAppendLogRequest() 並在 eb 這個 IO 執行緒中執行,我們把每個 appendLogsInternal() 請求和當前的時間戳關聯。然後設法把 eb 的執行緒 id 列印出來,並在 sendAppendLogRequest() 處理結果的回撥中也列印出對應的 tid(這裡還要考慮跑異常的情況)。這樣一來,如果 appendLogsInternal() 中沒有發生死鎖,我們必然能看到結果回撥中列印的 eb 的 tid:
void Host::appendLogsInternal(folly::EventBase* eb, std::shared_ptr<cpp2::AppendLogRequest> req) {
using TransportException = apache::thrift::transport::TTransportException;
auto reqId = std::chrono::high_resolution_clock::now().time_since_epoch().count();
pid_t thisTid = syscall(__NR_gettid);
std::cerr << folly::format("append with req: {}, started within thread {}", reqId, thisTid) << std::endl;
eb->runImmediatelyOrRunInEventBaseThreadAndWait([reqId]() {
pid_t tid = syscall(__NR_gettid);
std::cerr << folly::format("append log req {} will run within thread {}", reqId, tid) << std::endl;
});
sendAppendLogRequest(eb, req)
.via(eb)
.thenValue([eb, self = shared_from_this(), reqId](cpp2::AppendLogResponse&& resp) {
pid_t tid = syscall(__NR_gettid);
std::cerr << folly::format("append log req {} done within thread {}", reqId, tid) << std::endl;
...
})
.thenError(folly::tag_t<TransportException>{},
[reqId, self = shared_from_this(), req](TransportException&& ex) {
pid_t tid = syscall(__NR_gettid);
std::cerr << folly::format("append log req {} encounter exception {} within thread {}", reqId, ex.what(), tid) << std::endl;
VLOG(2) << self->idStr_ << ex.what();
cpp2::AppendLogResponse r;
...
return;
})
.thenError(folly::tag_t<std::exception>{}, [self = shared_from_this(), reqId](std::exception&& ex) {
pid_t tid = syscall(__NR_gettid);
std::cerr << folly::format("append log req {} encounter exception {} within thread {}", reqId, ex.what(), tid) << std::endl;
VLOG(2) << self->idStr_ << ex.what();
...
return;
});
}
重新跑測試,很快我們又觀察到死鎖的情況。通過死鎖程序的紀錄檔,我們看到 Host::appendLogsInternal() 確實卡住了:
...
append log req 1635908498110971639 done within thread 2470665
append with req: 1635908526021106910, started within thread 2470665
append log req 1635908526021106910 will run within thread 2470665
1635908526021106910 對應的 append 請求執行線上程 2470665 上,處理結果的時候卡住了,gdb attach 進去看 2470665 這個程序在幹嘛:
