想做長期的 AB 實驗?快來看看這些坑你踩了沒
作者:江顥
1.什麼是長期的 AB 實驗
大部分情況下,我們做的 AB 實驗都是短期的,一到兩週或者一個月之內的,通過分析這段時期內測得的實驗效應得出實驗結論,並最終進行推廣。
長期實驗即執行時間達數月甚至數年的實驗,實驗的長期效應指的是需要數月數年的 AB 實驗才能積累的實驗效應。
那什麼場景下還需要做長期的 AB 實驗,為什麼不直接將短期的實驗效應直接推廣到長期效應呢?
因為在某些情況下,實驗的長期效應和短期效應是不同的 。
例如,在搜尋引擎上顯示不夠匹配的搜尋結果會導致使用者再次搜尋,搜尋份額可能在短期內會增加,但隨著使用者體驗下降並切換到更好的搜尋引擎,搜尋份額從長期來看會減少;同樣,展示更多的廣告可以在短期內增加廣告點選和營收,但長期來看,卻會因為廣告點選甚至搜尋的減少而造成行銷的減少。
執著於短期的 AB 實驗,會使我們傾向於高估技術的短期效應,而低估其長期效應。
2.為什麼要做長期的 AB 實驗
2.1 歸因
資料驅動文化的團隊會使用實驗結果來跟蹤評估團隊的目標,在這種情況下需要對實驗的長期效應進行正確的測量和歸因。分析如果不引入新功能,從長遠來看,產品獲得的效果是怎麼樣的;引入新功能獲得成功的原因,是由於外部政策影響、競品變化還是使用者的體驗得到提升。這種歸因是非常具有挑戰性的
2.2 積累經驗
長期和短期的 AB 實驗在某種業務場景下是否存在差異,如果存在是什麼原因造成的?產品引入新功能對使用者的體驗用什麼影響,如果使用者被新功能吸引,但只體驗一次,則說明新功能可能不太滿足使用者需求;如果使用者需要花費很長時間才能體驗到新功能,則說明使用者引導可能不夠。瞭解這種差異可以為產品後續的升級迭代積累經驗
2.3 推廣結論
通過測量某種場景下的某些實驗的長期效應,我們可以嘗試總結並推廣實驗結論。之後在這類場景下做 AB 實驗時,我們能否通過這些長期效應,建立可預測長期效應的短期指標,將這些指標作為我們實驗的護欄指標;或者在決策中考慮那些推廣的結論
3.為什麼長期的 AB 實驗容易踩坑
我們先來介紹一種最常見最流行的做長期實驗的方式:即延長短期實驗的執行時間,長期執行它。
下圖展示了隨著時間推移,測得的實驗效應變化。第一個實驗週期測得的百分比增量測量值 P1 被認為是短期效應;而最後一個測量值 PT 則被認為是長期效應。
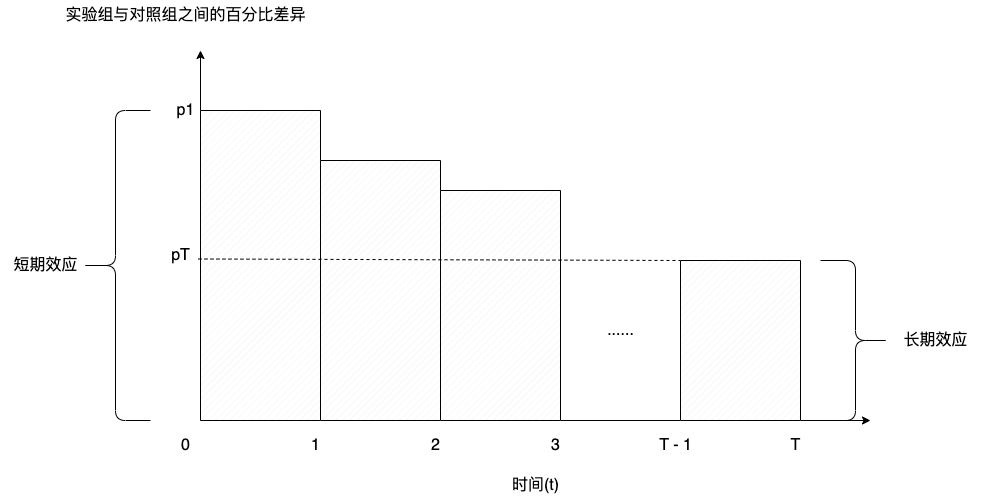
我們以此為例分析下這種簡單的方式容易踩那些坑,導致長期實驗最後一週的測量值 PT 可能無法代表實驗真正的長期效應:
3.1 實驗設計不合理
3.1.1 隨機化單元設計不合理
如果隨機化單元設定成使用者級別,但根據 cookie 進行試驗的隨機化,隨著時間推移,實驗組的使用者可能因為使用新 cookie 而被隨機分配到對照組,時而存在於實驗組,時而存在於對照組,從而帶來偏差。
3.1.2 倖存者偏差
並非實驗開始時的所有使用者都可以存在到實驗結束。
如果實驗組和對照組之間的使用者生存率不同,則 PT 會有幸存者偏差。
如果不喜歡新功能的試驗組使用者隨著時間流逝而啟用產品,那 PT 只包含了哪些仍然存在的使用者以及新加入實驗的使用者,從而帶來偏差。
3.1.3 實驗效應稀釋
使用者是可以使用多個裝置體驗功能,而如果實驗僅測量其中的一個子集。 那實驗時間越長,使用者在實驗期間使用多個裝置的可能性就越大。對於最後一週記憶體取的使用者,實際上實驗只包括了在整個時間段 T 中一部分的使用者體驗, 以 PT 衡量的結果不是使用者在時間 T 曝光於實驗的長期效應,而是稀釋後的結果。
3.2 實驗組和對照組之間存在潛在的干擾
3.2.1 直接關聯
使用者行為往往會受到網路中其他人的影響,尤其是熟悉的人的行為的影響。
如果被測試功能對使用者有顯著的影響,即使其本身可能需要一段時間才能被使用者發現並使用,但經過滲透使用者的社交圈,通過網路傳播可能很快就被發現並使用了。
例如如果實驗組會促使使用者給其他使用者傳送更多的私信,那麼對照組使用者也會回覆這些私信,並可能更主動傳送私信。如果實驗關注指標是私信傳送總數,那對照組關注指標也會增長,測出來的試驗組資料和對照組資料差別會偏小,而不能完整的捕捉到新演演算法的收益
3.2.2 間接關聯
實驗組和對照組可能會因為共用某種資源而產生間接關聯,造成干擾。
