Backbone 網路-DenseNet 論文解讀
目錄
摘要
ResNet 的工作表面,只要建立前面層和後面層之間的「短路連線」(shortcut),就能有助於訓練過程中梯度的反向傳播,從而能訓練出更「深」的 CNN 網路。DenseNet 網路的基本思路和 ResNet 一致,但是它建立的是前面所有層與後面層的密集連線(dense connection)。傳統的 \(L\) 層折積網路有 \(L\) 個連線——每一層與它的前一層和後一層相連—,而 DenseNet 網路有 \(L(L+1)/2\) 個連線。
在 DenseNet 中,讓網路中的每一層都直接與其前面層相連,實現特徵的重複利用;同時把網路的每一層設計得特別「窄」(特徵圖/濾波器數量少),即只學習非常少的特徵圖(最極端情況就是每一層只學習一個特徵圖),達到降低冗餘性的目的。
網路結構
DenseNet 模型主要是由 DenseBlock 組成的。
用公式表示,傳統直連(plain)的網路在 \(l\) 層的輸出為:
對於殘差塊(residual block)結構,增加了一個恆等對映(shortcut 連線):
而在密集塊(DenseBlock)結構中,每一層都會將前面所有層 concate 後作為輸入:
\([\mathrm{\mathrm{x_0},\mathrm{x_1},...,\mathrm{x_{l-1}}]}\) 表示網路層 \(0,...,l-1\) 輸出特徵圖的拼接。這裡暗示了,在 DenseBlock 中,每個網路層的特徵圖大小是一樣的。\(H_l(\cdot)\) 是非線性轉化函數(non-liear transformation),它由 BN(Batch Normalization),ReLU 和 Conv 層組合而成。
DenseBlock 的結構圖如下圖所示。
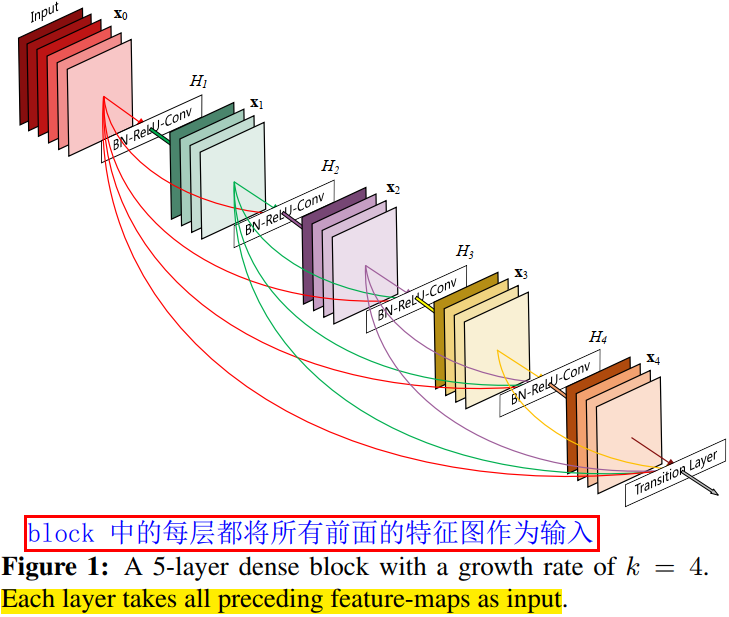
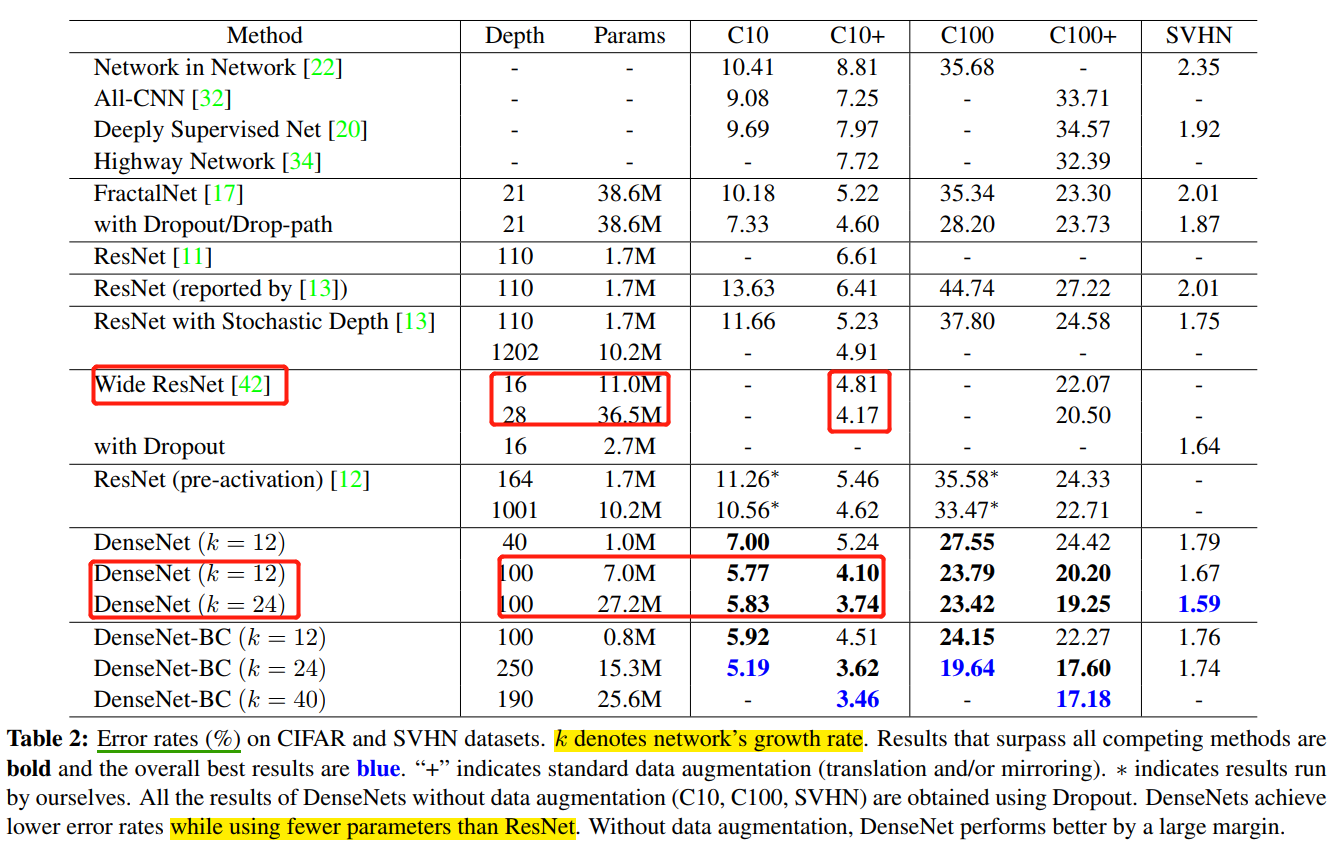
在 DenseBlock 的設計中,作者重點提到了一個引數 \(k\),被稱為網路的增長率(growth of the network),其實是 DenseBlock 中任何一個 \(3\times 3\) 折積層的濾波器個數(輸出通道數)。如果每個 \(H_l(\cdot)\) 函數都輸出 \(k\) 個特徵圖,那麼第 \(l\) 層的輸入特徵圖數量為 \(k_0 + k\times (l-1)\),\(k_0\) 是 DenseBlock 的輸入特徵圖數量(即第一個折積層的輸入通道數)。DenseNet 網路和其他網路最顯著的區別是,\(k\) 值可以變得很小,比如 \(k=12\),即網路變得很「窄」,但又不影響精度。如表 4 所示。
為了在 DenseNet 網路中,保持 DenseBlock 的折積層的 feature map 大小一致,作者在兩個 DenseBlock 中間插入 transition 層。其由 \(2\times 2\) average pool, stride=2,和 \(1\times 1\) conv 層組合而成,具體為 BN + ReLU + 1x1 Conv + 2x2 AvgPooling。transition 層完成降低特徵圖大小和降維的作用。
CNN網路一般通過 Pooling 層或者 stride>1 的折積層來降低特徵圖大小(比如 stride=2 的 3x3 折積層),
下圖給出了一個 DenseNet 的網路結構,它共包含 3 個(一半用 4 個)DenseBlock,各個 DenseBlock 之間通過 Transition 連線在一起。