Thread 1 (Thread 0x7fc8c15ff700 (LWP 2470665) "IOThreadPool9"):
#0 0x00007fc8e11f354d in __lll_lock_wait () from /lib64/libpthread.so.0
#1 0x00007fc8e11eee9b in _L_lock_883 () from /lib64/libpthread.so.0
#2 0x00007fc8e11eed68 in pthread_mutex_lock () from /lib64/libpthread.so.0
#3 0x0000000002a655d4 in __gthread_mutex_lock (__mutex=0x7fc8c54df150) at /data/vesoft/toolset/gcc/7.5.0/include/c++/7.5.0/x86_64-vesoft-linux/bits/gthr-default.h:748
#4 0x0000000002a658d6 in std::mutex::lock (this=0x7fc8c54df150) at /data/vesoft/toolset/gcc/7.5.0/include/c++/7.5.0/bits/std_mutex.h:103
#5 0x0000000002a6b43f in std::lock_guard<std::mutex>::lock_guard (this=0x7fc8c15fbbb8, __m=...) at /data/vesoft/toolset/gcc/7.5.0/include/c++/7.5.0/bits/std_mutex.h:162
#6 0x0000000003da1de2 in nebula::raftex::RaftPart::processHeartbeatRequest (this=0x7fc8c54df010, req=..., resp=...) at /root/nebula-workspace/nebula/src/kvstore/raftex/RaftPart.cpp:1650
#7 0x0000000003de1822 in nebula::raftex::RaftexService::async_eb_heartbeat (this=0x7fc8e0a32ab0, callback=..., req=...) at /root/nebula-workspace/nebula/src/kvstore/raftex/RaftexService.cpp:220
#8 0x0000000003e931dd in nebula::raftex::cpp2::RaftexServiceAsyncProcessor::process_heartbeat<apache::thrift::CompactProtocolReader, apache::thrift::CompactProtocolWriter> (this=0x7fc8d1702160, req=..., serializedRequest=..., ctx=0x7fc8c0940b10, eb=0x7fc8c0804000, tm=0x7fc8e0a142b0) at /root/nebula-workspace/nebula/build/src/interface/gen-cpp2/RaftexService.tcc:220
#9 0x0000000003e8ec96 in nebula::raftex::cpp2::RaftexServiceAsyncProcessor::setUpAndProcess_heartbeat<apache::thrift::CompactProtocolReader, apache::thrift::CompactProtocolWriter> (this=0x7fc8d1702160, req=..., serializedRequest=..., ctx=0x7fc8c0940b10, eb=0x7fc8c0804000, tm=0x7fc8e0a142b0) at /root/nebula-workspace/nebula/build/src/interface/gen-cpp2/RaftexService.tcc:198
...
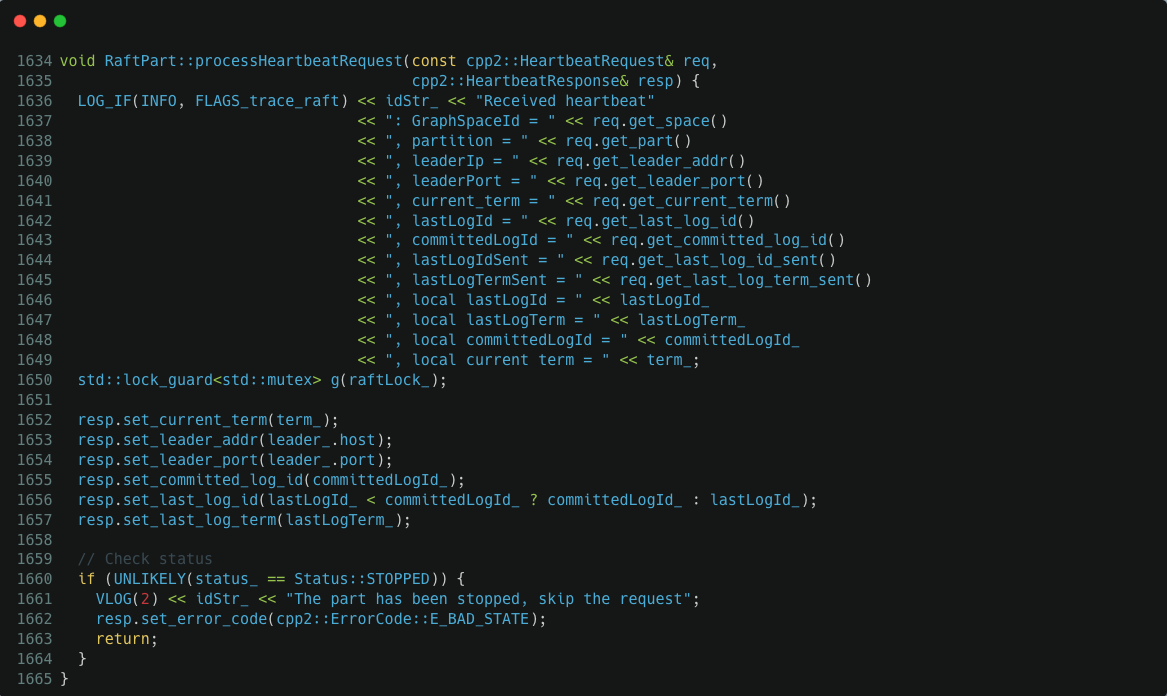
從堆疊上看,它被排程去處理 Raft heartbeat 請求了,然後它卡在 /root/nebula-workspace/nebula/src/kvstore/raftex/RaftPart.cpp:1650 上了,1650 這行程式碼正要獲取 raftLock_ 鎖,raft 完美死鎖了:
NebulaGraph 大量使用執行緒池來處理非同步回撥任務。總結以上問題就是在兩個執行緒池工作執行緒中:
- worker thread 1 執行以下回撥
- 拿到鎖 lock,等待在條件變數上;
- worker thread 2 執行以下回撥
- 嘗試獲取,然後執行後續任務;
- 修改資料並啟用條件變數;
因為 worker thread 2 先執行任務 a 也就是需要先獲取所,再執行回撥 b 以啟用條件變數,這種呼叫順序構成了一個非常隱蔽的死鎖場景。在使用執行緒池處理非同步回撥的設計中,如果並行加鎖的處理稍不留意可能就會踩到類似的坑上,而 NebulaGraph Raft 各項操作都是構建在非同步執行緒池的基礎上,並且包含各種複雜的加鎖操作。我們在修復這個問題後又陸陸續續在 NebulaGraph 上修復了多起類似的故障。
Raft 緩衝區死鎖問題
這也是 v2.6 之前我們通過 Chaos 測試用例發現的一個問題。執行一段時間後終止測試程式,等系統 CPU、磁碟 IO 等各項負載都空閒下來後,我們在 NebulaGraph 執行以一些簡單的查詢操作,我們發現 NebulaGraph 永遠都返回 Leader change 錯誤。檢視 NebulaGraph 紀錄檔,我們發現它在瘋狂報 Raft buffer overflow 錯誤:
W1019 08:26:21.220441 539751 RaftPart.cpp:601] [Port: 50944, Space: 3, Part: 1] The appendLog buffer is full. Please slow down the log appending rate.replicatingLogs_ :0
W1019 08:26:54.569221 539751 RaftPart.cpp:601] [Port: 50944, Space: 3, Part: 1] The appendLog buffer is full. Please slow down the log appending rate.replicatingLogs_ :0
W1019 08:27:27.919421 539751 RaftPart.cpp:601] [Port: 50944, Space: 3, Part: 1] The appendLog buffer is full. Please slow down the log appending rate.replicatingLogs_ :0
W1019 08:28:01.268051 539751 RaftPart.cpp:601] [Port: 50944, Space: 3, Part: 1] The appendLog buffer is full. Please slow down the log appending rate.replicatingLogs_ :0
W1019 08:28:34.615942 539751 RaftPart.cpp:601] [Port: 50944, Space: 3, Part: 1] The appendLog buffer is full. Please slow down the log appending rate.replicatingLogs_ :0
rate.replicatingLogs_ :0 表示 raft 沒有在複製紀錄檔。raft 緩衝區溢位說明有大量資料等待複製,但它卻沒有在複製紀錄檔,看起來就是個 bug。 我們發現穩定下來後 Raft 叢集主節點穩定,沒有出現切主行為,至少說明 Raft 選舉模組還是正常的。所以,從上面的紀錄檔看來大概率是紀錄檔複製模組被 Chaos 測試玩壞了。
首先我們看 NebulaGraph Raft 中的對 append log 的處理:
folly::Future<AppendLogResult> RaftPart::appendLogAsync(ClusterID source,
LogType logType,
std::string log,
AtomicOp op) {
if (blocking_) {
// No need to block heartbeats and empty log.
if ((logType == LogType::NORMAL && !log.empty()) || logType == LogType::ATOMIC_OP) {
return AppendLogResult::E_WRITE_BLOCKING;
}
}
LogCache swappedOutLogs;
auto retFuture = folly::Future<AppendLogResult>::makeEmpty();
if (bufferOverFlow_) {
LOG_EVERY_N(WARNING, 100) << idStr_
<< "The appendLog buffer is full."