例如 uber 測試一個溢價演演算法,效果很好以致於實驗組的使用者更願意打車,那麼在路上可能接客的司機數量減少了,對應的對照組的價格會升高,導致照組使用者願意打車的意願降低了。這種情況,會高估實驗組和對照組的差別。
又如關於搜尋引擎基於的關聯模型的實驗,如果我們使用從所有使用者那裡收集到的資料訓練實驗組和對照組,實驗組的關聯模型可以更好的預測使用者喜歡點選什麼,那麼實驗執行時間越長,實驗組產生的'好的'點選資料也會使對照組收益。實驗組和對照組的差別會降低。
3.3 實驗使用者的行為變化
隨著使用者對被測功能的學習並適應變化,使用者的行為也會發生變化。
如果被測功能是新功能,也許需要一段時間才能被使用者注意並使用,但是一旦發現它是有用的,長期來看,使用者就會頻發使用。
如果被測功能是對已有功能的修改,使用者由於已經適應了舊功能,使用者可能會需要時間適應新功能;也可能使用者會在短期內對新功能產生興趣,投入更多的時間和探索,但長期來看,使用者行為最終會達到一個平衡點。
對於這些情況,實驗的短期效應和長期效應存在不同
3.4 外部生態系統的變化
3.4.1 季節性變化
不同季節,商家會採取不同的行銷活動,導致使用者的購買意圖不同。例如雙十一期間使用者的購買意圖會比非雙十一期間表現不同
3.4.2 重大事件
例如政策發生變化、大型社會事件,都可能會影響使用者的被測試功能的表現
3.4.3 競品影響
如果競爭對手啟動了相同的功能,則可能影響使用者對被測試功能的體驗,該功能的價值可能會下降。
3.4.4 啟動其他新功能
長期實驗執行期間可能會啟動許多其他實驗,並且可能與被測試的功能進行互動,隨著時間推移,可能會對實驗產生影響。
4.如何做長期的 AB 實驗
實驗長期效應的偏差可能是由於不同原因引起的,以下介紹幾種改善長期實驗的測量方式來預防或者修正這種偏差。
注意沒有一種方式可以完全解決所有的偏差,都可能存在某種侷限性,建議使用前評估這些方法的侷限性。
4.1 群組分析
在實驗開始之前構建穩定的使用者群,並僅分析對該使用者群的短期效應和長期效應。這種方法可以幫助解決倖存者偏差和實驗效應稀釋的問題。
但這種方式有幾點需要注意:
1.群組的穩定性對這種方法的有效性非常重要。如果隨機化單元是基於 cookie 的,由於 cookie 流失率很高,群組的穩定性則比較差,導致這種方法不能很好的糾正偏差
2.群組必須具備代表性。如果群組不能代表總體人群,那分析結果可能無法推廣到整個人群。
4.2 後期分析
該方式的關鍵是在實驗執行一段時間後,使對照組使用者和實驗組使用者在測量期間內的產品體驗完全相同。
對於這種方式有兩種選擇:第一種在執行一段時間(時間 T)後關閉實驗,然後在時間 T 和時間 T + 1 期間測量實驗組使用者和對照組使用者之間的差異;或者可以將實驗組釋出給所有使用者來應用此方式。
這種方式本質上是在最後一段時間內做了一個 A/A 實驗,根據後期的 A/A 實驗測量長期效應。
但這種方式有個前提隱患,即系統可能‘記住’了實驗期間的資訊,我們稱之為系統的習得效應。常見的例子是通過機器學習模型向實驗組使用者展示更多的廣告,實驗組使用者使用足夠長的時間後系統可能會更瞭解使用者,即使在後期進行了 A/A 實驗,也仍然會向他們展示更多的廣告。
如果實驗中,系統的習得效應為零,那 A/A 實驗之後實驗組和對照組使用者都曝光於完全相同的一組功能。給定足夠多的實驗,測量使用者的習得效應,然後從新的短期實驗中外推出長期效應。
這種方式能有效的將效應與隨時間變化的外在因素和其他新功能帶來的潛在互動影響分割開來。因為使用者的習得效應是單獨測量的,能為實驗短期效應與長期效應的不同帶來更多的分析依據。
但這種方式存在倖存者偏差和實驗效應稀釋的問題,可與群組分析方式結合使用。
4.3 實驗留白
長期執行對照組是存在一定的成本的,代價可能是昂貴的,因為他們一直沒有獲得實驗組的新功能。因此如果迫於時間、迭代週期的壓力,需要將被測試的新功能推全給所有使用者,一種方式就是實驗留白。實驗結果出來之後,將實驗組流量釋出給 90%、95% 的使用者,剩下的使用者留在原來的對照組數週或在數月。
留出實驗是長期執行實驗的一種典型方式,但需要注意的是由於對照組流量比例此時比較小,統計功效會變低,要確保仍有足夠的流量不會影響實驗的目標