和 ResNet 一樣,DenseNet 也有 bottleneck 單元,來適應更深的 DenseNet。Bottleneck 單元是 BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3)這樣連線的結構,作者將具有 bottleneck 的密集單元組成的網路稱為 DenseNet-B。
Bottleneck譯為瓶頸,一端大一端小,對應著 1x1 折積通道數多,3x3 折積通道數少。
對於 ImageNet 資料集,圖片輸入大小為 \(224\times 224\) ,網路結構採用包含 4 個 DenseBlock 的DenseNet-BC,網路第一層是 stride=2 的 \(7\times 7\)折積層,然後是一個 stride=2 的 \(3\times 3\) MaxPooling 層,而後是 DenseBlock。ImageNet 資料集所採用的網路設定參數列如表 1 所示:
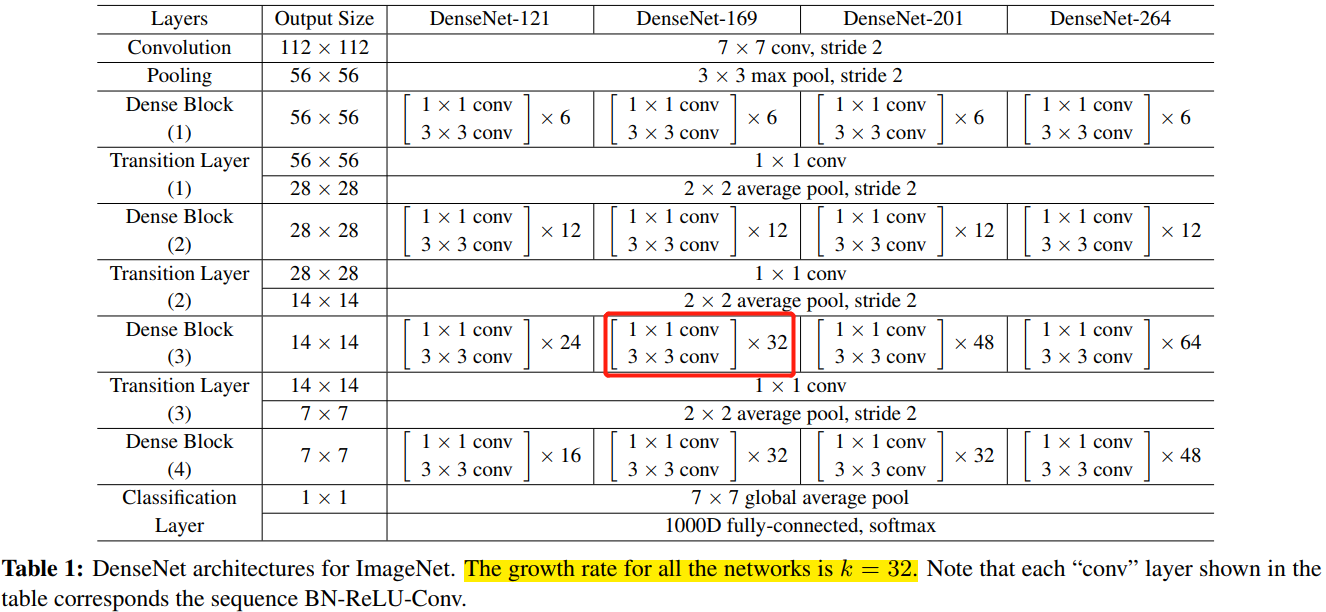
網路中每個階段折積層的 feature map 數量都是 32。
優點
- 省引數
- 省計算
- 抗過擬合
注意,後續的 VoVNet 證明了,雖然 DenseNet 網路引數量少,但是其推理效率卻不高。
在 ImageNet 分類資料集上達到同樣的準確率,DenseNet 所需的引數量和計算量都不到 ResNet 的一半。對於工業界而言,小模型(引數量少)可以顯著地節省頻寬,降低儲存開銷。
引數量少的模型,計算量肯定也少。
作者通過實驗發現,DenseNet 不容易過擬合,這在資料集不是很大的情況下表現尤為突出。在一些影象分割和物體檢測的任務上,基於 DenseNet 的模型往往可以省略在 ImageNet 上的預訓練,直接從隨機初始化的模型開始訓練,最終達到相同甚至更好的效果。
對於 DenseNet 抗過擬合的原因,作者給出的比較直觀的解釋是:神經網路每一層提取的特徵都相當於對輸入資料的一個非線性變換,而隨著深度的增加,變換的複雜度也逐漸增加(更多非線性函數的複合)。相比於一般神經網路的分類器直接依賴於網路最後一層(複雜度最高)的特徵,DenseNet 可以綜合利用淺層複雜度低的特徵,因而更容易得到一個光滑的具有更好泛化效能的決策函數。
DenseNet 的泛化效能優於其他網路是可以從理論上證明的:去年的一篇幾乎與 DenseNet 同期釋出在 arXiv 上的論文(AdaNet: Adaptive Structural Learning of Artificial Neural Networks)所證明的結論(見文中 Theorem 1)表明類似於 DenseNet 的網路結構具有更小的泛化誤差界。
程式碼
作者開源的 DenseNet 提高記憶體效率版本的程式碼如下。
# This implementation is based on the DenseNet-BC implementation in torchvision
# https://github.com/pytorch/vision/blob/master/torchvision/models/densenet.py
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from collections import OrderedDict
def _bn_function_factory(norm, relu, conv):
def bn_function(*inputs):
concated_features = torch.cat(inputs, 1)
bottleneck_output = conv(relu(norm(concated_features)))
return bottleneck_output
return bn_function