" Please slow down the log appending rate."
<< "replicatingLogs_ :" << replicatingLogs_;
return AppendLogResult::E_BUFFER_OVERFLOW;
}
{
std::lock_guard<std::mutex> lck(logsLock_);
VLOG(2) << idStr_ << "Checking whether buffer overflow";
if (logs_.size() >= FLAGS_max_batch_size) {
// Buffer is full
LOG(WARNING) << idStr_
<< "The appendLog buffer is full."
" Please slow down the log appending rate."
<< "replicatingLogs_ :" << replicatingLogs_;
bufferOverFlow_ = true;
return AppendLogResult::E_BUFFER_OVERFLOW;
}
VLOG(2) << idStr_ << "Appending logs to the buffer";
...
bool expected = false;
if (replicatingLogs_.compare_exchange_strong(expected, true)) {
// We need to send logs to all followers
VLOG(2) << idStr_ << "Preparing to send AppendLog request";
sendingPromise_ = std::move(cachingPromise_);
cachingPromise_.reset();
std::swap(swappedOutLogs, logs_);
bufferOverFlow_ = false;
} else {
VLOG(2) << idStr_ << "Another AppendLogs request is ongoing, just return";
return retFuture;
}
}
...
AppendLogsIterator it(firstId, termId, std::move(sendingLogs_));
appendLogsInternal(std::move(it), termId);
return retFuture;
}
這個函數一旦看到 bufferOverFlow_ 變數值是 true,便認為緩衝區滿了,直接報錯返回了。否則把要複製的紀錄檔先塞到緩衝區 logs_ 中。如果緩衝區滿了就設定 bufferOverFlow_ = true。接下來,測試 replicatingLogs_ 這個變數,true 說明已經有活動的非同步回撥在執行紀錄檔複製可以直接返回,否則在函數末尾呼叫 appendLogsInternal() 真正啟動 raft 紀錄檔複製操作。另一方面,當向 peer 節點複製紀錄檔的操作收到成功的響應後 NebulaGraph raft 會呼叫 checkAppendLogResult() 來處理結果。這個函數清空 raft 紀錄檔緩衝區,把 bufferOverFlow_ 和 replicatingLogs_ 重置為 false。
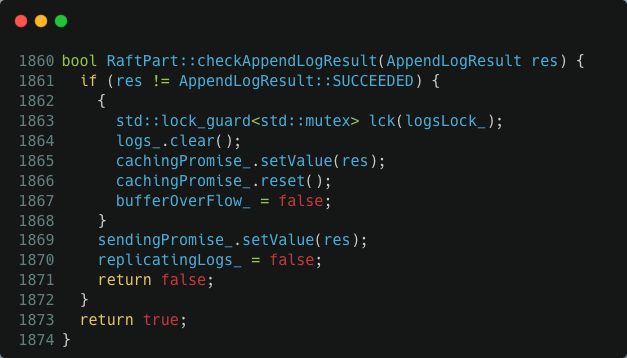
以上是 raft 紀錄檔複製的核心操作邏輯。需要注意的是,appendLogAsync() 和 checkAppendLogResult() 都是非同步並行執行的,最後意味著 bufferOverFlow_ 和 replicatingLogs_ 變數的更新需要鎖的保護,這裡用的是 logsLock_ 這個鎖。瞭解這個資訊後,我們再來看 checkAppendLogResult() 這個函數就會發現一個非常微妙的加鎖問題:replicatingLogs_ = false 這行程式碼是在沒有 logsLock_ 鎖保護的情況下執行的。如果使用者端的並行請求足夠高,那麼在 checkAppendLogResult() 釋放鎖和執行 replicatingLogs_ = false 這個間隙完全有可能把緩衝區打滿,然後把 bufferOverFlow_ 設定為 true。這個也就是我們開頭看到的,紀錄檔緩衝區滿了但 raft 卻沒有在執行紀錄檔複製場景,這種情況下所有的操作都會報緩衝區溢位錯誤,這個幾點基本就報銷了只能重啟。修復也非常容易,把 checkAppendLogResult() 中的 replicatingLogs_ = false 語句放在 logsLock_ 鎖的保護下執行即可。
Raft 選舉死鎖問題
這又是通過 Chaos 測試跑出來的一個 NebulaGraph Raft v2.6 之前版本的故障。我們構造了一個七節點的 Raft 叢集,在測試中我們發現,系統掛了三個節點後,另外四個節點再也無法選主了。我們把四個無法選主的節點和對應的伺服器埠篩選出來:
storage.0 : 54774
storage.2 : 39620
storage.3 : 48140
storage.5 : 33124
通過紀錄檔發現了一些很有意思的事情:

從紀錄檔上 storage.0 拒絕了 storage.5 的 vote request,因為 storage.5 的 term 1836 遠遠落後於其他節點的 term 1967、1968,投票請求被拒絕是意料之中。另一方面 storage.5 上的紀錄檔比其他三個節點都新,根據 raft 的選舉規則只有 storage.5 才能當選 leader。為什麼 storage.5 的 term 上不去,按道理在 storage.5 收到其他節點的 request vote 請求後就應該立即更新原生的 term 了?我們 review NebulaGraph Raft 中對 vote 請求的處理髮現了其中的問題:
void RaftPart::processAskForVoteRequest(const cpp2::AskForVoteRequest& req,
cpp2::AskForVoteResponse& resp) {
LOG(ERROR) << idStr_ << "Recieved a VOTING request"
<< ": space = " << req.get_space() << ", partition = " << req.get_part()
<< ", candidateAddr = " << req.get_candidate_addr() << ":" << req.get_candidate_port()
<< ", term = " << req.get_term() << ", lastLogId = " << req.get_last_log_id()
<< ", lastLogTerm = " << req.get_last_log_term();
std::lock_guard<std::mutex> g(raftLock_);
...
// Check the last term to receive a log
if (req.get_last_log_term() < lastLogTerm_) {
LOG(ERROR) << idStr_ << "The partition's last term to receive a log is " << lastLogTerm_
<< ", which is newer than the candidate's log " << req.get_last_log_term()
<< ". So the candidate will be rejected";
resp.set_error_code(cpp2::ErrorCode::E_TERM_OUT_OF_DATE);
return;
}
...
return;
}
我們發現 NebulaGraph Raft 處理選舉請求的時候,如果 candidate 的 log 比自己的 log 舊,raft 會直接拒絕這個請求。這個操作邏輯上沒問題,但是 Raft 論文裡要求一個 Raft 範例一旦遇到比自己 term 大的請求要立馬 update 自己的 term,這個函數裡執行這步操作了嗎?顯然沒有,判斷紀錄檔比自己舊後就直接 return 了,這種處理導致叢集永遠無法選出主節點。這個問題的修復也容易,再處理 request vote 請求的時候及時更新本地 term 即可。不過,如果在叢集出問題的時候放任 term 無序遞增也不是個好辦法。所以,我們在修復這個問題的時候順便把 Raft prevote 特性也加上去,讓 NebulaGraph 的 Raft 更加穩定。
Raft 資料不一致問題
我們的 Chaos 測試發現 v2.6 版本之前的 NebulaGraph Raft 中存在資料不一致的問題,而且可以穩定復現!以下是在一次測試中發現的 NebulaGraph Raft 紀錄檔資料和 NebulaGraph 資料不一致的情況:
1c1
< /data/src/nebula-cluster/data/data/store1/nebula/1/wal/1
---
> /data/src/nebula-cluster/data/data/store2/nebula/1/wal/1
293702,293720c293702,293720
< log index: 293701, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293702, term: 694, logsz: 57, cluster_id: 0, walfile:
< log index: 293703, term: 694, logsz: 57, cluster_id: 0, walfile:
< log index: 293704, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293705, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293706, term: 694, logsz: 57, cluster_id: 0, walfile:
< log index: 293707, term: 694, logsz: 57, cluster_id: 0, walfile:
< log index: 293708, term: 694, logsz: 57, cluster_id: 0, walfile:
< log index: 293709, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293710, term: 694, logsz: 57, cluster_id: 0, walfile:
< log index: 293711, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293712, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293713, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293714, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293715, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293716, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293717, term: 694, logsz: 57, cluster_id: 0, walfile:
< log index: 293718, term: 694, logsz: 55, cluster_id: 0, walfile:
< log index: 293719, term: 695, logsz: 0, cluster_id: 0, walfile:
---
> log index: 293701, term: 696, logsz: 53, cluster_id: 0, walfile:
> log index: 293702, term: 696, logsz: 55, cluster_id: 0, walfile:
> log index: 293703, term: 696, logsz: 59, cluster_id: 0, walfile:
> log index: 293704, term: 696, logsz: 57, cluster_id: 0, walfile:
> log index: 293705, term: 696, logsz: 55, cluster_id: 0, walfile:
> log index: 293706, term: 696, logsz: 57, cluster_id: 0, walfile:
> log index: 293707, term: 696, logsz: 57, cluster_id: 0, walfile:
> log index: 293708, term: 696, logsz: 59, cluster_id: 0, walfile:
> log index: 293709, term: 696, logsz: 55, cluster_id: 0, walfile:
> log index: 293710, term: 696, logsz: 57, cluster_id: 0, walfile:
> log index: 293711, term: 696, logsz: 55, cluster_id: 0, walfile:
> log index: 293712, term: 696, logsz: 55, cluster_id: 0, walfile:
> log index: 293713, term: 696, logsz: 55, cluster_id: 0, walfile:
> log index: 293714, term: 696, logsz: 57, cluster_id: 0, walfile:
> log index: 293715, term: 696, logsz: 57, cluster_id: 0, walfile:
> log index: 293716, term: 696, logsz: 57, cluster_id: 0, walfile:
> log index: 293717, term: 696, logsz: 57, cluster_id: 0, walfile:
> log index: 293718, term: 696, logsz: 55, cluster_id: 0, walfile:
> log index: 293719, term: 696, logsz: 53, cluster_id: 0, walfile:
可以看到,同一個 index 下,raft 紀錄檔的 term 和 size 值都存在差異,有 19 條 raft log 不一致!
comparing /Users/from-vesoft-with-love/src/toss_integration/data/store1/nebula/1/data to /Users/wenlinwu/src/toss_integration/data/store2/nebula/1/data
size mismatch: 489347, 489348
/Users/from-vesoft-with-love/src/toss_integration/data/store2/nebula/1/data missing keys:
b'\x06\x01\x00\x00key-1-12197-340'
b'\x06\x01\x00\x00key-1-11350-767'
b'\x06\x01\x00\x00key-1-12553-44'
b'\x06\x01\x00\x00key-1-10677-952'
b'\x06\x01\x00\x00key-1-13514-912'
b'\x06\x01\x00\x00key-1-9430-782'
b'\x06\x01\x00\x00key-1-18022-735'
b'\x06\x01\x00\x00key-1-7029-104'
b'\x06\x01\x00\x00key-1-4530-867'
b'\x06\x01\x00\x00key-1-8658-248'
b'\x06\x01\x00\x00key-1-8489-415'
b'\x06\x01\x00\x00key-1-2345-956'
b'\x06\x01\x00\x00key-1-8213-336'
b'\x06\x01\x00\x00key-1-8330-687'
b'\x06\x01\x00\x00key-1-9470-108'
b'\x06\x01\x00\x00key-0-62674-143'