class _DenseLayer(nn.Module):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, efficient=False):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate,
kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = drop_rate
self.efficient = efficient
def forward(self, *prev_features):
bn_function = _bn_function_factory(self.norm1, self.relu1, self.conv1)
if self.efficient and any(prev_feature.requires_grad for prev_feature in prev_features):
bottleneck_output = cp.checkpoint(bn_function, *prev_features)
else:
bottleneck_output = bn_function(*prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0: # 加入 dropout 增加模型泛化能力
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
class _DenseBlock(nn.Module):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, efficient=False):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
efficient=efficient,
)
self.add_module('denselayer%d' % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.named_children():
new_features = layer(*features)
features.append(new_features)
return torch.cat(features, 1)
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 3 or 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
small_inputs (bool) - set to True if images are 32x32. Otherwise assumes images are larger.
efficient (bool) - set to True to use checkpointing. Much more memory efficient, but slower.
"""
def __init__(self, growth_rate=12, block_config=(16, 16, 16), compression=0.5,
num_init_features=24, bn_size=4, drop_rate=0,
num_classes=10, small_inputs=True, efficient=False):
super(DenseNet, self).__init__()
assert 0 < compression <= 1, 'compression of densenet should be between 0 and 1'
# First convolution
if small_inputs:
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=3, stride=1, padding=1, bias=False)),
]))
else:
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
]))
self.features.add_module('norm0', nn.BatchNorm2d(num_init_features))
self.features.add_module('relu0', nn.ReLU(inplace=True))
self.features.add_module('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
ceil_mode=False))
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
efficient=efficient,
)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features,
num_output_features=int(num_features * compression))
self.features.add_module('transition%d' % (i + 1), trans)
num_features = int(num_features * compression)
# Final batch norm
self.features.add_module('norm_final', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Initialization
for name, param in self.named_parameters():
if 'conv' in name and 'weight' in name:
n = param.size(0) * param.size(2) * param.size(3)
param.data.normal_().mul_(math.sqrt(2. / n))
elif 'norm' in name and 'weight' in name:
param.data.fill_(1)
elif 'norm' in name and 'bias' in name:
param.data.fill_(0)
elif 'classifier' in name and 'bias' in name:
param.data.fill_(0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
問題
1,這麼多的密集連線,是不是全部都是必要的,有沒有可能去掉一些也不會影響網路的效能?
作者回答:論文裡面有一個熱力圖(heatmap),直觀上刻畫了各個連線的強度。從圖中可以觀察到網路中比較靠後的層確實也會用到非常淺層的特徵。
注意,後續的改進版本 VoVNet 設計的 OSP 模組,去掉中間層的密集連線,只有最後一層聚合前面所有層的特徵,並做了同一個實驗。熱力圖的結果表明,去掉中間層的聚集密集連線後,最後一層的連線強度變得更好。同時,在 CIFAR-10 上和同 DenseNet 做了對比實驗,OSP 的精度和 DenseBlock 相近,但是 MAC 減少了很多,這說明 DenseBlock 的這種密集連線會導致中間層的很多特徵冗餘的。
參考資料
- CVPR 2017最佳論文作者解讀:DenseNet 的「what」、「why」和「how」|CVPR 2017
- https://github.com/gpleiss/efficient_densenet_pytorch