b'\x06\x01\x00\x00key-1-12613-884'
b'\x06\x01\x00\x00key-1-8860-507'
/Users/from-vesoft-with-love/src/toss_integration/data/store1/nebula/1/data missing keys:
b'\x06\x01\x00\x00key-1-9504-429'
b'\x06\x01\x00\x00key-1-15925-489'
b'\x06\x01\x00\x00key-1-17467-978'
b'\x06\x01\x00\x00key-1-14189-663'
b'\x06\x01\x00\x00key-1-6414-170'
b'\x06\x01\x00\x00key-1-11835-136'
b'\x06\x01\x00\x00key-1-10409-874'
b'\x06\x01\x00\x00key-1-6672-385'
b'\x06\x01\x00\x00key-1-17840-561'
b'\x06\x01\x00\x00key-1-13118-1010'
b'\x06\x01\x00\x00key-1-7707-630'
b'\x06\x01\x00\x00key-1-5606-677'
b'\x06\x01\x00\x00key-1-10107-197'
b'\x06\x01\x00\x00key-0-64103-1001'
b'\x06\x01\x00\x00key-1-6373-99'
b'\x06\x01\x00\x00key-1-940-285'
b'\x06\x01\x00\x00key-1-10802-736'
b'\x06\x01\x00\x00key-1-7087-647'
b'\x06\x01\x00\x00key-1-3020-441'
diff 1-2: []
NebulaGraph 寫入的資料有 18 條不一致,和 Raft log 中的不一致的資料條目非常接近。Raft 資料不一致的問題處理起來非常棘手。不過,我們通過不斷地優化 Chaos 測試用例,讓問題可以在短時間內穩定復現。不管是紀錄檔還是 gdb 一時都沒有太清晰的策略去對付這個問題。後來我們想到了 Mozilla RR。RR 可以把整個程式的執行過程錄製下來,然後重複播放執行,而且產生相同的執行結果。我們可以用 RR 把 Raft 資料不一致的故障錄製下來。通過 RR 的執行過程回放,我們發現 NebulaGraph Raft 在處理選舉請求的時候會錯誤地把一個本應該變成 follower 的 leader 節點升級成下一個 term 的 leader:
void RaftPart::processAskForVoteRequest(const cpp2::AskForVoteRequest& req,
cpp2::AskForVoteResponse& resp) {
LOG(INFO) << idStr_ << "Received a VOTING request"
<< ": space = " << req.get_space() << ", partition = " << req.get_part()
<< ", candidateAddr = " << req.get_candidate_addr() << ":" << req.get_candidate_port()
<< ", term = " << req.get_term() << ", lastLogId = " << req.get_last_log_id()
<< ", lastLogTerm = " << req.get_last_log_term()
<< ", isPreVote = " << req.get_is_pre_vote();
std::lock_guard<std::mutex> g(raftLock_);
...
auto oldTerm = term_;
// req.get_term() >= term_, we won't update term in prevote
if (!req.get_is_pre_vote()) {
term_ = req.get_term();
}
// Check the last term to receive a log
if (req.get_last_log_term() < lastLogTerm_) {
LOG(INFO) << idStr_ << "The partition's last term to receive a log is " << lastLogTerm_
<< ", which is newer than the candidate's log " << req.get_last_log_term()
<< ". So the candidate will be rejected";
resp.set_error_code(cpp2::ErrorCode::E_TERM_OUT_OF_DATE);
return;
}
...
}
看以上程式碼,一個 leader 的 term 可能直接被 update 變成下一個 term 的 leader,它本應當變成 follower 的。這樣以來 Raft 直接腦裂了,腦裂的兩個 leader 分別提交了不一樣的資料上去,也就造成了上面的資料不一致問題。
以上。
謝謝你讀完本文 (///▽///)
如果你想嚐鮮圖資料庫 NebulaGraph,記得去 GitHub 下載、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 使用者一起交流圖資料庫技術和應用技能,留下「你的名片」一起玩耍呀~